A2 CS - 15 - Hardware and Virtual Machines
0.0(0)
Studied by 2 peopleCard Sorting
1/37
Earn XP
Description and Tags
Last updated 7:33 AM on 5/9/23
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
38 Terms
1
New cards
CISC
larger instruction set with multiple instruction formats, multi-cycle variable-length instructions requiring more memory, microprogrammable CU, poor pipelineability, more efficient use of RAM, may support microcode
2
New cards
RISC
smaller instruction set with few instruction formats, single-cycle fixed-length instructions requiring less memory, hardwired CU, better pipelineability, heavy use of RAM, uses more general multi-purpose registers
3
New cards
CISC - microprogrammable CU
control signals generated by software: code must be translated into microinstructions to generate so CU operates slower, easy to modify. software is less expensive, able to handle complex instructions
4
New cards
RISC - hardwired CU
control signals generated by hardware: CU can operate faster, difficult to modify. hardware is more expensive, unable to handle complex instructions
5
New cards
interrupt handling with pipelining
kernel consults IDT, links device to ISR, gives address of low level routine to handle interrupt.
either: erases pipeline contents for latest 4 instructions then saves state of remaining process in pipeline on stack to be restored after interrupt is serviced.
or: stores pipeline contents in 5 individual program counter registers to be restored after interrupt is serviced.
interrupts are prioritised using IPL: if interrupt priority > current process then process is suspended, if interrupt priority < current process then interrupt is stored. process with lower IPL is saved in interrupt register to be serviced when IPL falls to that level, current register values stored in PCB
either: erases pipeline contents for latest 4 instructions then saves state of remaining process in pipeline on stack to be restored after interrupt is serviced.
or: stores pipeline contents in 5 individual program counter registers to be restored after interrupt is serviced.
interrupts are prioritised using IPL: if interrupt priority > current process then process is suspended, if interrupt priority < current process then interrupt is stored. process with lower IPL is saved in interrupt register to be serviced when IPL falls to that level, current register values stored in PCB
6
New cards
explain pipelining
5 stages in FE cycle, takes 5 clock cycles to complete 1 FE cycle, as an instruction enters stage 2 of FE cycle, processor can already start fetching next instruction
7
New cards
why implement pipelining
allows multiple instructions to be executed simultaneously without waiting until the previous instruction is complete to begin the next, allows more efficient use of resources
8
New cards
5 stages of FE cycle
IF (instruction fetch), ID (decode), OF (operand fetch), IE (execute), WB (result write back)
9
New cards
pipelining issues
RAW, WAW, WAR
10
New cards
read after write
reading from same register that first instruction is writing to, but may read before value is written or ready to read, fix by stalling: identify the error and wait until write is resolved before reading.
11
New cards
write after write
writing to same register, but second instruction writes its result before the first, fix by renaming: modify second instruction to put its result in a different register.
12
New cards
write after read
reading from same register that second instruction is writing to, but second instruction writes its result before first instruction has read it, fix by renaming: modify second instruction to put its result in a different register
13
New cards
name the 4 basic computer architectures
SISD, SIMD, MISD, MIMD
14
New cards
SISD
Single Instruction Single Data, uses single processor, processing one data source, e.g. early personal computers with simple applications
15
New cards
SIMD
Single Instruction Multiple Data, uses single control unit instructing multiple processing units, processing parallel data inputs, e.g. multiple PUs aka array processors found in graphics cards, each pixel can be allocated a PU so brightness adjustments can happen simultaneously to maintain a consistent image
16
New cards
MISD
Multiple Instruction Single Data, many processors, all processing same shared data source, e.g. fault-tolerance system, same data inputted to multiple processors, output only accepted if all outputs are the same
17
New cards
MIMD
Multiple Instruction Multiple Data, many processing units, asynchronously processing parallel data inputs, each processing unit with dedicated cache memory executes a different instruction concurrently, e.g. multi-core systems like supercomputers/massively parallel computers
18
New cards
massively parallel computers
aka supercomputers, linking together several computers with interconnected data pathways, forms one machine with thousands of processors
19
New cards
parallel processing considerations
communication is important as data may need to be passed between processors, software design must consider parallel processing capabilities
20
New cards
parallel processing benefits
faster for processing independent data, removes bottleneck issue with Von Neumann model due to lower latency
21
New cards
parallel processing drawbacks
not suitable for processing dependent data, requires more expensive hardware
22
New cards
virtual machine
emulation of an existing computer system using a host OS and a guest OS for emulation
23
New cards
roles of virtual machines
testing new software on different OS, accessing virus-infected data, running software on OS they weren’t originally intended for, creating OS backups
24
New cards
host OS
the usual OS, controls physical hardware
25
New cards
guest OS
an OS running on a VM, controls virtual hardware
26
New cards
hypervisor
VM software that creates and runs VMs
27
New cards
benefits of VM
can test new software on many different OS emulations as multiple VMs can run simultaneously on same physical computer saves cost of buying lots of different hardware, sandboxed so easier to recover if VM crashes or downloads a virus as host OS is unaffected
28
New cards
drawbacks of VM
some OS cannot be emulated in a VM because they may be new so the VM does not exist yet, performance is slower than real machine because of extra load on host OS
29
New cards
combinational circuit
output depends entirely on input values, e.g. adder circuits
30
New cards
sequential circuit
output depends on input values produced from previous output values, e.g. flip-flop circuits
31
New cards
flip-flop
acts as a single bit of stable memory in storage or RAM with two states, able to maintain stable output Q that can only be changed by either an input pulse or power loss, also generates complement of output Qbar
32
New cards
draw an SR flip-flop circuit
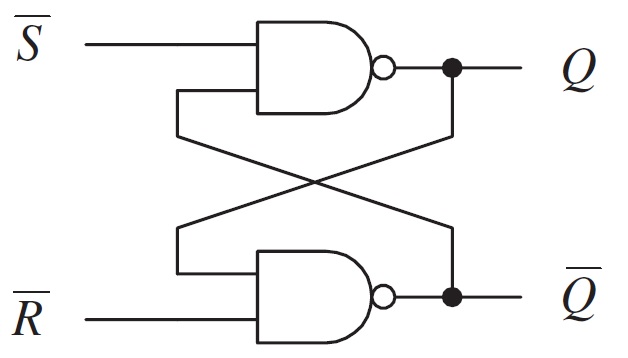
33
New cards
draw a JK flip-flop circuit
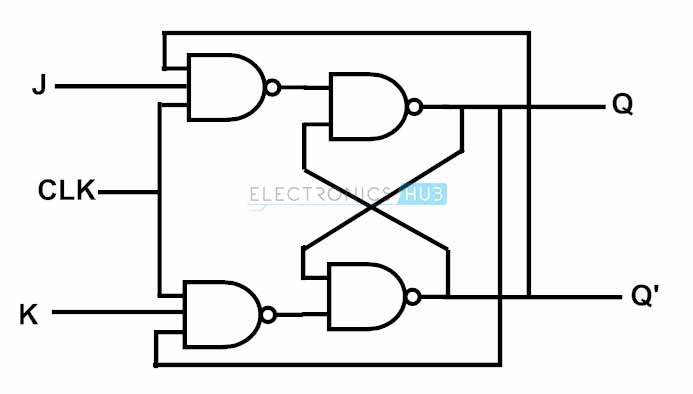
34
New cards
Karnaugh maps
method used to simplify logic statements and circuits, uses Gray codes: ordering of binary numbers such that successive numbers differ by only one bit value, e.g. 00 01 11 10
35
New cards
half adder
carries out binary addition on two 1-bit inputs, outputs a sum and a carry bit
36
New cards
full adder
two half adders combined to allow binary addition on two binary number inputs with a carry in, outputs a sum and a carry out
37
New cards
SR flip-flop
set reset flip-flop aka latch, initial state S=0 R=0 → racing state, set state S=1(pulse) R=0 → Q=1 Q’=0, reset state S=0 R=1(pulse) → Q=0 Q’=1, unchanged state S=1 when Q=1 or R=1 when Q=0, invalid state S=1 R=1 → racing state
38
New cards
JK flip-flop
same as SR flip-flop but has clock input, synchronises the two inputs to prevent invalid racing states by toggling after each clock pulse