Psychometrics - Exam 1
1/26
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
27 Terms
Define self-report measures with (at least) two advantages and two disadvantages.
A type of measure where participants report on some aspect of themselves.
Advantages:
Easy to collect
Can be administered by people who require relatively little training
Disadvantages:
People might not be willing to make completely accurate reports
Depends on the verbal skills of the respondents
Define a behavioral measure with (at least) two advantages and two disadvantages.
A type of measure where the researcher watches and records what people actually do and how they act.
Advantages:
Can be used without people being aware they they’re being observed
Can see behaviors that are performed automatically/unconsciously
Disadvantages:
Observers need to be trained to observe accurately
Can’t know their reasons for doing something/what their behavior means to them
Define a physiological measure with (at least) two advantages and two disadvantages.
A type of measure used to assess people’s biological responses to stimuli using electronic/mechanical instruments.
Advantages:
Not under people’s voluntary control and can’t be easily edited
Provide the most direct quantifying biological responses with precise measurement
Disadvantages:
Expensive to purchase and maintain the equipment
Participants losing interest can interfere with quality of the data
Define two question formats, including 1) why researchers prefer closed-ended questions and 2) when open-ended questions are useful.
Open-ended questions: These allow respondents to say anything they want to say; more elaborate and detailed answers. They’re useful you’re asking about sensitive/socially disapproved behaviors.
Close-ended questions: Participants select one response from a list of choices provided by researcher (yes or no answers). Researchers prefer these since they’re easily quantified (1 = low, 5 = high).
Explain four question-related biases with examples, respectively.
Scale ambiguity: when using unclear expression in the responses (ex: using a scale that goes none / a little / quite a bit / great amount - this is fairly unclear)
Category anchoring: when the response options serve as cues for an appropriate response (answer that they drank lower amounts of alcohol because they feel like what they actually drank was too much)
Estimation biases: when asking frequency and amount during the longer period or habitual behavior and they can’t remember correctly (someone cannot remember if they took their medication every single day last year)
Perceived meaning of negative sign: a negative sign being perceived as a negative status (a score of 1 is perceived better than a score of -3)
Explain three person-related biases with examples, respectively.
Social desirability: the tendency to respond in a way that makes the respondent look good (ex: job interviews)
Halo bias: happens when respondents overestimate the positive characteristics and underestimate the negative characteristics of people (or other stimuli) that they like or already know (ex: physically attractive person might be seen as more intelligent than they really are)
Stereotype: happens when a respondent sees a stimulus as being positive or negative on some important characteristic and that evaluation influences ratings of other characteristics (ex: looking at someone’s gender and judging the group they are in and evaluating the person based on that group)
Define nominal scales, ordinal, interval, and ratio scales with examples, respectively.
Nominal = categorical variables that represent different categories, but there is no specific order (example - gender, there is no specific order for male and female)
Ordinal = categories that are ranked; no points on the scale have the same difference (example - rank of student test scores)
Interval = scores are put in some sort of magnitude and there are also equal intervals between adjacent points on the scale (example - depression rating)
Ratio = this has all the features of the interval scale, except that there is an absolute zero point (example - weight)
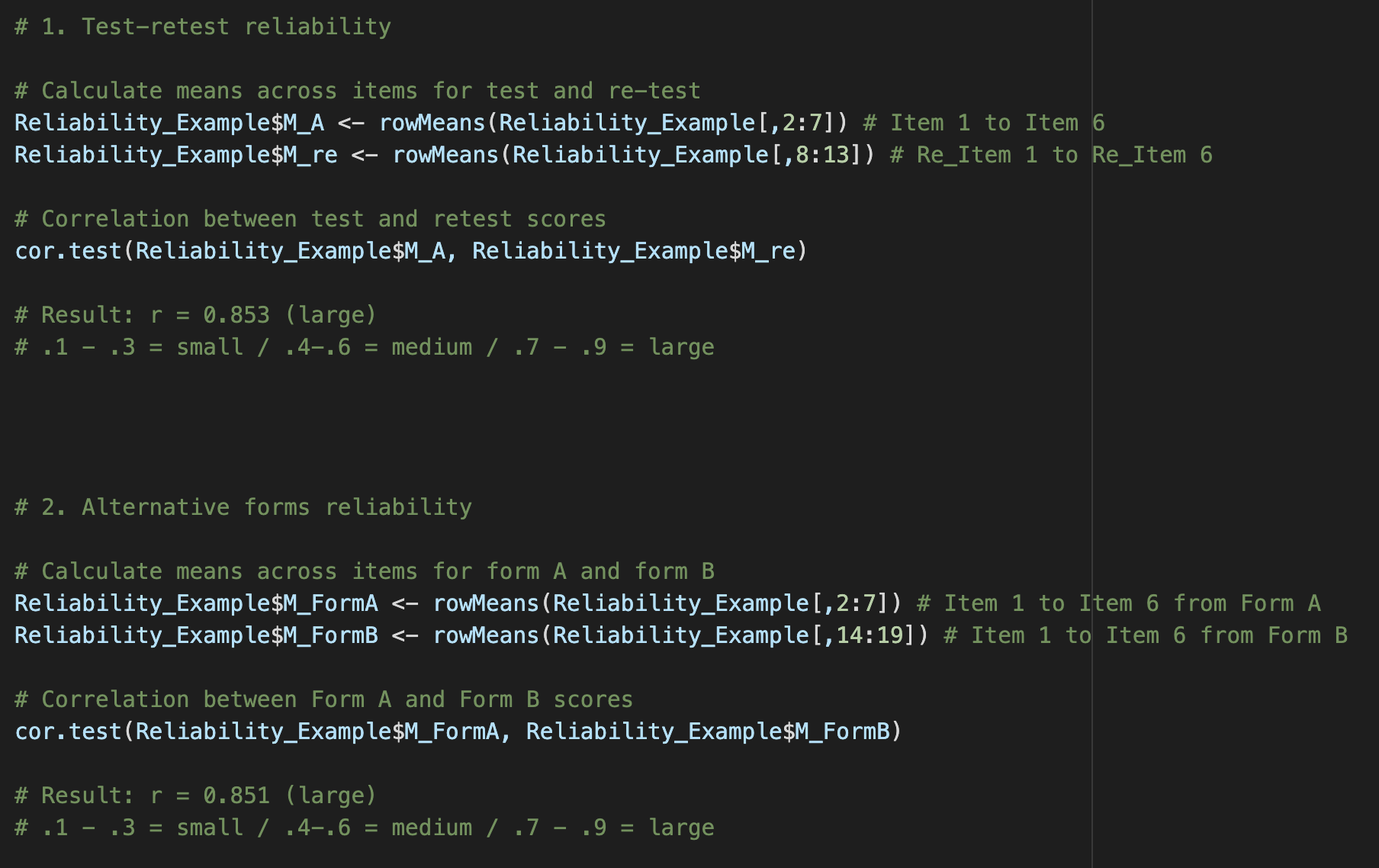
Define test-retest reliability, including 1) definition, 2) limitations, and 3) statistical analysis.
Definition: An estimate of reliability by correlating pairs of scores from the same people on two different times taken of the same test
Limitation: Fatigue effect and the fact that people might learn new things, forget some things, or acquire new skills between each test
Statistical analysis: Correlation between two time points’ scores
Define alternative (parallel) forms reliability, including 1) definition, 2) limitations, and 3) statistical analysis.
Definition: The degree of the relationship between various forms of a test; two different tests are given to the same group
Limitations: Low motivation to take another test and it is time-consuming and expensive to develop two forms
Statistical analysis: Correlation between the two tests’ form scores
Define split-half reliability, including definition, advantage, and statistical analysis.
Definition: A type of internal consistency; when you correlate two pairs of scores obtained from equivalent halves of a single test given once
Advantage: Useful when it does not need multiple forms or multiple times measured
Statistical analysis: Correlation between two half-split measurements
Define inter-item consistency, including definition, advantage, three types of inter-item consistency tests, statistical analysis, and caveats.
Definition: Degree of correlation among all the items on a scale; a measure is calculated from a single administration of a single form
Advantage: Useful when it does not need multiple forms or multiple times measured
3 types: Kuder-Richardson 20, Kuder-Richardson 21, and Cronbach alpha
Statistical analysis: Correlation value among all items (specifically for Cronbach alpha)
Caveats: Cronbach’s alpha is a characteristic of a certain group of test scores, not of the test itself; you need to do a reliability test each time you have a new sample
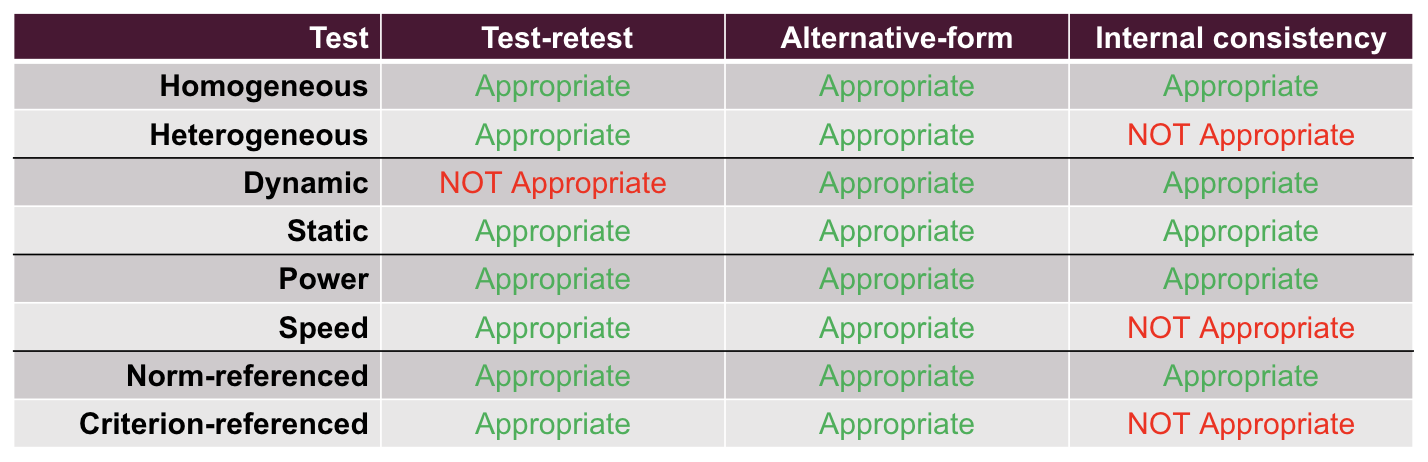
Explain which reliability analyses are recommended when your measure is a homogeneous test or a heterogeneous test, respectively.
Homogeneous test: Test-retest reliability, alternative-form reliability, and internal consistency are all appropriate to use
Heterogeneous test: Test-retest reliability and alternative-form reliability are appropriate, but internal consistency is not appropriate. It’s recommended to calculate internal consistency by each factor instead.
Explain which reliability analyses are recommended when your measure is a dynamic test or a static test, respectively.
Dynamic test: Alternative-form reliability and internal consistency are both appropriate. Test-retest reliablity is not appropriate since you are measuring something that is changing.
Static test: Test-retest reliability, alternative-form reliability, and internal consistency are all appropriate since the trait measured is presumed to be unchanging.
Explain which reliability analyses are recommended when your measure is a speed test or a power test, respectively.
Speed test: Test-retest reliability and alternative-form reliability are appropriate. Internal consistency is not because speed test questions should be easy enough to check their speed and not their knowledge.
Power test: All 3 types of tests are appropriate.
Explain which reliability analyses are recommended when your measure is a norm-referenced test or a criterion-referenced test, respectively.
Norm-referenced test: Test-retest reliability, alternative-form reliability, and internal consistency are all appropriate.
Criterion-referenced test: Test-retest reliability and alternative-form reliability are appropriate. Internal consistency is not because of small variability of scores in the sample since no one tries to get higher points than the cut-off score
Explain the differences among Cohen’s Kappa, Weighted Kappa, and Fleiss Kappa.
Cohen’s Kappa assumes that all disagreements are equivalent
Cohen’s Kappa and Weighted Cohen’s Kappa can only be used when there are two raters.
Weighted Cohen’s Kappa and Fleiss’ Kappa consider the severity of the disagreement
Fleiss’ Kappa allows for more than two raters and allows missing data
Define content validity, including the definition and how to quantify content validity.
It is the judgment of how adequately a test samples behavior representative of the universe of behavior that the test was designed to sample. It is quanitified by using the Content Validity Ratio, which looks at number of panelists who say the item is essential to the measure.
Explain two requirements to select appropriate criteria for criterion-related validity.
The first is that the criterion measure should be of high quality (high reliability and validity). The second is that the criterion construct should be closely related to our construct but should not fully overlap (ex: self-esteem and self-confidence)
Explain two types of criterion-related validity, including definition, statistical analyses, and an example, respectively.
Concurrent validity: test criterion measure scores are obtained at the same time that the developed measures are
Statistical Analysis: Pearson correlation
Example: Collect sample with both self-esteem and self-confidence measures at the same time. Then, do a correlation analysis of the two scores from each measure. Depending on the results, we can say our developed measure has concurrent validity
Predictive validity: looks at how accurately scores on the developed test predict some criterion measure
Statistical Analysis: Regression analysis
Example: Measuring the relationship between aggression and future substance
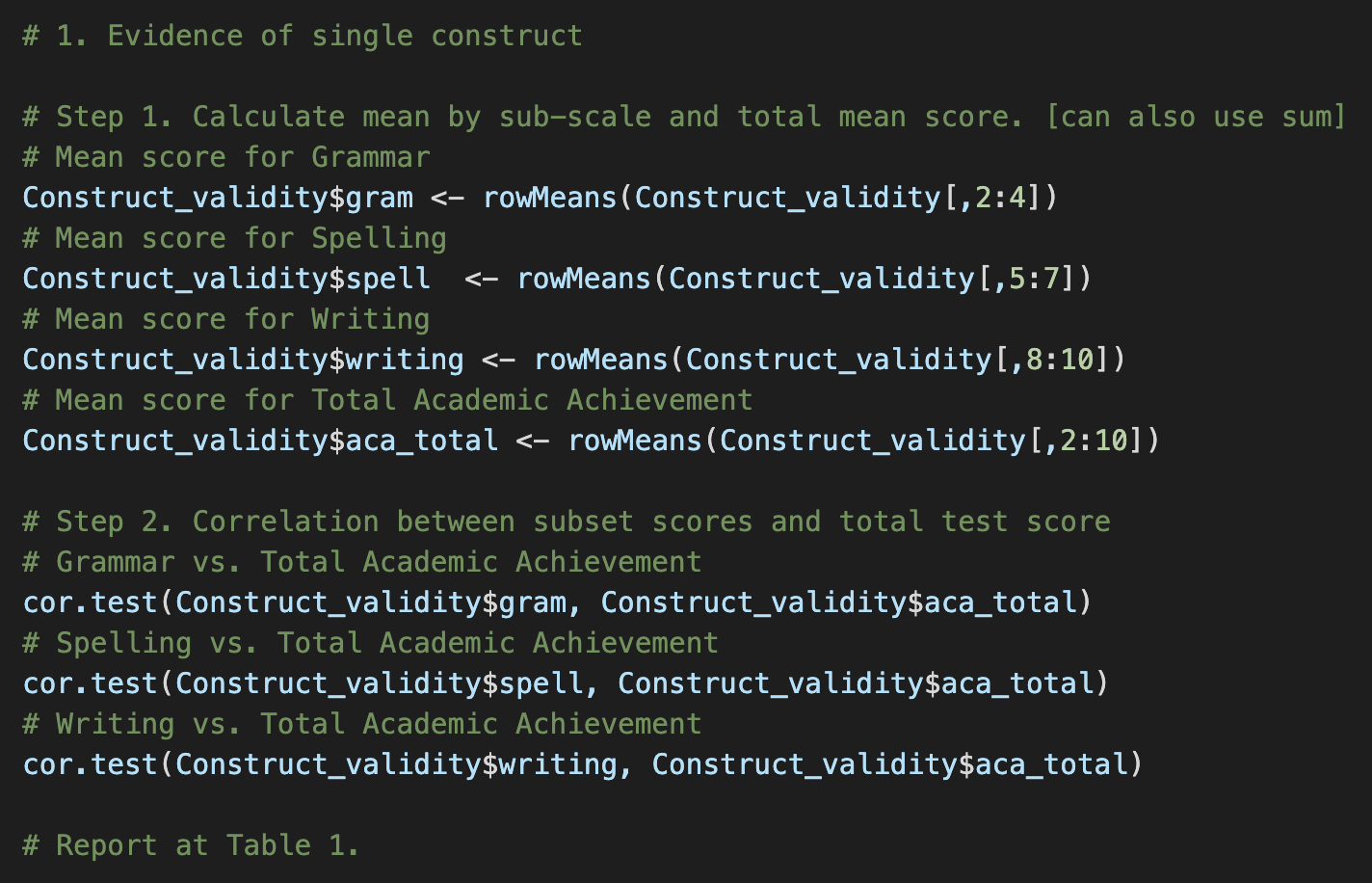
Define the construct and explain what our expectation is if our test is a valid measure of the construct.
It is unobservable and underlying traits that a test developer may invoke to describe test behavior or criterion performance. Our expectation would be fore high scorers and low scorers to behave as predicted by our hypotheses.
Explain two validity tests from the expected characteristics of the construct, including definition, statistical analyses, and an example, respectively.
Evidence of Changes with Age: tests that the measure shows changes across time (by age)
Statistical analysis: Longitudinal analysis (Repeated t-test, Repeated ANOVA)
Example: Measuring motor skills in toddlers and children and seeing that it changes as they grow older
Evidence of Pretest-Posttest Changes: measures if the construct is changed by stimuli or if the stimuli includes the contents that can change the level of the construct we are measuring
Statistical analysis: Repeated t-test
Example: Music skills should be changed after taking classes related to music
Lab 2 - Reliability related to Measurement

Lab 3 - Inter-rater Reliability

Lab 4 - Content Validity
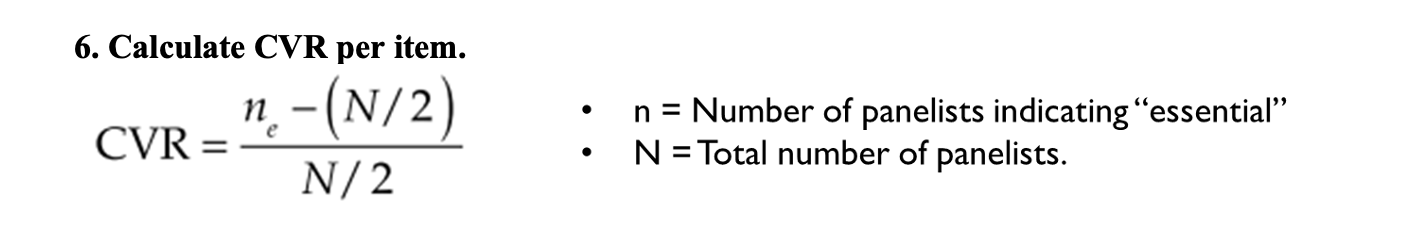
Lab 5 - Construct Validity

Levels of Agreement
0 = no agreement
0.01 - 0.20 = slight agreement
0.21 - 0.40 = fair agreement
0.41 - 0.60 = moderate agreement
0.61 - 0.80 = substantial agreement
0.81 - 1.00 = nearly perfect agreement