Databases- 2024/2025
1/142
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
143 Terms
problem analysis
identify and understand:
data to be collected
requirements
constraints
facts and enterprise rules etc…
database design
produce data models
entities and their relationships
database implementation
structured data in the physical database
database monitoring/tuning
monitor db usage
re-structure and optimise databse
data models
specify the concepts that are used to describe the db : its content
three categories of data models
high level - conceptual data model
representational level - logical data model
low level -physical data model
conceptual data model
concepts at user level:
entities/ classes
attributes
relationships/ associations.
independent of DBMS
may be presented to user
conceptual data model example
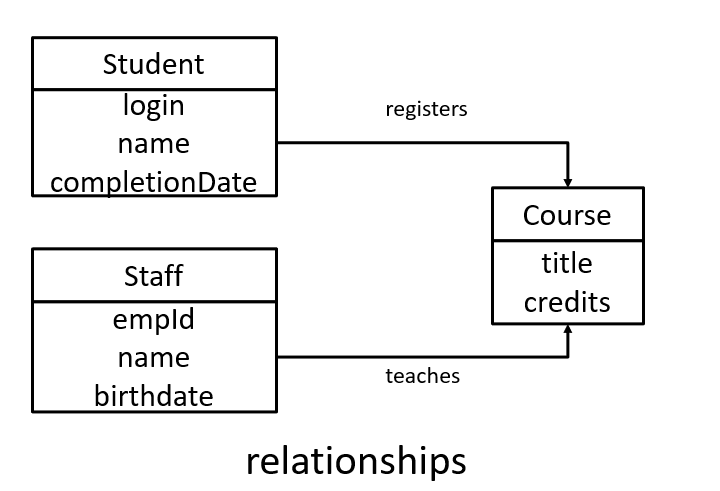
logical data model
e.g relational, network, hierarchical
may be record based, object oriented
physical data model
Describes details of physical data storage, formats, access paths, and ordering
Varies depending on the type of DBMS.
Typically not accessible by the user.
logical data model example
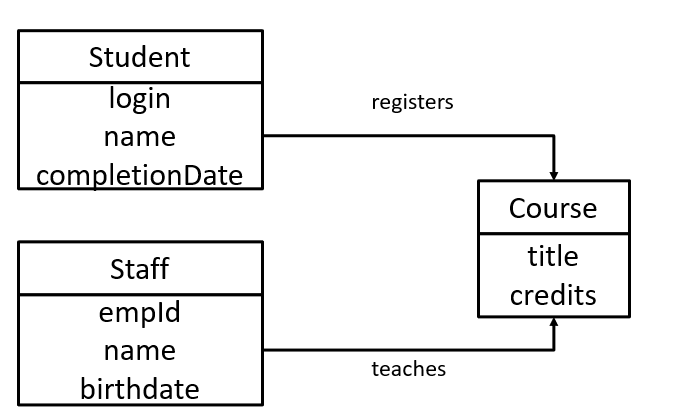
physical data model example
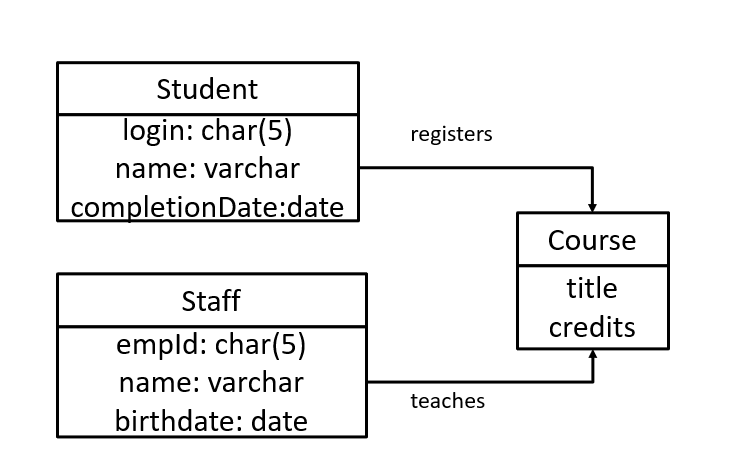
types of logical data modes
relational model
entity-relationship (ER) model
object-oriented model
relational model
forms basis of current database management systems
entity relationship model
A diagrammatic technique.
Provides a generalized approach to representing data.
Helpful in the design of relational database systems.
What is the object-oriented model in databases?
Gaining prominence in data management.
Competes with relational databases for certain applications.
Found in object-oriented databases.
What are the two main types of Database Languages?
Data Definition Language (DDL)
Data Manipulation Language (DML)
What does DDL include?
DDL includes structure and view definition languages.
What are the characteristics of DML?
High or low level (declarative or procedural)
Standalone or embedded in a host procedural language
Set-oriented or record-oriented
What is the single language most DBMS provide?
Most DBMS provide a single Structured Query Language (SQL) consisting of all required functionality.
transactions
a unit of work, i.e. an action, or a series of actions,carried out by a user or application program, which cesses or updates the contents of a database
actions: read/write op on on a ‘granule’ or data item
transaction outcomes
2 outcomes:
success: transaction comitted, db reaches a new consistent state
failure: transaction is aborted/rolled back and db must be restores to consitent state before it started
committed transactions cant be aborted
aborted transactions that are rolled back can be restarted later
transaction example
check wk6 l1 slide13-15
consistency requirements
db integrirty contraints:
entity integrit, referntial integrity
app constraints
a transaction transforms db from one consistent state to another- although consistency could be violated in this transaction
integrirty or app contraint example:
The Primary Key of the Customer table cannot have a null value - integrity: entity integrity
The shipping date of a product cannot be before the order date of the product - app
An entry in the order table must have an existing customer in the customer table: integrity: referential integrity
ACID propertties of transaction
Atomicity
Consistency
Isolation
Durability
Atomicity - transaction property
A transaction is either completed or aborted
Consistency - transaction property
If a database is in a consistent state before a transaction,it should in a consistent state after a transaction
Isolation - transaction property
Partial effects of incomplete transactions should not be visible to other transactions
Durability- transaction property
Once a transaction is committed, its effects must be permanent
atomicity - property and responsibility
p: all or nothing
r: recovery mechanisms
consistency- property and responsibility
p: only valid data
r: DBMS and the transaction implementer to enforce integrity constraints
Isolation- property and responsibility
p: partial effects not visible
r: concurrency control mechanism
durability- property and responsibility
p: effects are permanent
r: recovery mechanism
transaction issue
system failure:
hardware, software, network
concurrent transaction problems:
multiple ppl updating data at the same time
system failures
DBMS must return db to a consisten state after such a disaster - updates of partially executed transactions need to be undone or rolled back
concurrent transactions
DBMS - allows multiple users to access common db at same time
advantages to run multiple trnascations concurrently:
- better transaction thoughput: can full utilise resources
- faster respone time
Possible problems if concurrent transactions are not properly controlled:
Lost updates (dirty write, e.g. lost booking)
Reading uncommitted data (dirty read)
Non-repeatable read (inconsistent analysis, e.g. students in lecture hall)
lost updates (dirt write)
A successful transaction is lost or overwritten because two concurrent transactions are operating on the same data item
reading uncommitted data (dirty read)
A transaction is aborted, but its intermediate states (changed data) are visible to other transactions
non repeatable read ( inconsistent read)
Can occur when one transaction performs an aggregate operation, while another updates data.
schedules
A schedule is a sequence of operations by a set of concurrent transactions.
- the order of ach transaction is preserved
- operations from different transactions may be interleaved
serial schedules
A schedule were the operations of each transaction are executed sequentially
- each transaction commits before the next one is allowed to run
no comcurency issues
but poor throughput and response time
concurrency control
Shared databases must allow concurrent access to data items
Two operations may conflict only if :
-They are performed by different transactions on the same granule or data item, and one of the operations is a write
Concurrency control aims to schedule transactions to prevent conflict/interference between them
schedule is serializable if:
when interleaved actions produce exactly the same results as a serial schedule
serialized schedule - order:
order of reads/writes is important if one transaction writes a data item and another reads/writes the same data item
order not important when:
Two transactions only read a data item, or
Two transactions either read or write separate data items
Concurrency Control Techniques
2 basic control techniques:
locking, timestamping
Both are pessimistic approaches, i.e. they check for conflicts with other transactions on each read/write operation
Optimistic approaches assume conflicts are rare and only check for conflicts at commit
locking
A transaction uses locks to deny access to other transactions to prevent incorrect updates
To access a data item, e.g. a row, a transaction must first acquire a lock on that data item
Was the most widely used approach to ensure serializability
Multi-Version Concurrency Control
Used by all DBMSs that aim for scalability.
(but is more complex)
types of lock
Read Lock – Shared lock :If T1 has a Read Lock on a data item X,T2 may be granted a Read Lock on X but NOT a Write lock on X
Write Lock – Exclusive lock: If T1 has a Write Lock on X, T2 may NOT be granted either Read or Write locks on X
Lock manager maintains list of locks
A transaction can proceed only after the request is granted
two pahse locking
guarantees serializability: but limits the level of concurrency that can be achieved, i.e., how many transactions can make progress at the same time.
two phases:
growing - Locks are acquired incrementally as each data item is accessed,Cannot release any locks
shrinking: All locks are released on commit or rollback Cannot acquire any new locks
two phase lcoking potential problems
deadlock: A circular waiting condition, caused by two or more transactions each waiting for another to release its lock
livelock: Transactions waits indefinitely for a lock despite being rolled back repeatedly
Two or more transactions are changing the data locked, but never get to a state where one can complete
two phase locking - solution to problems
Deadlock prevention (expensive)
Deadlock detection followed by abort/recovery (manageable)
Timeout: abort uncompleted transactions after a timeout (easy)
time stamping
Timestamping is another way to eliminate conflicts -No locking, so no deadlock
timestamping example
check wk6 l1 slides 49-50
timstamping (1)
Timestamping guarantees that transactions are serialisable:
-Operations run in chronological order of timestamps
-No transaction waits no deadlocks
Better than locking if:
-Most transactions are read operations; or
-Most transactions operate on different data items
Not suitable if transactions have lots of conflicts :
-Transactions are frequently rolled back
optimistic methods
In both locking and timestamping, checking is made before Read/Write execution (thus, they are pessimistic)
In optimistic methods:
-No checking is performed during execution
-Transactions applied to local copies of data items and checked for serializability violation before commit
-Efficient when conflicts are rare – e.g. if DB mostly read-only
Three phases:
-Read:Updates applied to local values
-Validation:Check for serializability
-Write: If validation succeeds, updates applied to database,otherwise T is restarted
Query Processing - aims
to transforms a query written in high level lang like SQL into correct and efficient executionstratergy experessed in a lower level lang.
To execute the strategy to retrieve the required data
Restrict operation
Produce a new table, with all the rows that match the predicate (condition)
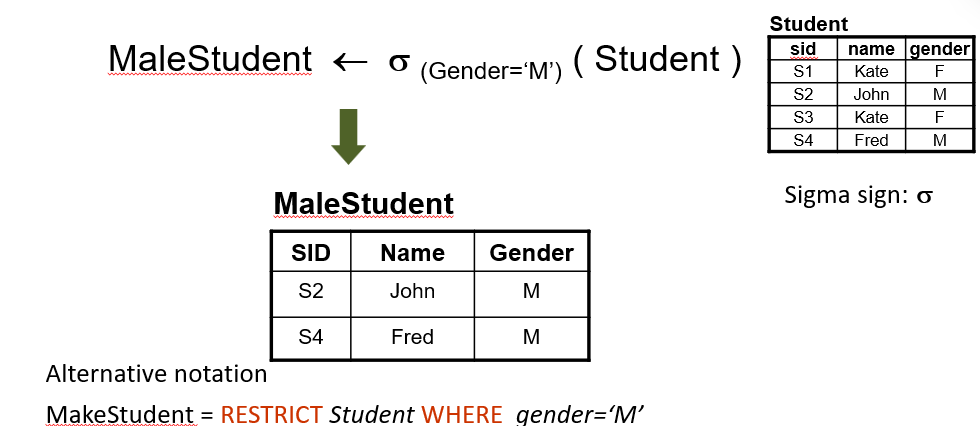
Project operation
Produce a new table, with all rows, but only the named columns
nateral join operation

Query processing example
wk6 l2 - slide 10-15
Standard computing performance indicators, depending on need
time peferomance
space performance
Queries in Relational Algebra
A query may require several operations to be performed
Most queries can be expressed as a combination of RESTRICT, PROJECT, and JOIN operations
Relational algebra is a procedural language,i.e., operations are evaluated in the order specified
efficiency in queries
Complex queries can be executed in multiple different ways
An efficient execution should be selected,as efficiency is an important DBMS requirement,i.e. query optimization
Query Processing
user queries are written in high level lang
queries specify what data is required
four stages of query processing
Query decomposition or parsing
Query optimization
Code generation
Run-time query execution
Query Decomposition
DBMS query processor:
- transforms a usery qry into a sequence of operation no relations
- check whether the query is correct both synthetically and smeantically
- selects a plan:
- - is written on low level and specifies how to retrieve and manipulate the data
- produced relation algebra tree
How to Measure Performance? - two main measures
- throughput: the number of task that can be completed which a given time
- response time: the amount of time required to complete a single task, also called latency.
How can we convert from Throughput to Response Time?

Query Optimisation
choosing an efficient execution stratergy or plan for processing a query;
either cost based or rule based.
cost based strategies
table size, no of rows and columns
disk access(I/O)
db keeps statistics that can be used for cost estimation
rule based strategies
-e.g. a heuristic rule for query optimisation
-Perform restriction and projection operations as early as possible to reduce the size of intermediate tables
Relational Algebra Query Tree
after the decomposition stage the query is converted in a relationalalgebra tree.
query tree
Query tree is built from leaf nodes upwards:
Leaf nodes are created for each base relation
Intermediate nodes for results of relational algebra operations
Root of the tree is the result of the query
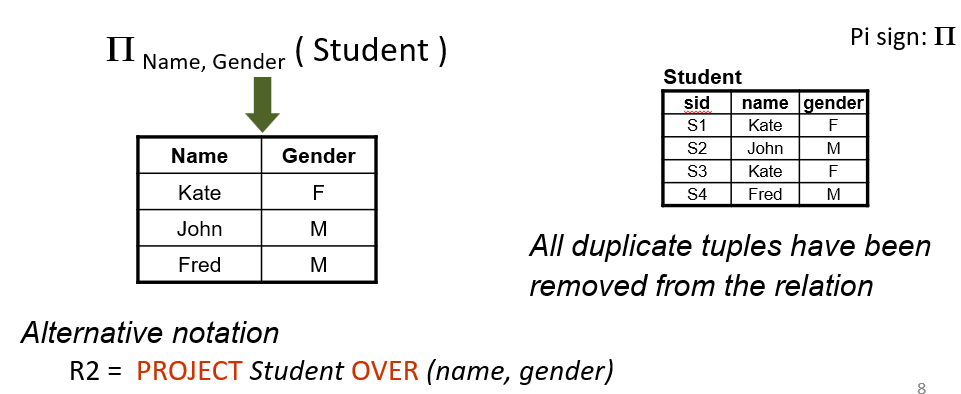
Relational Algebra Query Tree - example
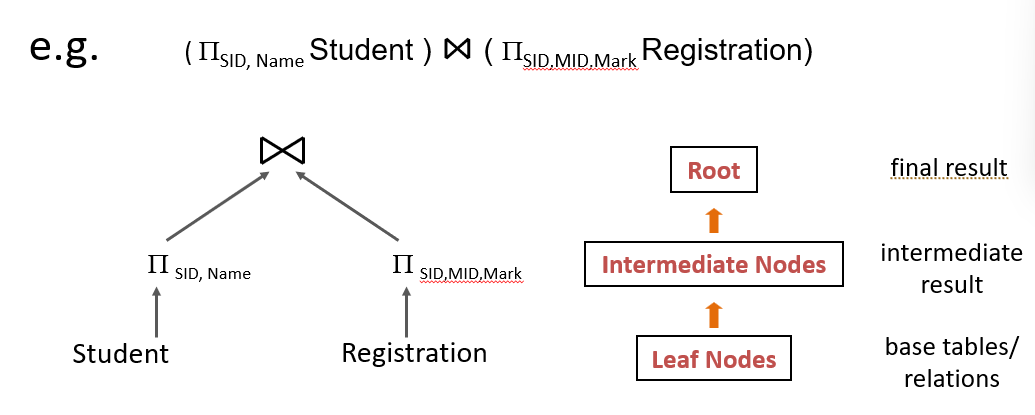
Relational Algebra Query Tree - example2
Physical Database Design
about how the db is implemented on secondary storage
inlcudes:
-spec of base relations/ tables: structures and integrity contraints
- analysis of transactions
-choice of physical representation: file organisation and indexing
- security measures
Database designers should be aware of
transaction requirements
how system resources affect db
Transaction requirements - physcialdb design
freq: no of transactions expected per sec
volume: no of transcations executed overall
type of access: mostly reading, mostly updating, moslty inserting? mis of access?
How system resources affect DB - physcial db design
main memory: sufficient to avoid or minimize swapping
CPU: have enough and fast enough cores to cope with the number of queries
Disk Access: accessing secondary storage is slow, a major bottleneck
Storage: OS, main database files, index files, log files, ideally distributed across multiple disks
Network: if network traffic excessive, collisions can occur and affect DB performance
what is swapping
data not fitting into main mem is stored to disk/ secondary storage, which is much slower.
physical db design -Objectives for file arrangement and access methods include:
throughput should be fast as possible
response time should be acceptably fast
disk storage should be minimised
physcial db design -Objectives may conflict
physical design needs to consider tradeoffs
Physical database design is not static
it must respond to performance monitoring and shifting requirements/usage
A DBMS needs to
Store large volumes of data
Store data reliably
Retrieve data efficiently
Computer storage types
primary: main memory (RAM)
secondary: disk tapes
Primary storage
-Very fast random access: Directly connected to CPU
-But not suitable to store database as it is
Volatile : Data stored in main memory disappears when power is off
Limited capacity
Expensive
Disks
-Very slow data read/write, compare to main memory
-Appropriate database storage medium as they are:
Non-volatile
Large capacity
Cheap
Provide random access to data
-SSD typically much faster than HDD
Tapes
Data can only be accessed sequentially – no random access
Not suitable for storing databases
Used for archival
Typical Usage of Storage Types
main memory: for currently used data
disks: dor main db storage
tapes: for db backupp and archival
File Structure - in db
data are organized as a collection of rows/records
stored in operating-system-managed files or fully managed by the DBMS
Each file contains one or more rows/records: usually belonging to a single table
Each record consists of one or more column
An architecture for data storage
The file manager:
Retrieves rows requested by a user as a collection of pages containing rows in the memory - logical records
Asks buffer manager if the required pages are already in the buffer – an area in the main memory, otherwise
Asks disk manager to retrieve the sectors on the disk where the blocks are located - physical records, which are then placed in the buffer by the buffer manager
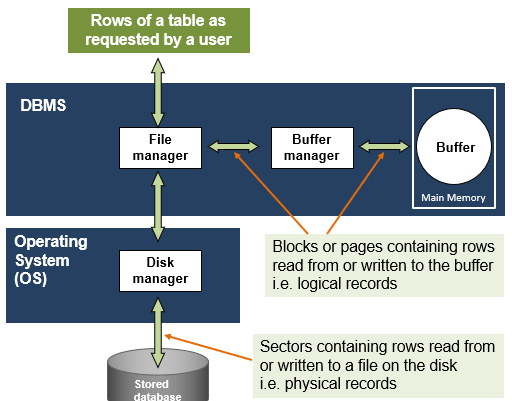
File Structure - os and DBMS
-Operating System (OS) transfers blocks of data between the secondary storage and the buffer in the main memory
-DBMS read/write pages from/to the buffer
-Typically, a page consists of several OS blocks
-Number of rows per page:
Size of row
Whether records are fixed or of variable length
Whether records are spanned/unspanned on disks
spanned record
Large records may be partitioned across pages, a pointer is used to link parts of the same record
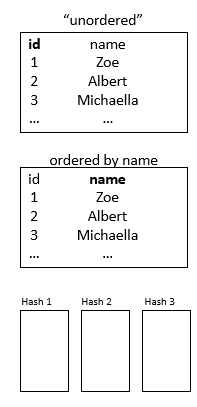
File Organisation
three types:
heap( unordered files)
sequential (ordered)
hash files
Heap (unordered) files
Records are placed on disk in insertion order,i.e. the order in which they are added to the table, which is considered unordered
The simplest and most basic method:
-Insertion is efficient
-Records are added at the end of the file,i.e. in ‘chronological’ order
-Retrieval is inefficient as search is linear from start
-Deletion is also a problem:
space with deleted records is marked as deleted but not freed
requires periodic reorganization to reclaim the marked space if file is very ‘volatile’, i.e. deletion occurs frequently
Heap is the default table structure
heap advangtages and disadvantages
Advantages:
Good for bulk loading data into a table
Useful when often retrieving a large part of the records
Disadvantages:
Inefficient for selective retrieval using key values, especially when table is large
External sorting may be time-consuming
Not suitable for volatile tables,i.e. with frequent changes/deletions
Sequential (ordered) files
Records are placed on disk in order of the value of a specified field
Very rarely used for database storage
Records in a file are sorted on values of one or more fields – ordering fields
Efficient retrieval of records containing a specific value or a range of values of the ordering fields. Binary search is faster than linear search
Problematic in insertion and deletion
Need to make sure records are still ordered
Hash files
Records are placed on disk into buckets or pages according to a hash function,e.g. division remainder (modulo function)
A hash function is applied to one or more fields in the record to generate the address of a disk block or page to store the record
Within each page or bucket, multiple records are stored in slots in the order of arrival
The base field is termed as hash field, or hash key if the field is the key field of the file
Techniques to spread hashes evenly across address space: division-remainder, and folding