19. La puissance statistique - Echantillonnage et recrutement
1/41
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
42 Terms
Collecte de données
Collecte systématique d’informations provenant de diverses sources pour répondre à des questions de recherche, tester des hypothèses et élaborer des théories psychologiques
Conduire une recherche expérimentale
Formuler des hypothèses
Choisir son flux (session, bloc, essais)
Choisir ses variables (VI, VD, confondantes / externes)
Décider du recrutement
population
échantillonnage
aléatoire
convenance
stratifié
boule de neige
critère d’inclusion et d’exclusion
stratégie de recrutement
taille d’échantillon → calcul de puissance
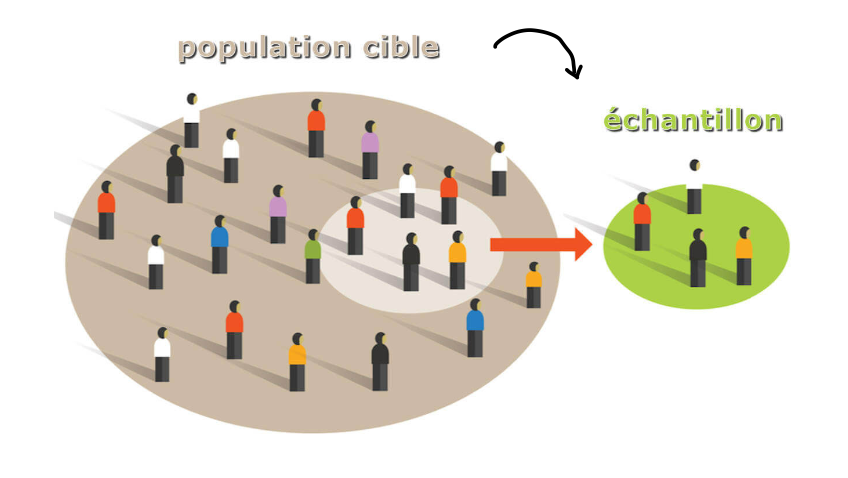
Échantillon
Quantité limitée d'un ensemble utilisée pour représenter et étudier les propriétés de cet ensemble
Puissance statistique
Probabilité de détecter un effet réel avec l'échantillon testé
Chance de détecter (avec notre échantillon) un effet qui existe dans la réalité
En générale mesuré en %
Les erreurs de prédiction
Ce sont des différences entre les valeurs prédites par un modèle et les valeurs observées.
Elles peuvent influencer la validité des conclusions d'une étude ou d'une expérience.
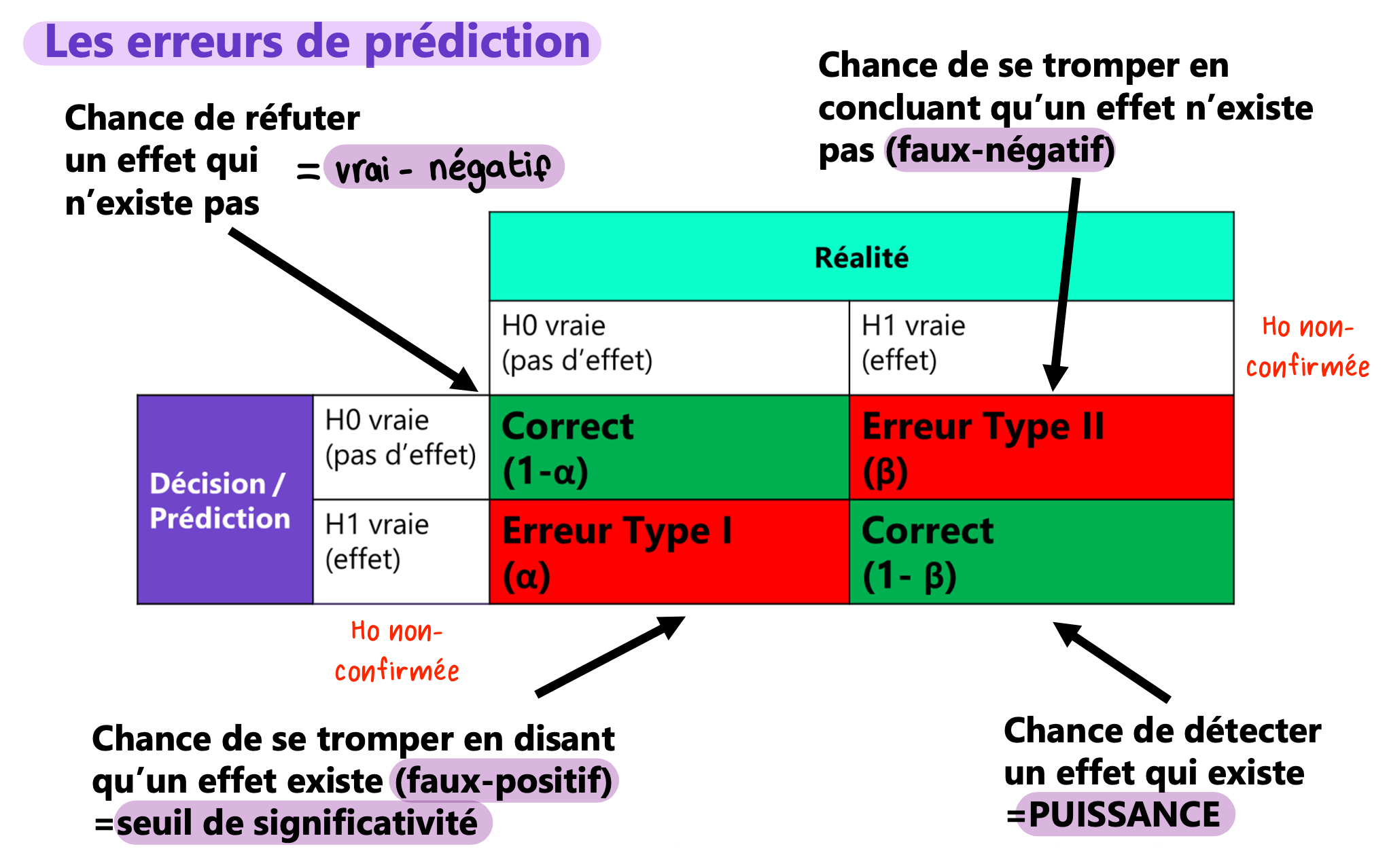
Faux-positif ( Erreur de type I)
Résultat positif d'un test alors qu'il n'y a pas d'effet réel, indiquant une erreur dans la conclusion
Faux-négatif (Erreur de type II)
Risque de conclure qu'un effet n'existe pas alors qu'il existe réellement
Conséquences d’une puissance trop basse
⇒ Conséquence d’un nombre insuffisant de participants
Risque de faux-négatifs (erreurs de type II)
→ une faible puissance augmente le risque de ne pas détecter un effet réel
Mauvaise estimation des effets
→ une faible puissance peut entraîner des estimations moins précises de l’ampleur de l’effet
Gaspillage de ressources
→ temps, effort et financement
Validité
→ risque d’interprétations erronées
⇒ absence de preuve ≠ preuve de l’absence
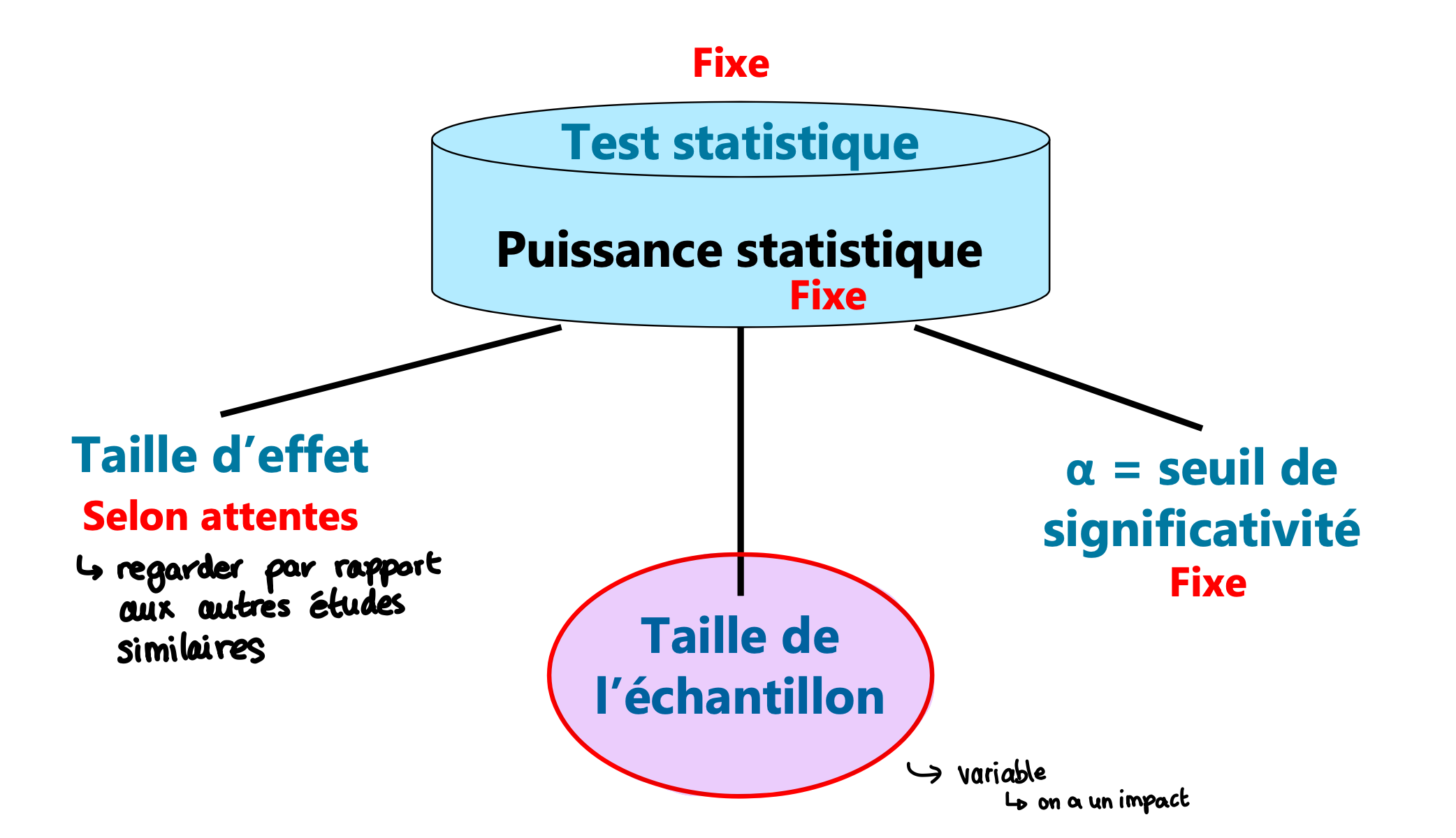
Taille de l'effet
Les effets sont plus faciles à voir si ils sont grands
Taille de lʼéchantillon
Les effets sont plus facile à voir si lʼéchantillon est grand
Seuil de signification (alpha)
Prendre le risque de monter l’alpha augmente vos chances de détecter un effet
→ généralement fixe
Type de test statistique
Certains tests sont plus puissants que d’autres pour une même situation
Variabilité des données
Moins de variabilité (moins de bruit) augmente la puissance
Quelle est la bonne puissance statistique à avoir ?
Jacob Cohen
→ 80 % = 0.8
Pourquoi déterminer l’échantillon ?
Pour s'assurer que les résultats des tests statistiques soient fiables et représentatifs de la population étudiée.
Comment déterminer l’échantillon ?
Méthode 1 : À la louche
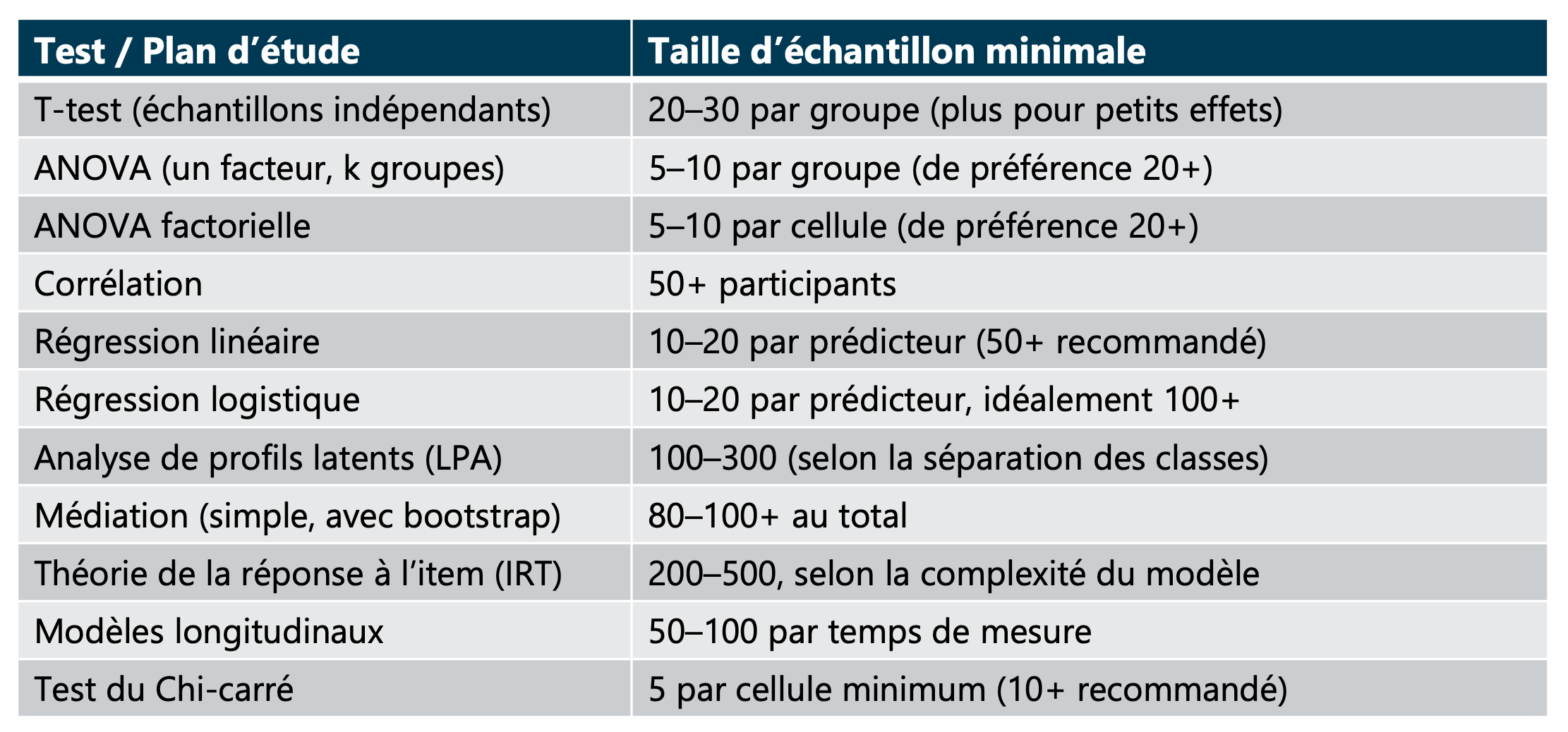
Méthode 2 : L’analyse de puissance
a posteriori
→ méthode statistique utilisée pour déterminer puissance que l’on a dans une étude (= chance de détecter un effet qui existe)
a priori
→ permet de déterminer la taille d’échantillon nécessaire afin de détecter un effet avec une probabilité donnée (80% de Cohen)
⇒ nécessite d’estimer les tailles d’effet
utilisation de G*Power
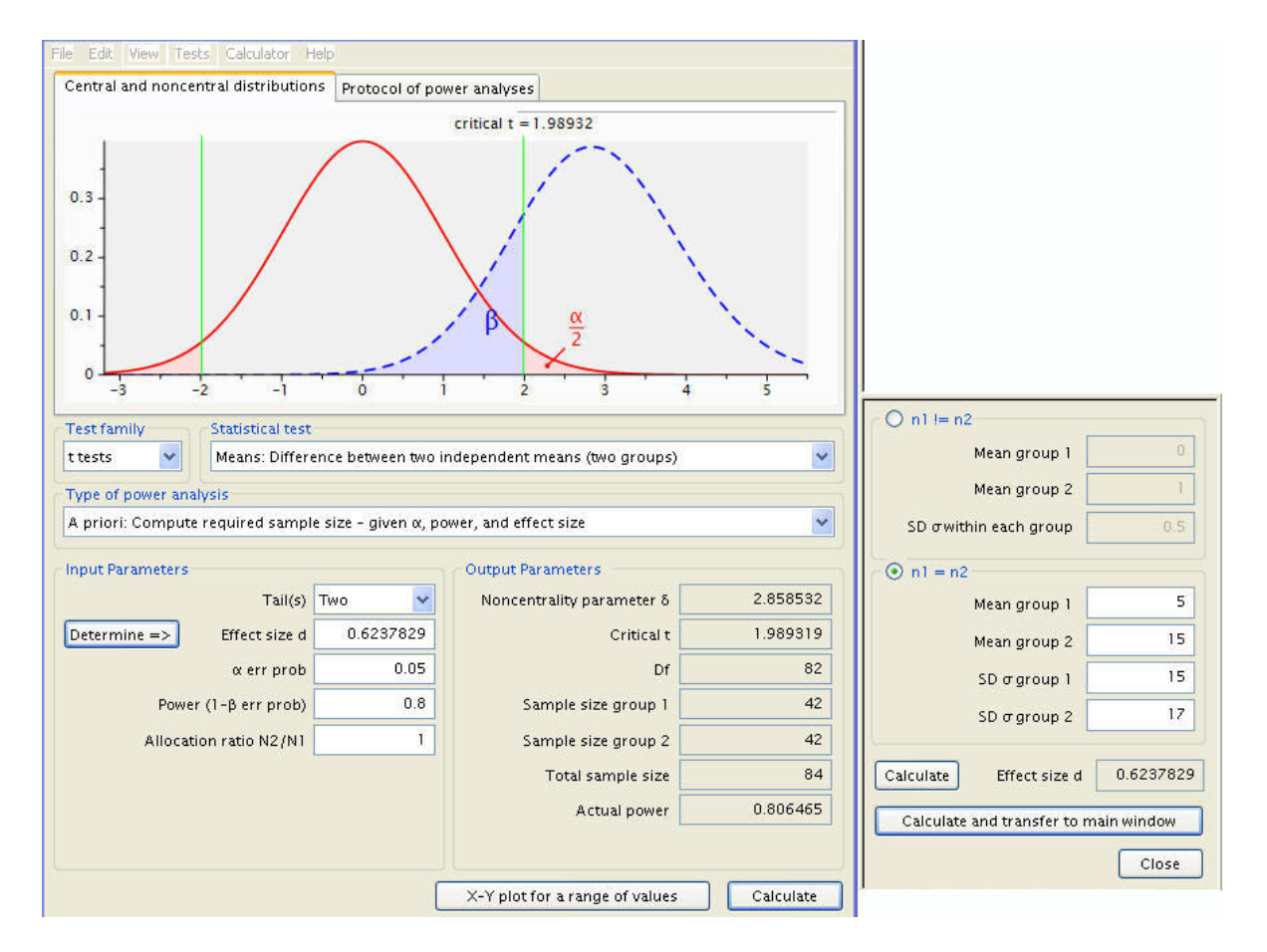
Déterminer la taille d’effet a priori
Indices les plus fréquents → le d de Cohen
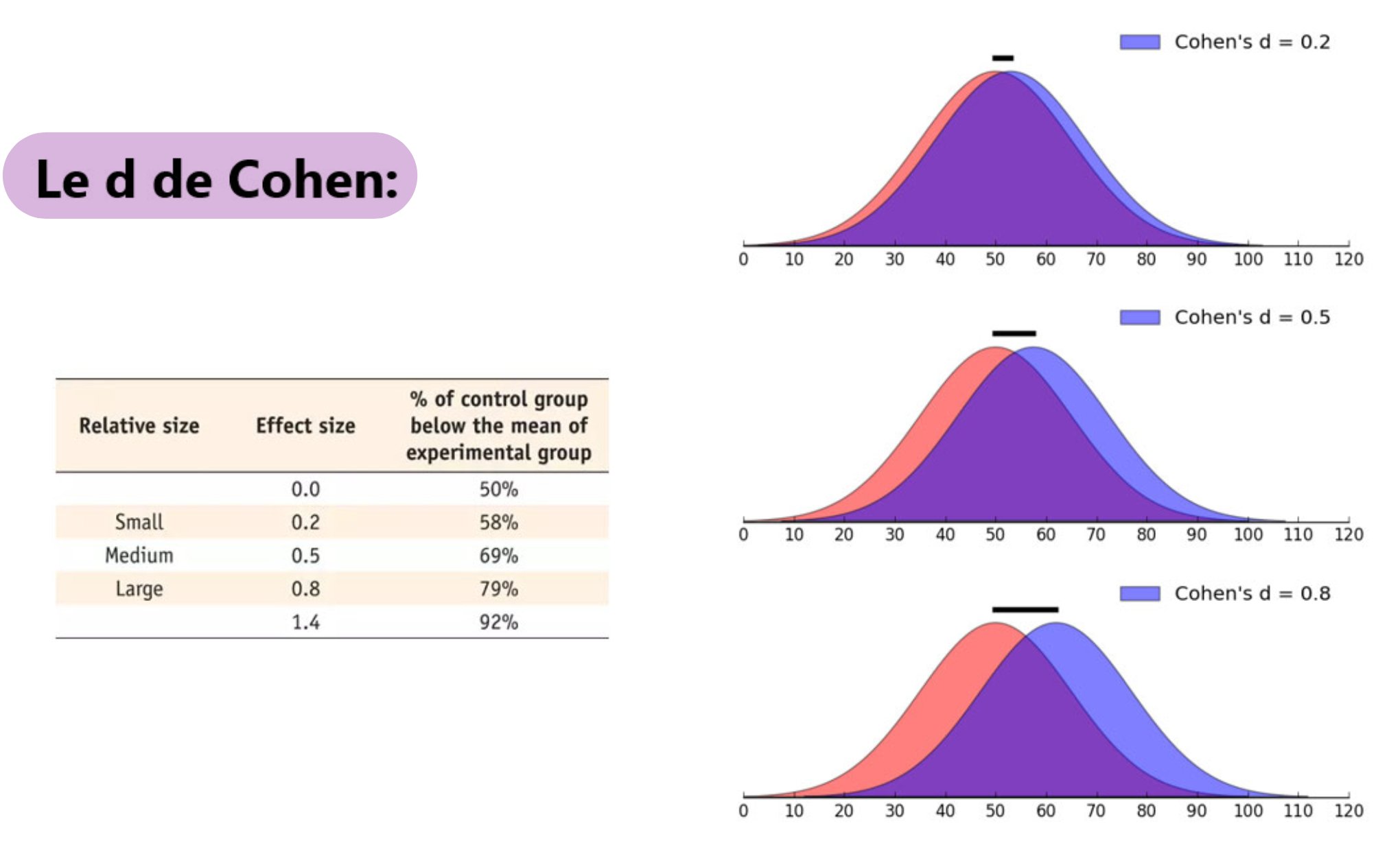
Précaution : partir du principe que l’effet est très petit
→ peut nous donner de très grands N (taille d’échantillon)
Observer les recherches antérieures
méta-analyses ? études avec concepts similaires ?
→ jamais ce que nous cherchons vraiment
Prendre la voie milieu (taille d’effet moyen)
Considérer la faisabilité et la signification pratique
Généralisation
→ Possibilité d'étendre les résultats d'un échantillon à la population cible, voire à d'autres populations similaires.
vision stricte
→ les résultats ne sont généralisables qu’à la population avec des caractéristiques identiques à l’échantillon
vision large
→ les effets observés ne sont pas spécifiques à l’échantillon étudié mais applicables à une plus large population
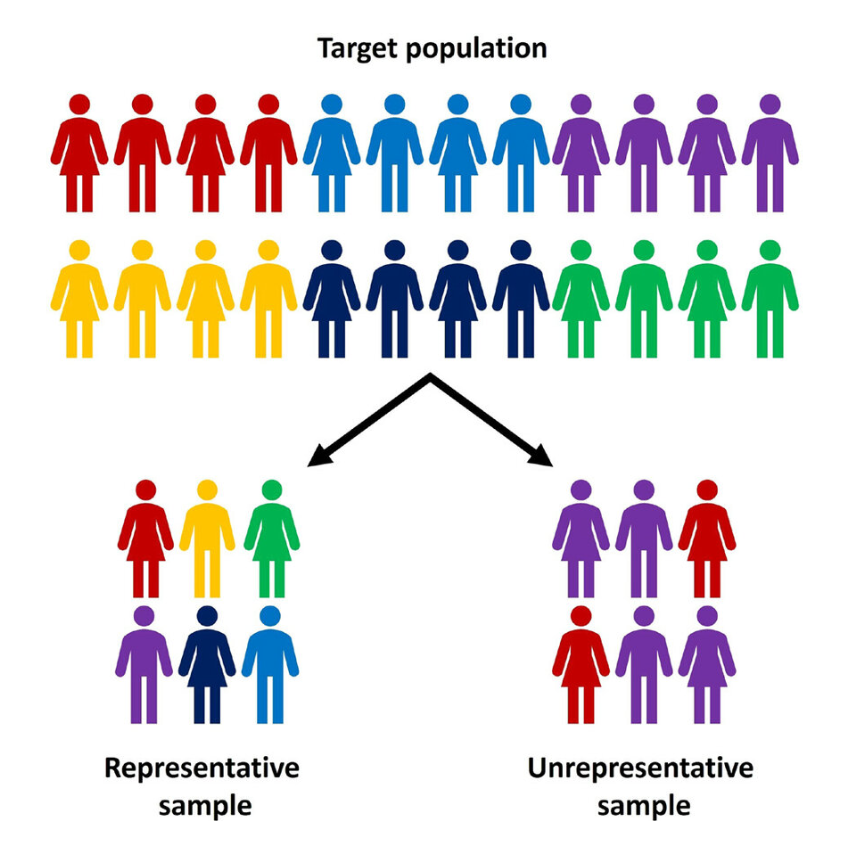
Représentativité
Degré auquel un échantillon reflète fidèlement les caractéristiques de la population d'intérêt
Un échantillon représentatif contient une distribution des variables clefs similaires à la population cible
âge
genre
niveau socio-économique
traits psychologiques
Les critères d’inclusion et d’exclusion
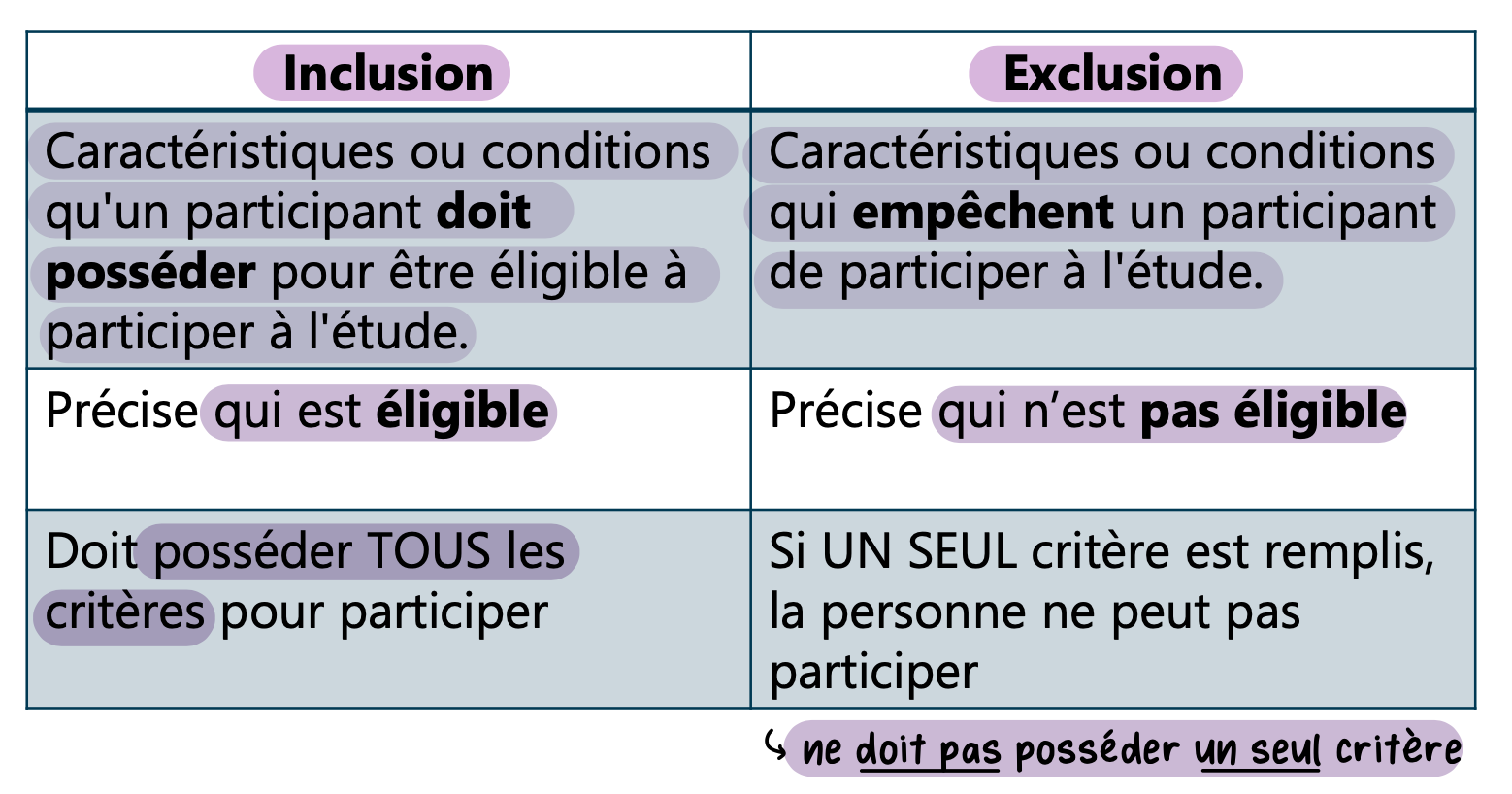
Ce sont les caractéristiques définissant qui peut ou ne peut pas participer à une étude.
Ils garantissent que l'échantillon est représentatif et que les résultats sont pertinents pour la population ciblée.
Critères d'inclusion
Caractéristiques ou conditions qu'un participant doit posséder pour être éligible à participer à l'étude
Précise qui est éligible
Doit posséder tous les critères pour participer
Critères d'exclusion
Caractéristiques ou conditions qui empêchent un participant de participer à l'étude
Précise qui n’est pas éligible
Si un seul critère est rempli, la personne ne peut pas participer à l’étude
Le participant ne doit pas posséder un seul critère
Techniques d’échantillonnage
méthodes probabilistes
aléatoire simple
aléatoire systématique
stratifié
en grappes (cluster)
méthode non-probabilistes
de commodité / convenance
accidentel
raisonné / intentionnel
en boule de neige
Echantillonnage Probabiliste
Chaque individu de la population a les mêmes chances dʼêtre sélectionnés
Echantillonnage Non-Probabiliste
Pas tous les individus de la population ont les mêmes chances dʼêtre sélectionnés
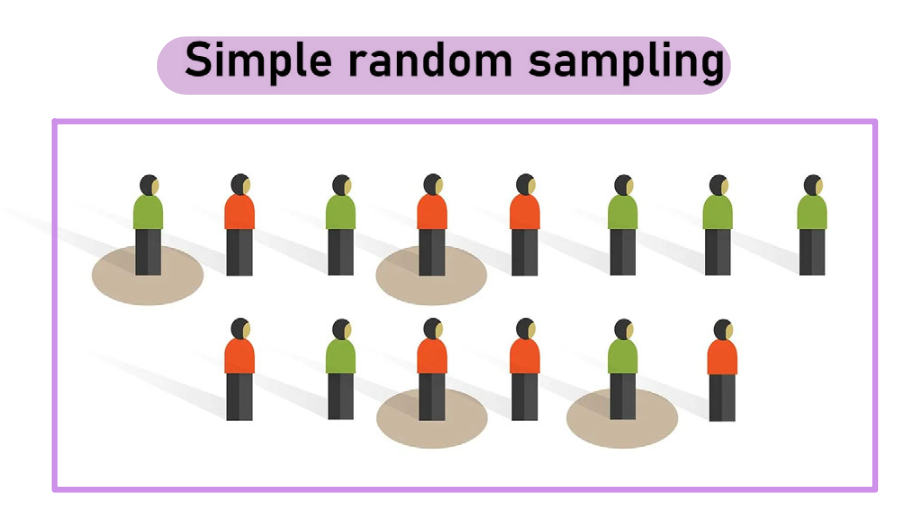
Echantillonnage aléatoire simple
Chaque individu de la population a une chance égale dʼêtre sélectionné via un tirage au sort ou un générateur de nombres aléatoires
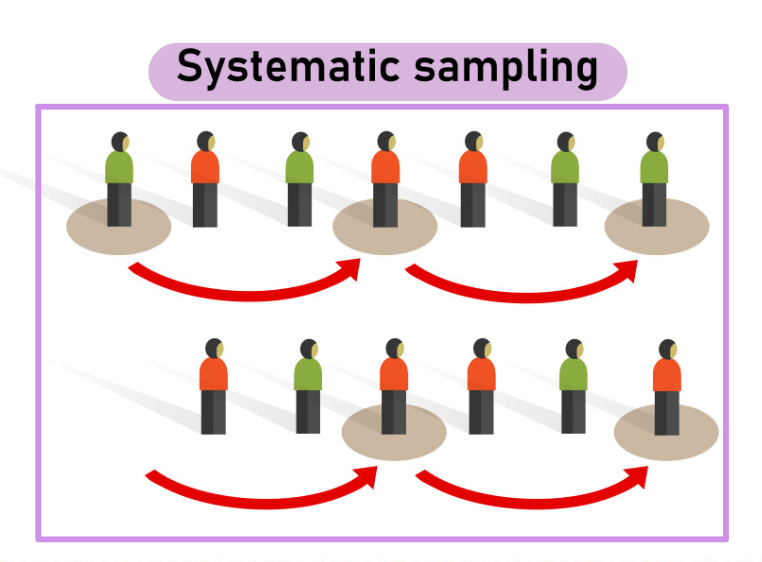
Echantillonnage aléatoire systématique
On sélectionne les participants à intervalles réguliers dans une liste ordonnée.
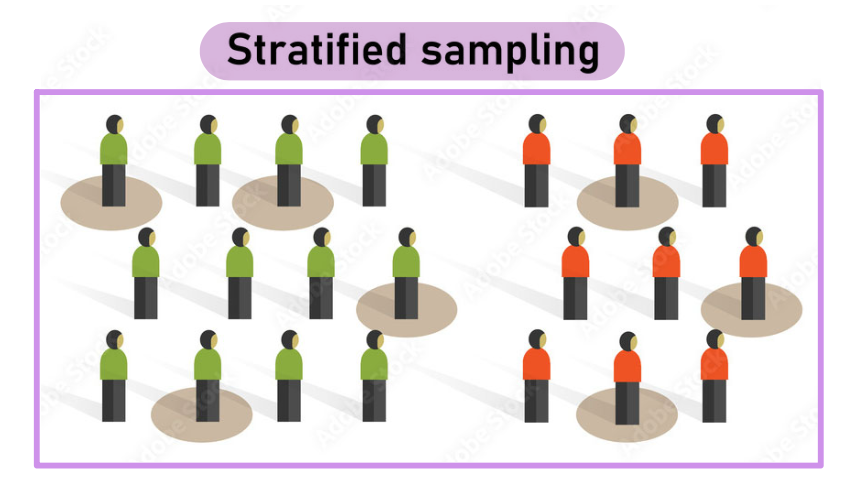
Echantillonnage stratifié
La population est divisée en sous-groupes homogènes (strates) selon une variable que lʼon considère comme importante (variable externe).
Puis un échantillon est tiré aléatoirement dans chaque strate de façon proportionnelle.
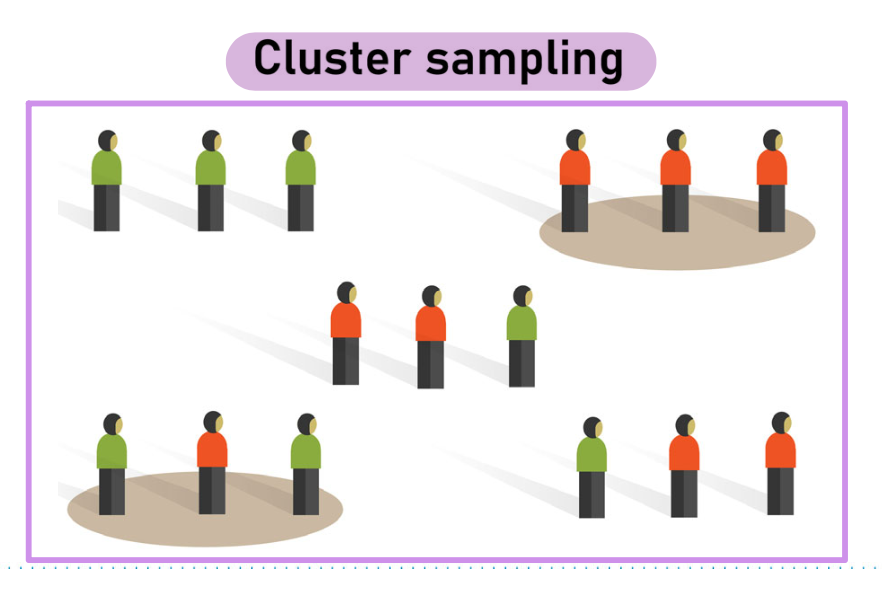
Echantillonnage en grappes (cluster)
Plutôt que de sélectionner des individus directement, on choisit des groupes entiers (grappes/cluster) de manière aléatoire, puis on teste tous les membres de ces groupes.
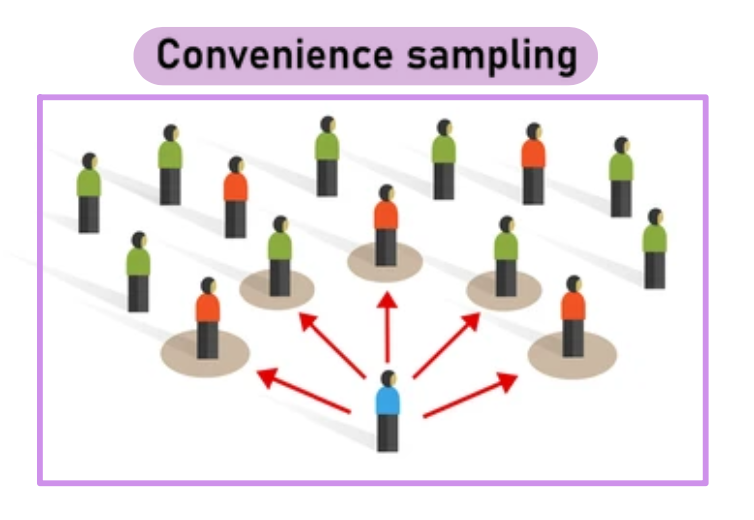
Echantillonnage de commodité / Convenance
On sélectionne les participants qui sont facilement accessibles, sans tirage aléatoire
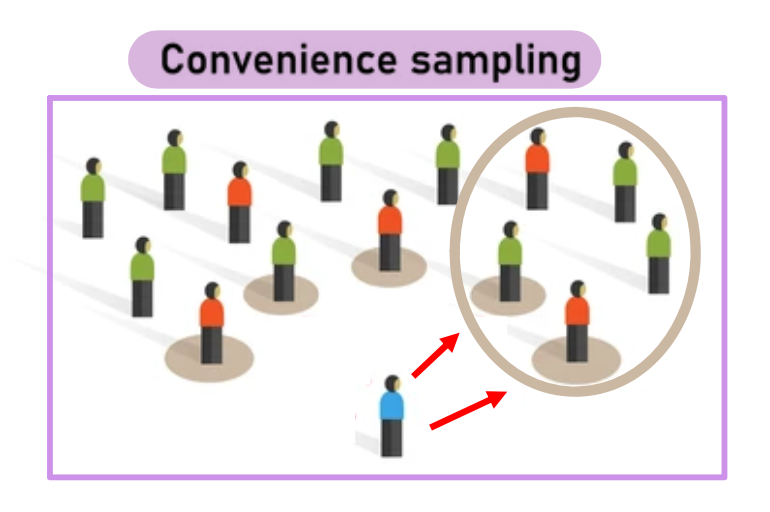
Echantillonnage accidentel
Les participants sont sélectionnés selon ceux qui se présentent spontanément, sans planification
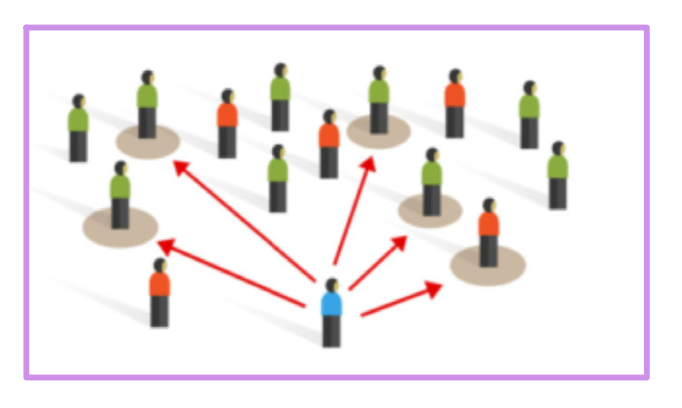
Echantillonnage raisonné / Intentionnel
Les participants sont sélectionnés selon des critères spécifiques liés aux objectifs de lʼétude.
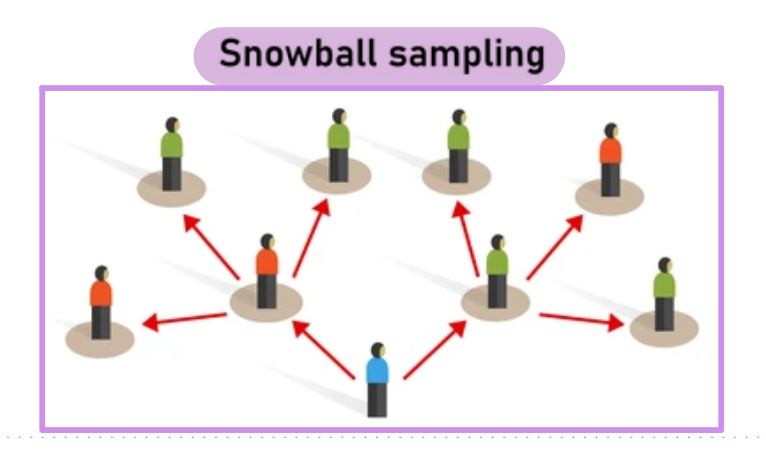
Echantillonnage en boule de neige
On commence par recruter un petit groupe de participants qui vont ensuite recommander dʼautres participants de leur réseau
Stratégies de recrutement
Par contact direct
Par publicité
Par réseau
Par plateforme de recrutement
Recrutement par contact direct
Les chercheurs contactent directement les participants (téléphone, lettre, e-mail, en personne).
Seule méthode pour les échantillonnages probabilistes: on ne contacte que ceux qui sont sorti sur la liste de notre échantillonnage (randomizé ou semi-randomizé)
La sélection se fait selon des critères précis, décidés en amont
Dans ce cas, lʼattrition (→ perte progressive de participants) est particulièrement problématique (enrôlement facile puis les gens y réfléchissent, peu de remplacement possible)
Recrutement par publicité
Affiches & Flyers : Placés dans des cafétéria, hôpitaux ou lieu de passage
Annonces en ligne : Publications sur des sites web, forums ou plateformes spécialisées
Biais de sélection 1: selon lʼendroit on touche une classe de participants seulement
Biais de sélection 2: ceux qui répondent ont des caractéristiques particulières
Recrutement par réseau
Le recrutement se fait via des contacts personnels ou professionnels
On peut encourager la diffusion à dʼautres réseaux
Echantillonnage « en boule de neige »
Recrutement via des collègues, conférences ou listes de diffusion.
Implication de plus en plus fréquentes des réseaux sociaux
Biais de sélection important
Recrutement par plateforme de recrutement
Plateformes de crowdsourcing permettant de recruter rapidement des participants en ligne
Services comme :
Amazon Mechanical Turk (Mturk)
Prolific
Qualtrics Panels
Les participants sont rémunéré (budget!)
Biais de sélection important
On accède à des « participants professionnels »
Biais potentiels dans les résultats
Attrition
La perte progressive de participants au cours dʼune étude, en particulier dans les recherches longitudinales
→ taux d’attrition = 1 - taux de rétention
Abandons (drop-outs)
Les cas de participants quittant volontairement lʼétude à un moment donné
Signification de l’attrition / l’abandon
Votre étude nʼest pas assez attractive (Trop longue? Trop difficile? Pas assez rémunérée?)
Votre étude a un problème intrinsèque (Trop stressante ou émotionnelle? Trop intrusive? Les participants se sentent rabaissé?)
Conséquences de lʼattrition / lʼabandon
Echantillonnage probabiliste → lʼéchantillon nʼest plus dû au hasard (les personnes qui arrêtent ou restent dans lʼétude partagent entre elles des caractéristiques communes)
Pertes de données utilisables