ECON Module 3: Lecture 13 - p-values, Type I and Type II Errors, and Intro to Multiple Regression
1/17
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No study sessions yet.
18 Terms
What is a p-value?
A p-value is associated with a statistical test and represents the lowest level of significance at which we are able to reject the H0 associated with that test.
What is 1-p?
The highest level of confidence at which we are able to reject the H0 associated with a statistical test.
What is a type I error?
A Type 1 error happens when you reject H0 (concluding βi≠0 ) when H0 is actually true. It is also the level of significance associated with a test. Therefore lower significance level means lower type 1 error rate therefore lower result false positives.
What is a type II error?
A Type 2 error happens when you do not reject H0 (concluding βi=0) when the predictor actually has a significant effect on the dependent variable (βi≠0) i.e. we fail to reject the truth.
What is Xij in the multiple regression equation?
The ith observation for jith independent variable in the model.
What is Bj?
The marginal effect of Xij on the expected value of Yi.
What is the mathematical expression for Bj in multiple regression analysis?
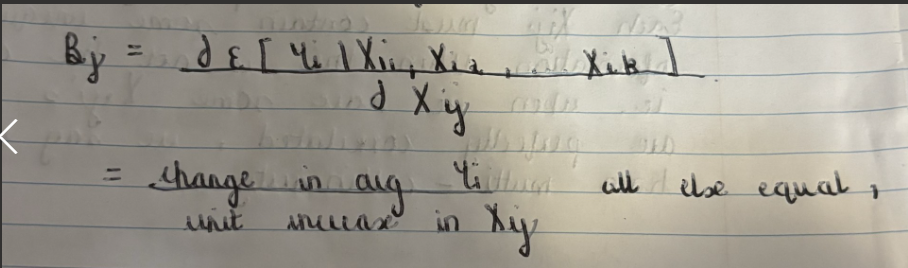
What is the mathematical expression for forecasting in multiple regression?
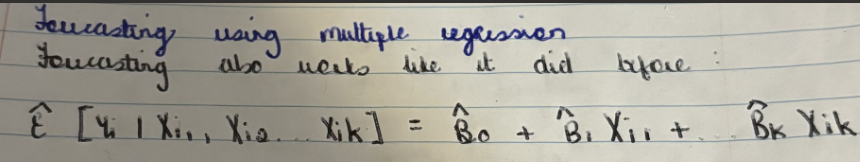
What do we mean by we want E(^Bj) = Bj, for j = 0,1,2…k?
We want the estimates to be unbiased and efficient.
What are the 9 assumptions for unbiased and efficient estimates in multiple regression analysis?
1. Linearity 2. No auto-correlation 3. No heteroskedasticity 4. No endogeneity 5. Zero mean error 6. Normally-distributed errors 7. Sufficient Degrees of Freedom 8. No regressors are perfectly correlated
What is linearity? What are the consequences if not true?
E | yi | xi | = B0 + B1 Xi is not mis-specified
If not true: biased estimates
What is meant by no autocorrelation? What are the consequences if not true?
no pattern or trend in the model residuals. Corr (Ui, Ui) = 0
If not true: biased estimates
What is meant by no heteroskedasticity? What are the consequences if not true?
The variance of model error is constant throughout the sample. i.e. model makes roughly same magnitude of errors everywhere. NOTE heteroskedasticity may be a feature of the data as opposed to a "bug" of the model.
What is meant by no endogeneity? What are the consequences if not true?
No correlation between Ui and Xi i.e. corr(Ui, Xi) = 0.
If not true: biased estimates
What is meant by zero mean error? What are the consequences if not true?
E (Ui) = 0
If not true: biased ^B0 but not biased ^B1
What is meant by normally distributed errors? What are the consequences if not true?
Ui follows normal distribution
If not true: Generally unsignificant unless we have unusual outliers
What is meant by sufficient degrees of freedom? What are the consequences if not true?
We must have more unique observations than number of betas in the model.
If not true: OLS is not feasible formulas breakdown and produce no solution.
What do we mean by no regressors are perfectly correlated?
Each Xij must contain some unique information when this is not the case we have multi-colinearity.