Lecture 17 - Dopamine + Reinforcement Learning I
1/34
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
35 Terms
Recap: What fall under representation, valuation, action selection, outcome evaluation?
representation: sensory representations, uncertainty estimation, Bayesian integration
valuation: value representations in PFC, availability/desirability
action selection: action selection in striatum
outcome evaluation: confidence/metacognition
Recap: What are the 3 types of learning?
supervised: learning from labelled data - accuracy is the feedback
unsupervised: learning structure in the data - distance/structure metric is the feedback
reinforcement: learning from trial and error - sparse reward or punishment as feedback
idea of action in reinforcement
What is the learning signal in supervised learning? Describe process in supervised learning. Is it useful conceptually or for biological systems?
you have one data point and one label
you get an error (target - prediction)
error gets back propagated into network
use error to figure out how to change network to give you correct network
the learning signal for a given neuron is dependent on other downstream neurons in the network
NOT USEFUL FOR BIOLOGICAL SYSTEMS SINCE YOU NEED TO KNOW ALL OTHER NEURONS DOWNSTREAM TO UPDATE A WEIGHT OF A NEURON
useful conceptually
What is the agent and environment in reinforcement learning?
the agent has to take a number of actions and obtains sparse rewards
the agent has to learn the value of states and action that lead to the reward
agent → actions → environment
environment → rewards/observations → agent
What is intracranial self stimulation? What experiment with rats?
stimulation of the medial forebrain bundle (MFB)
when the rats press on the lever, they receive an electrical stimulation
they were not food or water deprived
the rat self-stimulates → they will press the lever repeatedly it is paired with a stimulation
they work for this stimulation reward
What neurons were targeted in the self-stimulation experiment?
the dopaminergic system
ventral tegental area
substantia nigra
axons are activated and release of dopamine
What diseases is dopamine implicated in? What is a treatment option?
Parkinson’s disease arises from degeneration in dopamine neurons (substantial nigra)
motor disorder
treatments include L-Dopa which is a metabolic precursor of dopamine
forcing dopamine neuron activation can lead to recovery in dopaminergic system
How do psychopathic drugs operate with dopamine?
many addictive drugs act by increasing dopamine levels through different mechanisms
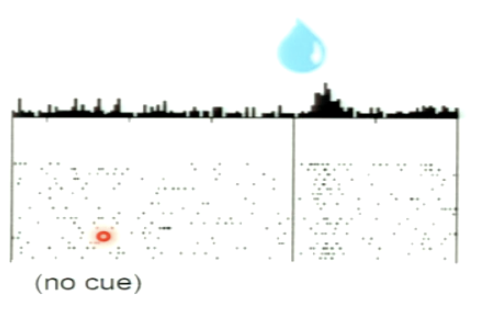
Describe experiment (part 1). What type of neuron is being recorded?
dopamine neuron from ventral tegmental area
response of the neuron to an unpredicted liquid reward
strong response after reward delivery
THERE IS REWARD CODING IN THESE NEURONS
What type of learning is it where we give a cue (CS) paired with a reward (US)?
classical conditioning
Pavlovian
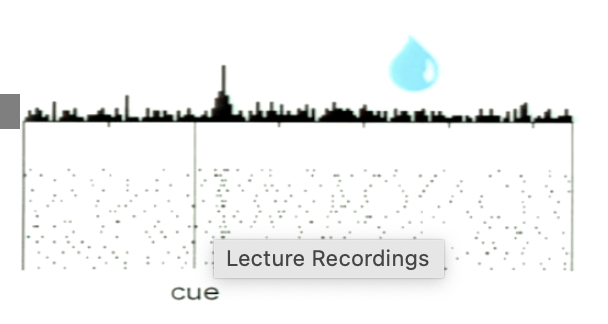
What is shown from the experiment? When does the neuron fire?
after association, neuron responds to cue that predicts the reward
increase in firing after cue
no response at the time of the reward delivery
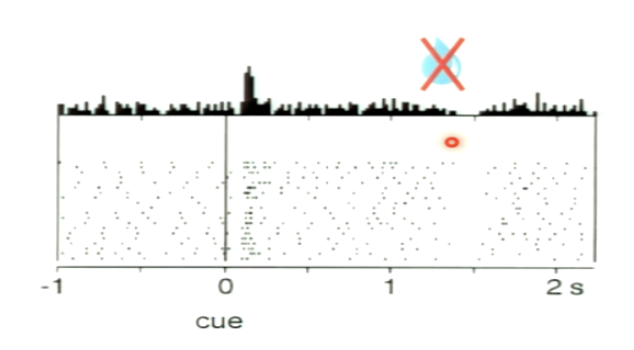
What occurs in this trial?
increase in response after cue
decrease in firing at the time of the reward when the reward isn’t given when it is expected
if the reward is omitted there is a dip in the dopamine activity at the time the reward should have been delivered
What is the Reward Prediction Error (RPE)?
actual value/reward - expected value/reward
comparison between what you expect and what you get
NOT AN ABSOLUTE VALUE SIGNAL
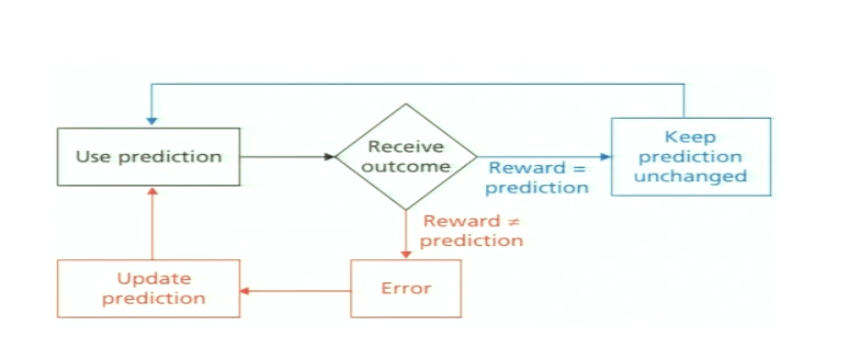
What is the model we use for updating reward prediction error?
use prediction → receive outcome —reward = prediction→ keep prediction unchanged
OR
use prediction → receive outcome —reward not = prediction→ error → update prediction
You are expecting a $5 reward. You receive instead a $2 reward. How would you expect one of your dopamine neurons to respond?
decrease in activity as you receive a worse reward than expected reward
positive value reward but negative prediction error
RPE: 2 - 5 = -3
You are expecting a $5 loss. You instead loose $2. How would you expect one of your dopamine neurons to respond?
RPE: -2 - -5 = 3
increase in activity as you receive a smaller loss
NOT IMPORTANT! How do you optimize your actions to get to goal? What 3 estimations are required?
learning signal
what is the feedback signal we should use
need to learn while propagating value across space
Value of each state
what is the definition of value for each state
choose action that maximizes future value
which action should we choose
How do we determine the value of each state?
state is usually location in space/time but can be defined in a more abstract space
we have a value estimation (value function)
the policy is given the value of the state, which action should we take
What is the TD error? What is it similar to?
TD error measures the difference between what an agent expected to happen and what actually happened at the next time step
used to update the value estimate so that future predictions become more accurate
the reward prediction error in dopamine neurons is similar to the Temporal Difference (TD) error in reinforcement learning algorithms
What is the ‘critic’ (value function)?
the critic uses state and reward information to compute the TD error
the TD error is used to update the value of the states
What is value of a state?
*value is a state is the sum of the value that can be reached from this state discounted by how far they are into the future
e.g. get reward now → full value
get reward in future → lower value amount
further in future = lower value (like graph)
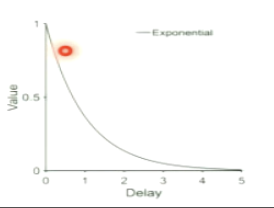
Why should we discount the value of future states?
uncertainty
you not sure that you’re getting reward
model of world in future is not predictable
What is the TD error formula?
TD error = Actual value (reward + expected future value) - expected value
reward (rt) + expected future value (yV(st+1)
y = discounting into the future
compare to current expected value of the state
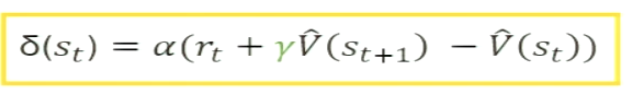
What is the policy (actor)?
actor: choose action that maximizes future values
What are different policies given the same value function?
greedy policy: always pick the most valuable future state
explore: sometimes pick another state to ensure high value states don’t exist elsewhere
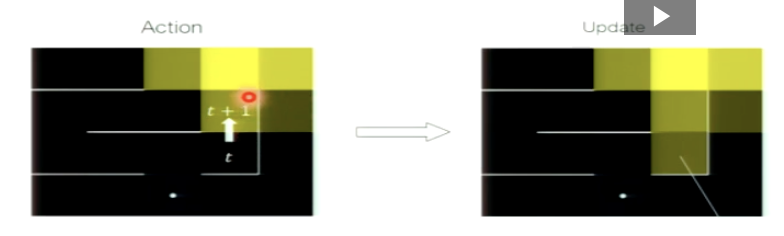
Explain this action and update.
the TD error is used as the learning signal
previous value is updated given the learning rate (alpha) and the prediction error
it is a local update that can be done before receiving the final outcome
you only need to know value of next state NOT the final state
you start on t
you want to move towards action where you have reward
you move to t + 1 where you’re going to have reward in future
use TD error to get updated value function
t + 1 has more reward than t (t has 0 reward)
t has a value now since it leads to a value state
CREATES A PATH TO A REWARD
What is TD learning? What is bootstrapping? Is this compatible with biological systems?
TD learning = learning a guess from a guess
bootstrapping = update the estimate based on the estimated value of other states
TD errors are computed at each timestep (moment by moment)
MORE REALISTIC FOR BIOLOGICAL MODELS
What is TD error equation and what does it mean?
δt — temporal-difference prediction error
Reflected in dopamine firing
Positive = better than expected
Zero = as expected
Negative = worse than expected
rt — reward received at time t
Actual outcome
V^(st) — predicted future value of the current state
What the brain expects before seeing the outcome
y — discount factor
How much the agent values future rewards
V^(st+1) — predicted future value of the next state
How valuable the next moment is expected to be
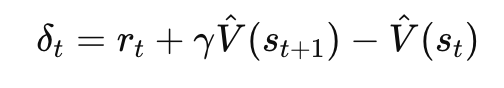
What happens at the CS (before learning)? What happens at reward (before learning)?
δ(CS) = yV^(st+1) = 0
CS does not predict reward
predicted value = 0
no dopamine response
δ(R) = rt−V^(st) = rt−0 = rt
reward is unexpected
predicted value is 0
large dopamine burst at reward
What happens at the CS (after learning)? What happens at the Reward (after learning)?
δ(CS)=γV^(st+1) − V^(st) ≈ positive jump
CS now predicts the reward
large dopamine burst at CS
δ(R) = rt − V^(st) ≈ rt−rt = 0
Reward is fully expected
No dopamine burst at reward
What happens at the CS (after learning)? What happens at the Reward (after learning)? NO REWARD THIS TIME
δ(CS)=γV^(st+1) − V^(st) ≈ positive jump
CS now predicts the reward
large dopamine burst at CS
δ(R) = 0−V^(st) = −V^(st)
The animal expects a reward because of the CS
But reward does not come
Dip in dopamine firing (below baseline)
How do dopamine neurons respond to rewards of different sizes?
graded response
more water = greater RPE
smaller amount of water = negative RPE
Why is there a negative prediction error to small rewards?
smaller reward than expected
compared to average size of reward, you’re getting something smaller
Is prediction error an absolute value?
no! it is not an absolute measure of reward vs. punishment
depends on expected value
relative to the expectation
can change with baseline
Recap of reinforcement learning to optimize rewards:
assign value to states in the world
assigning value is the value and the discounted future values
using learning signal to compare reward and expected future value of future place to expected value/current value of place
increase or decrease values of spaces