2 Computer Vision: 3 Fundamentals of Optical Character Recognition
1/4
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No study sessions yet.
5 Terms
[intro to OCR]
Suppose you have image files of road signs, advertisements, or writing on a chalk board.
Machines can read the text in the images using (OCR), the capability for (AI) to process words in images into machine-readable text.
In this module, we'll focus on the use of OCR technologies to detect text in images and convert it into a text-based data format,
which can then be stored, printed, or used as the input for further processing or analysis
Automating text processing can improve the speed and efficiency of work by removing the need for manual data entry.
The ability to recognize printed and handwritten text in images is
note taking,
digitizing medical records or historical documents,
scanning checks for bank deposits, and more
Optical character recognition (OCR) has been around for a long time. The ability to do the same extraction from images is where the Read API can help. The Read API provides the ability to extract large amounts of typewritten or handwritten text from images
[Get started with Azure AI Vision]
The ability for computer systems to process written and printed text is an area of AI where computer vision intersects with natural language processing.
Vision capabilities are needed to "read" the text, and then NLP capabilities make sense of it.
OCR is the foundation of processing text in images and uses machine learning models that are trained to recognize individual shapes as letters, numerals, punctuation, or other elements of text.
Much of the early work on implementing this kind of capability was performed by postal services to support automatic sorting of mail based on postal codes. Since then, the state-of-the-art for reading text has moved on, and we have models that detect printed or handwritten text in an image and read it line-by-line and word-by-word.
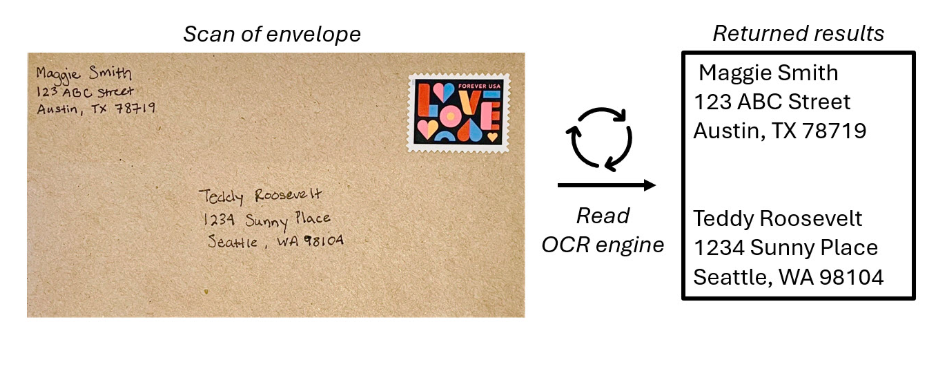
Azure AI Vision’s OCR Engine
[Get started with Azure AI Vision]
Azure AI Vision service has the ability to extract machine-readable text from images.
Azure AI Vision's Read API is the OCR engine that powers text extraction from images, PDFs, and TIFF files.
OCR for images is optimized for general, non-document images that makes it easier to embed OCR in your user experience scenarios.
The Read API, otherwise known as Read OCR engine, uses the latest recognition models and is optimized for images that have a significant amount of text or have considerable visual noise.
It can automatically determine the proper recognition model to use taking into consideration the number of lines of text, images that include text, and handwriting.
The OCR engine takes in an image file and identifies bounding boxes, or coordinates, where items are located within an image.
In OCR, the model identifies bounding boxes around anything that appears to be text in the image.
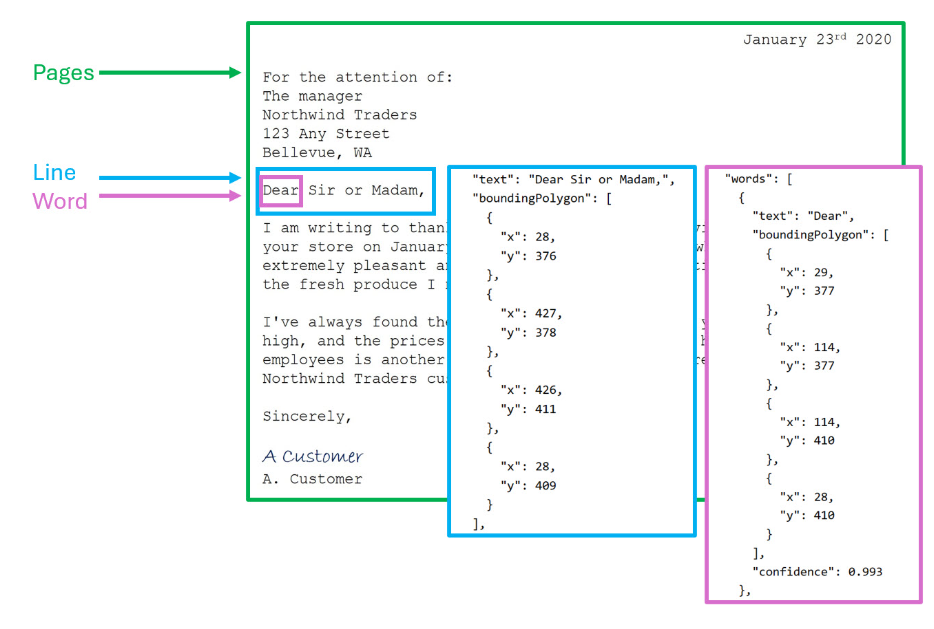
Calling the Read API returns results arranged into the following hierarchy:
Pages - One for each page of text, including information about the page size and orientation.
Lines - The lines of text on a page.
Words - The words in a line of text, including the bounding box coordinates and text itself.
Each line and word includes bounding box coordinates indicating its position on the page
[Get started with Vision Studio on Azure]
Once you've created a resource, there are several ways to use Azure AI Vision's Read API:
Azure AI Foundry
Vision Studio
REST API
Software Development Kits (SDKs): Python, C#, JavaScript
Azure Vision Studio
[Get started with Vision Studio on Azure]
Azure AI Vision Studio gives you access to Azure AI Vision APIs through a GUI that does not require coding to get started.
When you open Vision Studio, you need to select your default resource.
Your default resource in Vision Studio must be an Azure AI services resource, rather than Azure AI Vision resource
From the Vision Studio home page, you can select Optical Character Recognition and the Extract text from images tile to try out the Read OCR engine.
Your resource begins to incur usage costs when it is used to return results.
Using one of your own files or a sample file, you can see how the Read OCR engine returns detected attributes. These attributes correspond with what the machine detects in the bounding boxes.
Behind the scenes, the image is analyzed for features including people, text, and objects, and marked by bounding boxes.
The detected information is processed and the results are returned to the user.
The raw results are returned in JSON and include information about the bounding box locations on the page, and the detected text.
Keep in mind that Vision Studio can return examples of OCR, but to build your own OCR application, you need to work with an SDK or REST API