Cognitive Psychology Exam 2
1/45
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
46 Terms
Explain why object recognition is a challenging information processing task. Refer to the “THE” versus “CAT” example and the three different views of the cats example in your explanation.
THE/CAT: You are likely to easily read this sequence as “THE CAT” recognizing the middle symbol as an H in one case and as an A in the other.
The same features (input) are recognized as different objects (representation)
Different views: We recognize cats from the side or the front, whether we see them close up or far away
Different features (input) are recognized as the same object (representation)
The ventral processing stream starts at V1 and projects to which part of the brain? What kind of information processing does the ventral stream do?
The ventral processing stream starts at the primary visual cortex (V1) and projects to the inferior temporal cortex (IT cortex) and other areas of the temporal lobe.
What Pathway: Responsible for object recognition and identifying features like shape, color, and texture, allowing us to understand what we are seeing.
The dorsal processing stream starts at V1 and projects to which part of the brain? What kind of information processing does the dorsal stream do?
The dorsal processing stream starts at the primary visual cortex (V1) and projects to the posterior parietal cortex.
Where/How Pathway: Processes information related to where objects are located in space and how to interact with them, including spatial localization, motion detection, and the guidance of actions like reaching and grasping.
What is agnosia in general?
A rare neurological condition that makes it difficult or impossible to recognize and identify familiar objects, people, sounds, or other stimuli, despite normal sensory function
Apperceptive (integrative agnosia)
Patients get features of objects, but can’t put them together properly in a recognizable representation
Objects are represented as combinations of basic features
E.g., the patient just sees jumbles features – no organized object representations...so cannot submit to recognition processes
Associative agnosia
Patients represent well-formed objects, but cannot connect those representations with their meaning (semantics)
Recognition requires associating perceptual representations with stored representations
Malfunctioning part-based processes (commonly associated with damage to LOC)
E.g., the patient sees organized objects, and even sometimes knows what the object is for (function), but can’t associate it with a name
Prosopagnosia
An example of category-specific loss, an inability to recognize faces even though other objects can be recognized
Recognition consists of multiple separable systems, which may function differently
Malfunctioning holistic processes (commonly associated with damage to FFA)
E.g., the patient (Boo James) cannot recognize faces, in particular (“face blindness”)
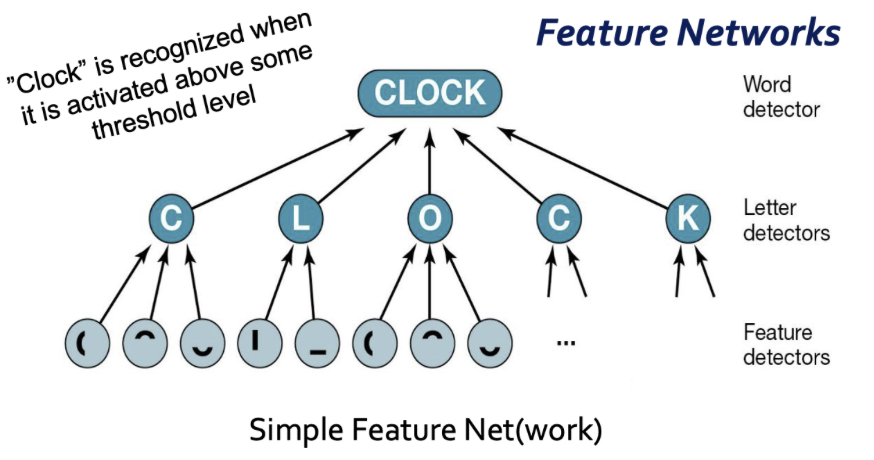
How are words represented in a simple feature network?
Figure 4.7 A Simple Feature Net
Here, the feature detectors respond to simple elements in the visual input. When the appropriate feature detectors are activated, they trigger a response in the letter detectors. When these are activated, in turn, they can trigger a response in a higher-level detector, such as a detector for an entire word.
Feature nets: As we move upward in the network, each subsequent layer is concerned with larger-scale objects; the flow of information would be bottom-up from the lower levels toward the upper levels
Activation level: Reflects the status of the detector at that moment—roughly how energized the detector is. A strong input will increase the activation level by a lot, and so will a series of weaker inputs
Response threshold: The quantity of information or activation needed to trigger a response in a node or detector
This simple feature network does not predict the effect of well-formedness
A solution: Bigram detectors reflect the rules of the language – no TJ bigram detector in an English speaker's brain, but would be in a German or Swedish speaker’s brain
Explain how frequency and priming effects occur within a simple feature network?
Frequency: The frequency effect states that common words are recognized more quickly than rare words
a. Frequent words: Words you encounter often, like "THE," have very high baseline activation for their word-level detectors. Because these detectors are already "revved up," they need less stimulation from the letter-level detectors to fire. This leads to quicker recognition.
b. Infrequent words: Words you rarely see, like "SARDONIC," have lower baseline activation for their word-level detectors. They require more activation from the letter detectors to reach their threshold and be recognized.
Repetition priming: When seeing a stimulus once helps you recognize it more quickly the next time.
a. First exposure: When you see a word like "HOUSE," the feature, letter, and word detectors for that word are all activated.
b. After the first exposure: Activation fades, the detectors do not return to their initial, neutral state. Instead, they retain a slightly elevated level of baseline activation.
c. Second exposure: If you see "HOUSE" again shortly after, the detectors for that word are already partially activated. This means they will fire more quickly, resulting in faster recognition.
Factors influencing recognition
Recency of view: If participants view a word and then, soon after, view it again, they’ll recognize the word more readily the second time around
Priming: A process through which one input or cue prepares a person for an upcoming input or cue
Repetition priming: A pattern of priming that occurs simply because a stimulus is presented a second time; processing is more efficient on the second presentation
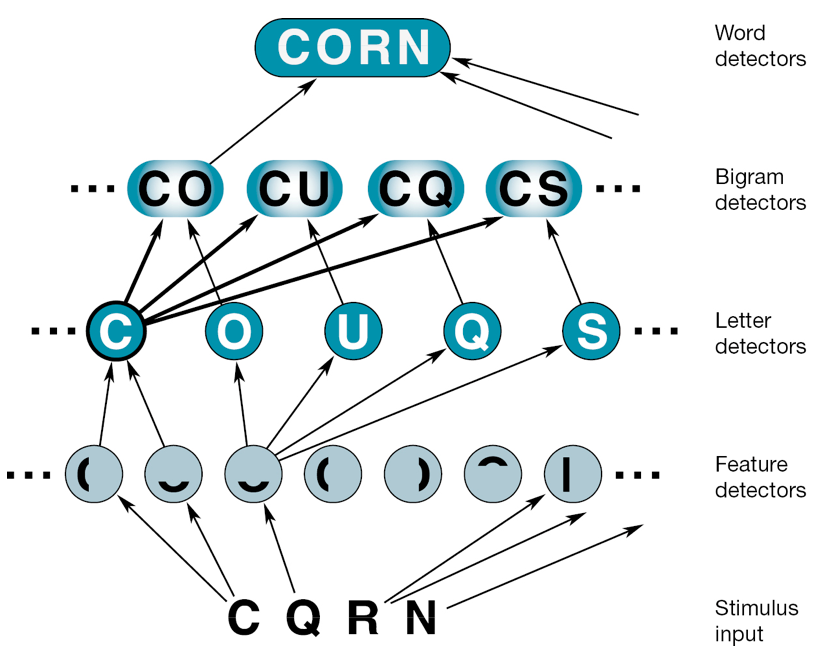
Explain how adding a bigram layer helps with recognition when the input is poor (Fig 4.8) but can also cause recognition errors (Fig 4.9).
The bigram CO is activated by the C. It does not need the O to activate the CORN.
Imagine that we present the string “CQRN” to the participants. If the presentation is brief enough, the participants might see only a subset of the string’s features. Let’s imagine that they register only the bottom curve of the string’s second letter. This detection of this curve will weakly activate the Q-detector but also the S-detector, the U-detector, and the O-detector
Figure 4.9 Recognition Errors
However, this weak signal is enough to trigger the well-primed CO-detector, and so the input will be (mistakenly) recognized as “CORN”
Well-formed nonwords are more readily perceived than letter strings that do not conform to the rules of normal spelling
Explain how adding inhibitory connections and two-way connections (i.e., feedback) increases the range of phenomena that the model can explain.
Bottom-up processing: A sequence of events that is directly shaped by the stimulus input itself – “data driven”
Bottom-up input: When you see the word "THE," the visual features of the middle letter stimulate both the letter detectors for "H" and "A".
Top-down processing: A sequence of events that is heavily shaped by the knowledge and expectations that the person brings to the situation – “concept driven”
Top-down influence: At the word level, the activation of "THE" sends a feedback signal down to the letter level, strongly activating the "H" detector. At the same time, the "A" detector receives a conflicting feedback signal from the word "TAE," which is less familiar and therefore has less activation. The stronger, more familiar "THE" signal wins out, allowing you to perceive "H".
Word-superiority effect (WSE)
The data pattern in which research participants are more accurate and more efficient in recognizing letters if the letters appear within a word (or word-like letter string) than they are in recognizing letters appearing in isolation
Well-formedness is a good predictor of word recognition: The more English-like the string is, the easier it will be to recognize
What is the problem of invariance with regard to object recognition? Use a basic template theory of object recognition to explain your answer.
Object invariance: The ability to recognize objects regardless of point of view
a. Any successful theory of object recognition must explain how object invariance is achieved
b. The problem of object invariance can be appreciated by what is wrong with template models of object recognition
Basic template theory: The brain recognizes an object by comparing it to a vast library of stored templates, or whole images, of known objects
a. We would need many ... many (technically, infinite) templates – Different orientations, different sizes, different version (think: font), different points of view
b. (Simple) template theories do not solve invariance
Recognition by components (RBC) model
Includes several important innovations, one which is the inclusion of an intermediate level of detectors, sensitive to geons (geometric ions)
a. Lowest-level detectors are feature detectors, which respond to edges, curves, angles, and so on
b. Higher levels of detectors are then sensitive to combinations of geons – geons are assembled into complex arrangements called “geon assemblies” which explicitly represent the relations between geons
c. These assemblies activate the object model, a representation of the complete recognized object
Geons: Simple shapes, such as cylinders, cones, and blocks
Recognition by Multiple Views (RMV)
Objects are recognized by matching the input image to a set of stored 2D views
a. Proposes that we recognize objects by storing multiple 2D representations of the object from different viewpoints
b. When you encounter an object, your visual system matches the input image to one of the stored views in memory
c. Invariance handling: The system stores a large number of views of an object, requiring significant memory
Part-based processing
Involves analyzing and recognizing objects by breaking them down into their individual components or features
Holistic processing
The ability to perceive and integrate the component features of an object into a single, unified whole
The whole is greater than the sum of the parts
The inversion effect (Thatcher effect)
Evidence that faces are processed differently
Face recognition is impaired more by inversion than non-face object recognition is impaired
Upside down faces engage the part-based system, rather than the holistic system
An inverted face is not treated by the visual system as a “face” ... so “regular” part-based processes dominate ... each part is essentially fine here
Right-side up faces engage the wholistic system, rather than the part-based system
A right-side up face is processed as a face recognition system (holistic) ... so holistic processing dominates ... the relations between parts are incongruous
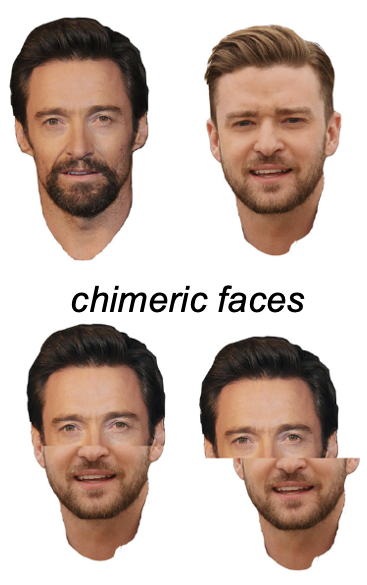
What is the Inversion Effect? Describe an experiment (logic, results, and conclusion) using the inversion effect that supports the hypothesis that recognizing faces is different from other kinds of object recognition because it relies more on holistic processing.
Task: Identify the top half of “chimeric” faces/objects
Results: Much worse when the two halves are aligned than when misaligned (difficult to isolate facial recognition system to just the top half when aligned)
Control: But not when they are inverted
Conclusion: The system processes right-side up faces holistically, which is especially bad for aligned chimeric faces. The misalignment helps break the dominance of holistic processing (perceptual organization)
Upside down faces are not processed holistically and so the misalignment is not needed to break the dominance of holistic processing
What are the key characteristics of attention that are captured in William James’ quote that starts out “Everyone knows what attention is…”?
Selectivity: The mind chooses one object or idea to focus on from a multitude of potential
Focalization and concentration: Attention is a deliberate act of focusing the mind and concentrating consciousness on a specific chosen object or thought
Clarity and vividness: The object of attention becomes more distinct, clear, and vivid in the mind’s eye
Possession: The mind actively takes possession of its chosen object, indicating a sense of ownership or control over the selected focus
Exclusion of alternatives: By taking possession of one object, attention inherently involves withdrawing from or pushing aside other simultaneously possible options
If human information processing were not limited capacity, then attention would be unnecessary. Explain why this is true.
Limited capacity: The brain has a finite amount of mental resources to handle information, forcing it to make choices about which stimuli to focus on and which to ignore to avoid being overwhelmed
If the brain's information processing capacity were unlimited, then:
No Need for Filtering: There would be no bottleneck or overflow of information, so the brain wouldn't need to filter out irrelevant stimuli.
Simultaneous Processing: All sensory input and internal thoughts could be processed concurrently without any cognitive strain.
No Competition for Resources: There would be no competition for limited resources because there would be an infinite supply, making selective attention unnecessary.
Constant Awareness: Humans could theoretically maintain a complete and comprehensive awareness of all information in their environment without having to choose what to focus on.
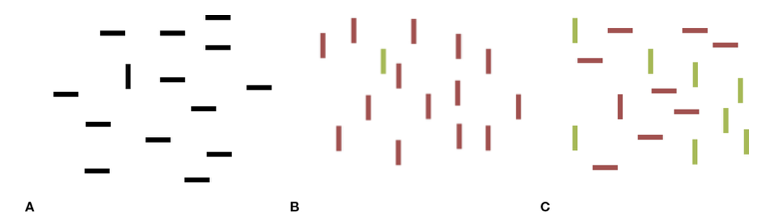
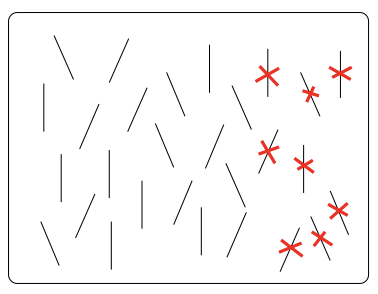
Visual search tasks
Tasks in which participants are asked to examine a display and judge whether a particular target is present or not
E.g., Finding a vertical segment in a field of horizontals or a green shape in a field of red shapes
In panel A, you can immediately spot the vertical, distinguished from the other shapes by just one feature. Likewise, in Panel B, you can immediately spot the lone green bar in the field of reds. But in Panel C, it takes longer to find the one red vertical, because now you need to search for a combination (conjunction) of features—not just for red or vertical, but for the one form that has both of these attributes.
Change blindness
The failure to notice (sometimes large) changes if you happen to not be attending to whatever changes as it changes
E.g., Not noticing your mother got a new haircut
Key Factor: You fail to notice a difference between what was there before and what is there now, because your focus isn’t on registering or remembering details
Inattentional blindness
The failure to notice things in your environment that you aren’t expecting and therefore are not attending, even though they are easy to notice when attended
E.g., Invisible gorilla experiment — most participants counting basketball passes fail to notice a person in a gorilla suit walking through the scene
Key Factor: You fail to detect a stimulus that is already present because your attention is focused elsewhere
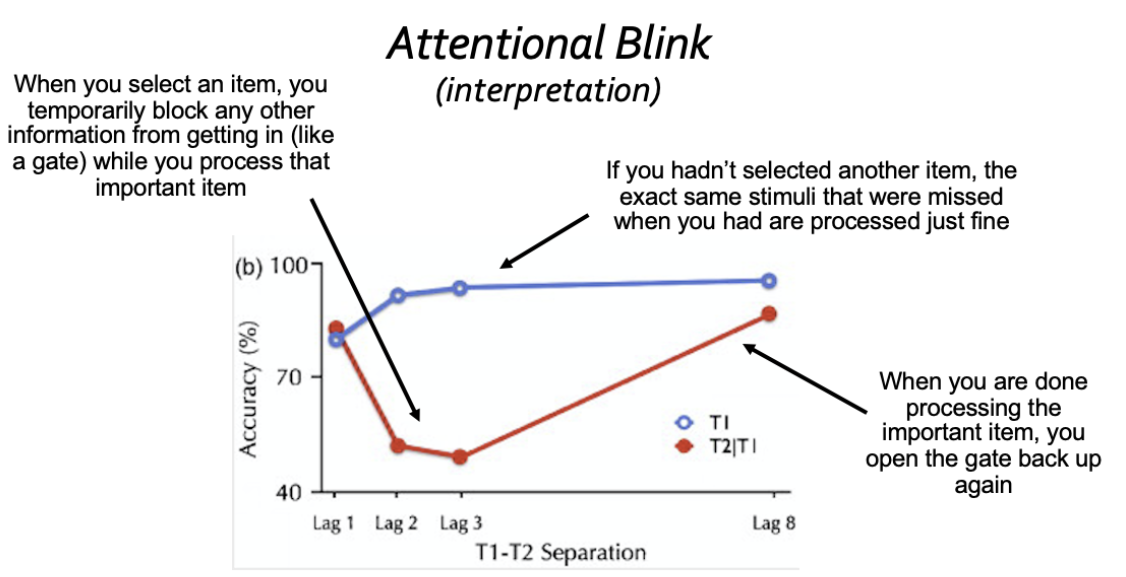
What is the attentional blink? Describe how it is measured experimentally. Be sure to include a description of the control task and why it is important.
Attentional blink: A period of time following the engagement of attention during which we fail to register new information
Fixation target: A visual mark (e.g., a dot or a plus sign) at which research participants point their eyes, or fixate
Task: A stream of visual stimuli (e.g., black letters and numbers) is flashed rapidly, one after another, at a single location on a screen. The presentation rate is typically fast, around 10 items per second.
Targets (T1 and T2): Two items in the stream are designated as targets, often by a unique feature such as a different color (e.g., a white letter in a stream of black letters). The first target (T1) and second target (T2) appear at varying temporal delays (lags).
Reporting: At the end of the stream, the participant is asked to report both T1 and T2. The experiment records the accuracy of these reports.
Performance pattern: An attentional blink is observed when participants correctly identify T1 but fail to report T2, specifically when the interval between the two targets is short, typically between 200 and 500 milliseconds.
Early selection hypothesis
The attended input is privileged from the start, so that the unattended input receives little analysis and therefore is never perceived
Selection occurs just before the stimuli reach consciousness, so that we become aware only of the attended input
Late selection hypothesis
All inputs receive relatively complete analysis, and selection occurs after the analysis is finished
Selection occurs later still—so that all inputs make it (briefly) into consciousness, but then the selection occurs so that only the attended input is remembered
Describe the ERP evidence that is often interpreted as evidence of early selection?
ERP evidence for early selection comes from the observation of differential brain activity, or selection-related ERP components, that emerge before 250 milliseconds (ms) after stimulus presentation
Discuss the difference between “early” in time versus functionally early (i.e., in the type of processing that has occurred).
Early in Time: This refers to the temporal sequence of neural events. If a specific ERP component (like the P1) shows a significant difference between two stimuli within a short window after stimulus onset (e.g., 100-200 ms), it is considered "early in time".
Functionally Early: This describes the type of cognitive processing that is occurring. For example, "early sensory processing" is a functional description of processing that occurs very early, even before deeper semantic or conceptual analysis.
Does the ERP evidence concern time or function?
ERP evidence concerns both time and function.
Time: The timing and duration of ERP components provide information about the speed of cognitive processes.
Function: The specific ERP components, their scalp distribution, and their modulation by task conditions reveal information about the type of cognitive function (e.g., sensory processing, attention, semantic integration) that is occurring at a particular time.
Describe the Stroop effect and why it suggests that selection is late.
Stroop interference: A classic demonstration of automaticity in which research participants are asked to name the color of the ink used to print a word, and the word itself is a name of a different color
It suggests that selection is "late" because all incoming information, both relevant and irrelevant, is processed for its meaning before a response is chosen.
Figure 5.21 Stroop Interference
As rapidly as you can, name out loud the colors of the ink in Column A. (You’ll say “black, green,” and so on.) Next, do the same for Column B—again, naming out loud the colors of the ink. You’ll probably find it much easier to do this for Column A, because in Column B you experience interference from the automatic habit of reading the words.

Cocktail party effect
There you are at a party, deep in conversation. Other conversations are going on, but somehow, you’re able to “tune them out.” All you hear is the single conversation you’re attending to, plus a buzz of background noise. But now imagine that someone a few steps away from you mentions the name of a close friend of yours. Your attention is immediately caught, and you find yourself listening to that other conversation and (momentarily) oblivious to the conversation you had been engaged in. This experience, easily observed outside the laboratory, matches the pattern of experimental data.
The “cocktail party effect” and the Stroop effect are logically similar because they both demonstrate how selective attention works by processing task-irrelevant information automatically, creating interference with a person’s conscious, goal-directed task
Describe the logic and design of the spatial-cueing experiment. What is the evidence that there are both costs and benefits to selective processing.
Participant task: Participants sit in front of a screen and are instructed to keep their eyes focused on a central fixation point, such as a cross or dot.
Visual display: Two identical placeholder boxes are shown on either side of the fixation point.
Trial procedure:
a. A cue is briefly presented. Cues can be endogenous (an arrow at the center pointing to one of the boxes) or exogenous (one of the boxes briefly flashes or brightens).
b. After a short delay, a target stimulus (e.g., a letter or shape) appears in one of the two boxes.
c. The participant's task is to respond as quickly as possible upon detecting the target or to identify what the target is.
Cue conditions: The experiment includes three primary conditions to isolate the effects of attention:
a. Valid-cue trials: The cue correctly predicts the location of the upcoming target. For example, a central arrow points to the left box, and the target appears there.
b. Invalid-cue trials: The cue incorrectly predicts the target's location. The central arrow points to the left, but the target appears in the right box.
c. Neutral-cue trials: A neutral cue (e.g., a double-headed arrow or a non-predictive symbol) provides no information about the target's location. This condition serves as a baseline against which to measure the benefits and costs of spatial cueing.
The faster responses in valid-cue trials highlight the benefits of correctly directing attention, while the slower responses in invalid-cue trials demonstrate the costs associated with misdirecting it. The neutral condition serves as the necessary baseline to isolate these two distinct effects of attentional selection.
Describe the difference between bottom-up and top-down attentional control.
Attention is “pulled” to the target... always goes there first, so it doesn’t matter how many there are – Bottom-Up Control of Attention
Attention is “pushed” by the searcher from one item to another – Top-Down Control of Attention
Bottom-up = controlled by the stimulus
Top-down = controlled by the observer
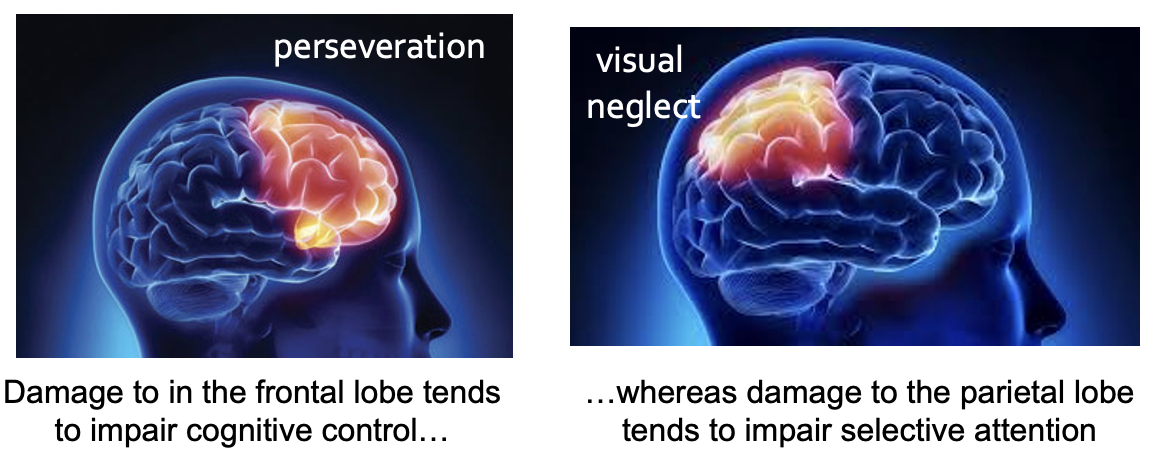
Unilateral neglect (hemineglect/neglect)
A form of dysfunction with attentional guidance that occurs following unilateral damage to the parietal cortex
Results from a line cancellation task from a patient with left-hemifield neglect (damage in the right parietal cortex)
They can see the lines on the left side with no problems, when their attention is drawn to them. They just fail to shift their attention to them on their own. This is an attention problem.
Response time experiment (Egly, Driver, Rafal, 1994)
Stimuli: Participants view two parallel rectangles that appear simultaneously on a screen.
Cue: A small cue flashes at one end of one of the rectangles.
Target: A target stimulus then appears. There are three conditions for the target's location:
a. Valid cue: The target appears at the exact location of the cue.
b. Invalid-same object: The target appears at the opposite end of the same rectangle as the cue.
c. Invalid-different object: The target appears on the other rectangle, at an equally distant location from the cue as the invalid-same object condition.
Task: Participants must press a button as quickly as possible when they detect the target.
Control: The distance between the cue and the target is identical for the two invalid conditions. This ensures that any difference in response time is not simply due to spatial distance.
Results and Conclusion:
Valid vs. Invalid: Participants are fastest at detecting the target in the valid cue condition, confirming that spatial attention is initially directed to the cued location.
Invalid-Same vs. Invalid-Different: Critically, participants are reliably faster at detecting the target in the invalid-same object condition than in the invalid-different object condition.
Object-based conclusion: The finding that attention spreads along the cued object, rather than just shifting through space, provides strong evidence for object-based attention. Attention is allocated to the entire object, causing a reaction time advantage for targets appearing anywhere on it.
FFA vs. PPA activity experiment (based on O'Craven, Downing, & Kanwisher, 1999)
Stimuli: Participants view superimposed images of a face and a house occupying the same location on the screen. The images are semi-transparent and in motion.
Task: On each trial, participants are instructed to attend to either the face or the house and to perform a detection task, such as monitoring for a slight change in the object's motion.
fMRI Measurement: An fMRI machine records the level of neural activity in the FFA and PPA during these tasks.
Results and Conclusion:
Attending to the face: When participants are instructed to attend to the face, fMRI shows increased activity in the FFA, the brain region specialized for faces.
Attending to the house: When participants are instructed to attend to the house, fMRI shows increased activity in the PPA, the brain region specialized for places.
Object-based conclusion: Even though the face and house occupy the same spatial location, the modulation of neural activity is object-specific. The pattern of brain activity changes depending on which object is being attended to, proving that attention is selecting the object itself and not just a region of space.
Divided attention
The skill of performing multiple tasks simultaneously
The flip side of selective attention
Cognitive control is separable from selection
Domain-general
Refers to broad, widely applicable mechanisms or skills
Mechanisms are flexible and can be applied to a wide range of tasks and information across different cognitive areas
E.g., Working memory, attention, and general intelligence
Domain-specific
Refers to narrow, specialized mechanisms or skills that apply to only a particular area of knowledge or function
Mechanisms are specialized for a particular type of information or function within a single domain
E.g., Innate perceptual systems, specialized brain areas for reading, or specific knowledge structures
Executive control (aka cognitive control)
The mechanisms that allow you to control your own thoughts, and these mechanisms have multiple functions
Refers to processes that determine how specific resources are allocated across multiple tasks
The point is that interference can occur between tasks due to a need to access a general control process, rather than any task-specific interference
Perseveration error: A tendency to produce the same response over and over even when it’s plain that the task requires a change in the response
Goal neglect: Failing to organize their behavior in a way that moves them toward their goals
Describe the experiment showing that driving and talking on the phone impairs driving performance more than driving and talking to someone who is in the car. What is an explanation for that difference?
Driving while talking on a cell phone significantly impairs performance more than talking to a passenger, with cell phone users showing worse lane keeping, greater following distance, and higher error rates.
The difference is because a passenger conversation shares situational awareness, as they often discuss traffic and context, creating a shared understanding.
In contrast, a cell phone conversation takes place in a "far space," away from the immediate environment, causing mental distraction and a deeper cognitive disconnect from the driving task.
Describe the example of perseveration in a task that we saw in the video with the child being asked to switch from playing the “shape game” to playing the “color game”.
That is an example of undeveloped executive control. Brain damage to what part of the brain can cause similar behavior in adults?
Shape game/color game: The child continues to sort by shape even when told to sort by color, demonstrating a difficulty in shifting their focus from the previous rule.
This undeveloped executive control is seen as a failure to inhibit a prepotent response and switch to a new rule.
In adults, similar behavior can be caused by damage to the brain's prefrontal cortex, which is crucial for executive functions like task switching and cognitive flexibility.