introduction to computational models of speech perception
1/23
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No study sessions yet.
24 Terms
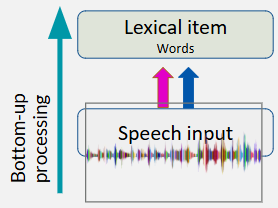
what is bottom-up processing in speech perception
intaken sensory input being processed to the point of semantic understanding
what is top-down processing in speech perception
applying prior knowledge of the world around you to sensory input
how are sounds comprehended in the brain
via accessing the mental lexicon —> the store of all the words/concepts we know
this includes accessing their semantics, syntax, orthography, phonological representation etc.
what are 4 challenges to lexical access
continuous speech stream —> lack of pauses in speech makes it difficult to disambiguate words
homonyms (sounds + spelt the same) + homophones (sounds the same) —> can make it difficult to differentiate the
coarticulation —> when speech production is influenced by sounds that precede + follow a phoneme
different accents —> changes the pronunciation of words, which may impede on ability to comprehend speech
what is the invariance problem
due to challenges to lexical access, there is no one definition for the acoustic properties of phonemes —> speech is therefore supported by complex cognitive processes to overcome/make sense of these challenges
what are 3 methods of disambiguating the speech stream
categorical perception —> ability to distinguish between sounds on a continuum based on voice onset times (VOT) e.g. ‘v’ vs ‘f’
perceptual learning —> adjusting categorical perception based on sounds we hear
top-down processing —> allows us to recognise a word based on prior knowledge and context, e.g. filling in the phonemes if someone coughs
how is top-down processing utilised to predict speech
spreading activation facilitates the activation of items related to the acoustic input —> if sound has degraded, relevant words are activated so we can readily guess out of a phonemically-similar cohort what word was said
the one with the strongest activation (most phonemically similar) is predicted
what 3 lexical characteristics affect the speed of lexical access
word length —> shorter words are faster to process
frequency —> words more frequently accessed in the lexicon are quicker to access
neighbourhood density —> the less phonetic neighbours a word has (e.g. choir), the quicker it is processed
what are 3 possible options as to now lexical access occurs
activate all words that sounds like the first phoneme of the target word, and gradually deactivate words that no longer match the following phonemes, until we are left with one candidate word
any word containing the first phoneme is activated, and matching word is gradually activated more than other words until it has the strongest + is selected for comprehension
activate words that match the sounds at each point in the unfolding speech stream
what are the 2 main models of speech comprehension (covered today)
Marlsen-Wilson (1987)’s Cohort Model
Elman + McClelland (1999)’s TRACE Model
what is a brief overview of the Cohort Model
predicts that we access words in the lexicon via activation of all words sharing initial features + gradually deactivate words that stop matching the features
what is a brief overview of the TRACE model
predicts that phonemic features activate phonemes that activate words, with a gradual increase in activation of words that match with all features, so that the word with the most activation wins
outline how lexical activation occurs in the Cohort model + what the cohort refers to
to activate the target word (e.g. ‘apricot), we activate all words that have the first phoneme present via a gradual process (chunks of word at the time)
cohort = made up of words that match the initial sound —> hearing input causes all of these to become active
as more phonemes of the word are said (‘apri’), words that fail to match output gradually deactivate
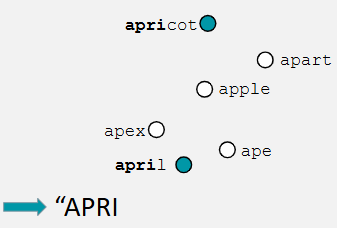
what is the uniqueness point in the Cohort model + how does this lead to lexical activation
when no other word in our lexicon matches the input (in this case ‘apric’) —> at this point the target word has already been identified, so rest of sound doesn’t need to be accessed
words in the cohort that do not match are deactivated + the target word’s representation in the lexicon is accessed
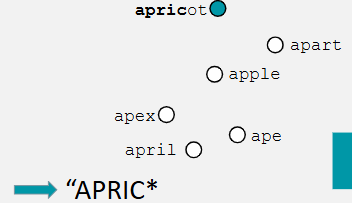
are items that do not match word onset activated in the Cohort model + why
no, as words that don’t have the same initial phoneme (e.g. ‘prickly’) are not activated —> model assumes that lexical activation is dominated by bottom-up processing, so relies on acoustic input
how does the Cohort model account for neighbourhood density effects
because words that match acoustic input compete for activation, words with many neighbours will all compete for recognition
when new word is integrated into our lexicon, uniqueness point must shift to accommodate for it (e.g. aprikol) —> addition of new word slows recognition of target word due to more competition
how does the Cohort model account for frequency effects
words used frequently have higher resting states of activation, so less activation is required to recognise them
words less frequently used (e.g. ‘aprikol’) would have lower activation point due to being less used in the lexicon, so less easily accessed
outline how gating experiments are conducted + what occurs cognitively during them
participants are presented with fragments of words that gradually reveal the whole word —> asked to guess what the word is after each presentation
the more of the word is presented, the more the size of the cohort in are lexicon reduces by words being deactivated, until only one target remains + is accessed
in what 2 ways do Warren + Marslen-Wilson (1987)’s gating experiments provide evidence for the Cohort model
results of gating experiments suggest that:
recognition of a word is a gradual process that starts from word onset + continues until the end of the word/uniqueness point
candidate words that no longer fit acoustic input are eliminated
how does the bottom-up processing occur in the Marslen-Wilson + Warren (1994)’s Cohort model
faciliatory signals are sent to the cohort of initial items in the lexicon that match the speech input, while inhibitory signals are sent to words that don’t match speech input
this process of sending signals from speech input to the lexicon is bottom-up
what is the phonemic restoration effect + what does it imply
even when you cannot hear certain phonemes in a word (e.g. if someone coughs), you can often still identify what the word
this shows we cannot simply rely on bottom-up processing, as context/knowledge of words that match closely allow you to intuit the info you missed
how does the Cohort model account for phenomena such as the phonemic restoration effect
though model prioritises bottom-up processing, the 3 stages to word recognition allow the influence of top-down processing via the step of integration
what are the Cohort model’s 3 stages to word recognition (Marslen-Wilson et al., 1997)
access —> acoustic-phonetic info is mapped onto lexical items
selection —> candidate words that mismatch the acoustic input are de-activated + candidate word is chosen
integration (top down processing) —> semantic + syntactic properties of the word are integrated + checked against the context of the sentence
what is the past + present relationship between the Cohort model + context
early iterations of the model suggested context constrained the cohort