Técnicas de Modelagem Dimensional de Dados
1/99
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
100 Terms
Abstração
Ato de separar mentalmente um ou mais elementos de uma totalidade complexa (coisa, representação, fato), os quais só mentalmente podem subsistir fora dessa totalidade.
Modelo
Representação (visual ou esquemática) que define a estrutura e a organização dos dados dentro de um SGBD.
Modelo Dimensional
Pode ser representado por um cubo
Fato
Métrica que se busca avaliar
Dimensões
Conjuntos de qualificadores usados para identificar e registrar fatos
Tabela de fatos
Dados agregados e mensuráveis (como vendas, quantidade, valor)
Tabela de Dimensões
Informações descritivas (como tempo, produto, cliente)
Modelagem dimensional
Não está preocupada com eventos e dados que sejam alterados em tempo real. Sua ênfase é facilitar o acesso rápido a dados agregados e históricos, permitindo que sejam analisados sob diferentes perspectivas.
Tabelas de Dimensões
Descrevem as entidades de negócios - os itens que são modelados.
As entidades podem incluir produtos, pessoas, locais e conceitos, incluindo o próprio tempo.
Em geral, contêm um número relativamente pequeno de linhas.
Tabelas de fatos
Armazenam observações ou eventos e podem ser ordens de venda, saldos de estoque, taxas de câmbio, temperaturas e muito mais.
Contém colunas chave e colunas de medida numérica.
Podem conter um grande número de linhas e continuar a crescer ao longo do tempo.
Tipos de Tabelas de Fatos
Transaction (transação)
Periodic Snapshot
Accumulating Snapshot
Tabela de Fatos de Transações
Captura eventos de transação individuais, armazenando dados em um nível de granularidade detalhado, normalmente por ocorrência. É constantemente atualizada com novos eventos.
Ex: vendas diárias em uma loja de varejo, onde cada linha representa uma venda específica de um produto.
Tabela de Fatos Periodic Snapshot
Captura o estado de uma métrica em intervalos regulares de tempo (diariamente, semanalmente, mensalmente, etc.), fornecendo uma visão periódica dos dados.
Ex: estoques mensais em um armazém, onde cada linha registra a quantidade de produtos no final de cada mês.
Tabela de Fatos Accumulating Snapshot
Acompanha o ciclo de vida de um evento ou processo que passa por várias etapas e acumula atualização ao longo do tempo até o evento ser concluído.
Ex: pedido de um cliente, onde cada linha acompanha o status de um pedido desde a criação até a entrega final.
Dimensão degenerada
É caracterizada por não ter uma tabela de dimensão própria.
Em vez disso, seus valores são armazenados diretamente na tabela fato, geralmente como parte de uma chave primária ou como um atributo identificador.
É comum para dados que não precisam de informações descritivas adicionais e que estão relacionados a um único eventos, como números de transação ou IDs de pedidos.
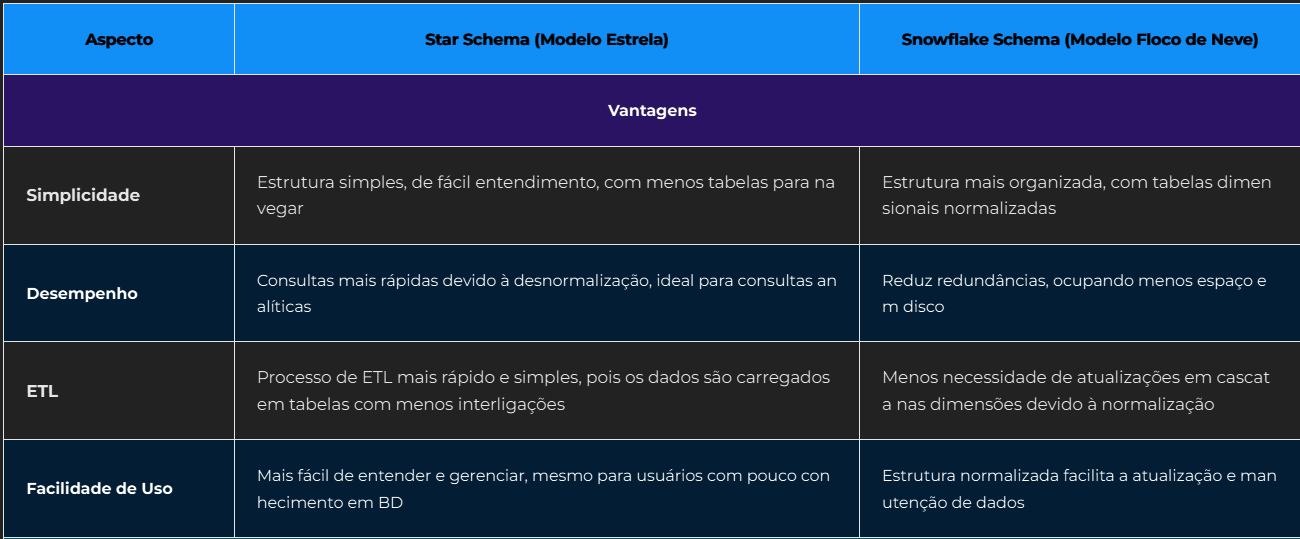
Principal diferença entre os modelos estrela e floco de neve
Grau de normalização e/ou desnormalização das tabelas de dimensões
Modelo Relacional
Ideal em sistemas transacionais (OLTP), com atualizações (não somente UPDATE, mas também INSERT e DELETE) frequentes e constantes dos dados.
Modelo Dimensional
Utilizado para lidar com grandes volumes de dados históricos e transacionais, sendo ideal para relatórios, painéis analíticos e data warehouse.
Normalmente depois que o fato é inserido na tabela de fatos, ele não é mais modificado.
Amplamente usado em ambientes OLAP.
Modelo Relacional X Dimensional
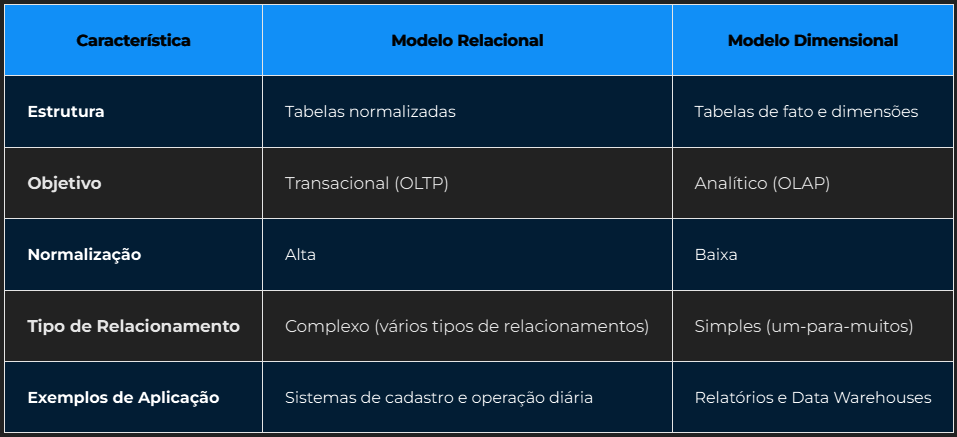
Granularidade
Refere-se ao nível de detalhe dos dados armazenados em uma tabela fato. Quanto mais atômico foi o dado, maior o nível de detalhamento, resultando em um volume maior de dados e em mais possibilidades de agregação.
Vantagens Star Schema e Floco de Neve
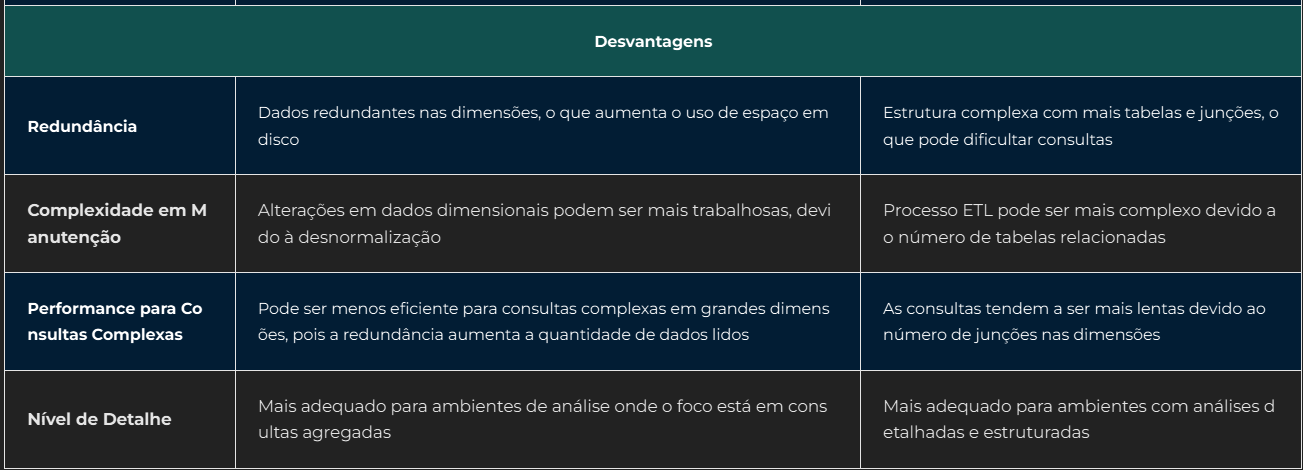
Desvantagens Star Schema e Floco de Neve
Principais Aplicações da Modelagem Dimensional
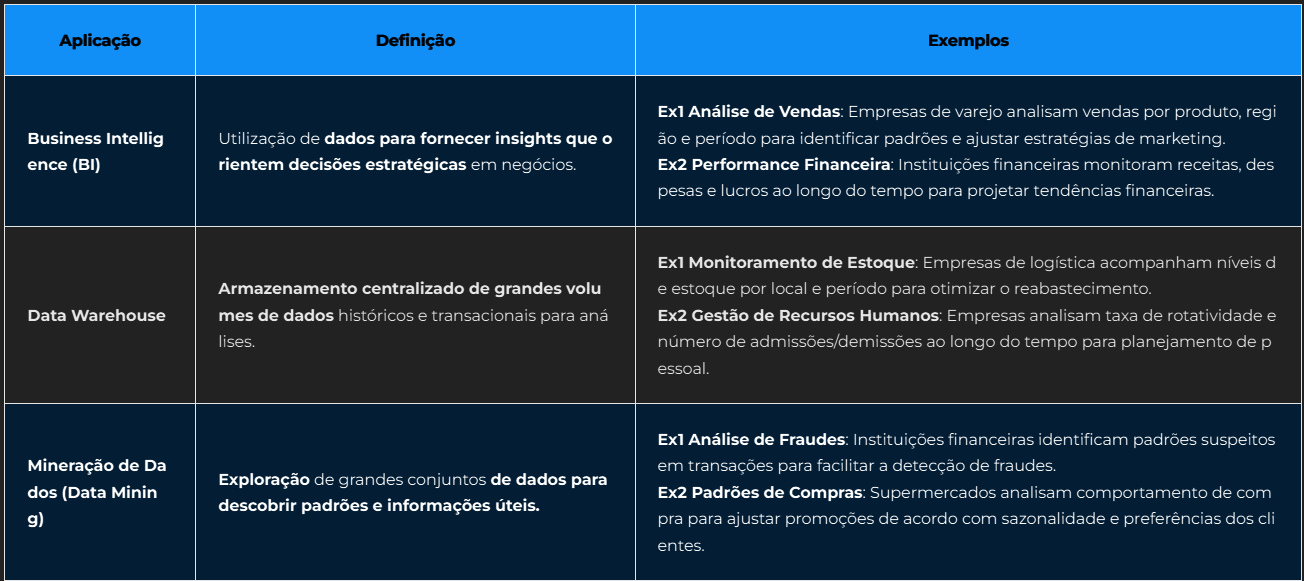
Business Intelligence (BI)
Utilização de dados para fornecer insights que orientem decisões estratégicas em negócios
Data Warehouse
Armazenamento centralizado de grandes volumes de dados históricos e transacionais para análises
Data Mining (mineração de dados)
Exploração de grandes conjuntos de dados para descobrir padrões e informações úteis.
Técnicas de Otimização em Bases Multidimensionais
Agregação (Sumarização)
Indexação
Particionamento
Compressão
Caching
Materialized Views
Tipos de Processo de Agregação
Manual: coletar e resumir informações de várias fontes de dados por intervenção humana, geralmente usando ferramentas como planilhas ou cálculos manuais
Automatizado: coleta, organização e resumo sistemáticos de grandes volumes de dados usando software ou ferramentas especializadas, sem a necessidade de intervenção manual
Agregação (Sumarização)
Consiste em pré-calcular e armazenar os valores (somas, médias, medianas, variâncias, desvios-padrões, etc) agrupados nos níveis superiores das hierarquias
Principais métodos de agregação
Soma
Contagem
Média
Mínimo e Máximo
Mediana
Modo
Variância e desvio padrão
Percentis
Intervalos de tempo
Ponderado
Geoespacial
Hierárquico
Rolante
Cumulativo
Método de agregação - Soma
Soma valores numéricos para calcular um valor total ou agregado
Método de agregação - Contagem
Determina o número total de pontos de dados em um conjunto de dados
Método de agregação - Média (Mean)
Calcula o valor central somando todos os pontos de dados e dividindo pela contagem total
Método de agregação - Mínimo e Máximo
Identifica os menores e maiores valores em um conjunto de dados, respectivamente
Método de agregação - Mediana
Encontra o valor médio em um conjunto de dados classificado, dividindo-o em duas metades iguais
Método de agregação - Moda
Identifica o valor que ocorre com mais frequência em um conjunto de dados
Método de agregação - Variância e desvio padrão
Medem a dispersão dos pontos de dados em torno da média
Método de agregação - Percentis
Dividem os dados em centenas de partes iguais, ajudando a entender a distribuição dos valores
Método de agregação - Intervalos de tempo
Agrupa dados com base em períodos temporais específicos (por exemplo, horas, dias, meses) para analisar tendências ao longo do tempo
Método de agregação - Ponderado
Aplica pesos diferentes aos pontos de dados com base em sua importância ou significância
Método de agregação - Geoespacial
Combina dados com base em localizações geográficas ou regiões
Método de agregação - Hierárquico
Agrega dados em uma estrutura hierárquica, permitindo resumos em diferentes níveis de granularidade
Método de agregação - Rolante
Calcula valores agregados em uma janela móvel ou em um intervalo específico de pontos de dados
Método de agregação - Cumulativo
Calcula totais correntes ou somas cumulativas sobre uma sequência de pontos de dados
Índices
São estruturas criadas para facilitarem o acesso a registros específicos de bancos de dados.
Também são utilizados no modelo de dados dimensional.
A literatura sugere que sejam criados preferencialmente nas tabelas fato
ArangoDB
É um sistema de banco de dados multimodelo, que suporta bancos não relacionais, como grafos ou documentos JSON
Índices multidimensionais
Permitem indexar dados bidimensionais ou de dimensões superiores, como intervalos de tempo, para intersecção eficiente de consultas de vários intervalos.
Mapeiam dados multidimensionais na forma de múltiplos atributos numéricos para uma dimensão
Principais tipos de indexação
Bitmap
B-tree (Árvore B)
Spatial Index
Inverted Index
Clustered Index
Hash Index
Bitmap
Utiliza sequências de bits para representar a presença ou ausência de um valor em uma coluna. Cada bit corresponde a uma linha na tabela.
Bitmap - Casos de uso recomendados
Consultas em colunas com baixa cardinalidade (poucos valores distintos), onde se deseja saber quais linhas possuem um determinado valor. Ex: status, flag, categorias simples
Bitmap - Vantagens
Eficiente para colunas de baixa cardinalidade.
Rápido para operações de AND, OR e NOR em múltiplas colunas.
Ocupa pouco espaço quando a cardinalidade é baixa.
Bitmap - Desvantagens
Ineficiente para colunas de alta cardinalidade
Atualizações podem ser lentas, pois exigem várias modificações
B-tree (Árvore B)
Uma estrutura autobalanceada que mantém os dados ordenados e permite pesquisas, inserções e exclusões em tempo logarítmico. É o tipo de índice mais comum em bancos de dados relacionais.
B-tree (Árvore B) - Casos de uso recomendados
Consultas em colunas com alta cardinalidade (muitos valores distintos), como IDs, datas, valores numéricos. Consultas por range (faixa de valores)
B-tree (Árvore B) - Vantagens
Eficiente para consultas por igualdade e por range.
Bom desempenho geral em diversos tipos de consultas
Suporta ordenação eficiente
B-tree (Árvore B) - Desvantagens
Pode ocupar mais espaço que o bitmap em colunas de baixa cardinalidade
Inserções e exclusões podem ser mais lentas que em outros tipos de índices, especialmente em estruturas muito grandes
Spatial Index
Um índice otimizado para dados espaciais (geográficos ou geométricos), permitindo consultas baseadas em localização ou proximidade. Ex: R-tree, Quadtree
Spatial Index - Casos de uso recomendados
Consultas que envolvem localização geográfica (ex: encontrar pontos de interesse próximos a um local), análise de proximidade, dados geoespaciais
Spatial Index - Vantagens
Permite consultas espaciais inteligentes (ex: encontrar pontos dentro de um raio, interseção de geometrias)
Spatial Index - Desvantagens
Mais complexo de implementar e manter do que índices tradicionais
O desempenho pode variar dependendo da distribuição dos dados e do tipo de consulta espacial realizada
Inverted Index
Um índice que mapeia palavras (ou termos) para os documentos ou linhas em que elas ocorrem, permitindo buscas rápidas por texto
Inverted Index - Casos de uso recomendados
Consultas de texto completo (full-text search), recuperação de informação, análise de documentos
Inverted Index - Vantagens
Permite buscas rápidas por palavras-chave em grandes volumes de texto
Inverted Index - Desvantagens
Pode ocupar bastante espaço, especialmente para textos com muitas palavras únicas
Atualizações podem ser lentas, pois exigem a modificação de várias entradas no índice
Clustered Index
Define a ordem física de armazenamento dos dados na tabela. Só pode haver um por tabela, já que os dados só podem ser armazenados em uma ordem.
Clustered Index - Casos de uso recomendados
Consultas que se beneficiam da recuperação de dados ordenados sequencialmente, como relatórios ou em tabelas que possuem uma chave primária sequencial
Clustered Index - Vantagens
Acelera a recuperação de dados quando a consulta se baseia na chave do índice
Reduz a necessidade de ordenação, pois os dados já estão ordenados
Clustered Index - Desvantagens
Inserções podem ser mais lentas se os dados precisarem ser inseridos em uma posição específica da ordem física.
Atualizar a chave do índice pode ser custoso, pois exige reorganização
Hash Index
Usa uma função para mapear chaves para seus respectivos valores, permitindo acesso rápido aos dados
Hash Index - Casos de uso recomendados
Consultas por igualdade exata em colunas com alta cardinalidade
Hash Index - Vantagens
Extremamente rápido para consultas por igualdade exata
Hash Index - Desvantagens
Ineficiente para consultas por range ou ordenação. Não é tão comum em ambientes OLAP por conta disso.
Pode sofrer com colisões de chave, que impactam o desempenho
Particionamento
É a divisão do cubo em partes menores, com o intuito de melhorar o gerenciamento e a performance
Benefícios do Particionamento
Criação e armazenamento simplificado
Facilidade no gerenciamento e atualização dos dados e esquemas
Maior eficiência na utilização de soluções de gerenciamento de dados
Partições
São um meio poderoso e flexível de gerenciar cubos, especialmente cubos grandes.
Podem ser utilizadas em conjunto com outras técnicas de otimização (ex: podem permitir um controle mais granular dos índices existentes)
Modo de Armazenamento - Partições
Pode ser configurado para cada uma independentemente das outras no grupo de medidas.
Compressão de dados
Técnica usada para reduzir o tamanho dos dados armazenados, de modo a economizar espaço em disco e melhorar a velocidade de leitura
Run-Length Encoding (RLE)
Substitui sequencias de valores repetidos por um valor e um contador de repetições
Run-Length Encoding (RLE) - Uso Recomendado
Colunas com longas sequencias de valores repetidos, dados ordenados ou com baixa cardinalidade
Run-Length Encoding (RLE) - Vantagens
Simples e eficiente para dados com muitas repetições
Run-Length Encoding (RLE) - Desvantagens
Ineficaz para dados sem muitas repetições
Dictionary Encoding
Cria um dicionário que mapeia valores distintos para códigos menores
Dictionary Encoding - Uso Recomendado
Colunas com cardinalidade moderada a alta, valores que se repetem, mas não em sequencia
Dictionary Encoding - Vantagens
Reduz significativamente o tamanho de colunas de texto ou categóricas
Dictionary Encoding - Desvantagens
Introduz a sobrecarga de gerenciar o dicionário
Delta Encoding
Armazena a diferença entre valores consecutivos
Delta Encoding - Uso Recomendado
Dados numéricos ordenados onde a diferença entre valores consecutivos é pequena (séries temporais)
Delta Encoding - Vantagens
Eficiente para dados numéricos sequenciais
Delta Encoding - Desvantagens
Menos eficaz se os dados não forem ordenados ou se as diferenças entre valores forem grandes
Columnar Storage
Armazena os dados em colunas em vez de linhas
Columnar Storage - Uso Recomendado
Bancos de dados analíticos (OLAP) e data warehouses
Columnar Storage - Vantagens
Melhora a eficiência da compressão e o desempenho das consultas analíticas
Columnar Storage - Desvantagens
Pode ser menos eficiente para operações de escrita (inserção, atualização)
Caching
Manter na memória os dados mais acessados, o que otimizará o tempo de resposta em consultas que envolvam tais dados.
Materialized Views (visões materializadas)
São semelhantes às agregações, pois haverá também resultados pré-calculados. Contudo, a diferença fundamental é que esses resultados são armazenados fisicamente em disco, como uma tabela. Isso pode melhorar significativamente o desempenho de consultas complexas e frequentes, pois os cálculos não terão de ser refeitos
View (visão)
É uma consulta SQL salva com um nome. Toda vez que for acessada, a consulta será executada dinamicamente
Atualização Completa de Materialized Views
A consulta é executada novamente e todos os dados são substituídos
Atualização Incremental de Materialized Views
Apenas as mudanças desde a última atualização são aplicadas
Atualização Sob Demanda de Materializes Views
A atualização é feita manualmente
Materialized Views - Vantagens
Podem ser baseadas em consultas muito mais complexas, envolvendo múltiplas tabelas, junções, filtros, funções e agregações. Não estão limitadas a agregações simples como as comumente encontradas na estrutura básica de um cubo