Looks like no one added any tags here yet for you.
DynamoDB Architecture
NoSQL database as a service products, its public database as a service (DBaas)- wide column key/value and document. No self managed servers or infrastructure. Supports range is scaling options- manual/automatic provisioned performance IN/OUT or on demand. Can also be highly resistant across AZs and optionally global. It’s really fast. Supports backups, point in time recovery, encryption at rest. Supports event driven integration (do things when data changes)
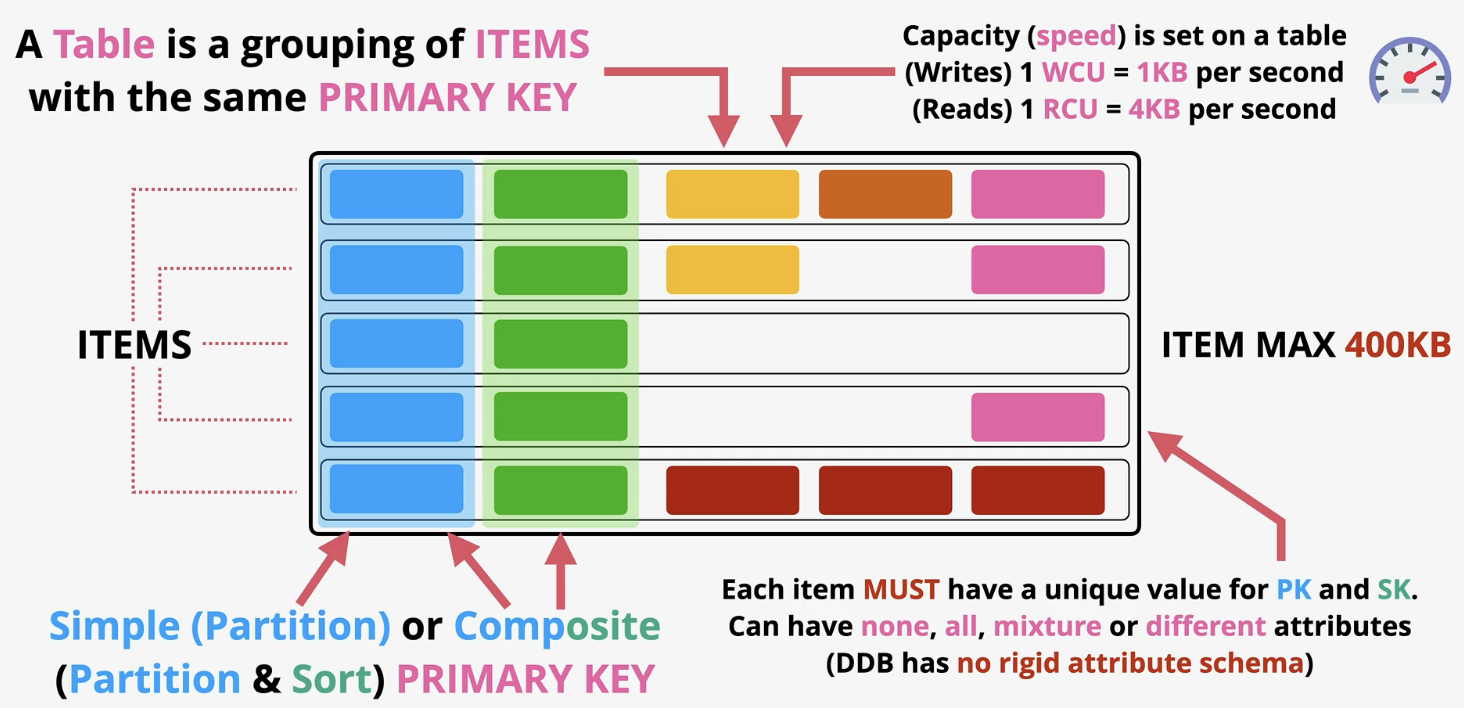
Tables: base entity of dynamoDB. It is a grouping of items with the same primary key. No limit to number of items in a table. A Primary key can be a simple (partition) or composite (partition and sort) primary keys. Each item must have a unite value. Can have none, all, mixture, or different attributes (no right scheme). Item max 400KB (this is speed not space)
DynamoDB backups
On demand: full copy of table retained until removed. Can be used for same/cross region restoration. Can adjust encryption and if its with/without indexes when restored
Your responsible for performing and removing old backups
Point in time recovery: not enabled by default. When enabled it results in continuous stream of backups for a 35 day window. You can resort any one second granular backup
DynamoDB key points
NoSQL == DynamoDB (NEVER relational data)
Key/value == preference DynamoDB
Accessed via console, CLI, API, NEVER SQL
Billing is based on RCU, WCU, storage and features
DynamoDB- Reading and writing:
On demand: unknown, unpredictable and low admin for table. No need to set specific capacity setting. You pay on demand for the R or W units (typically more expensive)
Provisions: you set RCU and WCU set on a per table basis.
> every operation consumes at least 1 RCU or WCU
> 1 RCU is 1 x 4KB read operation per second
> 1 WCU is 1 x 1KB write operation per second
> Even table has a RCU and WCU burst pool (300 second)
DynamoDB- Operations: Query
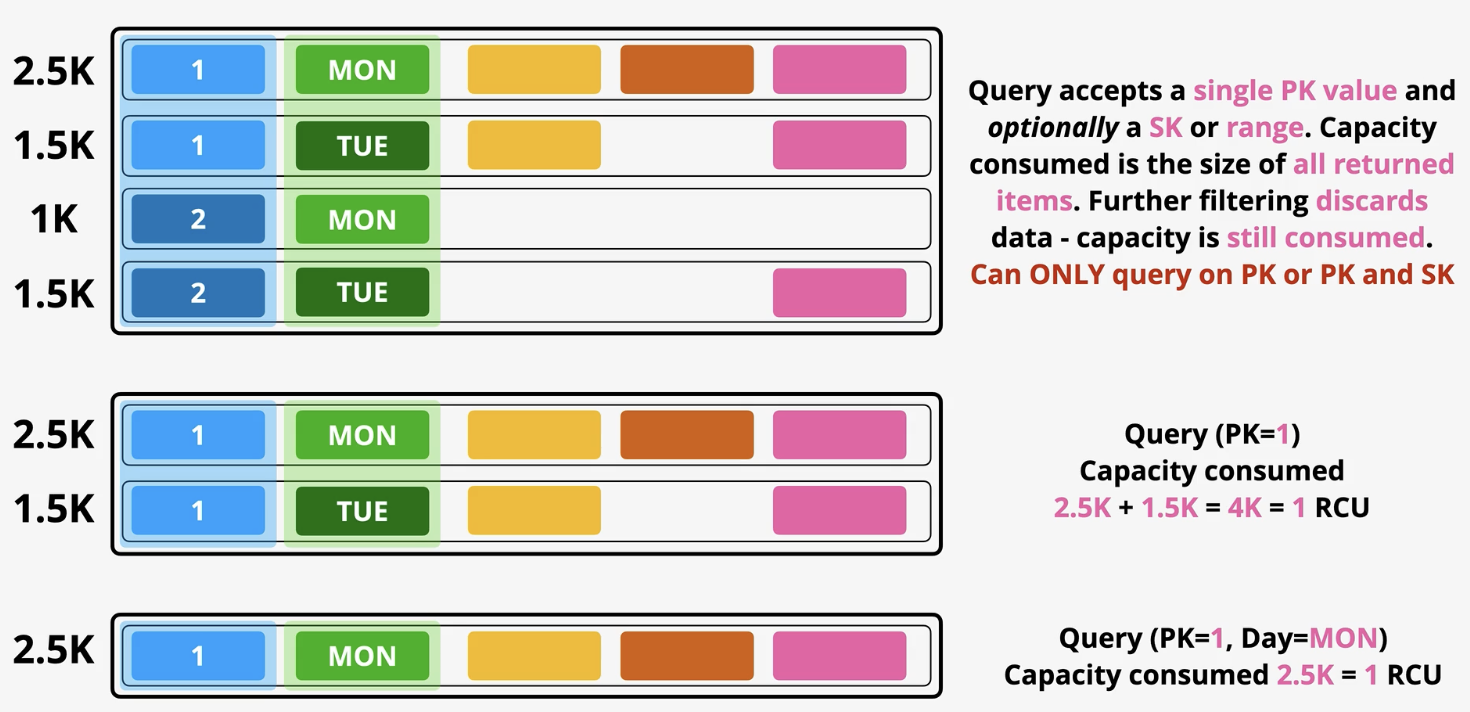
Query: way to retrieve data from product
You need to pick a partition key (blue). Query accepts a single PK value and optionally a SK or range. Capacity consumed is the size of all returned items. Further filtering discards data- capacity is still consumed!! Can ONLY query on PK or PK and SK
Best to combine operations single operation (in the example, if you were to spit the two PK==1 operations you would have consumed 1 RCU since it rounds up for each, totaling 2 RCU)
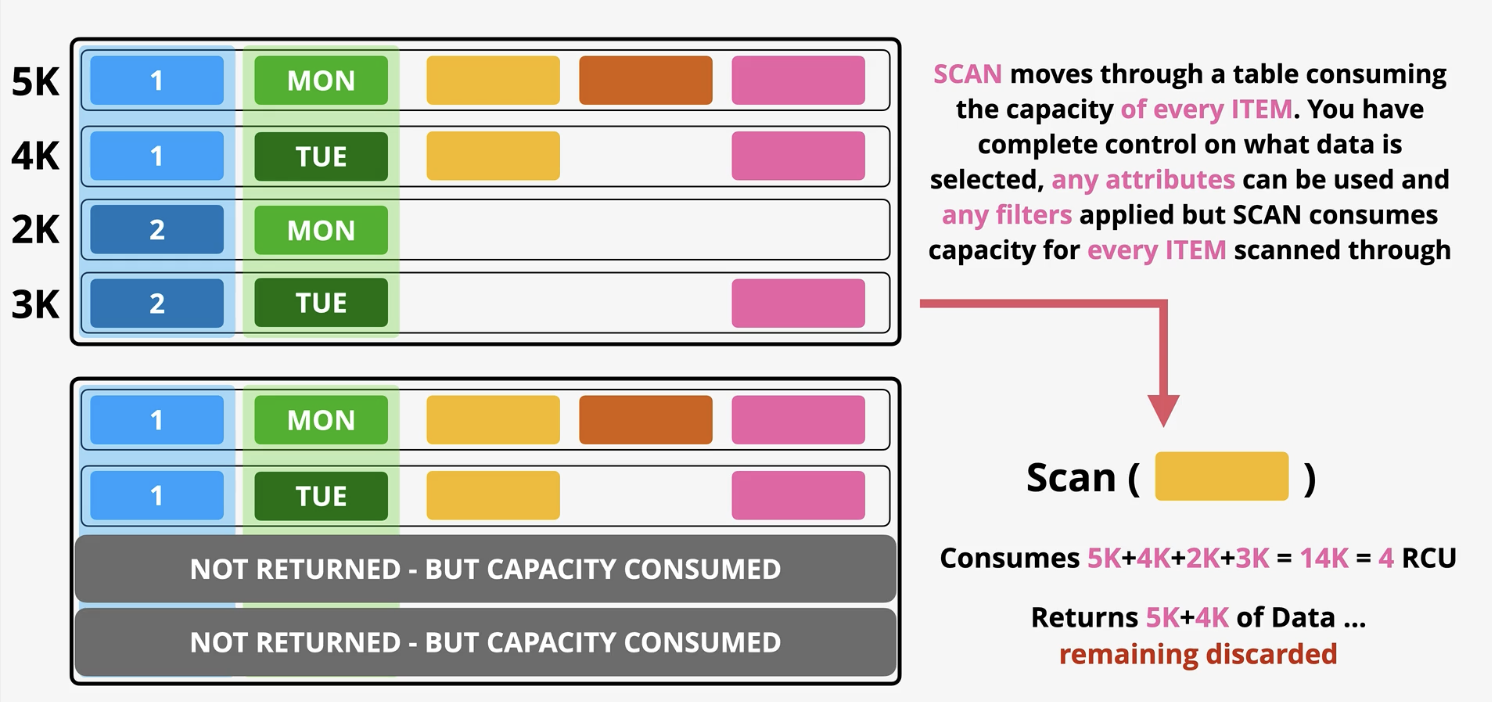
DynamoDB- Operations: Scan
Scan: least efficient in getting data but its more flexible. IT move through the table consuming capacity of every ITME. You have control on what data is selected, any attributes can be used and filters applied but SCAN consumes capacity for every time scanned through.
DynamoDB- Operations: Consistency model:
how when data is updated or when new data is written to the database and then immediacy read is that data immediacy the same or only eventually the same.
In dynamoDB all data is replaced to separate AZ. Each is a “storage node” one of them is a leader node. Writes are always directed to the leader node. The leader node is “consistent”. The leader node then starts process of replication of data to the other nodes
Eventually consistent read: If you do a read, you are directed to one of the nodes at random. If the data is not yet consistent you pay less for the read (half the price)
Strongly consistent: when you do a read, you are taken to the must up to dat copy (leader node)
DynamoDB- operations cost issue
indexes: improve efficiently of query data.
Queries are most efficient operation in DDB, but it can only work on 1 PK value at a time (optionally single or range of SK values)/ indexes are an alternative views on the table. You can get view using SK (LSI) or different PK and SK (GSI). When creating both indexes you have the ability to choose which attributes are projected (some/all).
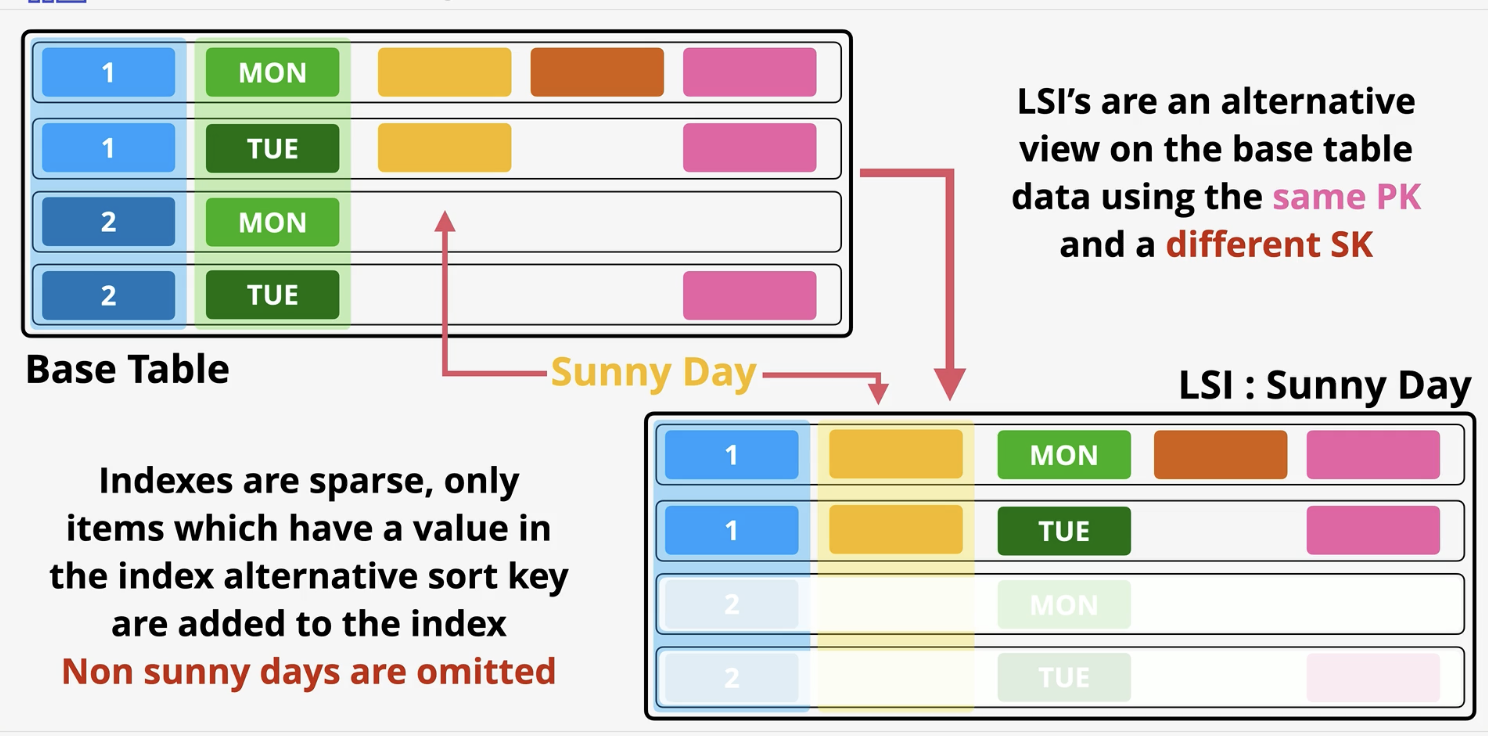
DynamoDB- Local secondary indexes (LSI):
alternative view for a table. It MUST be created with the table, cannot be made after the table is made. You can have 5 LSI’s per base table. It has the SAME PK but alternative SK on the sale. It shares the RCU and WCU with the table. When picking attributes, you can chose to have all, Keys only and include.
If you want ONLY a specific attribute, that attribute can be used as the SK.
Capacity shared with the table
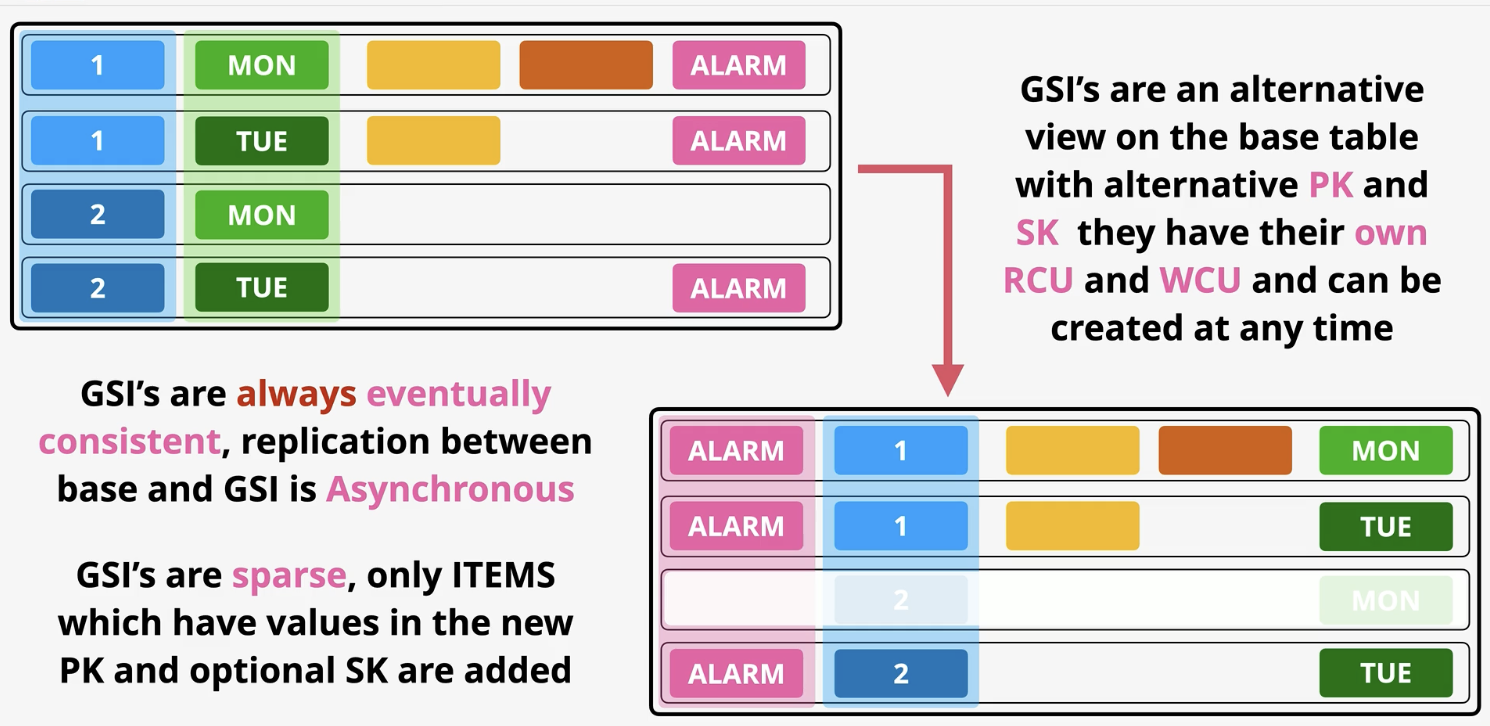
DynamoDB- Global secondary index (GSI):
can be created at any time after the tables creation. Default limit of 20 per base table. You can choose both an alternate PK and SK. GSI’s have wither own RCU and WCU allocations. You chan choose what attributes are displayed (same as LSI)
Always eventually consistent, relation between base and GSI is asynchronous
Own capacity allocation
DynamoDB- LSI and GSI exam points
Careful with projects (all, Keys only and include)- you pay for capacity
Queries on attributes not projected are expensive
GSI as default over LSI (LSI is better for strong consistency requirement)
Use indexes for alternative access patterns
DynamoDB stream
is a time ordered list of item changes in a table. It’s a 24 hour rolling window. You need to enable it on a per table bases. Records are inserts, updates, or deletes. Different view types influence what is in the stream
Streams can be configured with the following view types:
Keys Only: stream will only record PK and any applicable SK changes
New image: stores entire item AFTER to change
Old image: stores entire item PRIOR to change
New and old images: shows full visibility- both pre and post change of image
DynamoDB Trigger
allows actions to take place in the event of a change in data.
The event contains the data which changes. An action is taken using the data. AWS = streams + lambda(trigger)
DynamoDB global tables: provide multi master cross region replication (read and write for all global tables). Tables are made in multiple regions and added to the same global tables (becoming replica tables). Follows last writer wins is used for conflict resolution (recent overwrites). Reads and writes can occur in any region and there is sub second replication between regions. Its sternly consistent reads only in the same region as writes (other regions are eventually consistent)
Provides global HA and Global DR/BC
DynamoDB accelerator (DAX):
in memory cache for DynamoDB- integrated in DynamoDB.
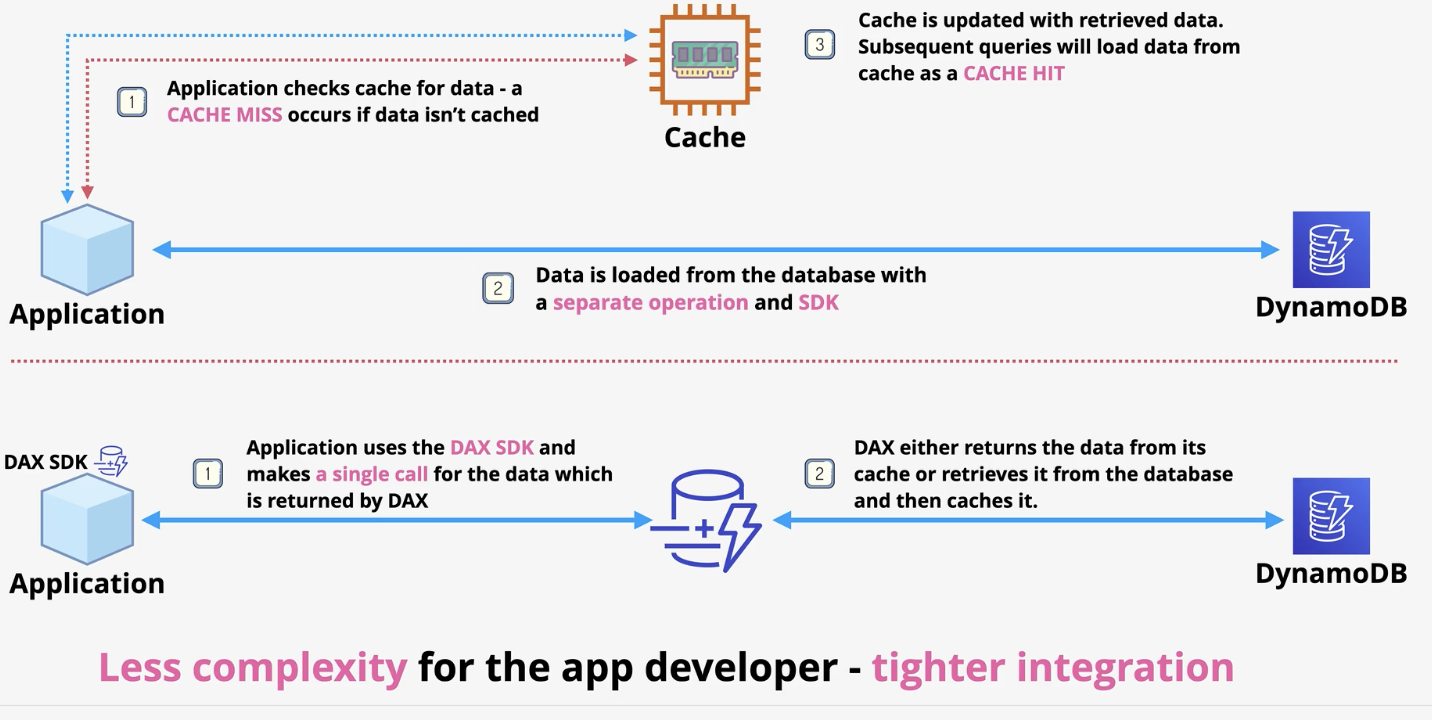
Traditional cache vs DAX
traditional: application goes to cache, if miss, it must go to the DB and grab data and add to cache, cache is then updated and retried data is now a hit
DAX: removes admin overhead. App makes single call to DAX, if miss, DAX does all the work to return and retrieve data from the DB back to the application.
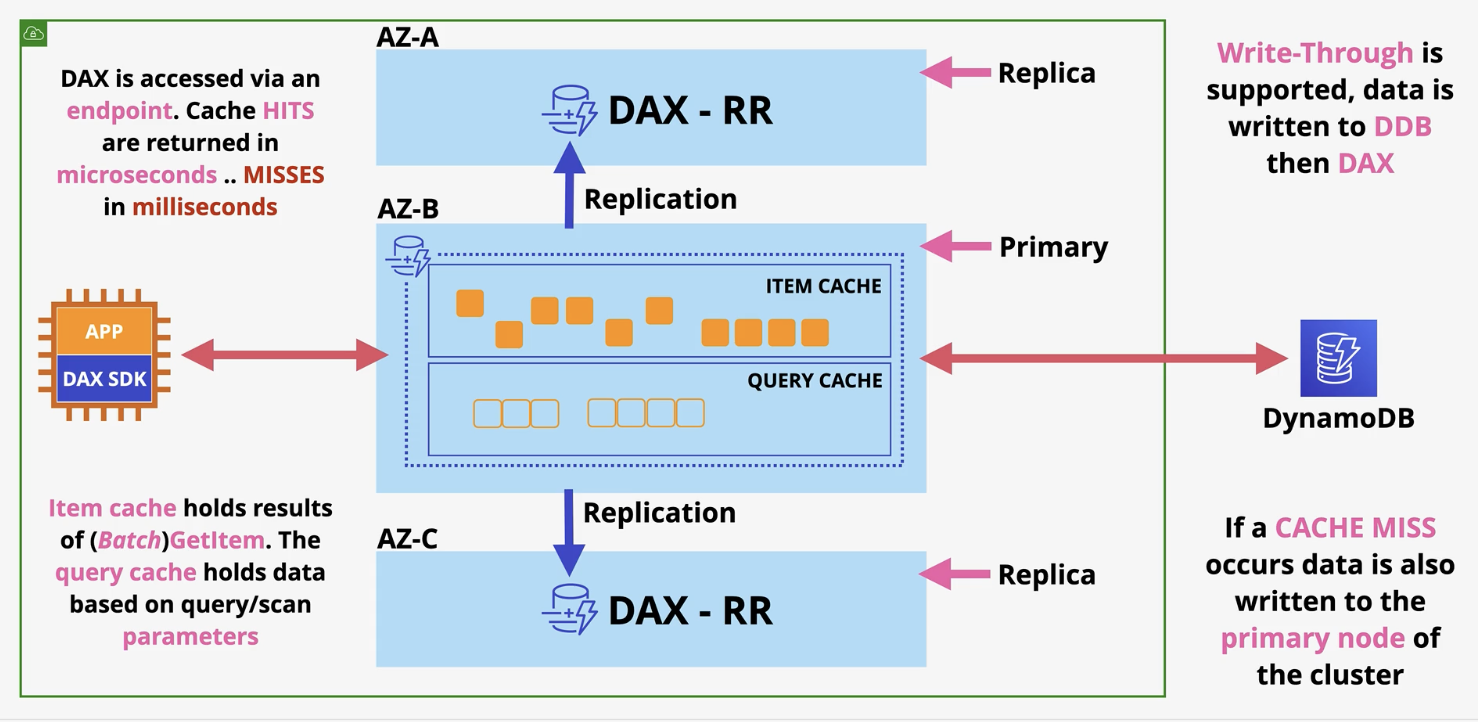
Dax is cluster service
nodes are placed in multiple AZ, one being the primary and the others being replicas (which are read replicas). Item cache holds result of batch getItem.
DAX Exam points
Primary node (supports writes), replicas (read)
Nodes are Highly avalbilbe, if primary fails, its replaced
In memory cache- sharing is much faster for reads, less cost
Can scale up and scale out (bigger or more)
Supports write-through (store data in cache too)
DAX deployed within a VPC
Good for workloads with heavy reads, want low response time
Not ideal for applications that need high consistency
DyanmoDB TTL
TTL lets you define a timestamp for automatic deletion of item. You specific a date and time and its set to ‘expired’. You configure TTL on a specific attribute.
A Per partition process periodically runs, checking the current time (in seconds since epoch) to the value in the TTL attribute. They are set to ‘expired’, then its ran again and if an item is set to expired its actually deleted
Athena
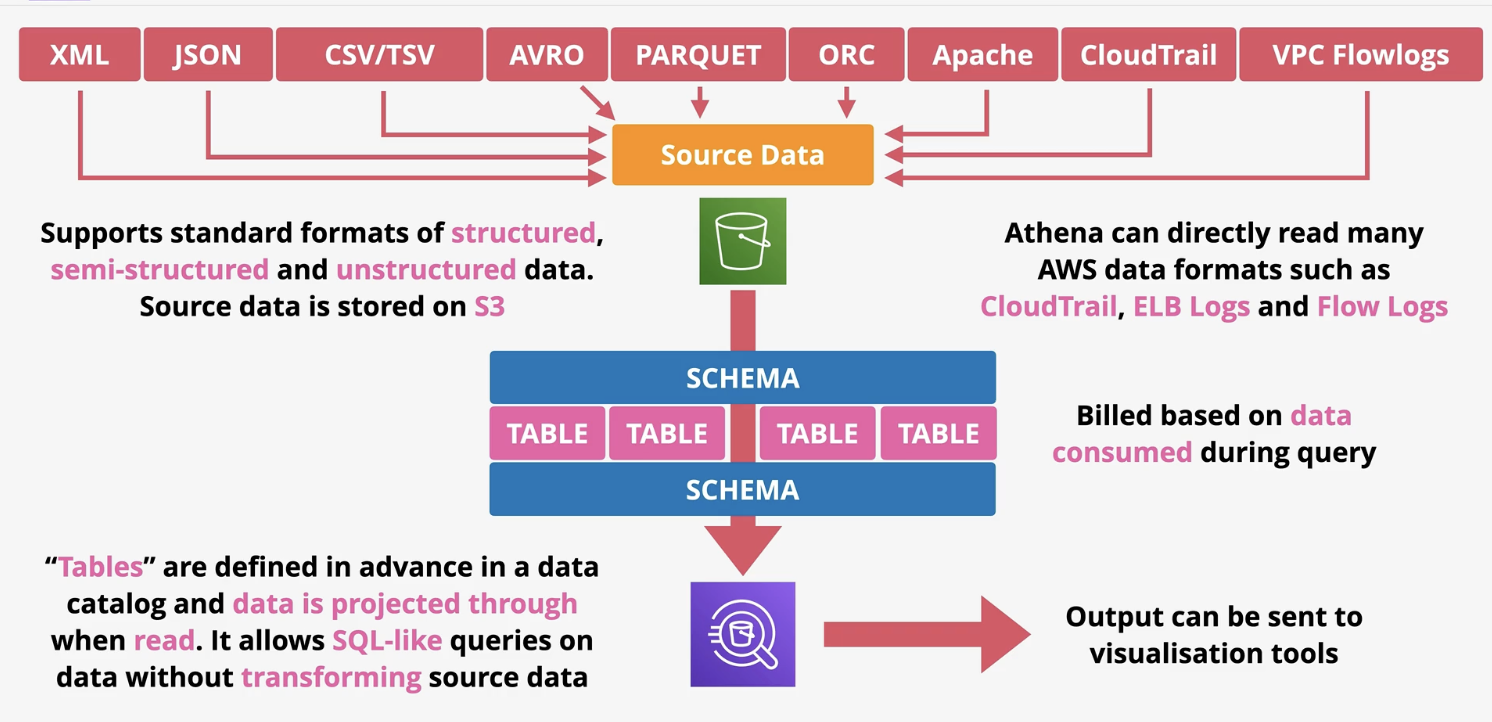
serverless interactive query service. Allows you to preform ad-hoc queries on data- pay only for data consumed. Athena uses schema on read-> data stored on S3 never changes, the schema translates the data into a table like structure (relational like when read). Output can be sent to other AWS service.
You have the source data then you define the schema (which the tables). It’s how you want to take source table and convert them to a table.
Athena key points
Athena has no infrastructure- no need to load data in advance. Best if you dont want to load/transform data.
Best for occasional queries on data in S3
Great if cost conscious- and serverless quiering scenarios
Best or query of AWS logs (VPC flow logs, cloud trail, ELB logs, cost reports, etc)
Can also query data from aws glue data catalog and web server logs
feature: Athena federated query- data source connector (code that translates between large data source that isn’t S3 and Athena)
ElastiCache
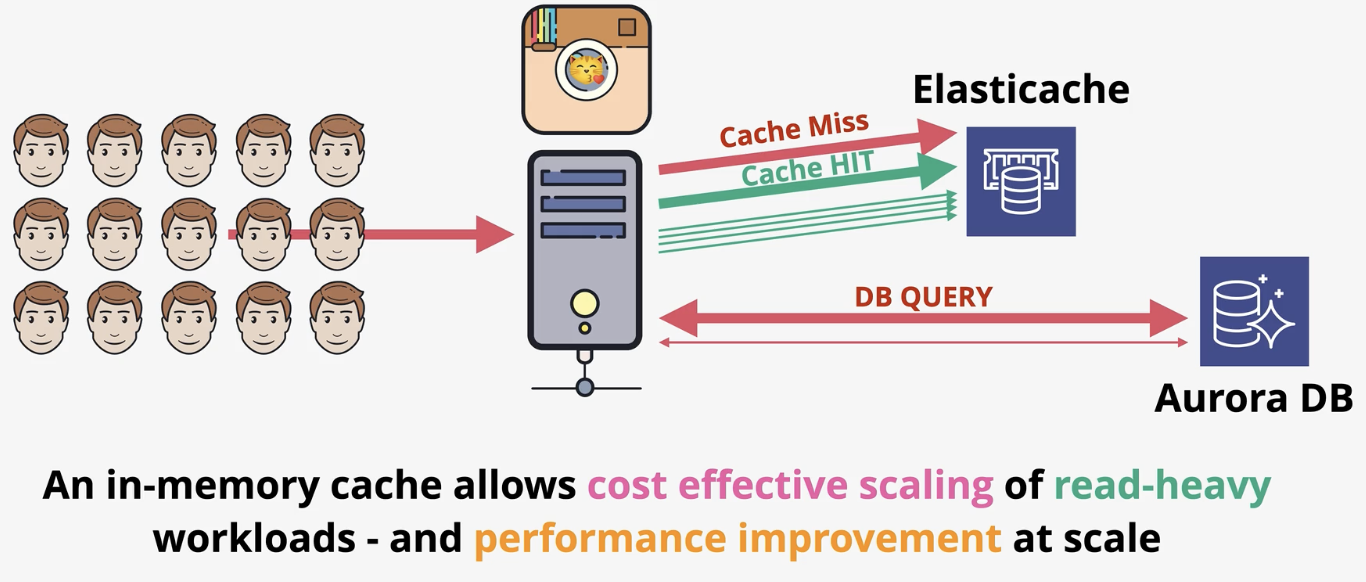
in memory database for apps that tree high performance. ElastiCache delivers managed Redis or Memcache as a service. Can be used to cache data for read heavy workloads with low latency requirements reduces database workloads (expensive). Can also be used to store session data (stateless servers). Using ElastiCache means you need to make changes to application code! Must know to check/write to cache (NOT FREE).
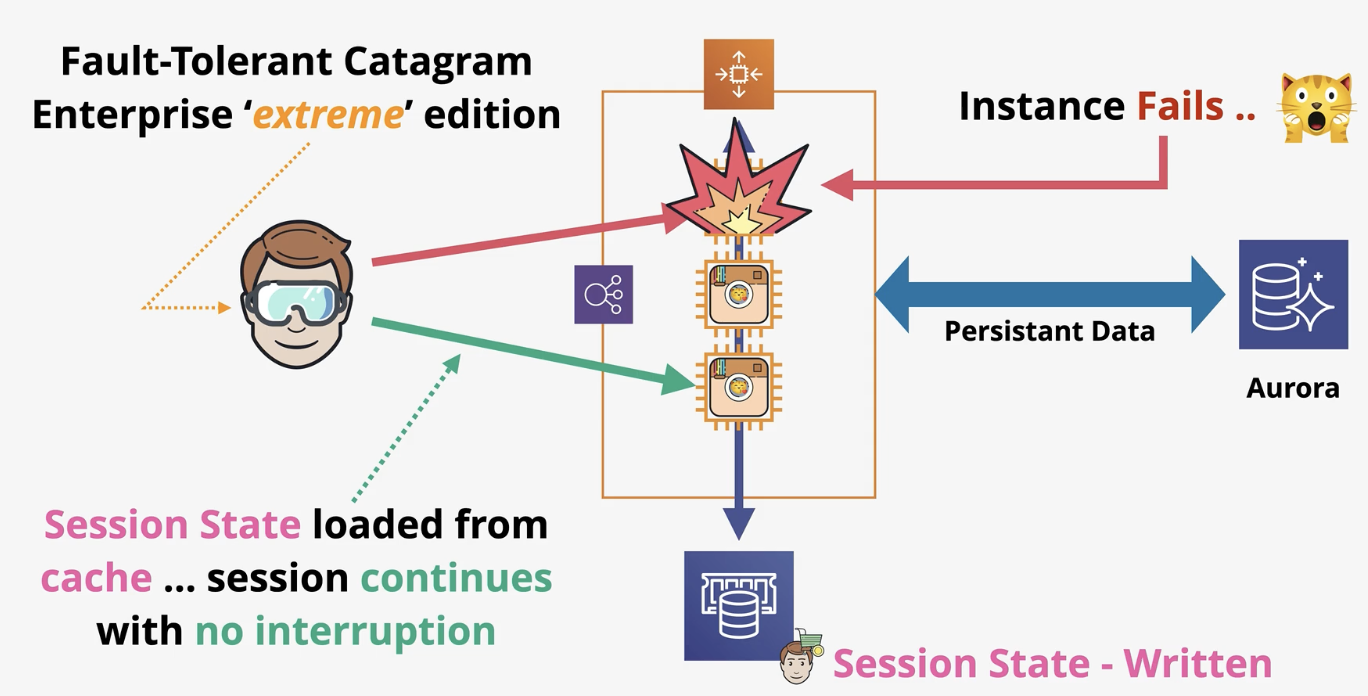
ElastiCache- session state data
if connected to an instance, session state is written to the instance. ElastiCache also ensures that the session state stays up to date, so if the connection is moved to another instance, the session data is maintained (stateless!!)
ElastiCache- Engines
both offer sub-millisecond access to data, both support many programming languages
Memcached:
simple data structures
No replication
Mulitple nodes (shading)
No backups
Multi threaded (better performance)
Redis:
advanced structures (can help sore ordered data)
Multi AZ
Replication (scale reads)
Backup and restore
Transactions (can allow all or none to work)
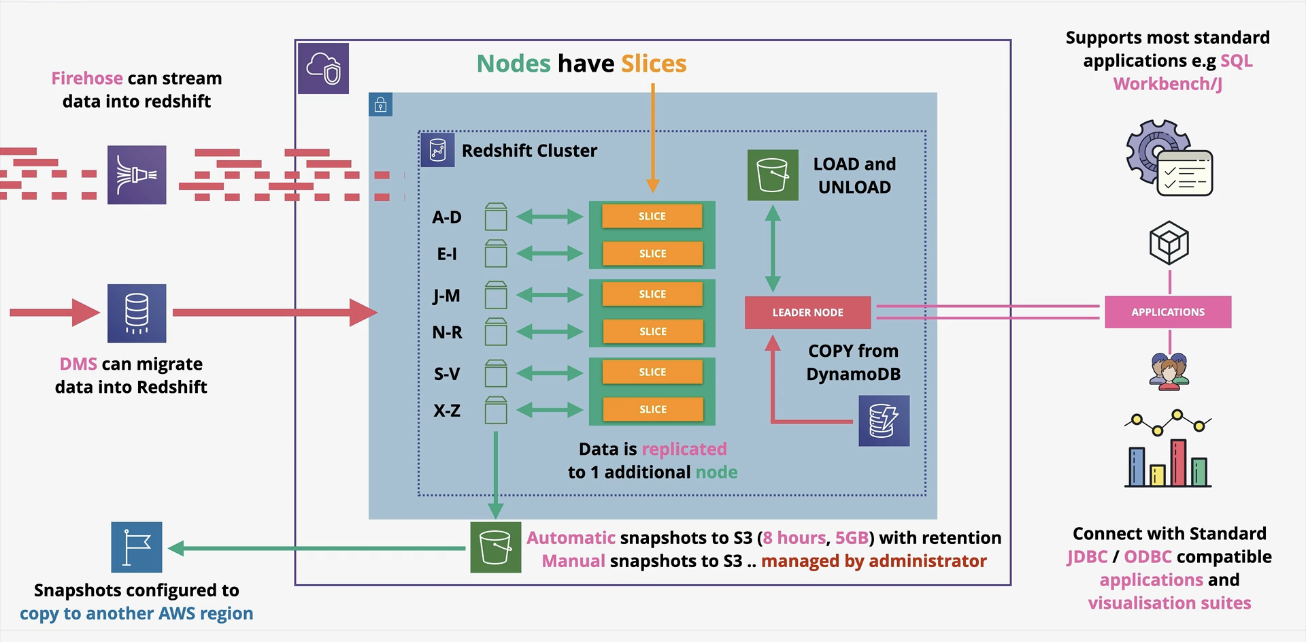
Amazon Redshift architecture:
petabyte scale data warehouse (where you can pump data from databases across you business into here for analysis). It’s an OLAP (column based) not OLTP (row/transaction). Redshift is pay as you go similar to RDS.
Can be used to query S3 using redshift spectrum
Can directly query other DBs using federation query
Integrates with AWS tooling such as quick sight
SQL like interface JDBC/ODBS connections
Amazon Redshift architecture
Server based, not serverless (unlike Athena)
NOT used ad hoc like Athena since it needs provisioning
Redshift cluster runs with nodes privately, in one AZ. There is a leader node where query input, planning and aggregation, compute node perfumes querying of data.
Since it is a VPC service, you can manage it as such: VPC security, IAM permissions, KMS at rest encryption, CS monitoring
feature: Redshift enhance VPC routing-VPC networking
By default it takes public routing but using enhanced VPC routing you can configure specific VPC routing. - customizable networking
Redshift resilience and recovery
we know Redshift runs in one AZ. There are some recovery features
Can take backups. Can be automatic incremental which occurs every 8 hours (anything changed is added to an S3, retention for 1-35 days) can also have manual backups (you manage deletion). Snapshots can be backed up to other AZ (multi AZ) and can also be sued to configure the data in another region if needed