CS3002 - Artificial Intelligence
1/119
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
120 Terms
Turing Test
One method of determining the strength of artificial intelligence, in which a human tries to decide if the intelligence at the other end of a text chat is human. An intelligence test to see whether the machine's true identity can be deceived. Also called the imitation game! No AI as genuinely passed the test.
Its a 3 way player 'game' where there is a interrogator and two player one of which is an AI that is trying to deceive the interrogator into thinking it is human.
What is a chatbot?
It is a computer program/ software that uses AI to simulate an online conversation with the a human user. An early example is ELIZA.
Who is ELIZA ?
An AI computer program "chatbot" created in 1950 that tried to simulate a psychiatrist. Used "pattern matching" to respond to the human user.
What has been easy and what has been hard in AI?
EASY: pattern recognition, reasoning & reading, sensing & responding, physical & responsive, learning logic & game playing. EG boston dynamics, face recognition, IBM ATSON gameshow 'jeopardy', alphaGO, DEEPBLUE.
HARD: creativity, limits of learning (learning to write eg. harry potter and learning to recognise e.g. an original image of a cat vs the 'hacked' image of cat), nothing has passed the turing test, Google's self-driving car and finally language.
Connectionism
an approach in the field of cognitive science that hopes to explain mental phenomena using artificial neural networks (ANN). Lesion studies showed recovery of damaged brains. It showed how -distributed processing can exhibit graceful degradation. It has the ability to adapt & generalise. This approach helped assimilate new info.
What are the classes of learning? and give examples of each.
• unsupervised : (clustering/ PCA (dimensionality reduction/ association rules)
• supervised (classification / regression)
• reinforcement learning (neural networks)
Define unsupervised learning and give examples
learning without the desired output. An algorithm explains relationships without an outcome target variable to guide the process. Looks for patterns in unstructured data.
e.g. dimensionality reduction (PCA), association rules/ recommender systems, CLUSTERING
Define supervised learning and give examples
learning with the desired output i.e. teacher signals. Training an AI system using a huge number of examples, the algorithm learns how to predict or classify an outcome variable of interest.
e.g. CLASSIFICATION, regression.
Define reinforcement learning and give examples
learning association : perform an action then learn based on a reward or punishment.
e.g. neural networks
Define clustering
to partition a data set into subsets (clusters), so that the data in each subset share some common trait - often similarity or proximity for some defined distance measure./ the process of organising objects into groups whose members are similar in some way.
Define a cluster
a collection of objects which are "similar" between them and are "dissimilar" to the objects belonging to other clusters
What are the different uses of CLUSTERING?
• Social networks: Marketing, Terror networks, Allocation of resources in a company / university
• Customer Segmentation -> advertisement
• Gene networks (Understanding gene interactions and then identifying important genes linked to disease)
Euclidean distance
the straight-line distance between two points.
√(x-y)^2 + ...(x_n-y_n)^2
the shorter the distance, the more similar the two patterns.
Name a few pattern similarity/ distance metrics. How to choose?
• euclidean
• correlation
• manhattan (|x-y|+ ...|x_n -y_n|
Often application dependant and it depends on what is important(shape/ distance/ scale)
K-means clustering algorithm
1. Place K points (initial cluster centroids) into the feature space.
2. Assign each pattern (data point) to the closest cluster centroid using a distance metric.
3. When all objects have been assigned, recalculate the positions of the K centroids. (this is done by calculating the mean of all the data points assigned to the cluster).
4. Repeat Steps 2 and 3 until the assignments do not change.
K-means discussions/ problems
1. How to determine k, the number of clusters? 2. Any alternative ways of choosing the initial cluster centroids? 3. Does the algorithm converge to the same results with different selections of initial cluster centroids? If not, what should we do in practice? 4. Intuitively, what is the ideal partition of the following problem? Can K-means Clustering algorithm give a satisfactory answer to this problem?
Pros and Cons of KM
PROS:
•simple,
•works well for globular data and therefore can produce tighter clusters,
•computationally fast (if k value is small enough).
•nondeterministic, objects/data can be reassigned to a different cluster
CONS:
•fixed number of initial clusters means its difficult to predict K
• the initial centroids (location) has a large impact on the final cluster (result not repeatedly replicable)
•potentially end up with empty clusters
•not good for elongated data
•hard assignment of labels
Hierarchical Agglomerative Clustering (HAC)
1) each data point is assigned to its own cluster (i.e. n cluster of 1 item)
2)let the distance between the clusters equal the distances between the objects they contain
3) find the closest two data points (clusters) and merge into one cluster (one less cluster)
4) recompute the distance between new cluster and each of the old (single, complete, average linkage)
5) repeat steps 3+4 till only one cluster left (series of merges)
•results in a tree like structure called a dendrogram
What are the types of linkage?
•single (looks at distance between two closest data points)
•complete (looks at the further two data points)
•average (average distance between all pairs in the two clusters).
Pros and Cons of HAC
Hierarchical Agglomerative Clustering
PROS:
•the resultant dendrogram is a good visual tool (data display) for understanding the structure/ shape of the data.
•Size of the cluster can be controlled i.e. smaller clusters can be generated
CONS:
•different linkage forms different outcomes (major impact!)
•deterministic i.e. no relocation of objects that have been incorrectly grouped at an early stage this means its not possible to "re-cluster"
•hard assignment of labels
Name the various clustering methods
•HAC (hierarchical agglomerative clustering)
•K-means
•fuzzy c-means
•DBSCAN
What is DBSCAN?
method for density-based clustering i.e. image or spatial data, good for elongated clusters.
There is a core point (interior of a cluster) which must have at least minPts within a radius (Eps).
Two points are considered neighbours if the distance between them are ≤ Eps.
minPts = min number of data points to define a cluster.
border point = if it is reachable from a core point + there are less than the minPts.
the points form a chain: p<- p2 <- p1 <-q: if p is directly density reachable from p2 and if p1 is directly density reachable from p1 and so on.
What is Fuzzy C Means?
Classifier where each point has a degree of
belonging to clusters (fuzzy logic) rather than belonging completely to just one cluster. In real applications often no sharp boundary ---> no hard assignment of cluster between clusters. i.e. a data point which sits in-between two clusters.
Cluster membership = 0
How do we evaluate cluster quality?
•cohesion = tightness of data points in a cluster
•separation = how far apart data points in two different clusters are.
•comparing clusters: Weight-Kappa Metrics (ranges -1 to 1) which measures how similar two clustering arrangement are thus if a method produces similar clustering arrangements then the method is consistent.
Association Rules
AKA basket data.
Association rules specify a relation between attributes that appears more frequently than expected if the attributes were independent. Descriptive; discovers links or associations amongst data.
support, confidence & lift
support = freq(x,y)/ N
confidence = freq(x,y)/ freq(x)
lift = support/ sup(x).sup(y)
Classifier
A machine learning model that provides classification to a data input.
Define classification and name two classification algorithm
Given some data, take each case that has been allocated a class and learn a mapping from the data to the class. When new data is introduced that hasn't been assigned a class, the class can be predicted.
for e.g. given 10 cases with 2 variables, a scatter can be plot and then colour code the classes. When two new cases are introduced, predict their class.
•decision tree
•k-nearest neighbour
Importance of understanding the mapping between the supervised learning model and the data space that it is splitting up
Decision Tree
AKA rules induction
nodes = decision
arcs = possible answers
terminal nodes = classification
•traverse starting at the root node (which is at the top)
•follow appropriate branch
•repeat until leaf node
•leaf node = classification
e.g. for a scatter plot, the cuts (i.e. the branches = decision boundary) are always orthogonal to the axis.
Building a Decision Tree
•nodes are repeatedly split until all elements represented belong to one class.
•the nodes then become the terminal nodes
•deciding which node to split next + the evaluation function used to split depends on the algorithm
ID3 algorithm
•most well known and widely used algorithm for building decision trees
A <-attribute that best classifies examples=>entropy
Assign A as decision attribute for node
For each value of A create descendent of node
Sort training examples to leaves
If examples perfectly classified stop
else iterate over leaves
•recursive
Shannon entropy
Used to decide which attribute best classifies an example. Captures, compresses and removes uncertainty. Higher entropy, less uncertainty like the score on the scrabble tile.
-Σp_j log(p)_j
What wrong with a complex model?
Too niche, overfitting to a specific data set. When a model "memorises" noise/features + fits too closely to its training set. Overly complex. Thus won't be able to correctly perform tasks to new data.
What is an overfit model?
When a model "memorises" noise/features + fits too closely to its training set. Overly complex. Thus won't be able to correctly perform tasks to new data.
What is pruning of decision trees?
•simplifies the model therefore prevents overfitting
•occam's razor
•goes through each decision node and considers converting it into a leaf node (pruning) if it does not reduce classification accuracy.
K-Nearest Neighbor (KNN)
Classification technique that does not model data.
•distance metric
•k parameter (no. of neighbours)
•weighting function
•how to combine the info from the neighbours
•case-based reasoning
How to test the performance of the ML models created by KNN or DT?
Error rate = no. of errors/ no. of classes
error calculated from test set = empirical error, this is based on the sample of the data so it may be biased
"TRUE" error rate = based on infinite cases therefore must be estimated.
This leads onto a confusion matrix which is used when errors are of differing importance.
What is the holdout method?
The method of splitting the data into training set (learn the model) and test set (score accuracy).
Ideally the two sets are independent otherwise the data must be resampled.
What if the data set used in the holdout method is not independent?
Resample the data via cross-validation or bootstrapping.
What is resampling?
A method of drawing samples up, so that we get a more accurate / closer to the true error rate. Randomly select training and test sets in different ways.
Most common methods are bootstrapping and cross-validation.
Describe cross validation.
It is a resampling method that is considered an unbiased estimate of the true error rate.
•randomly split dataset into k sets of equal size.
•remove 1 subset, train on remaining subsets
•test on removed subset
•repeat for all subsets
•average/ variance calculated
The result is an assessment of the modelling technique.
This creates multiple models however there are different ways of combining/ collapsing them down into one.
Bootstrapping
It is a resampling method that produces worse-case rates rather than true error rate.
•random sampling of items from data with replacement (repeatedly) -> training set
•anything that is not sampled will become the test set.
•this process is repeated several times and each one is called a "bootstrap".
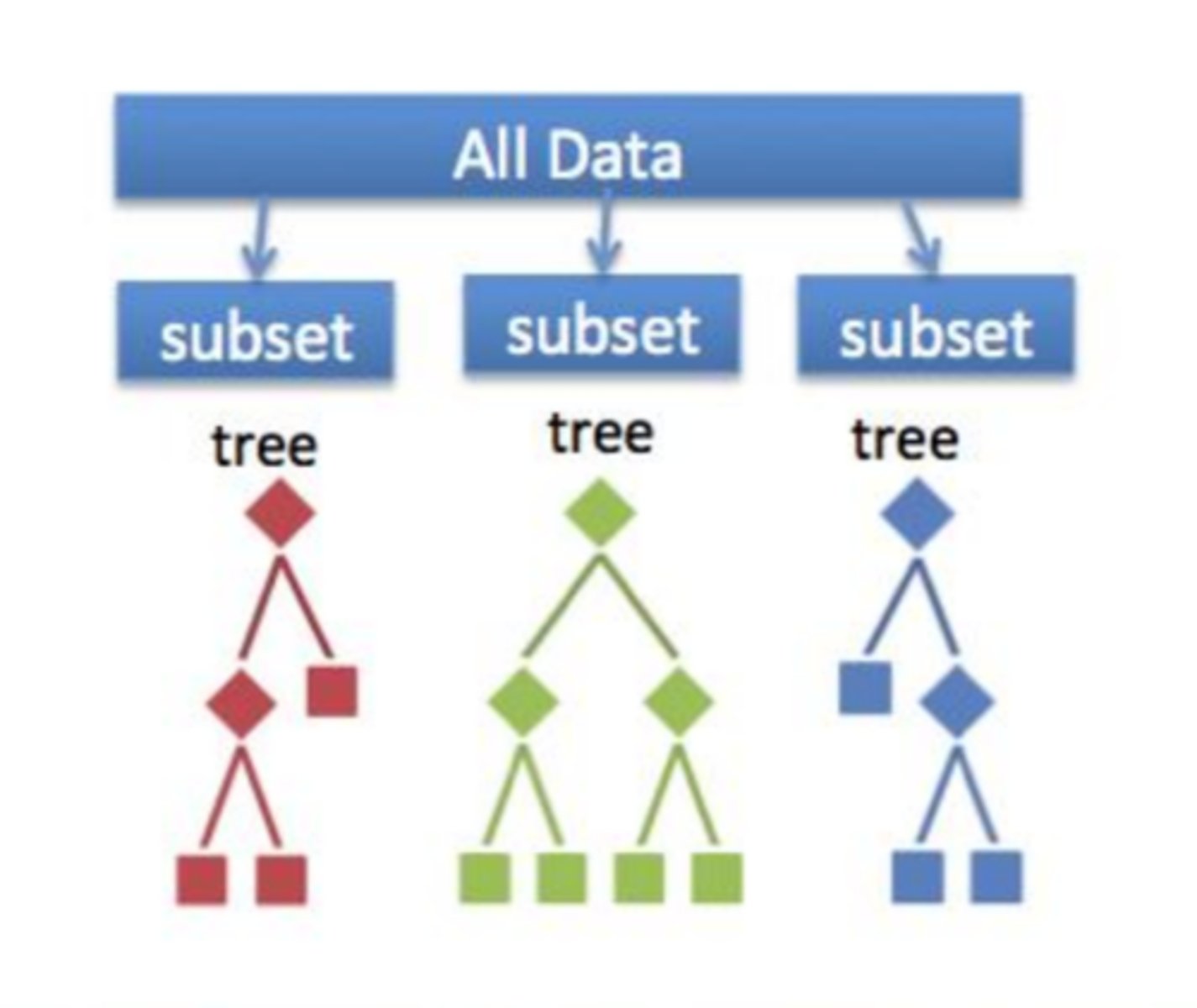
What is a random forest?
It is a mixture of decision tree + resampling and is considered one of the best AI techniques apart from DL and neural networks.
This method builds decision trees on different samples and then uses a voting mechanism to decide the best classification.
What is a confusion matrix?
To identify how well a classifier or a ML model performs when the errors are of differing importance. For e.g. failing to diagnose a disease is worse than diagnosing one that doesn't exist (a false neg vs a false pos)
A confusion matrix compares the class vs prediction and false positive/ negatives.
It allows you to calculate the sensitivity + specificity. And precision + recall.
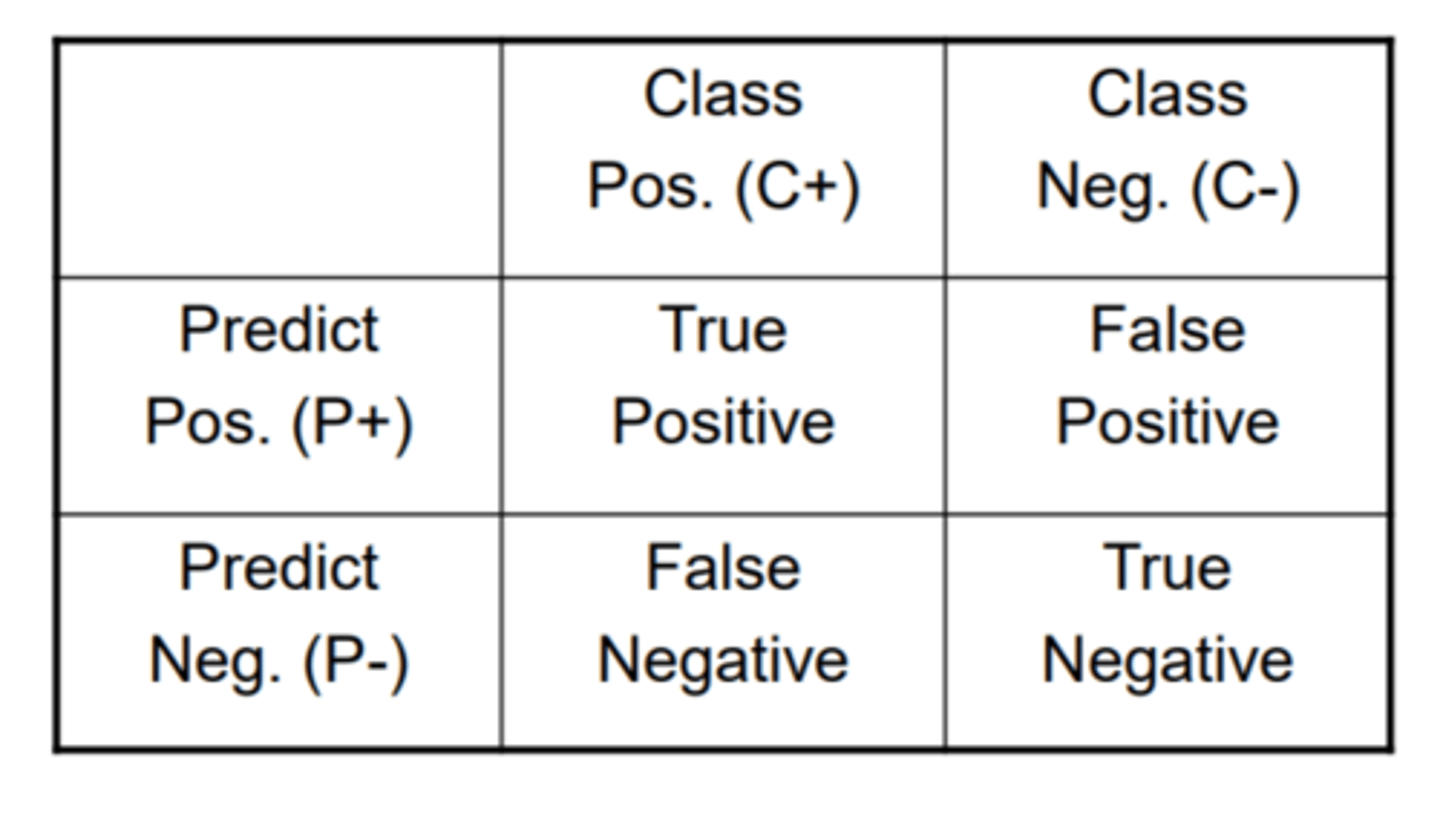
What is sensitivity? specificity?
sensitivity: TP / C+
specificity: TN/ C-
What is accuracy?
(TP + TN) / ( C+ + C-)
What is precision and recall?
recall is the same as sensitivity: TP / C+
precision: TP / (TP +FP)
•good for imbalanced data eg few ill people out of many.
ROC Curves vs PR Curves
ROC: receiver operating characteristic curve --> Sensitivity / Specificity tradeoff (TP/C+ vs TN/C- )
top left corner = best
PR: precision recall curves --> Precision / Recall tradeoff TP/C+ vs. TP / (TP+FN)
larger area under curve = best
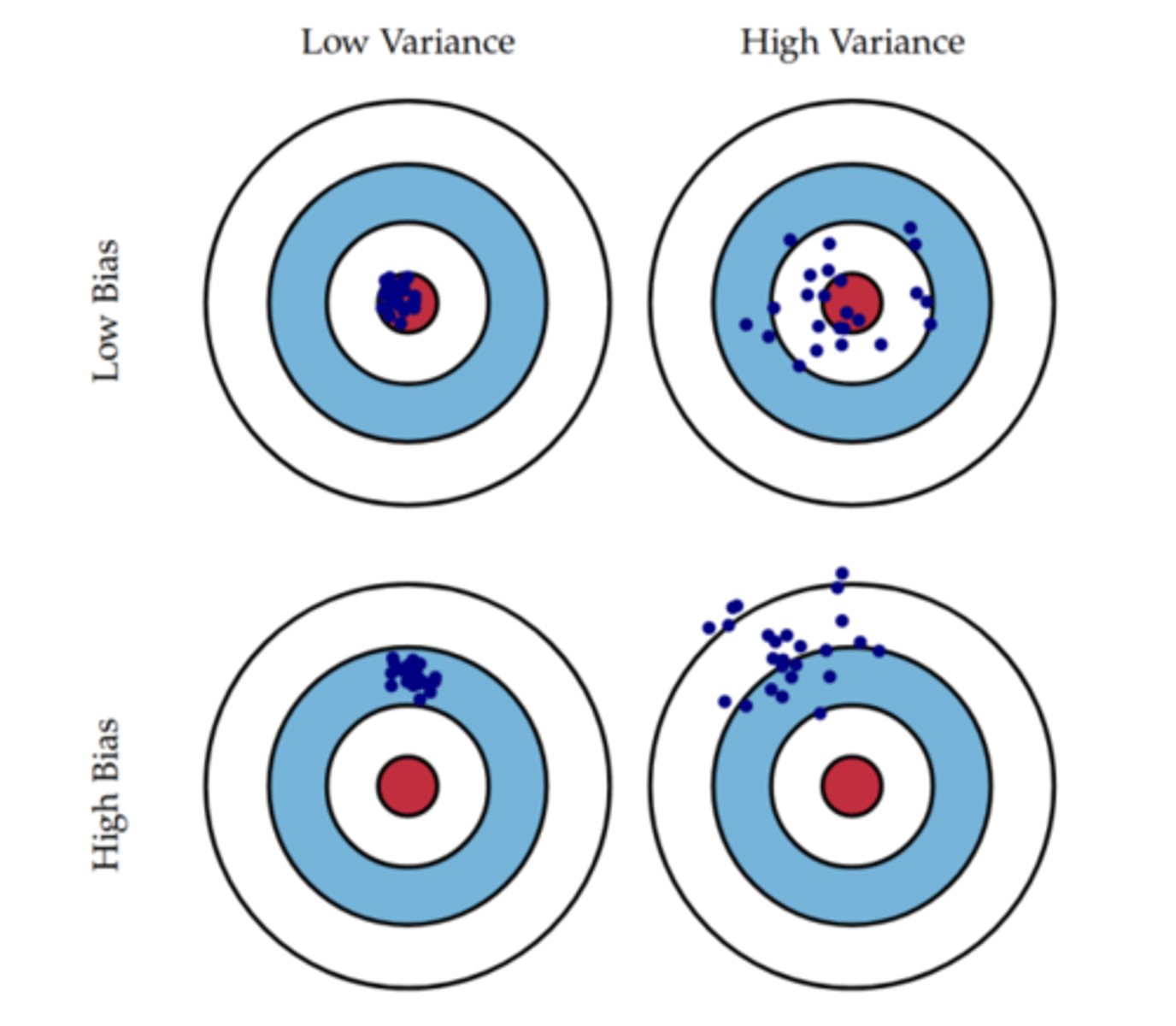
Define Overfitting, Bias and Variance
overfitting = too complex and niche. Model that fits too closely to data including irrelevant features or noise due to too many parameters.
bias = systematic error in the model i.e. decision trees are biased as they can only model orthogonal cuts through the data
variance = the difference from one model to the next (if resampled and model built again, how different would it be?)
the balance between bias and variance for a model is important and they both are kind of measuring overfitting in some ways.
Explain how the variance and bias impacts a model?
high bias, low variance -- > most dangerous as looks like there should be faith in the model.
low bias, low variance --> best
high bias, high variance --> worst
Pros and Cons DT vs KNN
DT:
•easy to interpret
•prone to overfit but can be pruned.
•biased as only can model data orthogonal cuts through the data
•discrete+ continuous data can be modelled
KNN: easy to interpret, does not model data, -difficult to pick correct value of K.
What is the simplest neural network?
perceptron, it is a single processing unit that takes in inputs and uses a transfer/ activation function which computes an activation value which is there evaluated using a threshold function: sign function.
+1 if value >0. -1 if otherwise.
Will a simple neuron network always converge to a solution?
Only if it is linearly separable.
But may take a long time, therefore
•normalise data
•use a learning rate to control the weight changes.
What are the other threshold functions used in a neural network?
classification:
•step function 0
What is the activation function for forward propagation of a neural network?
Σxᵢwᵢ + θ
Where x is the input, w is the weight and θ is the bias.
What is epoch?
It is a single pass through the data.
What is the error correcting procedure in forward propagation for a perceptron?
wᵢ(p+1) = wᵢ(p) - Δwᵢ(p)
θᵢ(p+1) = θᵢ(p) - Δθᵢ(p)
Where Δwᵢ(p) = (Yᵈ - Y) xᵢ
Δθᵢ(p) = (Yᵈ - Y)
Yᵈ = true / correct answer
Y= perceptron output
What type of problem fails in a single perceptron neural network?
Non-linearly classifiable problems such as the XOR gate which requires a multineural network.
What is MNN?
It is multineural network which consists of input layer, hidden layer of multiple perceptrons (processing units) and output layer. The nodes are fully connected i.e. one layer fully connected to next layer. Results in many optima unlike the single perceptron.
What is back propagation?
It is a learning procedure that allows you to adjust the weights in multi-layer networks to train them to respond correctly.
•same as forward to begin (random assignment of value to weights)
•input propagated to output with an activation function + threshold function
•sigmoid function used
•error derivative vector propagated backwards to update the weight change
•learning rate to scale the adjustment to ensure prevention of largely cyclic behaviour of weight change
What are the application of a neural network?
•classification
•forecasting
•tracking?
•image recognition
•natural language processing
•ATARI SPACE INVADERS
What is knowledge?
it is the theoretical or practical understanding of a subject or a domain.
Who are experts?
They possess theoretical or practical understanding of a subject or domain i.e. knowledge.
What is an expert system?
A computer software package that is designed to assist humans in situations in which an expert in a specific area (controlled domain) is required.
What are the two methods for representing knowledge?
1)Programming language: procedural + declarative knowledge - facts
2) production rules (if/then) - rules based system
When is a rule fired?
When the antecedent (condition) is met and then the action (consequence) part is fired.
What are the 3 major tasks of an expert system?
1)Gather knowledge from an expert
2)express knowledge as a collection of rules (knowledge base) i.e. expertise encoded in production rules.
3)extract conclusion (reasoning)
What is a knowledge base?
A se of rules describing knowledge of a specific domain.
What is an inference engine?
The engine carries out the reasoning whereby the expert system reaches a solution. Links/matches the rules given in the knowledge base to the fact given in the database.
What is the reasoning of an inference engine?
The reasoning is a mechanise for selecting the relevant facts and extracting conclusions from them.
What is the basic structure of a rule-based expert system?
What is the match-fire procedure in expert systems?
IT compares the antecedent part of the rule with any facts in the database until it finds a match, if it finds a match then the consequence part of the rule is fired. Then it will add the new fact/info inferred into the database. This creates an inference chain which indicates how an expert system applies rules to reach a conclusion.
What is an inference chain in an expert system?
It is a chain of inferences inferred by the match fire procedure which indicates how an expert system applies rules to reach a conclusion.
What are the two goals of an expert system and how are they achieved?
1)data driven reasoning (forward chaining)
2)goal driven reasoning (backward chaining)
What is forward chaining in an expert system?
It is a data-driven reasoning technique where the reasoning starts with known data and proceeds forward, explores + gathers all possible info and inferring from it. It executes with the top-most goal, adds new fact to database. Each rule can only be executed once and the match-fire procedure terminates once there are no more rules to be fired. This technique fires many rules that may not have anything to do with the established goal thus if the goal is to infer 1 fact, this technique is inefficient.
What is backward chaining of an expert system?
It is a goal driven reasoning technique which the inference engine finds the evidence to prove the goal. 1)First, knowledge base is searched to find the rule with the desired goal whereby the rule would have the goal in the action (consequence) part. If found then and the antecedent part matches the data/fact in database then the rule is fired.
2)If not, the inference engine stacks this rule and sets up new goal, sub-goal to prove the antecedent (if) part of this rule.
3)This process is repeated continuously including the stacking until no rules can be found to prove the current sub-goal.
How to choose which type of reasoning (backward or forward chaining) is appropriate for the expert system?
1) if an expert needs to gather information and infer as much as possible then forward chaining is appropriate.
2) If the expert has a hypothetical solution which it attempts to prove then it should choose backward chaining.
What is conflict resolution of an expert system?
It is the method of choosing which rule to fire when there are two rules with the same antecedent but different consequence. (in forward chaining the topmost rule is fired first)
1) fire rule with highest priority
2)fire the most specific, complex rule as the assumption is that is possesses more info.
3)fire rule that was most recently entered into the knowledge base (this is because expert system are not refactored but instead adds new rules which overrides previous rules like our law system)
This is also known as metaknowledge.
What is metaknowledge of an expert system?
It is the knowledge about the USE and CONTROL of domain knowledge in an expert system
These consist of metarules:
1)expert knowledge supplied rules > novice knowledge supplied rules
2)rules governing the rescue of human lives have higher priority that rules concerning the clearing overloads on power system equipment.
What are the 3 rules of robotics imposed by Issac Asimov?
1)robot may not injure human
2)robot must obey human
3)robot must protect it's own existence
but each of the above rules must over rides the rule below it i.e. top rule overrides all below rules.
Pros of an expert system?
Cons of expert system?
Example of an expert system?
Mycin which helps identify bacteria causing severe infections. This systems assists physicians/ clinicians in making life and death decisions (of the diagnosis and therapy selection) by using inference.
What is a black box model?
It is the box between input and output that is unknown, the internal behaviour of the code is unknown as it is too complex/ difficult for us to understand: huge no. of parameters.
Do we care about opening black box model?
one argument: any ML AI algorithm must explain how it is made it's decision.
Opposing argument: Geoff Hinton "is this a 2" argument is that if ourselves are not very good at explaining, even our own experts cannot explain why should we care that an AI cannot explain itself?
What new law came into power in 2018 regarding opening the black box?
A GDPR law which states our right to explanation + possible human intervention when a decision has been made though automated processing.
Why must we know the underlying mechanism of the black box?
•gain insight
•gain trust
•make better decisions/ interventions
What is a BN?
They model some sort of underlying causal relationships within data in a transparent way using networks. It is a method to store joint distribution, defined as a directed acyclic graph with local conditional dependencies. Evidence can be inferred using any node. inference can be used to determine the probability distribution of the other nodes given the observed evidence.
event?
outcome?
true event probability?
false event probability?
Event = x, an action which results in various possible outcomes.
p(x=outcome)
true event probability p(x)=1
false event probability p(x)=0
What is conditional probability?
Two events that are dependent on each other.
P(B|A) = P(A n B)/ P(A)
What is Naive Bayes' rule?
P(B|A)= P(A|B)P(B) / P(A)
What is the Monty Hall problem?
given 3 doors, a prize is behind 1 door, you pick a door and another door with a goat is revealed. Do you stick with your door or change choice? --> apparently higher probability of receiving prize if you change choice
What is a probability distribution?
A distribution of all outcomes of one event/ variable which sums to 1.
What is a joint probability?
n-dimensional table with a probability in each cell of that state occurring. Would be written as P(X1,X2, X3,...Xn).
How to retrieve probabilities from the conditional distributions?
P(x1,x2,...,xn) = πP(x_i | Parents(x_i)
What must be checked before inference is applied to a Bayesian network?
Identify which nodes are independent through D-Separation.
Then no need to apply inference on all those independent nodes.
What is D-separation?
It models conditional independence. E=very undirected path from x to y is d-separated from E, then P(XnY|E) = 0.
A path is blocked given a set of nodes, E if:
1) Z is in E and has 1 arrow in going and 1 going out.
2) Z is in E and has both arrows going out
3) Z is not in E, nor any descendants of Z are in E AND both arrows leading in.
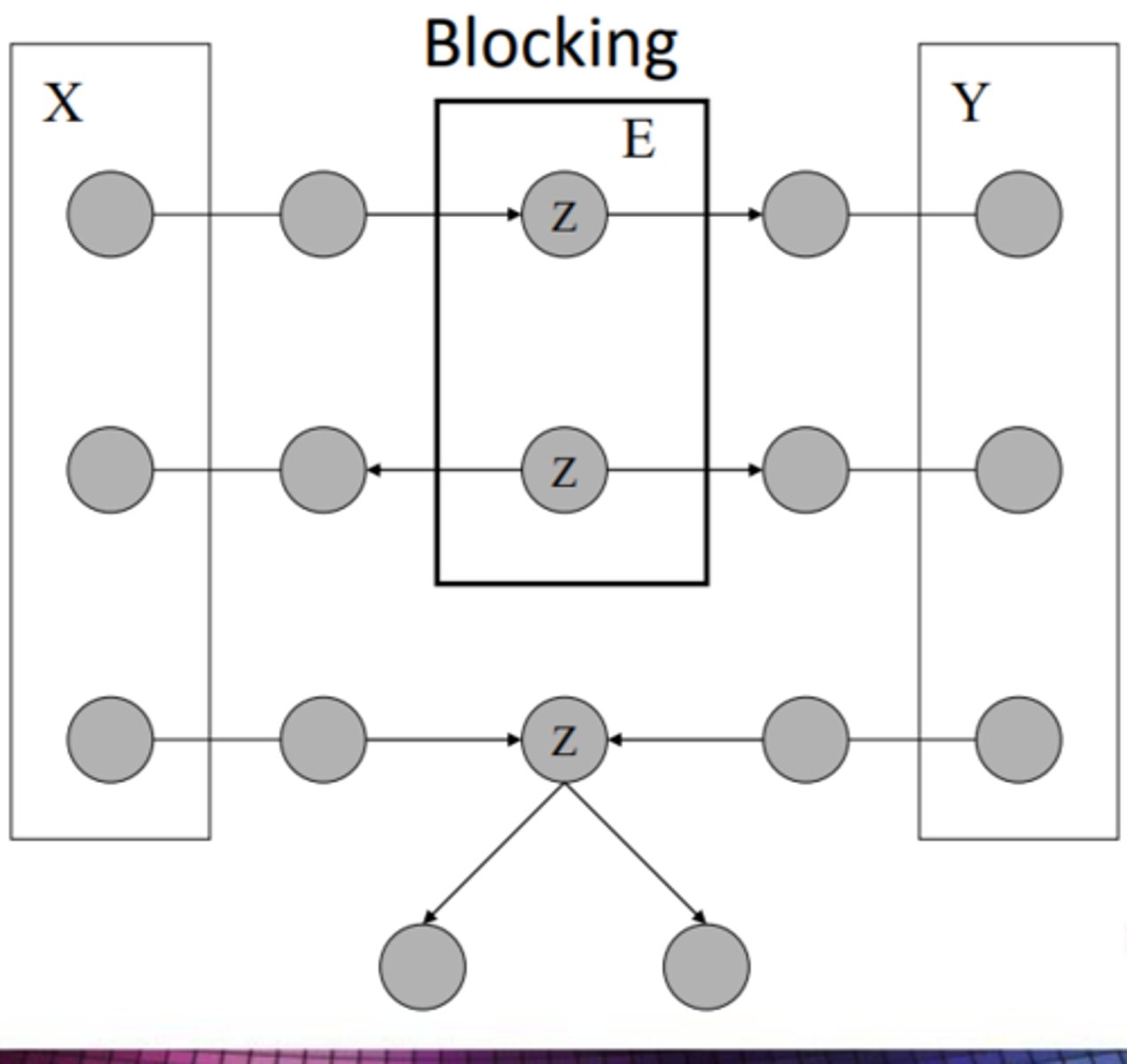
What is a Markov Blanket?
node = x_i. It is the set of nodes: all parents of Xi, children of xi, parents of the children of xi. This renders all other nodes independent of xi.
What is the point of d-separation / markov blankets?
They models conditional independence which allows efficient inference which can be used to determine the probability distribution over the remaining nodes given the observed evidence.
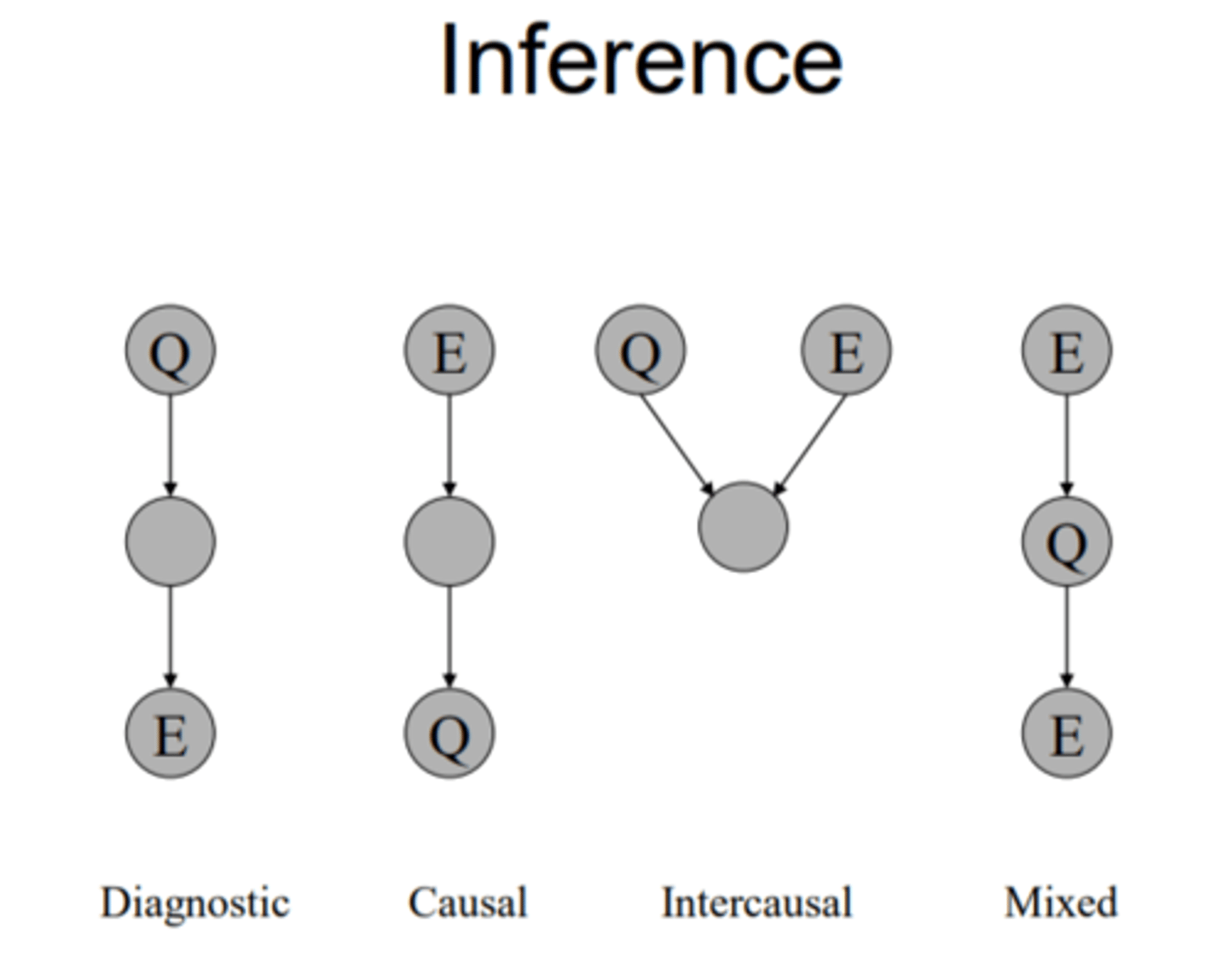
it allows us to inference:
1)diagnostic
2)causal
3)intercausal (explaining way) (if Z is unobserved)
4) mixed of all
How many layers required to tranform a NN into deep?
No universally agreed threshold. Earliest DL MNN had only 3 hidden layers?
What does the understanding of the markov blanket and d-separation allow us to do ?
They models conditional independence which allows efficient inference which can be used to determine the probability distribution over the remaining nodes given the observed evidence.
it allows us to inference:
1)diagnostic
2)causal
3)intercausal (explaining way) (if Z is unobserved)
4) mixed of all