DAT255 Lecture 5 - Optimizers and Learning Rates
1/13
Earn XP
Description and Tags
Flashcards about optimizers and learning rates in deep learning, based on lecture notes.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
14 Terms
What are the two conditions a loss function must satisfy?
Differentiable and bounded below (L >= 0).
For regression tasks, which loss function is primarily used in this course?
Mean squared error (MSE) loss.
For classification tasks, which loss function is primarily used?
Cross-entropy loss (or log loss).
In gradient descent, what does (η) represent?
The learning rate.
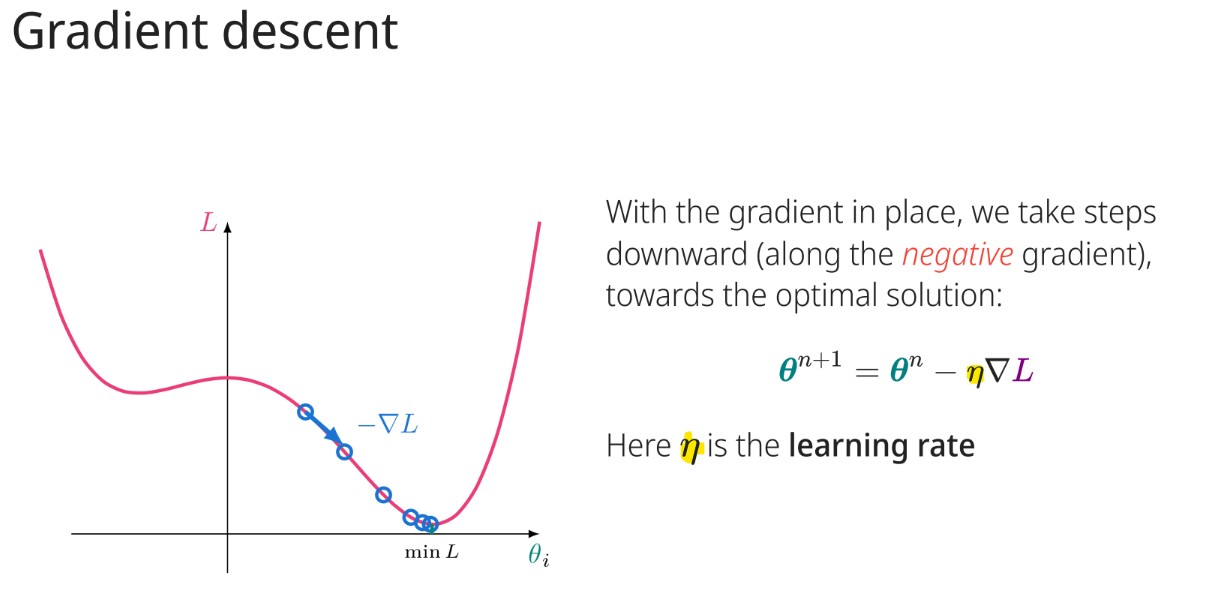
What is the primary strategy used in gradient descent to find the optimal solution?
Take steps downward (along the negative gradient).
What is a potential issue with local minima in the context of optimization?
They can lead to bad predictions.
What is the purpose of momentum optimization?
To improve on regular gradient descent by keeping track of past gradients.
What does the (β) hyperparameter represent in momentum optimization?
The momentum, which controls the amount of 'friction'.
What is the key feature of AdaGrad?
It introduces an adaptive learning rate, adjusted independently for different parameters.
How does AdaGrad adjust the learning rate for parameters with steep gradients?
It reduces the learning rate quickly.
How does RMSProp improve upon AdaGrad?
By exponentially scaling down old gradients before summing them.
What two optimization methods are combined in Adam?
Momentum and RMSProp.
What is a common issue that must be addressed for all optimization methods?
Choosing an appropriate learning rate.
Name one method of learning rate scheduling.
Reduce η when learning stops, gradually reduce η for each step, change η by some other rule.