Computer vision - The guide
1/16
Earn XP
Description and Tags
RUG Master's computer vision course. Contains (almost) all the questions/answers that frequently appear.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
17 Terms
Give two ways in which we can increase accuracy of a stereo set up
Increase the baseline b → cameras further apart → larger disparities → more precise depth estimates
Increase focal length f → more zoom → larger disparities → more precise depth estimates
z = (b * f) / p
What is the correspondence problem?
Given the same 3D point P, it project to point P_L in the left image and P_R in the right image, which P_R matches P_L
The key to successful shape-from-stereo is solving the correspondence problem. A common approach is feature-based correspondence. Describe the approach and give a practical example of features that could be used.
The correspondence problem is the problem of determining which point in the left image corresponds to a given point in the right image. The feature-based approach uses feature detectors to locate readily recognizable points, and tries to match up points in one image along the corresponding epipolar lines in the other. Features used in practice may be corners or edges, and also SIFT features.
Neither shape from shading nor shape from texture derive surface normals unambiguously from a single image. Which of these two methods offers tighter constraints on the surface normal and why?
Shape from shading constrains the normal to a cone around the light source direction (any normal with the correct angle to the light is consistent with the observed brightness). This leaves infinitely many possible normals.
Shape from texture, using the foreshortening of the texture pattern, constrains both the direction and magnitude of the surface gradient. The moment-based method reduces this to only two possible normals.
Therefore texture offers tighter constraints.
Assuming we observe the density Γ(u, v) you derived, and you were able to derive the surface normal at each point. What extra assumption would you need to make to reconstruct the surface (z values) itself (up to a constant distance)?
You would need to assume the surface was smooth, so you can iteratively derive a unique solution that explains the data. The smoothness constraint can be seen as a way to obtain the simplest surface that explains the observed texture.
Explain what the role is of each of the energy terms of the snake, and how changing them (e.g., setting them higher or lower) affects the outcome.
E_int (Internal energy) - Controls the tension and rigidity of the contour.
Increasing it will result in a straighter contour with less bending
Lowering it will result in a more flexible/elastic contour, allowing for sharper bends. The contour will be easily deformed by image forces.
E_img (Image energy) - Controls how much the snake is pulled to image features like edges. Makes edges in the image low-energy valleys, so the snake is pulled towards them.
Increasing it will result in the snake being pulled more strongly to any edges nearby, including weak or noisy ones. Leading to a less smooth contour that potentially overfits to noise
Decreasing it results in the E_internal dominating, so the snake shrinks, smooths out and most likely underfits.
E_con (external constraints) - User-defined or geometric rules on the snake’s shape and point distribution. Keeps points evenly spaced and prevents them from bunching up in high-image-energy areas. Also defines additional forces such as a balloon force that deflates or inflates the snake, and/or additional user-defined forces.
Increasing it strengthens even distribution of points
Decreasing it more free placement of points.
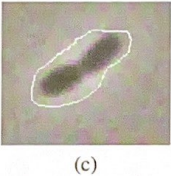
Snakes are sensitive to initialization. Consider the initializations shown in the figure. What kind of problems could be expected in this case, and can we add forces to the snake to counteract these problems?
Contour is initialized too loosely around the bacteria, leading to the local region E_image considers to potentially miss the bacteria edges.
Fix: Use a gaussian-blurred version of the image to compute E_image. This spreads the gradient field outwards, giving the snake a larger capture range.

Snakes are sensitive to initialization. Consider the initializations shown in the figure. What kind of problems could be expected in this case, and can we add forces to the snake to counteract these problems?
Snake initialized inside the object, with no changes the snake has no reason to expand outwards.
Fix: Add a balloon (inflation) force to E_con that pushes the snake outwards until it hits the edges.
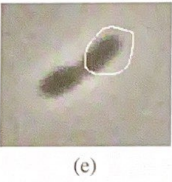
Snakes are sensitive to initialization. Consider the initializations shown in the figure. What kind of problems could be expected in this case, and can we add forces to the snake to counteract these problems?
Bad initial position (offset): The snake is too far off-center. E_int tension will drag the whole contour rather than helping it wrap around the shape.
Fix: There is no simple forces you can add to fix this, as snakes are fundamentally sensitive to initializing postion. The best solution is just better initialization
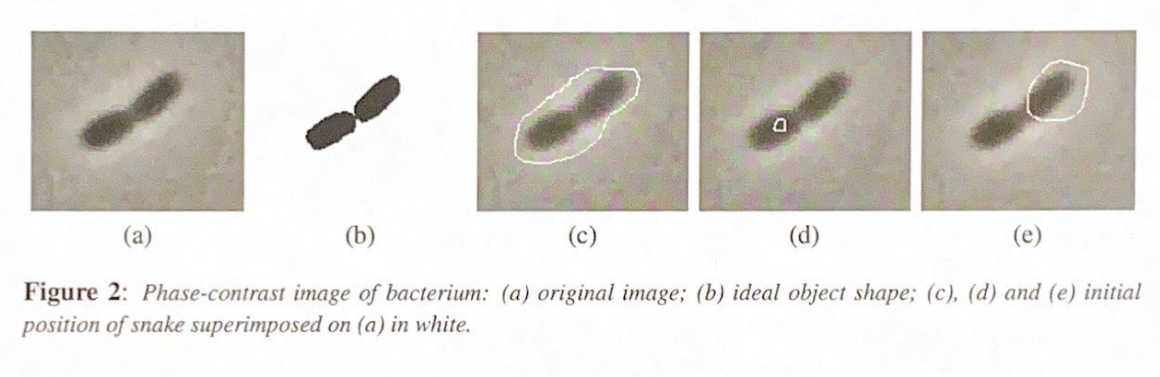
Suppose we do want to split the shape of the bacteria in two. What feature must we add to most standard snake algorithms to achieve this?
Standard snakes are a fixed-topology closed contour - they can not split. To split the bacterium in two, you need to add Topological adaptivity, making it a topologically adaptive snake. This allows the snake to split (and merge), which is not possible with a standard snake.
What is the aperture problem in optical flow?
When observing motion through a local region, you can only measure the component of motion perpendicular to an edge. Motion along the edge is invisible. This means the full 2D motion vector cannot be recovered from a single point.
What is the optical flow constraint equation and why is it insufficient?
\frac{\partial E}{\partial u}\dot{u} + \frac{\partial E}{\partial v}\dot{v} + \frac{\partial E}{\partial t} = 0
\frac{\partial E}{\partial u} — how much brightness changes as you move horizontally in the image (spatial gradient in u)
\frac{\partial E}{\partial v} — how much brightness changes as you move vertically in the image (spatial gradient in v)
\dot{u}, \dot{v} — the velocity of the point we're trying to find
\frac{\partial E}{\partial t} — how much brightness at this pixel changes over time
Intuitively: the equation says that the brightness change you observe over time (\frac{\partial E}{\partial t} ) must be fully explained by the spatial gradients multiplied by the velocity. If brightness is truly constant along the motion, these must balance to zero.
It gives 1 equation with 2 unknowns (\dot{u} and \dot{v}), so the motion field cannot be uniquely determined from this alone. The derivatives are estimated from the image.
How does Horn-Schunck solve the underdetermined optic flow problem, and what is its limitation?
It adds a smoothness constraint — assuming the motion field varies smoothly — as a penalty term in a minimization problem. Limitation: the smoothness assumption fails at motion boundaries, as seen in the translating square example where flow is only detected at edges, not in uniform regions.
When does Horn-Schunck's smoothness constraint fail to recover the full motion field?
When the image has no gradient in one direction (e.g. \frac{\partial E}{\partial u} = 0 ), that velocity component disappears from the constraint equation entirely. Adding smoothness does not help because any constant velocity trivially satisfies the smoothness constraint.
What does the function G do in Perona-Malik anisotropic diffusion?
G is a decreasing function of the image gradient. In flat regions (small gradient) G ≈ 1, so diffusion is strong. At edges (large gradient) G ≈ 0, so diffusion stops. This smooths noise while preserving edges, unlike Gaussian blurring which blurs everything equally.
Argue that the Perona-Malik anisotropic diffusion scale space is translation invariant
The PDE only depends on local image gradients, not on absolute position (x,y)(x, y) (x,y). Therefore shifting the image by any amount produces the same result — the scale space is translation invariant.
Is Perona-Malik anisotropic diffusion rotation invariant? Argue why
Yes. The PDE depends only on ||\text{grad} I||, the magnitude of the gradient. Rotation preserves vector magnitudes, so G is unchanged under image rotation — the scale space is rotation invariant