NLP B1-5.
1/41
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
42 Terms
Attention layer types
self-attention
cross-attention
Self-attention
The queries generated from the input are used to query the input iself: X = I.
Cross-attention
An external vector sequence is queried, e.g., in encoder-decoder transformer architectures a sequence created by an encoder.
Purpose of multi-head attention
To be able to attend to multiple aspects of the input
Goal of task-oriented dialog systems
To complete a task or tasks in a predefined task set, e.g., order something, make a call, transfer money, get directions etc.
Goal of open-domain dialog systems
▶ The goal is an open-ended and unstructured, extended conversation.
▶ There is no predetermined task (or set of tasks) whose successful execution would be the goal
▶ The main result in many cases is simply “entertainment”
Types of dialog systems based on initiation
user-initiated
system-controlled
mixed initiative
User-initiated dialog system
Dialogs are typically very short, e.g., a user question and a system answer using a mobile assistant
System-controlled dialog system
Variants:
▶ the system initiates and controls, e.g. by warning or reminding the user of something
▶ the user initiates by asking for instructions, from there the system instructs without essential user input
▶ the user initiates by asking for a service, from there the system helps the user to “fill in a questionnaire” by asking questions
Mixed initiative dialog system
There are several turns and both the system and the user can take the initiative – these are typically open-domain dialog systems.
General conversational requirements
grounding
adjecency pairs
pragmatic inferences
Grounding
There is a constantly evolving common ground established by the speakers who constantly acknowledge understanding what the other said.
Speakers:
▶ introduce new pieces of information
▶ acknowledge the added information (by gestures of verbal confirmation)
▶ ask for clarification if needed
Response by retrieval (in the context of corpus-based ODD systems)
Respond with the utterance in the data set that is
▶ most similar to the last turn, or
▶ is the response to the utterance which is most similar to the last turn.
(Similarity can be totally pretrained, or trained/fine-tuned embedding based.)
Response by generation (in the context of corpus-based ODD systems)
Train a generator model on the data set, typical architectures:
▶ RNN or Transformer based encoder-decoder
▶ a fine-tunded “Predict next”, language-model, e.g., a GPT-like architecture
Frame (in the context of TODs)
Structured representations of the user’s intentions, which contain slots that can be filled in with values.
Frame-based TOD system
Asks questions that help filling the frame slots until all slots are filled that are required for the current target task, and then executes it.
Components of early frame-based TODs
Control structure
Natural language understanding (NLU)
Natural language generation (NLG)
Optional ASR (Automatic Speech Recognition) module
Control structure of TODs
A production rule system controlling how to manipulate the slot values and which question to ask based on the actual state and the user’s input.
NLU module of TODs
A rule-based NLP module determining the domain (general topic), intent (concrete goal), and slots and filler values of the utterance.
It can be implemented by classifiers and sequence tagging models (e.g. IOB tagging)
NLG module for TODs
A template-based system to generate appropriate system questions for the user.
Differences between dialog-state and frame-based TODs
▶ decomposing control into two separate modules:
the dialog state tracker
dialog policy
▶ extensive use of machine learning methods in all modules, instead of the early systems’ rule-based approach
Dialog state tracker
Based on the NLU’s (N-best) output and/or dialog history, it determines the dialog act that took place, and the current (updated) dialog state.
This can happen by generating a set of candidate states and scoring them, or by scoring individual (slot, value) pairs separately. The scorer can be based on a pretrained encoder like BERT.
Dialog policy
Decides which action should the system take next, on the basis of the dialogue state and possibly other elements of the dialog history.
Action types:
system dialog acts
querying a database
external API calls
Implementations:
rule based systems
supervised ML
RL optimized ML
NLG component in dialog-state system
When the required action is a type of system utterance, it generates the actual sentence based on the concrete action, the dialog state, and (optionally) the dialog history. It can be implemented as a rule-based system or as an ML model (seq2seq)
Parts of the NLG task
▶ utterance planning: planning the content of the utterance (which slots/values should be mentioned, perhaps also their order and grouping),
▶ utterance realization: actually generating the natural language expression of the planned content.
Dialog schema graph
Fully general task-oriented dialog model that explicitly conditions on task-oriented dialog descriptions.
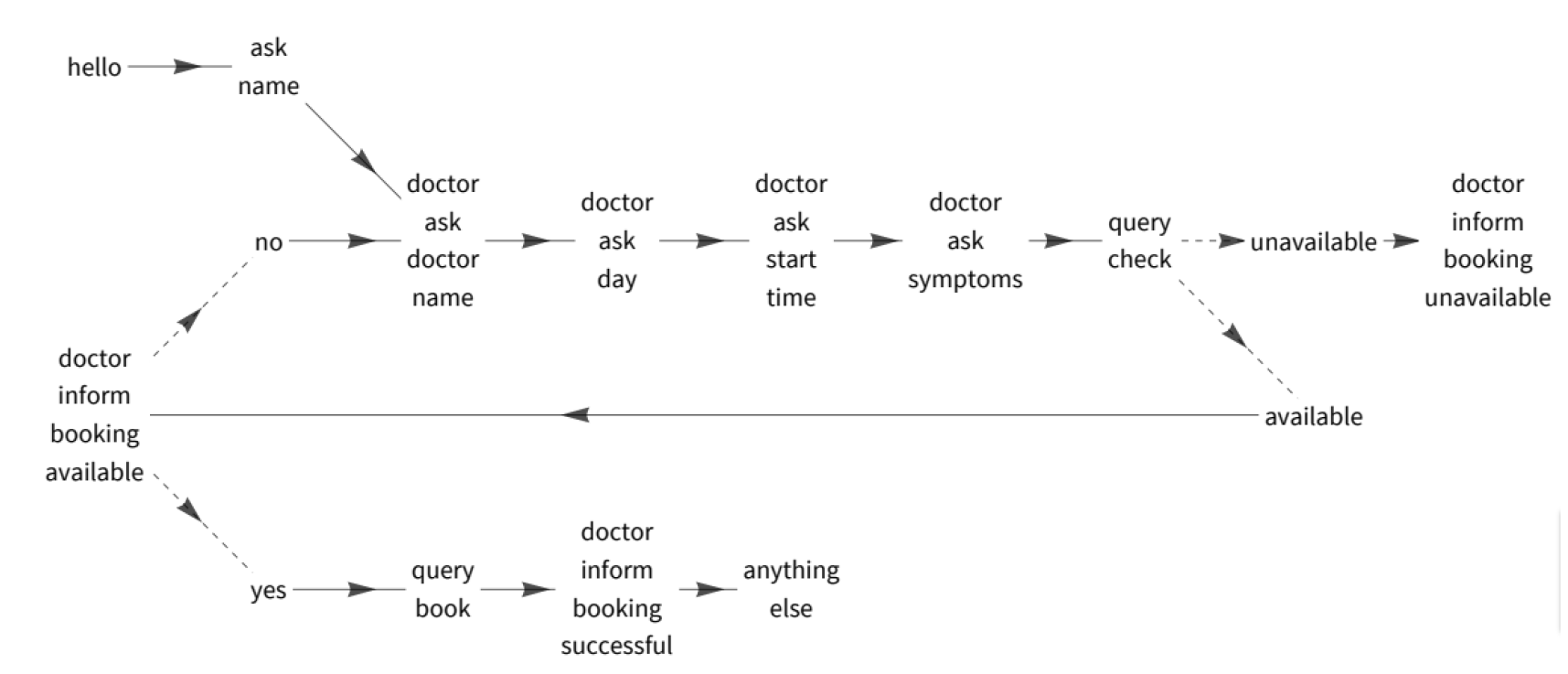
Several schema-guided task-oriented dialog datasets
STAR
SGD
SGD-X
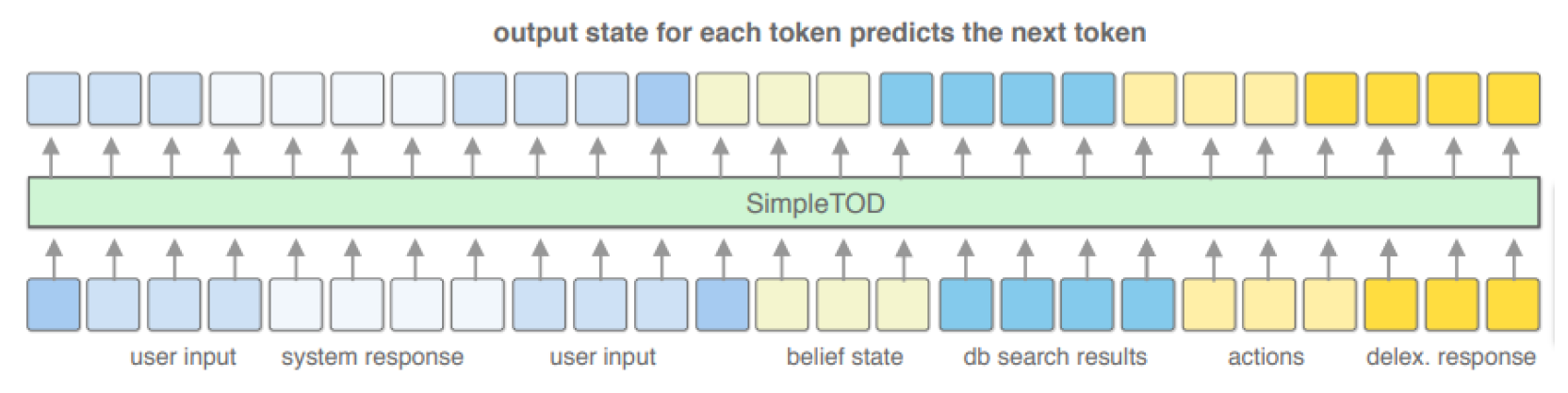
SimpleTOD
A single multi-task seq2seq model based on a pretrained LM.
It is simultaneously trained for:
dialog state tracking
dialog policy
NLG
Open-domain dialog system evaluation aspects
▶ how engaging was the dialog
▶ are the utterances human(-like)
▶ do responses make sense in the context
▶ are they fluent
▶ do they avoid repetitions
Task-oriented dialog system evaluation aspects
absolute task success
slot error rate
user satisfaction
general dialog quality
Temperature scaling
Modifying the model’s probability distribution to control its ‘creativity’ with a T temperature parameter:
the higher the temperature, the closer it gets to a uniform distribution → more unexpected behavior, creativity
in case of 0 temperature, the single best option has 1.0 probability, no other option can be chosen -> deterministic model
Top-k sampling
Restricting the vocabulary at each step to the top k tokens based on their score
Top-p sampling
Restricts the vocabulary by keeping the smallest set of most probable tokens whose combined probability mass meets (and exceeds) a threshold p.
Logit biasing
Biasing the logits of the model to favor certain tokens. This can be used to prevent the model from generating harmful content, or to make it generate content that is more aligned with a certain style.
Presence penalty
Decreases bias towards tokens that appear in the current text with a flat penalty.
Frequency penalty
Incrementally decreases the bias towards the token with the number of its occurrences.
Beam size
A hyperparameter of beam search, the number of sequences that are kept at each step.
A larger beam size will result in more diverse outputs, but also in a significantly slower inference.
Flash decoding
Parallelizes the QK product calculation over the sequence length, softmax and the output are calculated after the parallel processing is done
→ we can achieve higher GPU utilization
Flashdecoding++
It uses a fixed global constant based on activation statistics to prevent the overflow of the exponential in the softmax, thus the elements of the softmax can be calculated in parallel. If the method meets an overflow it will recompute the softmax with the actual maximum value, but this should happen with < 1% probability
Phases of inference
Prefill
Decoding
Prefill inference step
The user prompt is processed, K and V are calculated and cached. This could be done in a single pass, and it might be a much longer sequence than the generated output. This also includes generating the first output token.
Decoding inference step
The iterative process of generating the next token and calculating the next K and V. This cannot be parallelized, but the K and V can be reused from the cache. We only need to calculate a single Q for each pass.