Lecture 25: null effects in research designs
1/44
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
45 Terms
what are Abelson’s laws about null effects? (5)
chance is lumpy: we aren’t good at understanding what happens by chance because we look for patterns
overconfidence hates uncertainty: if you’re too confident, you can oversee some uncertainty (biases)
there is no free hunch: hunches are biases by scientists, which can cause misinterpretation of the hypothesis
you can’t see dust if you don’t move the couch: we tend to look at where it’s the easiest instead of all the possible outcomes
criticism is the moth of methodology: research methods need criticism
define “interpreting standalone statistics”
claims are often presented with no supporting data
according to Abelson, what do people overestimate? (2)
systematic effects: influence that contributes contributes equally to each observation in a consistent way → pattern, predictable
chance effect: influence that contributes by chance to each observation → no pattern, unpredictable
*systematic tends to be overestimated
people tend to overestimate [chance/systematic] effects
systematic
systematic effects: influence that contributes contributes equally to each observation in a consistent way → pattern, predictable
chance effect: influence that contributes by chance to each observation → no pattern, unpredictable
define “systematic effects”
influence that contributes to each observation in a consistent way (pattern, predictable)
define “chance effects”
influence that contributes by chance to each observation (no pattern, unpredictable)
what’s used as comparison standards?
control groups: they can reduce misleading statistical interpretations
define “null effect”
outcome that does not support rejecting the null hypothesis (no statistically significant effect on the design)
define “null hypothesis”
statement that the effect being studied (H0) does not exist
what’s the difference between a null effect and a null hypothesis?
null effect: outcome doesn’t support rejecting the null hypothesis (no statistically significant difference)
null hypothesis: the effect studied doesn’t exist (what’s the probability that outcome x happens if the null hypothesis is true)
define “alternative hypothesis”
studied effect that exists
what’s the difference between a null hypothesis and an alternative hypothesis?
null: the effect studied doesn’t exist
alternative: the effect studied exists
what does it mean when we say that the null hypothesis and the alternative hypothesis are mutually exclusive?
that both cannot be correct/true at the same time (it’s one or the other)
which one is correct/incorrect and explain why:
if the null hypothesis is true, then outcome X is highly unlikely. outcome X occurred. therefore, the null hypothesis is highly unlikely to be true.
if the null hypothesis is true, then outcome X cannot occur. outcome X occurred. therefore, the null hypothesis is false (rejected).
correct: “highly unlikely”, “highly unlikely to be true”
almost correct: “cannot occur”, “false/rejected”
we cannot prove the null hypothesis (2), we can only provide evidence against it
data and hypotheses aren’t “all-or-none”, they are probabilistic
what are the types of null effects? (3)
outcome isn’t different from chance because there is no true evidence for the alternative hypothesis
outcome is real, but not statistically significant because there isn’t enough data or the measures aren’t sensitive enough
outcome reached significance level to reject H0, but the size of the impact was too small to be meaningful
*null effect: outcome doesn’t support rejecting the H0
how do we know that there is a publication bias regarding null effects?
we see more null effects in registered reports (reports that go through processing before the data is submitted) than in non-registered/standards reports → underestimation of the null effect in scientific papers
why do we care about null effects? (3)
know if a cheaper or shorter treatment works just as well (no difference between the conditions = they both work the same)
design a study to demonstrate that another article was wrong and that there is no effect
be prepared to observe a non-significant finding in any study (H0 is a possible outcome)
what are the criteria to reject the null hypothesis? (3)
falsifiable: must be possible to reject the null hypothesis
results must be consistent with the null hypothesis
experiment doesn’t try to disprove the H0 only, must have tried to find an effect
when you report the results of a study, what should you consider as potential reasons for null results? (3)
were the two groups equivalent at baseline
what’s the minimum detectable effect size? is it small enough to detect meaningful impacts?
what is the difference between the treatment and control group? was the contrast strong enough?
how could the IV cause null effects? (4)
not enough between-subjects differences
within-subjects variability (individual differences) hid group differences
no actual difference
null effect is hard to find
how could the DV cause null effects?
ceiling and floor effects (used a lot of data or more sensitive to IV) → if not sensitive enough, we might not see differences that are there
how can you reduce the floor or ceiling effect?
by having more precise measurements and do manipulation checks: did the manipulation work as expected
define “manipulation check”
additional DV included to make sure that the IV worked
what are the causes of null effects in a within-subjects design? (3)
measurement error: what the DV well measured, equipment problems
indvidual differences
situation noise: external distraction that could cause variability within groups
how could you reduce measurement errors? (2)
use reliable and precise measurements
measure multiple times
how could you reduce individual differences? (2)
change the design to a matched-group design (2 participants with same individual differences)
add more participants
define “situational noise”
external distractions that could cause variability within groups that obscures within-subjects or between-subjects differences
how can you reduce situational noise?
controlling the environment
how can sampled participants cause null effects? (5)
are they representative of the population
was variability under/overestimated
were they all naive and unbiased
did you recruit enough, were there some carryover effects
ethical issues
how can stimulus materials/equipment cause null effects? (5)
are they all familiar or new for all participants
are they too hard or easy
are they representative of the task
are they standardized across studies and responses
was the equipment the same for all participants
*you can control these after you’ve sampled
how can experimenters cause null effects? (4)
are they adequately trained for the task
are they objective/passive in the task
are they treating the participants the same
is there fatigue/practice occurring in the experimenter?
how can procedures cause null effects? (3)
were the procedures reproduced the same way across participants
were the procedures standardized relative to other studies
did new procedures have a time for participants to practice?
how can constrains on study designs cause null effects? (3)
limited sample sizes
issues with data collection process
issues with the analysis of methods
you obtained null results, what should you do next? (4)
re-run the study with improved design details
re-measure the DV to reduce variability
constrain analyses to address portions of the study that don’t have flaws
consider publishing null effects as it is
what’s an advantage and a disadvantage of re-running the study with improved design details?
advantage: more likely to be a strong test of H0 (prove more strongly what you already have)
disadvantage: time consuming
what’s an advantage and a disadvantage of constraining your analyses to address parts of the study that don’t have flaws?
advantage: data is already available
disadvantage: hard to interpret findings from partial report
what does having multiple outcomes from re-running a study allows you to do?
mean and variance metrics: you can know the effect size you should expect
when should you conduct the original study (2) and when should you conduct the improved study (2)?
original
believe that there are no design flaws
seeking confirmation of an outcome
improved
can improve on design flaw
can extend to another sample, materials or tasks (whatever is changed may account for observed differences)
what’s the difference between re-running a study and re-measuring the DV?
re-running: redo the experiment
re-measuring: obtaining another point of view
what’s important to know/understand when you are constraining your analyses to focus on parts without flaws?
the null hypothesis for all conditions (because it might differ and you won’t be able to compare them all)
true or false: you should not publish your study if there are strong evidences of null effects
false
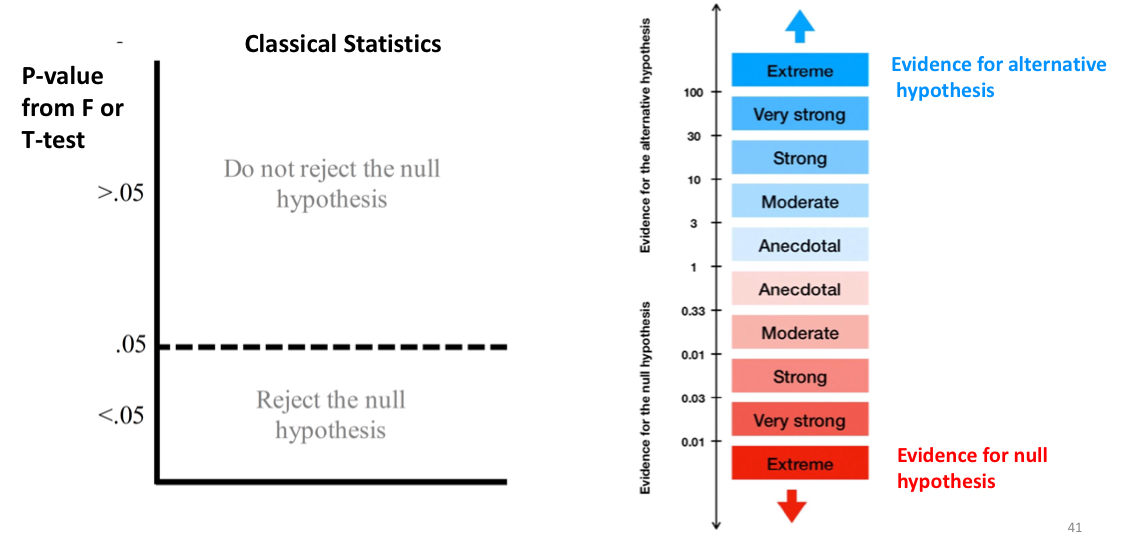
what’s the difference between a classic analysis and Bayesian analysis?
classic: p < 0.5 = reject H0; p > 0.5 = retain H0
Bayesian: evidence that supports H0 VS doesn’t support H0
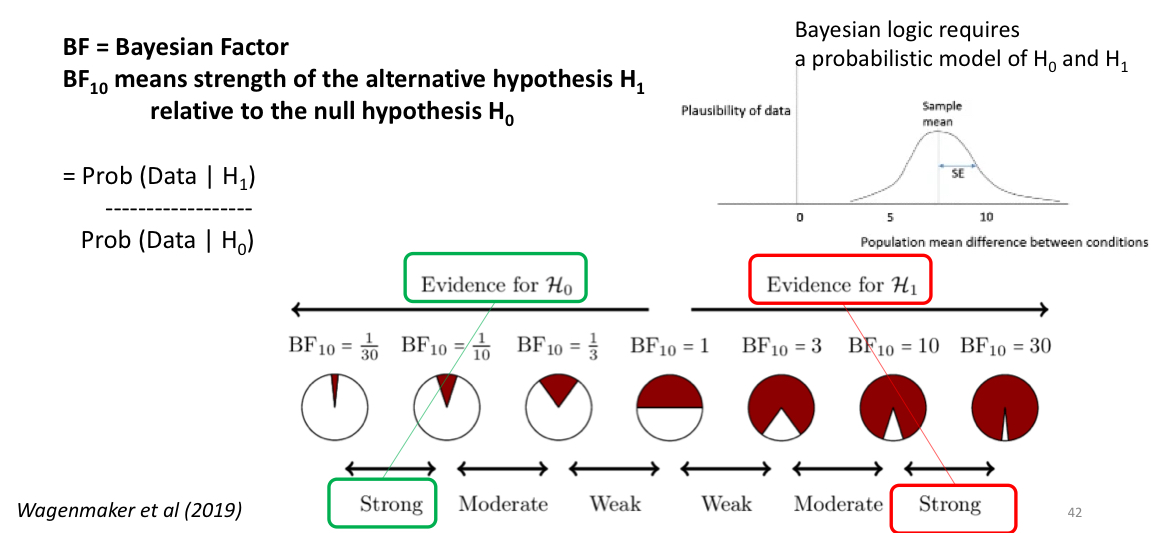
what’s “BF” and “BF10”?
BF: bayesian factor
BF10: strength of the H1 relative to H0
how do you compute the bayesian factor (BF)?
BF = Prob (Data | H1) ÷ Prob (Data | H0)
(probability H1 is true ÷ probability that H0 is true)
if your BF10 is close to 1/30, then you have strong evidence for the [H0/H1]. if your BF10 is close to 30, then you have strong evidence for the [H0/H1]
BF10 = 1/30: evidence for H0
BF10 = 30: evidence for H1