Immediate addressing
the operand is specified in the instruction explicitly
ex: addi, li
Register addressing
the data to be operand is inside the register, and the register is the operand
ex: add, sub
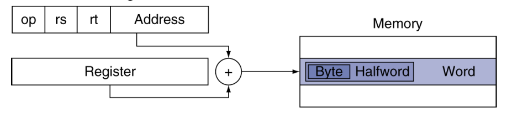
Base addressing
the address of the instruction is added to the register content, and is saved to the memory
ex: lw, sw
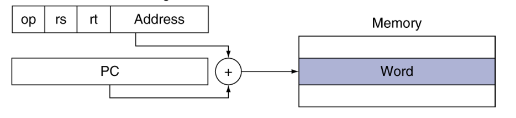
PC-relative addressing
the address of the instruction is added to the PC content, and is saved to the memory
ex: beq, bne
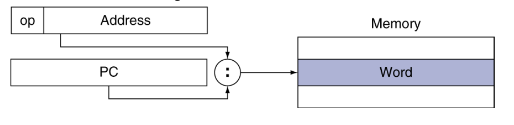
Pseudodirect addressing
the address and the PC content are combined with : and saved to the memory
ex: j
instruction fetch
PC (program counter)
instruction decode
IM, RF
instruction execute
ALU, RF
writeback
RF, DM
1
For a single cycle processor, CP1 is always __
jump target address
26 bits from address (given) + 4 bits from MSByte + last 2 bits "00"
branch target address
sign extend from 16 to 32 bits + shift left by 2
instruction memory
used to decode/read instruction (1 clock cycle to decode)
data memory
used to write data
need to access data and instruction from memory in the same clock cycle
Why do we separate memory?
CPI performance factors
instruction count
CPI and cycle time
instruction count
determined by ISA and compiler
CPI and cycle time
determined by CPU hardware
ALU calculates
arithmetic result
memory address for load/store
BTA
datapath
elements that process data and address in the CPU
ex: ALUs, registers, multiplexers, memories
execution time formula
(# of instructions) (CPI) (Tc)
single cycle pros
simple
easy to pipeline because of separate instructions
single cycle cons
latency due to longest instruction
more hardware is used (ex: adders, ALUs, memories)
CPI formula
(clock cycles) / (# of instructions)
single cycle processor
interface between controller and data path, used to get complete implementation for any instruction