computer systems
1/131
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
132 Terms
signed magnitude pros
simple and intuitive representation
easy to convert unsigned values to signed positive numbers (just add 0 as sign bit)
signed magnitude cons
sign bit makes it difficult to do arithmetic
2 representations of 0, makes no sense
ones complement pros
easy to perform addition so simple circuits
ones complement cons
2 representations of 0
twos complement pros
no special bits so simple circuits
single representation of 0
2 reasons why computers use binary
computers use transistors which only have 2 states
efficient for boolean computational logic
decimal to ones complement method
decimal to unsigned binary
extend bits if needed
flip bits
ones complement to decimal method
if MSB if 1, flip bits
unsigned binary to (negative) decimal
decimal to twos complement method
decimal to unsigned binary
if decimal was negative, flip bits + add 1
twos complement to decimal method
if MSB = 1, flip bits + add 1
unsigned binary to decimal
maximum/minimum for unsigned binary
minimum = 00000000 = 0
maximum = 11111111 = 255
maximum/minimum for signed binary
minimum = 11111111 = -127
maximum = 01111111 = 127
maximum/minimum for ones complement
minimum = 1 0000000 = -127
maximum = 0 1111111 = 127
maximum/minimum for twos complement
minimum = 10000000 = -128
maximum = 01111111 = 127
signed magnitude addition method
if operands have same sign, add magnitudes and keep bit
else large operand - small operand and choose sign bit of larger magnitude operand
signed magnitude subtraction method
rearrange -b to +b by changing sign bit
if operands have same sign post change, add
else large operand - small operand with final answer sign same as large operand
signed multiplication/division method
perform as unsigned, if operands have same signs then keep, else pick from larger operand
ones complement addition overflow
end carry around
twos complement addition overflow
discard excess carry bits
if final carry bit is not same as last answer bit, overflow is detected
ones/twos complement multiplication/division method
convert both operands to be positive
perform as unsigned
convert to negative is operands had different signs
IEEE-754 single precision format
32 bits
sign bit + 8 bit exponent + 23 bit significand
127 bias
IEEE-754 double precision format
64 bits
sign bit + 11 bit exponent + 52 bit significand
1023 bias
IEEE-754 single precision to decimal method
calculate exponent by exponent - bias
add leading 1 to significand (1.significand)
move floating point as per exponent, calculate and add sign
decimal to IEEE-754 single precision method
convert to unsigned binary
normalise and find exponent
set sign bit
0, infinity and not a number special values for IEEE-754
0: 0/1 00000000 000…
infinity: 0/1 11111111 000…
not a number: 0 11111111 any significand
IEEE-754 addition method
adjust floating point so significands have same exponent (2^0)
if different signs, add significands else subtract
renormalise if needed and pick sign
IEEE-754 multiplication method
add decimal exponents
multiply significands
renormalise and set exponent
select sign
IEEE-754 division method
subtract decimal exponents
divide significands
renormalise and set exponent
select sign
overflow/underflow in IEEE-754
overflow: exponent > 128
underflow: magnitude too close to 0 to be distinguished from it
word
smallest addressable unit in memory
block
method of grouping sequential words in memory
number of blocks = number of words / block size
memory address
uniquely identifies a word
block field (block of word) + offset field (word position in block)
exposed hierarchy
programmers decide where to store data
complex load/store instructions for each form of memory in memory hierarchy
when CPU wants to load data it must be specified which memory is being used from the hierarchy as it has full access
implicit memory hierarchy
memory complexities hidden from processor
hardware handles where data goes, in fast or slow memory
processor sees fast memory as long as hardware keeps required data in cache
processor needs to handle different latencies on demand
cache miss
data for address is not in cache
request passed to main memory, high latency
temporal locality: data retained in cache
spatial/sequential locality: request additional close addresses from memory
EAT for hit and miss ratios
without cache, EAT = main memory access
if access is overlapped and cache checked in parallel with main memory, then
EAT = (HR x cache access) + (MR x main memory access)

internal structure of cache (given a request for data in a memory address)
cache checks for a tag that matches memory address to see if it is in cache
if tag found, cache hit so return data
else cache miss
read data at address from memory and return data
select address in cache to store data
direct mapped cache
each block in memory is mapped to one cache block
multiple memory blocks can be mapped to same cache blocks
address has block (no of bits to address all cache blocks) + offset (no of bits to address all words in a block) + tag (left over bits)
1 pro and con of direct mapped cache
search is fast ad only 1 location in cache where an address can be
overly rigid
fully associative cache
main memory blocks can be stored anywhere in cache
address = tag (block of main memory) + offset (position of word within that block)
con of fully associative cache
may have to search entire cache to find tag
if no space in cache to copy data from main memory, select victim block according to replacement policy
set associative cache
cache divided into contiguous equal sized segments
each address maps to only 1 set (main memory block number MOD number of sets)
but can be stored anywhere within that set
address is tag (main memory block in cache) + set (set in cache) + offset (word in block)
3 replacement policies
LRU (least recently used): keeps track of last time each block in cache was accessed
victim block is block unused for longest, complex to track
FIFO: victim block is block in cache the longest
simple, still keeps track
random policy: random block selected as victim block
no overhead but risky
5 factors to consider when picking an ISA
instruction length
operands/instruction type
memory organisation
addressing modes
operations available
3 main measures for an ISA
memory space (RAM as expensive)
instruction complexity
number of available instructions
endianness
byte ordering, how data is stored
ordering of bytes of data
little endian machines
LSB → MSB
flexible for casting
16 to 32 bit integer address doesn’t require any arithmetic
big endian machines
MSB → LSB
natural
sign of number obvious by looking at byte at address offset 0
strings and integers are stored in same order
3 types of register architectures
stack architecture
accumulator architecture
general purpose register architecture
tradeoff is between simplicity and cost of hardware, and execution speed and ease of use
stack architecture
instructions and operands taken from stack
cannot be accessed randomly
stack machine
use 1 and 0 operand instructions
instructions operate on elements on top of stack
access instructions are push and pop that need 1 memory address operand
accumulator architecture
1 operand of binary operand is stored in accumulator
one operand in memory, creating bus traffic
GPR architecture
registers used instead of memory
faster than ACC architecture
longer instructions
3 types of GPR architecture
memory-memory: 2/3 operands in memory
register-memory: at least 1 operand in register
load-store: no operands in memory
move data to CPU, work with it, move out when done
immediate addressing
data is part of instruction
direct addressing
address of data is given in instruction
indirect addressing
address of address of data is given in instruction
index addressing
uses register as offset (index , for index addressing, base for base addressing)
added to address in operand to find effective address of data
register addressing
data located in a register
register indirect addressing
register stores address of address of data
stack addressing
operand assumed to be on top of stack
FDE broken down into instruction level
fetch instruction
decode opcode
calculate effective address of operand
fetch operand
execute instruction
store result
theoretical speed offered by pipeline
each instruction is a task T, no. of tasks is N
Tp is time pers take, K is number of stages in pipeline
for no pipelining, time is NKtp
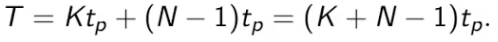
pipeline speed up equation

3 pipeline hazards
resource conflicts
data dependencies
conditional branching
2 parts of a CPU
datapath + control unit
2 parts of a datapath
ALU + registers
purpose of control unit
sends signals to CPU components
determined based off PC and status register values
what is a word
addressable cell of fixed size
how is RAM measured
length x width
length is number of words
width is how many bits in a word
2 methods of connecting I/O to CPU
memory mapped: devices act like memory from CPU POV with its own address in memory
instruction mapped: CPU has specific instructions for the device
what is a bus
array of wires simultaneously converting 1 bit along 1 line
2 types of buses
point to point: connect 2 components
multipoint: connect many components (data bus)
functions of data, control and address lines
data line: convey bits from one component to another
control line: choose direction of data flow + when devices can access the bus
address line: choose data source + destination location
one way
equation for cpu time to run a program
T = seconds/program = instructions/program x avg cycles/instruction x seconds/cycle
MARIE specs (6)
twos complement binary
von neumann (fixed word length data + instructions)
16 bit word size, 16 bit instructions (4 opcode, 12 address)
16 bit ALU
7 registers
ACC
holds data to be processed
16 bit
MBR
holds data just read from memory/to be written to memory next
16 bit
IR
holds instruction just before execution
16 bit
MAR
holds memory address of data being referenced
12 bit
PC
holds address of next instruction to be executed
12 bit
IN
holds data read from input device
8 bit
OUT
holds data to be written to output device
8 bits
which registers are the 2 special bus connection in between in MARIE
AC + MBR
ALU + AC + MBR
load X
loads contents of address X into AC
MAR ← X
MBR ← M[MAR]
AC ← MBR
store X
stores contents of AC at address X
MAR ← X + MBR ← AC
AC ← MBR
add x
adds contents of address X to AC
MAR ← X
MBR ← M[MAR]
AC ← AC + MBR
subt X
subtracts contents of address X from AC
MAR ← X
MBR ← M[MAR]
AC ← AC - MBR
input
inputs into AC
AC ← InREG
output
outputs value in AC
AC ← OutREG
skipcond
skips next instruction
if IR[11 - 10] = 00 and AC < 0 then
PC ← PC + 1
else if IR[11 - 10] = 01 and AC = 0 then
PC ← PC + 1
else if IR[11 - 10] = 10 and AC > 0 then
PC ← PC + 1
jump X
load X into PC
PC ← X
FDE cycle
fetch from memory
address from PC —> IR
instruction from MAR —> IR
increment PC
decode
address put into MAR
if operand uninvolved put in MBR
else data in MAR —> MBR
exectute
6 step interrupt processing
store register data in memory
look up ISR address in interrupt table
place ISR address in PC
execute ISR instructions
restore registers data
resume FDE
maskable/non-maskable interrupt
maskable: interrupts ignored while another interrupt is running
non-maskable: must be processed to keep system stable ssmblera
assembler process
create object program file from source code
assembler assembles as much as possible while building symbol table with memory references for symbols
instructions completed using symbol table
AddI
MAR ← X
MBR ← M[MAR]
MAR ← MBR
MBR ← M[MAR]
AC ← AC + MBR
JnS
MBR ← PC
MAR ← X
M[MAR] ← MBR
MBR ← X
AC ← 1
AC ← AC + MBR
PC ← AC
JumpI
MAR ← X
MBR ← M[MAR]
PC ← MBR
clear
AC ← 0