Critically Appraising the Quality of the Research Evidence: Diagnostic Research Studies & Expert Opinion
1/38
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
39 Terms
Diagnostic Tests in the Rehabilitation Sciences
Any assessment that provides a measurement of function to the therapist and provides information used in clinical decision-making
These may be tests that the therapist directly performs to measure function
Manual muscle test, goniometry, girth measurements
These may be tests that use equipment to measure function
Electromyography, nerve conduction velocity
These may be standardized tests
DASH, SF-36, WOMAC
These may be differential diagnosis test conducted to rule-in or rule-out a pathology or diagnosis
Carpal tunnel test, lateral epicondylitis tests, tests for impingement
Both OTs and PTs use tests in practice that can be considered diagnostic within our practice
For every diagnostic test that is used in examination, you should know the answers to these questions:
What diagnostic information am I seeking?
Will this test assist me in confirming or refuting my clinical hypothesis regarding my patient’s movement problem?
How will this test result affect my treatment recommendations?
What do I know about the characteristics of the test I am using?
What should I know about the characteristics of the test I am using?
Research Designs for Diagnostic Tests
Cohort design: most common design for developing diagnostic tests
Preferred: prospective cohort design
Follows participants forward in time
Collects data on both index test (e.g., Lachman test) and gold-standard test (e.g., MRI)
Diagnostic Tests for Subacromial Impingement Syndrome
Neer Impingement Test
Hawkins Test
Horizontal Adduction Test
Painful ArcTest
Drop Arm Test
Yergason Test
Speed Test
Studies of Diagnostic Accuracy
To what extent do we trust the finding of a test and how much do we rely on them to inform our clinical decision-making?
Qualities of the design, administration, and interpretation of quantitative tests for measurement of variables
Reliability – remember this is a quality of a test, not a study
Sensitivity
Specificity
Positive predictive value
Negative predictive value
Likelihood ratios
The Accuracy of Clinical Tests
Few, if any, are perfect
The accurcay (truth) of the test is determined against a gold standard (or reference standard when no gold standard exists
EX: carpal tunnel tests (clincial test) and nerve conduction velocity (reference/gold standard)
Why not just use the reference standard?
Cost
Efficiency
Discomfort to the patient (surgery)
QUESTION 1 (applicability)
Is the entire spectrum of patients represented in the study sample?
Key considerations
Population relevance: the study population must match the clinical population relevant to both the test and your patient
EX: Berg Scale validated for post stroke patients, patients with Parkinson’s disease (PD), patients with multiple sclerosis (MS)
Spectrum of Impact: if the study doesn’t cover the full spectrum of the condition, the test’s applicability is limited
Limitation of acknowledgement:
Authors should state when a test is applied to populations not validated by the study
QUESTION 2 (applicability)
Was there an independent, blind comparison with a gold-standard test of
diagnosis?Comparison with a Gold-Standard Test
Index Test (Test of Interest): the diagnostic test being evaluated
Gold-Standard Test: the most accurate test available for the condition
Purpose Alignment: both the index test and gold-standard test must measure the same outcome
QUESTION 2 (examples in rehab science)
Musculoskeletal diagnoses: orthopedic rehab science tests are often compared to imaging, such as MRI
Benefit of valid tests:
Time saving: reduces delays in care
Cost-effective: avoids unnecessary use of expensive tests
Accessibility: provides rapid results in clinical settings
QUESTION 3 (applicability)
Did all participants receive both tests (index and gold- standard tests) regardless of test outcomes?
Comparison of Diagnostic Tests
Conduct both tests: complete the index test and gold-standard test regardless of individual outcomes
Blinded professionals: two or more masked (blinded) professionals perform and interpret the test independently
Importance of dual testing:
Ensures accuracy and validity of the diagnostic process
Prevents bias by ensuring that all participants undergo both tests, regardless of individual test outcomes
Dianosis Research Studies—Internal Validity (bias)
Application and scoring of the reference and diagnostic tests (each of the below is good if you have two or all three of these, even better)
Independent: conducted separately, likely by different evaluators (better than if the gold standard test is done by the same group that is performing the
diagnostic test)Universal: more than one evaluator is used to administer the tests, and then results are compared (and possibly averaged or pooled, if the data allows)
Blinded: evaluators do not know the results of
diagnostic tests or reference/gold standard test
QUESTION 4 (applicability)
Were the diagnostic tests performed by one or more reliable examiners?
Masking (Blinding) of Examiners
At least two examiners, each performing only one test (index or gold standard).
Tests performed without knowledge of the other test results or the study goals.
Purpose: Reduces bias and ensures objective test administration.
QUESTION 4 (Reliability of Examiners)
Test Reliability:
Consistent results across multiple trials of the same test.
Influenced by the stability of the phenomenon being tested (e.g., balance) and rater consistency
Types of Reliability:
Intra-rater: Consistency within the same examiner.
Inter-rater: Consistency between different examiners.
Key Point:
Reliability must be established with relevant patient populations
(e.g., spinal cord injury) to ensure the test’s usefulness.Example: Manual muscle testing may yield different results in
healthy individuals versus patients with movement disorders.
QUESTION 5 (interpreting)
Was the diagnostic test interpreted independently of all clinical information?
Key Principle:
Tests should be conducted independently of patient history or clinical experience.
Why This Matters:
Isolating the test ensures it contributes uniquely to the diagnostic process.
Prevents bias by keeping examiners blind to clinical characteristics of participants.
QUESTION 6 (interpreting)
Were clinically useful statistics included in the analysis and interpreted for clinical
application?Comparing a reference test to a gold-standard test involves the computation of diagnostic statistics.
Many different statistics can be used to reflect the accuracy and usefulness of a diagnostic test.
Key Diagnostic Statistics:
Sensitivity – Identifies how well the test detects true positives.
Specificity – Identifies how well the test detects true negatives.
Positive and Negative Predictive Values (PPV & NPV) – Reflect the accuracy of positive/negative test outcomes.
Likelihood Ratios – Combine sensitivity and specificity to refine
diagnostic decisions.Receiver Operating Characteristic (ROC) Curve – Visualizes
the trade-off between sensitivity and specificity.
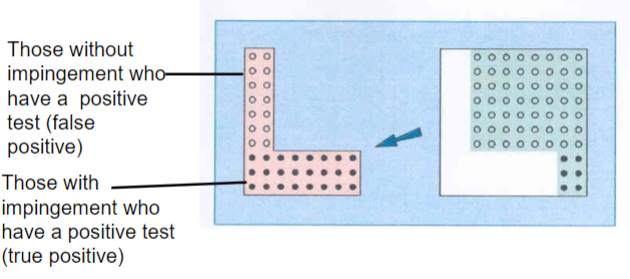
Sensitivity
“the test’s ability to obtain a positive test when the target condition is really present, or the true positive rate”
Measures a test’s ability to correctly identify a condition (true positives)
The proportion of individuals who test positive for the condition out of all those who actually have it, or the probability of obtaining a correct positive test in patients who have the target condition
A highly sensitive test will correctly classify those who have the condition of interest
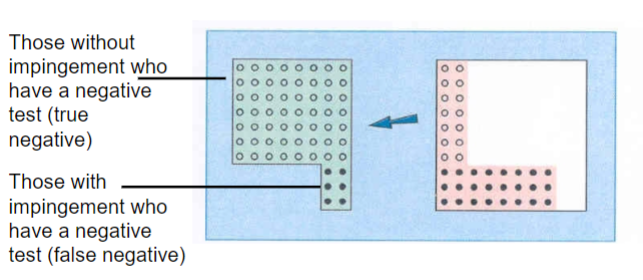
Specificity
the test’s ability to obtain a negative test when the condition is really absent, or the true negative rate”
Measures a test’s ability to correctly identify absence of a condition (true negatives)
The proportion of individuals who test negative for the condition out of all those who are truly normal, or the probability of a correct negative test in those who do
not have the target condition.A highly specific test will rarely test positive when a person does not have the disease
Sensitivity is ____
How good a test is at correctly identifying people who have a disease/pathology
Expressed as a proportion
“Truth” is determined by use of reference/gold standard
= True Positive/True Positive + False Negative
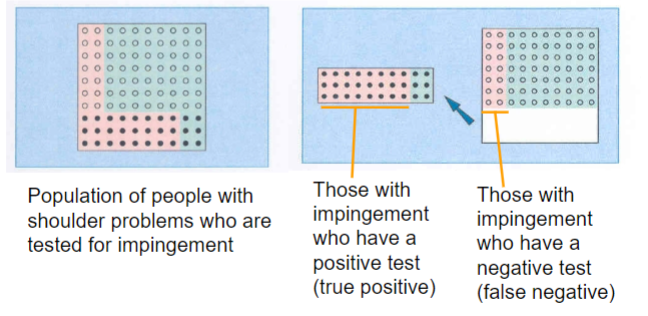
Sensitivity (percentage)
70% or higher is good
When a test has high sensitivity, a negative test rules out the diagnosis
Specificity is ___
How good a test is at correctly identifying people who do not have a condition/pathology
Expressed as a proportion
= True Negative/False Positive + True Positive
Where “truth” is determined by use of gold/reference standard
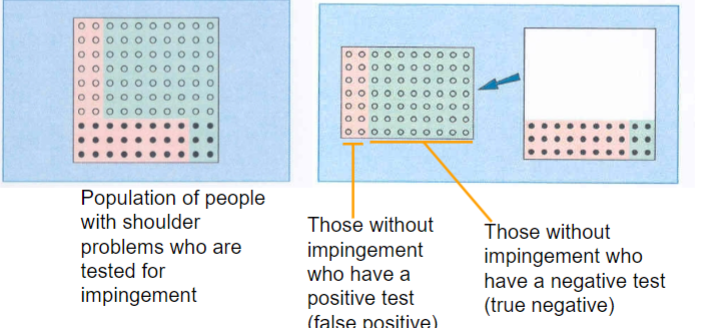
Specificity (percentage)
70% or higher is good
When a test has high specificity, a positive test rules in the diagnosis
SpPin
with high specificity, a positive test rules in the diagnosis
SnNout
with high sensitivity, a negative test rules out the diagnosis
ROC Curve
Graphs sensitivity vs. 1-specificity at various cut-off points.
Optimal cut point: Closest to the upper-left corner (best combination of sensitivity and specificity)
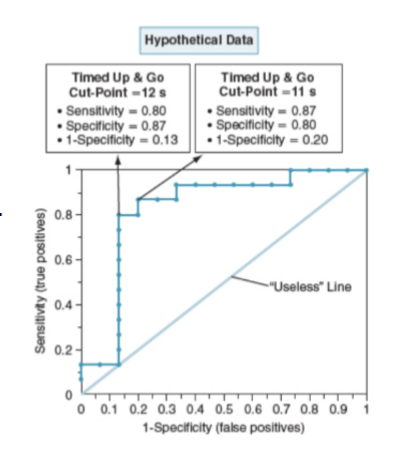
Grouping tests can
enhance your ability to determine a particular diagnosis
A group of tests that have both high sensitivity and specificity is
preferredSometimes, you have to combine a test with high sensitivity (even if its
specificity is low) with a test with high specificity (even if its sensitivity
is low)
Positive predictive value
estimates the likelihood that a person who tests positive actually has the disease”
Percentage of positive index tests confirmed by gold-standard tests.
In this context, “disease,” “pathology,” and “diagnosis” have the same meaning
A test with a high positive predictive value will provide a
strong estimate of the actual number of patients who have
the target condition
Negative predictive value
“indicates the probability that a person who tests negative is actually disease free”
Percentage of negative index tests confirmed by gold-standard tests.
A test with a high negative predictive value will provide a strong estimate of the number of people who do not have the target condition
Positive predictive value relates to
the chance that a positive test will be correct
= True Positive/True Positive + False Positive
Negative predictive value relates to
the chance that a negative test result will be correct
= True Negative/False Negative + True Negative
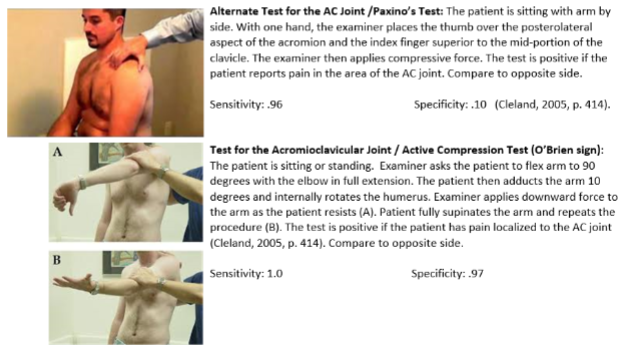
Test for Abductor Pollicis Brevis Weakness (Used to assess for carpal tunnel syndrome)
Positive predictive value:
The chance that a positive test result will be correct.
76% (Kuhlman & Hennessey, 1997)
Negative predictive value:
The chance that a negative test result will be correct.
54% (Kuhlman & Hennessey, 1997)
QUESTION 7 (summarizing)
Is the test accurate and clinically relevant to physical therapy practice?
Accuracy Matters:
The test must reliably determine the patient’s diagnostic status
Clinical Relevance Matters:
Tests must align with patient goals and the objectives of
physical therapyA test should inform your clinical decisions and treatment
planning
KEY POINT:
Choose diagnostic tests that are not only accurate but also
useful for guiding physical therapy interventions and
achieving patient outcomes
QUESTION 8 (summarizing)
Will the resulting posttest probabilities affect my management and help my patient?
Likelihood ratios provide quantitative information that shifts your certainty about your clinical diagnosis
Helps explain test results to patients by showing how the chances of having or not having a condition change based on their test results and initial risk
QUESTION 8 (likelihood ratio)
Positive Likelihood Ratio (LR+):
Answers: “What is the likelihood that my patient with a positive test result has the problem?”
Negative Likelihood Ratio (LR-):
Answers: “What is the likelihood that my patient with a negative test result has the problem?”
Using Pretest and Posttest Probabilities in Decision-Making:
Pretest Probability: Estimated from patient history and symptoms.
Posttest Probability: Adjusted based on diagnostic test
results and likelihood ratios.
Likelihood ratios
tells us how much more likely it is that a person has the diagnosis after the test is done (aka Posttest probability)
Less commonly seen in occupational therapy or physical therapy research
However, may be calculated from known sensitivity and specificity values
The LR+ will tell us how many times more likely a positive test will be
seen in those with the disorder than in those without the disorder. A
good test will have a high positive likelihood ratio.The LR– will tell us how many times more likely a negative test will
be seen in those with the disorder than in those without the disorder.
A good test will have a low negative likelihood ratio
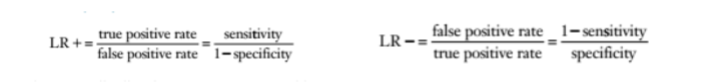
Likelihood Ratios (powerful & SpPin and SnNout)
Test considered fairly powerful if:
Positive likelihood ratio > 10
Negative likelihood ratio < 0.1
Going back to the concepts of SpPin and SnNout:
A large LR+ (>10) indicates that a positive test is good at ruling the disorder IN.
A low LR– (<.1) indicates that a negative test is good at ruling the disorder OUT.
A LR close to 1.0 does not contribute to the probability that a
person has or does not have the disorder.

Likelihood Ratios and You Clinical Bottom Line
What are the important findings in terms of your clinical question?
Address strengths and weaknesses of the study
How will you use this information
Clinical Expertise: Yours and Others
Better-than-average therapists:
Are always questioning their assumptions, opinions, and ‘habits’
Are open to new information
Are not afraid to change what they’re doing when informed decision-making suggests that they should do so
Are continually learning
Critical Appraisal of the Clinical Expertise of Others
Identify the source of clinical expertise that is under consideration for informing
clinical decision-makingIs the clinical expertise based on valid clinical research evidence?
Clinical expertise is built on a foundation of valid clinical research that is of high value. Clinicians find this source of evidence helpful because it combines an expert’s interpretation of research with the expert’s personal experiences with individual patients
Critical Appraisal of the Clinical Expertise of Others (cont’d)
Is the clinical expertise based on sound physiologic, anatomic, or basic science evidence?
Clinical expertise built on a foundation of valid basic science evidence extrapolated to clinical care is of high value. Clinicians find this source of evidence helpful because it combines an expert’s interpretation of research with the expert’s personal experiences with individual patients.
Is the clinical expertise based on the documented experience of numerous clinicians over time?
Clinical expertise that is formally documented, particularly by numerous clinicians over time, is of high value. Formal documentation can exist in narrative reviews,
textbooks, case reports, and case series, and in informal reports.
Is the clinical expertise free of branding and monetary ties that are likely to benefit one individual or company?
Clinical expertise that is free from branding or monetary ties that directly benefit an individual or company is not biased by the pressure to maintain certain recommendations in the interest of financial gain. Many experts make their living by providing continuing education courses. This fact does not discredit these experts but consumers maintain responsibility for evaluating the quality of the educational content. Expertise tied to a specific ‘brand’ or device for therapy is at higher risk for bias than expertise tied to clinical and basic science research.