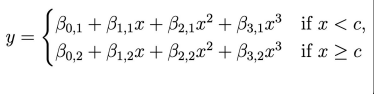DATA MINING MIDTERM
1/39
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
40 Terms
Sum of squared residuals
We estimate the linear regression coefficients by minimizing the _____
RSE( Residual squared error)
The standard deviation of the error and accuracy of the model is measured using ____
P-Value
The _____ can be used to reject the null hypothesis if < 0.05
MSE
The ____ is reported in units of Y
K-Nearest Neighbor
The _____ approach is a non-parametric method that makes a prediction based on the closest training observation
Cross validation (either LOOCV OR K-Fold)
Performing _____ ensures that every observation is selected for the testing data at least once
Decision Boundary (Discriminant function)
Linear discriminant analysis uses a _____ to seperate observations into distinct classes
Prior Probability
The ______ measures the probability that a random chosen observation belongs to class
Posterior Probability
Refers to updated beliefs or probabilities after new data has been incorporated through Bayes' Theorem
Best Subset Selection
Performing ______ to sub-select predictors requires the user to check every possible combinations of predictors (2p).
Principal Component Analysis (PCA)
The ______ is unsupervised method used to transform the predictors (p) to a linear combination of the predictors (M, p ≥ M).
Knot
A _____ is a location where our coefficients and functions change.
Regression spline
The _______ is a combination of step functions and polynomial regression.
Random Forest
The Decision Tree based model can be improved upon by using bagging and sub-selecting predictors at each split, typically called _______.
Pure Nodes
The goal of splits in trees is to produce homogeneous child nodes, often called ______.
We can relax the additive assumption of linear regression by adding interaction terms.
True
Linear regression is applicable to datasets where p is larger than n.
False
Naive Bayes classifiers assumes that all predictors are independent within classes
True
Classifiers typically return a probability that a given observation belongs to class k.
True
It is expected that the training error rate is lower than the testing error rate.
True
A confusion matrix is used to assess accuracy for classification and regression models.
False
It is good practice to prevent data leakage by reusing the same sample in both training and testing.
False
Both Ridge Regression and Lasso use a shrinkage penalty to regularize the coefficients to reduce the impact of the predictor on the model.
True
Forward and Backward Stepwise Selection are guaranteed to find the best possible combinations of predictors.
False
Cross Validation is often the best method to find the most optimal parameters.
True
Basis Functions are fixed, known functions (bk(X)) that transform X to allow us to use statistical tools like Standard Errors and Coefficient estimates.
True
For splines, it is best practice to use fewer knots to increase flexibility in regions where it may be necessary.
False
Generalized Additive Models allow us to use more than one predictor in our model.
True
Ridge Regression
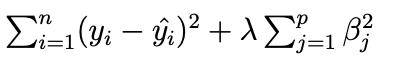
Smoothing Splines
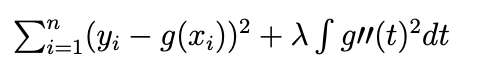
Linear Regression
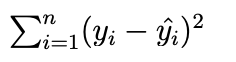
Lasso Regression
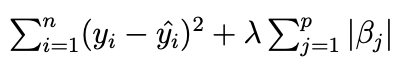
Linear Regression
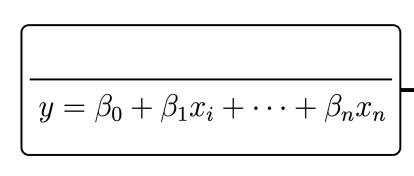
Logistic Regression
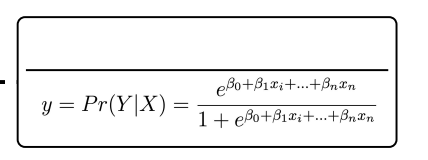
Ridge Regression
Polynomial Regression

Step Functions
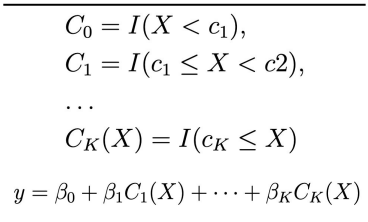
Lasso Regression
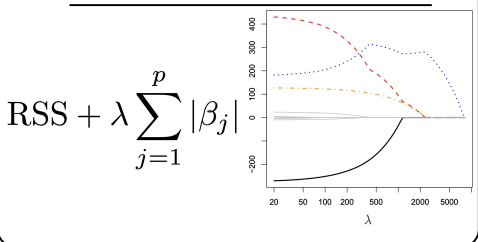
Regression Splines