H6 - Stream Processing
1/28
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
29 Terms
Recap: data processing system types
Services (online systems)
Service waits for request or instruction from a client to arrive
When request is received service tries to handle it as quickly as possible and sends response back
Response time usually primary measure of performance of a service
Availability often also important
Batch processing systems (offline systems) (vorig hoofdstuk)
Take a large amount of input data, run a job to process it and produce output data
Jobs often take a while (minutes/hours/days)
Often scheduled to run periodically
Primary performance measure is usually throughput
Time it takes to crunch through an input dataset of a certain size
Stream processing systems (near-real-time systems) (dit hoofdstuk)
Between online and offline/batch processing
Stream processor consumes inputs and produces outputs (rather than responding to events)
A stream job however operates on events shortly after they happen versus batch job operates on fixed set of input data
Allows stream processing systems to have lower latency than equivalent batch systems
Stream processing
Continuous stream of data
High velocity and low latency processing required
Typical data: unstructured log records, sensor events
Why streaming?
Store-first, process later (batch) data processing unable to offer the combination of latency and throughput requirements
Scalable, optimized architecture for near-zero latency (distributed execution over multiple servers/cores)
Designed for 24/7 operation
Stream vs batch processing
algemeen
transmitting event streams (figuur)
Assumption in batch processing: input is bounded - known and finite size
In reality: a lot of data is unbounded
What if we run processing more frequently?
A second worth of data at the end of every second (micro-batch)
Or continuously, abandoning fixed time slices entirely and processing every event as it happens → Stream processing is born
TRANSMITTING EVENT STREAMS
Batch: input and outputs of a job are files
Streaming: when input is a file first processing step is to parse it into a sequence of records (called events)
Record / event = small, self-contained immutable object
Usually contains a timestamp indicating when it happened
May be encoded as a text string, JSON, binary form, etc.
Allows to send event over network to another node to process it
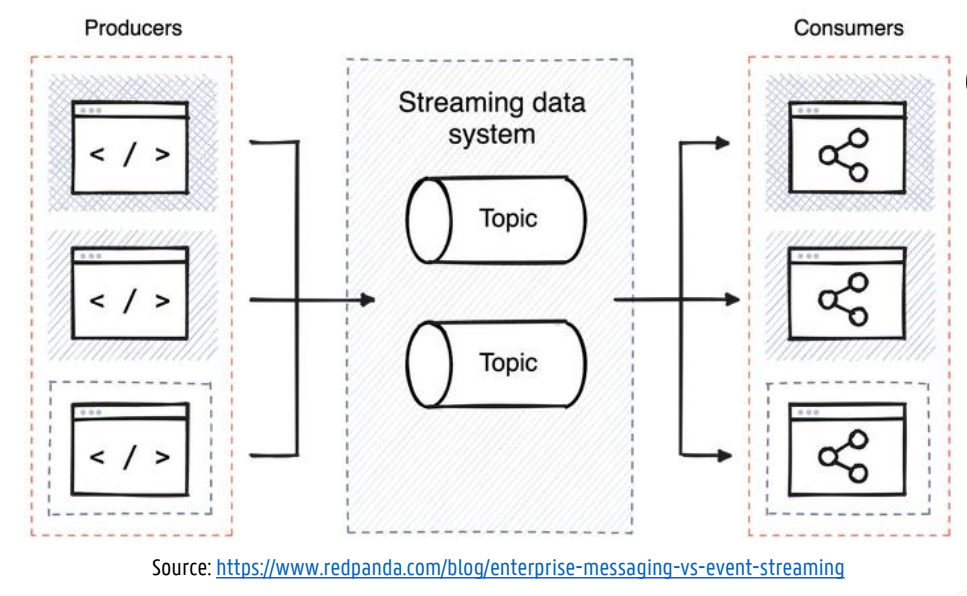
Batch: file is written once and then potentially read by multiple jobs
Streaming: an event is generated once by a producer (a.k.a. publisher or sender) and then potentially processed by multiple consumers (a.k.a. subscribers or recipients)
In a streaming system related events are usually grouped into a topic or stream
Stream Processing
messaging systems
2 questions/dingen die fout kunnen lopen
Producer sends message containing event
Event is pushed to consumers
Typically, multiple producer nodes send messages to the same topic and allow multiple consumer nodes to receive messages in a topic
Topic = named logical channel providing a logical grouping of events
Messaging system implementations differ based on two questions
What if producers send messages faster than consumers can process them?
System can drop messages
Buffer messages in a queue
Does the system crash if queue no longer fits in memory? Does it write messages to disk? How does disk access impact performance?
Apply backpressure (a.k.a. flow control), blocking producer from sending more messages
What if nodes crash or temporarily go offline – are any messages lost?
Durability may require combination of writing to disk and / or replication
If possible to sometimes lose messages, able to attain higher throughput and lower latency
Stream Processing
direct messaging systems
message brokers
DIRECT MESSAGING SYSTEMS
A number of messaging systems use direct network communication between producers and consumers without going via intermediary nodes
StatsD and Brubeck use unreliable UDP messaging for collecting metrics from machines on the network
UDP multicast is widely used in the financial industry for streams such as stock market feeds
Brokerless messaging libraries such as ZeroMQ and nanomsg take a similar approach, implementing publish / subscribe messaging over TCP or IP multicast
webhook
If consumer exposes a service, producers can make a direct HTTP or RPC request to push messages to the consumer
Pattern in which a callback URL is registered with another service (which calls this URL whenever an event occurs)
Direct messaging systems generally require application code to be aware of potential message loss
Notable direct messaging protocols: AMQP (Advanced Message Queuing Protocol), JMS (Java Message Service)
MESSAGE BROKERS
Alternative to direct messaging: send messages via a message broker (a.k.a. message queue)
Essentially a DB optimized for handling message streams
Runs as a server with producers and consumers connecting to it as clients
By centralizing data in broker
Able to more easily tolerate clients that come and go (connect, disconnect, crash)
Question of durability is moved to broker
Some message brokers only keep messages in memory, others write them to disk
Events are typically unbounded queued (as opposed to dropping messages or backpressure)
Limited by resource constraints
Consumers are generally asynchronous: when a producer sends a message it only waits for confirmation from the broker
Stream Processing
logs for message storage
figuur!
Log: append-only sequence of records on disk, can be used to implement a message broker
Producer sends message by appending to end of log
Consumer receives messages by reading log sequentially
If consumer reaches end of log → waits for notification that new message has been appended
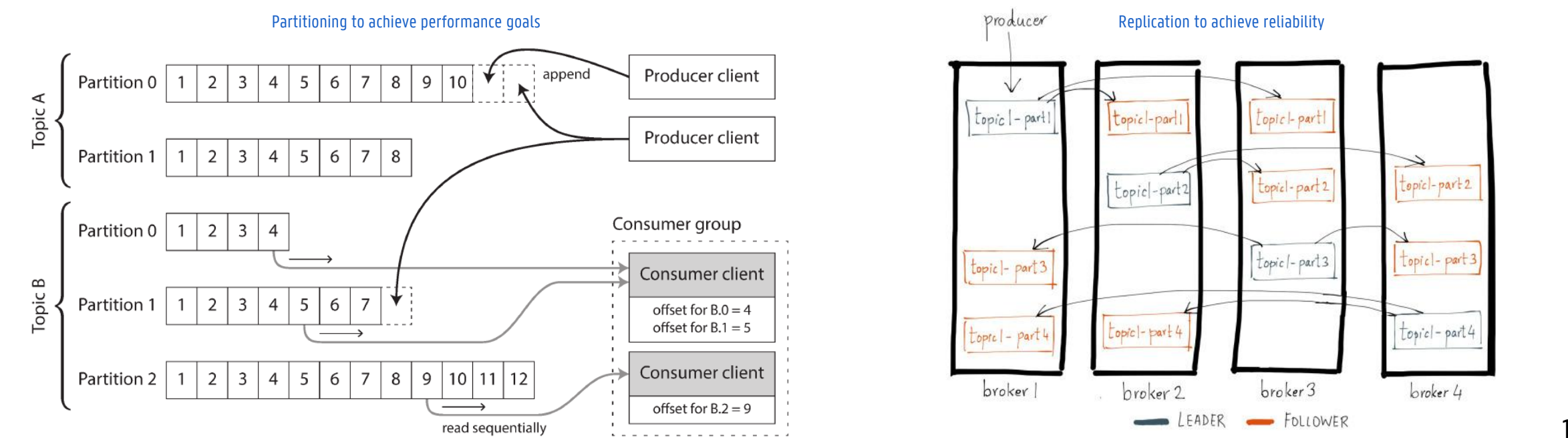
To scale to higher throughput than single disk can offer, log can be partitioned
Different partitions can be hosted on different machines → separate log read and written independently from other partitions
A topic can be defined as a group of partitions that all carry messages of the same type
Within each partition the broker assigns an increasing sequence number (a.k.a. offset) to every message
Within a partition: messages are totally ordered
Across different partitions: no ordering guarantees
Apache Kafka
figuur
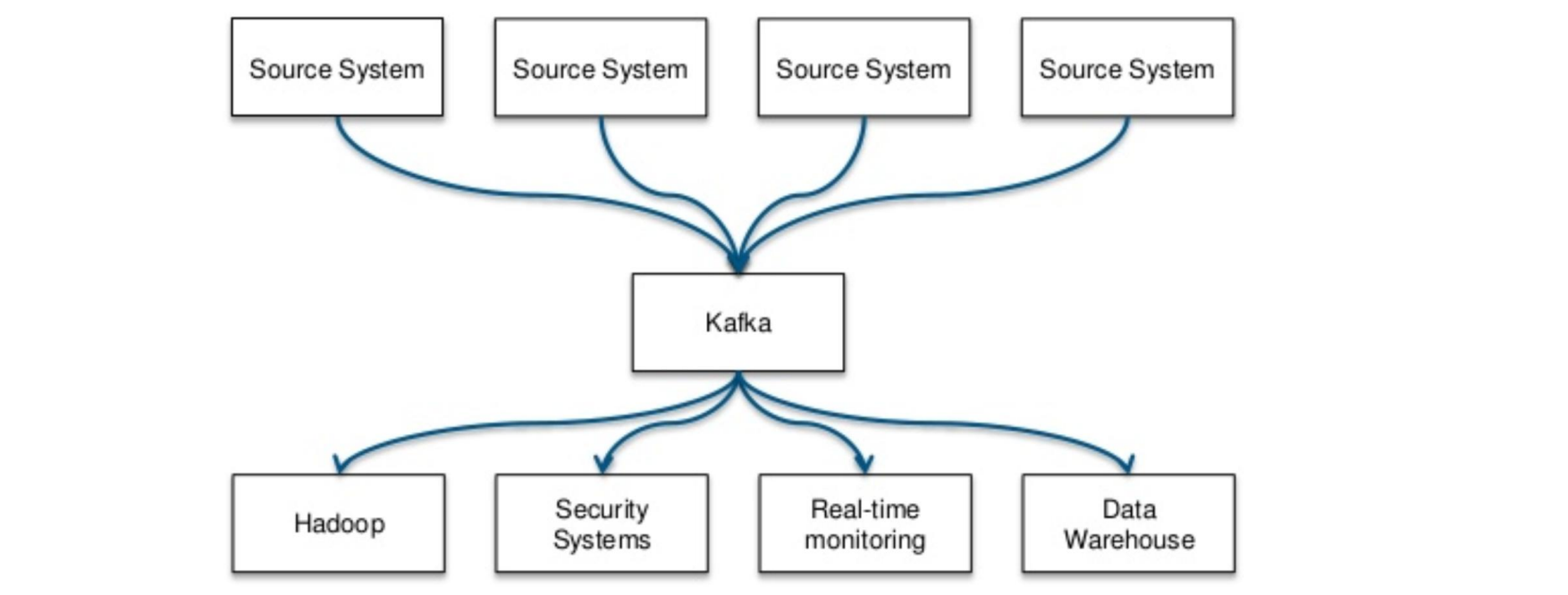
Apache Kafka
Distributed streaming platform
Decouples data pipelines
Originated at LinkedIn, Open-sourced through Apache, commercially exploited by Confluent
wil van dit
naar dit
Apache Kafka
concepts and properties
figuur
Topics: categories that maintain streams of records (key, value, timestamp)
Producers: message-generators that publish stream of records to topics
Consumers: message-processers subscribe to topics
Connectors: connect topics to existing applications or systems (e.g. connector to relational database capturing every change)
Stream processors: consume input stream from one or more topics and produce output stream to one or more topics
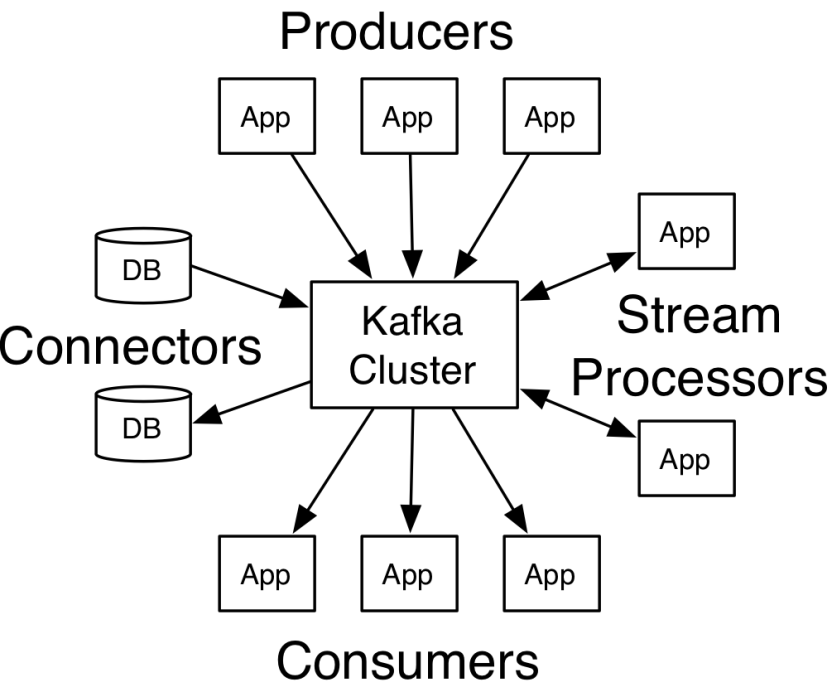
properties
kafka itself run as a cluster on one or more servers (brokers)
High performance (throughput & latency)
Fault-tolerant and durable by design (via replication)
Apache Kafka
topic partitions
figuur
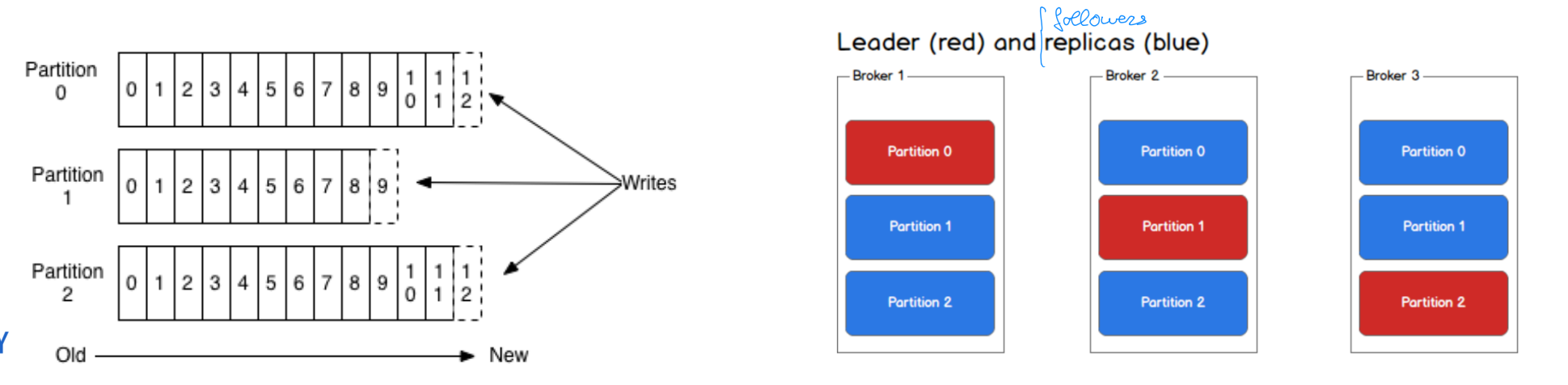
Topics broken into ordered commit logs called partitions
Records in a partition get a sequential ID (offset)
Data retained for configurable period, whether or not they have been consumed e.g. two days (longer = more resources)
Ordering only guaranteed within a partition
Group messages in partition by key (e.g. producer)
Configure one consumer instance per partition
Guarantees
Messages sent by a producer to a topic appended in the order they are sent
For a topic with replication factor N, Kafka tolerates N-1 server failures without losing any messages committed to the log
In-sync partition replicas = not too far (configurable distance) from partition leader
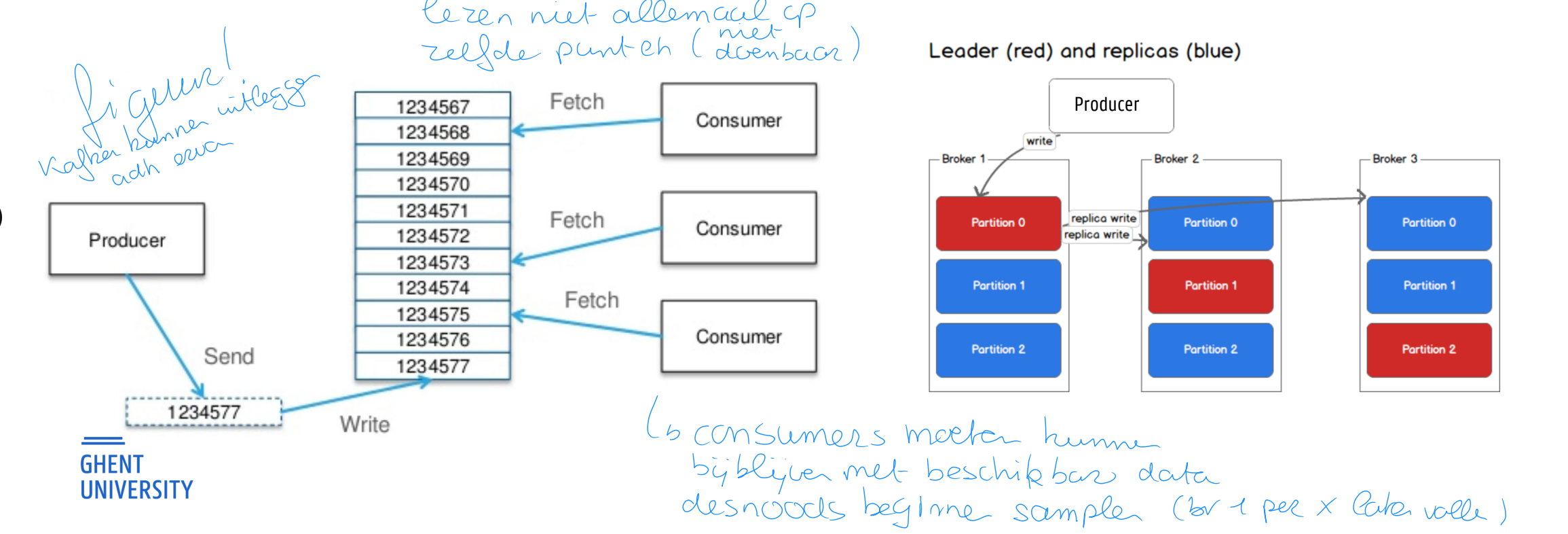
Apache Kafka (EX)
Producers en consumers
figuur!
PRODUCERS
Publish (push) to a topic of their choosing
Load distribution over topic partitions
Round-robin
Based on key in the message
CONSUMERS
Multiple consumers can read from the same topic
Each consumer manages own offset in topic
Messages stay on Kafka for the configured retention period (even if read by consumer)
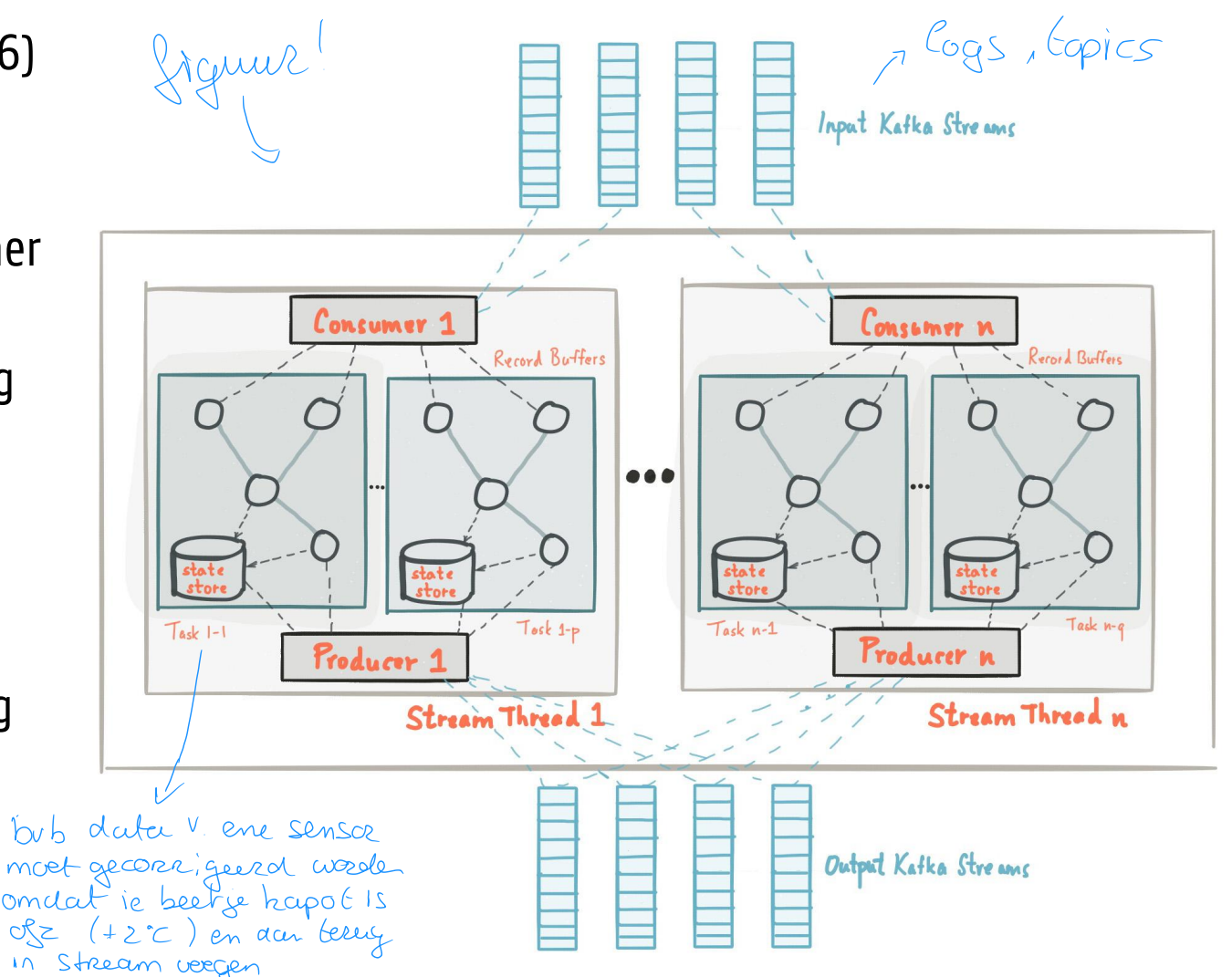
Apache Kafka Streams (EX)
figuur
Newer Kafka feature (introduced mid 2016)
Lightweight Java library for building streaming applications
No external dependencies on systems other than Kafka
Horizontal scaling: handles load balancing multiple instances of the streaming application
Supports fault-tolerant local application state
Supports one-record-at-a-time processing (ms latency) and event-time based windowing operations
Apache Kafka Streams (EX)
stream concepts
figuur
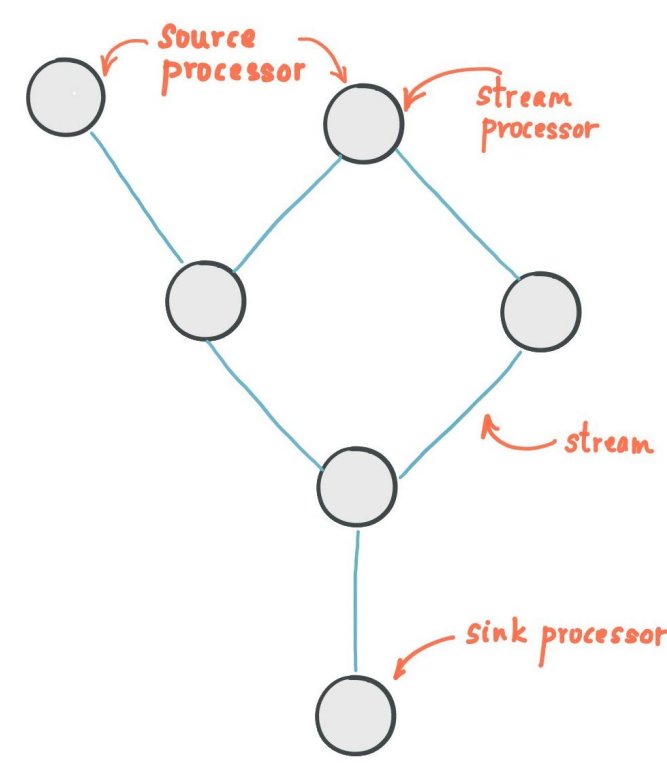
Stream: unbounded continuously updating data set
Ordered, replayable and fault-tolerant sequence of immutable data records (key/value pairs)
Stream processing application: defines computational logic through one or more processor topologies (graph of stream processors (nodes) connected by streams (edges))
Stream processor: node in the processor topology, transforms data by receiving one input record at a time from upstream processors, applying its operation to it, and producing one or more output records to downstream processors
Source processor: does not have any upstream processors, consumes records from Kafka topics
Sink processor: does not have downstream processors (processed results streamed back to Kafka or written to external system)
Operations like map, filter, join, aggregations supported out of the box
Apache Kafka streams (EX!!)
voor en nadelen

Apache storm
algemeen
figuur
Operates on streams: unbounded sequence of tuples (key-value pairs)
Fast and scalable
Million 100-byte tuples processed per second per node (on 2x Intel E5645@2.4Ghz, 24GB RAM)
Thousands of workers per cluster supported and on-the-fly node additions supported
Fault tolerant
When workers die, Storm will automatically restart them
If a node dies, the worker will be restarted on another node
Reliable
Guaranteed message delivery
Every tuple will be fully processed (at-least-once) -> verklapt beetje leeftijd

Apache storm
werking
figuur
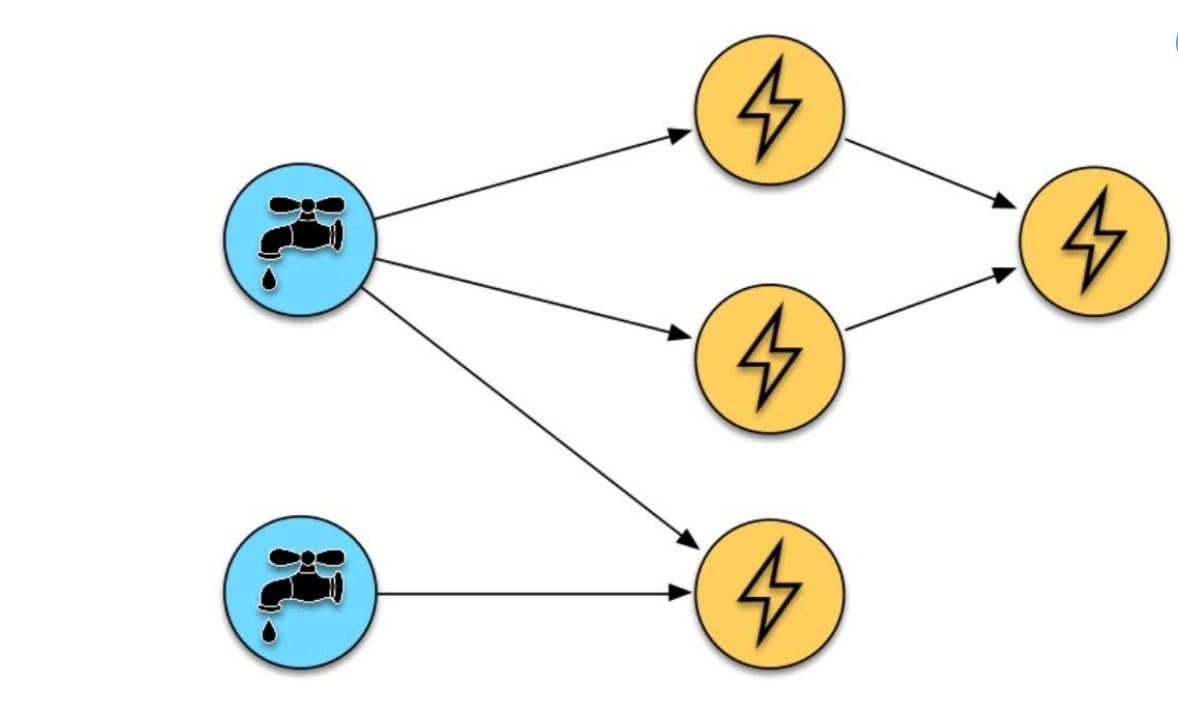
Spout
"Geef my tuples"
Tuples: key-value pairs, each value of any type
Streams = sequence of tuples
Spout = source of streams, ingests data (e.g. Kafka, files, Amazon Kinesis, Redis)
Bolts
"doet iets met tuples"
Core function of a streaming computation
Receive tuple, process it (transform, aggregate, analyze) and optionally emit new tuples
Can
Read/write from/to a data store (MongoDB, Cassandra, RDBM, etc.)
Perform computation (filter, join, etc.)
topologie: Directed Acyclic Graph (DAG) representing flow of data in the application
Apache storm
reliability
figuur
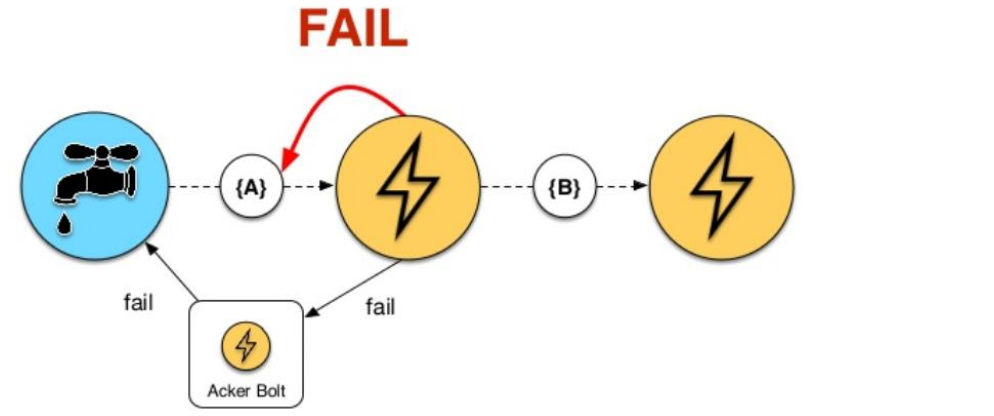
Storm automatically adds reliability measures
If any tuple of the tree is not marked as processed within a time-out, Storm will replay the tuple starting from the spout: at-least-once processing
Apache Storm Trident
Higher level micro-batch system built on Storm (also developed by Twitter)
Simplifies DAG topology building
Adds windowing, aggregations, state management (on top of database or persistent store)
Adds ‘exactly once’ processing as opposed to ‘at least once’ in Storm
Useful when dealing with state (e.g. Tuple processed by bolt that increments a value in a database)
Due to micro-batching and state → latency higher than pure Storm
Lagging behind modern streaming approaches (SparkStreaming, Flink, Kafka Streams)
Apache Storm (EX)
voor en nadelen
voordelen:
Very low latency, true streaming, high throughput
Good for non-complicated streaming use cases
nadelen:
No implicit support for state management, time windowing, etc.
Managing a Storm cluster challenging compared to Kafka streams or Flink
At least once guarantees only
Started to lag behind more modern options like Apache Spark / Apache Flink which are typically better integrated in cloud-native systems (gedateerd platform)
Apache Spark Streaming
algemeen
figuur
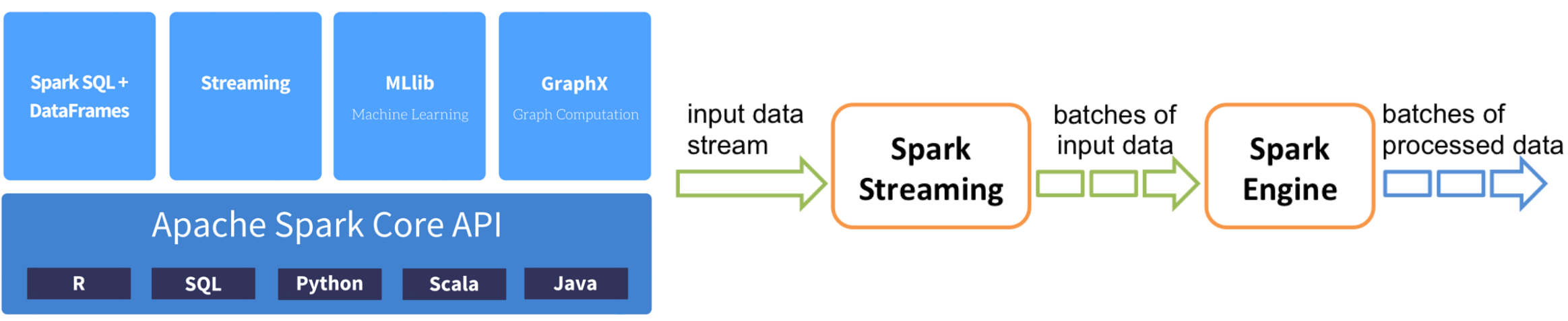
Part of the Apache Spark ecosystem
Processes data as streams (called Discretized Streams or Dstreams)
Divides stream into microbatches
Pre-defined interval (N seconds)
Treats each minibatch as a Spark RDD (Resilient Distributed Dataset)
Can use all Spark batch functionality on microbatches (map, filter, reduce) and sliding time window operations
At-least-once guarantees (toont opnieuw beetje de age)
In-use by a.o.
Uber (real-time telemetry analytics)
Netflix (real-time online movie recommendation and data monitoring solution)
Apache Spark Streaming (EX)
voor en nadelen
voordelen:
High throughput, good for many use cases where ms-latency is not required
Fault tolerance
High level APIs (map, join, filter, time windows)
Big and active Spark community
nadelen:
At least once, can offer exactly once depending on source /
Latency due to micro-batch model
Considered legacy, superseded by Apache Spark Structured Streaming
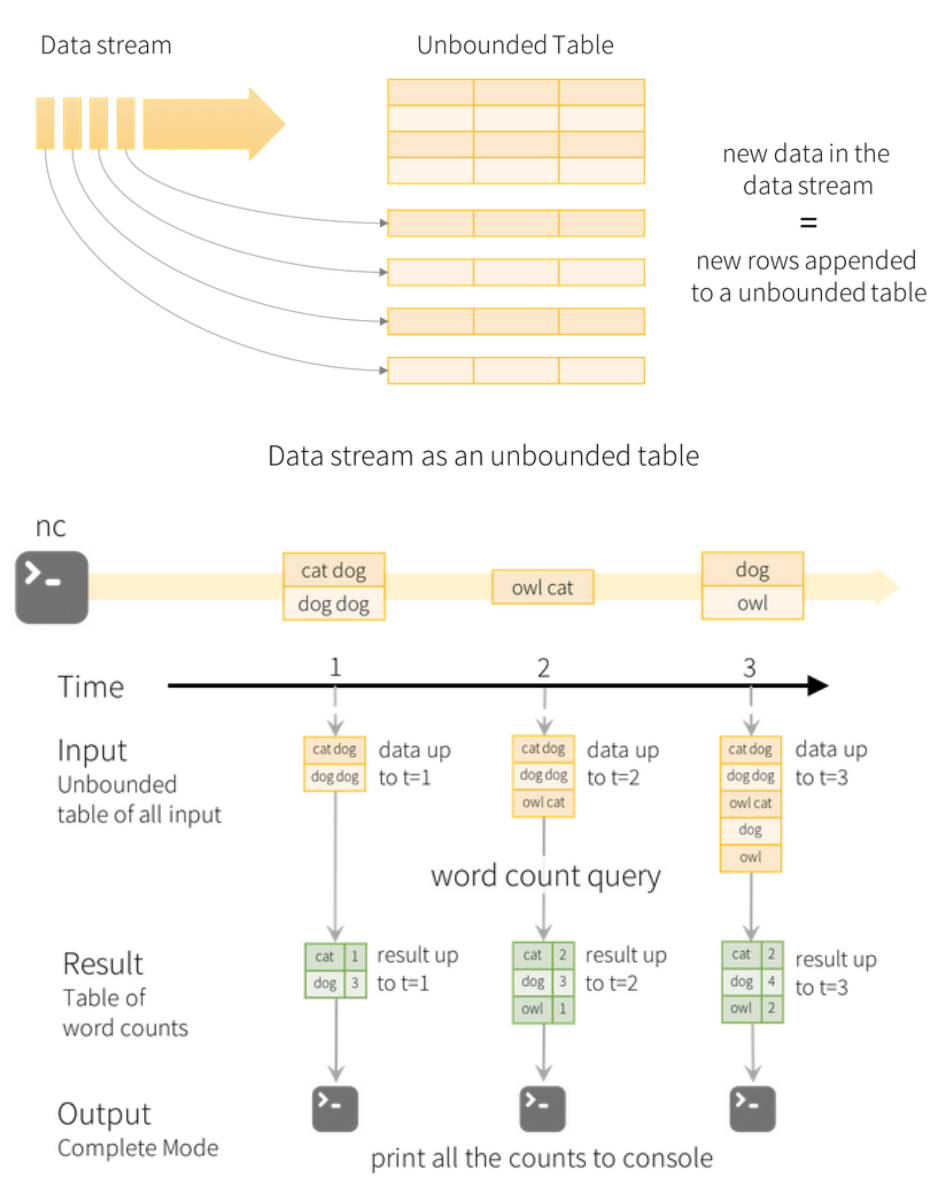
Apache Spark structured streaming
figuur
Introduced in Spark 2.0 and built on Spark SQL
Processes data as unbounded tables – continuously updated as new data arrives
Input from Kafka, sockets, files, HDFS, custom sources...
Unified API for both (micro-)batch and true streaming processing
Extends DataFrame and Dataset APIs
Allows using SQL-like queries on data (higher-level than Apache Spark streaming)
Event-time processing: processing can start per record that enters the system
Exactly once processing
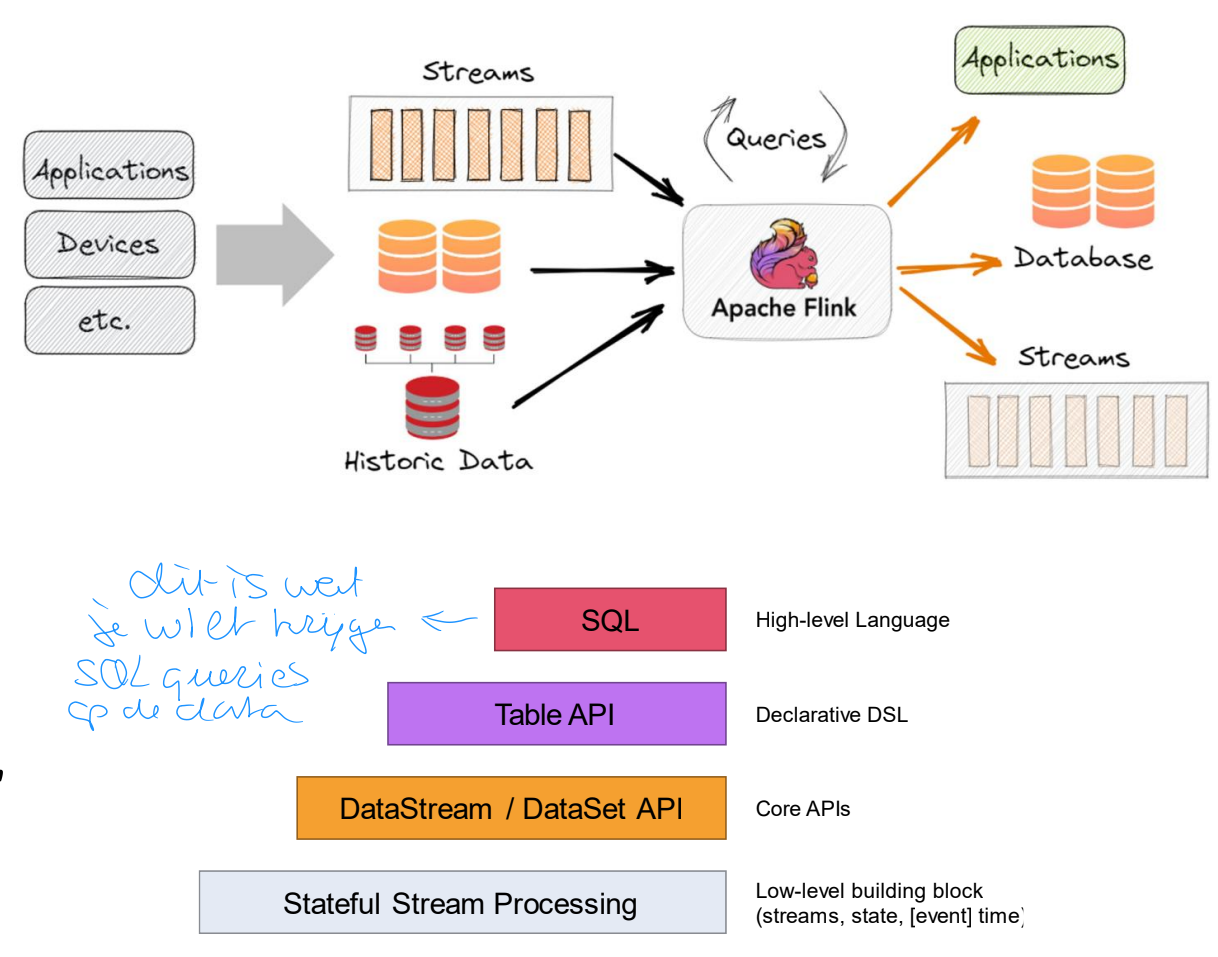
Apache Flink
algemeen
figuur
Modern distributed streaming dataflow engine
Support for batch and stream processing programs
In-memory, with disk spillover if needed
Both bounded and unbounded streams
Unbounded stream: start but no defined end
Bounded stream: defined start and end (batches)
Reliability model: exactly once
Managed state: application state is stored on processing nodes and distributed/made fault-tolerant
Fault tolerance: lightweight distributed checkpoints
Data source and sink connectors to Amazon Kinesis, Kafka, HDFS, Cassandra, etc.
Runs as a distributed system on most cluster-types: standalone, YARN, Mesos, Kubernetes
Notable deployments: Alibaba, Huawei, Ebay, Ericsson, Zalando
Apache Flink (EX)
voor en nadelen
voordelen:
Leader of innovation in open-source streaming
Batch and streaming all in one framework with similar APIs
True streaming possible with advanced features (per-event processing, watermarks to handle out of order data, etc).
Low latency with high throughput, configurable to meet demands
Exactly once
Getting large operational deployments (Uber, Alibaba)
nadelen:
Spark has a larger ecosystem and is considered more mature
Spring Cloud Dataflow
algemeen
Data processing pipeline that uses Spring Boot microservices
Each microservice takes in a message, processes it and produces a message
Spring Boot = JVM framework for building microservices
Open-source, Java-based
Spring Cloud Dataflow
designing a data processing pipeline
uitleg adhv vb twitter hashtags
figuur!
Understand source data
What does an invididual message contain? → a single tweet
Understand the function of your pipeline
What do you want to filter? → a set of hash tags in the body of a Tweet
Understand what you want to measure
Trending analytics in real time
Understand the output
The velocity of hash tag counts from specific tweets every second
What is the result of our measurements
Real time streaming analytics to make informed decisions
A graph showing the velocity of each tweet and its hash tags over time
NPUT AND OUTPUT CHANNELS
Spring Boot Microservice
TWEET SOURCE MODULE
Ingest data from multiple sources
Streaming REST API
HDFS
Transform a stream into discrete messages
E.g. individual Tweets
Output those messages to an output channel for next service to process
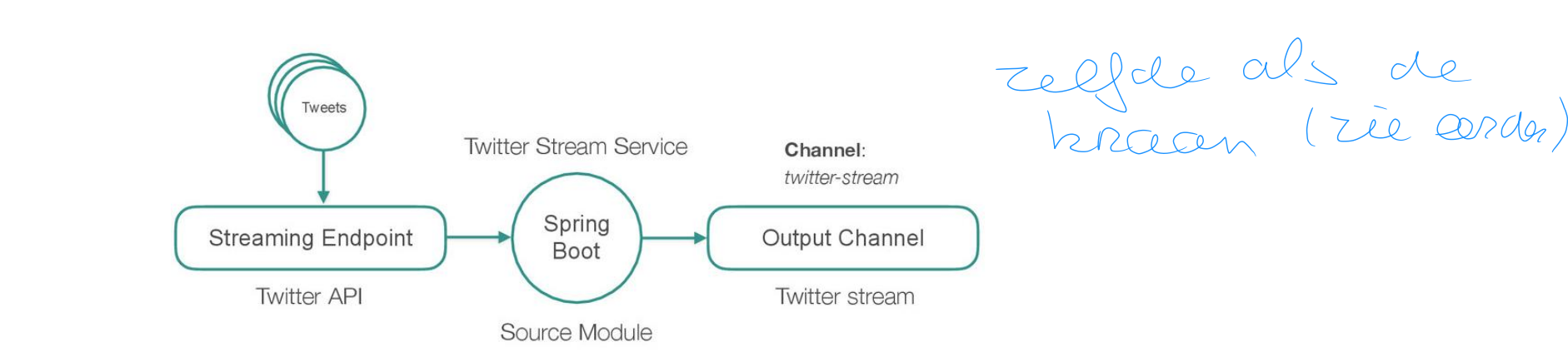
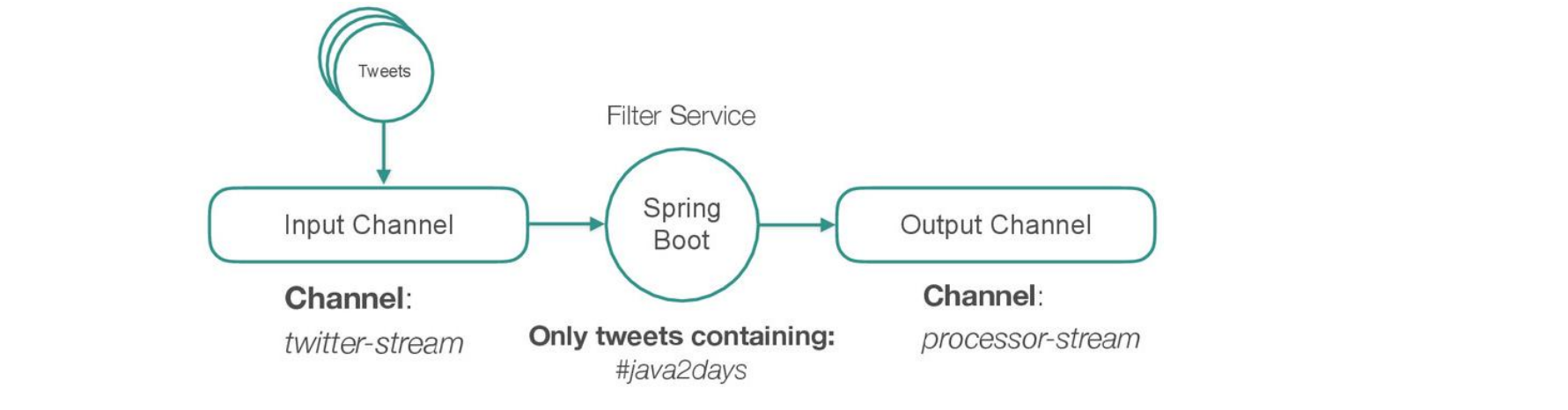
FILTER MODULE
Filter messages from source module
Filter noise to increase quality of measurements in downstream modules
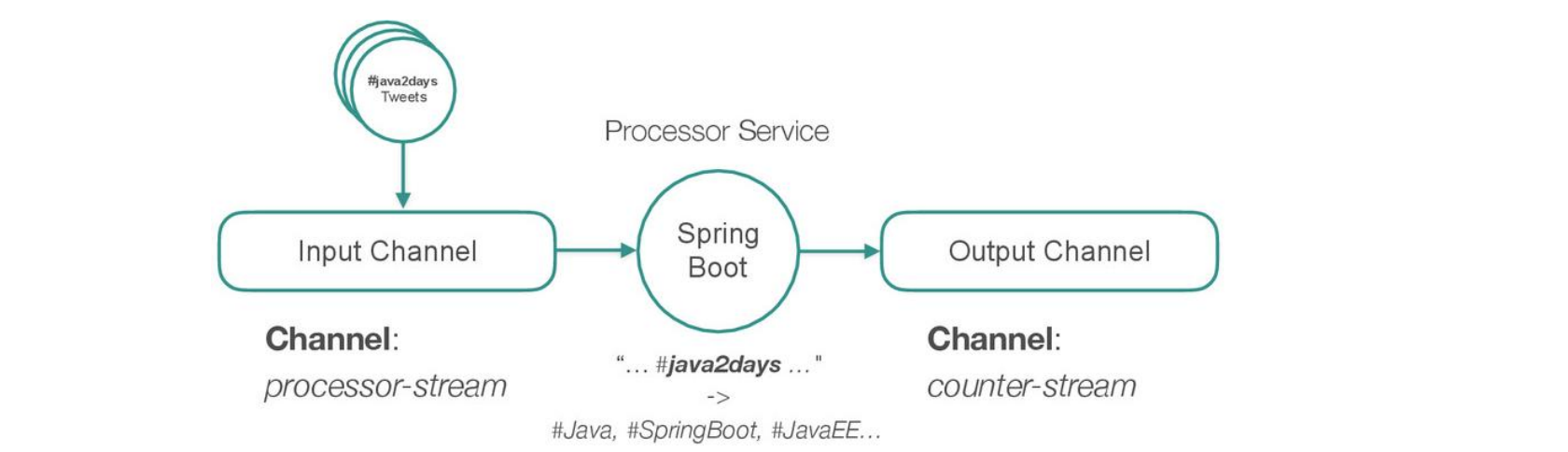
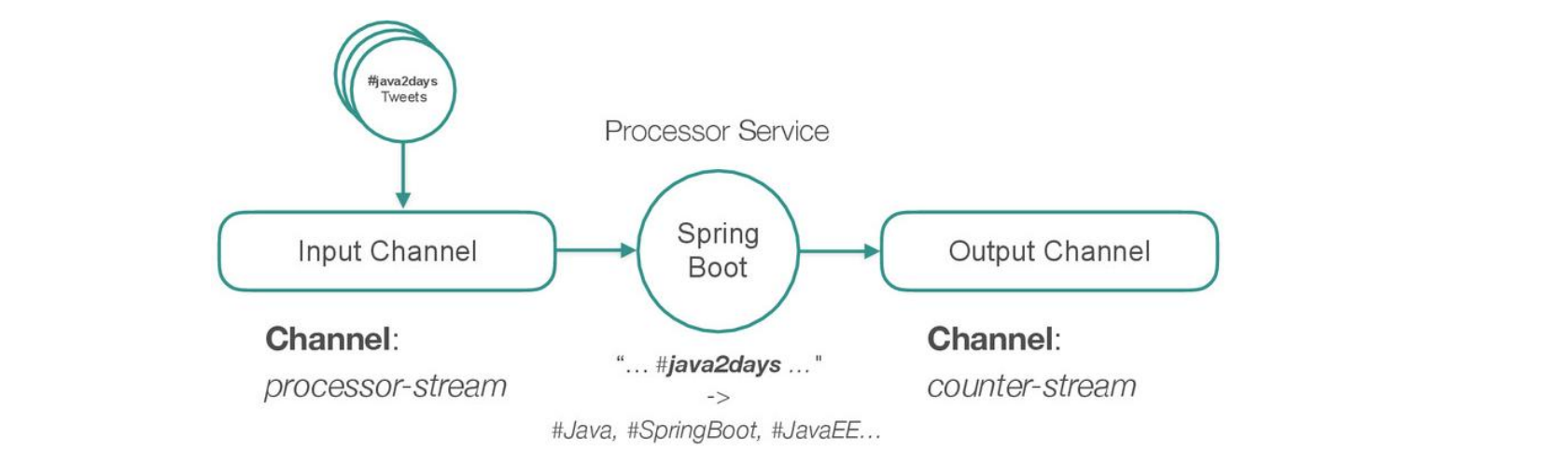
PROCESSOR MODULE
Take filtered stream of messages
Produce multiple output messages by transforming the payload into multiple dimensions of attributes
Example: take #java2days tweet and parse other hash tags, output one message per hash tag
#java2days -> #Java, #SpringBoot, #JavaEE
COUNTER MODULE
Take messages from input channel
Output an increment to multiple buckets that count message attributes over time
Save the results to a sink (e.g. database)
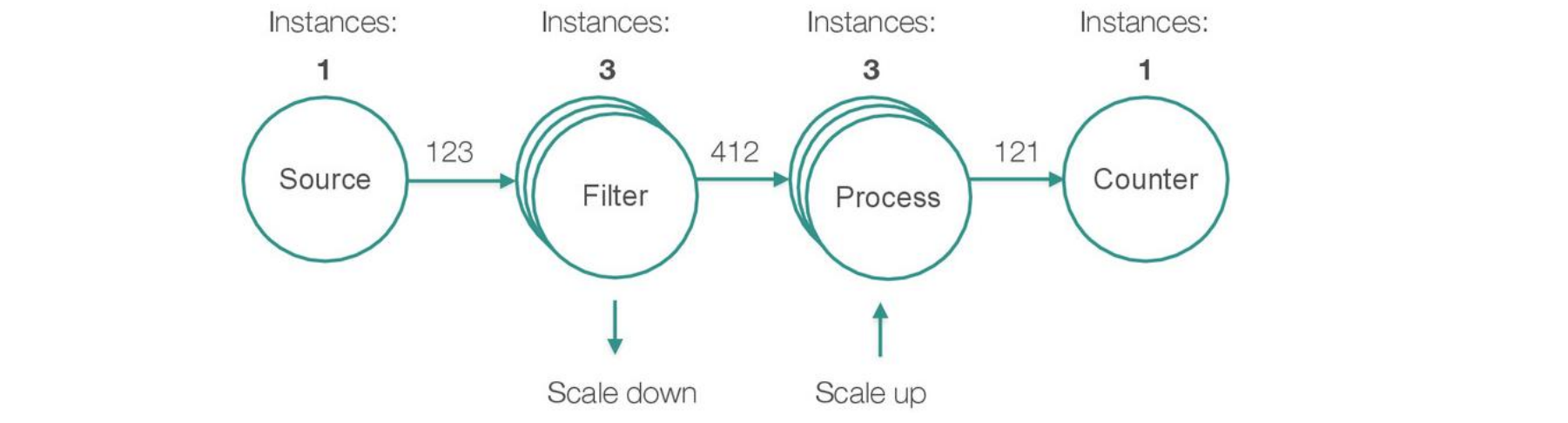
CALING THE PIPELINE
Services in the pipeline can be scaled up and down automatically to handle the load
Can be deployed on YARN, Kubernetes, Mesos, Pivotal Cloud Foundry, etc.
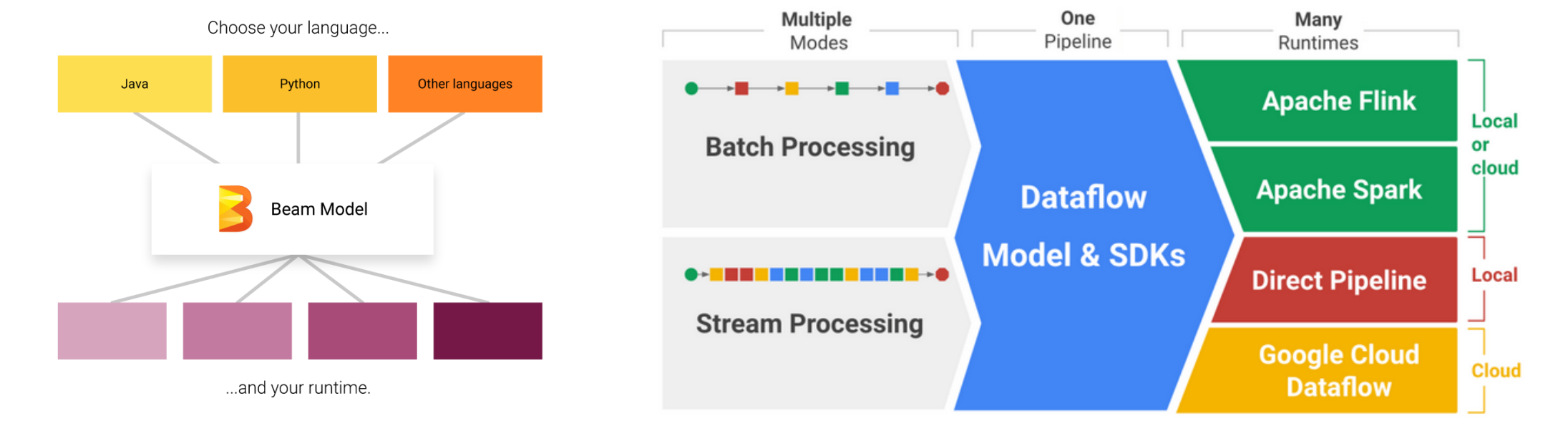
Apache Beam
Attempts to avoid platform lock-in
Create data processing pipelines and deploy to a runner of your choosing: Apache Flink, Apache Spark, Apache Samza, Google Cloud Dataflow, etc.
Use a single programming model for both batch and streaming use cases (Java, Python or Go)
Supports advanced features like windowing, watermarks
Ontwikkeld door Google
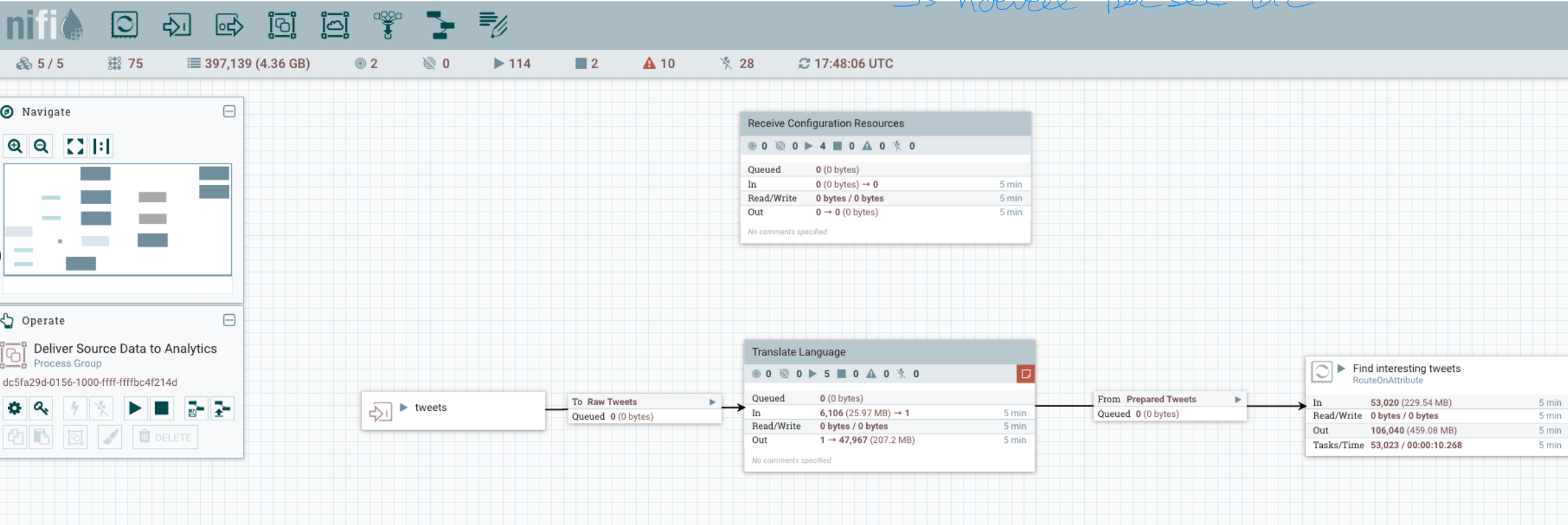
Visual dataflow management
apache nifi
Data integration tool for automating the movement of data between different systems
Web-based visual management of data flows (e.g. streaming data pipelines, ETL)
Move and track provenance of data (with a focus on performance of each step)
Integrates with other frameworks (Flink, Spark, Kafka) for computationally heavy tasks
Originated at NSA intelligence gathering
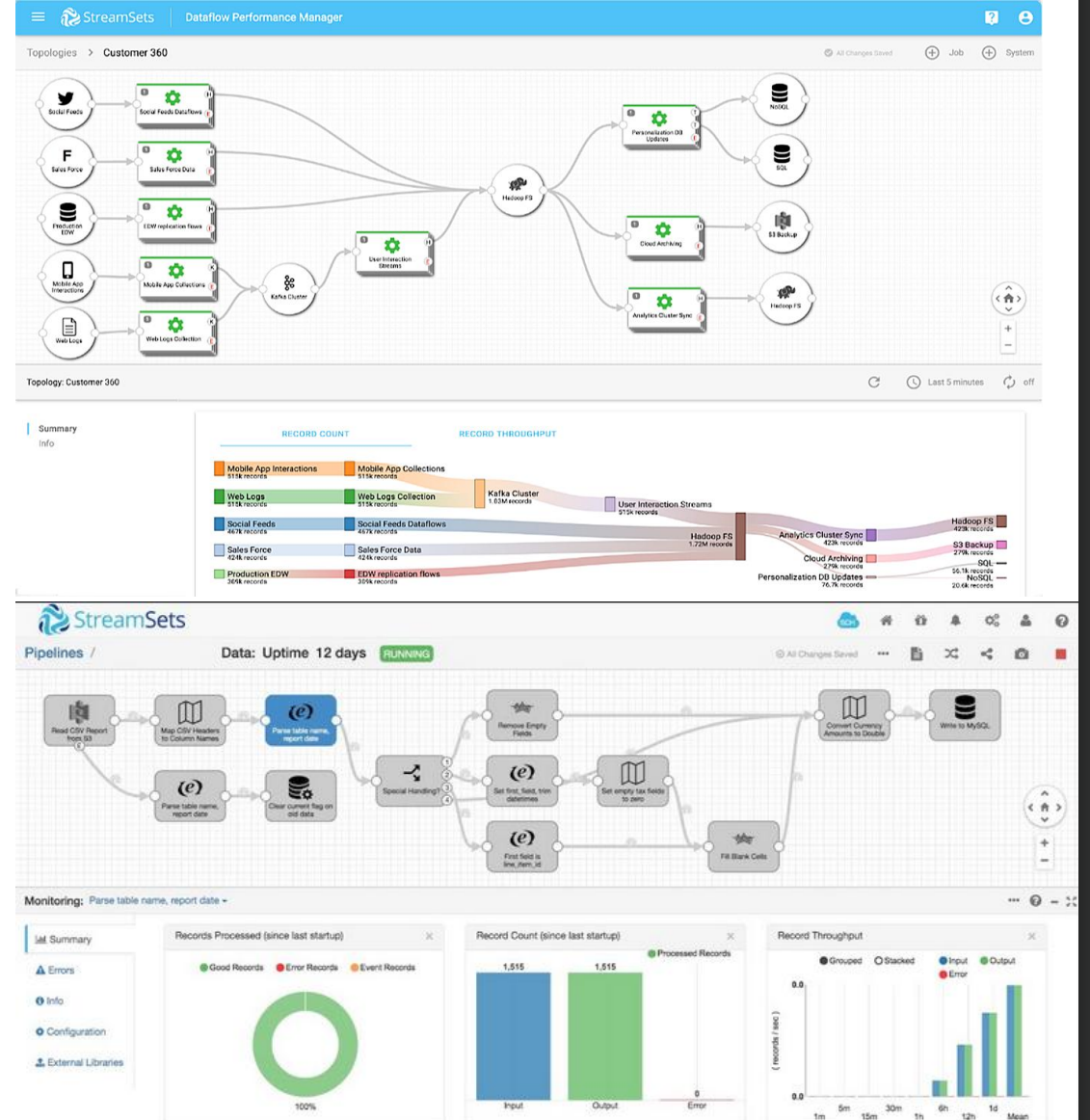
Visual dataflow management
IBM Streamsets
Data integration platform to build, deploy and operate data pipelines
Web-based visual management of dataflow performance
Drag-and-drop interface for creating pipelines
Connectors to Kafka, AWS S3, BigQuery, Snowflake, HDFS, etc.
Hoe kies je beste streaming framework
Depends on use case: if simple, no need to go for the latest / greatest framework if complicated to learn or deploy
Kafka streams
Future considerations: potential need for advanced features (event time processing, aggregation, watermarking, exactly once, SQL-like query language)?
Storm has no notion of state
Spark Structured Streaming or Apache Flink good candidates
Bear in mind community adoption and evolution of chosen framework
Existing technology stack
Do you already use Kafka? Kafka Streams or Samza may be an easy fit
Do you already use Spark? Spark Structured Streaming may be a natural fit