Computational Models of reading
1/30
Earn XP
Description and Tags
ND Lectures 1 & 2
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
31 Terms
What is reading?
A form of information processing where print is transformed to speech and/or meaning
Who proposed two modes of reading aloud?
Originally suggested by de Saussure in 1922, then this idea was presented again by Forster & Chambers in 1973 causing this notion to gain prominence in research
What are the two routes of reading?
The lexical and non-lexical route
What is the non-lexical route?
Describes reading aloud through mapping graphemes and aspects of orthography (how a word is written) to the corresponding phonology (how it sounds)
The sound form of words are accessed through processing the sounds of individual letters or groups of letters that form phonemes
What is the lexical route?
Involves accessing the sound form of a word through its representation in long-term memory, where information about its meaning and pronunciation are retrieved
Requires recognition of the word, and its encoding in long-term memory, once a word is represented in LTM, its retrieval is fairly easy and automatic
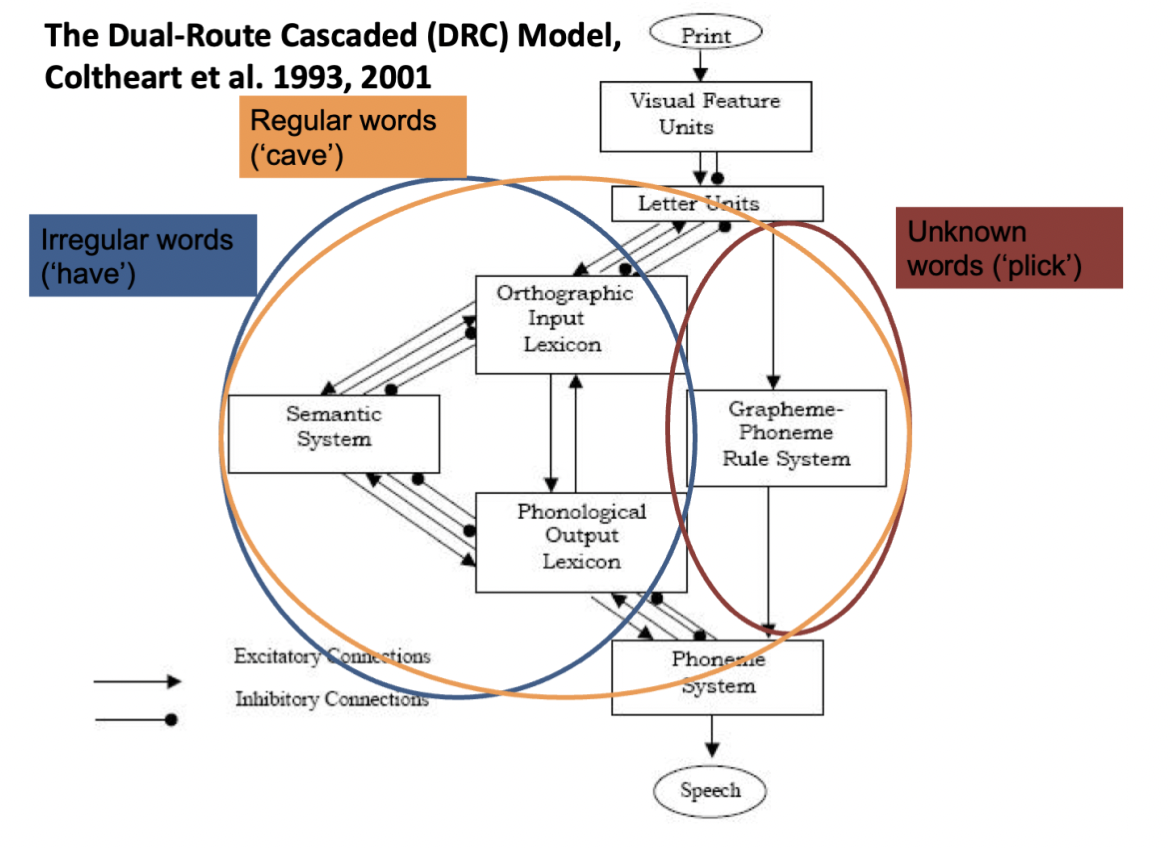
Who proposed the Dual-Route Cascade (DRC) model?
Coltheart and colleagues (1993, 2001)
What does the DRC propose?
This model proposes a dual route approach to reading aloud: a lexical route that involves a lexicon and semantic system and a non-lexical route that relies on a grapheme-phoneme mapping system
Together these two routes can work together to correctly pronounce regular, irregular, unknown and non-words
This model relies both on excitation and inhibition, as well as feedforward and feedback influences
What is the non-lexical route in the DRC?
This route involves transforming letters or groups of letters into sounds using LTM of these mappings, then building these sounds to create a final pronunciation
applies rules of grapheme to phoneme correspondence rules to convert letters into sounds
this is achieved in a serial fashion
What types of words can the non-lexical route successfully read?
Regular words
using the GPC rules to derive pronunciation
Novel or non-words
uses GPC rules to approximate a pronunciation for a new word or even a non-words
What types of words can the non-lexical route not read?
Irregular words
this is because the GPC rules in the non-lexical route are for the regular correspondences, not for exceptions to these rules
This can result in the regularisation of irregular words, known as regularisation errors
What is the lexical route in the DRC?
In this pathway, readers recognise the word they are reading and access its pronunciation and meaning through representations in long-term memory
Representations in the orthographic input lexicon are accessed, which activates the corresponding node in the phonological output lexicon allowing for access to the word’s phonemes
Meaning can be accessed via the semantic system
What types of words can the lexical route read?
Regular words
represented in the lexicon and semantic system
Irregular known words
the irregular pronunciation is encoded in the lexicon and meaning in the semantic system
What word types can the lexical route not read?
Novel or non-words
there is no representation for new or non-words in the lexicon or semantic system
What is the role of excitation and inhibition in the DRC?
There are excitatory and inhibitory connections across the DRC
Excitatory connections allow one representation to activate compatible representations at the next level as well as (sometimes) the preceding level
Inhibitory connections do the opposite, allowing representations to suppress incompatible representations
What is an example of feedforward influence in the DRC?
If letter unit detectors see and recognise the letter P in a word string, the letter unit for P will activate all of the words in the input lexicon that contain P via excitatory connections and suppress those that do not by inhibitory connections
What is an example of feedback influence in the DRC?
The word pen in the input lexicon activates the letter units P, E, N using excitatory connections but suppresses all other letters that word does not contain using inhibitory connections
This is word memories (e.g., past experience) dictating what letter you should see and can be useful in some instances such as when the font is ambiguous for certain letters
How does processing in the DRC occur?
The model makes no prior decisions about which route reads a particular word once it is identified, instead the pronunciation and meaning are extracted from the outputs of both routes
this can explain why some non-words can evoke lexical and meaning activation if they are more similar to certain words
if a non-word is similar to an irregular word, they may evoke the same irregular pronunciation despite having no representation in LTM, for example, FINT is more likely to be read using the pronunciation of PINT than MINT
There is no race between routes to produce a pronunciation, except when reading under time pressure
under these conditions individuals may make regularisation errors, but also mistake non-words for an existing word
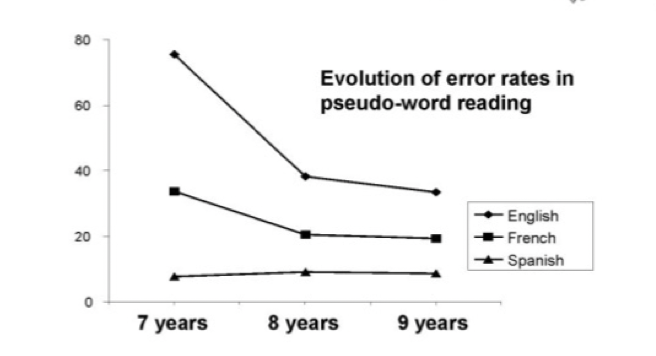
How do differences in the structure of languages affect aspects of the DRC?
Children learning languages that have more irregular cases or less clear rules about grapheme and phoneme conversions will take longer to learn these sets of correspondences
Examples of these languages are English, French, Danish
In contrast, learning transparent languages, where letters always correspond to the same sound takes less time as exceptions do not need to be learnt and stored in the lexicon
Examples of these languages are Spanish, Dutch, Italian
As a result, the transparency or opacity of a language can often be indexed by the prevalence of developmental dyslexia, which is greater in opaque languages
How do researchers assess knowledge of print-to-sound correspondences?
Use pseudoword reading
What are some aspects of normal reading that support the DRC?
Words read faster than non-words
High frequency words are read faster than low frequency words
Regular words are read faster and more accurately than irregular words, especially when the irregular word is less frequent
The larger orthographic neighbourhood of a nonword, the faster it is read aloud
Non-words that sound like words are read faster than non-words that do not sound like existing words
Increasing number of letters slows reading of non-words but has little or no effect on reading real words
How does the faster reading of words compared to non-words support the DRC?
This is because reading aloud of words benefit from being supported by the lexical and non-lexical routes whereas non-words must be sounded out in the non-lexical route (unless they are very similar to real words)
How does the faster reading of more frequent words support the DRC?
This is because more frequent words have been more extensively practised, both word recognition in the lexical route and print-to-sound conversions in the non-lexical route are faster and more accurate as a result
How does the faster reading of regular compared to irregular words support the DRC?
This is because irregular words can only be read from the lexical route. Also, for irregular words, the two routes will produce different pronunciations and this conflict takes time to resolve. When irregular words are not very frequent, their representation in the lexicon is fairly weak and this is the only place they are represented, regular words can be read by either route.
How does the larger orthographic neighbourhood of non-words promoting reading support the DRC?
If a non-word is similar to many words, these evoke the input and output lexicons which can help select the correct sounds in the phoneme system
What is a word or non-word’s orthographic neighbourhood?
It describes the pool of existing words that are similar to the target string
For example, mat, rat, cat are all similar for the target string lat
How does faster reading for non-words that sound like words support the DRC?
This is because as soon as pronunciation of a non-word has been computed, recognition using inner speech will activate the existing alike sound knowledge and in return, the existing lexicon entry will confirm the sound form initially derived using the non-lexical route
For example, non-word brane, sounds like brain
How does the number of letters influencing reading speed of non-words only support the DRC?
This is because when reading using the non-lexical route, the word must be segmented into their individual graphemes to obtain individual phonemes and build a plausible pronunciation. This is a sequential process causing longer non-words to take longer to pronounce. For words, the whole word can be processed in one fixation and in one go for the lexical route through parallel processing.
How can irregular words be read in the DRC?
Using only long-term knowledge of the whole word
How can novel words or non-words be read in the DRC?
Using only knowledge of grapheme-to-phoneme correspondences, unless they are similar to an existing word
How can regular, known words be read in the DRC?
Using both routes and there will be no conflict between the outputs of each route
Image of the DRC