L1 Transformers
1/32
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
33 Terms
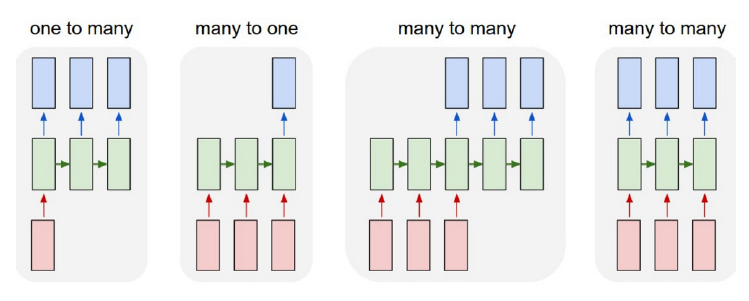
4 types of sequence-to-sequence modeling
One to many: A single input produces a sequence of outputs
→ e.g. image captioningMany to one: A sequence of inputs produces a single output.
→ e.g. sentiment analysisMany to many aligned: A sequence of inputs produces a sequence of outputs of the same length.
→ e.g. video frame classificationMany to many unaligned: a sequence of inputs produces a sequence of outputs, where the input and output lengths can differ.
→ e.g. translation
RNN key concept
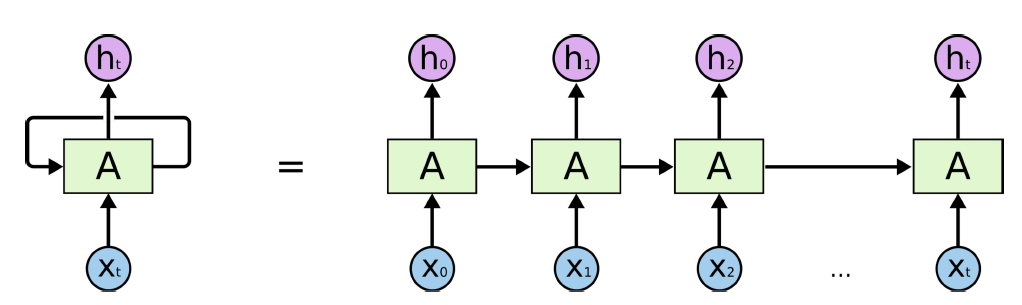
RNNs are neural networks designed to work with sequential data by maintaining a "memory" of previous inputs.
Architecture:
Neurons have connections that form loops.
The same parameters are shared across all timesteps.
An internal hidden state is passed from one step to the next.
RNN use cases
Time series forecasting
Language modeling
Speech recognition
RNN pros and cons
Advantages:
Can process sequential data of arbitrary length.
Retains memory of previous inputs (useful for time series, language data).
Challenges:
Vanishing/Exploding Gradient problem when dealing with long sequences
→ repeated multiplication with W raises the eigenvalues to the power of the sequence lengthStruggles with long-range dependencies due to fading influence of earlier steps.
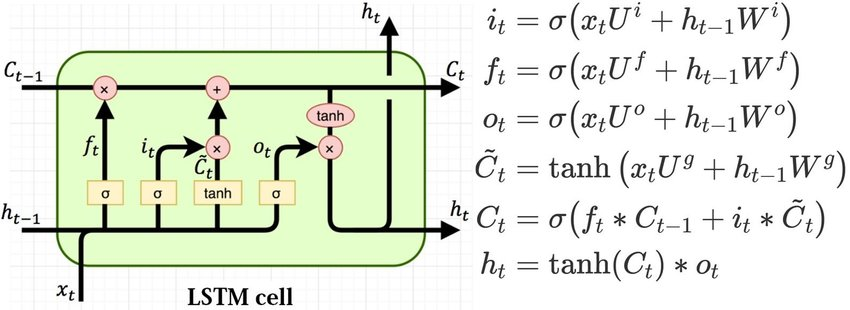
LSTM key concept
LSTM is a special type of RNN designed to overcome the vanishing gradient problem by using memory cells and gates to control information flow.
Architecture:
Contains 3 gates:
Forget Gate: decides what to remove from memory.
Input Gate: decides what new information to add.
Output Gate: decides what to send as output.
Memory cells store information over time, managing long-term dependencies.
Comparison of cell state and hidden state in LSTMs

LSTM use cases
LSTMs excel in scenarios with limited resources, smaller datasets, and short-range dependencies, where the sequential nature of data is inherent and local information is more important.
Time series forecasting (stock prices, weather)
Speech recognition
Anomaly detection in sequences
Small dataset problems
LSTM pros and cons
Advantages:
Handles long-term dependencies better than traditional RNNs.
Effectively solves the vanishing gradient problem
→ uses gating mechanisms to prevent irrelevant information from overwhelming the model
→ additive cell state updates instead of multiplication
Challenges:
Sequential nature slows down training and inference.
Performance declines with very long sequences.
At each step the same weights are used → no positional information
General seq2seq architecture and its problem
Bottleneck problem:
The encoder will have to compress the whole sequence into a single context vector
→ loss of information
→ the decoder will have to reconstruct the whole sequence from this single vector
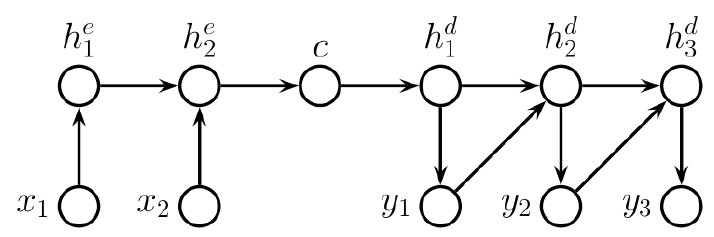
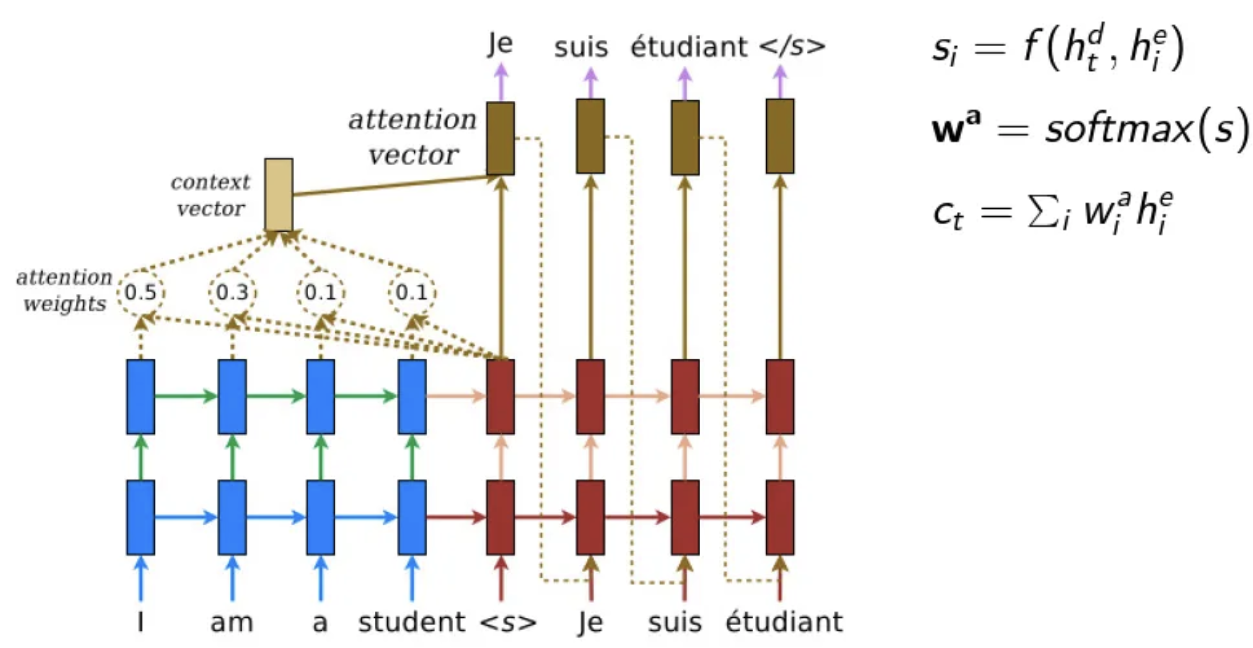
Main idea of attention
Create a unique context vector for each decoding step by giving different importance to encoder outputs:
each step of the decoding has access to the individual encodings of each input word ( = all the encoder outputs get stored)
during decoding, the encoder outputs get queried based on the current decoder state
=> the decoder state is the query, and each encoder output acts as both the key and the valuewe use similarity scores and softmax to determine the weight (attention) of each encoded input, and use their weighted sum as the context vector => the prediction of the next output is based on the combination of the context vector and current decoder hidden state
Transformer key concept
A model architecture based on self- and cross-attention mechanisms, but it completely removes recurrence, enabling parallel processing of sequential data.
Transformer processing types
Temporal: with multi-head attention modules
Positional: adding positional encodings to the input embeddings
Point-wise: with point-wise feed-forward networks to convey information between the dimensions of each vector in the sequence
→ 3-layer MLP with ReLU applied to each vector in the sequence separately, with the same weights
Transformer architecture
Uses Encoder-Decoder structure
Embedding layer: converts the input tokens to a vector representation, then adds them to a positional encoding vector
Encoder:
Multi-head Bidirectional Self-Attention Mechanism
FFN
Residuals (Add, Norm)
Decoder:
Multi-head unidirectional self-attention
Multi-head bidirectional cross-attention: takes the encoded sequence as the key and value, while the query comes from the decoder
FFN
Residuals (Add, Norm)
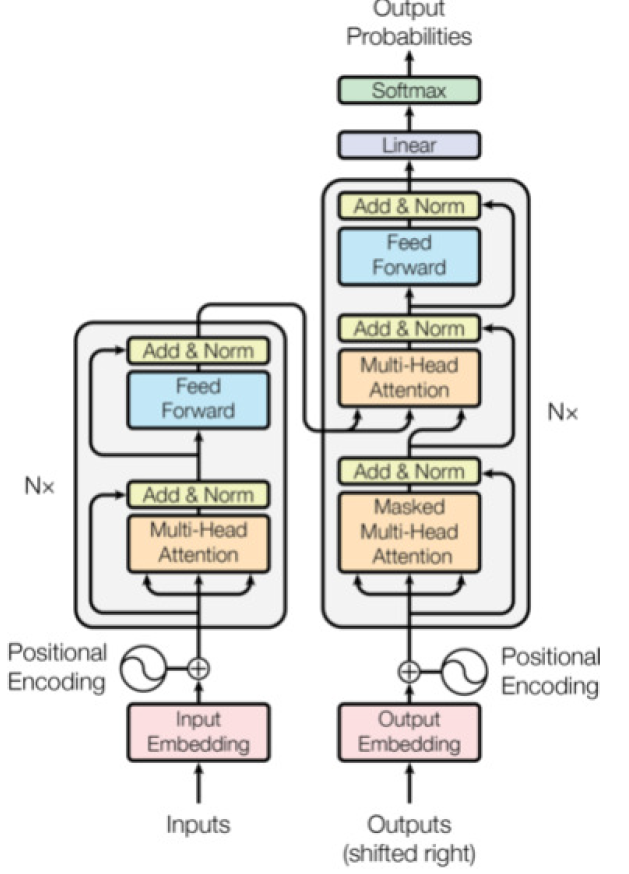
Purpose of each component in the transformer architecture
Input Embedding: Converts discrete tokens (e.g., words) into dense, continuous vectors that encode semantic information for processing.
Positional Encoding: Adds position-specific information to input embeddings, allowing the model to capture the order of tokens in the sequence.
Encoder Self-Attention: Computes contextualized representations for each token by attending to all other tokens in the input sequence, capturing relationships and dependencies.
Encoder Feedforward Network (FFN): Applies position-wise transformations to refine token embeddings with nonlinear transformations and richer representations.
Encoder Output: Provides contextualized embeddings for the entire input sequence to guide the decoder in generating the output.
Decoder Self-Attention: Processes the sequence generated so far, attending only to previously generated tokens (via masking) to build a coherent partial representation.
Decoder Cross-Attention: Aligns the decoder's partial sequence with the encoder's output, capturing input-output relationships and guiding the next token prediction.
Decoder Feedforward Network (FFN): Refines the decoder's intermediate representations for the current token to improve predictive accuracy.
Final Linear Layer: Maps the decoder's output embeddings to logits over the vocabulary, representing scores for each possible token.
Softmax Layer: Converts the logits into probabilities, enabling the model to predict the most likely next token.
Transformer use cases
NLP tasks (e.g., translation, text generation, language modeling)
Large-scale data applications (e.g., BERT, GPT models)
Vision tasks (e.g., Vision Transformers for image classification)
Transformers pros and cons
Advantages:
Solves the bottleneck problem of LSTMs → has access to all encoder hidden states, the representation doesn’t get reduced to a fixed single context vector
Handles long-range dependencies well via self-attention.
Highly parallelizable = faster training
Effective with long sequences and large datasets.
Challenges:
Memory and computationally intensive (requires powerful GPUs/TPUs), the attention mechanism is O(L²) complexity (L is sequence length)
Positional encoding adds complexity.
Data hungry, requires large datasets for training
By removing recurrence, Transformers lose the ability to process variable-length sequences
Which part of the transformer processing can be parallelized?
Creation of a contextualized embedding for each input token both during training and inference
Prediction making for each element of the target sequence (using causal masking) during training
←→ inference is sequential
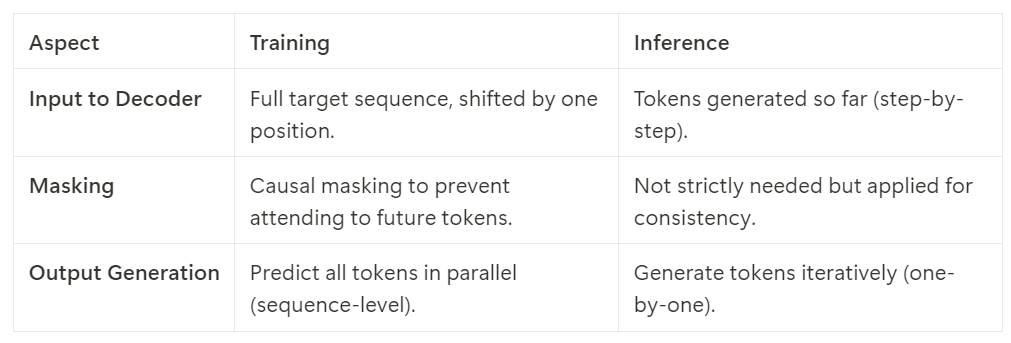
What is the difference between transformer training and inference?
The encoder's behavior and operations remain the same during training and inference, gets called only once, encodes the whole input sequence at once
←→ decoder behaves differently
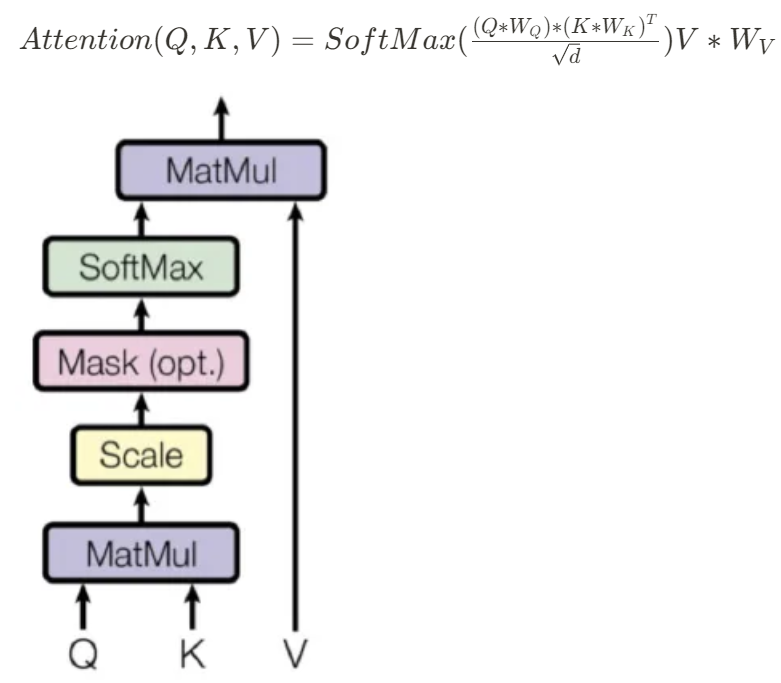
Dot product attention
The mechanism used to compute attention scores in Transformer models.
How it Works:
Input: Takes three vector sequences: Query (Q), Key (K), and Value (V), produced by learnable linear layers WQ, WK, WV from their corresponding inputs (usually creating embeddings of way smaller dimension)
Dot Product: Compute the dot product between the Query and Key vectors to measure similarity.
Scale: Divide by the square root of the dimension of the key vector to avoid large dot products.
Softmax: Apply a softmax function to get the attention weights (probabilities).
Weighted Sum: Multiply the attention weights by the Value (V) vectors to get the final output
Why is scaling by sqrt(d) necessary?
To prevent large dot products from leading to extremely small gradients and poor training performance.
=> Dividing by sqrt(d) normalizes the dot product, avoiding large variance in the output.
The scaling by sqrt(d) ensures that:
The magnitude of the dot products doesn’t grow too large with increasing vector dimensions.
The softmax function remains sensitive to changes in the input, avoiding the saturation problem.
The training process remains stable, with consistent gradients even for high-dimensional inputs.
Why can the dot product be used as a similarity function?
Because it is computationally simple to calculate and it can be expressed in terms of the magnitudes of the vectors and the cosine of the angle θ between them:
a⋅b=∥a∥*∥b∥*cos(θ)
=> The dot product reflects how much the two vectors point in the same direction. When vectors are aligned (i.e., their angle θ is small or zero), the cosine of θ is close to 1, making the dot product large and positive. This indicates high similarity.
Multi-headed attention
Multi-Headed Attention enhances the power of self-attention by allowing the model to focus on different parts of the sequence simultaneously.
How it Works:
Multiple Heads: Instead of computing a single attention score, the model computes attention multiple times (in parallel) with different weight matrices.
The input vectors are split into h parts along the embedding dimension. The attention module is run on each part separately in a batched manner
The outputs of all attention heads are concatenated and passed through a final linear transformation to mix information across heads.

Self-attention
Focuses on the internal relationships within a single sequence.
Key Concept: Each token in the input sequence attends to every other token within the same sequence.
How it Works: For each token, self-attention computes how much attention should be paid to every other token in the same input using dot-product attention.
Use Case: Encoders in Transformers (e.g., BERT), where the model processes the entire input sequence simultaneously.
Cross-attention
Establishes connections between two different sequences.
Key Concept: Each token attends to tokens from a different sequence (e.g., source-target sequence pairs in translation tasks).
How it Works: The Query (Q) comes from one sequence (e.g., target sequence in translation), while the Key (K) and Value (V) come from another sequence (e.g., source sequence).
Use Case: Decoders in Transformers (e.g., translation tasks), where the decoder attends to both the current output sequence and the input sequence from the encoder.
Bidirectional attention
Key Concept: Bidirectional attention allows the model to take into account both past and future context when processing sequences.
How it Works: The model attends to all tokens before and after a given token in the input sequence.
Advantages:
Richer context: Unlike unidirectional attention (e.g., in GPT), bidirectional models can utilize information from both directions, leading to more accurate predictions.
Better for understanding relationships: Allows the model to understand complex dependencies, including long-range ones in both directions.
Use Case: Text classification (BERT), question answering, sentence prediction, and other NLP tasks where full sequence understanding is important.
Main idea of positional encoding
Unlike RNNs, Transformers do not process sequences in order.
→ They need a way to incorporate information about the position of tokens to understand their relationships.
=> Each token in the input sequence is assigned a positional encoding vector that is added to the token's embedding vector.
=> Provides a unique encoding for each position, allowing the model to differentiate between similar tokens at different positions.
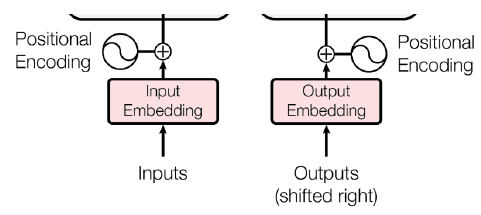
Expectations for positional encodings
When added to the token representation, it moves it towards the direction of tokens in the same position in other sequences
It should not overdominate the semantic representation → have some bounded value
←→ it should still be expressive enough for the model to detect
It should be deterministic, assign a unique and consistent value for each position
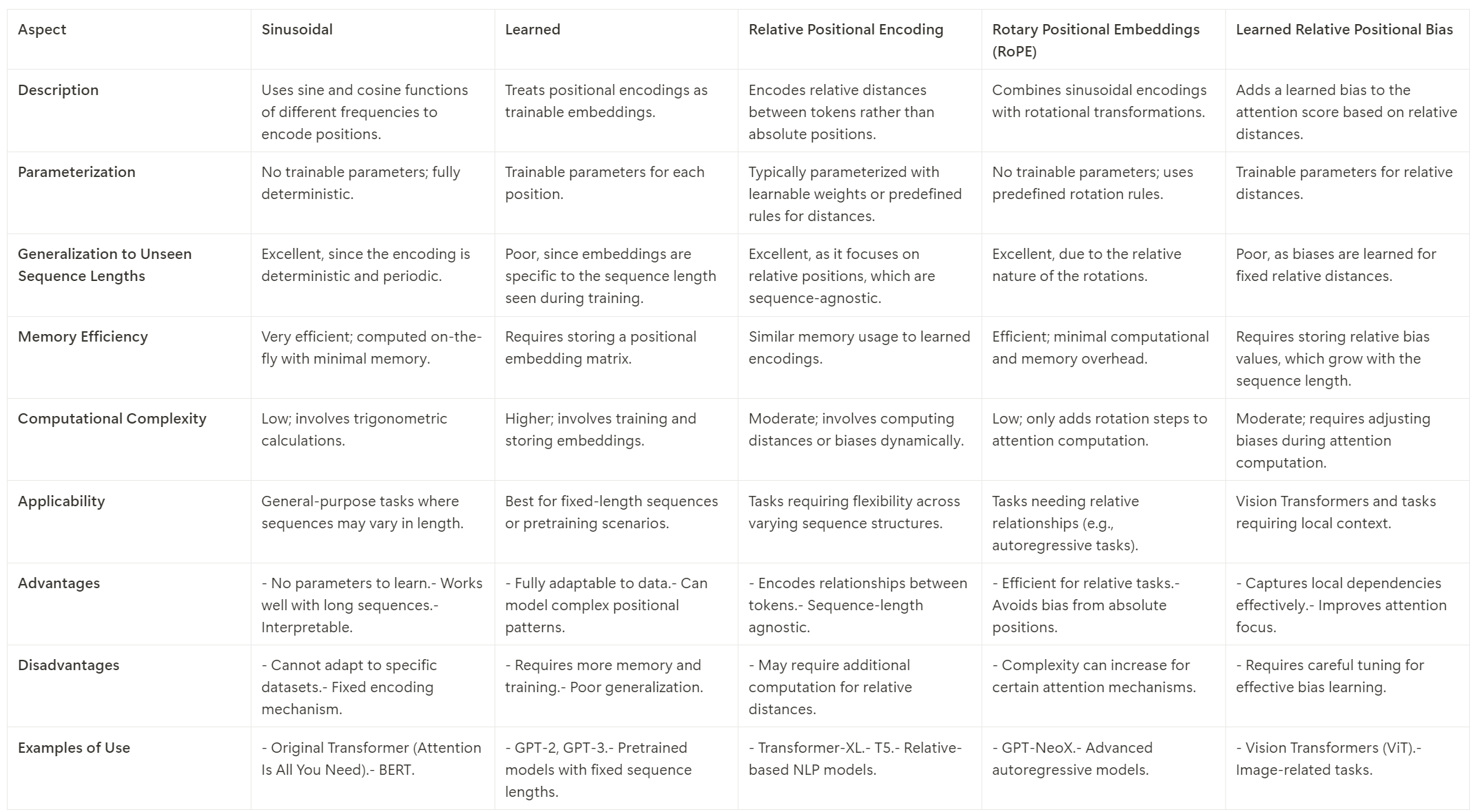
Main positional encoding types
sinusoidal (used in the original Transformer paper)
learned: treated as trainable parameters
relative: encodes the relative distances between tokens
rotary: Combines sinusoidal encodings with rotational transformation
learned relative: Adds a learned bias term to the attention scores based on the relative distance between tokens
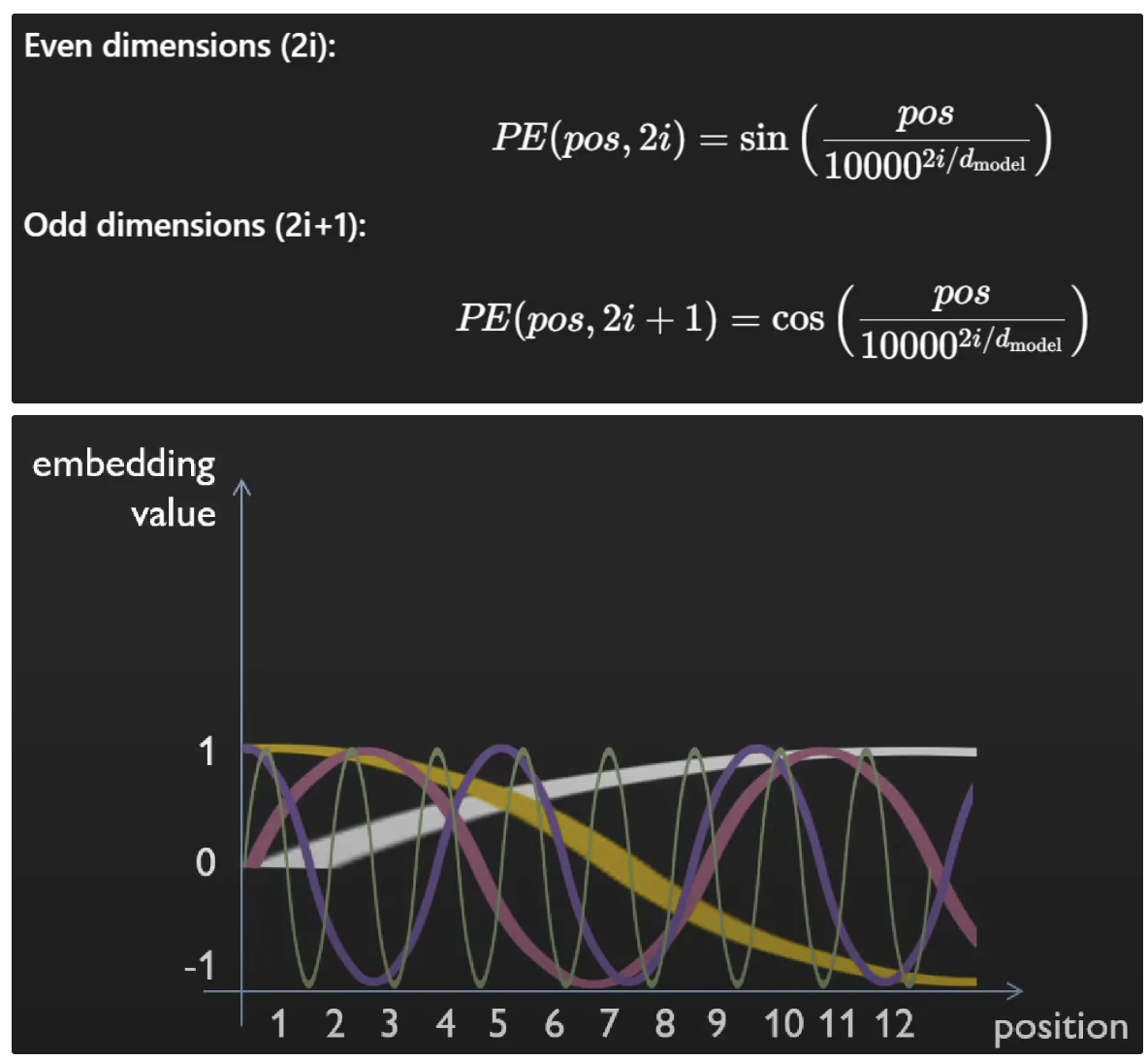
Sinusoidal positional encoding main idea
Each dimension of the encoding corresponds to a specific frequency of sine/cosine wave over positions
=> pattern of sinusoids uniquely identifies the location in the sequence.
Frequencies vary exponentially across dimensions:
Low i → low frequency → smooth, coarse position changes, global position info (beginning, mid, end)
High i → high frequency → fine position differences, local position details (22. or 23.)
Sin and cos pairs per frequency uniquely define the phase, capturing shifts in position as rotations in embedding space.
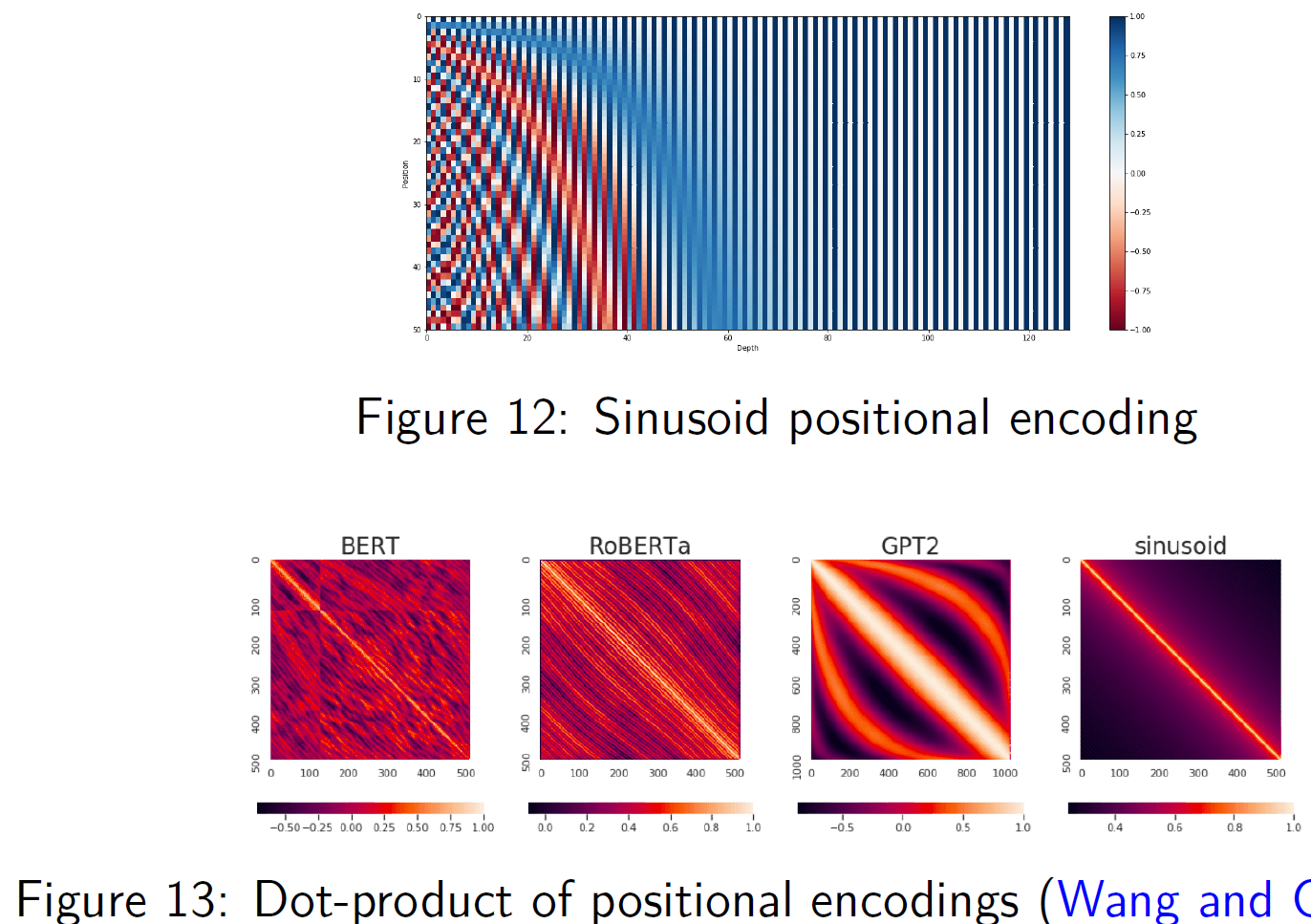
Sinusoidal positional encoding advantages
The similarity (dot-product) of positional encodings quickly drops off away from diagonal.
=> positions are most similar to themselves, less similar farther away
=> Very structured, predictable decay
=> The difference in encodings roughly reflects relative distance
Advantages:
parameter-free (no learning needed, fixed functions)
interpretable (encodings are smooth, periodic)
encodes relative positions naturally (Because sin/cos are continuous and smooth, differences between positions are encodable as shifts in phase → For nearby positions, encodings are similar in a structured way)
extrapolates to unseen sequence lengths
Teacher forcing
The method of using the ground-truth output sequence as the input for each step during the generation, not taking the model’s previous outputs into account.
Solves the problem of error propagation: if we used the model’s output as input, then a mistake would badly influence the rest of the following tokens
This method is used during training and is highly parallelizable, if we input the whole sequence at once (each output should refer to the next element in the sequence).
Problem: the model will learn to rely on the future ground-truth elements, which will not be available during inference.
=> To avoid this, the decoder self-attention is masked, so that each element can only attend to the previous elements (causal masking).
Masked attention
Key Concept: Masked attention is a technique used in Transformers to prevent the model from attending to certain tokens, typically used to maintain causality in autoregressive models.
How It Works:
Certain attention scores are masked out (set to minus infinity) before softmax computation to block certain positions from being considered in the attention calculation.
For example, in the decoder of a Transformer, a mask can be applied so that each token can only attend to previous tokens and not future ones (ensuring that predictions for a token do not rely on future information).
Types of Masks:
Causal Mask: Prevents access to future tokens, enforcing a left-to-right attention pattern.
Padding Mask: Ensures that padding tokens do not contribute to the attention scores, allowing the model to focus only on valid tokens in the sequence.
Attempts to reduce the complexity of attention
Sparse attention: sampling from the input sequence randomly/locally
Projective attention: reducing the vector dimensionality