Medical Image Processing Exam 1
1/111
Earn XP
Description and Tags
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
112 Terms
what are the two things that spatial resolution rely on?
point spread function and pixel size
what is the nyquist shannon sampling thereom as it relates to pixel size and sampling rate?
pixel size should be smaller than half of the smallest feature that you want to capture
sampling rate should be 2x the highest frequency present in an image
As pixel size decreases what happens to spatial resolution?
spatial resolution increases because there are more pixels in the image
what is the point spread function and how is it typically shaped?
it is how an ideal point object is spread or blurred in an image due to the characteristics in the imaging system
typically bellshaped curve with a central peak
what is the relationship between the point spread function and spatial resolution?
a narrower point spread function increases the spatial resolution
what is black and what is white on an MRI?
fluid, fat, and vascular abnormatlities are brighter are on an mri
bones, air filled spaces, necrosis, and calcification are black or darker on an mri
most soft tissue is grey on an mri
what is black and what is white on a ct scan?
hyperdense areas like bones and metals are whiter or brighter on an ct scan
hypodense areas like air filled spaces (lungs), fat, and cysts are darker or black on a ct
most organs and soft tissue and brain area are grey on a ct scan
is higher spatial resolution always a good thing?
no because in modalities like ct and fluoroscopy that means higher radiation doses
more spatial resolution means more scanning time which is more expensive
higher spatial resolution might mean introducing more noise and artifacts
how high should a sampling rate be?
2x the highest frequency present in the image
what happens when you under sample and image?
higher frequency components of a signal fold into lower frequency components
results in a distorted image
loss of information because not all frequency components are captured
artifacts are introduced that are distortions that are not present in the original data
what is the optimal intensity level of a grey level image?
our visual system can only distinguish between 30 levels
most 8-bit computers have 256 levels
qualitative analysis is done using 16-bits
is a higher or lower signal to noise ratio desired?
a higher signal to noise ratio is desired
what are some ways to increase the SNR?
increase exposure time
increase signal - higher field of strength
introduce noise filtering
use motion correction
how does a higher spatial resolution effect the signal to noise ratio?
a higher spatial resolution means you are capturing more fine details and using smaller pixel sizes
This might decrease the signal to noise ratio because the the signal is spread out over a smaller pixel area and therefore makes it more susceptible to noise
what does a signal to noise mean?
might been larger pixel values which means a higher signal bc more info is captured per pixel
however, fine details may be lost
how do you calculate a signal to noise ratio
(signal)/(noise)
SNR (in decibels, dB) = 10 * log10(Ps / Pn)
how do you calculate the signal in SNR?
Ps = (Σ(signal pixel intensities)) / (number of signal pixels)
how do you calculate the noise in SNR?
Pn = sqrt((Σ(noise pixel intensities^2)) / (number of noise pixels))
noise in an image is a combination of what two types of noise?
photon noise
electronic noise
what are photon noise and electron noise?
photon noise - relies on uncertainty of a photon arrival
electronic noise - random fluctuation of electrical signal
what is a grey level histogram?
a graphical representation of pixel intensities of grey levels within an image
division of data into bins - grouped by size
frequency count - counts the # of pixels that fall into each bin
what is “brightness” in an image?
perception of light and dark
what is “contrast” in an image?
degree in which light and dark areas of an image differ in brightness
what would high and low brightness look like in a histogram?
an image with high brightness would have a peak shifted towards the end of the histogram
an image with low brightness would have a peak shifted towards the beginning/start of the histogram
what would an image with low contrast and an image with high contras look like?
an image with high contrast would have a wide range of pixel intensities
an image with low contrast would have pixel intensities clustered together in one area
what is dynamic range?
the ability of an image to display a wide range of pixel intensities
are dynamic range and contrast the same?
no they are not
when is high contrast and high dynamic range important?
high contrast is important in x-rays for things like bone breaks
high dynamic range is important when you are looking at small anatomical features
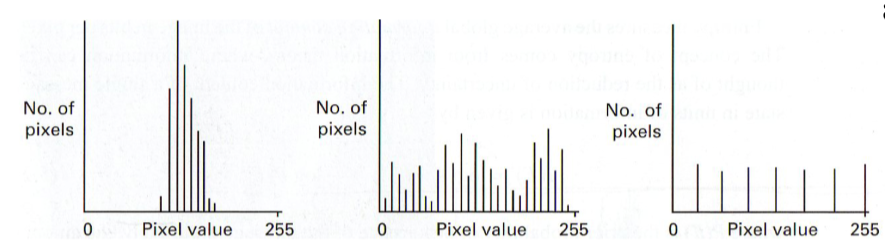
label these images according to how high their contrast and dynamic range
low dynamic range and low contrast
max dynamic range and high contrast
max dynamic range and higher contrast than any of the previous ones
entropy in medical image processing?
entropy defines the measure of randomness and pixel intensity
spread of states in which a system can adopt
what is the difference between high entropy and low entropy as it related to histograms
high entropy - diverse range of pixels so that means it is more random
low entropy - pixel intensities that are more uniform
what can high and low entropy tell you about texture
high entropy - more/rough textured
low entropy - smooth texture
what is a histogram stretch and what is the main goal of this?
an image enhancement technique whose primary goal is to expands the range of pixel intensities to cover the full dynamic range
what are the steps in performing a histogram stretch?
Compute original histogram
Identify min and max intensity values
map the min and max intensity values to the desired intensity values
apply the mapping function to all the pixel intensity values to stretch the histogram across the full display range
what is the main limitation of histogram stretching and what is a solution to this?
main limitation is that might outliers might prevent stretching
solution - ignore a certain percent of pixel values to get outliers out of there
what do you have to do when you want to apply a histogram stretch to a colored image?
convert it to hsv and then look at the value channel
what is histogram equalization?
transforming intensity values so that the histogram and output image matches a specified isogram
to enhance image contrast it spreads out the most frequent pixel intensity values
tries to achieve a more uniform distribution of pixels
what are some limitations of histogram equalization?
this can over amplify noise and make it seems like it might be an actual object
when would you use histogram equalization vs histogram stretching?
equalization: enhance contrast images with significant local variations or emphasize fine details
stretching: improve overall contrast in a more straight forward manner w/out introducing much noise
what is the most common noise in medical images? is this multiplicative or additive?
gaussian noise which is additive
is speckle noise multiplicative or additive?
multiplicative
what is the spatial domain based on?
an image that is represented in the form of a 2D matrix where each element of the matrix represents pixel intensity
spatial domain = intensity domain
what is the frequency domain based on?
the fourier transform of an image
frequency in image = rate of change in pixels
where does the reduction of multiplicative and additive noise take place?
additive = spatial
multiplicative = frequency
how is additive noise applied to an image
added to the original image, typically as a constant value across all the pixels
what are two ways you can remove additive noise?
Smoothing filters (median filters or gaussian filters): reduce high frequency noise components while preserving larger scale features
Averaging filters: calculates a running average of neighboring pixel values and replaces pixels with the average of the pixels in that neighborhood
how is multiplicative noise added to an image?
scales the pixel values non-uniformly, usually as a multiplicative factor
how do you remove multiplicative noise from an image?
taking the logarithmic transform of the image can convert multiplicative noise to additive noise which is easier to remove
Wavelet Denoising: separate the image into different frequency components, and denoising can be applied selectively to these components.
what is another way that noise can be reduced?
increasing the number of signal averages (NSA)
How is image subtraction helpful in medical image processing?
change detection - monitor the progression of diseases, like cancer, by subtracting the baseline image from a follow up image in order to highlight the change over time
enhancement - by subtracting a reference image from the original image, you can highlight specific ROIs like lesions or blood vessels
how does image subtraction work?
1st you blur the original image so you can have an uneven background
Then you subtract the blurred image with uneven background from the original image which results in the image with a blurred background
what is digital subtraction angiography?
image after contrast - image before contrast = digital subtraction angiography
commonly used to visualize blood vessels
what is a limitation of image subtraction?
data overflow
what is data overflow?
when the pixel value in the resulting image exceeds the max allowable range for the data type used to represent the image
absolute diff between the pixel vessels in the images being subtracted are too large
wrap arounds can fix this
why would you use image multiplication?
Contrast Enhancement: multiplying the original image with a specific mask or weight map you can selectively emphasize some areas
For example, if you want to highlight blood vessels in a medical image, you can multiply the image by a mask that assigns higher weights to regions likely to contain vessels, effectively increasing their visibility.
Noise Reduction: Multiplying an image by a low-pass filter or a spatial smoothing kernel can help reduce high-frequency noise in the image. This is especially useful when dealing with speckle noise in medical ultrasound or MRI images. The low-pass filter attenuates high-frequency noise components, leaving the underlying image structure intact.
Masking Regions of Interest (ROI):Image multiplication with a binary mask can be used to isolate and extract specific regions of interest (ROI) from an image. This is valuable for isolating and analyzing particular anatomical structures or pathologies within medical images.
The mask is applied element-wise to the image, setting the intensity values outside the ROI to zero while preserving the values inside the ROI.
what is scaling in image processing?
the transformation of an image to change its size while preserving the underlying data
what is zooming in image processing?
image enlargement, increases the size of the image
individual pixels become more visible, so you can see fine details but also blurring
interpolation is also used to estimate pixel-values at non integer coordinates
what is compression in image processing?
process of reducing the size of an image
reduces the amount of data in an image file by encoding it more efficiently
takes up less space
what is interpolation in medical image processing?
a tactic to estimate pixel-values at non-integer coordinates in an image
what is nearest neighbor interpolation?
assigns the value of the nearest known data point to the target point
each pixel in the original image is duplicated to a 2×2 block in this zoomed in image
what can nearest neighbor interpolation result in?
a blocky and pixelated image
what is linear interpolation?
assigning the weighted average of the nearest pixels
assumes a linear relationship between the data points
what are some examples of interpolation in medical image processing?
MRI images are acquired at different spatial resolutions
ADC slices are acquired at 128 × 128 ×10
DCE slices are acquired at 192 × 192 × 10
what is a weighted average mask?
a convolution kernel or filter
matrix consists of numeric values that define how much each pixel in the neighborhood of a central pixel contirbutes to the computation of the new pixel
how do weighted average masks work
mask size = mask size determines the area of the neighborhood around each pixel that is considered during computation
weights = each element within the mask has an associated weight, where weights represent the contribution of the corresponding pixel to the computation of the new pixel
convolution of operation = to calculate the value of a new pixel in the output image, you perform a convolution operation. This operation involves placing a mask over the source image such that the central pixel of the mask aligns with the central pixel being processed, you then assign the values in the mask by corresponding pixel values in the source image and sum up the results
center pixel weight = in many cases the weight of the central pixel in the mask is given importance of surrounding pixels, central weight is often the largest value in the mask
what is a gaussian mask and what does it do?
perform image smoothing and image blurring, by applying the gaussian mask you reduce high frequency noise and fine details while preserving the overall structure and larger features
low pass filter
uses weights
what is a median mask and what does it do?
does not use weights
calculates the median value from a set of neighboring pixels
what is a median mask mostly used for?
noise reduction, the removal of salt and pepper noise, and impulse noise
is a median mask or an averaging mask more sensitive to outliers? which is more commonly used in medical imaging? which is better at preserving edges?
median mask is less sensitive to outliers
median mask is more commonly used in medical imaging
median mask is better at preserving edges
what is the purpose of edge detection?
to identify and highlight the boundaries or edges within an image
what is a sobel operator?
an edge detection filter in image processing
highlight edges in an image by computing the gradient or rate of change in pixel intensity at each pixel
emphasizes areas of rapid changes in intensity, which often corresponds to object boundaries or edges
give the 2 kernels that the sobel operator use?
X direction
[ -1 0 1
-2 0 2
-1 0 1]
Y direction
[ -1 -2 -1
0 0 0
1 2 1]
Give the process for the convolution with the kernels in sobel and prewitt?
Convolution with Sobel-X Kernel:
Place the center of the Sobel-X kernel on the target pixel in the image.
Multiply each element of the Sobel-X kernel by the corresponding pixel value in the image under the kernel.
Sum up the products to get the horizontal gradient (Gx) at that pixel.
Repeat this process for every pixel in the image, using the Sobel-X kernel for each calculation.
Give the prewitt operator kernels
x kernels
-1 0 1
-1 0 1
-1 0 1
y kernels
-1 -1 -1
0 0 0
1 1 1
explain the process of unsharp masking:
Start with the original image you want to sharpen
Create a blurred/smoothed image ; apply a smoothing or blurring filter (gaussian filter) to the original image, which reduces high frequency noise while retaining low frequency info
Generate a mask - subtract the smoothed image from the original image, this enhancement mask, highlights the differences or edges between original and smoothed image
apply mask to original image - add enhancement mask back to original image
what is a fourier transform?
mathematical technique that is used to decompose a signal into its constituent frequencies
2D Fourier Transform in the Context of Medical Images:
F(u, v) represents the frequency components present in the image. Each point (u, v) in the frequency domain corresponds to a specific sinusoidal pattern with a particular frequency and orientation.
The magnitude of F(u, v) indicates the amplitude of the corresponding frequency component, while the phase encodes information about the phase shift.
How is Fourier Transform related to MRIs?
Used a lot for MRI reconstruction
MRI acquires data in the frequency domain (k-space) and then uses the inverse fourier transform to reconstruct the spatial domain
how is thresholding used in image processing?
used to segment objects/ROIs within an image based on pixel intensity valies
simplifies the image by converting it into a binary image where pixels are classified into 1 of 2 categories: foreground (object) and background (non-object)
what is the effect of a too high or too low threshold
Too High:
undersegmentation - important objects/details are missed
objects with lower intensity values are not included
loss of info
increased false negatives
Too Low:
oversegmentation - noise or small intensity variations may be treated as objects
more noise
false positives - highlights non-objects regions or noise
what is otsu’s method? what does it do?
an automatic image thresholding technique
find an optimal threshold value that can be used to separate objects or regions of interest from the background in a gray scale image \
maximizes the separation between the object and the background,
minimizes between class variance
k means clustering
identifies k # of centroids and then allocates every data point to the nearest cluster while keeping the centroids as small as possible
‘means’ refers to a averaging of the data - finding the centroid
is k means clustering sensitive to outliers?
yes, they can effect centroid placement
when would it be useful to use k means clustering in medical image processing?
tissue segmentation - segment brain tissue in MRI scans by grouping similar pixel intensity values into clusters.
lesion detection - extract blood vessels by separating them from the background and surrounding tissue based on contrast
functional image analysis - Functional MRI (fMRI) and positron emission tomography (PET) images often require the analysis of functional regions or activation patterns. K-means clustering can group voxels or regions with similar functional responses.
what is adaptive thresholding
calculates a threshold value for each pixel in the image based on its local neighborhood
threshold value is determined independently for each pixel
what is global thresholding?
a fixed threshold value is applied to the whole image
when would you use global vs adaptive thresholding
global - when image is relatively uniform and foreground and background are clear
adaptive - uneven lighting, shadows or varying contrasts
what is region growing? what does it do?
groups pixels with similar properties or characteristics into regions or segments
based on the idea that adjacent pixels with similar attributes often belong to the same object or region
what is the difference between k clustering and region growing
K-means clustering is a global technique that partitions the entire image into K clusters, whereas region growing is a local technique that starts with one or more seed pixels and grows regions from them.
K-means requires specifying the number of clusters in advance, while region growing does not require specifying the number of regions.
Region growing is often used when you have prior knowledge or cues about the regions of interest, as it relies on seed selection and local criteria.
give a simple process of what region growing is?
Seed Selection:
Region growing starts with the selection of one or more seed points or seed pixels. These seeds serve as the initial building blocks for the regions. You can choose seeds manually or through automated methods based on certain criteria, such as intensity values.
Initialization:
Initialize an empty region for each seed point. Initially, each region contains only the seed point(s).
Pixel/Region Expansion:
Iteratively expand each region by considering neighboring pixels or voxels. The specific criteria for expansion depend on the similarity measure used. Common similarity measures include:
Intensity Similarity: Pixels are added to the region if their intensity values are similar to those of the region's seed or average intensity.
Texture Similarity: If texture features (e.g., standard deviation) are considered, pixels with similar texture characteristics are added.
Color Similarity: In color images, regions can be grown based on color similarity.
Region Growing Criteria:
Define a stopping criterion for region growing to prevent over-segmentation. Common stopping criteria include:
Threshold: Stop when the difference between the pixel being considered and the region's average value exceeds a predefined threshold.
Size Constraint: Stop when the region reaches a predefined size or when no more similar pixels are found.
Connectivity: Ensure that only neighboring pixels are considered for expansion to maintain spatial coherence.
Iteration:
Repeat the pixel/region expansion process for each region until all regions have reached their stopping criteria. Continue expanding regions as long as similar pixels are found.
Final Segmentation:
Once the region growing process is complete, you have segmented the image into meaningful regions or objects based on the similarity criteria and seed selection.
Post-processing (Optional):
Optionally, you can apply post-processing steps to refine the segmentation results. This may include merging small regions, splitting large regions, or applying morphological operations.
when would region growing be useful in medical image processing?
tumor detection: seed starting within the tumor and growing based on the intensity or texture similarity
vessel extraction: extract blood vessels from angiograms - seed points are placed on vessels
organ segmentation - seed points starting within target organ
bone fracture detection - detect bone fractures by indentifying ROIs with disrupted bone density patterns
watershed segmentation
based on images topographical features
useful when objects touch or overlap
treating pixels as elevations on a topographical map
what are the bright points and dark points in watershed segmentation?
bright points = peaks
dark regions = valleys
what happens when “flooding” occurs in watershed segmentation?
water starts filling up the valleys from the seeds you places and as the water level increases it fills the regions
when 2 waterflows from different seeds meet, they create a boundary and boundary lines create watershed lines that separate regions
areas enclosed by watershed lines are segmented regions
what is a challenge in watershed segmentation?
oversegmentation
what is the difference between endogenous and exogenous contrast?
Endogenous Contrast:
Endogenous contrast relies on natural differences in tissue properties within the body being imaged
Exogenous Contrast:
Exogenous contrast involves the introduction of external contrast agents or substances into the body to enhance the visibility of specific structures or processes.
These contrast agents are administered before or during the imaging procedure to highlight particular areas or functions.
Examples of exogenous contrast agents include iodine-based contrast agents used in CT scans to visualize blood vessels, gadolinium-based contrast agents in MRI for highlighting specific tissues, and radioactive tracers in nuclear medicine for functional imaging.
what is the difference between chemiluminescence and photoluminescence?
Chemiluminescence:
Chemiluminescence is a process in which light is emitted as a result of a chemical reaction. It occurs when certain chemical compounds, known as chemiluminescent compounds, undergo a chemical reaction that releases energy in the form of photons (light).
The chemical reaction typically involves the breaking and forming of chemical bonds, resulting in the release of energy that excites electrons in the molecule. When these excited electrons return to their lower energy states, they release photons of light
Photoluminescence:
Photoluminescence is a process in which light is emitted when a material absorbs photons (light) from an external source and then re-emits them at longer wavelengths (lower energy).
It occurs when a material, typically a semiconductor or a phosphorescent substance, absorbs photons, which elevate electrons to higher energy states. When these electrons return to their ground states, they release energy in the form of photons of lower energy and longer wavelength.
Photoluminescence is the basis for various technologies, including fluorescent lighting, laser operation, and the emission of light in semiconductor devices like light-emitting diodes (LEDs).
what is flourescence as it relates to medical image processing?
Fluorescence Imaging Process:
Fluorescent Labels: In fluorescence imaging, specific molecules or structures of interest (e.g., proteins, DNA, cellular components) are labeled with fluorescent molecules known as fluorophores or fluorescent probes. These probes are designed to bind selectively to the target molecules.
Excitation: A fluorescence imaging system emits a specific wavelength of light (excitation light) that matches the absorption spectrum of the fluorophores. When this excitation light illuminates the sample, it energizes the fluorophores, causing them to enter an excited state.
Emission: As the excited fluorophores return to their ground state, they release energy in the form of photons of a longer wavelength (lower energy). This emitted light is referred to as fluorescence emission and is characteristic of the specific fluorophore used.
Detection: The emitted fluorescence is collected by a detector or camera, which records the intensity and spatial distribution of the fluorescence signal. This data is then processed and used to create fluorescence images.
What is a GUI?
A GUI, or Graphical User Interface, is a visual interface that allows users to interact with electronic devices or software through graphical elements such as icons, buttons, windows, and menus, rather than text-based commands. GUIs are designed to make computer systems and software applications more user-friendly and accessible to individuals who may not have extensive technical knowledge
what does '“closing” mean morphologically?
Involves two other morphological operations? (in this order)
Dilation - expanding or thickening the foreground in the binary image
Erosion - shrinking or thinning the white image regions in the binary image