Transformers / Self-attention
1/21
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
22 Terms
What is the purpose of Self-Attention?
To consider information from other inputs, to produce contextualized input representations
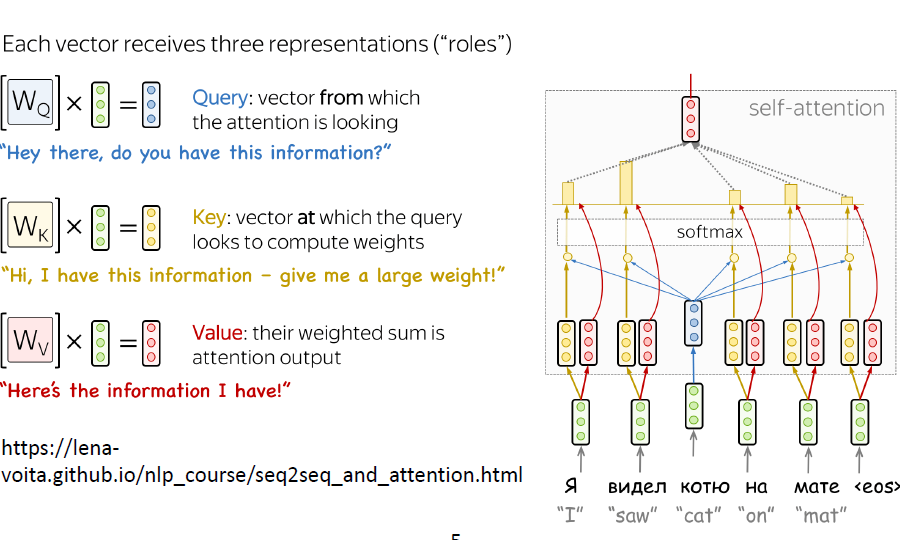
How are the three projections called which take the input embedding?
Key, query and value
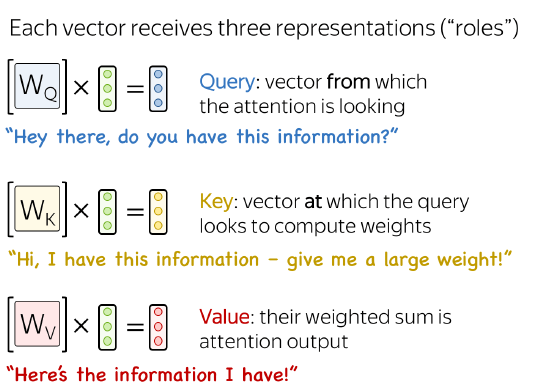
What are the weights in Self-Attention?
The matrices for the key, query and value projections (one for each projection)
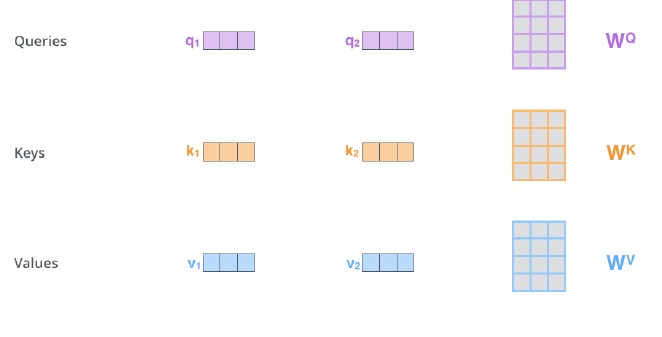
A Transformer combines several self-attention outputs.
True
The Transformer architecture does not work on sequence inputs.
False
In a Transformer, the complexity for each layer is quadratic with respect to the input sequence length.
True

During training, Self-Attention is fast since all inputs can be processed in parallel.
True
What is the first step in the Transformer model?
Convert input tokens into dense vector representations (embeddings).
Why is positional encoding added to input embeddings?
To provide information about the order of tokens (since Transformers process tokens in parallel).
What does the self-attention mechanism do?
Computes attention scores to determine how much each token should focus on other tokens.
What are the three vectors in self-attention?
Query (Q), Key (K), and Value (V). Q and K compute attention scores; V carries the actual information.
How are attention scores computed?
Dot product of Query (Q) and Key (K), scaled by √(d_k), followed by softmax.
What is the purpose of multi-head attention?
To capture different types of relationships (e.g., syntactic, semantic) between tokens.
What happens after self-attention?
The output is passed through a feed-forward neural network (FFN) for further processing.
Why are residual connections used?
To stabilize training and improve gradient flow by adding the input to the output of each sub-layer.
What is layer normalization used for?
To normalize the outputs of each sub-layer, improving training stability.
What are the two main components of a Transformer?
Encoder (processes input) and Decoder (generates output).
What does the encoder stack consist of?
Multiple layers of self-attention and FFN, with residual connections and layer normalization.
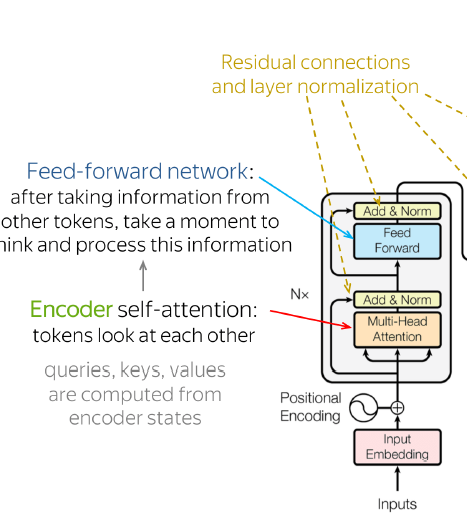
What does the decoder stack consist of?
Multiple layers of masked self-attention, encoder-decoder attention, and FFN, with residuals and layer normalization.
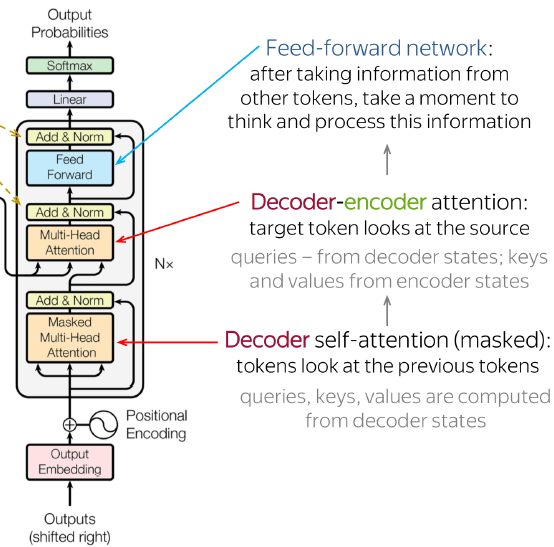
How does the Transformer generate output?
The final decoder output is passed through a linear layer and softmax to predict the next token.
How is the Transformer trained?
Using a loss function (e.g., cross-entropy) to minimize the difference between predicted and actual outputs.
Why are Transformers faster than RNNs?
They process all tokens in parallel, unlike RNNs, which process tokens sequentially.