sd - 04 - microservice internals
1/10
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
11 Terms
issues with layered architecture inside of a single microservice
layered vaak opgesteld als:
presentation layer (controllers / endpoints)
business logic layer (services)
persistence layer (repos / db acces)
single presentation layer:
hoe support je multiple clients (web / mobile / api / …)
force everything through one presentation layer
gaan internal messages voorbij de presentation layer
internal messages door zelfde controllers als http?
single persitence layer
hoe support je verschillende query patterns
transactional
read heavy (dashboards)
caching
=> 1 god layer met extreem veel special cases
business logica hangt af van persistence layer
onmogelijk om business logica te testen zonder effectieve db connection
layers zorgen voor onnodige dependencies
problemen
ieder request moet door alle lagen gaan, ook als maar een lightweigt request is
bv typing indicator
what aje zo snel mogelijks status moe terug geven

x
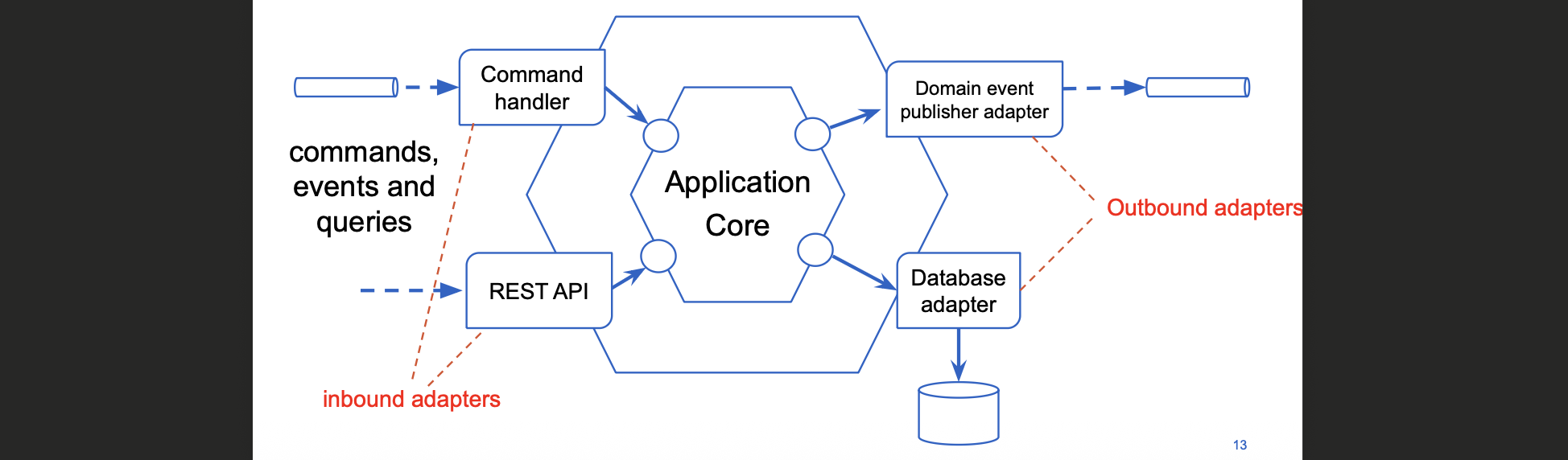
hexagonal and onion style architecture
waarom inward dependencies
Hexagonal Architecture
Application Core: business rules + domain logic
Inbound adapters: REST, messaging, GUI
→ vertalen externe input naar commands/queriesOutbound adapters: DB, message broker, externe services
→ implementeren interfaces (ports) gedefinieerd door de core
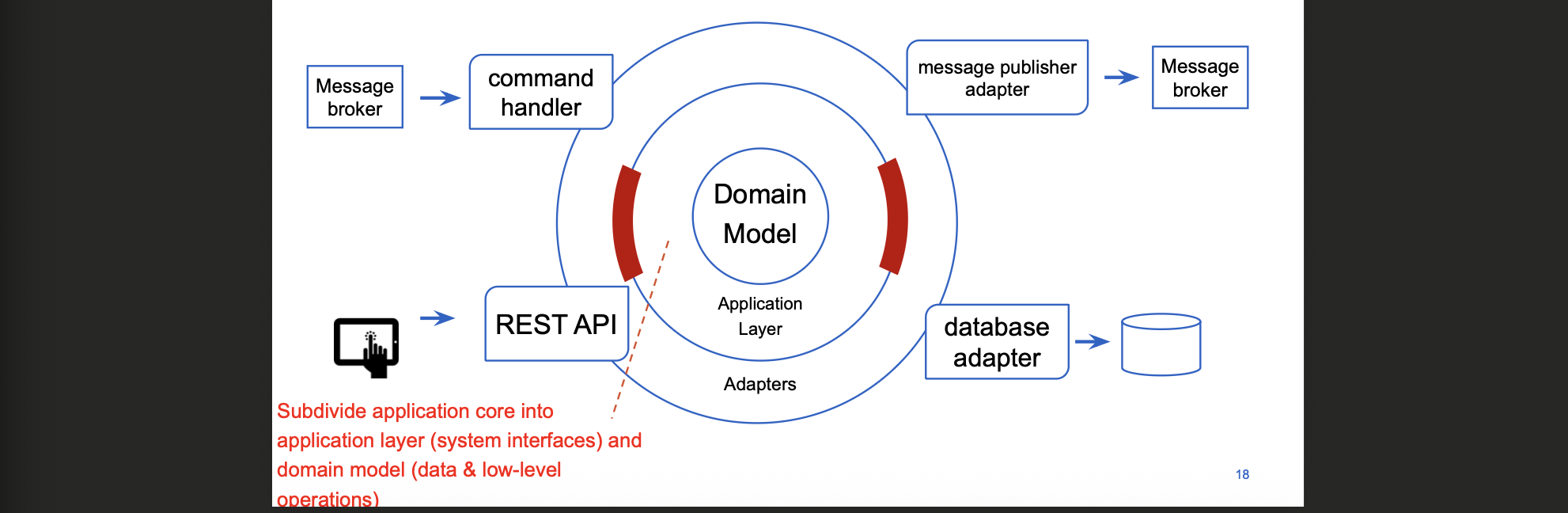
Onion / Clean Architecture (verfijning)
Domain Model (center)
Data en low level operations
Geen framework- of infrastructuurafhankelijkheden
Entities, value objects, domain services
Application Layer
Definieert interfaces (repositories, external services)
Use cases / application services
Orkestreert workflows
Adapters / Infrastructure (outer ring)
REST controllers, DB-implementaties, Kafka, gRPC
Bevatten geen business logic, enkel vertaling
Inward dependencies (essentie)
Regel
Alle dependencies wijzen naar binnen:
Adapters → Application Layer → Domain Model
Concreet (slides 20–21)
REST API importeert application layer
REST API maakt concrete adapters (bv. DB adapter)
REST API roept application service aan en geeft adapter mee
Application layer en domain kennen geen adapters, enkel interfaces
slides sta toch meer gwn dit wi:
Application layer exposes:
acties clients kunnen uitvoeren
abstract interfaces naar extern infra
gebruikt inward dependencies
om business logica te testen zonder db
application layer geen dependencies heeft op adapters
Waarom inward dependencies? (slides 21–22)
Business logica is onafhankelijk van infrastructuur
→ domain/application kennen geen REST, DB, message broker
→ enkel abstractiesTestbaarheid
→ business logica kan getest worden zonder DB of externe systemenWijzigingen zijn lokaal
→ infrastructuur kan veranderen zonder impact op core
→ business logica kan veranderen zonder adapters aan te passen
→ technologien aanpassen zonder impact
Transaction script vs (rich) domain model
transaction script
1 procedure per command / query
bevatten infrastucture isuues (db, messaging, network…) + business logica
workflow + validatie + berekeningen + db-calls in 1 methode
procedures gegroepeerd in manager / service klasse
alle business logica zit in application layer
domain model bevat enkel classes met enkel state (aka data)
Rich domain model
kleinere klassen met minder verantwoordelijkheden
business logica zit in domain objects (entities / values)
application layer = orchestration
oo design shit → makkelijk uitbreiden zonder veel code aan te passen
verschil:
domain makkelijker te begrijpen ipv 1 grote klasse die lett alles doet
meerdere klassen: banking transaction / account → real world shit, mensen snappen
oo patterns → uitbreidbaar
domain model dwingt internal consistency af


Patterns to create a rich domain model
Entities, values, domain service and domain events
Aggregates and repository
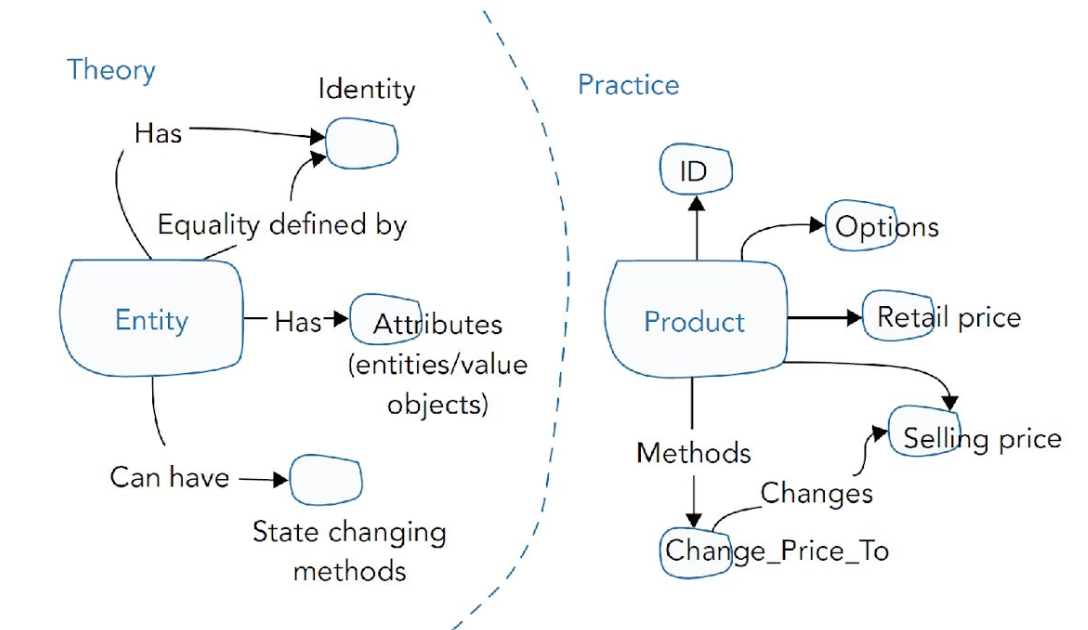
entity objects:
domain concept dat gedef door identity ipv attributen
zelfde attr zijn geen 2 dezelfde objecten
entity altijd in state consistent met business rules
order, product
Patterns to create a rich domain model
Entities, values, domain service and domain events
Aggregates and repository
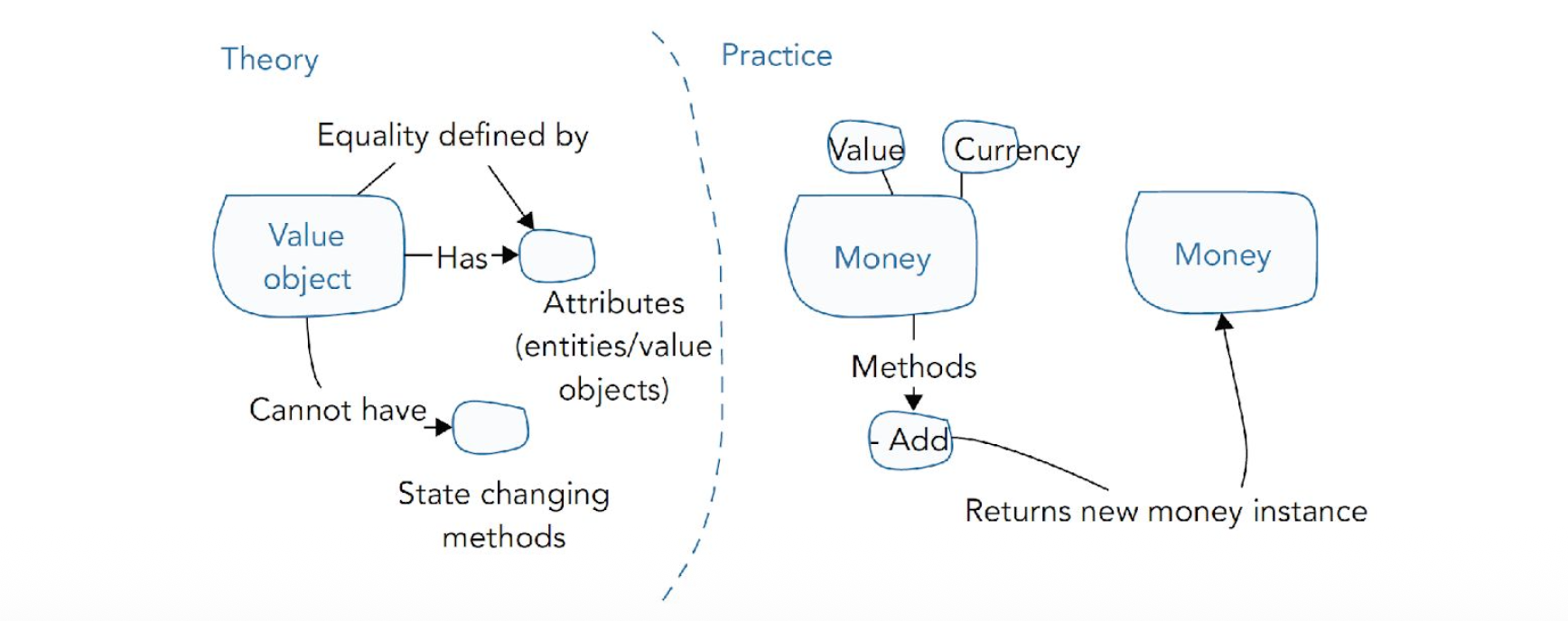
Value objecten
domeinconcepten zonder id, enkel gekend door attributen / values shit, meestal quantity
enkel betekenis in context met ander object
immutable en kan combineren met andere shit
gelijkheid door attributen te vergelijken, niet ids
price / address
Patterns to create a rich domain model
Entities, values, domain service and domain events
Aggregates and repository
Domain services
waarom
domain model logica past niet in enkele methode / entity / value objecten
wanneer logica over meerdere entities of values gaat
wat:
represent behavior → stateless
orchestreren van business logica
liggen nog steeds in domain model layer
bv: free subscription for highscores → highscore service + subscription service shit
Patterns to create a rich domain model
Entities, values, domain service and domain events
Aggregates and repository
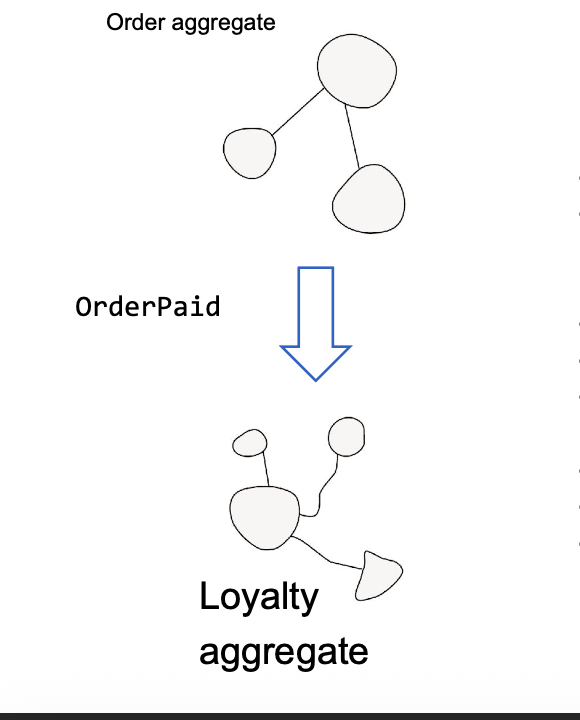
= beschrijft iets dat gebeurd is in het businessdomain en waar de business om caret
fact geen cmd
generated wanneer een aggregate state veranderd
triggers andere shit
state updates in andere / notification of a user
maintain data consistency / notify nog shit kejet bla bla bla
Patterns to create a rich domain model
Entities, values, domain service and domain events
Aggregates and repository
waarom:
in rich domain model: elk concept is aparte klasse → voor ieder service request → alle data van db laden → in objecten steken en dan hierop functies oproepen
niet alle relations zijn nodig om business use case te supporten
moeilijk om consistency te behouden
complex
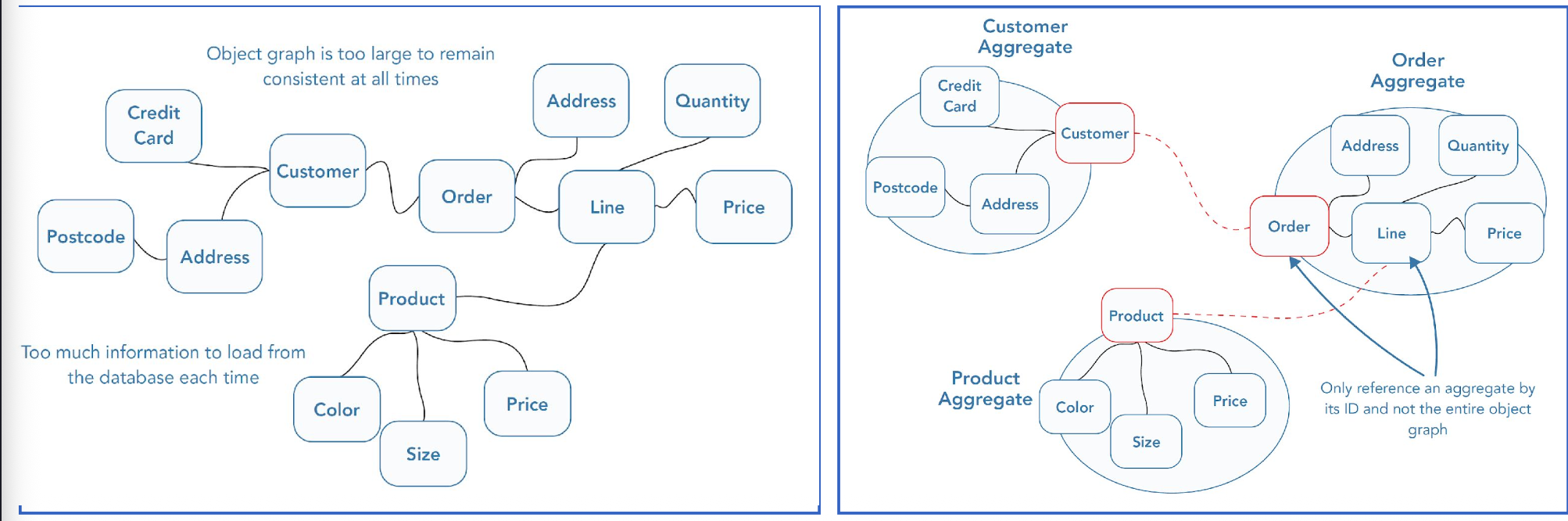
→ Aggregates are groups of objects that act as a whole
heeft
root entitiy
andere entities / value objecten
regels:
reference enkel de aggregate root
niet root kan referenties naar andere aggregate roots bevatten
inter aggregate referenties moeten primary keys gebruiken
1 transactie maakt of update 1 aggragate
anders weer locking en dependencies maken
maak gebruik van saga wanneer meerdere transacties nodig zijn
kern / waarom aggregates nodig:
Zonder aggregates:
verschillende users kunnen gelijktijdig verschillende delen van dezelfde object graph uitleggen
updates gebeuren op gedeelde data zonder duidelijke grenzen
→ business rules kunnen breken
bv client past op zelfde moment: order hoeveelheid en adres aan
kan zijn dat dan verstuurd wordt naar oud adres / foute hoeveelheid verstuurd wordt
(“The order is no longer consistent” – slide 50)
Aggregates definiëren consistency boundaries:
alle business rules binnen één aggregate blijven altijd consistent
gelijktijdige updates buiten de aggregate kunnen geen interne inconsistentie veroorzaken
Concurrency wordt niet vermeden maar veilig begrensd:
elke wijziging gebeurt via de aggregate root
in één transactie
zonder cross-aggregate locks
Patterns to create a rich domain model
Entities, values, domain service and domain events
Aggregates and repository classes
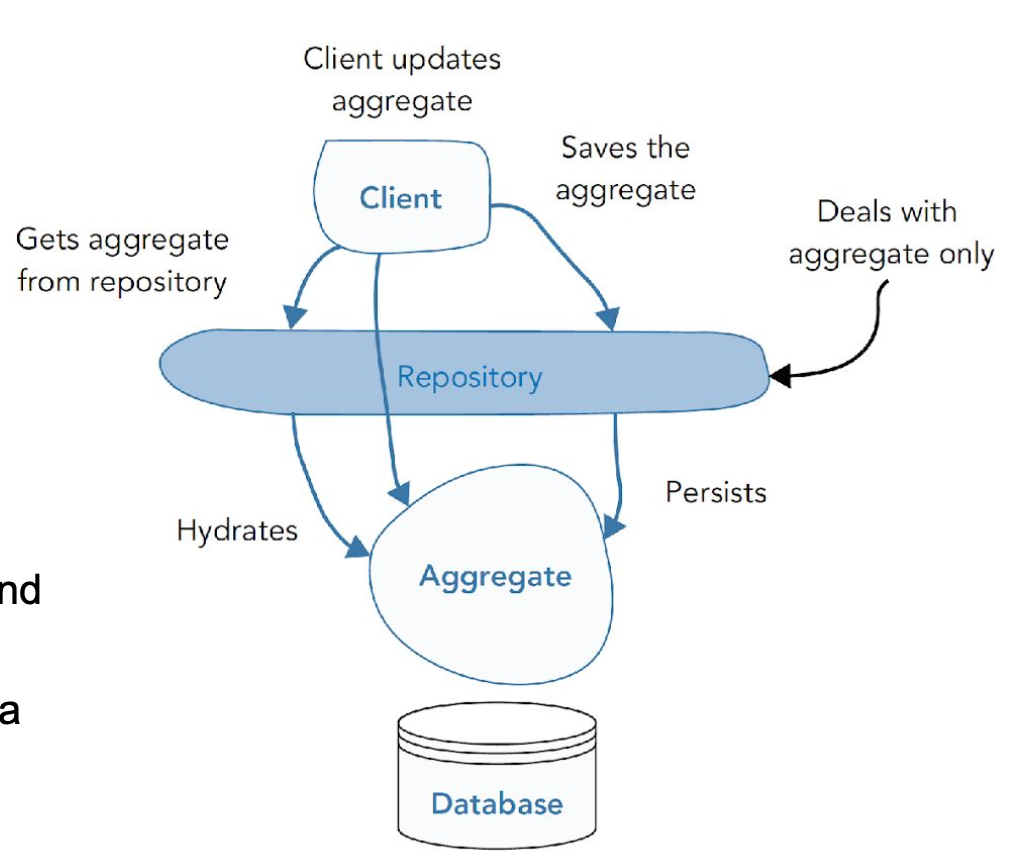
how to load en save aggregates
enkel ophalen en persistence van aggregate roots
verstop underlying tech die gebruikt wordt om aggregates te persisten / ophalen
grens tussen domain model en data model
geen: business logica / validatie / workflows
enkel aggregate roots opvragen en persisten
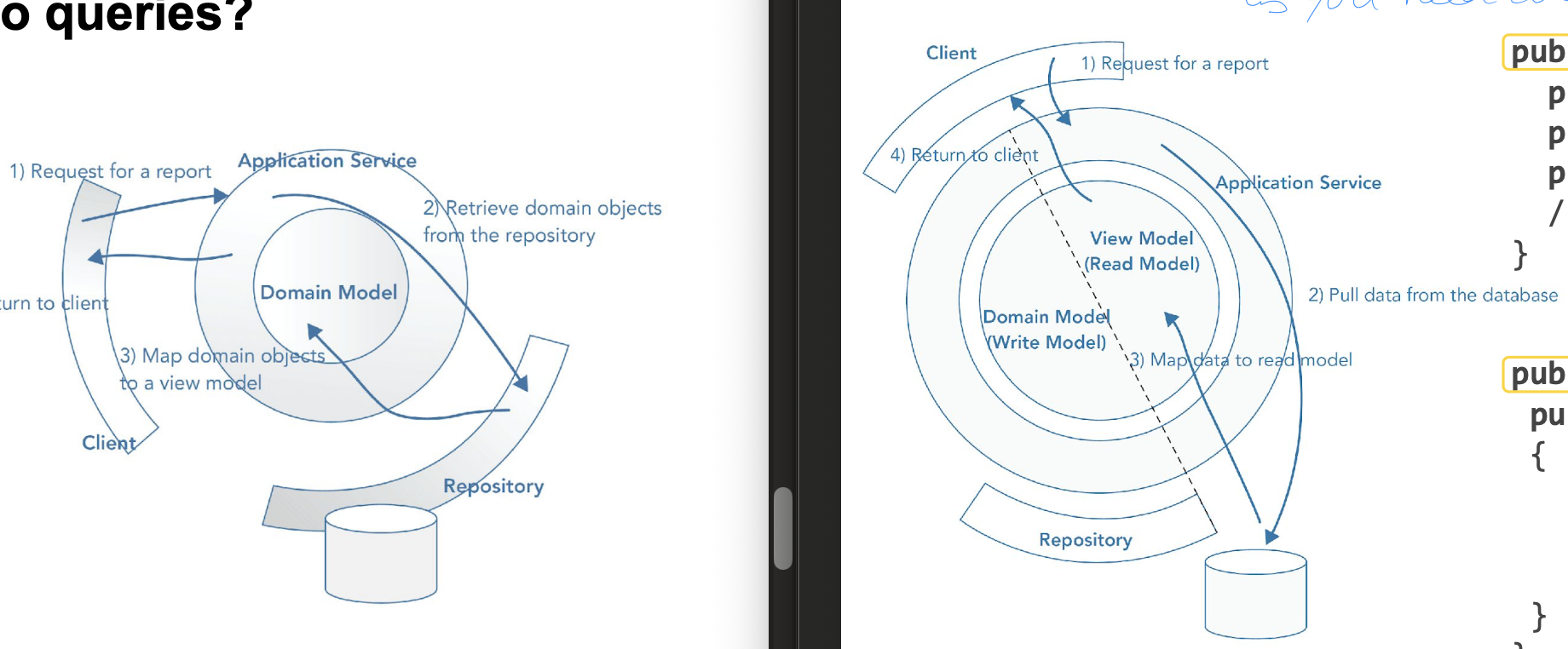
Different methods for handling queries in a microservice architecture
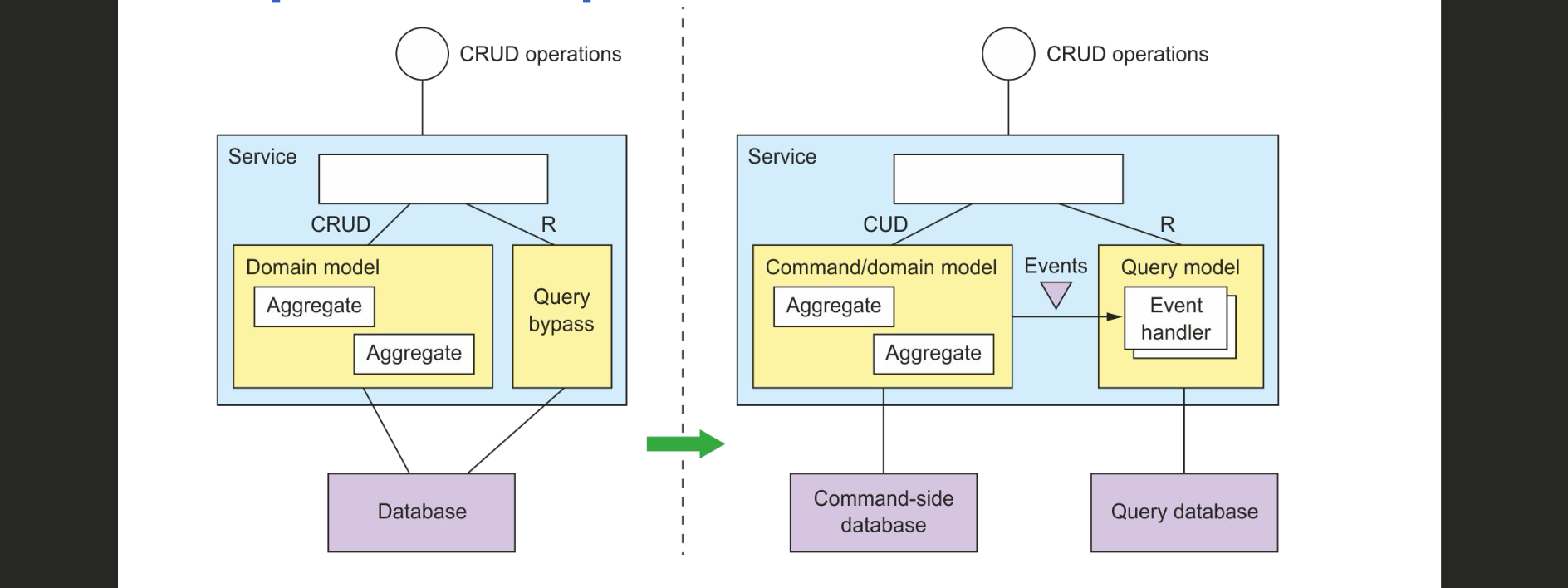
CQRS
Naive way:
Commands + queries events gaan domain model updaten
queries lezen rechtstreeks uit domain model
problemen:
meerdere aggregates laden om view te populaten
Expose internal state van domain objecten die niet in de aggregate root zitten
compromisen van domain model enkel voor performance
CQRS: Command-query responibility segregation
domain model splitsen in
Read model: queries + presentatie shit (ui)
indexed for fast queries and filtering
geen business logic
write model: afhandelen en verwarken van commands, business tasks
aggregates + domain events
wat:
scheiding tussen commands en queries
separate write db from view db: read model kan eigen datastore hebben → optimiseer voor queries
hierdoor:
domain model blijft clean / onaangepast
betere performance
eventual consistency
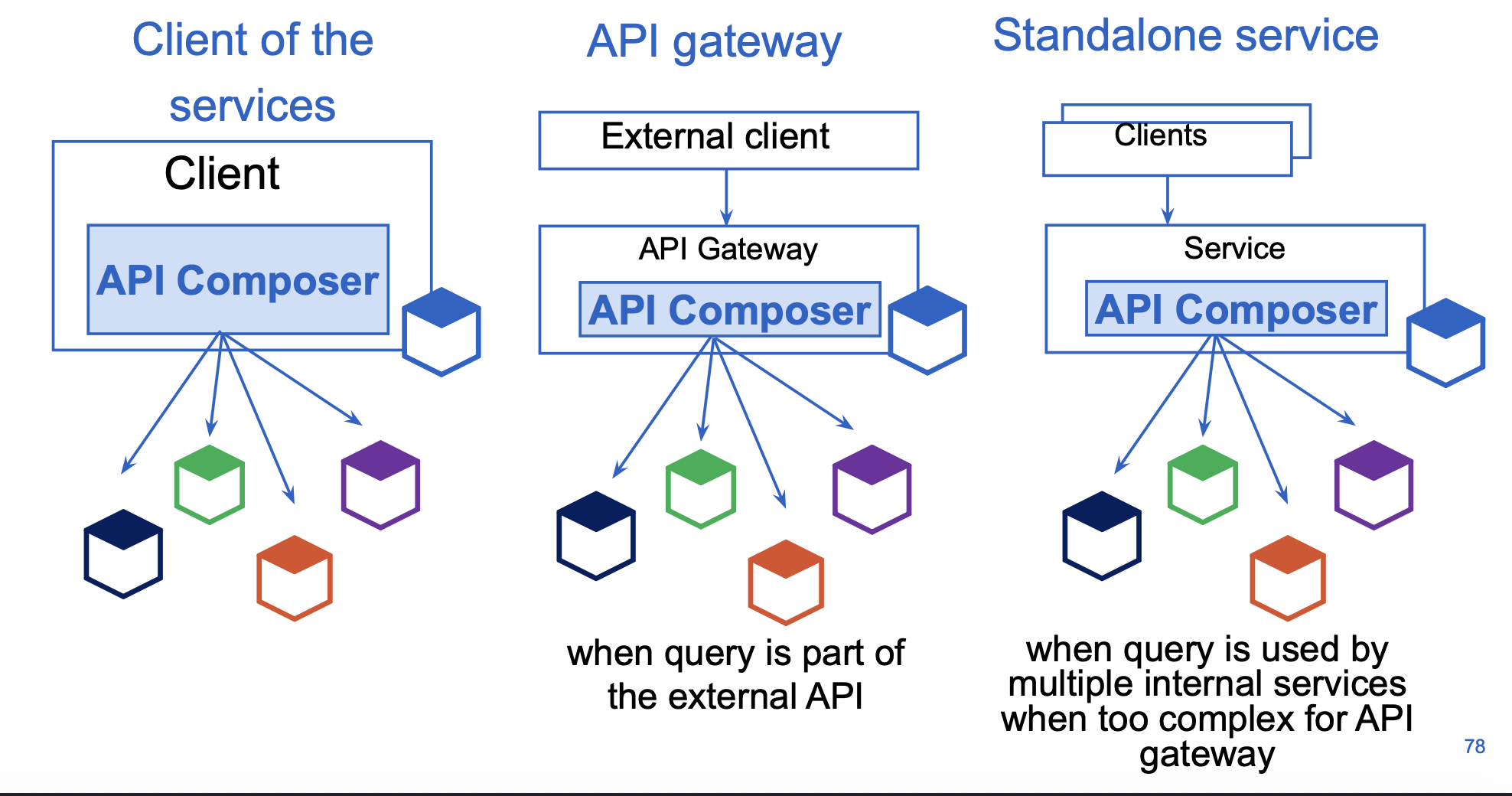
The api composition pattern
delen
hoe werkt het
waar kan de composer zitten
voor / nadelen
wanneer niet
= wanneer een query data nodig heeft van meerdere services
api composer: implementeerd de query operatie door de provider services te querien
provicer serivce: bezit deel van de data dat de query returned
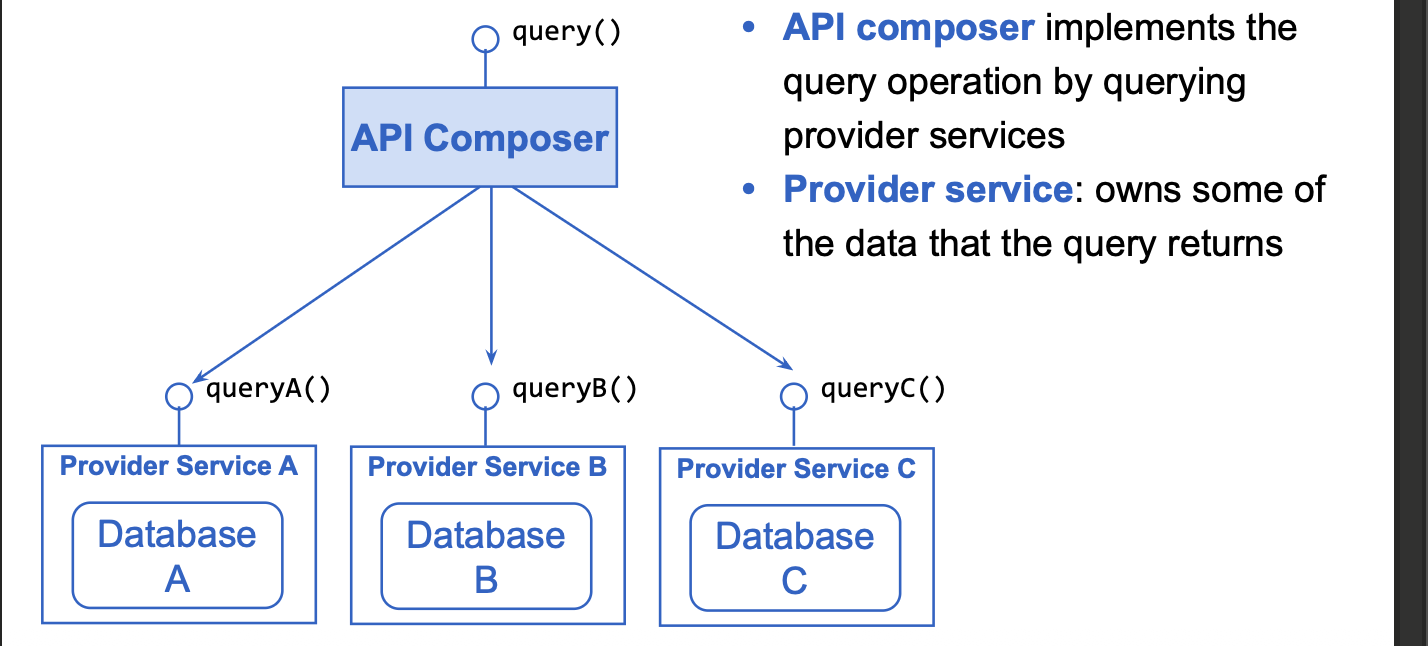
Hoe werkt het (volgens de slides):
Een API Composer ontvangt de query.
De composer roept meerdere provider services aan.
Elke provider service bezit zijn eigen data.
De composer voegt de resultaten samen en retourneert één view.
Where can the composer live?
Client-side composition: client calls all services
Simple but too many round trips and exposes internals.
API Gateway as composer: gateway orchestrates calls
Good for external API aggregation.
Dedicated composition service: internal service that composes views
Useful when composition is complex or reused internally.
Voordelen:
Eenvoudig en intuïtief
Nadelen (belangrijk):
overhead: meerdere request en db queries
risico van lagere availability: composer kan gedeeltelijke / cached data returnen
Geen transactionele consistentie (meerdere DB’s).
Wanneer niet geschikt?
Als de query moet filteren op data die een service niet heeft
→ dan is CQRS met een read model beter.