Databases
1/37
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
38 Terms
Object Relational Databases
databases where specific data types are more naturally represented in original form (ex: X-ray scans)
Create Type
CREATE TYPE complex AS (r double precision, r double precision)
Create FUNCTION
CREATE FUNCTION AS (complex, complex)
CREATE Operator
Create operator + (leftarg = complex rightarg = complex function = complex_add commutator = +)
CREATE aggregate average (complex)
CREATE AGGREGATE average (complex) (sfunc = complex_add stype = (complex, integer) finalfunc = divide_complex_by_int init_cond = (0,0)
Text in postgres
Select 'a fat cat sat on a mat and ate a fat rat'::tsvector@@'cat & rat'::tsquery
Text queries
& AND, | OR, ! NOT, <-> next-to (
Ranking in search
TF(k) → normalized by length
IDF(k) → normalized by how discriminating keywords are
TF * IDF
Memory Hierarchy
Register, CPU cache, RAM, SSD, Magnetic disks, tape, remote
First 3 are volatile (quickest also)
SSD
solid state drive
states represented as electron voltage
low charge = 1, high charge = 0
charges can be freely sensed in read
pristine page = all 1s
writing from 1 to 0 is easy
writing from 0 to 1 involves an erase-block to reset many pages
Magnetic disks
To read: seek to right track (seek latency) → wait until requested data rotates in time (rotational latency) → transfer (transfer time)
Rotational latency depends on RPM (to find, find how many seconds per rotation and get average (multiply by .5))
Solutions to SSD failure
Mirroring → write on two SSDs
Mirror and striping → mirroring while reading from both at same time
RAID
RAID
Keep one disk that is related to the others
Ex: P1 = A1 XOR B1 XOR C1 XOR D1
If parity disk fails: recompute parities
If other fails: calculate value from parity
Problem: parity disk is used frequently
Solution: rotate which disk is parity disk
Grouping data
Row-store (favors inserting data) and column-store (favors few columns)
Record-identifier (RID)
A record can then be accessed via a pair of:
• Disk block address
• Offset into the pointer array

Buffer pool
The buffer pool is a RAM cache for hot data
Replacement policies: least recently used, least frequently used

B+ tree
Used to store (value, RID) pairs where the value comes
from the indexes attribute(s) and the RID is the record having that
value
Has n values and n+1 pointers down to lower trees
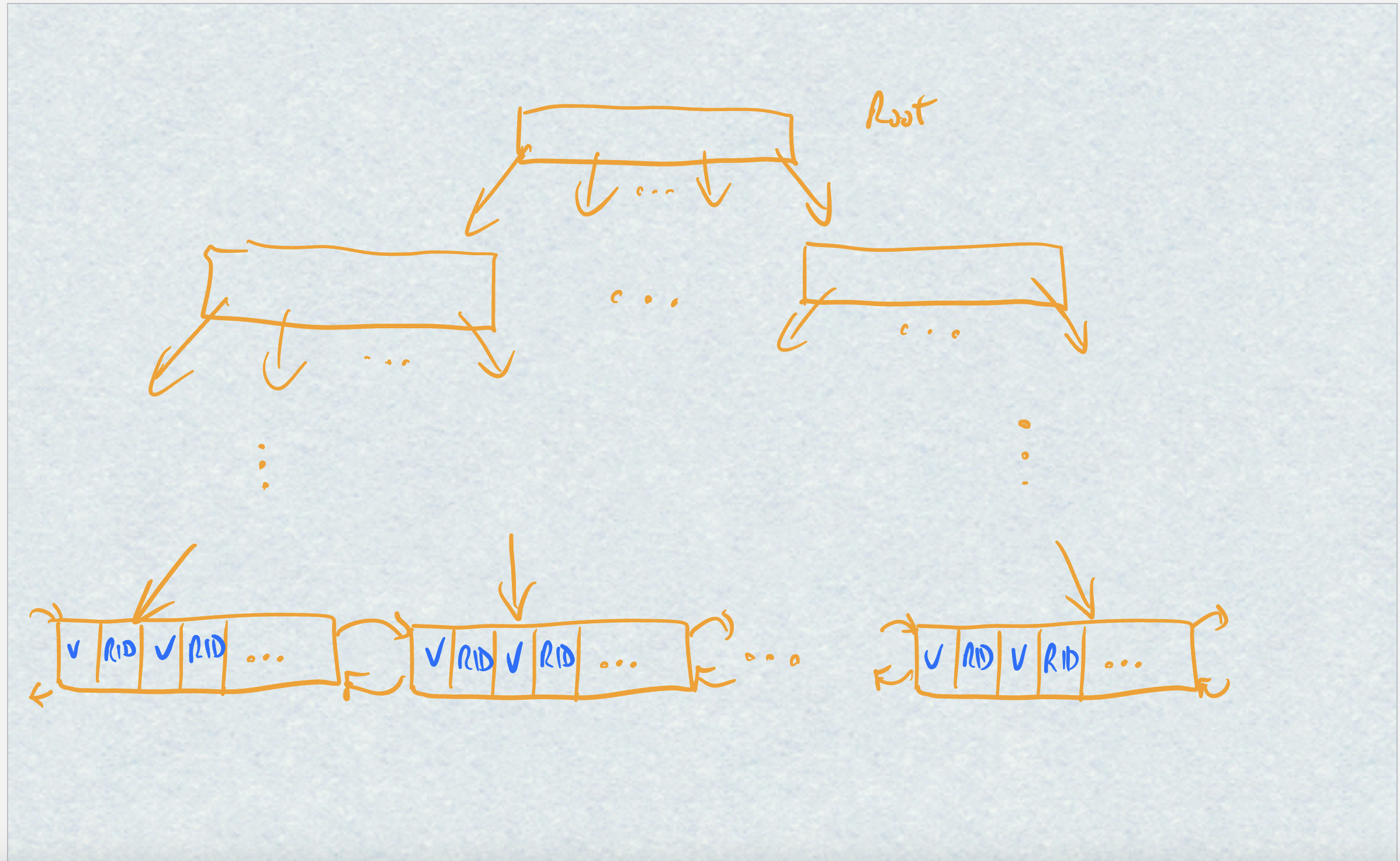
Example of B+ tree math: E.g., suppose that values and block pointers each take 8 bytes, and that our block size is 4096 bytes. How many levels in a 256-way search tree of 2^30 items?
Need 8n + 8(n+1) <= 4096
16n <= 4088
n <= 255
So a branching factor of up to 256 (i.e., n+1) is possible
log(base 256) 2^thirty = 4
Clustered vs unclustered B+ trees
Cost of B+ trees
Main file sorted or unsorted by index key
cost = (h + n)*(t_T + t_S)
where
h = tree height
n = #records fetched
t_T = transfer time
t_S = seek+rotation time
First group of hash query process operators and their cost (if it fits in RAM)
Eliminate duplicates: |R|
Equaliity-join: |R| + |S|
Aggregation: |R|
One layer of partitioning
If the necessary data cannot fit in RAM, then we can make a pass though the inputs to partition them into smaller pieces.
For duplicate elimination, partition-number = f(record)
For equality joins, partition-number = f(join-attribute)
For aggregationpartition-number = f(group-by attributes)
Cost of the partitioning phase is one scan of each input (to read)
plus one scan of each input (to write the partitions) (ex: multiply all times by 3)
Sort-merge
a) Sort each input by join-key
b) Merge them in join-key order
cost = (#records in R)*(index lookup cost) + |R|
Left-deep trees and pipelining
left-deep tree: left-most branch is deepest
Pipelining: In a query plan with many joins, you can pause processing of a particular join once it has generated a certain amount of output
store the intermediate output in an in-memory buffer
Then start processing the parent join to consume that output
pause the parent operator when its output fills a buffer, or when
the input is exhausted
Keep processing in this way, alternating between joins
Optimality principle to create most efficient joins
Step 1 → find most efficient plan for each table
Step 2 → find most efficient plan to join each table from step 1 with another table. Keep cheapest for each group of 2 tables
Step 3 → find most efficient plan to join each plan from step 2 with another table. Keep the cheapest for each group of 3 tables
Index-only plans
Sometimes queries can be answered using information in the index without even consulting the main table, such as by looking just at B+ leaves
Materialized views
Create Materialized View V As
Select ...
From ...
Where ...
Like a conventional view, but now the records in the view are explicitly stored in the database. Use a refresh function for incremental maintainence
Isolation
Partial transaction effects are not visible to other transactions
Conflict-equivalence (CONFLICTS)
Two operations conflict if operations operate on same data item and at least one of them is a write
Conflict-equivalence
Order of conflicting operations in 2 schedules is the same
Conflict serializable
Conflict equivalent to a serial schedule. A schedule is conflict serializable if the order of its conflicting operations is the same as the order of conflicting operations in some serial schedule.
Finding conflict serializability using dependency graph
nodes are transactions, edges for each pair of conflicts, cycle means not serializable
2PL
two phase locking means of concurrency control. Before reading an item, need to obtain a shared lock. Before writing an item, need to obtain an exclusive lock. Once a transaction is done with an item, it can release locks it no longer needs
Two-phase protocol:
• During an initial phase, locks are obtained but not released.
• During a subsequent phase, locks are released, and no new locks are requested.
2PL issues
deadlocks. Addressing deadlocks
1) Detect it. Maintain a graph of which transactions are waiting for each other. If a cycle occurs, abort some transaction in the cycle.
2) Time-out if a transaction takes "too long".
• Requires sophisticated tuning of timing thresholds
3) Prevent it by locking in a restricted way.
• Always lock items in a fixed order (e.g., lexicographic)
• Always obtain all locks at the start, and abort if that's not possible.
• Problem: unrealistic to know at the start of a transaction which items are going to be accessed
Timestamp-based protocol
Check if transaction’s timestamp is happening after the most recent write’s timestamp
Optimistic protocol
Instead of locking, just operate like no issues and see if there are issues later
Durability
Our buffer pool has two performance-oriented choices:
No force, i.e., we will update the buffer pool page without forcing the updates to persistent storage.
Steal, i.e., a buffer pool page could be evicted even when it contains uncommitted modifications.
No-force means that we might lose updates in case of failure.
Steal means we may have uncommitted updates on persistent storage after a failure, and those updates will need to be reversed.
Log data structure
Append-only file on persistent storage that records updates made by transactions
Recovering using Log
ARIES (Analysis, redo, undo)
Analysis identifies committed vs uncommitted transactions and dirty pages.
Redo reapplies all updates (committed and uncommitted) that might not be on disk, using the dirty page table.
Undo rolls back all uncommitted transactions using the transaction table and the log.