GFS, Parallel Processing Platforms, Net Virtualization
1/113
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
114 Terms
what is a distributed file system
allows access to files from multiple hosts sharing via a computer network using a protocol
what are the desirable characteristics/properties
network transparency
location transparency
location independence (file mobility)
fault tolerance
scalability
user mobility
explain location transparency
file name does not reveal the file’s physical storage location.
most DFSs provide this. client based mounting.
explain location independence
file name does not need to be changed when the file’s physical storage location changes.
file migration(AFS/GFS supports this). server based flat naming.
how does UNIX semantics deal with shared files
every operation on a file is instantly visible to all processes
how does session semantics deal with shared files
no changes are visible to other processes until the file is closed
how does immutable files deal with shared files
no updates are possible; simplifies sharing and replication (read only)
how does transaction deal with shared files
all changes occur atomically.
which means all changes occur and finish completely or none are.
what is the goal of a local procedure call in terms of execution?
to execute exactly one call
why might a remote procedure call (RPC) be executed 0 times?
the server crashed or the server process died before executing server code
what does it mean if an RPC is executed 1 time?
the RPC works as intended - everything went well
is achieving “exactly once” semantics easy in RPC
No, its difficult due to excess latency or lost reply from server, client retransmitted
what are the main two types of RPC semantics
at least once and at most onceh
what does at least once RPC semantics mean
the call is guaranteed to be executed one or more times
what kind of functions are safe with at least one semantics
idempotent functions - they can run any number of times without harm
what is an example of a suitable app for at least once semantics
logging, read operations, or updating a cache
what does at most once RPC semantics mean
the call is executed either once or not at all
what is an example of a suitable app for at most once semantics
financial transactions or creating user accounts (non-idempotent operations)
what are google’s key needs in its search system?
crawl the web, store it all on one big disk, and process user searches on one big CPU
why can a single PC handle google’s needs
it doesnt have enough storage or CPU power
why not just use a custom parallel supercomputer
it is too expensive and not easily available
How can we build a supercomputer using cheaper hardware?
Use a cluster of many cheap PCs, each with its own disk and CPU.
What are the benefits of using a PC cluster?
High total storage and spread search processing across many CPUs
What is Ivy and how does it share data?
Ivy uses shared virtual memory with fine-grained consistency at the load/store level.
What is NFS and what does it aim to do?
Network File System (NFS) shares a file system from one server to many clients, mimicking UNIX file system behavior.
What consistency model does NFS use for performance?
Close-to-open consistency.
What is GFS and why was it created?
Google File System (GFS) is a file system designed specifically to handle data sharing in clusters for Google’s workloads.
How many PCs are typically in a Google cluster?
Hundreds to thousands.
What kind of hardware does Google use in its clusters?
Cheap, commodity parts.
What are common types of failures in Google’s clusters?
App bugs, OS bugs, human error, disk/memory/network/power/connector failures.
What is essential for handling frequent failures in Google’s clusters?
Monitoring, fault tolerance, and automatic recovery.
What is a key design goal of the Google File System (GFS)?
Detect, tolerate, and recover from failures automatically.
What types of data operations is GFS optimized for?
Large files (≥ 100 MB)
Large, streaming reads (≥ 1 MB), usually read once
Large, sequential appends, written once
How does GFS handle concurrent appends by multiple clients?
It supports atomic appends without requiring client synchronization.
What are the main components of the GFS architecture?
One master server (with backup replicas) and many chunk servers (hundreds to thousands).
How is data divided in GFS?
Into 64 MB chunks, each with a 64-bit globally unique ID.
How are chunk servers organized in the network?
Spread across racks; intra-rack bandwidth is faster than inter-rack.
Can many clients access GFS at the same time?
Yes, clients can access the same or different files concurrently in the same cluster.
what does GFS master server do?
holds all metadata: namespace (directory hierarchy) - access control info (per file) - mapping from files to chunks - current locations of chunks (chunk servers)
manages chunk leases to chunk servers
garbage collects orphaned chunks
where is metadata stored?
in RAM; this makes for fast operations on file system metadata
what is GFS chunk servers role
stores 64MB chunks on local disks using standard Linux file system (each with a version number and checksum).
read/writes are specified by chunk handle and byte range
chunks are replicated on configurable number of chunkservers
CANNOT cache file data.
what is GFS clients role?
issues control (metadata) requests to master server
issues data requests directly to chunkservers
caches metadata
CANNOT cache data [no consistency difficulties among clients, streaming reads (read once) and appends write (write once) don’t benefit from caching at client]
is GFS a file system in traditional sense?
no, its a user space library that applications link to for storage access
does GFS mimic UNIX semantics
no it only partially does
what are the main API functions by GFS
open, delete, read, write, snapshot, and append
what does the function snapshot do
quickly create copy of file
what does the function append do
at least once, possibly with gaps and/or inconsistencies among clients
how does the client read
client sends master —> read(file name, chunk index)
master replies —> chunk ID, chunk version num, locations of replicas
client sends closest chunk server w/replica —>read(chunkID, byte range)
closest determine by IP address on simple rack-based network topology
chunkserver replies with data
how does the client write
some chunk serve is the primary chunk, master grants lease to primary for typically 60 secs. leases renewed using periodic heartbeat messages between masters and chunkservers.
client asks server for primary and secondary replicas for each chunk.
client sends data to replicas in daisy chain
what happens after replicas are daisy chained/pipelined
all replicas acknowledge data write to chunk server. client sends write request to primary.
primary assigns serial number to write request, providing order. it forwards write request with same serial number to secondaries.
secondaries all reply to primary after completing write.
primary replies to client.
what is GFS consistency model
any changes to namespace (metadata) are atomic
done by a single master server. this master uses log to define global total order of namespace changing operations
data changes are more complicated
consistent - file region all clients see as same, regardless of replicas they read from
defined - after data mutation, all clients see that entire mutation
what are app and record append semantics
apps should include checksums in record they write using record append
reader can identify padding / record fragments using checksums
if app cannot tolerate duplicate records, it should include unique ID in record
reader can use unique ID to filter dupes
how does the master log
it has all metadata info. it logs all client requests to disk sequentially. replicates log entries to remote backup servers.
it only replies to client after log entries are safe on disk on self and backups.
how do chunk leases and version numbers work
if there is no outstanding lease when client requests write, master grants new one.
chunks have version numbers
stored on disk as master and chunkserver
each time master grants new lease, it increments version and informs all replicas
master can revoke it (if client request rename or snapshot)
what is master reboots
replays log from disk to recover namespace info and file to chunk id mapping.
asks chunk server which chunk they hold to recover chunk ID to chunk server mapping.
if chunk server has older chunk, its stale.
if chunk server has new chunk, it adopts version number.
how was GFS a success
it is used actively by google to support search service and other applications.
high availability and recoverabilty on cheap hardware
high throughput by decoupling control and data
supports massive data sets and concurrent appends
how has GFS fallen short
semantics not transparent to apps - must verify file contents to avoid inconsistent regions and repeated appends (at least once semantics)
performance not good for all apps - assumes read once and write once, no client caching
what was wrong with GFS architecture
master - one machine not large enough, single bottleneck for metadata operations, need better HA
predicitable performance and no guarantees of latency
what replaces GFS
master replaced by colossus and chunkserver replaced by D
what was the file system for big table
append only, single write, multi reader, no snapshot or rename, directories not neccessary. so where to put meta data?
what are colossus components
client - most complex part
lots of functions such as software RAID, application encoding chosen
curators - foundation, its scalable metadata service
can scale out horizontally, built on NoSQL DB like BigTable, allows scaling 100x over GFS
D servers - simple network attached disks
custodians - background storage manager
handles such as disk space balancing and RAID construction
ensures durability, availability, and system efficiency
data - hot data and cold data
very efficient storage organization, mixing flash and spinning disks
just enough flash to push I/O density, and just enough disks to fill them
flash to serve really hot data and low latency
what is WORM
write once read many. this inspired MapReduce programming model.
different than transactional or the customer order data.
ex. web logs, web crawlers data, or healthcare and patient information
what was the motivation for MapReduce
process lots of data, a single machine cannot serve all the data
you need a distributed system to store and process in parallel
what is the difficultly in parallel programming
threading it hard. facilitating communication between nodes. scaling to more machines. and handling machine failures.
what does MapReduce provide
automatic parallelization, distribution
i/o scheduling - load balancing and network/data transfer optimization
fault tolerance - handling machine failures
what are typical problems MapReduce solved
read a lot of data
map - extract something you care about from each record
shuffle and sort
reduce - aggregate, summarize, filter, or transform
write the results
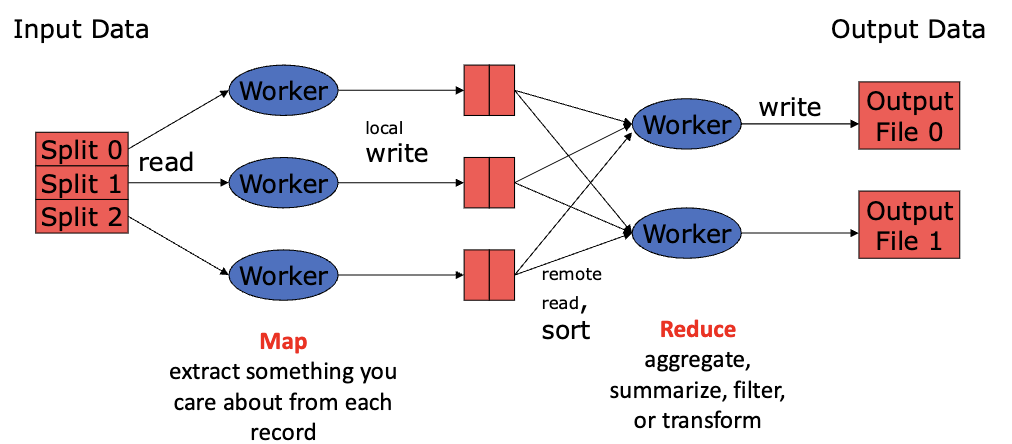
when to use mappers and reducers
need to handle more data - add more
no need for multithreaded code - the mappers and reducers are single threaded and deterministic meaning they allow for restarting of failed jobs
they run independently
how does mapper take input and output
reads in input pair and outputs a pair
input <key,value>
output <K’,V’>
how does reducer work with output
accepts the mapper output, and aggregates values on the key
ex. <store, 1><store, 1><store, 1> then the output would be <store, 3>
what kind failures can occur in mapreduce
this is a norm in commodity hardware.
worker failure - detect failures via periodic heartbeats, re-execute in progress map/reduce tasks
master failure - single point of failure, resume from execution log
summarize map reduce
programming paradigm for data-intensive computing with a distributed and parallel execution model. simple to program
what were map reduce two major limitations
difficulty of programming directly in it and performance bottlenecks, or batch not fitting the use cases. overall did not compose well for large applications
what was Sparks goal
to generalize mapReduce to support new apps within the same engine.
extend the mapReduce model to better support two common classes on analytics apps:
iterative algos (ML, graphs)
interactive data mining
enhance programmability:
integrate into scala
allow interactive use from scala interpreter
what were two additions to the previous model spark expressed
fast data sharing and general DAGs. this allowed for an approach more efficient for the engine and simpler for end users.
what are the key points about spark
handles batch, interactive, and real time within a single framework
native integration with java, python, scala
programming at a higher level of abstraction
more general - map/reduce is just one set of supported constructs
what is the benefit of acyclic data flow
stable storage to stable storage. runtime can decide where to run tasks and can automatically recover from failures.
what is the set back of acyclic data flow
inefficient for applications that repeatedly reuse a working set of data:
iterative algos (ML, graphs) and interactive data mining tools (R, Excel, Python)
current frameworks, apps reload data from stable storage on each query.
what was the solution to acyclic data flow
RDD Resilient distributed datasets. this allowed apps to keep working sets in memory for efficient reuses. retain the attractive qualities of map reduce (fault tolerance, data locality, scalability). support a wide range of applications.
what was the programming model for RDD
immutable, partitioned collections of objects.
created through parallel transformations (map, filter, groupBy, join) on data in stable storage.
can be cached for efficient reuse.
what actions are available on RDD
count, reduce, collect, save, etc.
what frameworks were build on spark
pregel on spark (bagel) - google message passing model for graph computation, 200 lines of code
hive on spark(shark) - 3000 lines of code.
how is spark implemented
runs on apache mesos to share resources with hadoop and other apps
can read from any hadoop input source (HDFS)
how does spark schedule
pipelines functions within a stage. cache aware work reuse and locality. partitioning aware to avoid shuffles
what did interactive spark require
scala interpreter modified so spark could be used in command line.
modified wrapper code generation so that each line typed has references to objects for its dependencies, and distributed generated classes over the network.
summarize spark
provides a simple efficient and powerful programming model for a wide range of apps
what are the layers in internet protocol
application - supporting network apps (HTTPS,IMAP,SMTP,DNS)
transport - process-process data transfer (TCP, UDP)
network - routing of datagrams from source to destination (IP, routing)
link - data transfer between neighboring network elements (ethernet, WiFI)
physical - bits on the wire
what is network virtualization
the process of combining hardware and software resources and network functionality into a single, software based admin entity, a virtual network (VN)
what does network virtualization enable
the coexistence of multiple VNs on the same physical substrate network. they share physical resources whilst being isolated from one another.
what does a physical substrate network consist of
physical nodes - servers and switches
physical links
what does a virtual network consist of
a collection of virtual nodes and virtual links with a subset of underlying physical resources
why would one prefer network virtualization
to separate different admin areas
to develop and test out new protocols
to adopt new protocols or techniques - multi provide nature of the internet, restricts the updates and deployment of new network tech
to support multi-tenant environments of cloud computing over widely spread data centers -
sharing computing, storage, and networking resources for different applications
incremental deployment of emerging applications
to support new/emerging applications (over cloud)
what are the goals of network virtualization
gives each app/tenant its own virtual network with its own: topology, bandwidth, broadcast domain
and delegate admin for virtual networks
how to implement a VN
VPN - virtual private network where you can connect multiple sites using tunnels over the public network. L3/L2/L1 technologies
VLAN virtual local area network - L2 network, partitioned to create multiple distinct broadcast domains, port level VLAN, or mark packets with tags
active and programmable networks - support co-existing networks through programmability. customized network functionality through programmable interfaces to enable access to switches/routers. (software defined network) L2,L3,L4
overlay networks - app layer virtual networks that are built upon existing network using tunneling/encapsulation. implement new services without changes in infrastructure.
how do static VLANS work
they are port based. switch port statically defines the VLAN a host its a part of
how do dynamic VLANS work
Mac-based. mac address defines which VLAN a host is a part of. typically configured by network admin.
how are VLANs tagged
access port - port connected to end host, assigned to a single VLAN
trunk port - port that sends and received tagged frames on multiple VLAN networks
VLAN tagging at trunk link
tag added to layer 2 frame at ingess switch
tag stripped at egress switch
tag defines on which VLAN the packet is routed
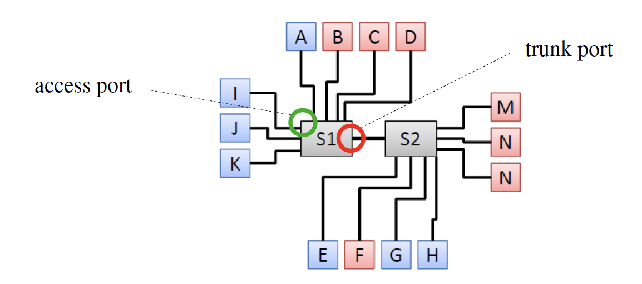
what are problems with VLANs
requires separate configuration of every network node, static config. requires admin, number of VLANS limited.
what is the purpose of software defined networks
to overcome network ossification, essentially the rigidity of internet protocols and techniques.
also to separate data plane and control plane
routing decision is computed in a controller
SDN routers/switches only forward packets based on routing decision made by controllers
SDN controller and routers are communicated through secure connections
explain forwarding
this happens on the data plane, its a network function of moving packets from router’s input to appropriate router output