L3 - Sequence Labelling and POS tagging
1/15
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
16 Terms
What is sequence labeling in NLP?
The task of assigning a label to each token in a sequence.
E.g.:
Part-of-Speech tagging (POS tagging)
Named Entity Recognition (NER)
Information extraction
Useful and challenge - sequence labelling
Useful: generalize information retrieval
Challenge:
Diff understand meaning from text
Word ambiguity
Context sensitivity
BIO tagging
Tagging format for sequences.
B: Begin
I: Inside
O: Outside
E.g.:
The New York Times reported
B-org: The
I-org: New, York, Times
O: reported
Sequence Label as classification
Classifier depends of words around
E.g.:
seems like it
if the goal is to class. “like” → check “seems” and “it”
Cons of Sequence Label as classification
Not possible to determine most likely of all tokens
cos does not model the dependencies between labels
Cannot change earlier decisions once made
What is a Hidden Markov Model (HMM)?
Probabilistic model
Predicts tag sequences based on state transitions.
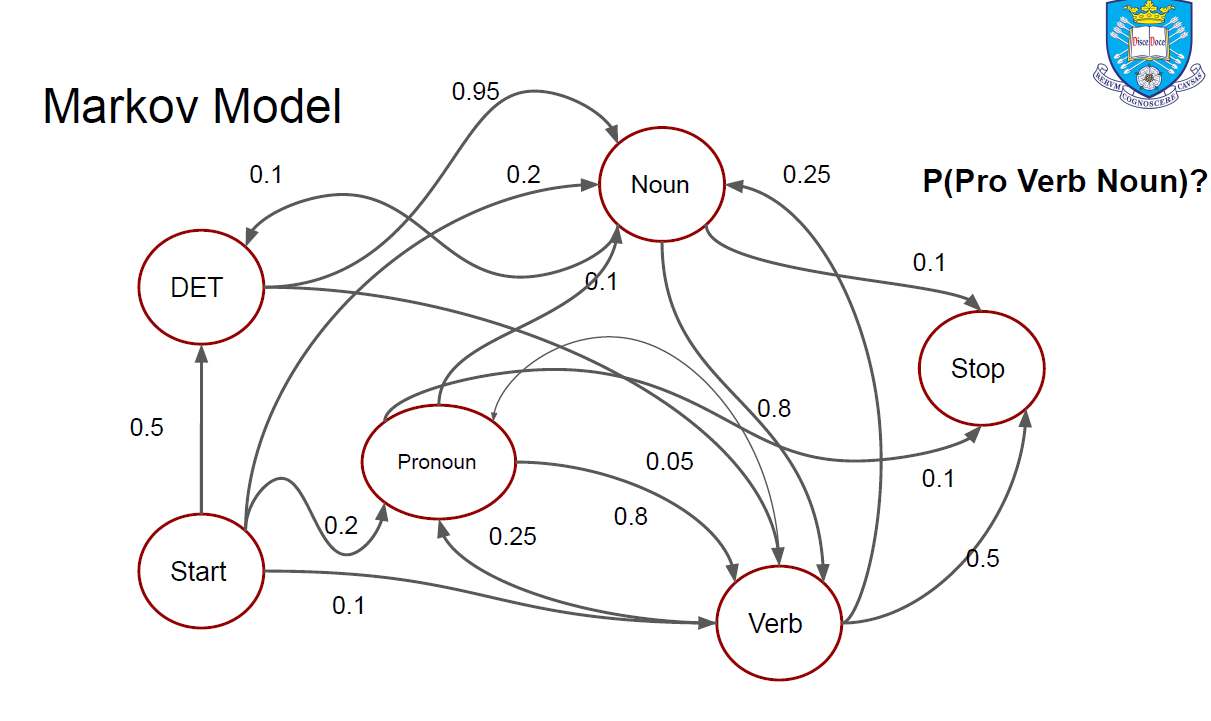
Markov assumption
Each next step only depends on current state
What are the three main problems solved in HMMs?
Given a model λ and a sequence of observations О = O1 O2 … OT
Evaluation
What is the proba the observations are generated by the model? P(O|λ)
Decoding
What is the most likely state sequence in the model that produced the observations?
Learning
How should we adjust the model’s parameters in order to MAX P(O|λ)?
HMM Evaluation (Likelihood)

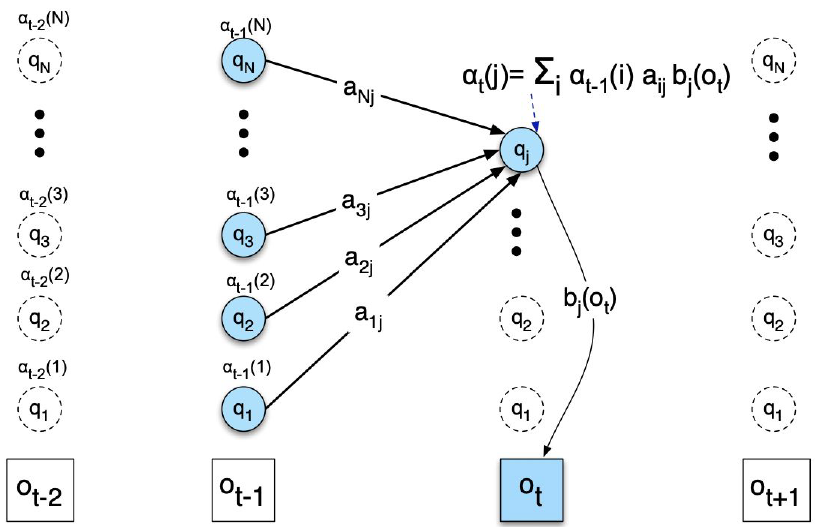
Forward Algorithm Complexity
O(TN2)
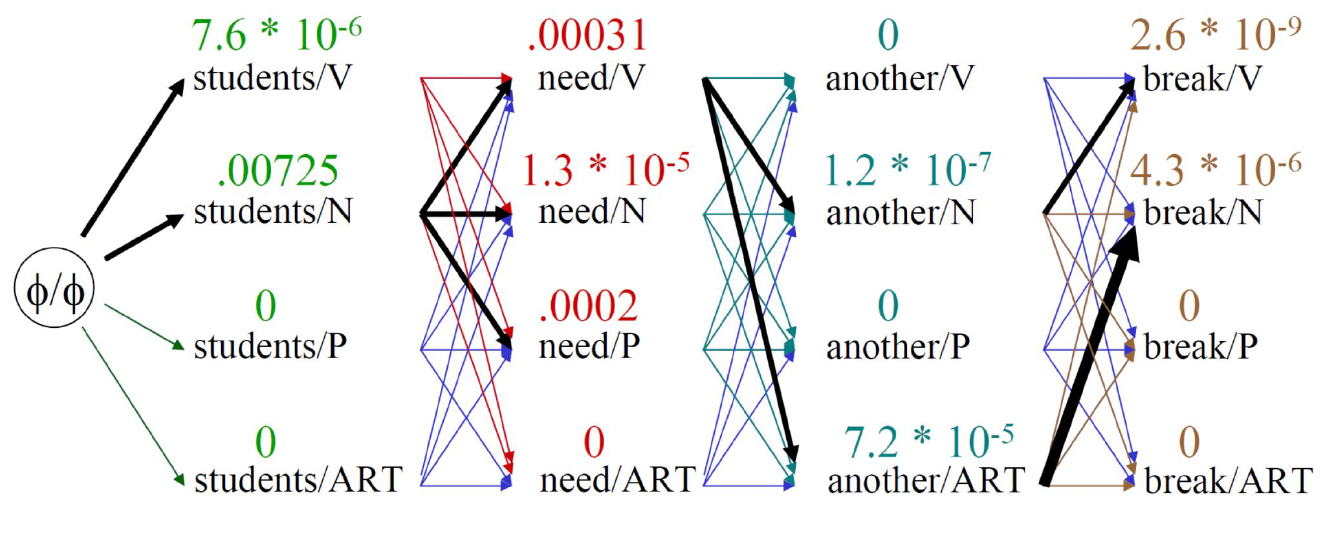
What algorithm is used for decoding in HMMs?
Viterbi Algorithm
Viterbi Algorithm
find the best path of length t-1 to each state.
extend each by 1 step to sj
take the best option (Max) and save the best path
Beam Search
Inexact
Keep only best k hypothesis at each step
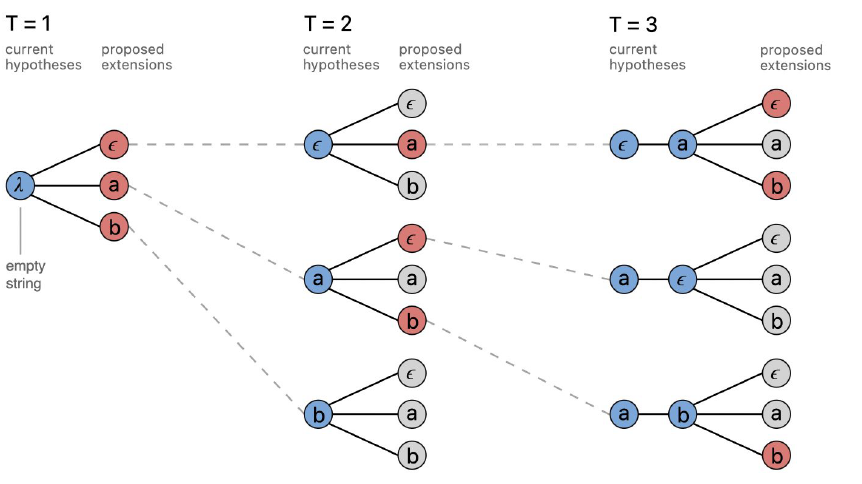
Diff Viterbi and Beam Search
Viterbi: Performs exact search (assumption) by evaluating all options.
Beam Search: faster but inexact. Avoids labeling some sequences
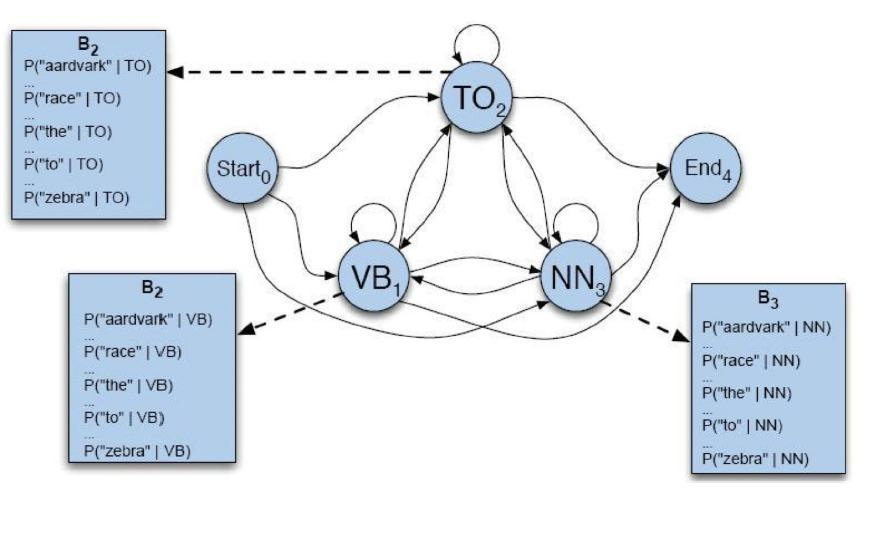
POS tagging
States = POS tags
HMM Learning - Supervised
Training instances with labeled tags
Learning with Maximum Likelihood Estimation (MLE)
Transition probabilities (aij)
Count(qt=si,qt+1=sj)/count(qt=si)
Observation likelihood (bj(k))
Count(qt=sj,oi=vk)/count(qt=sj)