[MSYS 140] Module 2
1/43
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
44 Terms
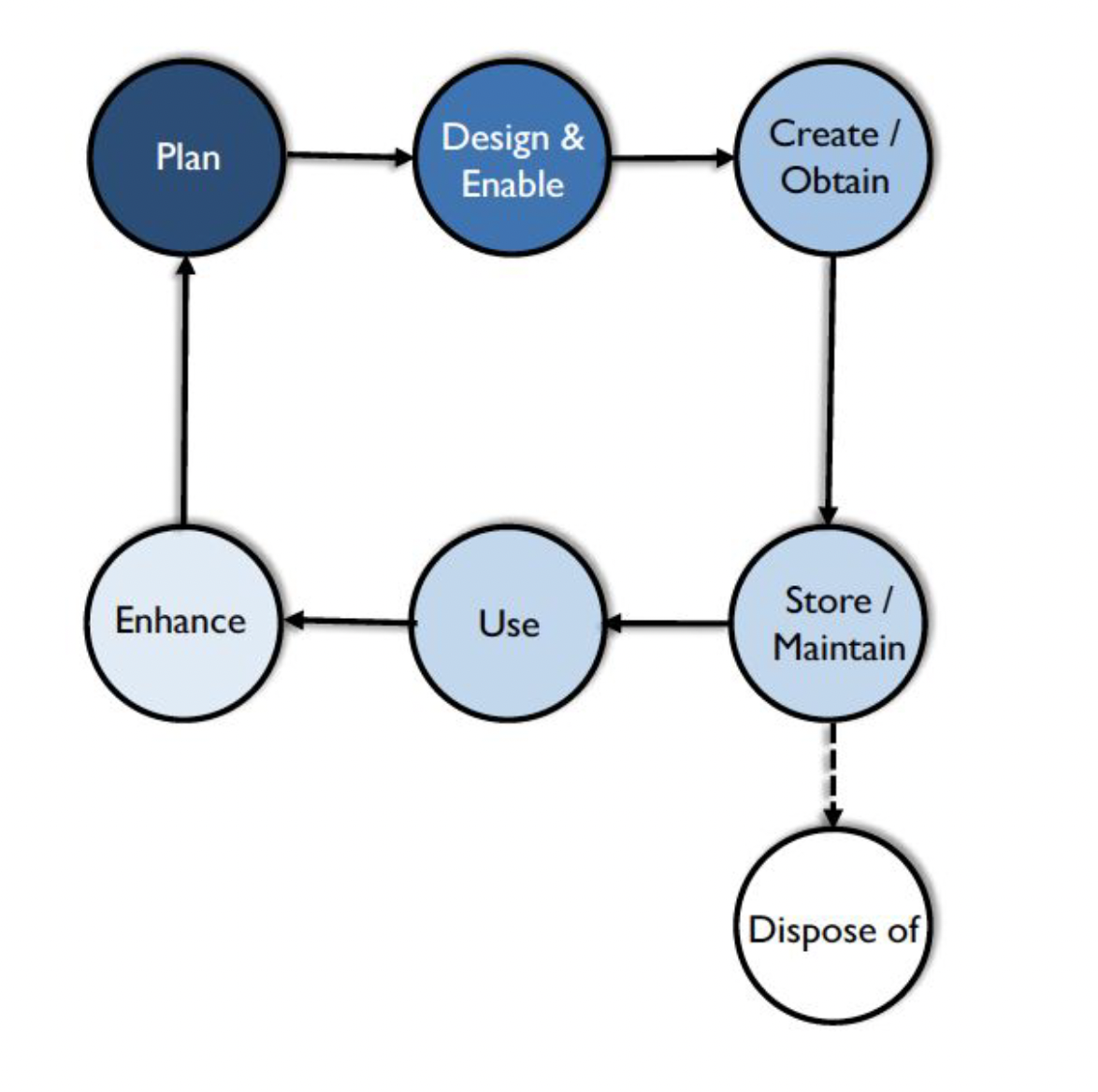
Data Life Cycle
The data lifecycle is based on the product life cycle
1. Plan
2. Design & Enable
3. Create / Obtain
4. Store / Maintain
5. Dispose of*
6. Use
7. Enhance
Data Storage and Operations
The design, implementation, and support of stored data to maximize its value.
● Primary Goals:
Manage availability of data throughout the data lifecycle.
Ensure the integrity of data assets.
Manage performance of data transactions.
● Crucial for the continuity of operations of businesses relying on data.
If a system becomes unavailable, company operations may be impaired or stopped completely.
A reliable data storage infrastructure for IT operations minimizes the risk of disruption.
Database
Any collection of stored data, regardless of structure or content.
Instance
An execution of database software controlling access to a certain
area of storage.
Schema
A subset of a database objects contained within the database or an instance. Used to organize objects into more manageable parts.
Node
An individual computer hosting either processing or data as part of a distributed database.
Database Abstraction
means that APIs are used to call database functions,
such that an application can connect to multiple different databases.
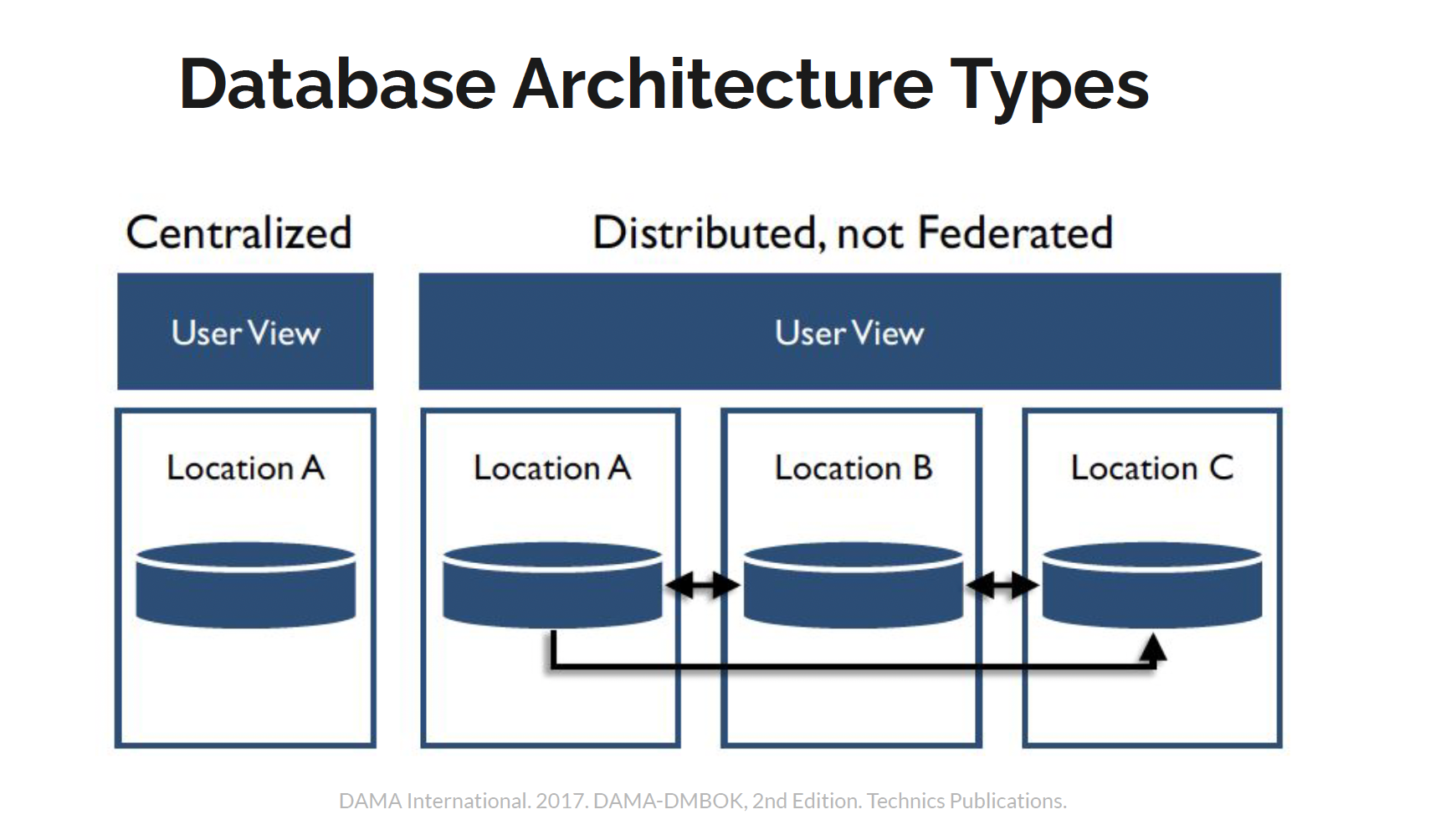
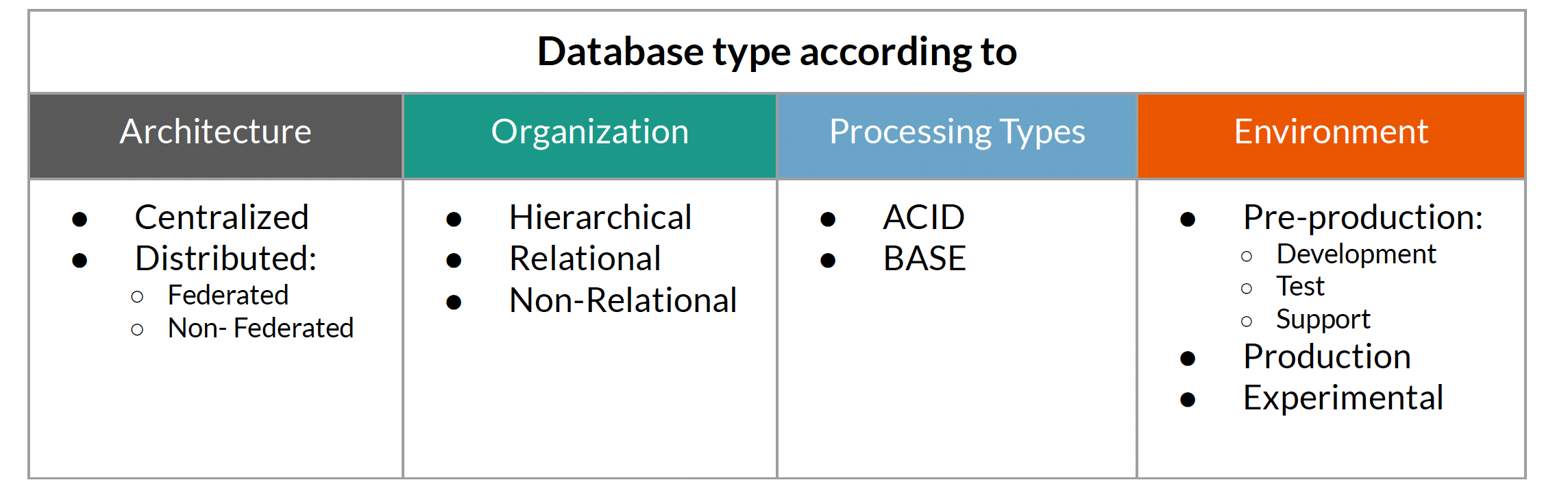
Database Architecture Types
Centralized Databases
Have all the data in one system in one place.
If the centralized system is unavailable, there are no other alternatives for accessing the data.
Ideal for data security
Not ideal for data accessibility
Distributed Databases
Provide quick access to data over a large number of nodes.
Designed to scale out from single servers to thousands of machines, each offering local computation and storage.
Federated or Non-Federated: depending on the view it provides it users.
Blockchain is an example of a distributed federated database commonly used to store financial transactions.
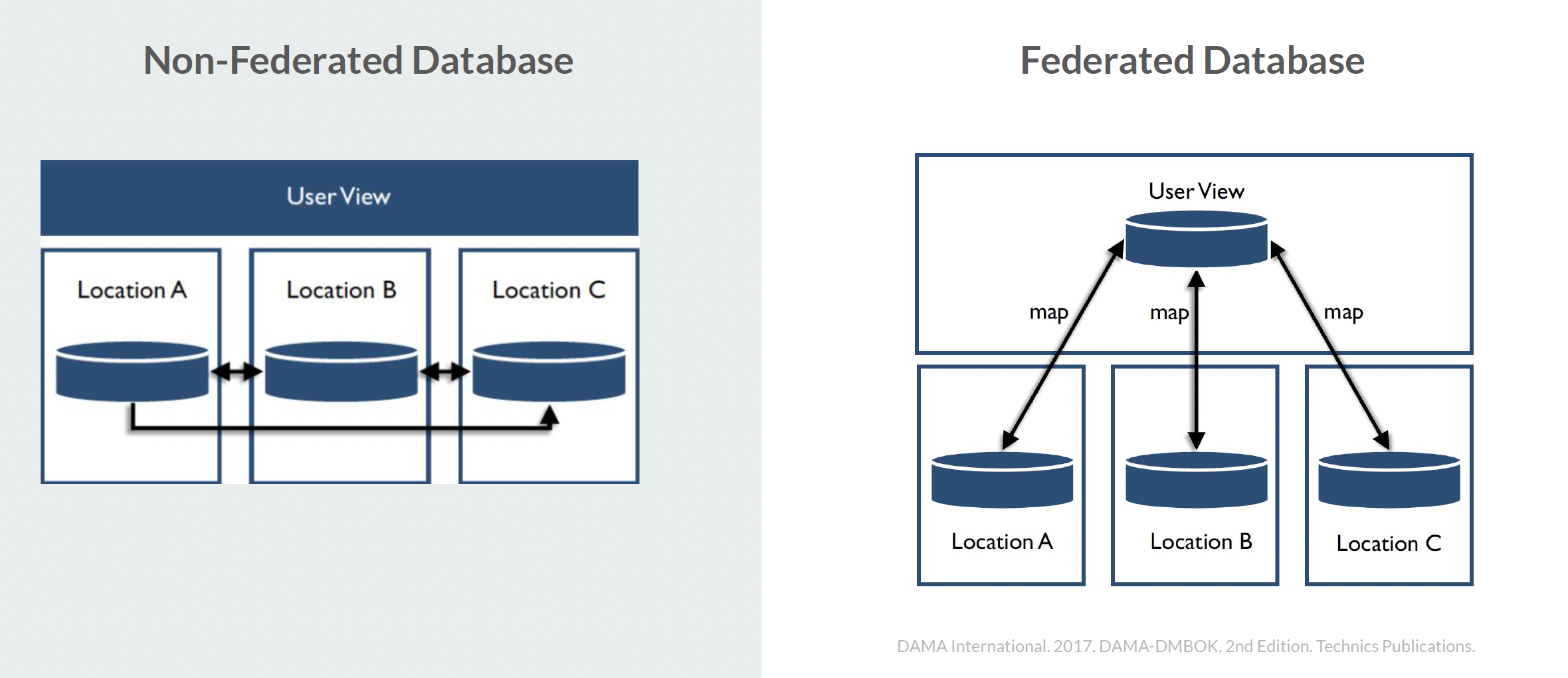
Federated vs Non-Federated Database
cohesive, integrated view of the dispersed data (federated) or a more decentralized view (non-federated)
Blockchain is given as an example of a distributed federated database that is commonly used to store financial transaction
Federated: Like a travel aggregator (Skyscanner, Expedia). You search once, it fetches results from multiple airlines and hotels without moving their data into one place.
Non-Federated: Like a single airline’s booking site. All data is already managed and stored in one system.
Database Organization Types
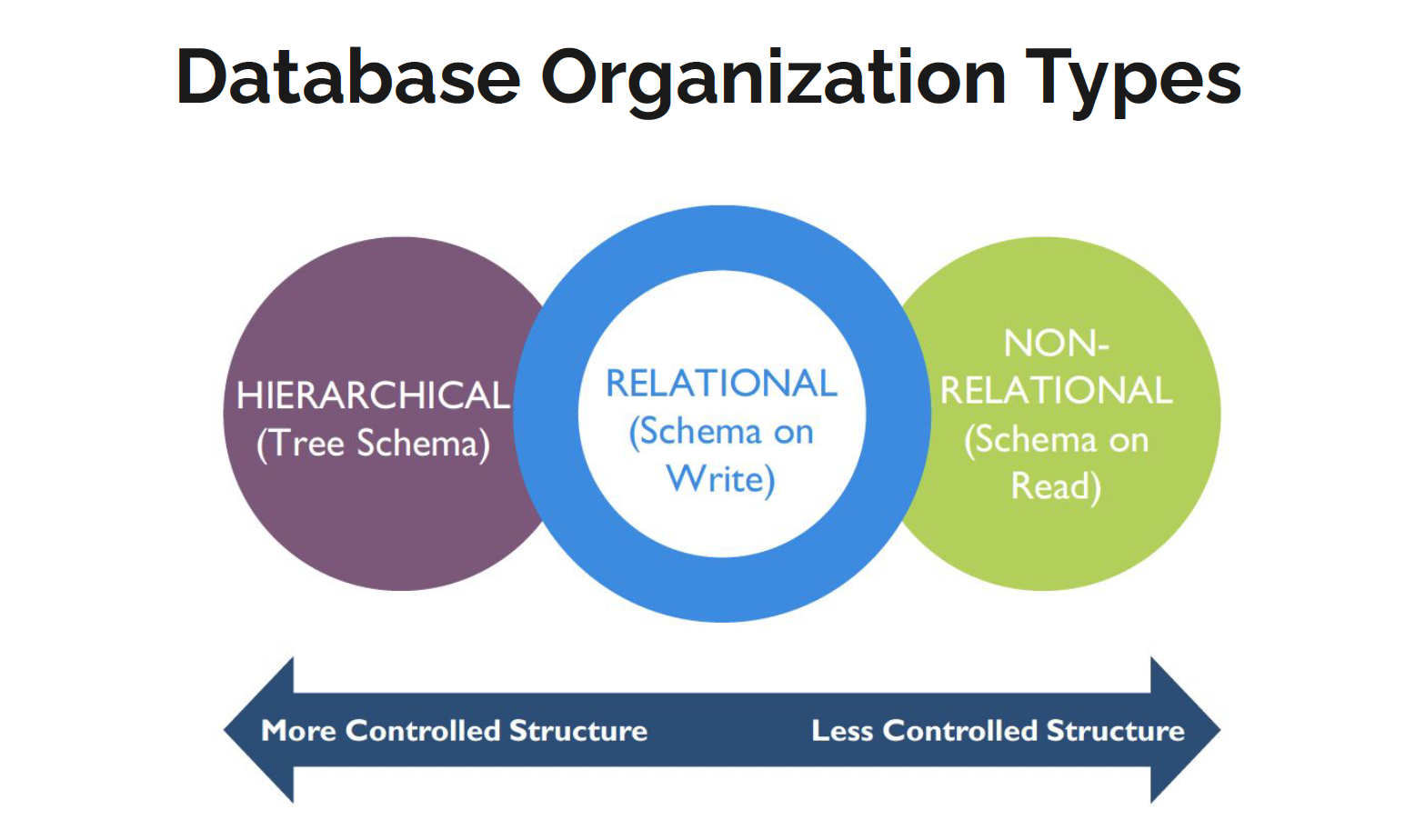
Hierarchical Databases
Oldest and most rigid database model, used in early mainframe DBMS.
Data is organized into a tree-like structure with mandatory parent/child relationships
Each parent can have many children, but each child has only one parent
Relational Databases
Row-oriented, where tables in the database are sets of relations with identical structure.
Predominant choice in storing data that constantly changes
Set operations (like union, intersect, and minus) are used to organize and retrieve data from relational databases, in the form of Structured Query Language (SQL).
Non-relational Databases
May be row-oriented, but is not required.
Stores data as simple strings or complete files
Employs a less constrained consistency model for storage and retrieval of data
NoSQL (which stands for “Not Only SQL”).
The primary differentiating factor is the storage structure itself, where the data structure is no longer bound to a tabular relational design.
It could be a tree, a graph, a network, or a key-value pairing.
CAP Theorem
The theorem asserts that a distributed system cannot comply with all
parts of ACID at all time.
The larger the system, the lower the compliance. A distributed system must instead trade-off between properties
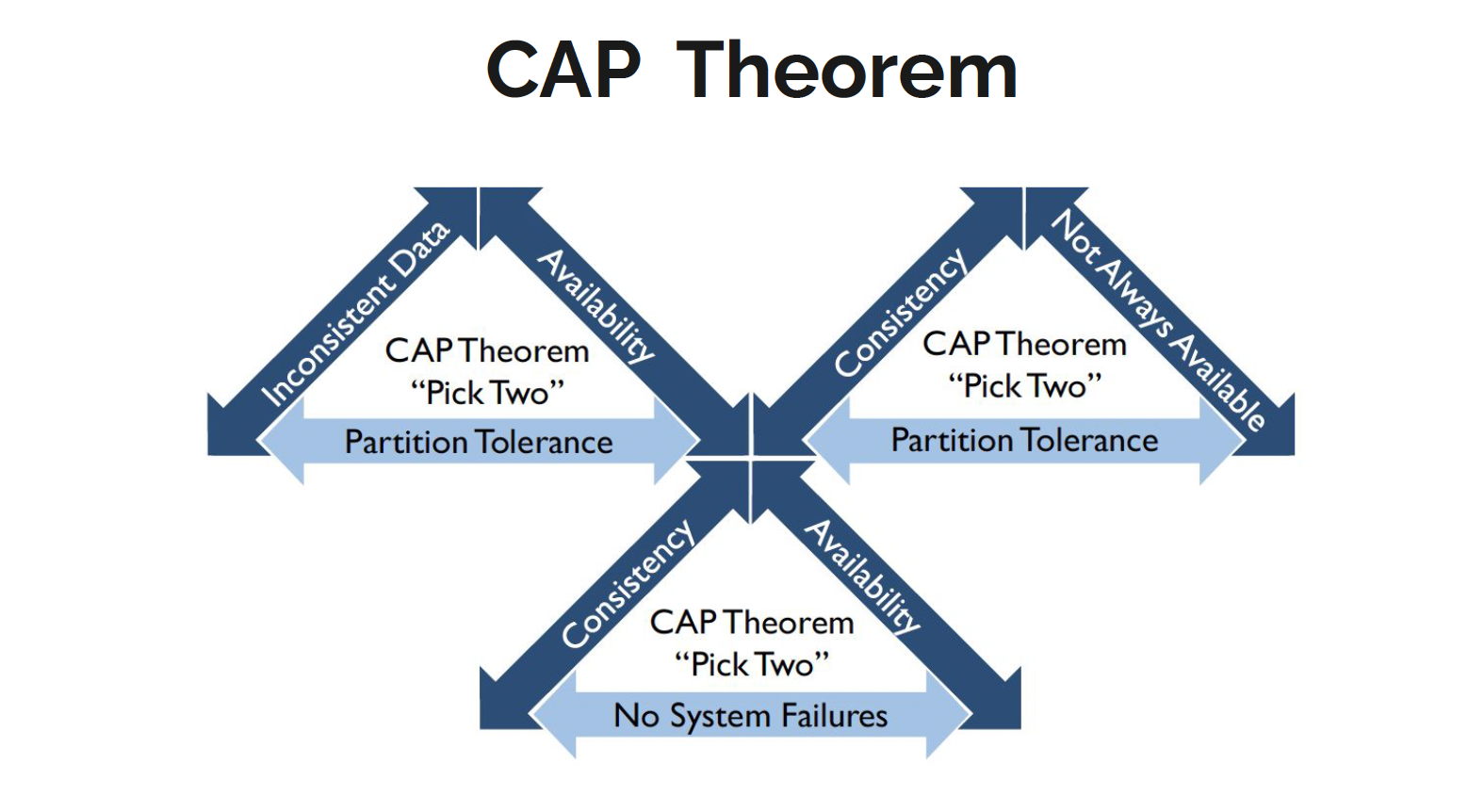
Consistency
The system must operate as designed and expected at all times
Availability
The system must be available when requested and must respond
to each request.
Partition Tolerance
The system must be able to continue operations during
occasions of data loss or partial system failure.
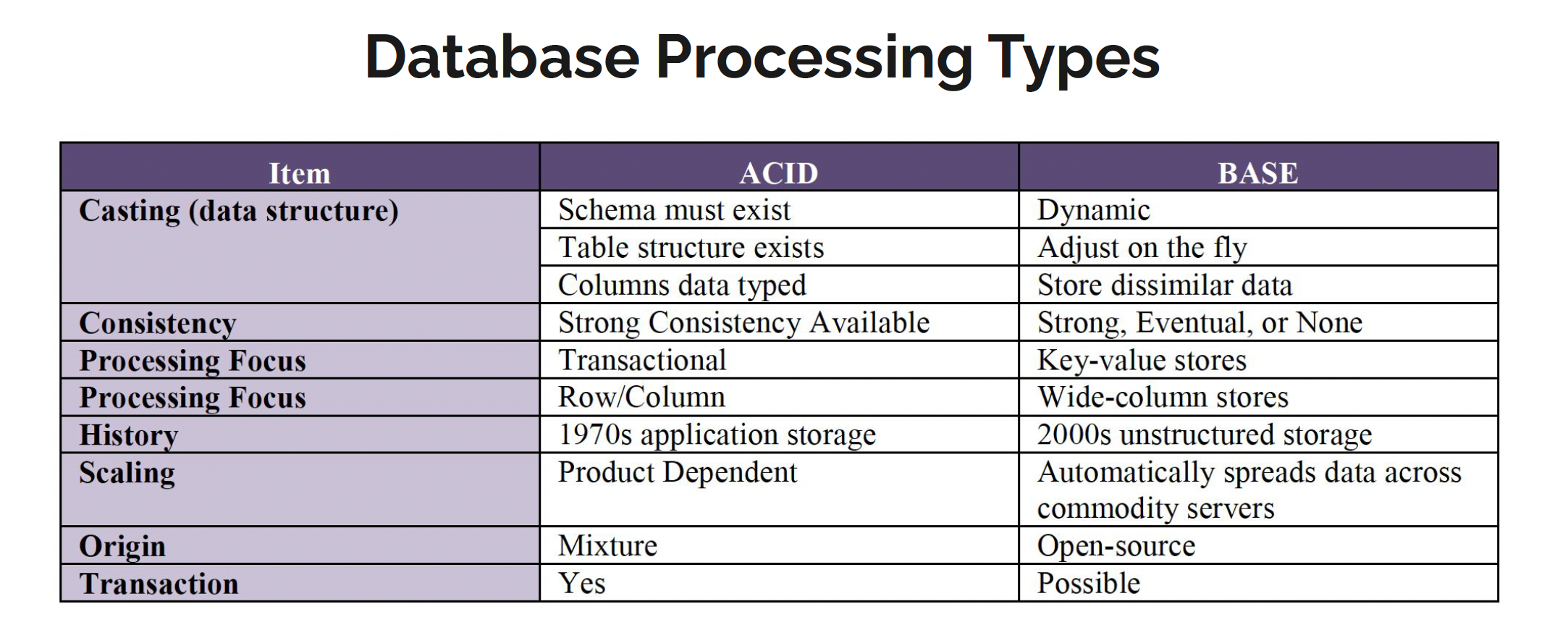
ACID Databases
Database Processing Types
Atomicity: All operations are performed, or none of them is, so that if one part of the transaction fails, then the entire transaction fails.
Consistency: The transaction must meet all rules defined by the system at all times and must void half-completed transactions.
Isolation: Each transaction is independent unto itself.
Durability: Once complete, the transaction cannot be undone.
BASE Databases
Basically Available: Guarantees some level of availability to the data even when there are node failures.
Soft State: The data is in a constant state of flux; while a response may be given, the data is not guaranteed to be current.
Eventual Consistency: The data will eventually be consistent through all nodes and in all databases, but not every transaction will be consistent at every moment.
Database Processing Types
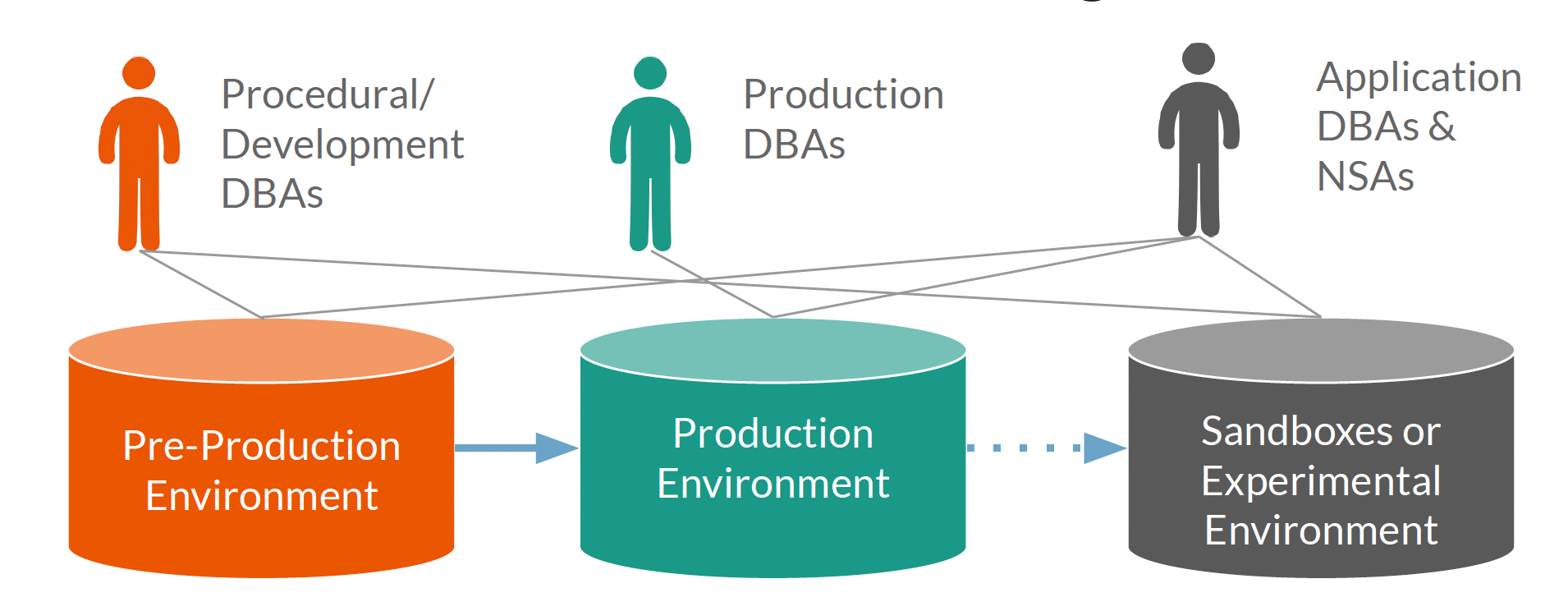
Database Environments
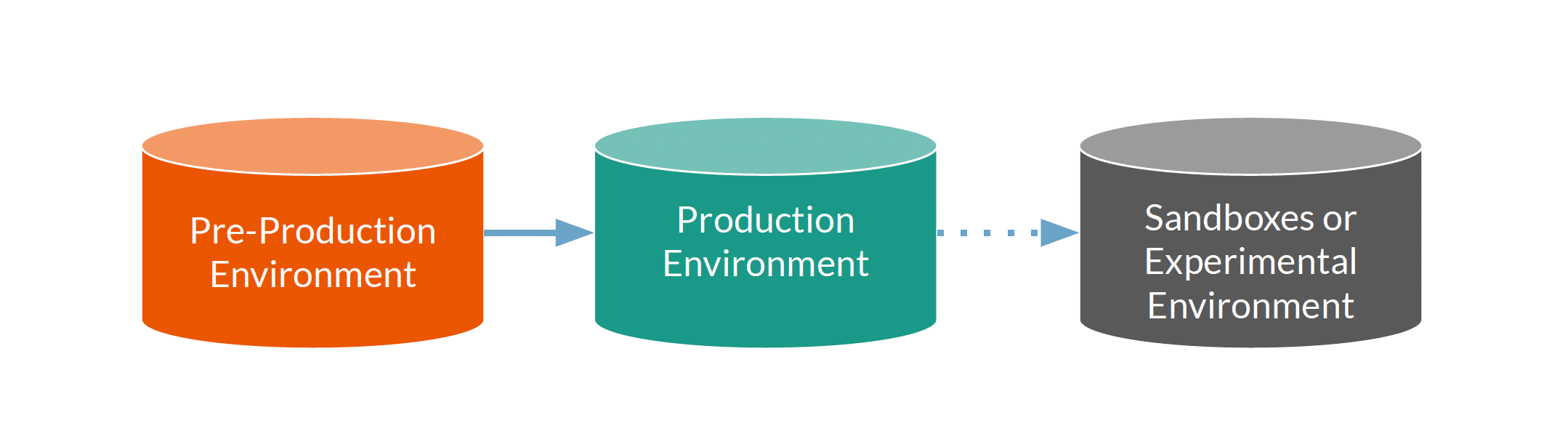
Production Environment
‘Real’ environment from a business perspective
It is where all actual business processes occur
Mission-critical to the business, if this environment ceases to operate, business processes will stop.
Should not be used for development and testing
Pre-Production Environment
Used to develop and test changes before such changes are introduced to the production environment
Issues with changes can be detected and addressed without affecting normal business processes.
Must closely resemble the production environment.
Common types: development, test, support, and special use environments.
Sandboxes or Experimental Environment
Used to experiment with development options and test hypotheses about data from production
Provides quick validation ideas and options for changes to the system.
Used when performing Proof-of-Concept
Should never write back to the production systems
Database Type According to
Database Administrators
DBAs are the most established and the most widely adopted data professional role.
Provide support for development, testing, Quality Assurance, and special use database environments.
Companies with huge operations divide specific roles for DBAs according to different database environments and use cases.
Production DBAs
Data Operations Management
Ensures the performance and reliability of the database, through performance tuning, monitoring, error reporting, etc.
Implementing measures for:
Backup and recovery mechanisms
Clustering and failover of the database
Archiving data
Procedural and Development DBA
Procedural: specializes in development and support of procedural
logic controlled and executed by the DBMS (stored procedures,
triggers, and user-defined functions)
Development: focused on data design activities including creating
and managing special use databases, such as ‘sandbox’ or exploration areas.
These 2 roles are usually combined under 1 position
Application DBA
Focused on a specific database for certain application/s so, they can provide better service to application developers.
Responsible for one or more databases in all environments, all concerned to the specific application.
Network Storage Administrators
Concerned with the hardware and software supporting data storage arrays
Database Administrators Positioning
Archiving
Process of moving data off immediately accessible storage media and onto media with lower retrieval performance
Capacity and Growth Projections
Determining the capacity of the database means deciding on the finite amount of storage that would be utilized for the business.
Growth Projections pertain to how quick the storage must increase to meet the demands of the business.
Change Data Capture (CDC)
Process of detecting that data has changed and ensuring that information relevant to the change is stored appropriately
Purging
Process of completely removing data from storage media such that it cannot be recovered
Replication
Storing the same data on multiple storage devices to make data
highly-available
Resiliency and Recovery
Resiliency in databases is the measurement of how tolerant a system is to error conditions.
Recovery is the process of continuing the ongoing function that has crashed.
Increasing the resilience of data processing systems means:
trap and re-route data causing errors,
detect and ignore data causing errors,
implement flags in processing for completed steps
Retention
Refers to how long data is kept available. Data retention planning should be part of the physical database design.
○ Retention requirements also affect capacity planning.
Sharding
Process where small chunks of the database are isolated and can be updated independently of other shards, so replication is merely a file copy
Data Storage and Operations Activities
1. Database Technology Support
selecting and maintaining the software that stores and manages the data.
2. Database Operations Support
specific to the data and processes that the software manages.
Database Technology Support
Understand Database Technology Characteristics
Understanding how technology works, and how it can provide value
DBAs and Database Architects combine their knowledge of available tools with the business requirements in order to suggest the best possible applications of technology to meet organizational needs.
Data professionals must first understand the characteristics of a candidate database technology before determining which to recommend as a solution.
Evaluate Database Technology
Manage and Monitor Database Technology
DBAs should have working knowledge of application development skills, such as data modeling, use-case analysis, and application data access.
The DBA will be responsible for ensuring databases have regular backups and for performing recovery tests.
When a business requires new technology, the DBAs will work with business users and application developers to ensure the most effective use of the technology

Database Operations Support
Understand Requirements
Define Storage Requirements
Identify Usage Patterns
Define Access Requirements
Plan for Business Continuity
In the event of disaster or adverse event, DBAs must make sure a recovery plan exists for all databases and database servers.
Each database should be evaluated for criticality so that its restoration can be prioritized
Make Backups
Recover Data
Develop Database Instances
a. Manage the Physical Storage Environment
b. Manage Database Access Controls
c. Create Storage Containers
d. Implement Physical Data Models
e. Load Data
f. Manage Data Replication
Manage Database Performance
a. Set Database Performance Service Levels
b. Manage Database Availability
c. Manage Database Execution
d. Maintain Database Performance Service Levels
e. Maintain Alternate Environments
Manage Test Data Sets
Test data is data that has been specifically identified to test a system.
It can be generated from production data that was filtered or aggregated to create multiple sample data sets, depending on the need, but with masked identifiers.
Test data may be produced by the tester, by a program or function that aids the tester, or by a copy of production data that has been selected and screened for the purpose
Manage Data Migration
Data migration is the process of transferring data between storage types, formats, or computer systems, with as little change as possible.
Data migration occurs for a variety of reasons, including server or storage equipment replacements or upgrades, website consolidation, server maintenance, or data center relocation
Automated and manual data remediation is commonly performed in migration to improve the quality of data, eliminate redundant or obsolete information, and match the requirements of the new system