Ch10: Text Mining
1/18
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
19 Terms
What is text mining?
A: The process of discovering/deriving/extracting high-quality information or unknown patterns from large amounts of unstructured textual data.
Why is text mining important?
A: Because around 80% of data is unstructured text, and traditional data mining techniques cannot process it directly.
Give three example applications of text mining.
A:
Spam filtering
Customer care service
Document summarization
What are the main tasks in text mining?
A:
Text Categorization (supervised)
Text Clustering (unsupervised)
Sentiment Analysis (supervised)
Document Summarization (supervised/unsupervised)
Named Entity Recognition (supervised)
Why can't we represent text as raw strings or list of sentences for mining?
Strings have no semantic meaning for the machine
→ grammar/order is ignored in naive representations.
List of sentences are just like another document
→ recursive problem
What is the Bag of Words (BoW) model?
A: A common document representation where a document is treated as a set of words, ignoring grammar and word order.
What is tokenization?
A: The process of breaking text into smaller units (tokens), such as words or sentences.
What are the main assumptions and limitations of Bag of Words?
A:
Assumes word independence
Pro: Simple & preserves all info of the text
Con: Loses grammar and sequence & Cannot detect synonyms or semantic similarity
What is Zipf’s Law in text mining?
A: A small number of words occur very frequently, while most words appear rarely — creating a long tail in word frequency.
What are the common pre-processing steps in text mining?
A:
Tokenization
Normalization (e.g., lowercase, remove punctuation)
Stop-word removal
Stemming (reduce words to root form)
What is Term Frequency (TF)?
A: The number of times a term appears in a document — indicates how important the word is in that document.
Why is raw Term Frequency sometimes misleading?
A: It doesn't account for document length or the diminishing importance of repeated terms.
What is Inverse Document Frequency (IDF)?
A measure of how rare a term is across documents — rare terms get higher weights.
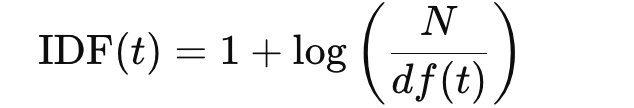
What is TF-IDF?
A: A score that combines Term Frequency and Inverse Document Frequency to balance importance within a document and across the corpus.
TF-IDF(t,d) = TF(t,d)×IDF(t)
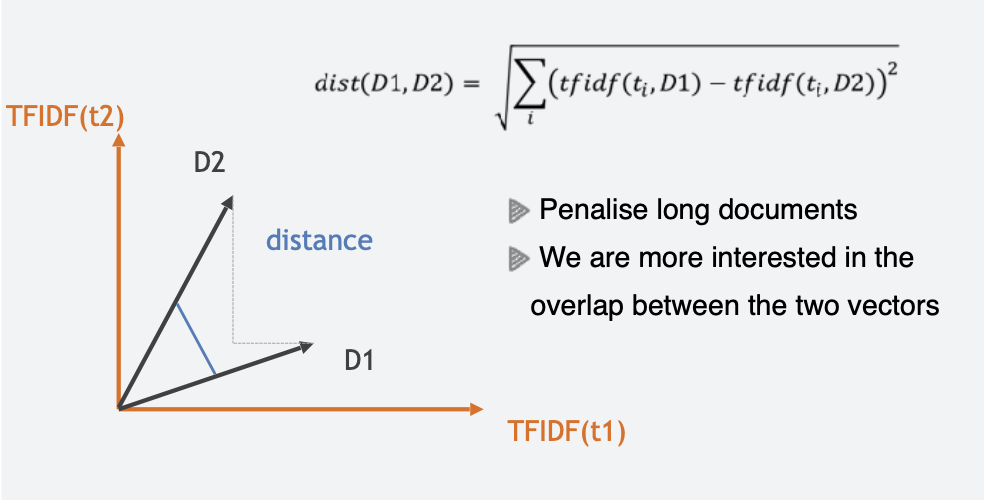
How are documents compared after vectorization?
A: By computing similarity or distance between their vector representations.
Euclidian distance is a common measure.
What is cosine similarity?
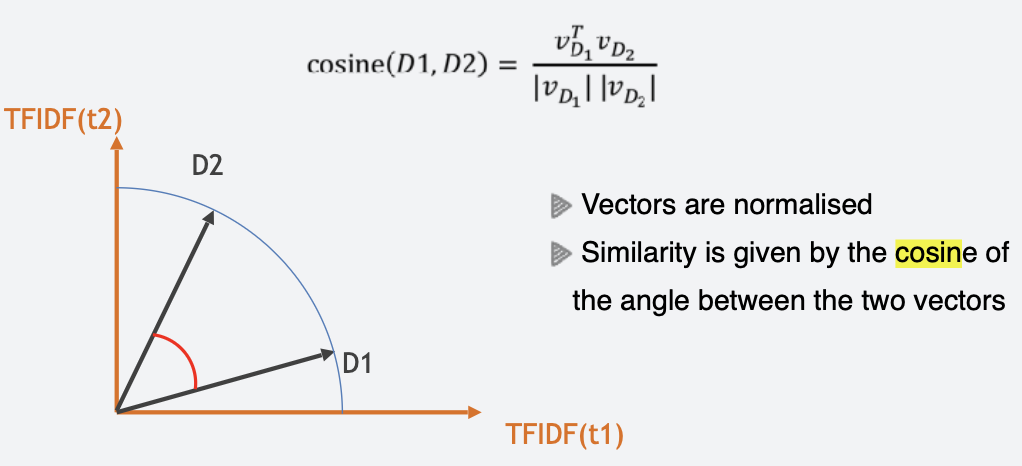
A: A measure of similarity between two vectors based on the cosine of the angle between them - ranges from 0 (no overlap) to 1 (identical direction).
Why is cosine similarity preferred over Euclidean distance for comparing documents?
A: Because it accounts for direction (overlap) rather than just length, making it better for comparing documents of different sizes.
How can TF-IDF and similarity be used in document classification?
A:
Preprocess documents
Compute TF-IDF
Measure similarity between documents
Assign the new document to the most similar category
What are some advanced models used in text classification?
Probabilistic models (e.g., Naive Bayes)
Decision trees
Support Vector Machines
k-Nearest Neighbors
Neural networks