Chapter 1. Proximity Service
1/22
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
23 Terms
Functional requirements
Return all nearby business
Business owner can add, update, delete info
User can read business info
Non functional requirements
Low latency
Data privacy for user location
High availability and scalability for peak hours
What is the read write pattern for this system and what’s the solution?
It is read heavy, use leader follower pattern.
What are 2 real life geospacial database?
Postgres with GIS extension
Redis geohash
How do we use geospacial index?
Convert location to index
Get index of nearby area
Search for business belong to the area index
What are 3 types of geospatial index?
Geohash
Quadtree
Google S2
How does geohash work?
Uses base32 representation
6 chars is around 1 square mile and 10 chars is 1 square meter
You can query business using LIKE ‘9q8zn%’
What are some issues and solutions with geohash?
Business close enough but not match prefix
Not enough business with current prefix
Solution: expand search range to get 8 neighbor cells
How to build quadtree?
Given list of business with coordinates
Create a parent node representing the coordinates it covers
If has more than 100 business, subdivide coordinates into 4 areas, making them the child nodes
Quadtree vs Geohash
Quadtree is a tree structure, geohash is stored as table (though it’s index can be trie)
For quadtree, the leaf node siblings have 100+ business, but geohash sublings might not. (Dynamic grid size)
Easier to update geohash index than a tree
How do we store quadtree?
We can store it in memory, because given a billion business, there would be only 1M leaf nodes if each node has 1000 business
Time complexity of building quadtree
For each business, it takes logn time to send it to leaf node, so it’s O(nlogn)
For 200M business it would take a few minutes
How to find nearby business with quadtree
Given coordinate, find the node for it
Traverse up until gathered enough business
How does quadtree handle updates?
Real time: insert business to the tree
Batch job: re-build tree weekly
Operational considerations of quadtree
Keep multiple replica for availability and scalability
Blue green or canary deployment
What is google S2
It maps a location to 1D index based on hilbert curve
1 points that have similar value are close in 2D space
Advantages of google S2
Great with geofencing because it can cover arbitrary areas
More flexible cell size and precision
What do geospacial index have in common?
Represent 2D space with 1D index
A range in 1D index covers an area in 2D space
Nearby locations have similar 1D index value
Which one should I pick during interview?
Geohash
What to cache?
List of business IDs in the grid
Business metadata
How to cache business ID list in grids?
Select 3 geohash precision
8 bytes x 200 million x 3 precisions = ~5 GB
How to have international support?
Deploy servers in different regions
DNS geo based routing
Add country specific cache that can scale independnetly
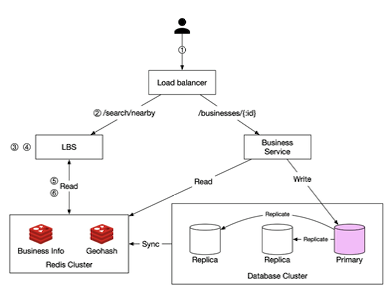
Component diagram
Location service: get nearby
Business service: get business info
Cache: business info + geohash
DB: leader follower setup