CS 122A - Database Design
1/77
Earn XP
Description and Tags
midterm one practice flashcards
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
78 Terms
Databases
Databases represent the “product” of a larger area called “Data management”. A database is typically a collection of large sets of data which contain relationships between the data stored.
DBMS
A database management system that provides standards for inputting and retrieving data, as well as the organization. It has a standard method of querying and can often manage multiple databases.
Enables access retrieval, and use of data with relationships. Optimized for better performance. Data protection and crash recovery. (In comparison to file systems)
File systems
Store data as separate entities with no relationship between them. Files are stored on disk. As size increase, access time increases. Data integrity issues. (In comparison to DBMS)
Why DBMS?
Data independence (application is protected from complexity of the data)
Efficient data access
Integrity and security
Uniform data administration (better organization, fine-tuning…)
Concurrent access and recovery
Reduced development time
Data model
A collection of high-level data description constructs.
semantic data model
Abstract, high-level model initially describing the information to store and is the starting point for design.
Relational data model
Schema to describe the data in attributes, type, size.
Most widely used data model.
Relation
A table with rows of data and named columns
Schema
Description of the tables and their columns which also contains the name of the table, name of each column, and the type of field.
Ex:
Student (student ID: string, First name: string, Last name: string)
Provider (provider ID: string, Provider name: string)
hasProvider (student ID: string, provider ID: string, Type of plan: string, Start date: date)
DBMS Abstraction
External (view based access) → Conceptual (describes how data is organized) → Physical (how the data is stored through files and indexes)
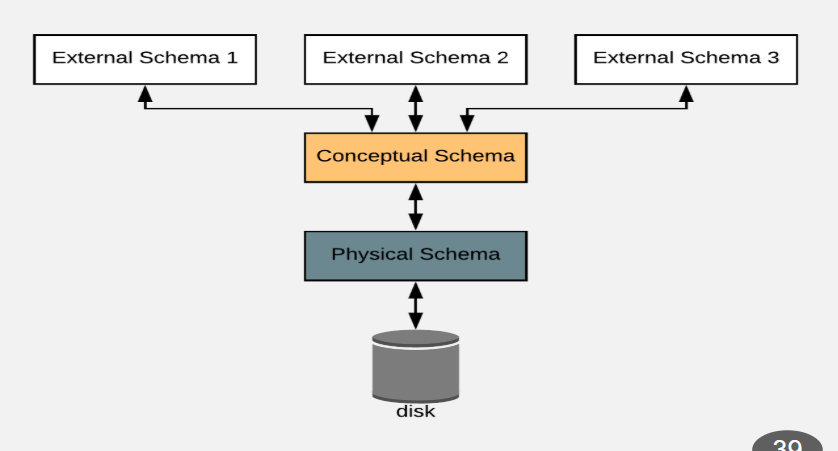
Data independence
Logical data independence → protection from the changes in the logical structure of data
Physical data independence → protection from the changes in the physical structure of data.
Why is this important? It allows changes to data without impact on application.
DML
Data manipulation language encompasses queries. It defines creation, modification, and querying of the data.
Concurrency & Recovery
Isolation, independent, arbitrary.
Write ahead log → all changes are written to a log prior to DB modification.
Transaction
A single execution of a user program in a DBMS. Enables concurrent accesses to data, giving the illusion of isolation and locking. Protects against system crashes using the log.
DBMS Components
Query Parser → parse and analyze SQL query. Performs validity check.
Query optimizer → rewrites the query logically based on how the data is stored.
Plan executor + Relational Operators → actual run of the query process. Query plan is represented as a tree of relational operators.
Files of records → API to access records which are sets of typed fields. Uses a heap.
Access methods → Index structure using a B+ Tree.
Buffer Manager - memory management in which all disk page access go through the buffer pool. Caches pages from files and indices.
Disk space manager → allocates, deallocates, and read and write pages to disk. Manages the I/O.
Concurrency Control → Determines the transaction execution using ACID (lock = consistency[valid data] + isolation[transactions aren’t interleaved], log = atomicity[single operation] and durability[record of changes])
Recovery Manager → maintains logs and restores the system after a crash.
System catalog → maintains the information being held. e.g: tables, data statistics, indexes, views, security profiles.
Requirements Analysis
What are the entities and relationships in the enterprise?
What information about the entities and relationships needs to be stored in the DB?
What are the integrity constraints (preserve the validity and consistency of your data) or business rules?
Database Design
Conceptual Database Design → high level description of the data to be stored in the DB along with the constraints on the data (ER Model)
Logical Database Design → translation of the Conceptual Database Design into the chosen DBMS (relational DB)
Entity
A distinguishable real-world object which are described by a set of attributes.
E.g: Car → make, model, year, color
Entity set
A collection of similar entities. All entities in a set have the same set of attributes with an associated domain type (data type). Each entity set has a key, the minimal set of attributes which uniquely identify an entity.
single attribute = “atomic” key
set of attributes = “composite” or “candidate” key. In which case, one must be designated as the “primary” key.
Name of entity set
Represented in a rectangle
Attribute of entity set
oval, each with a unique name.
Key attribute of entity set
Underline the attribute name
Composite atttributes
Attribute containing sub attributes
Multi-valued attributes vs. single valued
An attribute that can have more than one value for an entity. Represented by a double lined oval. Tiny circle indicates optional participation and can only be used on multi-valued attributes.
Derived attributes
Calculated value based on other data. Represented by a dotted oval.
ISA hierarchies
Inherited attributes → “IS A”. Uses a triangle. Design with a top-down or bottom-up style.
Every C entity is also considered a D entity.
Ex: C ISA D
Covering constraint
Does every entity be one of the subclasses?
If yes, then every entity must be one of the subclasses.
If no, then can have entities of class and subclass.
E.g: User IS A Student, TA, Professor. If the user has to be one of those, then it is covering.
Overlapping constraint
Can the subclasses contain the same entities?
If yes, then the subclasses overlap each other.
If no, then it is implicitly disallowed without without specification.
Ex: A student can also be a TA.
Relationship (a verb)
An association between two or more entities. Represented by a diamond.
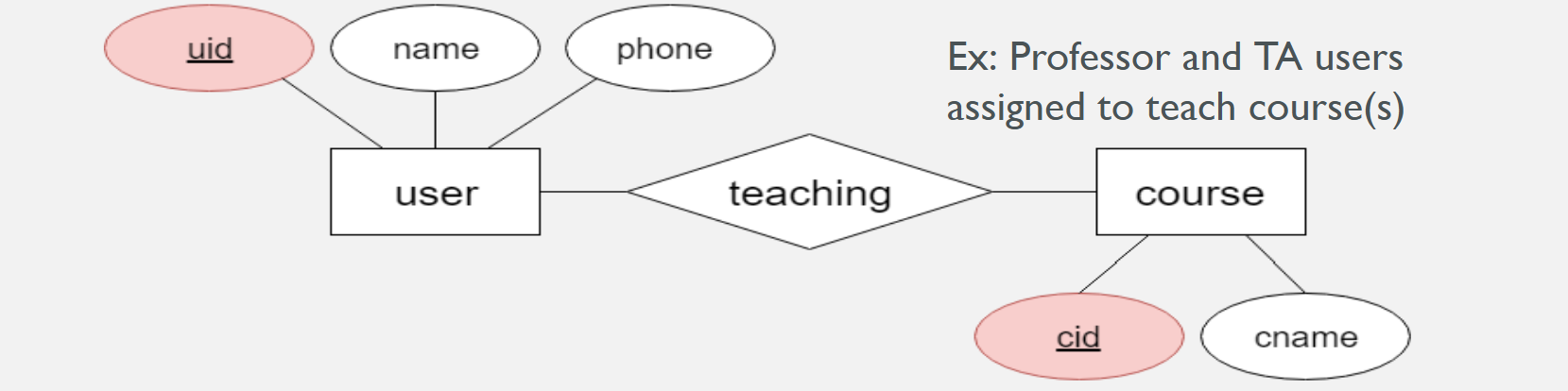
Relationship set
Collection of similar relationships. Can have their own associated descriptive attributes.
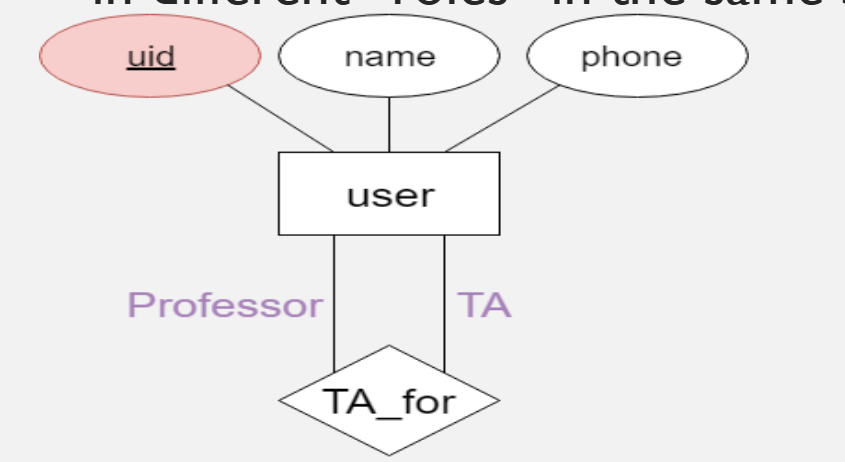
Entity roles in a relationship set
An entity set can participate in different relationship sets - or in different “roles” in the same set. Role indicators are used to identify the specific entities.
E.g: professor_uid, TA_uid
Cardinality Constraints
Limit the possible combinations of entities which participate in a relationship set
E.g: 1:1, 1:N, N:N, N:M
A.k.a: one to one, many to 1, many to many
Diagram stuff: A line indicates a relationship. The value on the line indicates the cardinality. A single line indicates partial participation meaning that not all entities in the entity set are involved in the relationship. A double line indicates a participation constraint, totality, or subjectivity. All entities in the entity set must participate in at least one relationship in the relationship set.
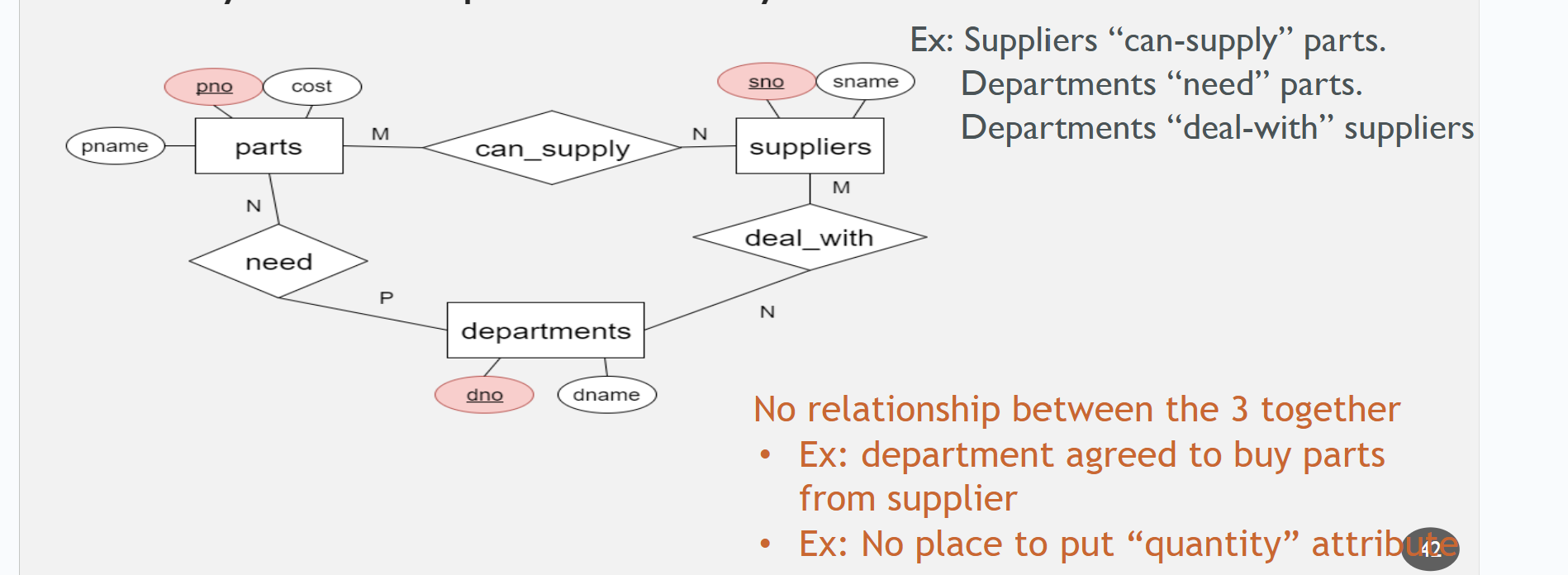
Ternary Relationships
Relationship between 3 entity sets. The relationship key <= entity keys.
Weak entites
can not exist without another (owner) entity. Can only be uniquely identified along with the primary key of the owner entity. Must have a total participation with a 1:N relationship to the owner (one owner, many weak entities). Dependent identifier is unique only within the context of the owner, the full key is the set (owner key, identifier key).
Aggregation
Ability to create a relationship with another relationship set. Treats a relationship set as an entity set. Represented as by a dotted-rectangle. Why not ternary? → each relationship has its own attributes
Design choices
Should a given concept be modelled as an entity or as an attribute?
Should a given concept be modelled as an entity or as a relationship?
Characterizing relationships: binary or ternary? aggregation?
Constraints on model
Many data semantics can be captured, but not all. E.g: a course can have at most 5 homework assignments. E.g: the enrollment of the course must be less than the location capacity.
Entity vs Attribute?
Will the data item have multiple occurrences per entity?
If yes, use a multi-valued attribute or an entity.
Does the data item have a structure of its own & do you need access to these parts?
If yes, use a composite attribute or an entity.
Is the data item a refer-able entity in the design, e.g: logically separate?
If yes, use entity.
entity vs. relationship
Keep total # of entities and relationships to a minimum to reduce the relational model. Eliminate redundancy - avoid storing the same information in multiple places.
binary vs. ternary
Depends on how specific you’d like the database to be. E.g: there are many discussions and TAs per course. Maybe if the TA leads a specific discussion, then a binary may be better.
However, binary is not always better. E.g: supplier parts. There may not be a way to track quantity in the example given.
Relational Database in depth
Contains a set of relations. A relation, aka a table, consists of two parts. The table, and the schema.
A row is called a tuple and should be a unique entry. columns are fields and attributes. Cardinality of a relational instance = number of tuples/rows. Degree (or arity) of a relational instance = number of columns.
SQL Query Language
SELECT, FROM, WHERE….
Each field/attribute specifies a domain/type. DBMS will enforce it.
Creating a table
CREATE TABLE User (
uid CHAR(10),
name CHAR(20),
phone INTEGER,
gpa REAL ← double but with single point decimals for closer approximations
);
Dropping table
DROP TABLE User;
All tuples are deleted. schema is deleted.
Altering table
ALTER TABLE User
ADD enter DATE;
User schema is altered to include a new field/column. Existing tuples will obtain column with null value assigned.
Insert single tuple
optional to specify column names. Advised to specify to ensure proper placement of data.
INSERT INTO User
(uid, name, phone, gpa, enter)
VALUES
(…,…,….,…,…);
Delete tuples
DELETE FROM User S
WHERE S.gpa <= ‘3.0’
SQL Integrity Constraints
Conditions that must be true for any instance of the database:
Restricts the data that can be stored in the database
Can be specified by the requirements documentation
Specified when the schema is defined
Checked when relations are modified
A legal instance of the relation is one that satisfices all ICs
A DBMS checks for these and should not allow illegal instances
Primary Key Constraints
Candidate key - a set of attributes for which no two distinct tuples can have the same values in all key fields and no subset of the selected fields is a unique identifier for the tuple → minimal set of attributes.
one of the keys chosen is to be the primary key. The others are candidate keys.
A super key is a set of fields which contain a key.
in principle, any key can be used to refer to a tuple. use of the primary key is what the DBMS expects and optimizes for. But be careful, since an IC could accidently prevent data from being stored.
Possible to have many candidate keys along w/ a primary key. Specified using UNIQUE - means the items specified in UNIQUE are also a key. E.g: UNIQUE(cid, grade)
SQL - Foreign Key
Sets of fields in one relation is used to “refer” to a tuple in another relation. Must refer to the primary key of the other relation. Field name can be different than the key name. Acts as a pointer.
E.g: FOREIGN KEY (user_id) REFERENCES User(uid)
SQL - Referential integrity
Each foreign key entry MUST exist in the associated relation.
e.g: reject an insert of a tuple if the foreign key doesn’t exist
If a User tuple is deleted, what do you do?
Can remove all associated foreign key reference tuples.
Disallow deletion of the User because it is referred to by other data.
Set the user_id of Enrolled tuples to a “default uid” value.
What if a primary key of a tuple in User is updated?
Same options as if deleted
4 Actions:
NO ACTION → delete or update is rejected
CASCADE → delete all tuples which refer to the tuple which is being deleted
SET NULL or SET DEFAULT → sets the foreign key value of the referring tuple accordingly.
Context: ON DELETE ___ or ON UPDATE ____
More SQL ICs
ICs are based on the specification of the system
Might be in the ER schema
Can perform a check on a database instance to see if ICs are violated
However, cannot infer by looking at an instance that an IC is true.
An IC is a statement about ALL POSSIBLE instances. (this can change if someone inserts another tuple that violates the IC essentially. The law hasn’t been broken yet. )
Key & foreign keys ICs are the most common type
Others are also supported.
Delta table approach
create a relation for each entity
every user created in user relation table
relation for each subclass with extra associated attributes
delete entries in subclass relation when tuple in base is removed.
ISA Hierarchies for Logical DB design
Union of tables → create a relation for each entity, duplicate the base attributes in each of the subclass relations
Mashup table → everything in one table.
Advanced Attributes for SQL Query Language
Multi-valued attributes
Create a table for this
Composite attributes
Create attributes for each sub-attribute only
Derived
requires querying the data
Aggregation - Logical db design
No distinction between entity tables and relationship tables in the relationship model.
Treat a relation table as an entity to another relationship.
Requires utilization the primary key of the created relation as a component of the primary key for the relationship.
assignes (cid, title, posted_on)
monitors (cid, title, uid, until)
Schema refinement
Identifying and eliminating redudancy using ICs. There are three main types of constraints: functional dependencies, multivalued dependencies, join dependencies
Redundancy problem
Redundant storage
Repeated storage of the same data
Update anomalies
Reduces the data integrity and complicates maintenance with the need to update many places
Insertion Anomalies
Complicates storage of data by requiring unnecessary data storage
Deletion Anomalies
Loss of data when unrelated or other information is removed
Functional dependencies
can help to identify problem schemas and suggest improvements
Decomposition reason
replacement of a relation with a collection of ‘smaller’ regions
each smaller relation includes a subset of the attributes, together they cover them all.
needs to be used with reason and without negative impact. each functional dependency is a statement about all allowable relations.
Reflexivity
If Y is a subset of X, then X → Y. Eg. Given all attributes {A,B,C,D}, Y = AB and X = ABD, then ABD → AB
Augmentation
If X→Y, then XZ → YZ. Eg. Given all attributes {A,B,C,D}, if AB → C, then ABD → CD
Transitivity
If X→Y and Y→Z, then X→Z.
Eg. Given all attributes {A,B,C,D}, if AB → C and C → D then AB → D
Union
If X →Y and X → Z, then X → YZ
Decomposition
If X →YZ, then X →Y and X → Z
Self-determination
X → X based on Reflexivity (Y ⊆ X, then X →Y)
Input
An instance of a relation. Schema of input relation are fixed
output
An instance of a relation. Schema for the result is also fixed.
Sigma (selection)
selects of subset of rows from relation
Projection (pi)
Extracts columns from a relation
Cross product
Combines fields of 2 relations into a single relation (cartesian product)
Self-difference
returns only the tuples in the first relation, but not in the second relation
Union
all tuples in the first and second relation or both
intersection
only tuples which appear in both relations
join
cross-product of 2 relations on a condition
Division
identifying which are related to all members of an attribute set
Renaming (rho)
Assign new field names to resultant relations