Intro to Big Data & Data-Driven Marketing (MKT46090 – Lecture 1)
1/112
Earn XP
Description and Tags
Vocabulary flashcards summarizing key concepts, processes, and pitfalls related to Big Data, data mining, CRISP-DM, AI/ML, and the evolution of data-driven marketing organizations.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
113 Terms
Big Data
Datasets so large and complex they require specialized storage, sourcing, and analysis methods, typically defined by high volume, variety, and velocity (plus veracity).
Volume (Big Data ‘V’)
The sheer size of data that makes manual inspection impossible and demands scalable storage and processing solutions.
Variety (Big Data ‘V’)
Presence of multiple data types—often unstructured or semi-structured—such as text, images, audio, and video.
Velocity (Big Data ‘V’)
The speed at which data is generated or updated, making it hard to capture a fixed ‘snapshot.’
Veracity (Big Data ‘V’)
The authenticity, accuracy, and reliability of data and the uncertainty surrounding its quality or availability.
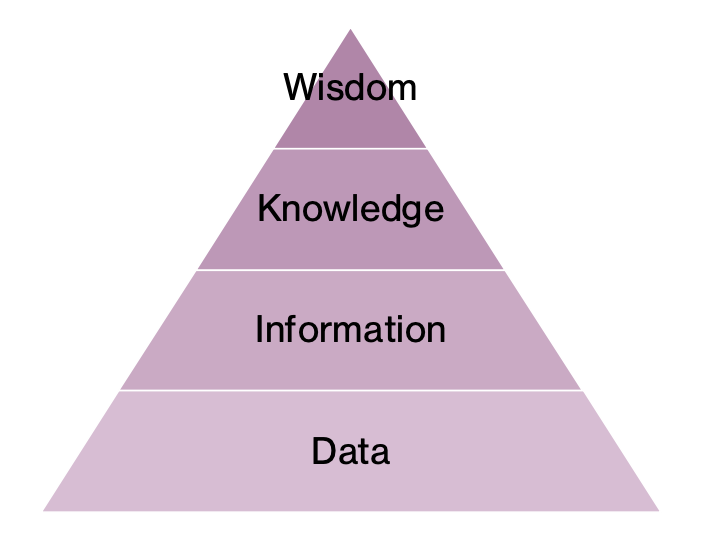
Hierarchy of data translation
Wisdom: Ability to use knowledge to make data-informed decisions or judgements
Knowledge: Process of blending information with business or market knowledge, context, expertise, and intuition
Information: Capacity to transform or summarize data into something useful and relevant, often using AI or Machine Learning (known as data mining)
Data: Foundational ability to collect and manage data; ensure veracity
Data Mining
Also called knowledge discovery from databases; the structured process of exploring and modeling data
With the goal of uncovering systematic patterns and insights tied to a business problem.
Focus:
Extracting information from data
Implementing data products (knowledge)
Defines a specific process
CRISP-DM
Cross Industry Standard Process for Data Mining; a six-step framework: Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, and Deployment.
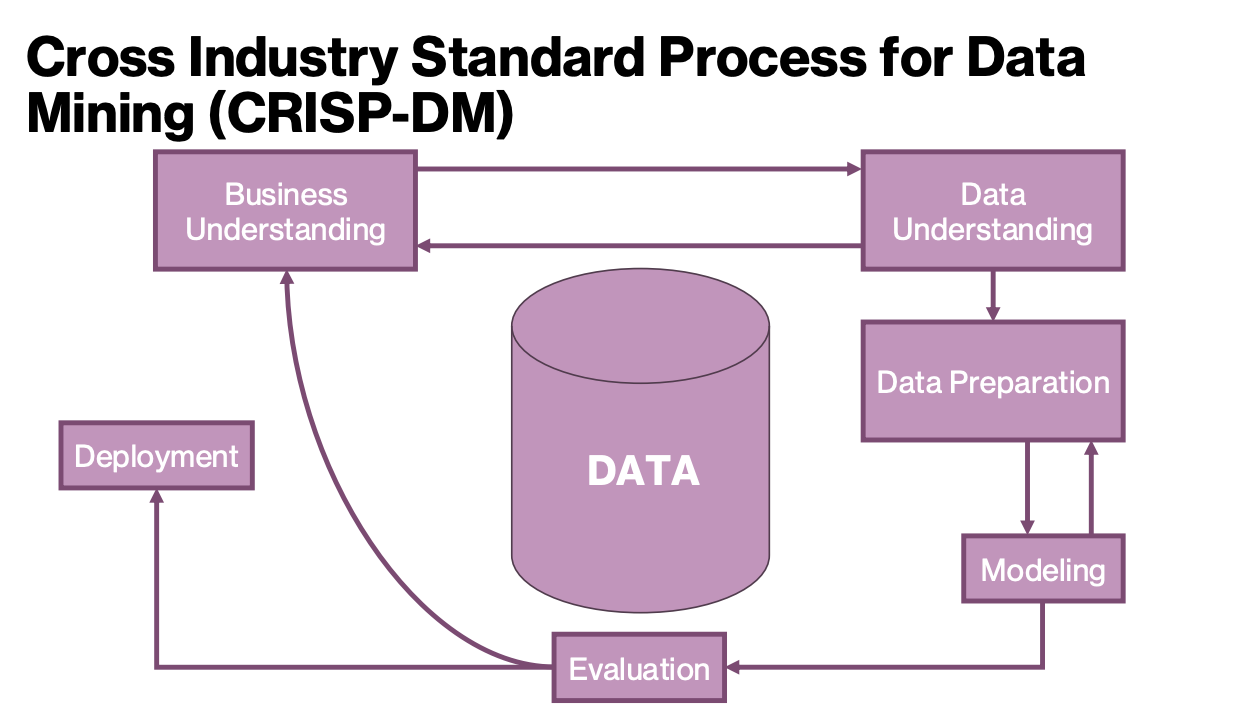
Business Understanding (CRISP-DM) - Determine Marketing Objects
What is the marketing action or decision trying to achieve?
Distill complex task description into objective which is:
Specific: Well-defined and discrete description of what will be accomplished
Measurable: A description of how success will be quantified
Achievable: Ensure that the objective is realistic given other considerations
Relevant: Align the objective with overarching business goals
Time-bound: Set a deadline for when the goal will be accomplished
Business Understanding (CRISP-DM) - Assess the Situation
What is currently being done to achieve the marketing goals?
Consider the resources available for the project:
Personnel: Determine whether the appropriate expertise is available for the project
Data: Assess the data sources available and their accessibility
Risks: Identify the most likely risks or threats to the success of the project
Determine the data mining goals
Decompose the broader objective into specific analytics tasks
What task or tasks will contribute to the broader goal?
Data Understanding (CRISP-DM) - Explore existing data and plan for acquiring new data
Assess existing data
Take an inventory of existing data sources
Determine which sources are available and accessible
Document what information is contained in each data source
Identify sources of additional data
Data can be collected from online or offline sources
Data can be purchased from third-parties
Describe the data
Develop a codebook, dictionary, and/or data sheet
Explore the data
Conduct visual analysis of the data
Calculate typical values and distributions
Verify data quality
Check for data errors and inconsistencies
Identify and characterize missing values
Consider outliers or extreme values
Data Preparation (CRISP-DM) - Also Known as “Feature Engineering"“
Integrate Data Sets:
Merge data: Combine data sets with overlapping but largely different information
Append data: Combine data sets with the same information but different cases
Aggregate data: Compute higher-order summary values
Select Relevant Data
Subset data based on business objective
Sample data based on analytics requirements
Clean Data
Handle missing and duplicate cases
Verify Data Quality
Check for data errors and inconsistencies
Identify and characterize missing values
Consider outliers or extreme values
Construct New Data
Calculate or derive new variables as required
Reformat Data
Transform data for modeling as required
Modeling (CRISP-DM)
How do we transform data into information?
Modeling approach
Do we use statistical modeling, machine learning, or AI?
What’s the difference?
Modeling: Statistical Modeling (CRISP-DM)
Methods traditionally used in marketing
Emphasize causal and explanatory relationships
Requires knowledge of the relationships between variables, often based on theory
Modeling: Machine Learning (CRISP-DM)
Modeling Approach: Statistical Modeling
Methods traditionally used in marketing
Emphasizes casual and explanatory relationships
Requires knowledge of the relationships between variables; often based on theory
Modeling Approach: Machine Learning
Emphasizes operational effectiveness and prediction accuracy
Often at the expense of explanation
“Learns” from data without prior knowledge or assumptions
Modeling: ML is a Subset of AI (CRISP-DM)
Modeling Approach: AI
Broad class of technology with the objective of collecting data to solve problems or make decisions
Modeling: What is “Learning”? (CRISP-DM)
“Learning” in the context of ML and AI refers to
A computational system which can improve at a task based on experience
Improvement is not dependent on explicit instructions
Instead, improvement comes from the detection of patterns in data
Types of Learning
Supervised: A system learns which features (variables) are associated with an outcome (label) which is provided
Unsupervised: A system learns the patterns between features when no outcome is provided
Reinforcement: A system learns from decisions and feedback, when no historical data is provided

Modeling: Supervised Learning (CRISP-DM)
During training, the model sees:
a target picture
a label for the picture
During testing, or validation, the model sees:
a target picture, attempts to “guess” the label

Modeling: Unsupervised Learning (CRISP-DM)
A system learns the patterns between features when no outcome is provided
For example
Using customer characteristics
To create groups or segments of similar customers
Modeling: Reinforcement Learning (CRISP-DM)
A system learns from decisions and feedback, when no historical data is provided
The feedback serves as a “label” or indicator of success or failure
For example
training a system to play Super Mario Brothers
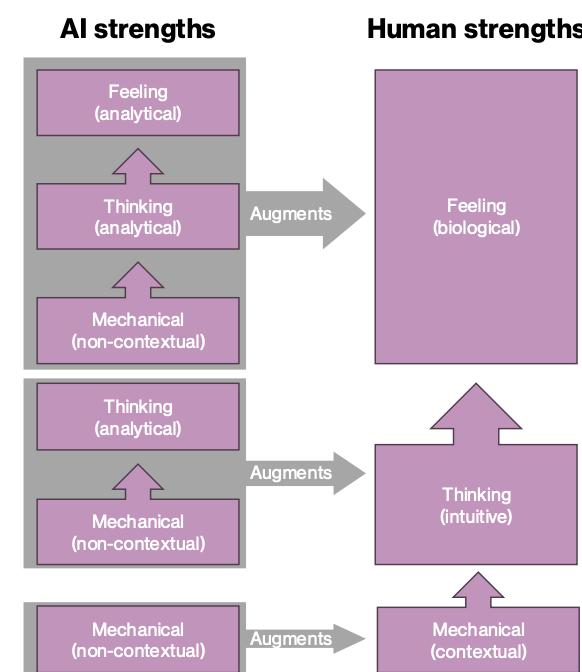
Mechanical Intelligence (Types of Intelligence)
Demonstrates minimal learning and adaptation
Excels at routine and repetitive tasks
Useful when standardized output is required
Thinking Intelligence (Types of Intelligence)
Informed by large amounts of data
Capable of processing and integrating complex data (big data)
Provides personalized output
Feeling Intelligence (Types of Intelligence)
Recognizes emotion and responds appropriately
May be able to simulate emotion in a manner recognizable to humans
Currently, understands emotion through analysis of data
Collaborative Intelligence
Thinking (analytical) Augments Feeling (biological)
Thinking (analytical) Augments Thinking (intuitive)
Mechanical (non-contextual) Augments Mechanical (contextual)
Evaluation (CRISP-DM)
Have we met the goals laid out in the first step of this project?
Compare model results to predetermined success criteria
determine whether the model has surpassed the threshold for success according to the primary metric
utilize supporting metrics to understand success or failure
Review the results in reference to each data mining goal
Review the results in reference to each business objective
Compile and communicate results
Deployment (CRISP-DM)
How will we create business value from the results of this project?
Implement the results of modeling
integrate model with ongoing product roadmaps
how does it fit with the greater MarTech or consumer product ecosystem?
Apply to or integrate with an existing marketing campaign/strategy
Stand-Alone ML (CRISP-DM) Deployment
Isolated, More complex
Ex. Fully automated customer service bot
Integrated ML (CRISP-DM) Deployment
Integrated, More complex
Product recommendations
Predictive sales-lead scoring
Stand-Alone Task Automation (CRISP-DM) Deployment
Isolated, Less complex
Email automation
Customer service triage
Integrated Task Automation (CRISP-DM) Deployment
Integrated, Less complex
Inbound call routing
CRM Marketing Automation
Deployment: Integration with Strategy
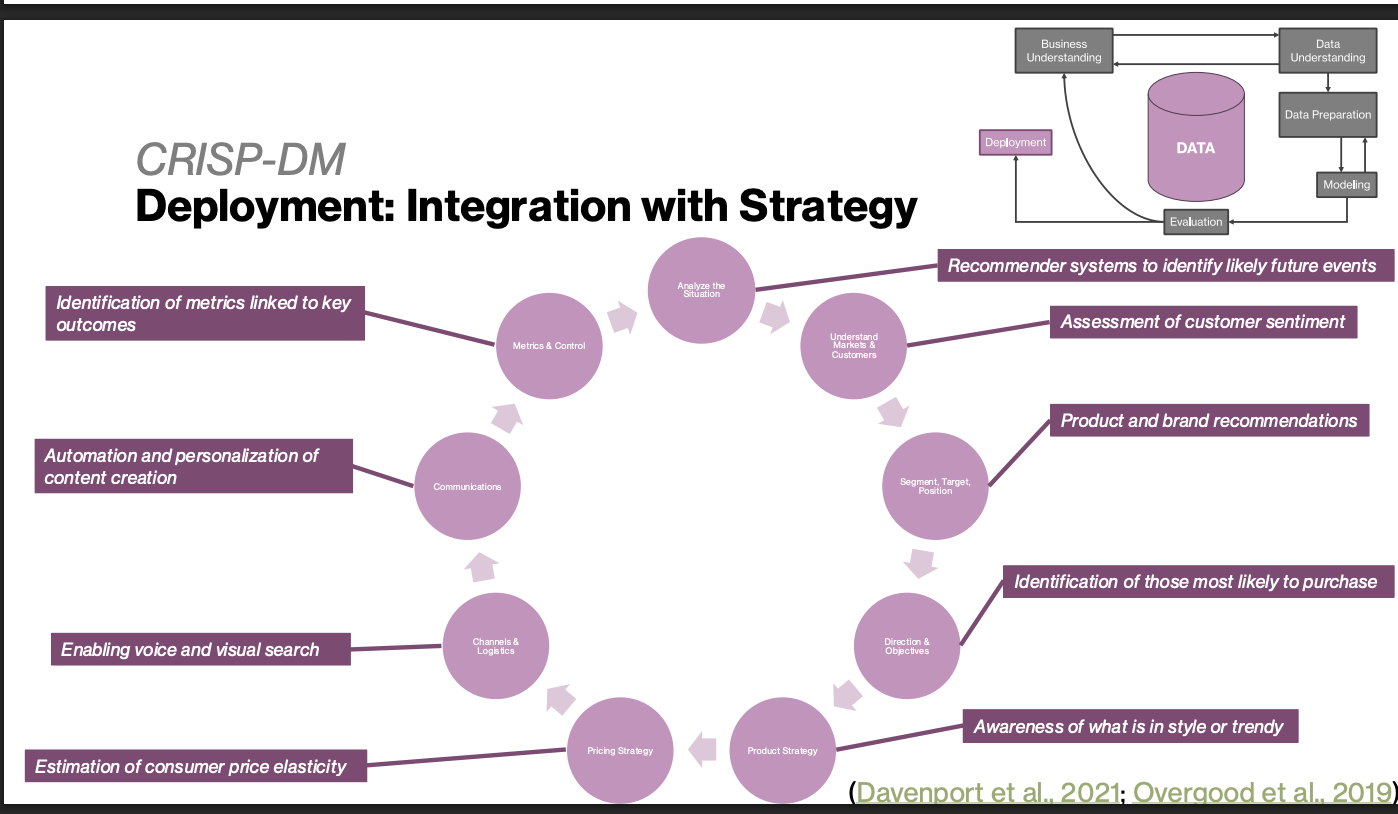
Feature Engineering
The creation or transformation of input variables during data preparation to improve model performance.
Statistical Modeling
Traditional analytical approach emphasizing causal, explanatory relationships grounded in theory.
Machine Learning (ML)
Subset of AI that focuses on predictive accuracy and operational effectiveness by learning patterns from data without explicit programming.
Artificial Intelligence (AI)
Broad class of technologies designed to collect data and make decisions; ML is one of its subsets.
Supervised Learning
ML approach in which models learn to map features to known outcome labels provided during training.
Unsupervised Learning
ML approach that discovers structure or patterns in data without any provided outcome labels.
Reinforcement Learning
Learning paradigm where an agent improves by taking actions and receiving feedback (rewards or penalties) without historical labeled data.
Hierarchy of Data Translation (DIKW)
Progression from Data ➔ Information ➔ Knowledge ➔ Wisdom, illustrating how raw data becomes actionable decision support.
Mechanical Intelligence
AI that displays minimal learning, excels at routine, repetitive tasks, and produces standardized outputs.
Collaborative Intelligence
Integration of AI strengths (mechanical, thinking, feeling) with human strengths to augment overall decision making.
Predictive Modeling
Using historical data (often via ML) to forecast future outcomes, such as click-through rate (CTR).
A/B Testing
Experimental method that compares a control group to a treatment group to evaluate the impact of a change.
Customer Lifetime Value (CLV) Estimation
Calculating the net value a customer is expected to generate over the duration of the relationship.
Segmentation
Dividing customers into homogeneous groups based on characteristics or behaviors to tailor marketing actions.
Personalization
Customizing content, offers, or experiences to individual users, frequently powered by ML and integrated data.
Data Warehouse
Centralized repository that stores and integrates structured data from multiple sources for analysis.
Data Quality
Degree to which data is accurate, complete, consistent, and reliable; poor quality impairs 77% of organizations.
Street Light Effect
Pitfall of focusing analysis on easily available data instead of the most relevant but harder-to-obtain information.
Sprouting Stage (Data-Driven Org)
Earliest phase in the evolution of a data-driven marketing organization, characterized by basic tool acquisition.
ROI Obsession (Pitfall)
Excessive focus on immediate return on investment that discourages experimentation and long-term innovation.
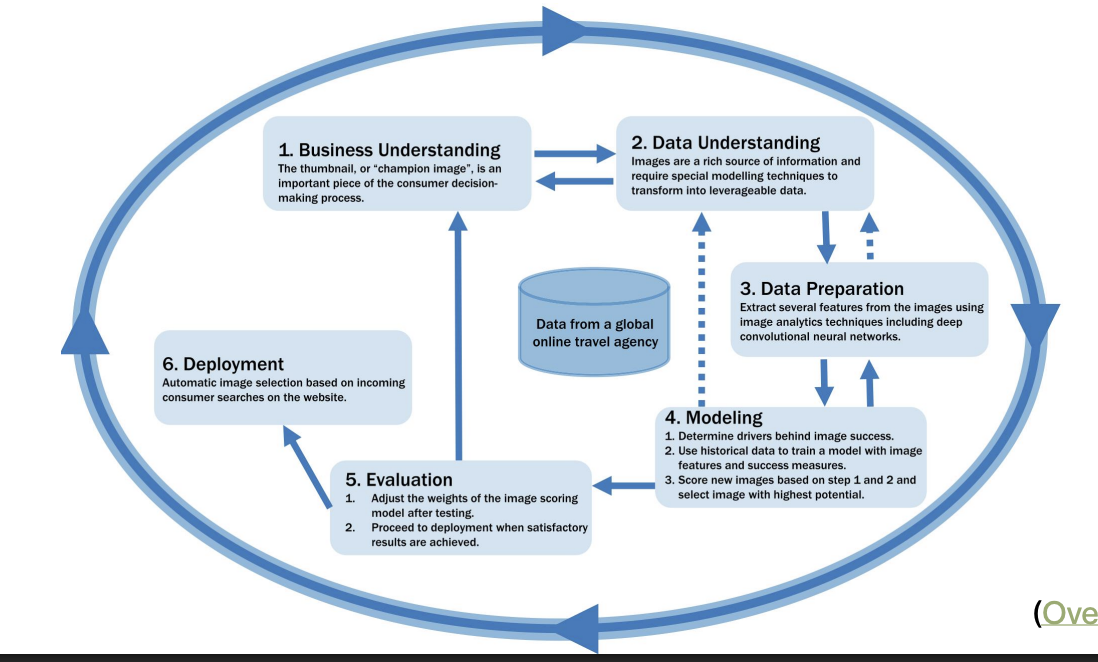
In Practice: Business Understanding (CRISP-DM)
Problem: An online travel agency posts images online promoting properties. These images are selected by marketing managers based on “expertise” and “gut feeling.”
The business wants to make image selection choices based on which will generate the highest CTR
How would you approach this problem?
Image represents FMOT
We must determine which aspects of an image encourage CTR
CTR related to images increases after selecting images based on the score we assign
The successful system is integrated into the travel agency website – The system depends on clickstream data, an image archive, and web publishing systems and is thus integrated – The system utilizes ML to make a prediction about customer behavior and is thus complex • Benefits: – Improves CTR performance for hotel clients – Saves time for marketing managers by automating some tasks – Helps us to better understand what aspects of an image are associated with CTR
What is a dataset? (Traditionally: Think Excel)
a set of observations
typically, the same information is recorded for each item
each item is an elementary unit
consumers
visitors
companies
cities
described as unit of observation
What is a dataset (Big data may include…)
a database of individual records
a collection of documents
rich media (e.g., photos, videos)
a set of data summaries (models of underlying data)
A (traditional) data set can be classified by
the number of pieces of information (variables) for each elementary unit
The kind of information recorded in each case (case means observation or item indicating unit or row of data)
Quantitative data consists of meaningful numbers
categorical data are categories which may be
ordered (ordinal)
or not (nominal)
Whether the information captures a single moment in time or extends across time
Time series data has information from one unit over many points in time
Panel data has information from many units over many points in time
Whether we control the data gathering process (primary data) or whether this process is controlled by others (secondary data)
Whether variables are observed (observational data) or manipulated (experimental data)
A (traditional) data set can be classified by (Quantitative or Categorical?)
Name (e.g., john, jane, stephen, sarah)
Type: Categorical
Sub-type: Nominal
CPM (Clicks per Thousand)
Quantitative
Continuous
Star Rating (e.g, 1,2,3,4, or 5)
Quantitative
Discrete
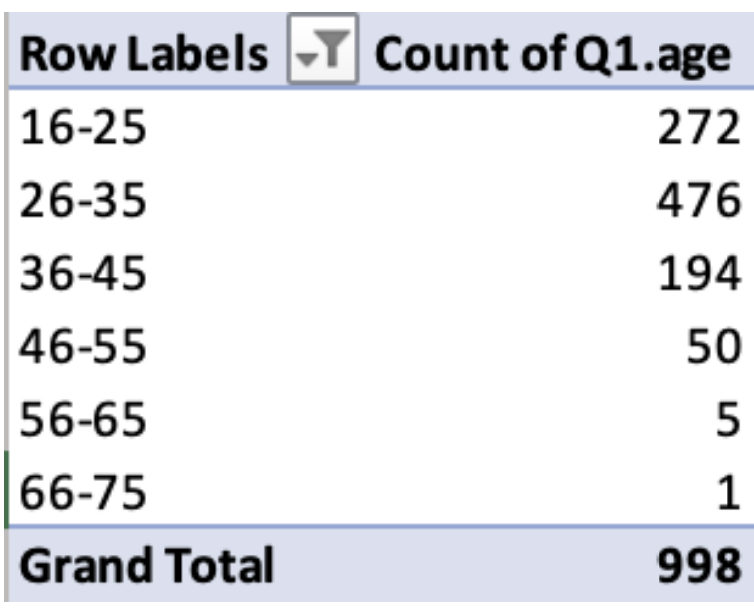
Age Group (e.g., 16-25, 26-35, 36-45)
Categorical
Ordinal
Satisfaction (e.g., not satisfied, satisfied, very satisfied)
Categorical
Ordinal
What kind of information? Quantitative
Meaningful numbers represent the measured or observed amount of some characteristic or quality
Price-per click, number of employees, clickthrough rate
Non-meaningful numbers are those used to code or keep track of some category
Discrete and continuous quantitative variables
Quantitative information is either
Discrete data can only assume values from a list of specfic numbers
Often this is a “count” variable
In Python, this is referred to as an integer (int)
Continuous data can assume any of the infinite values within a range
In Python, this is referred to as a floating-point number (float)
Are these variables discrete or continuous?
The price-per-click of a paid search ad
The number of sales in the last quarter
The conversion rate of our landing page
Total new leads in the last quarter
Continuous - price-per-click can take any value within a range and can be measured with precision, often involving fractional values
Discrete - number os sales is a countable quantity, which can only take integer values
Continuous - conversion rate is a ratio that can take any value between 0 and 1 and have fractional values
Discrete - number of new leads is a countable quantity that can only take integer values
What kind of information? (Categorical)
Identifies which of several nonnumerical categories each item falls into
in python this is often referred to as a character data type (string)
Records some quality of the data (hence, qualitative)
Categories can be summarized numerically
Counted
Calculated as a ratio or percentage
Qualities can be represented with numbers
Data Structures in Python
A data structure is a method for storing and organizing data
Data structures can be mutable (changeable) or immutable (unchangeable)
Data structures can be ordered (items have a fixed and indexed position) or unordered (no fixed position)
Types of data structures in python
List: ordered, mutable, allows duplicates
fruits = [“apple”, “orange”, “mango”]
Note, the type of brackets used defines the data structure
“fruit” is a a variable, an arbitrary name we can use to reference the data structure
Tuple: ordered, immutable, allows duplicates
colors = (“red”, “green”, “blue”)
Set: Unordered, mutable, no duplicates
input: unique_numbers = {1, 1, 2, 3, 3}
output: unique_numbers = {1, 2, 3}
Dictionary: unordered, mutable, stored in key-value pairs
student = {“name”: “Alice”, “age”: 22}
Special Data Structures in Python
Dataframe: A tabular format like an Excel spreadsheet, enabled by the Pandas Library
Common in data analysis applications
Array: a matrix of numbers, enabled by the NumPy library
Commonly used in ML applications
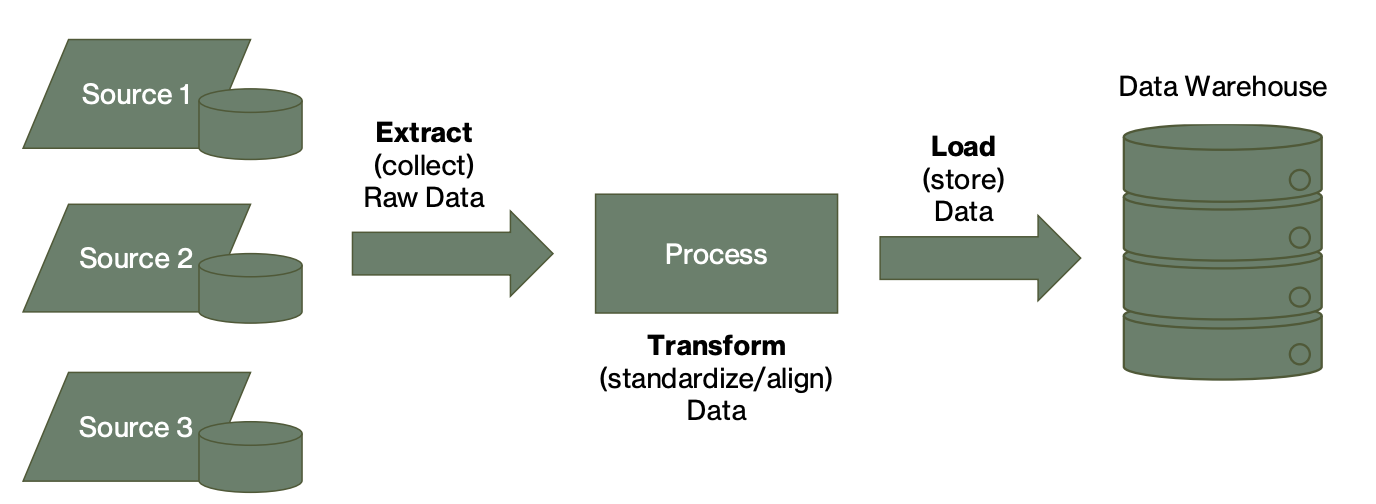
Extract-Transform-Load (ETL) Data Pipeline
Extract (collect) from sources —> process (transform by aligning data) Load (store data) —> data warehouse
ETL For Internal Data: Extract (Internal Sources of Raw Data)
Enterprise Resource Management (ERP)
Financial/Accounting
Order fulfillment
Production/manufacturing
Supply chain management
Inventory management
Procurement
“back office” management
Microsoft dynamics 365, Oracle ERP cloud, NetSuite, SAP S
OVERLAPS WITH CRM VIA OVERLAPPING FUNCTIONALITY AND OVERLAPPING DATA
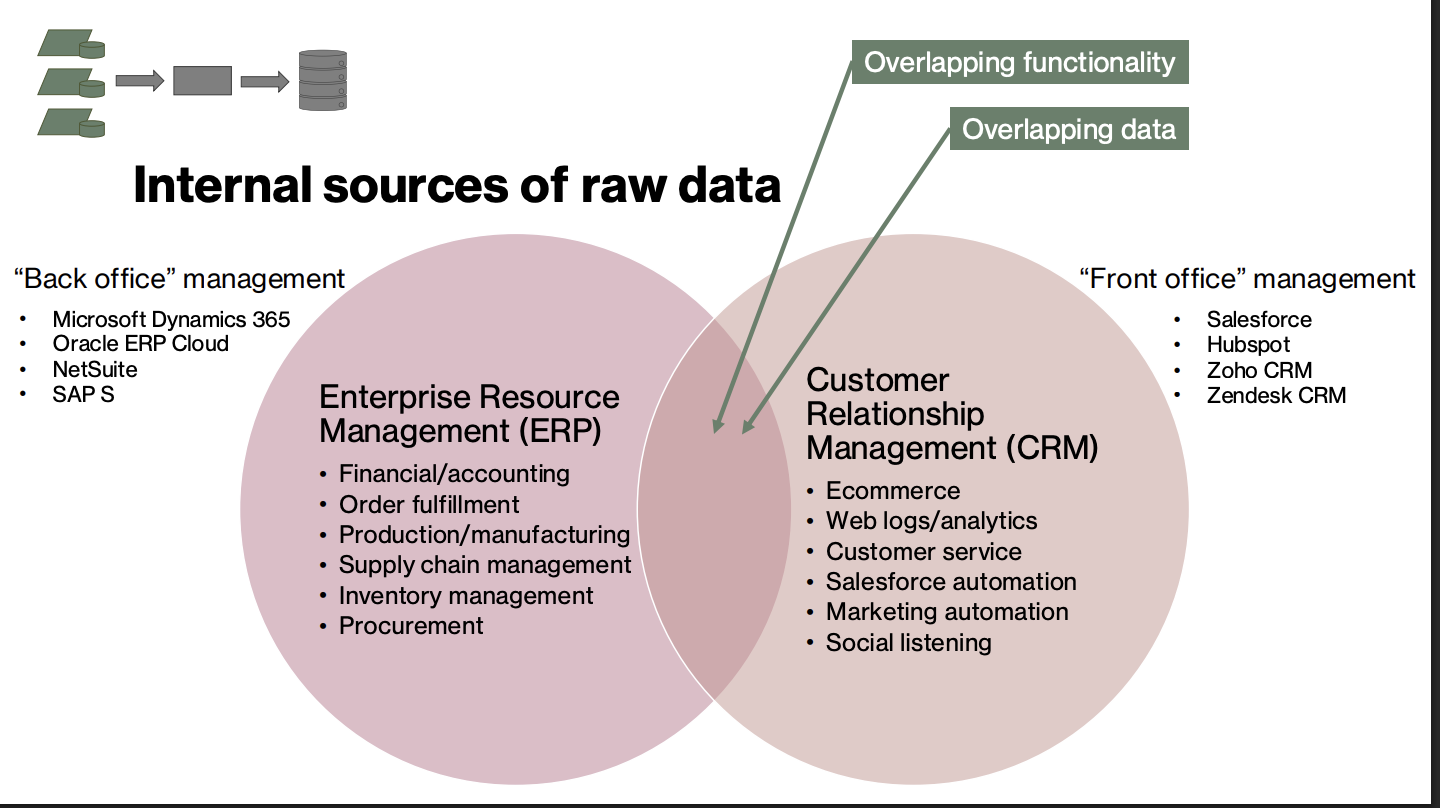
CRM For Internal Data: Extract (Internal Sources of Raw Data)
Customer Relationship Management (CRM)
Ecommerce
Web logs / analytics
Customer Service
Salesforce automation
marketing automation
Social listening
“Front Office” Management
Salesforce, Hubspot, Zoho CRM, Zendesk CRM
OVERLAPS WITH CRM VIA OVERLAPPING FUNCTIONALITY AND OVERLAPPING DATA
ETL for Internal Data - Benefits
Data is recorded in real time
captures velocity
Provides a granular picture of business operations and customer relationships
Generated in structured form
Structured data: a standardized format enabling easy access and analysis. Typically, in a tabular format (think spreadsheet)
Should have documentation
ETL for Internal Data - Challenges
Limited to information within the business
cannot provide insight into competitor actions
limited or no visibility into preferences and behaviors of customers outside current market penetration
Data must be aligned
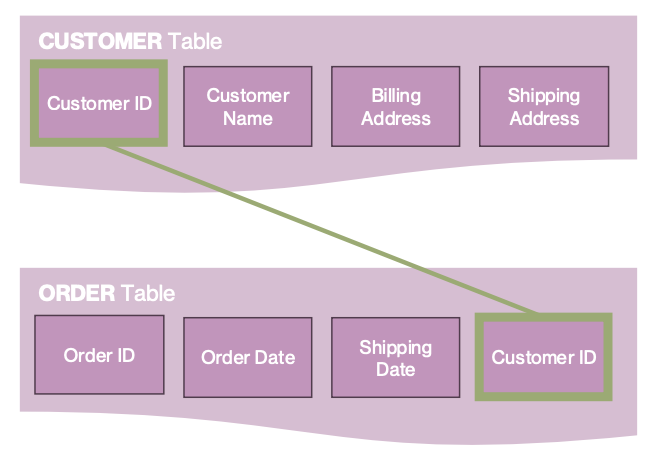
ETL for Internal Data Transform: Aligning Data
Structured data consists of
Attributes or:
columns, variables, features
Records or;
rows, cases, observations
Each data table must have a primary key attribute
a unique identifier of the record
The keys are used to create links or relations between tables
hence the name “relational database”
During the transform stage, key attributes must be added and verified
Requires business knowledge about how the data will be used
ETL for Internal Data: Load & Utilize: Storing Data
Data from each source are stored as independent tables
Typical interface is SQL (or sequel) a specialized language for relational database interactions
Tables can be accessed and combined for analysis
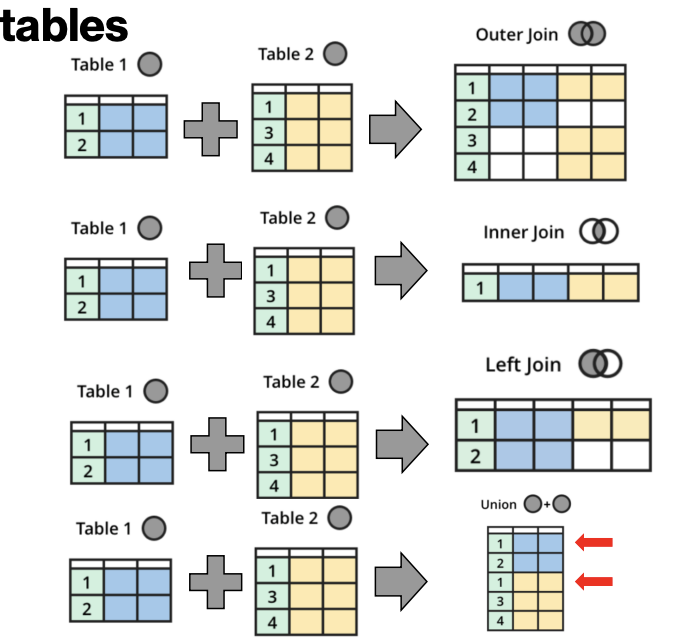
ETL for Internal Data: Load & Utilize: Combining Tables
Common ways to combine tables:
Outer join: Preserve all data in both tables, even if values are missing
Inner join: Only preserve columns with data in both tables (no missing values)
Left (right) join: Maintain all values of table 1 (or 2), even if values are missing
Union (merge): Combine tables which share common columns – Note that a union or merge may result in duplicate rows
ETL for External Data: Extract - External Data Can Be Used to…
External data can be used to:
Augment existing data: add additional information to internal records, linked by a common primary key
i.e., adding consumer demographics from 3rd party data to purchase records, linked by common credit card number
Supplement existing data: Provide insight into broader market or macroeconomic trends
i.e., using census data to target specific neighborhoods for outdoor digital display ads
Extend existing data: provide information not available in internal records
i.e., using scanner data from a new market to develop an entry strategy
ETL for External Data: Extract - External Sources of Raw Data
External Data comes from:
3rd party data vendors or marketplaces
Web Scraping: the process of automatically collecting data as displayed in a web browser
captures the underlying webpage code
data must subsequently be extracted from this code
Application Programming Interface (API): a system which allows two pieces of software to communicate with each other
Authentication and authorization: APIs often require authentication and authorization. This can involve API keys, OAuth tokens, or other security mechanisms. Like a login and password
Request and Response: The client sends a request to the API endpoint, specifying the required data parameters. The server processes this request and sends back the requested data in a structured or semi-structured format
ETL for External Data: Extract - Comparing External Sources (WebScraping)
Webscraping
Can extract data from any website, regardless of whether an API is available
Generally cheaper since it doesn’t require paid access to data APIs
DEVELOPMENT OF SCRAPING SCRIPTS CAN BE TIME CONSUMING
Allows for tailored data extraction to meet specific needs
Captures exactly what is displayed on the webpage (“consumer” view)
DRAWBACKS
Webpage structures can change frequently, causing scraping scripts to break and requiring constant maintenance
Risk of incomplete or inconsistent data due to website changes or errors in scraping scripts
Potential legal issues related to terms of service violations and data privacy laws
ETL for External Data: Extract - Comparing External Sources (API - Application Programming Interface)
APIs
Designed for data access, providing stable and consistent data retrieval
Generally complies with terms of service, reducing legal risks
Often faster and more efficient than web scraping, as APIs are optimized for data delivery
DRAWBACKS
Many APIs require a subscription or payment, which can be expensive
API access is limited to the data and endpoints provided by the service, which may not cover all desired information
Reliance on the API provider for data availability and access, including potential changes in API terms or data limits
Web Scraping: Legal and Ethical Considerations (ETL)
Unauthorized access
Breach of contract
Copyright infringement
Trespass to Chattels
Trade Secrets Misappropriation
Privacy Violations
Organizational Confidentiality
Diminished Organizational Value
Discrimination and Bias
Data Quality and Accuracy
Unauthorized Access
[Web Scraping: Legal and Ethical Considerations (ETL)]
Web scrapping can violate computer fraud laws if it involves accessing a website without permission
Particularly if the site’s terms of service explicitly prohibit scraping
Breach of Contract
[Web Scraping: Legal and Ethical Considerations (ETL)]
Scraping can breach a website's terms of service – Always check the terms of service!
Copyright Infringement
[Web Scraping: Legal and Ethical Considerations (ETL)]
Scraping copyrighted content and using it for commercial purposes without permission can lead to copyright infringement claims –
This is currently under debate, because of actions taken by OpenAi.
Trespass to Chattels
[Web Scraping: Legal and Ethical Considerations (ETL)]
Overloading a website's servers through excessive scraping can potentially cause material damage to the server
Trade Secrets Misappropriation
[Web Scraping: Legal and Ethical Considerations (ETL)]
Extracting and using proprietary information through scraping can lead to trade secrets misappropriation claims
Privacy Violations
[Web Scraping: Legal and Ethical Considerations (ETL)]
Scraping can compromise individual privacy, especially if it involves collecting personal data without consent
Organizational Confidentiality
[Web Scraping: Legal and Ethical Considerations (ETL)]
Web scraping may expose confidential information or trade secrets of an organization
Diminished Organizational Value
[Web Scraping: Legal and Ethical Considerations (ETL)]
Bypassing website interfaces to scrape data can reduce the value of the website's services and content
Discrimination and Bias
[Web Scraping: Legal and Ethical Considerations (ETL)]
The use of biased data from scraping activities can lead to discriminatory outcomes in decision-making processes
Data Quality and Accuracy
[Web Scraping: Legal and Ethical Considerations (ETL)]
Inaccurate or incomplete data obtained through scraping can lead to poor decision-making, financial losses, and negative impacts on various stakeholders
External data formats: Structured Data
[ETL for External Data]
Highly organized data that is easily searchable in relational databases and spreadsheets
Customer databases containing detailed profiles (name, age, contact information)
Sales figures and financial reports in Excel spreadsheets
Follows a predefined schema, making it easy to analyze and report
Data is stored in tables with rows and columns, supporting complex queries
Most rigid format
External data formats: Semi-Structured Data
[ETL for External Data]
Data that does not follow a strict schema but has some organizational properties, making it easier to parse and analyze than unstructured data
JSON files from web analytics tools or APIs (e.g., Google Analytics data)
XML feeds from social media platforms or content aggregators
Contains tags or markers to separate data elements, offering flexibility
Easier to store and query compared to unstructured data but not as rigid as structured data
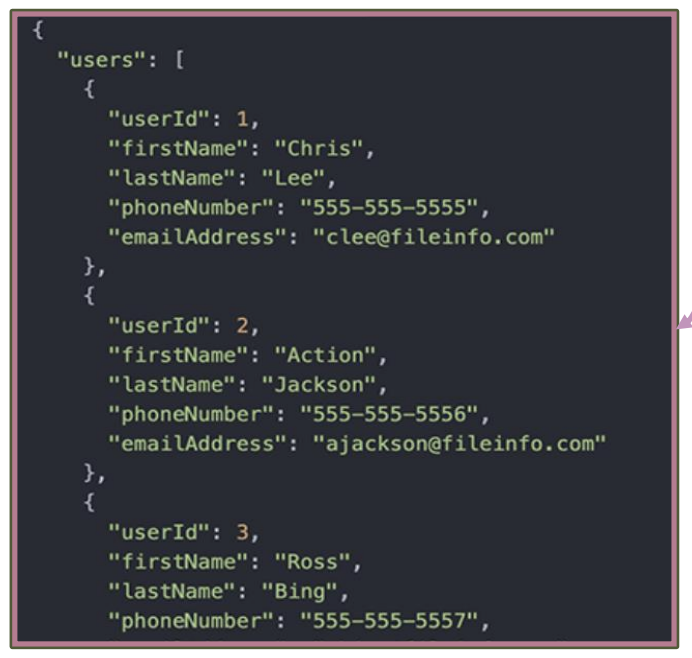
External data formats: Unstructured Data
[ETL for External Data]
Data without a predefined format or structure, making it more complex to process and analyze
Text documents, social media posts, videos, and images
Customer reviews, emails, and blog posts
Provides rich insights into customer sentiment and brand perception
Enables content analysis and trend spotting in social media and online communities
No fixed schema or data model, highly varied in format
Requires advanced tools and techniques (e.g., natural language processing, machine learning) to analyze
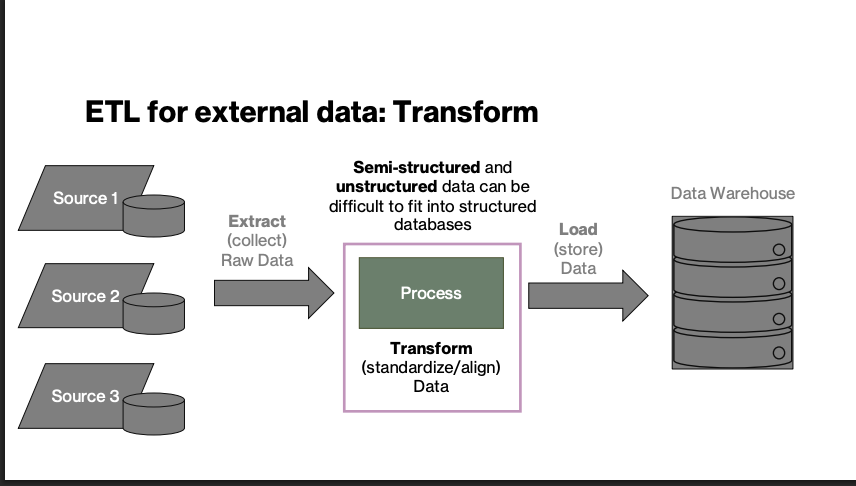
ETL for External Data: Transform
Semi-structured and unstructured data can be difficult to fit into structured databases
Different Storage Paradigms Compared - Data Warehouse
[ETL for External Data]
Structured Storage: Stores data in a highly organized, schema-based format
Data Quality: Ensures high data quality, consistency, and reliability due to its schema-on-write approach
Performance: Optimized for complex queries and reporting
Integration: Easily integrates with traditional BI tools and supports SQL queries
DRAWBACKS
Inflexibility: Less flexible in handling unstructured or semi-structured data, requiring ETL processes to structure the data before storage
Scalability: May face challenges in scaling up efficiently with the growing volume and variety of data
Complexity: Requires significant upfront planning and ongoing management to maintain data schemas
Different Storage Paradigms Compared - Data Lake
[ETL for External Data]
Flexibility
Scalability
Agility
Advanced Analytics
DRAWBACKS
Data Quality: May suffer from lower data quality and consistency due to lack of enforced schema
Complexity: Requires sophisticated data management and governance practices to avoid becoming a data swamp
Performance: Query performance may be slower compared to data warehouse
Document Data Collection
[ETL for External Data]
Plan for long-term storage of raw and processed data
Maintain a logbook with important process events and comments
Develop templates for documentation
Carefully capture information about data
Datasheets for datasets described the dataset, including its motivation and purpose
Data dictionaries describe the features and related metadata in detail
Data cards provide a modular documentation framework for complex, evolving datasets
Datasheets for datasets workflow
[ETL for External Data]
Datasheets are critical for understanding the data and using it responsibly!
Motivation: Why was the dataset created? Who funded and created it?
Composition: Details about the dataset’s content, types of instances, representativeness, labels, and any missing information
Collection Process: How was data collected? Methods used, timeframe, participants involved, and ethical reviews
Preprocessing/Cleaning/Labeling: Steps taken to preprocess or clean the data, saved raw data, and available preprocessing software
Uses: Recommended and past uses, potential risks or harms, and tasks for which the dataset should or should not be used
Distribution: Plans for dataset distribution, licensing, and any third-party restrictions
Maintenance: Plans for updating and maintaining the dataset, contact information, and support for older versions
Data Dictionaries
[ETL for External Data]
Data dictionaries are critical for executing and interpreting analyses!
A collection of metadata which aids in the acquisition, understanding, and analysis of a dataset.
Focused on describing the features or variables contained in the dataset
Includes a plain language description of the feature and what it represents
Having a process preserves data quality…
[ETL for External Data]
…for data producers and collectors
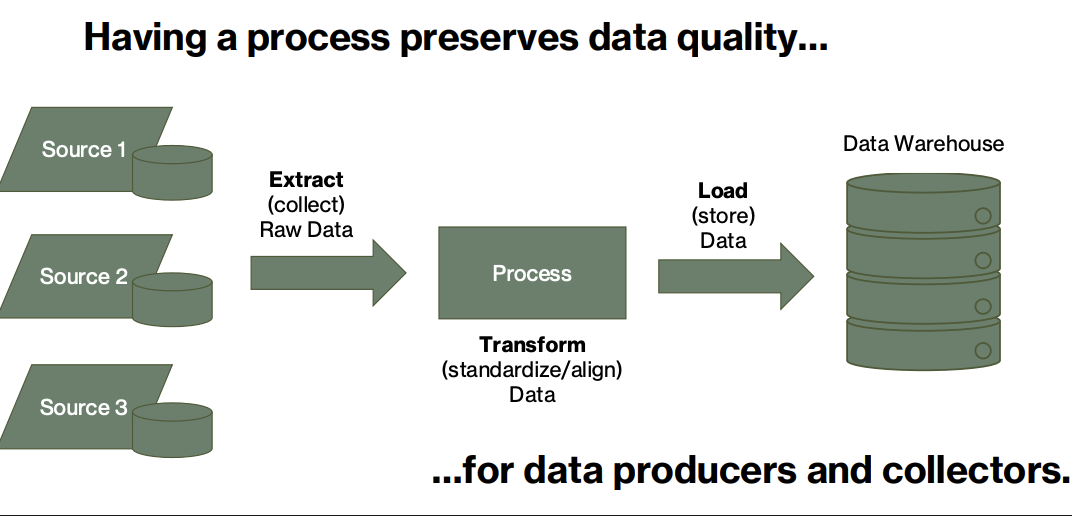
The Roles of Data Producers
Generate, collate, organize and document data
Focused on creating data and information
Defines the scheme or structure of data
Validates data and structures at the point of generation
Enables access to stored (transformed) data
The Roles of Data Consumers
Combine, analyze, report, and interpret data
Focused on creating knowledge and wisdom
Ensure data is drawn from authorized sources
Actively participate in data quality assessments, reporting issues as necessary
Assessing data quality leads to data understanding
Identify additional data needs and communicate requirements
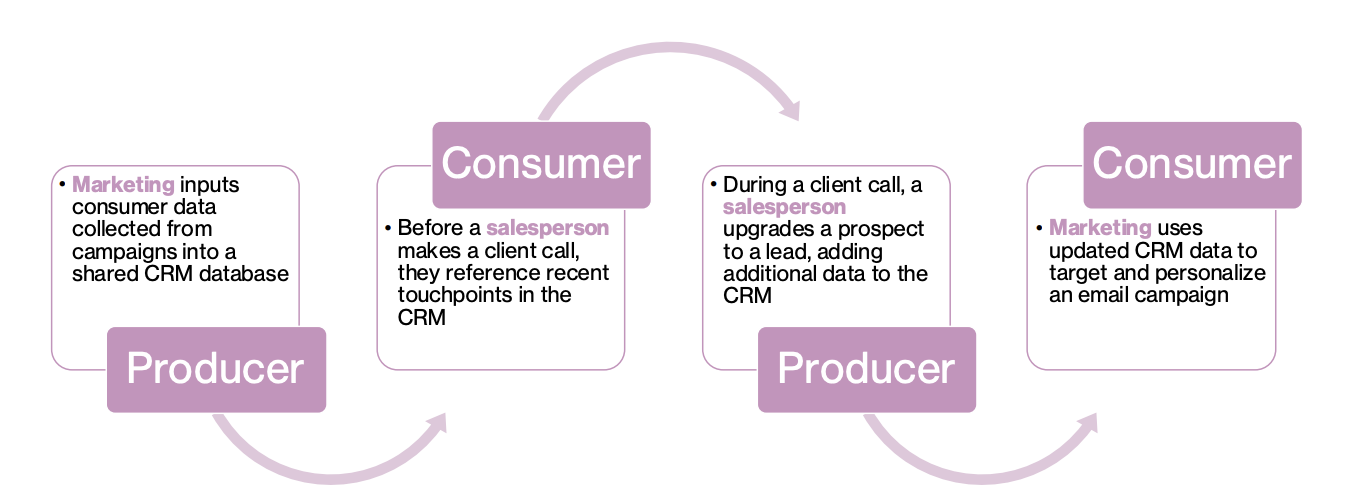
Data Producer-Consumer Value Chain
Producer
Marketing inputs consumer data collected from campaigned into a shared CRM database
Consumer
Before a salesperson makes a client call, they reference recent touchpoints in the CRM
Producer
During a client call, a salesperson upgrades a prospect to a lead, adding additional data to the CRM
Consumer
Marketing uses updated CRM data to target and personalize an email campaign
Data quality dimensions: Availability
Accessibility
what method will we use to interface with the data (ie SQL, API, Scraping?, do we have the data we need or do we need more?
Timeliness
When was data collected, does it still represent data generating process
Authorization