CSI 3640 - Final Exam Review
1/124
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
125 Terms
Exam Contents:
A) Section 5.1 of the Textbook [Cache Memory]
B) PDF file on Storage and Other IO (Sections 6.2, 6.3, 6.4, and 6.9)
C) PDF file on Binary and Decimal Conversion
D) Section 3.5 (only pages 205-215) of the textbook [Floating Point Numbers]
E) Section 2.12 of the textbook [Compiler, Assembler, Linker, and Loader]
F) PDF file on Wallace Tree Multiplier
G) PDF file on Multiprocessors
H) PDF file on Digital Logic (pages 396-405)[Sequential Circuits]
A) Section 5.1 of the Textbook [Cache Memory]
From the earliest days of computing, programmers have wanted _________.
From the earliest days of computing, programmers have wanted unlimited amounts of fast memory.
The topics in this chapter aid programmers by creating that illusion.
Consider the analogy below and explain how it demonstrates the illusion of a large memory that we can access as fast as a very small memory.
Suppose you were a student writing a term paper on important historical developments in computer hardware. You are sitting at a desk in a library with a collection of books that you have pulled from the shelves and are examining. Having several books on the desk in front of you saves time compared to having only one book there and constantly having to go back to the shelves to return it and take out another.
The same principle allows us to create the illusion of a large memory that we can access as fast as a very small memory.
Just as you did not need to access all the books in the library at once with equal probability, a program does not access all of its code or data at once with equal probability. Otherwise, it would be impossible to make most memory accesses fast and still have large memory in computers, just as it would be impossible for you to fit all the library books on your desk and still find what you wanted quickly.
Principle of Locality:
1) What is it?
2) What are the two different types of locality?
1) Principle of Locality:
The principle of locality underlies both the way in which you did your work in the library and the way that programs operate.
The principle of locality states that programs access a relatively small portion of their address space at any instant of time, just as you accessed a very small portion of the library’s collection.
2) There are two different types of locality:
Temporal Locality
Spatial Locality
Temporal Locality:
1) What is it?
2) Give an example.
1) Temporal locality (locality in time): if an item/data location is referenced, it will tend to be referenced again soon.
2) Example: If you recently brought a book to your desk to look at, you will probably need to look at it again soon.
Spatial Locality:
1) What is it?
2) Give an example.
1) Spatial locality (locality in space): if an item/data location is referenced, items/data locations with nearby addresses will tend to be referenced soon.
2) For example, when you brought out the book on early English computers to learn about the EDSAC, you also noticed that there was another book shelved next to it about early mechanical computers, so you likewise brought back that book and, later on, found something useful in that book.
Libraries put books on the same topic together on the same shelves to increase spatial locality.
Locality in Programs:
1) How do programs exhibit temporal locality?
Give an example.
1) Just as accesses to books on the desk naturally exhibit locality, locality in programs arises from simple and natural program structures.
For example, most programs contain loops, so instructions and data are likely to be accessed repeatedly, showing large temporal locality.
Locality in Programs:
2) How do programs exhibit spacial locality?
Give an example.
2) Since instructions are normally accessed sequentially, programs also show high spatial locality. Accesses to data also exhibit a natural spatial locality.
For example, sequential accesses to elements of an array or a record will naturally have high degrees of spatial locality.
How do we take advantage of the principle of locality?
We take advantage of the principle of locality by implementing the memory of a computer as a memory hierarchy.
Memory Hierarchy:
1) What is a memory hierarchy?
2) Why are faster memories smaller in a memory hierarchy?
1) Memory Hierarchy:
Textbook Writing: A memory hierarchy consists of multiple levels of memory with different speeds and sizes.
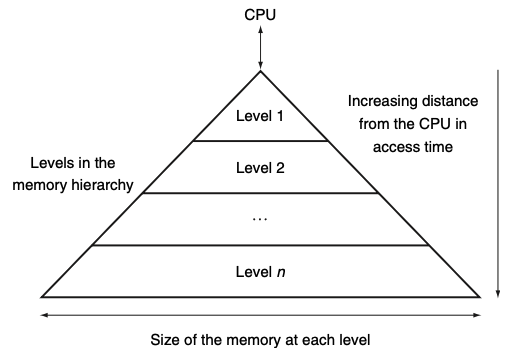
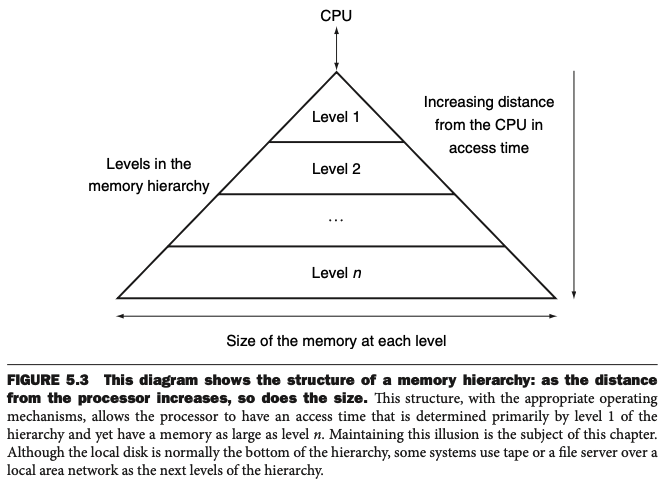
Formal Textbook Definition: A structure that uses multiple levels of memories; as the distance from the processor increases, the size of the memories and the access time both increase.
2) The faster memories are more expensive per bit than the slower memories and thus are smaller.
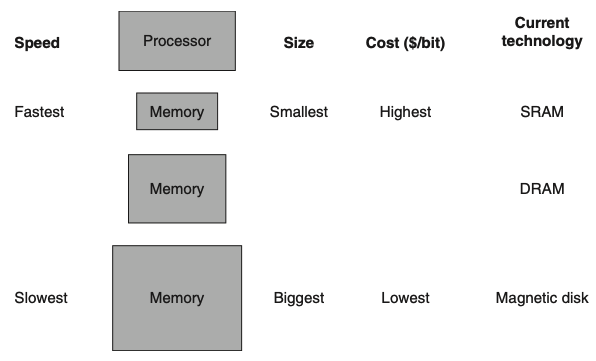
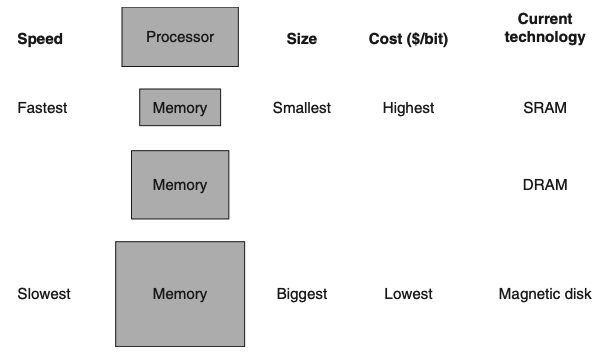
Visual - Basic Structure of a Memory Hierarchy:
1) By implementing the memory system as a hierarchy, what illusion does the user get?
1) By implementing the memory system as a hierarchy, the user has the illusion of a memory that is as large as the largest level of the hierarchy, but can be accessed as if it were all built from the fastest memory.
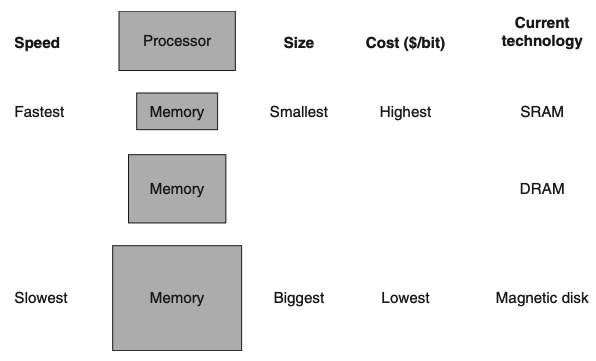
Visual - Basic Structure of a Memory Hierarchy:
2) What does this figure show in regards to memory?
What is the goal of this?
2) Figure 5.1 shows the faster, more expensive memory is close to the processor and the slower, less expensive memory is below it.
The goal is to present the user with as much memory as is available in the cheapest technology, while providing access at the speed offered by the fastest memory.
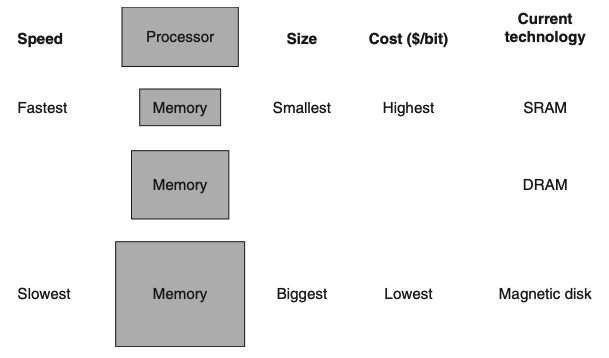
Visual - Basic Structure of a Memory Hierarchy:
3) How is data organized in a memory hierarchy?
3) How Data is Organized:
The data are similarly hierarchical: a level closer to the processor is generally a subset of any level further away, and all the data are stored at the lowest level.
By analogy, the books on your desk form a subset of the library you are working in, which is in turn a subset of all the libraries on campus.
Furthermore, as we move away from the processor, the levels take progressively longer to access, just as we might encounter in a hierarchy of campus libraries.
A memory hierarchy can consist of multiple levels, but data are copied between only two adjacent levels at a time, so we can focus our attention on just two levels.
Flash Memory:
1) What has flash memory replaced in many personal mobile devices?
2) What may flash memory lead to?
1) Flash memory has replaced disks in many personal mobile devices.
2) Flash memory may lead to a new level in the storage hierarchy for desktop and server computers.
Levels & Data in a Memory Hierarchy:
1) How many levels in a memory hierarchy?
2) How are data copied within a memory hierarchy?
1) A memory hierarchy can consist of multiple levels, but…
2) data are copied between only two adjacent levels at a time, so we can focus our attention on just two levels.
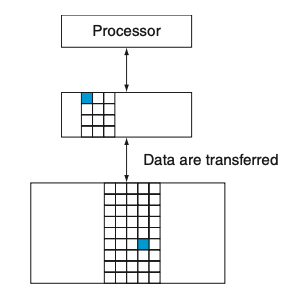
Visual - Figure 5.2
1) What is important to note about every pair of levels in a memory hierarchy?
1) Every pair of levels in the memory hierarchy can be thought of as having an upper and lower level.
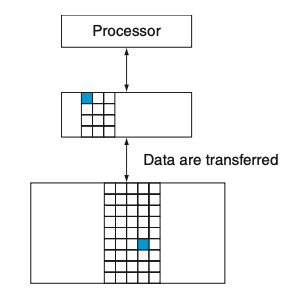
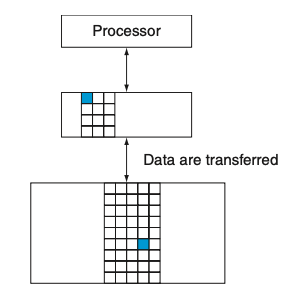
Visual - Figure 5.2
2) How does the upper level compare to the lower level?
2) The upper level—the one closer to the processor—is smaller and faster than the lower level, since the upper level uses technology that is more expensive.
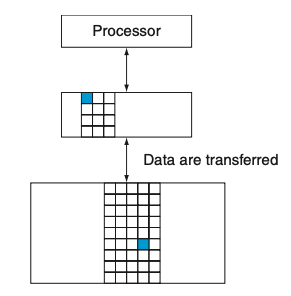
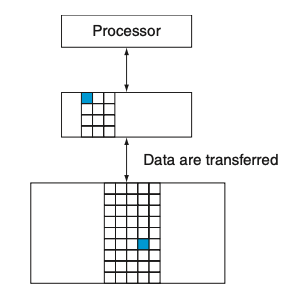
Visual - Figure 5.2
3) What is a block or a line?
3) Within each level, the unit of information that is present or not is called a block or a line.
Usually we transfer an entire block when we copy something between levels.
Formal Definition:
block (or line): The minimum unit of information that can be either present or not present in a cache.
Textbook Notes:
Figure 5.2 shows that the minimum unit of information that can be either present or not present in the two-level hierarchy is called a block or a line; in our library analogy, a block of information is one book.
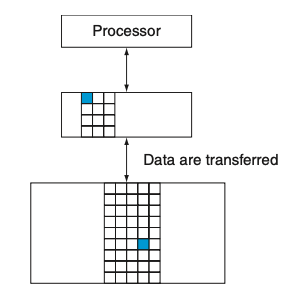
Hit
If the data requested by the processor appear in some block in the upper level, this is called a hit (analogous to your finding the information in one of the books on your desk).
Miss
If the data are not found in the upper level, the request is called a miss. The lower level in the hierarchy is then accessed to retrieve the block containing the requested data. (Continuing our analogy, you go from your desk to the shelves to find the desired book.)
Hit Rate
The hit rate, or hit ratio, is the fraction of memory accesses found in the upper level; it is often used as a measure of the performance of the memory hierarchy.
Formal Definition:
hit rate: The fraction of memory accesses found in a level of the memory hierarchy.
Miss Rate
The miss rate (1−hit rate) is the fraction of memory accesses not found in the upper level.
Formal Definition:
miss rate: The fraction of memory accesses not found in a level of the memory hierarchy.
Hit Time
Since performance is the major reason for having a memory hierarchy, the time to service hits and misses is important.
Hit time is the time to access the upper level of the memory hierarchy, which includes the time needed to determine whether the access is a hit or a miss (that is, the time needed to look through the books on the desk).
Formal Definition
hit time: The time required to access a level of the memory hierarchy, including the time needed to determine whether the access is a hit or a miss.
Miss Penalty
The miss penalty is the time to replace a block in the upper level with the corresponding block from the lower level, plus the time to deliver this block to the processor (or the time to get another book from the shelves and place it on the desk).
Formal Definition:
miss penalty The time required to fetch a block into a level of the memory hierarchy from the lower level, including the time to access the block, transmit it from one level to the other, insert it in the level that experienced the miss, and then pass the block to the requestor.
Compare the hit time and miss penalty.
Because the upper level is smaller and built using faster memory parts, the hit time will be much smaller than the time to access the next level in the hierarchy, which is the major component of the miss penalty.
(The time to examine the books on the desk is much smaller than the time to get up and get a new book from the shelves.)
Data cannot be present in level i unless they are also present in level _____.
Data cannot be present in level i unless they are also present in level i + 1.
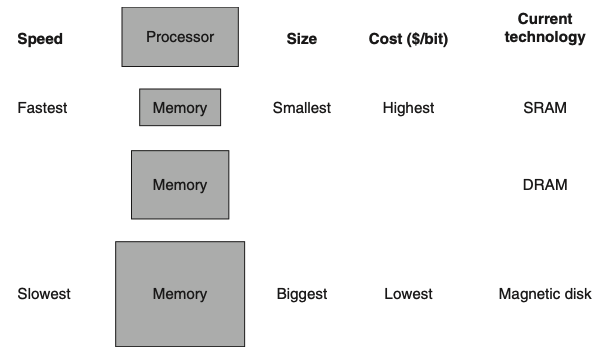
The Big Picture Summary
Programs exhibit both temporal locality, the tendency to reuse recently accessed data items, and spatial locality, the tendency to reference data items that are close to other recently accessed items. Memory hierarchies take advantage of temporal locality by keeping more recently accessed data items closer to the processor. Memory hierarchies take advantage of spatial locality by moving blocks consisting of multiple contiguous words in memory to upper levels of the hierarchy.
Figure 5.3 shows that a memory hierarchy uses smaller and faster memory technologies close to the processor. Thus, accesses that hit in the highest level of the hierarchy can be processed quickly. Accesses that miss go to lower levels of the hierarchy, which are larger but slower. If the hit rate is high enough, the memory hierarchy has an effective access time close to that of the highest (and fastest) level and a size equal to that of the lowest (and largest) level.
In most systems, the memory is a true hierarchy, meaning that data cannot be present in level i unless they are also present in level i + 1.
What does the figure show?
B) PDF file on Storage and Other IO (Sections 6.2, 6.3, 6.4, and 6.9)
6.2 - The Difficulty of Creating Parallel Processing Programs
What is the difficulty with parallelism?
The difficulty with parallelism is not the hardware; it is that too few important application programs have been rewritten to complete tasks sooner on multiprocessors.
It is difficult to write software that uses multiple processors to complete one task faster, and the problem gets worse as the number of processors increases.
Why have parallel processing programs been so much harder to develop than sequential programs?
The first reason is that you must get better performance or better energy efficiency from a parallel processing program on a multiprocessor; otherwise, you would just use a sequential program on a uniprocessor, as sequential programming is simpler.
In fact, uniprocessor design techniques, such as superscalar and out-of- order execution, take advantage of instruction-level parallelism (see Chapter 4), normally without the involvement of the programmer. Such innovations reduced the demand for rewriting programs for multiprocessors, since programmers could do nothing and yet their sequential programs would run faster on new computers.
Why is it difficult to write parallel processing programs that are fast, especially as the number of processors increases?
In Chapter 1, we used the analogy of eight reporters trying to write a single story in hopes of doing the work eight times faster.
To succeed, the task must be broken into eight equal-sized pieces, because otherwise some reporters would be idle while waiting for the ones with larger pieces to finish.
Another speed-up obstacle could be that the reporters would spend too much time communicating with each other instead of writing their pieces of the story.
For both this analogy and parallel programming, the challenges include scheduling, partitioning the work into parallel pieces, balancing the load evenly between the workers, time to synchronize, and overhead for communication between the parties.
The challenge is stiffer with the more reporters for a newspaper story and with the more processors for parallel programming.
Speed-up Challenge

Strong Scaling
Strong scaling means measuring speed-up while keeping the problem size fixed.
Formal Definition: Speed-up achieved on a multiprocessor without increasing the size of the problem.
Weak Scaling
Weak scaling means that the problem size grows proportionally to the increase in the number of processors.
Formal Definition: Speed-up achieved on a multiprocessor while increasing the size of the problem proportionally to the increase in the number of processors.
Let’s assume that the size of the problem, M, is the working set in main memory, and we have P processors.
Then the memory per processor for strong scaling is approximately _____, and for weak scaling, it is about _____.
Let’s assume that the size of the problem, M, is the working set in main memory, and we have P processors.
Then the memory per processor for strong scaling is approximately M/P, and for weak scaling, it is about M.
Memory Hierarchy can ____
Memory hierarchy can interfere with the conventional wisdom about weak scaling being easier than strong scaling.
Give an example of how memory hierarchy can interfere with the conventional wisdom about weak scaling being easier than strong scaling.
For example, if the weakly scaled dataset no longer fits in the last level cache of a multicore microprocessor, the resulting performance could be much worse than by using strong scaling.
Give an argument for applications of both scaling approaches.
Depending on the application, you can argue for either scaling approach:
For example, the TPC-C debit-credit database benchmark requires that you scale up the number of customer accounts in proportion to the higher transactions per minute. The argument is that it’s nonsensical to think that a given customer base is suddenly going to start using ATMs 100 times a day just because the bank gets a faster computer. Instead, if you’re going to demonstrate a system that can perform 100 times the numbers of transactions per minute, you should run the experiment with 100 times as many customers.
Bigger problems often need more data, which is an argument for weak scaling.
6.3 - SISD, MIMD, SIMD, SPMD, and Vector
One categorization of parallel hardware proposed in the ____ is still used today.
It was based on _____ and ____.
One categorization of parallel hardware proposed in the 1960s is still used today.
It was based on the number of instruction streams and the number of data streams.
a) Compare a conventional uniprocessor and a conventional multiprocessor.
b) What are these two categories called?
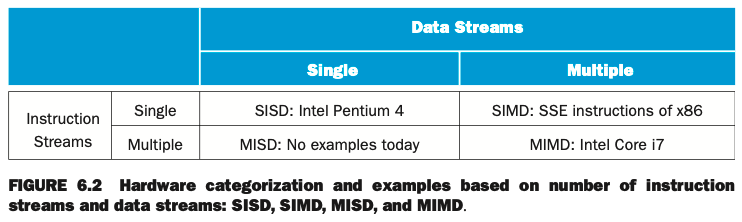
a) A conventional uniprocessor has a single instruction stream and single data stream, and a conventional multiprocessor has multiple instruction streams and multiple data streams.
b) These two categories are abbreviated SISD and MIMD, respectively.
SISD
SISD - Single Instruction stream, Single Data stream.
A uniprocessor.
MIMD
MIMD - Multiple Instruction streams, Multiple Data streams.
A multiprocessor.
SPMD
SPMD - Single Program, Multiple Data streams.
The conventional MIMD programming model, where a single program runs across all processors.
SIMD
SIMD - Single Instruction stream, Multiple Data streams.
The same instruction is applied to many data streams, as in a vector processor.
Complete the table.
SIMD works best when dealing with arrays in ____ loops.
Hence, for parallelism to work in SIMD, there must be a great deal of identically structured data, which is called _______.
SIMD works best when dealing with arrays in for loops
Hence, for parallelism to work in SIMD, there must be a great deal of identically structured data, which is called data-level parallelism.
data-level parallelism
Parallelism achieved by performing the same operation on independent data.
SIMD is at its weakest in ____ or ____ statements, where each execution unit must perform a different operation on its data, depending on what data it has.
Execution units with the wrong data must be disabled so that units with proper data may continue.
If there are n cases, in these situations, SIMD processors essentially run at _____ of peak performance.
SIMD is at its weakest in case or switch statements, where each execution unit must perform a different operation on its data, depending on what data it has.
Execution units with the wrong data must be disabled so that units with proper data may continue.
If there are n cases, in these situations, SIMD processors essentially run at 1/nth of peak performance.
Advanced Vector Extensions (AVX) supports the simultaneous execution of four ____ floating-point numbers.
The width of the operation and the registers is encoded in the ____ of these multimedia instructions.
Advanced Vector Extensions (AVX) supports the simultaneous execution of four 64-bit floating-point numbers.
The width of the operation and the registers is encoded in the opcode of these multimedia instructions.
An older and, as we shall see, more elegant interpretation of SIMD is called a ______, which has been closely identified with computers designed by _____ starting in the ____.
An older and, as we shall see, more elegant interpretation of SIMD is called a vector architecture, which has been closely identified with computers designed by Seymour Cray starting in the 1970s.
IMPORTANT
a) Explain the basic philosophy of vector architecture.
b) What is a key feature of vector architectures?
Rather than having 64 ALUs perform 64 additions simultaneously, like the old array processors, the vector architectures pipelined the ALU to get good performance at lower cost.
a) The basic philosophy of vector architecture is to collect data elements from memory, put them in order into a large set of registers, operate on them sequentially in registers using pipelined execution units, and then write the results back to memory.
b) A key feature of vector architectures is therefore a set of vector registers. Thus, a vector architecture might have 32 vector registers, each with 64 64-bit elements.
Comparing Vector to Conventional Code (1/2)

Comparing Vector to Conventional Code (2/2)

Vector vs Scalar

Vector vs Multimedia Extensions

vector lane
One or more vector functional units and a portion of the vector register file. Inspired by lanes on highways that increase traffic speed, multiple lanes execute vector operations simultaneously.
Structure of a vector unit containing four lanes
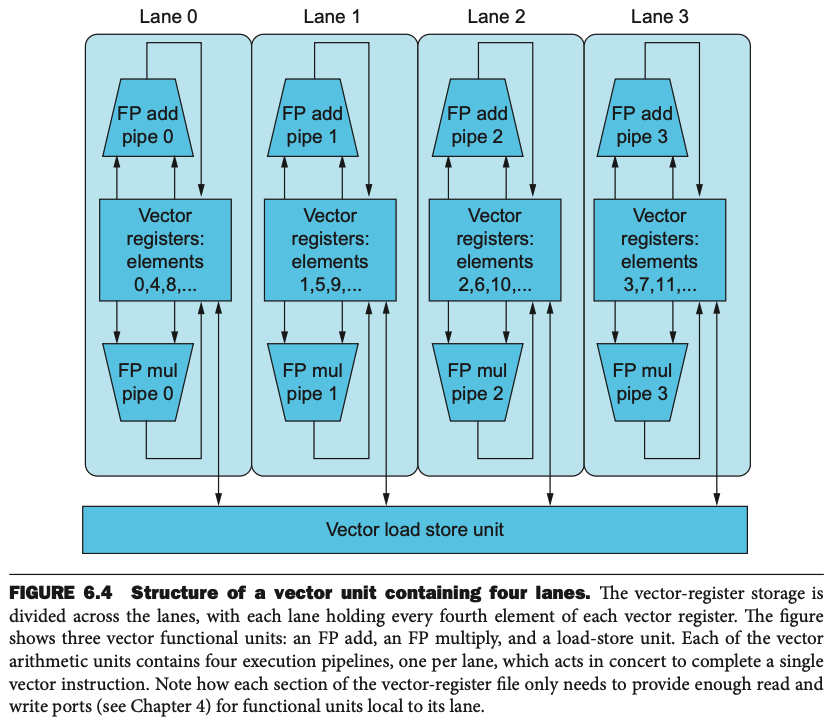
6.4 - Hardware Multithreading
hardware multithreading
Increasing utilization of a processor by switching to another thread when one thread is stalled.
While MIMD relies on multiple processes or threads to try to keep many processors busy, hardware multithreading allows multiple threads to share the functional units of a single processor in an overlapping fashion to try to utilize the hardware resources efficiently.
To permit this sharing, the processor must duplicate the independent state of each thread. For example, each thread would have a separate copy of the register file and the program counter. The memory itself can be shared through the virtual memory mechanisms, which already support multi-programming. In addition, the hardware must support the ability to change to a different thread relatively quickly. In particular, a thread switch should be much more efficient than a process switch, which typically requires hundreds to thousands of processor cycles while a thread switch can be instantaneous.
What are the two main approaches to hardware multithreading?
Fine-grained multithreading
Coarse-grained multithreading
fine-grained multithreading
A version of hardware multithreading that implies switching between threads after every instruction.
Fine-grained multithreading switches between threads on each instruction, resulting in interleaved execution of multiple threads. This interleaving is often done in a round-robin fashion, skipping any threads that are stalled at that clock cycle. To make fine-grained multithreading practical, the processor must be able to switch threads on every clock cycle. One advantage of fine-grained multithreading is that it can hide the throughput losses that arise from both short and long stalls, since instructions from other threads can be executed when one thread stalls. The primary disadvantage of fine-grained multithreading is that it slows down the execution of the individual threads, since a thread that is ready to execute without stalls will be delayed by instructions from other threads.
coarse-grained multithreading
A version of hardware multithreading that implies switching between threads only after significant events, such as a last-level cache miss.
Coarse-grained multithreading was invented as an alternative to fine-grained multithreading. Coarse-grained multithreading switches threads only on expensive stalls, such as last-level cache misses. This change relieves the need to have thread switching be extremely fast and is much less likely to slow down the execution of an individual thread, since instructions from other threads will only be issued when a thread encounters a costly stall. Coarse-grained multithreading suffers, however, from a major drawback: it is limited in its ability to overcome throughput losses, especially from shorter stalls. This limitation arises from the pipeline start-up costs of coarse-grained multithreading. Because a processor with coarse-grained multithreading issues instructions from a single thread, when a stall occurs, the pipeline must be emptied or frozen. The new thread that begins executing after the stall must fill the pipeline before instructions are able to complete. Due to this start- up overhead, coarse-grained multithreading is much more useful for reducing the penalty of high-cost stalls, where pipeline refill is negligible compared to the stall time.
simultaneous multithreading (SMT)
A version of multithreading that lowers the cost of multithreading by utilizing the resources needed for multiple issue, dynamically scheduled microarchitecture.
Simultaneous multithreading (SMT) is a variation on hardware multithreading that uses the resources of a multiple-issue, dynamically scheduled pipelined processor to exploit thread-level parallelism at the same time it exploits instruction- level parallelism (see Chapter 4). The key insight that motivates SMT is that multiple-issue processors often have more functional unit parallelism available than most single threads can effectively use. Furthermore, with register renaming and dynamic scheduling (see Chapter 4), multiple instructions from independent threads can be issued without regard to the dependences among them; the resolution of the dependences can be handled by the dynamic scheduling capability.
Since SMT relies on the existing dynamic mechanisms, it does not switch resources every cycle. Instead, SMT is always executing instructions from multiple threads, leaving it up to the hardware to associate instruction slots and renamed registers with their proper threads.
6.9 - Communicating to the Outside World: Cluster Networking
memory-mapped I/O
An I/O scheme in which portions of the address space are assigned to I/O devices, and reads and writes to those addresses are interpreted as commands to the I/O device.
direct memory access (DMA)
A mechanism that provides a device controller with the ability to transfer data directly to or from the memory without involving the processor.
interrupt-driven I/O
An I/O scheme that employs interrupts to indicate to the processor that an I/O device needs attention.
The operating system acts as the ______
The operating system acts as the interface between the hardware and the program that requests I/O.
The network responsibilities of the operating system arise from three characteristics of networks….
1) Multiple programs using the processor share the network.
2) Networks often use interrupts to communicate information about the operations. Because interrupts cause a transfer to kernel or supervisor mode, they must be handled by the operating system (OS).
3) The low-level control of a network is complex, because it requires managing a set of concurrent events and because the requirements for correct device control are often very detailed.
These three characteristics of networks specifically and I/O systems in general lead to several different functions the OS must provide….
These three characteristics of networks specifically and I/O systems in general lead to several different functions the OS must provide:
The OS guarantees that a user’s program accesses only the portions of an I/O device to which the user has rights. For example, the OS must not allow a program to read or write a file on disk if the owner of the file has not granted access to this program. In a system with shared I/O devices, protection could not be provided if user programs could perform I/O directly.
The OS provides abstractions for accessing devices by supplying routines that handle low-level device operations.
The OS handles the interrupts generated by I/O devices, just as it handles the exceptions generated by a program.
The OS tries to provide equitable access to the shared I/O resources, as well as schedule accesses to enhance system throughput.
device driver:
1) What is it?
2) How many steps when transmitting or receiving a message?
1) A program that controls an I/O device that is attached to the computer.
The software inside the operating system that interfaces to a specific I/O device like this NIC is called a device driver.
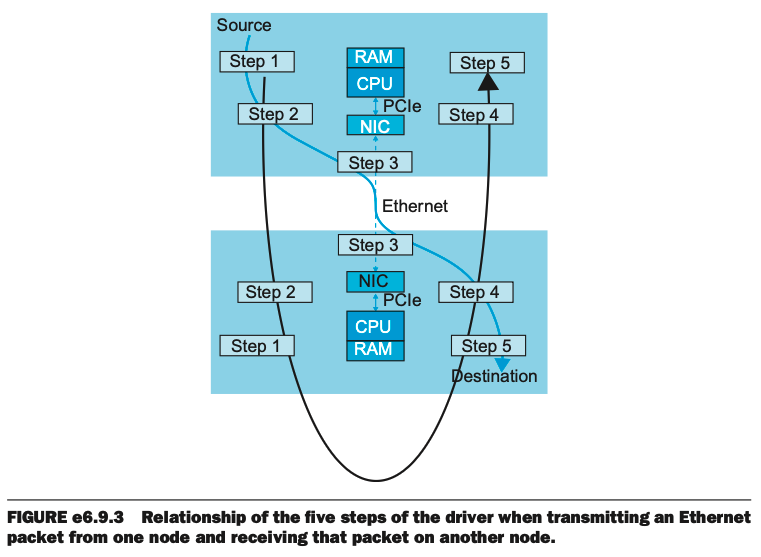
2) The driver for this NIC follows five steps when transmitting or receiving a message.
5 Transmit Steps
5 transmit steps:
1) The driver first prepares a packet buffer in host memory. It copies a packet from the user address space into a buffer that it allocates in the operating system address space.
2) Next, it “talks” to the NIC. The driver writes an I/O descriptor to the appropriate NIC register that gives the address of the buffer and its length.
3) The DMA in the NIC next copies the outgoing Ethernet packet from the host buffer over PCIe.
4) When the transmission is complete, the DMA interrupts the processor to notify the processor that the packet has been successfully transmitted.
5) Finally, the driver de-allocates the transmit buffer.
5 Receive Steps
Next, the receive steps:
1) First, the driver prepares a packet buffer in host memory, allocating a new buffer in which to place the received packet.
2) Next, it “talks” to the NIC. The driver writes an I/O descriptor to the appropriate NIC register that gives the address of the buffer and its length.
3) The DMA in the NIC next copies the incoming Ethernet packet over PCIe into the allocated host buffer.
4) When the transmission is complete, the DMA interrupts the processor to notify the host of the newly received packet and its size.
5) Finally, the driver copies the received packet into the user address space.
Figure - Relationship of the five steps of the driver when transmitting an Ethernet packet from one node and receiving that packet on another node.
As you can see in Figure e6.9.3, the first three steps are time-critical when transmitting a packet (since the last two occur after the packet is sent), and the last three steps are time-critical when receiving a packet (since the first two occur before a packet arrives). However, these non-critical steps must be completed before individual nodes run out of resources, such as memory space. Failure to do so negatively affects network performance.
(1/3) Starting with software optimizations, one performance target is ___________
Starting with software optimizations, one performance target is reducing the number of times the packet is copied
(2/3) A second software optimization is to ______
A second software optimization is to cut out the operating system almost entirely by moving the communication into the user address space.
By not invoking the operating system and not causing a context switch, we can reduce the software overhead considerably.
(3/3) A third step would be to ______
A third step would be to drop interrupts.
One reason is that modern processors normally go into lower power mode while waiting for an interrupt, and it takes time to come out of low power to service the interrupt as well for the disruption to the pipeline, which increases latency.
polling
The process of periodically checking the status of an I/O device to determine the need to service the device.
The alternative to interrupts is for the processor to periodically check status bits to see if I/O operation is complete, which is called polling.
Looking at hardware optimizations, one potential target for improvement is ______
Looking at hardware optimizations, one potential target for improvement is in calculating the values of the fields of the Ethernet packet.
A second hardware optimization, available on the most recent Intel processors such as Ivy Bridge, improves ____
A second hardware optimization, available on the most recent Intel processors such as Ivy Bridge, improves the performance of the NIC with respect to the memory hierarchy.
C) PDF file on Binary and Decimal Conversion
The most basic unit of information in a digital computer is called a ____, which is a contraction of ____.
The most basic unit of information in a digital computer is called a bit, which is a contraction of binary digit.
Bit:
1) What is a bit within a computer circuit?
2) How are bits used as a basic unit of addressable computer storage?
1) In the concrete sense, a bit is nothing more than a state of "on" or "off" (or "high" and "low") within a computer circuit.
2) In 1964, the designers of the IBM System/360 mainframe computer established a convention of using groups of 8 bits as the basic unit of addressable computer storage.
They called this collection of 8 bits a byte.
Computer ____ consist of two or more adjacent bytes that are sometimes addressed and almost always are manipulated collectively.
Computer words consist of two or more adjacent bytes that are sometimes addressed and almost always are manipulated collectively.
The _______ represents the data size that is handled most efficiently by a particular architecture.
The word size represents the data size that is handled most efficiently by a particular architecture.
Words can be ______ (what size)
Words can be 16 bits, 32 bits, 64 bits, or any other size that makes sense in the context of a computer's organization (including sizes that are not multiples of eight).
An 8-bit byte can be divided into two 4-bit halves called _____
An 8-bit byte can be divided into two 4-bit halves called nibbles (or nyb-bles).
Because each bit of a byte has a value within a positional numbering system, the nibble containing the least-valued binary digit is called the _____, and the other half the _____.
Because each bit of a byte has a value within a positional numbering system, the nibble containing the least-valued binary digit is called the low-order nibble, and the other half the high-order nibble.
The general idea behind positional numbering systems is that a numeric value is represented through increasing powers of a ______.
This is often referred to as a ______ because each position is weighted by a power of the radix.
The general idea behind positional numbering systems is that a numeric value is represented through increasing powers of a radix (or base).
This is often referred to as a weighted numbering system because each position is weighted by a power of the radix.
The set of valid numerals for a positional numbering system is equal in size to ______
The set of valid numerals for a positional numbering system is equal in size to the radix of that system.
______ was the first to generalize the idea of the (positional) decimal system to other bases.
Gottfried Leibniz (1646-1716) was the first to generalize the idea of the (positional) decimal system to other bases.
______ occurs in unsigned binary representation when the result of an arithmetic operation is outside the range of allowable precision for the given number of bits.
Overflow occurs in unsigned binary representation when the result of an arithmetic operation is outside the range of allowable precision for the given number of bits.
______ separate the integer part of a number from its fractional part.
In the decimal system, the radix point is called a _____.
Binary fractions have a binary point.
Radix points separate the integer part of a number from its fractional part.
In the decimal system, the radix point is called a decimal point.
Binary fractions have a binary point.
D) Section 3.5 (only pages 205-215) of the textbook [Floating Point Numbers]
scientific notation
A notation that renders numbers with a single digit to the left of the decimal point.
normalized
A number in floating-point notation that has no leading 0s.