AWS Certified Machine Learning Engineer Associate
1/107
Earn XP
Description and Tags
Updated Mar 2025 | Missing qns - 29
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
108 Terms
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company needs to use the central model registry to manage different versions of models in the application.
Which action will meet this requirement with the LEAST operational overhead?
A. Create a separate Amazon Elastic Container Registry (Amazon ECR) repository for each model.
B. Use Amazon Elastic Container Registry (Amazon ECR) and unique tags for each model version.
C. Use the SageMaker Model Registry and model groups to catalog the models.
D. Use the SageMaker Model Registry and unique tags for each model version.
Answer:
C. Use the SageMaker Model Registry and model groups to catalog the models.
---
### Detailed Explanation
#### Requirements Summary
1. Central Model Registry: Manage multiple versions of models.
2. Secure & Isolated Training Data: Ensure data in S3 remains protected during the ML lifecycle.
3. Least Operational Overhead: Minimize manual processes, custom code, or complex setups.
---
### Analysis of the Correct Answer (Option C)
##### What It Does
- Uses SageMaker’s Model Registry to catalog models in model groups, where each group represents a logical model (e.g., "FraudDetectionModel") with versions (v1, v2, etc.).
##### Why It Meets the Requirements
1. Central Model Registry:
- Model Groups: Each group acts as a container for all versions of a model (e.g., "CustomerChurnModel-v1", "v2").
- Native Versioning: Automatically tracks versions, lineage, and metadata (training metrics, datasets, hyperparameters).
2. Security & Isolation:
- IAM Integration: Controls access to the Model Registry and S3 data via AWS IAM policies.
- S3 Isolation: Training data in S3 is secured using bucket policies and encryption, ensuring isolation during training and deployment.
3. Least Operational Overhead:
- No Custom Tooling: Fully managed by SageMaker, eliminating the need for manual tagging, ECR repository management, or external scripts.
- Automated Workflows: Direct integration with SageMaker Pipelines, training jobs, and deployment tools (e.g., one-click deployment to endpoints).
---
### Key Differentiators for Option C
1. Purpose-Built for Model Management:
- The Model Registry is explicitly designed for tracking model versions, approvals, and lifecycle stages (e.g., "Staging" vs. "Production").
2. End-to-End SageMaker Integration:
- Models trained in SageMaker can be registered automatically.
- Deployment is streamlined through built-in tools like SageMaker Endpoints or Batch Transform.
3. Governance and Compliance:
- Approval workflows ensure only validated models are deployed.
- Audit trails for model lineage (e.g., which data trained which version).
4. Scalability:
- Supports large-scale ML operations with minimal configuration.
---
### Analysis of Incorrect Options
##### Option A: Separate Amazon ECR Repositories for Each Model
- Problem:
- Misaligned Tool: ECR is designed for Docker containers, not model artifacts. Managing models here requires custom workflows to link containers to model versions.
- High Overhead: Creating and managing isolated ECR repositories for each model introduces complexity in permissions, cleanup, and tracking.
- No Native Versioning: Versioning would rely on manual tagging or external tools.
##### Option B: Amazon ECR + Unique Tags for Model Versions
- Problem:
- Manual Effort: Requires strict tagging discipline, which can lead to errors (e.g., inconsistent tags).
- No Lifecycle Management: ECR lacks native approval workflows, rollback capabilities, or staging environments for models.
- Operational Friction: Combines the overhead of ECR with manual tagging, doubling maintenance effort.
##### Option D: SageMaker Model Registry + Unique Tags
- Problem:
- Redundancy: The Model Registry already tracks versions via model groups. Adding tags duplicates functionality.
- Risk of Inconsistency: Tags could diverge from model group versions if not meticulously synchronized.
- Unnecessary Complexity: Enforcing tagging policies alongside model groups increases maintenance.
---
### Conclusion
Option C is the only solution that natively supports model versioning, governance, and security while minimizing operational overhead. The SageMaker Model Registry is purpose-built for managing ML models, whereas ECR-based solutions (A, B) are workarounds requiring custom tooling, and tagging (D) adds redundant effort. By using model groups, the company ensures a scalable, secure, and centralized model management system.
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company is experimenting with consecutive training jobs.
How can the company MINIMIZE infrastructure startup times for these jobs?
A. Use Managed Spot Training.
B. Use SageMaker managed warm pools.
C. Use SageMaker Training Compiler.
D. Use the SageMaker distributed data parallelism (SMDDP) library.
Answer:
B. Use SageMaker managed warm pools.
---
### Detailed Explanation
#### Requirements Summary
1. Minimize Infrastructure Startup Times: Reduce delays when launching consecutive training jobs.
2. Secure & Isolated Training Data: Ensure S3 data remains protected during the ML lifecycle.
---
### Analysis of the Correct Answer (Option B)
##### What It Does
- SageMaker Managed Warm Pools keep training instances (e.g., containers, ML compute resources) in a "warm" state after a training job completes. Subsequent jobs reuse these pre-initialized resources, avoiding cold starts.
##### Why It Meets the Requirements
1. Reduced Startup Time:
- Avoids Cold Starts: Traditional training jobs require provisioning new instances, installing dependencies, and loading containers, which can take several minutes. Warm pools skip this initialization phase.
- Reusable Resources: Consecutive jobs reuse the same warm pool, slashing startup latency to seconds instead of minutes.
2. Security & Isolation:
- Warm pools operate within the same SageMaker environment, inheriting IAM roles, VPC configurations, and S3 data access policies.
3. Cost Efficiency:
- While warm pools incur costs for idle instances, they are cheaper than repeated cold starts for frequent, consecutive jobs.
---
### Key Differentiators for Option B
1. Direct Impact on Startup Latency:
- Warm pools explicitly target infrastructure initialization delays, unlike other options that optimize training runtime.
2. Seamless Integration:
- Managed by SageMaker—no custom code or complex configurations required.
3. Scalability:
- Supports high-frequency experimentation by maintaining ready-to-use resources.
---
### Analysis of Incorrect Options
##### Option A: Managed Spot Training
- Problem:
- Focus on Cost, Not Speed: Managed Spot Training uses EC2 Spot Instances to reduce costs but does not reduce startup times.
- Increased Interruptions: Spot Instances can be reclaimed by AWS, causing job restarts and unpredictable delays.
##### Option C: SageMaker Training Compiler
- Problem:
- Optimizes Training Runtime, Not Startup: The Training Compiler speeds up model training by optimizing compute operations (e.g., GPU utilization). It has no impact on infrastructure provisioning times.
##### Option D: SageMaker Distributed Data Parallelism (SMDDP)
- Problem:
- Improves Training Efficiency, Not Startup: SMDDP accelerates distributed training across multiple GPUs/nodes but does not address the time required to provision resources.
---
### Conclusion
Option B is the only solution that directly minimizes infrastructure startup times by reusing pre-initialized resources via SageMaker managed warm pools. Other options focus on cost (A), training speed (C, D), or parallelism (D), which do not address the core requirement of reducing delays between consecutive job launches. Warm pools ensure rapid iteration during experimentation while maintaining security and isolation.
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company must implement a manual approval-based workflow to ensure that only approved models can be deployed to production endpoints.
Which solution will meet this requirement?
A. Use SageMaker Experiments to facilitate the approval process during model registration.
B. Use SageMaker ML Lineage Tracking on the central model registry. Create tracking entities for the approval process.
C. Use SageMaker Model Monitor to evaluate the performance of the model and to manage the approval.
D. Use SageMaker Pipelines. When a model version is registered, use the AWS SDK to change the approval status to "Approved."
Answer:
D. Use SageMaker Pipelines. When a model version is registered, use the AWS SDK to change the approval status to "Approved."
---
### Detailed Explanation
#### Requirements Summary
1. Manual Approval Workflow: Ensure only approved models are deployed to production.
2. Integration with Central Model Registry: Models must be registered and tracked.
---
### Analysis of the Correct Answer (Option D)
##### What It Does
- SageMaker Pipelines automates the ML workflow, including training, validation, and model registration.
- After a model version is registered in the SageMaker Model Registry, the AWS SDK (e.g., Boto3) is used to manually update the model’s approval status to "Approved."
##### Why It Meets the Requirements
1. Manual Approval:
- A human operator uses the AWS SDK (via scripts, CLI, or custom tools) to explicitly set the model version’s status to "Approved" in the Model Registry.
- This enforces a manual "gate" before deployment.
2. Central Model Registry Integration:
- The Model Registry natively supports approval statuses (e.g., "PendingManualApproval," "Approved," "Rejected").
- Deployment tools (e.g., SageMaker Endpoints) can be configured to only deploy "Approved" models.
3. Security:
- IAM policies restrict who can modify approval statuses, ensuring only authorized users approve models.
---
### Key Differentiators for Option D
1. Native Support for Approval Status:
- SageMaker Model Registry includes built-in fields for tracking approval, eliminating the need for custom tagging or external systems.
2. Flexibility in Workflow Design:
- Pipelines automate model registration, while the SDK allows manual approval outside the pipeline (e.g., via human review).
3. Auditability:
- Approval actions via the SDK are logged in AWS CloudTrail, providing an audit trail for compliance.
---
### Analysis of Incorrect Options
##### Option A: SageMaker Experiments
- Problem:
- Focus on Experiment Tracking: Experiments tracks training runs, parameters, and metrics but lacks native approval workflows.
- No Enforcement: Cannot prevent unapproved models from being deployed.
##### Option B: ML Lineage Tracking
- Problem:
- Audit Tool, Not Approval System: Lineage Tracking records model artifacts, datasets, and processes for compliance but does not enforce approval gates.
- Manual Effort: Creating "tracking entities" for approvals would require custom code and lacks integration with deployment controls.
##### Option C: SageMaker Model Monitor
- Problem:
- Post-Deployment Monitoring: Model Monitor evaluates live model performance (e.g., data drift) but does not govern pre-deployment approvals.
- Misaligned Purpose: Approval occurs after deployment, violating the requirement.
---
### Conclusion
Option D is the only solution that directly implements a manual approval workflow using SageMaker’s native capabilities. By combining Pipelines (for automated model registration) and the AWS SDK (for manual status updates), the company ensures that only approved models are deployed. Other options lack enforcement mechanisms or focus on unrelated stages of the ML lifecycle (tracking, monitoring).
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company needs to run an on-demand workflow to monitor bias drift for models that are deployed to real-time endpoints from the application.
Which action will meet this requirement?
A. Configure the application to invoke an AWS Lambda function that runs a SageMaker Clarify job.
B. Invoke an AWS Lambda function to pull the sagemaker-model-monitor-analyzer built-in SageMaker image.
C. Use AWS Glue Data Quality to monitor bias.
D. Use SageMaker notebooks to compare the bias.
Answer:
A. Configure the application to invoke an AWS Lambda function that runs a SageMaker Clarify job.
---
### Detailed Explanation
#### Requirements Summary
1. On-Demand Bias Drift Monitoring: Detect bias drift in models deployed to real-time endpoints.
2. Automated Workflow: Trigger monitoring programmatically.
3. Integration with SageMaker: Ensure compatibility with deployed endpoints.
---
### Analysis of the Correct Answer (Option A)
##### What It Does
- AWS Lambda invokes a SageMaker Clarify job on demand (e.g., via API Gateway, scheduled events, or application triggers).
- Clarify analyzes live endpoint data for bias metrics (e.g., disparate impact, class imbalance) and compares them to baseline training data.
##### Why It Meets the Requirements
1. Bias-Specific Analysis:
- SageMaker Clarify is purpose-built to measure bias in datasets and model predictions, including pre-training and post-deployment drift.
- Metrics like Class Imbalance (CI), Difference in Positive Proportions (DPP), and Conditional Demographic Disparity (CDD) are tracked.
2. On-Demand Workflow:
- Lambda enables event-driven execution (e.g., triggered by user requests, time intervals, or new data batches).
- Results are stored in S3 or visualized in SageMaker Studio for review.
3. Security & Isolation:
- Clarify jobs run in SageMaker-managed environments with IAM roles, ensuring secure access to S3 data and endpoints.
---
### Key Differentiators for Option A
1. Native Bias Monitoring:
- Clarify directly addresses the requirement to measure bias drift, unlike generic monitoring tools.
2. Automation:
- Lambda + Clarify creates a serverless, scalable workflow without manual intervention.
3. Real-Time Endpoint Integration:
- Clarify can ingest live endpoint data captured via SageMaker’s Data Capture feature.
---
### Analysis of Incorrect Options
##### Option B: SageMaker Model Monitor Built-In Analyzer
- Problem:
- Focuses on Data/Model Quality: The sagemaker-model-monitor-analyzer image checks for data drift (e.g., feature distributions) and model performance (e.g., accuracy), but not bias metrics.
- No Native Bias Tracking: Requires custom code to replicate Clarify’s bias analysis.
##### Option C: AWS Glue Data Quality
- Problem:
- Data Profiling, Not Bias: Glue Data Quality validates datasets for completeness, uniqueness, and schema compliance but lacks model bias evaluation.
##### Option D: SageMaker Notebooks
- Problem:
- Manual Process: Notebooks require human intervention to run bias comparisons, violating the "on-demand workflow" requirement.
- No Integration with Endpoints: Pulling live endpoint data and analyzing bias would require custom scripting.
---
### Conclusion
Option A is the only solution that combines automated, on-demand execution (via Lambda) with specialized bias drift monitoring (via SageMaker Clarify). Other options either lack bias-specific capabilities (B, C) or rely on manual processes (D). By using Clarify, the company ensures compliance with fairness standards while maintaining a secure, serverless workflow.
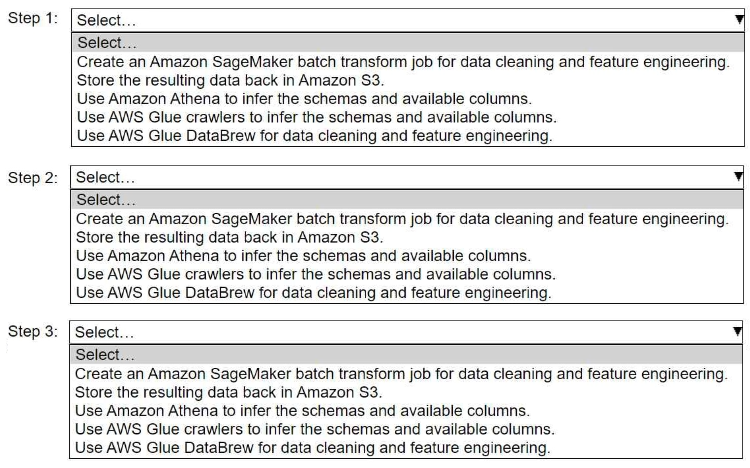
A company stores historical data in .csv files in Amazon S3. Only some of the rows and columns in the .csv files are populated. The columns are not labeled. An ML engineer needs to prepare and store the data so that the company can use the data to train ML models.
Select and order the correct steps from the following list to perform this task. Each step should be selected one time or not at all. (Select and order three.)
• Create an Amazon SageMaker batch transform job for data cleaning and feature engineering.
• Store the resulting data back in Amazon S3.
• Use Amazon Athena to infer the schemas and available columns.
• Use AWS Glue crawlers to infer the schemas and available columns.
• Use AWS Glue DataBrew for data cleaning and feature engineering.
Answer
Use AWS Glue crawlers to infer the schemas and available columns.
Use AWS Glue DataBrew for data cleaning and feature engineering.
Store the resulting data back in Amazon S3.
Detailed Explanation - Requirements Summary
The company has historical .csv files stored in Amazon S3 that contain incomplete data (some rows and columns are empty) and lack labeled columns. The goal is to prepare this raw data so it can be used for training ML models. The data preparation steps should:
Identify and label the data schema (column names, types, and structures).
Clean the data (handling missing values, normalizing formats, and applying transformations).
Store the processed data back in S3 for ML model training.
AWS provides multiple services for data preparation, but selecting the right ones requires understanding their specific roles and capabilities.
Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Use AWS Glue crawlers to infer the schemas and available columns:
AWS Glue is a fully managed ETL service that can automatically infer the schema of structured and semi-structured data.
AWS Glue Crawlers scan files in Amazon S3, detect column structures, and generate a schema in the AWS Glue Data Catalog.
Since the
.csvfiles lack labeled columns, this step is critical for structuring the data correctly before cleaning.
Use AWS Glue DataBrew for data cleaning and feature engineering:
AWS Glue DataBrew is a visual data preparation tool that allows users to apply transformations like:
Handling missing values.
Standardizing formats (e.g., converting dates to a common format).
Removing duplicates and normalizing column names.
This step ensures that the dataset is clean and usable for machine learning.
Store the resulting data back in Amazon S3:
The processed data needs to be stored in Amazon S3, where it can be accessed for training ML models using Amazon SageMaker or other ML services.
AWS services such as SageMaker and Athena can work with structured data stored in S3.
Key Differentiators for Option
AWS Glue Crawlers vs. Amazon Athena for Schema Inference:
Glue Crawlers automate schema discovery and create metadata catalogs.
Athena is primarily a SQL query engine and does not automatically generate schemas.
AWS Glue DataBrew vs. SageMaker Batch Transform for Data Cleaning:
DataBrew is designed for data preparation, including transformations and cleaning.
SageMaker Batch Transform is used for batch inference, not data cleaning.
Amazon S3 as a Storage Layer:
Amazon S3 is the most suitable choice for storing cleaned data, as it integrates with AWS ML services.
Analysis of Incorrect Options
Use Amazon Athena to infer the schemas and available columns:
Athena is an interactive query service that allows running SQL queries on data stored in S3.
However, Athena does not infer schema automatically—schema must be defined manually or through AWS Glue Crawlers.
Create an Amazon SageMaker batch transform job for data cleaning and feature engineering:
SageMaker Batch Transform is used to apply ML models for inference, not for data preprocessing.
It assumes that the data is already cleaned and structured, making it unsuitable for this task.
Conclusion
To prepare raw .csv data for ML training, the best approach is to first infer the schema using AWS Glue Crawlers, clean and transform the data with AWS Glue DataBrew, and finally store the processed data back in Amazon S3. This workflow ensures that the data is structured, clean, and ready for ML training while leveraging AWS-native tools optimized for large-scale data processing.
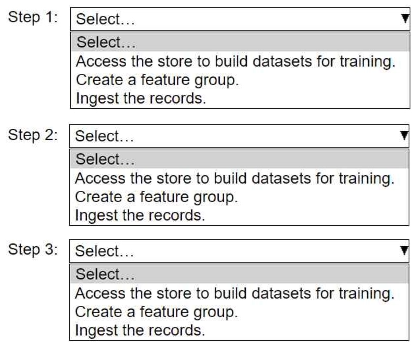
An ML engineer needs to use Amazon SageMaker Feature Store to create and manage features to train a model.
Select and order the steps from the following list to create and use the features in Feature Store. Each step should be selected one time. (Select and order three.)
• Access the store to build datasets for training.
• Create a feature group.
• Ingest the records.
Answer
Create a feature group.
Ingest the records.
Access the store to build datasets for training.
Detailed Explanation - Requirements Summary
Amazon SageMaker Feature Store is a purpose-built repository to manage, store, and retrieve features for machine learning (ML) models. The goal is to create a structured and reusable feature store that can be accessed efficiently during both training and inference. The key steps involved in setting up and using SageMaker Feature Store are:
Defining a feature group to organize and manage related features.
Ingesting data into the feature store.
Accessing the stored features to build datasets for model training.
These steps ensure that ML models can utilize well-defined and versioned feature sets during training and inference.
Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Create a feature group:
A Feature Group is a logical grouping of features in SageMaker Feature Store, similar to a table in a database.
It defines the schema, including feature names, data types, and identifiers.
Feature groups can be stored in two modes:
Online store: For real-time low-latency access.
Offline store: For batch processing and training.
This step is fundamental because it establishes the structure in which feature data will be stored.
Ingest the records:
Once the feature group is created, feature data must be ingested into the store.
Features can be updated in real-time (online store) or in batches (offline store).
Ingestion ensures that feature values are available for training and inference.
This step includes timestamping, ensuring that the latest feature values are always accessible for training.
Access the store to build datasets for training:
After features are stored, they need to be retrieved for model training.
This is done by querying the offline store, which maintains historical feature versions.
The accessed feature dataset can be used to train models in Amazon SageMaker or other ML frameworks.
Key Differentiators for Option
Creating a Feature Group First
A feature group provides the structure for feature data.
Without defining it, there is no organized place to ingest or retrieve features.
Ingesting Records Second
Data must be ingested before it can be accessed for training.
This step ensures that SageMaker Feature Store has relevant data to use.
Accessing the Store Last
Once features are ingested, they can be queried from the offline store for training datasets.
Analysis of Incorrect Options
Access the store to build datasets for training (as the first step):
Incorrect because there are no features stored at this stage.
The feature group must be created and populated before accessing it.
Ingest the records (before creating a feature group):
Incorrect because there is no defined structure to store the features.
Without a feature group, SageMaker Feature Store does not know how to handle ingested data.
Conclusion
The correct order for using Amazon SageMaker Feature Store is:
Create a feature group to define the schema and structure.
Ingest the records to populate the feature store with data.
Access the store to build datasets for training by retrieving features from the offline store.
This workflow ensures an organized, efficient, and scalable feature management process, enabling high-quality ML model training.

A company wants to host an ML model on Amazon SageMaker. An ML engineer is configuring a continuous integration and continuous delivery (Cl/CD) pipeline in AWS CodePipeline to deploy the model. The pipeline must run automatically when new training data for the model is uploaded to an Amazon S3 bucket.
Select and order the pipeline's correct steps from the following list. Each step should be selected one time or not at all. (Select and order three.)
• An S3 event notification invokes the pipeline when new data is uploaded.
• S3 Lifecycle rule invokes the pipeline when new data is uploaded.
• SageMaker retrains the model by using the data in the S3 bucket.
• The pipeline deploys the model to a SageMaker endpoint.
• The pipeline deploys the model to SageMaker Model Registry.
Answer
An S3 event notification invokes the pipeline when new data is uploaded.
SageMaker retrains the model by using the data in the S3 bucket.
The pipeline deploys the model to SageMaker Model Registry.
Detailed Explanation - Requirements Summary
The company is setting up a CI/CD pipeline in AWS CodePipeline to automate ML model training and deployment. The goal is to trigger the pipeline when new training data is uploaded, retrain the model with this data, and then manage the model lifecycle efficiently.
The required steps must ensure:
Automatic pipeline execution when new data arrives
Model retraining using the latest dataset
Model versioning and storage for controlled deployments
This setup enables continuous model training and deployment with minimal manual intervention.
Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
An S3 event notification invokes the pipeline when new data is uploaded.
Why? The CI/CD pipeline should start automatically when new training data is added.
How? Amazon S3 event notifications can send triggers to AWS services like AWS Lambda, Amazon SNS, or AWS CodePipeline.
Alternative? AWS Step Functions could also orchestrate this workflow, but S3 event notifications are a standard trigger mechanism for ML pipelines.
SageMaker retrains the model by using the data in the S3 bucket.
Why? The model needs to be retrained with the new dataset before deployment.
How? SageMaker Training Jobs can be triggered by CodePipeline to use the updated dataset from S3.
Alternative? AWS Step Functions could manage this step, but CodePipeline is commonly used for CI/CD automation.
The pipeline deploys the model to SageMaker Model Registry.
Why? Model Registry is essential for model versioning, tracking, and governance before deployment.
How? SageMaker Model Registry stores different versions of the model, enabling model selection for production deployment.
Alternative? Direct deployment to a SageMaker endpoint is an option, but Model Registry allows better control over model promotions and rollback strategies.
Key Differentiators for Option
S3 Event Notification vs. S3 Lifecycle Rule
S3 Event Notification triggers pipelines instantly.
S3 Lifecycle Rules are used for managing storage (e.g., moving old data to Glacier) and cannot invoke pipelines.
Deploying to SageMaker Model Registry vs. SageMaker Endpoint
SageMaker Model Registry is used for storing, versioning, and managing models.
Deploying to a SageMaker Endpoint is done only when a model is approved for production use.
The CI/CD pipeline should store the retrained model first, and a separate process can decide when to deploy.
Analysis of Incorrect Options
S3 Lifecycle rule invokes the pipeline when new data is uploaded.
Incorrect because:
S3 Lifecycle rules are used to move, archive, or delete objects, not trigger events.
Lifecycle rules cannot start a CodePipeline or SageMaker job.
The pipeline deploys the model to a SageMaker endpoint.
Incorrect because:
CI/CD pipelines typically first store models in SageMaker Model Registry to manage versions.
Deployment to an endpoint should be a controlled process, often requiring approval or testing before production deployment.
Conclusion
The best approach for automating model retraining and management using AWS CodePipeline and SageMaker is:
Trigger the pipeline using S3 event notifications.
Retrain the model using updated data from S3.
Store the model in SageMaker Model Registry for versioning and controlled deployment.
This workflow ensures continuous and automated model training while maintaining proper governance over deployed models.
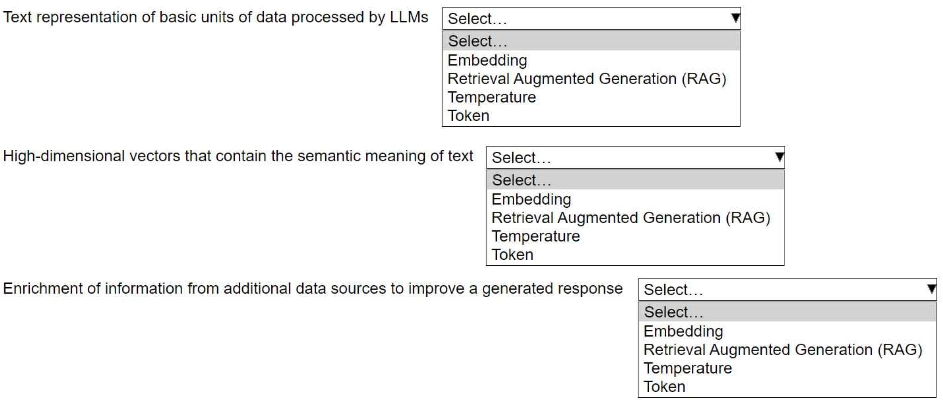
An ML engineer is building a generative AI application on Amazon Bedrock by using large language models (LLMs).
Select the correct generative AI term from the following list for each description. Each term should be selected one time or not at all. (Select three.)
• Embedding
• Retrieval Augmented Generation (RAG)
• Temperature
• Token
Answer
Text representation of basic units of data processed by LLMs → Token
High-dimensional vectors that contain the semantic meaning of text → Embedding
Enrichment of information from additional data sources to improve a generated response → Retrieval Augmented Generation (RAG)
Detailed Explanation - Requirements Summary
The ML engineer is working with Amazon Bedrock and LLMs for a generative AI application. The task is to correctly match key generative AI terms with their respective definitions.
LLMs process text data in the form of tokens.
Semantic representations of text are stored as embeddings.
Retrieval Augmented Generation (RAG) enhances responses by incorporating external knowledge sources.
These concepts are critical for improving text generation quality, retrieval efficiency, and model interpretability in AI applications.
Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Token - Text representation of basic units of data processed by LLMs
What it does:
A token is a basic unit of text used by LLMs.
It can be a word, subword, or character, depending on the tokenizer.
Why it fits:
LLMs do not process entire sentences at once; they convert text into a sequence of tokens before processing.
Embedding - High-dimensional vectors that contain the semantic meaning of text
What it does:
Embeddings are numerical representations of text that capture meaning and relationships.
They map words or sentences to high-dimensional vector spaces.
Why it fits:
LLMs and search engines use embeddings for semantic search, clustering, and recommendation systems.
Retrieval Augmented Generation (RAG) - Enrichment of information from additional data sources to improve a generated response
What it does:
RAG improves LLM outputs by retrieving relevant information from external sources (e.g., databases, documents, APIs).
It combines retrieval-based search with generative AI for more accurate and contextually rich responses.
Why it fits:
Many enterprise LLM applications use RAG to ensure up-to-date responses instead of relying only on pretrained data.
Key Differentiators for Option
Token vs. Embedding:
A token is a unit of text (e.g., "dog" → token).
An embedding is a vector representing meaning (e.g., "dog" → [1.2, 0.5, -0.7]).
RAG vs. Temperature:
RAG improves model output by fetching relevant information from external knowledge sources.
Temperature controls randomness in text generation (lower = more deterministic, higher = more creative).
Analysis of Incorrect Options
Temperature (Incorrect)
Why it doesn’t fit?
Temperature controls randomness in generated text but is not related to retrieving external data.
Where is it used?
A lower temperature (e.g., 0.2) makes responses more predictable.
A higher temperature (e.g., 1.0) adds diversity and randomness.
Token for High-dimensional vectors (Incorrect)
Why it doesn’t fit?
Tokens represent textual units, but do not capture relationships or semantic meaning.
Correct term: Embeddings are used for this purpose.
Conclusion
The correct matches for each description are:
Token → Smallest unit of text processed by LLMs.
Embedding → High-dimensional vector representation of text meaning.
Retrieval Augmented Generation (RAG) → Enhancing responses with additional retrieved data.
This mapping ensures an accurate conceptual understanding of LLM processing, vectorization, and retrieval techniques in Amazon Bedrock.

An ML engineer is working on an ML model to predict the prices of similarly sized homes. The model will base predictions on several features The ML engineer will use the following feature engineering techniques to estimate the prices of the homes:
• Feature splitting
• Logarithmic transformation
• One-hot encoding
• Standardized distribution
Select the correct feature engineering techniques for the following list of features. Each feature engineering technique should be selected one time or not at all (Select three.)
Answer
City (name) → One-hot encoding
Type_year (type of home and year the home was built) → Feature splitting
Size of the building (square feet or square meters) → Logarithmic transformation
Detailed Explanation - Requirements Summary
The ML engineer is working on a home price prediction model, requiring proper feature engineering techniques to handle different types of data:
Categorical data (City name) needs encoding for machine learning models.
Composite features (Type and year built) should be split into separate features.
Numeric features with large ranges (Size of the building) benefit from transformations like log scaling to improve model stability.
Each feature requires a specific transformation to ensure optimal ML model performance.
Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
City (name) → One-hot encoding
What it does:
Converts categorical variables (e.g., "New York", "Los Angeles") into binary vectors.
Why it fits:
City names are nominal categories with no inherent order, so one-hot encoding is the best choice.
Example Transformation:
Original:
"New York", "Los Angeles", "Chicago"One-hot encoded:
[1,0,0],[0,1,0],[0,0,1]
Type_year (type of home and year the home was built) → Feature splitting
What it does:
Splits a composite feature (e.g., "Single Family, 1995") into two distinct features: home type and year built.
Why it fits:
Separating categorical and numerical values improves model interpretability.
Example Transformation:
Original:
"Apartment, 2010"Split into:
"Apartment"(categorical) and2010(numerical)
Size of the building (square feet or square meters) → Logarithmic transformation
What it does:
Applies a log transformation to reduce skewness in numeric data.
Why it fits:
Home sizes vary widely (e.g., 500 sq ft vs. 5000 sq ft), and a log transformation helps normalize the distribution.
Example Transformation:
Original:
500, 1000, 5000Log Transformed:
log(500) ≈ 6.2, log(1000) ≈ 6.9, log(5000) ≈ 8.5
Key Differentiators for Option
One-hot encoding vs. Feature splitting:
One-hot encoding is for pure categorical data.
Feature splitting is for composite features containing multiple attributes.
Logarithmic transformation vs. Standardized distribution:
Log transformation reduces the impact of outliers in skewed numerical data.
Standardized distribution scales numerical features to a mean of 0 and standard deviation of 1, but doesn’t address skewness.
Analysis of Incorrect Options
Feature splitting for City (Incorrect)
Why it doesn’t fit?
Cities are not composite attributes needing splitting.
Correct choice: One-hot encoding because "New York" vs. "Los Angeles" is a categorical distinction.
Standardized distribution for Size of the building (Incorrect)
Why it doesn’t fit?
Standardization adjusts the scale but does not correct data skew (large homes vs. small homes).
Correct choice: Logarithmic transformation better handles extreme size differences.
One-hot encoding for Type_year (Incorrect)
Why it doesn’t fit?
The year built is numerical and should not be encoded as a category.
Correct choice: Feature splitting separates "Type" (categorical) from "Year" (numerical).
Conclusion
The correct feature engineering techniques for the dataset are:
One-hot encoding for city names (categorical variable).
Feature splitting for type and year built (composite feature).
Logarithmic transformation for building size (numeric variable with large variance).
Using these methods ensures better model interpretability, reduced skewness, and improved prediction accuracy for the home pricing model.
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model's algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
Which AWS service or feature can aggregate the data from the various data sources?
A. Amazon EMR Spark jobs
B. Amazon Kinesis Data Streams
C. Amazon DynamoDB
D. AWS Lake Formation
Answer:
D. AWS Lake Formation
---
### Detailed Explanation
#### Requirements Summary
1. Aggregate Data from Multiple Sources: Combine transaction logs (Amazon S3), customer profiles (Amazon S3), and on-premises MySQL tables into a unified dataset.
2. Class Imbalance & Feature Engineering: While not directly addressed by aggregation, centralized data is critical for preprocessing.
---
### Analysis of the Correct Answer (Option D)
##### What It Does
- AWS Lake Formation simplifies building and managing a data lake by aggregating structured/unstructured data from diverse sources (S3, databases, on-premises systems) into a centralized repository (e.g., Amazon S3).
- Key Features:
- Crawlers: Automatically discover and catalog data from S3 and MySQL (via AWS Glue connectors).
- ETL Jobs: Transform and merge data using AWS Glue.
- Centralized Permissions: Securely manage access across datasets.
##### Why It Meets the Requirements
1. Multi-Source Aggregation:
- S3 Integration: Directly ingest transaction logs and customer profiles.
- On-Premises MySQL: Use AWS Glue JDBC connectors to pull data into the lake.
2. Unified Data Preparation:
- Clean, deduplicate, and merge datasets in a single location for ML training.
3. Security:
- Lake Formation enforces fine-grained access controls (e.g., column-level permissions) on aggregated data.
---
### Key Differentiators for Option D
1. Purpose-Built for Data Lakes:
- Lake Formation is designed to unify disparate data sources into a governed, queryable repository.
2. Automation:
- Glue crawlers auto-detect schemas, reducing manual effort to structure data.
3. Scalability:
- Handles large volumes of data across hybrid (cloud + on-premises) environments.
---
### Analysis of Incorrect Options
##### Option A: Amazon EMR Spark Jobs
- Problem:
- Manual Coding Required: While EMR can process data from S3 and MySQL via Spark, it requires writing custom jobs to extract, transform, and join datasets.
- Operational Overhead: Managing clusters and ETL pipelines adds complexity compared to Lake Formation’s managed workflows.
##### Option B: Amazon Kinesis Data Streams
- Problem:
- Real-Time Focus: Kinesis streams data in real time (e.g., clickstreams), which is irrelevant for batch aggregation of existing S3 files and MySQL tables.
##### Option C: Amazon DynamoDB
- Problem:
- NoSQL Database Use Case: DynamoDB is optimized for low-latency transactional workloads, not batch data aggregation or large-scale ML datasets.
---
### Conclusion
AWS Lake Formation (D) is the optimal choice for aggregating data from S3 and on-premises MySQL into a centralized, governed data lake. It automates schema discovery, ETL, and access controls, enabling the ML engineer to focus on resolving class imbalance and feature interdependencies with a unified dataset. Other options either require manual coding (A), address unrelated use cases (B, C), or lack native hybrid data integration.
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model's algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
After the data is aggregated, the ML engineer must implement a solution to automatically detect anomalies in the data and to visualize the result.
Which solution will meet these requirements?
A. Use Amazon Athena to automatically detect the anomalies and to visualize the result.
B. Use Amazon Redshift Spectrum to automatically detect the anomalies. Use Amazon QuickSight to visualize the result.
C. Use Amazon SageMaker Data Wrangler to automatically detect the anomalies and to visualize the result.
D. Use AWS Batch to automatically detect the anomalies. Use Amazon QuickSight to visualize the result.
Answer:
C. Use Amazon SageMaker Data Wrangler to automatically detect the anomalies and to visualize the result.
---
### Detailed Explanation
#### Requirements Summary
1. Automated Anomaly Detection: Identify outliers or anomalies in the aggregated dataset.
2. Visualization: Generate insights to understand anomalies.
3. Integration with Aggregated Data: Work with data already unified from S3 and MySQL.
---
### Analysis of the Correct Answer (Option C)
##### What It Does
- Amazon SageMaker Data Wrangler provides a low-code interface for data preparation, including built-in anomaly detection and visualization.
- Key Features:
- Outlier Detection: Uses statistical methods (e.g., Interquartile Range, Z-score) to flag anomalies.
- Visual Analysis: Generates histograms, scatter plots, and heatmaps to highlight anomalies.
- Integration: Directly processes data from S3 or Lake Formation.
##### Why It Meets the Requirements
1. Automated Anomaly Detection:
- Prebuilt transforms like Find Outliers automatically identify anomalies in features.
- Supports custom thresholds and rules for fraud-specific patterns.
2. Visualization:
- In-app visualizations (e.g., box plots, distribution charts) show detected anomalies.
- Exports cleaned data for downstream ML training.
3. End-to-End Workflow:
- Integrates with SageMaker Pipelines for automated retraining and deployment.
---
### Key Differentiators for Option C
1. Purpose-Built for ML Data Prep:
- Combines anomaly detection and visualization in a single tool, tailored for ML workflows.
2. Low-Code Automation:
- No need to write custom scripts or manage infrastructure (unlike AWS Batch).
3. SageMaker Ecosystem Integration:
- Seamlessly connects to SageMaker training jobs and model registry.
---
### Analysis of Incorrect Options
##### Option A: Amazon Athena
- Problem:
- Ad-Hoc Query Tool: Athena requires manual SQL queries to detect anomalies, lacking automation.
- No Native Visualization: Athena outputs tabular results; visualization would require separate tools.
##### Option B: Amazon Redshift Spectrum + QuickSight
- Problem:
- Complex Setup: Redshift Spectrum requires defining external tables and writing SQL/ML queries for anomaly detection.
- No Native Anomaly Detection: QuickSight visualizes results but doesn’t automate detection.
##### Option D: AWS Batch + QuickSight
- Problem:
- Manual Coding: Requires writing custom anomaly detection logic (e.g., Python scripts) and managing Batch jobs.
- Disconnected Workflow: Anomaly detection and visualization are separate steps, increasing operational overhead.
---
### Conclusion
Option C is the only solution that automates anomaly detection and visualization within a unified, ML-focused tool. SageMaker Data Wrangler’s built-in transforms and visualizations eliminate manual coding, enabling the engineer to quickly address data quality issues and improve model performance. Other options lack integration, automation, or require fragmented workflows.
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model's algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
The training dataset includes categorical data and numerical data. The ML engineer must prepare the training dataset to maximize the accuracy of the model.
Which action will meet this requirement with the LEAST operational overhead?
A. Use AWS Glue to transform the categorical data into numerical data.
B. Use AWS Glue to transform the numerical data into categorical data.
C. Use Amazon SageMaker Data Wrangler to transform the categorical data into numerical data.
D. Use Amazon SageMaker Data Wrangler to transform the numerical data into categorical data.
Answer:
C. Use Amazon SageMaker Data Wrangler to transform the categorical data into numerical data.
---
### Detailed Explanation
#### Requirements Summary
1. Prepare Training Data: Convert categorical data to numerical format for ML algorithms.
2. Maximize Model Accuracy: Address class imbalance and feature interdependencies.
3. Minimize Operational Overhead: Avoid complex scripting or infrastructure management.
---
### Analysis of the Correct Answer (Option C)
##### What It Does
- Amazon SageMaker Data Wrangler provides a low-code/no-code interface to automatically encode categorical data (e.g., one-hot encoding, ordinal encoding) into numerical features.
- Key Features:
- Built-in Transforms: Preconfigured recipes for categorical encoding (e.g., one-hot, frequency, target encoding).
- Visual Workflow: Drag-and-drop transformations with real-time visual feedback.
- Integration: Directly processes data from S3 or Lake Formation and exports to SageMaker training jobs.
##### Why It Meets the Requirements
1. Categorical-to-Numerical Conversion:
- ML algorithms (e.g., XGBoost, neural networks) require numerical input to capture patterns effectively.
- Techniques like one-hot encoding resolve interdependencies between categorical features.
2. Operational Efficiency:
- No need to write custom ETL code (unlike AWS Glue). Prebuilt transforms reduce setup time.
3. Accuracy Improvements:
- Proper encoding helps models leverage feature relationships, mitigating class imbalance effects.
---
### Key Differentiators for Option C
1. ML-Focused Tool:
- Data Wrangler is purpose-built for ML data prep, with optimizations for feature engineering.
2. Low Overhead:
- Managed service with no infrastructure to provision. Integrates seamlessly with SageMaker.
3. Automation:
- Reusable workflows for consistent preprocessing across experiments.
---
### Analysis of Incorrect Options
##### Option A: AWS Glue for Categorical-to-Numerical
- Problem:
- Manual Scripting: Requires writing PySpark/Scala code to implement encoders, increasing development time.
- No ML-Specific Optimizations: Glue is a general-purpose ETL tool, lacking built-in ML feature engineering.
##### Option B/D: Converting Numerical to Categorical
- Problem:
- Counterproductive: Most algorithms perform better with numerical data. Discretizing numerical features (e.g., binning) risks losing critical patterns.
##### Option D: AWS Glue for Numerical-to-Categorical
- Same Issues as B: Converts data in the wrong direction, harming model accuracy.
---
### Conclusion
Option C is the only solution that efficiently converts categorical data to numerical while minimizing operational overhead. SageMaker Data Wrangler’s prebuilt transforms and visual interface enable rapid, accurate feature engineering, directly addressing the model’s inability to capture underlying patterns. AWS Glue (A) requires manual coding, and converting numerical to categorical (B/D) degrades model performance.
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model's algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
Before the ML engineer trains the model, the ML engineer must resolve the issue of the imbalanced data.
Which solution will meet this requirement with the LEAST operational effort?
A. Use Amazon Athena to identify patterns that contribute to the imbalance. Adjust the dataset accordingly.
B. Use Amazon SageMaker Studio Classic built-in algorithms to process the imbalanced dataset.
C. Use AWS Glue DataBrew built-in features to oversample the minority class.
D. Use the Amazon SageMaker Data Wrangler balance data operation to oversample the minority class.
Answer:
D. Use the Amazon SageMaker Data Wrangler balance data operation to oversample the minority class.
---
### Detailed Explanation
#### Requirements Summary
1. Resolve Class Imbalance: Address the skewed distribution of fraud (minority) vs. non-fraud (majority) classes.
2. Minimal Operational Effort: Avoid manual scripting or complex configurations.
---
### Analysis of the Correct Answer (Option D)
##### What It Does
- Amazon SageMaker Data Wrangler includes a Balance Data operation that automatically oversamples the minority class (e.g., fraud cases) using techniques like Synthetic Minority Oversampling Technique (SMOTE) or random duplication.
##### Why It Meets the Requirements
1. Automated Class Balancing:
- A single click/configuration applies oversampling, ensuring the model trains on a balanced dataset.
- No need to manually code resampling logic or manage data pipelines.
2. Integration with SageMaker:
- Directly processes data from S3 or Lake Formation and exports to SageMaker training jobs.
3. Operational Simplicity:
- Managed UI-driven workflow eliminates coding, infrastructure setup, or dependency management.
---
### Key Differentiators for Option D
1. Built-In, ML-Optimized Solution:
- Data Wrangler is purpose-built for ML data preparation, with balancing tailored to improve model performance.
2. Low-Code Efficiency:
- Preconfigured balancing methods reduce the risk of errors compared to manual scripting (e.g., AWS Glue).
---
### Analysis of Incorrect Options
##### Option A: Amazon Athena
- Problem:
- Manual Analysis Only: Athena identifies imbalance via SQL queries but requires custom code to resample data (e.g., rewriting datasets in S3).
- No Automation: Operational effort increases due to manual dataset adjustments.
##### Option B: SageMaker Built-In Algorithms
- Problem:
- No Preprocessing: Built-in algorithms (e.g., XGBoost) do not automatically balance data. Some support class weights, but this only adjusts loss functions—it does not fix imbalanced input data.
- Partial Solution: Class weighting requires manual hyperparameter tuning and is less effective than oversampling.
##### Option C: AWS Glue DataBrew
- Problem:
- No Native Balancing: DataBrew focuses on cleaning (e.g., missing values, outliers) but lacks built-in oversampling/undersampling features.
- Custom Effort: Resampling would require writing custom transforms, increasing operational overhead.
---
### Conclusion
Option D is the only solution that automates class balancing with minimal effort. SageMaker Data Wrangler’s "Balance Data" operation directly addresses the root cause of class imbalance, enabling the model to learn fraud patterns effectively. Other options either lack automation (A, C) or fail to resolve the data imbalance (B).
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model's algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
The ML engineer needs to use an Amazon SageMaker built-in algorithm to train the model.
Which algorithm should the ML engineer use to meet this requirement?
A. LightGBM
B. Linear learner
C. К-means clustering
D. Neural Topic Model (NTM)
Answer:
A. LightGBM
---
### Detailed Explanation
#### Requirements Summary
1. Class Imbalance: The fraud detection dataset has a skewed distribution (e.g., few fraud cases vs. many non-fraud).
2. Feature Interdependencies: Complex relationships between features that the model must capture.
3. Use SageMaker Built-in Algorithm: Leverage AWS-native solutions to minimize custom code.
---
### Analysis of the Correct Answer (Option A)
##### What It Does
- LightGBM (Gradient Boosting Machine) is a SageMaker built-in algorithm optimized for classification tasks.
- Key Features:
- Handles Class Imbalance: Automatically adjusts weights for minority classes (e.g., fraud) via parameters like scale_pos_weight.
- Captures Feature Interactions: Uses gradient-boosted trees to model non-linear relationships and feature interdependencies.
- Efficiency: Faster training and lower memory usage compared to traditional GBM frameworks.
##### Why It Meets the Requirements
1. Class Imbalance Mitigation:
- LightGBM penalizes misclassifications of the minority class more heavily, improving fraud detection recall.
2. Complex Pattern Recognition:
- Decision trees inherently model feature interactions, capturing interdependencies (e.g., transaction amount vs. customer location).
3. SageMaker Integration:
- Preconfigured hyperparameters and one-click deployment reduce operational effort.
---
### Key Differentiators for Option A
1. Optimized for Imbalanced Data:
- LightGBM supports is_unbalance and scale_pos_weight parameters to prioritize minority class accuracy.
2. Tree-Based Architecture:
- Splits data hierarchically, naturally identifying interactions between features (e.g., "high-value transactions from new accounts").
3. Built-In Algorithm:
- No need to install custom libraries or manage dependencies.
---
### Analysis of Incorrect Options
##### Option B: Linear Learner
- Problem:
- Linear Models Struggle with Complexity: Assumes linear relationships between features, failing to capture interdependencies.
- Manual Class Weighting: Requires explicit hyperparameter tuning to address imbalance, increasing effort.
##### Option C: K-Means Clustering
- Problem:
- Unsupervised Use Case: K-means groups unlabeled data, but fraud detection requires supervised learning (labeled fraud/non-fraud).
- Ignores Class Labels: Cannot directly optimize for fraud detection accuracy.
##### Option D: Neural Topic Model (NTM)
- Problem:
- Text/Topic Modeling Focus: NTM analyzes document topics (e.g., LDA alternative), irrelevant for tabular transaction data.
---
### Conclusion
LightGBM (A) is the only SageMaker built-in algorithm that directly addresses class imbalance and feature interdependencies for fraud detection. Its tree-based architecture and built-in imbalance handling outperform linear models (B) and are irrelevant to unsupervised (C) or NLP-focused (D) algorithms. By using LightGBM, the engineer maximizes model accuracy with minimal operational overhead.
A company has deployed an XGBoost prediction model in production to predict if a customer is likely to cancel a subscription. The company uses Amazon SageMaker Model Monitor to detect deviations in the F1 score.
During a baseline analysis of model quality, the company recorded a threshold for the F1 score. After several months of no change, the model's F1 score decreases significantly.
What could be the reason for the reduced F1 score?
A. Concept drift occurred in the underlying customer data that was used for predictions.
B. The model was not sufficiently complex to capture all the patterns in the original baseline data.
C. The original baseline data had a data quality issue of missing values.
D. Incorrect ground truth labels were provided to Model Monitor during the calculation of the baseline.
Answer:
A. Concept drift occurred in the underlying customer data that was used for predictions.
---
### Detailed Explanation
#### Key Requirements & Context
- Problem: The F1 score of an XGBoost model (monitored via SageMaker Model Monitor) dropped significantly after months of stability.
- F1 Score: Measures the balance between precision and recall, critical for imbalanced tasks like subscription churn prediction.
- Baseline Analysis: Model Monitor compares live performance to an initial baseline. A sustained drop suggests a systemic issue post-deployment.
---
### Analysis of the Correct Answer (Option A)
##### What is Concept Drift?
- Definition: Changes in the statistical properties of input data or relationships between features and the target variable over time.
- Example: Customer behavior evolves (e.g., new cancellation reasons emerge, economic shifts alter spending patterns), making the model’s original assumptions outdated.
##### Why It Explains the F1 Score Drop
1. Delayed Impact:
- The model performed well initially because training data matched live data. Over months, gradual drift degraded predictions.
2. F1 Sensitivity:
- F1 depends on both precision and recall. Concept drift can disproportionately affect minority classes (e.g., cancellations), reducing recall or precision.
3. Model Monitor Detection:
- Model Monitor flags deviations from the baseline F1 threshold, aligning with the observed drop.
---
### Key Differentiators for Option A
- Temporal Pattern: The F1 score was stable initially but declined later, matching the gradual onset of concept drift.
- Real-World Dynamics: Subscription behaviors naturally evolve due to external factors (e.g., market trends, competitor actions).
---
### Analysis of Incorrect Options
##### Option B: Model Complexity
- Issue:
- If the model was insufficiently complex, poor performance (low F1) would appear immediately, not after months of stability.
- XGBoost is inherently capable of capturing complex patterns via boosted trees.
##### Option C: Missing Values in Baseline Data
- Issue:
- Baseline data quality issues (e.g., missing values) would skew the initial F1 threshold. However, Model Monitor would detect deviations from the start, not after months.
- The problem is a recent decline, not a flawed baseline.
##### Option D: Incorrect Ground Truth Labels in Baseline
- Issue:
- Wrong labels during baseline creation would invalidate the F1 threshold. However, this would cause mismatched monitoring from day one, not a delayed drop.
- Example: If baseline F1 was artificially high due to mislabeled data, live performance would immediately appear worse, not degrade later.
---
### Conclusion
Concept drift (A) is the most plausible explanation. The model’s performance decayed because the relationships between input features (e.g., customer behavior) and the target variable (subscription cancellation) shifted over time. Other options fail to explain the delayed decline in F1 or conflict with the problem’s timeline. To resolve this, the company should retrain the model with recent data and implement continuous monitoring for drift detection.
A company has a team of data scientists who use Amazon SageMaker notebook instances to test ML models. When the data scientists need new permissions, the company attaches the permissions to each individual role that was created during the creation of the SageMaker notebook instance.
The company needs to centralize management of the team's permissions.
Which solution will meet this requirement?
A. Create a single IAM role that has the necessary permissions. Attach the role to each notebook instance that the team uses.
B. Create a single IAM group. Add the data scientists to the group. Associate the group with each notebook instance that the team uses.
C. Create a single IAM user. Attach the AdministratorAccess AWS managed IAM policy to the user. Configure each notebook instance to use the IAM user.
D. Create a single IAM group. Add the data scientists to the group. Create an IAM role. Attach the AdministratorAccess AWS managed IAM policy to the role. Associate the role with the group. Associate the group with each notebook instance that the team uses.
Answer:
A. Create a single IAM role that has the necessary permissions. Attach the role to each notebook instance that the team uses.
---
### Detailed Explanation
#### Requirements Summary
1. Centralize Permissions: Manage permissions for all data scientists’ SageMaker notebook instances from a single location.
2. Minimize Redundancy: Eliminate per-notebook role updates.
---
### Analysis of the Correct Answer (Option A)
##### What It Does
- Single IAM Role: A unified role is created with all required permissions (e.g., S3 access, SageMaker API permissions).
- Role Attachment: This role is assigned to every SageMaker notebook instance used by the data science team.
##### Why It Meets the Requirements
1. Centralized Management:
- Permissions are defined once in the role’s policy. Changes to the role (e.g., adding S3 write access) automatically apply to all notebook instances using it.
2. Scalability:
- New notebook instances inherit the role without requiring individual permission updates.
3. Security:
- Follows AWS best practices by using roles (not users/groups) for resource permissions.
---
### Key Differentiators for Option A
1. Role-Based Access Control (RBAC):
- IAM roles are designed to grant permissions to AWS resources (e.g., SageMaker notebooks), unlike groups/users, which manage human/application access.
2. Operational Simplicity:
- No need to manage users, groups, or credentials—only one role is maintained.
---
### Analysis of Incorrect Options
##### Option B: IAM Group Associated with Notebook Instances
- Problem:
- Groups Manage Users, Not Resources: IAM groups organize users (e.g., data scientists) but cannot be directly attached to SageMaker notebook instances.
- No Permission Inheritance: Associating a group with a notebook instance is not a valid AWS configuration.
##### Option C: Shared IAM User with AdministratorAccess
- Problem:
- Security Risk: Sharing a single user with broad permissions violates the principle of least privilege and complicates auditing.
- Not Resource-Focused: Users are for human/application identities, not resources like notebooks.
##### Option D: Group + Role with AdministratorAccess
- Problem:
- Overly Broad Permissions: The AdministratorAccess policy grants excessive privileges, increasing security risks.
- Mismatched Components: Groups manage user permissions, not resource permissions. Associating a role with a group does not automatically grant the role to notebook instances.
---
### Conclusion
Option A is the only solution that centralizes permissions for SageMaker notebook instances using AWS’s native role-based model. By assigning a single IAM role to all notebooks, the company ensures consistent, scalable, and secure permission management. Other options misuse IAM components (B, D) or introduce security risks (C).
An ML engineer needs to use an ML model to predict the price of apartments in a specific location.
Which metric should the ML engineer use to evaluate the model's performance?
A. Accuracy
B. Area Under the ROC Curve (AUC)
C. F1 score
D. Mean absolute error (MAE)
Answer:
D. Mean absolute error (MAE)
---
### Detailed Explanation
#### Requirements Summary
1. Regression Task: Predicting apartment prices (continuous numerical output).
2. Performance Metric: Measure how closely predicted prices align with actual prices.
---
### Analysis of the Correct Answer (Option D)
##### What It Does
- Mean Absolute Error (MAE) calculates the average absolute difference between predicted and actual values.
- Formula:
MAE=n1i=1∑n∣yi−y^i∣
where y i y i = actual price, y ^ i y ^ i = predicted price, and n n = number of samples.
##### Why It Meets the Requirements
1. Regression-Specific:
- MAE is designed for regression tasks (continuous outputs like prices).
2. Interpretability:
- Represents the average error in price units (e.g., "average prediction is off by \$5,000").
3. Robustness:
- Less sensitive to outliers compared to Mean Squared Error (MSE).
---
### Key Differentiators for Option D
- Appropriate for Regression: Unlike classification metrics (A, B, C), MAE directly quantifies prediction errors for numerical targets.
- Alignment with Business Goals: Real estate pricing requires understanding average error magnitude, which MAE provides.
---
### Analysis of Incorrect Options
##### Option A: Accuracy
- Problem:
- Classification Metric: Accuracy measures the percentage of correct class predictions (e.g., spam vs. not spam). Irrelevant for numerical predictions.
##### Option B: AUC-ROC
- Problem:
- Binary Classification Metric: AUC evaluates how well a model distinguishes between two classes (e.g., fraud vs. non-fraud). Does not apply to regression.
##### Option C: F1 Score
- Problem:
- Classification Metric: Combines precision and recall for imbalanced classification tasks. Not applicable to numerical outputs.
---
### Conclusion
MAE (D) is the only metric tailored for regression tasks like apartment price prediction. It quantifies prediction errors in a meaningful, interpretable way, unlike classification metrics (A, B, C). For regression, alternatives like MSE or R² could also be valid, but MAE is the best choice among the given options.
An ML engineer has trained a neural network by using stochastic gradient descent (SGD). The neural network performs poorly on the test set. The values for training loss and validation loss remain high and show an oscillating pattern. The values decrease for a few epochs and then increase for a few epochs before repeating the same cycle.
What should the ML engineer do to improve the training process?
A. Introduce early stopping.
B. Increase the size of the test set.
C. Increase the learning rate.
D. Decrease the learning rate.
Answer:
D. Decrease the learning rate.
---
### Detailed Explanation
#### Problem Analysis
- Symptoms: High and oscillating training/validation losses indicate instability in the training process.
- Root Cause: A learning rate that is too high causes the optimizer to overshoot the optimal solution, leading to erratic updates and unstable convergence.
---
### Why Decreasing the Learning Rate Helps
1. Smoother Convergence:
- A smaller learning rate reduces the step size during gradient descent, allowing the optimizer to approach the loss minimum more carefully.
2. Reduced Oscillations:
- Prevents large parameter updates that cause the loss to "bounce" around instead of steadily decreasing.
3. Mitigates Underfitting:
- While high loss suggests underfitting, oscillations are a stronger indicator of unstable training dynamics (fixed by tuning the learning rate).
---
### Key Differentiators for Option D
- Directly Addresses Oscillations: The cyclical loss pattern is a hallmark of an excessively high learning rate. Decreasing it stabilizes updates.
- Improves Model Fit: A stable learning process allows the model to better minimize training and validation losses.
---
### Analysis of Incorrect Options
##### Option A: Early Stopping
- Issue:
- Early stopping halts training when validation loss increases to prevent overfitting. However, both training and validation losses are high, indicating underfitting or unstable training—not overfitting.
##### Option B: Increase Test Set Size
- Issue:
- A larger test set improves evaluation reliability but does nothing to fix the training process or reduce loss values.
##### Option C: Increase Learning Rate
- Issue:
- A higher learning rate would amplify oscillations, worsening instability and preventing convergence.
---
### Conclusion
Decreasing the learning rate (D) is the most effective action to stabilize training and reduce oscillating losses. This adjustment allows the optimizer to navigate the loss landscape more effectively, improving model performance on both training and test data.
An ML engineer needs to process thousands of existing CSV objects and new CSV objects that are uploaded. The CSV objects are stored in a central Amazon S3 bucket and have the same number of columns. One of the columns is a transaction date. The ML engineer must query the data based on the transaction date.
Which solution will meet these requirements with the LEAST operational overhead?
A. Use an Amazon Athena CREATE TABLE AS SELECT (CTAS) statement to create a table based on the transaction date from data in the central S3 bucket. Query the objects from the table.
B. Create a new S3 bucket for processed data. Set up S3 replication from the central S3 bucket to the new S3 bucket. Use S3 Object Lambda to query the objects based on transaction date.
C. Create a new S3 bucket for processed data. Use AWS Glue for Apache Spark to create a job to query the CSV objects based on transaction date. Configure the job to store the results in the new S3 bucket. Query the objects from the new S3 bucket.
D. Create a new S3 bucket for processed data. Use Amazon Data Firehose to transfer the data from the central S3 bucket to the new S3 bucket. Configure Firehose to run an AWS Lambda function to query the data based on transaction date.
Answer:
A. Use an Amazon Athena CREATE TABLE AS SELECT (CTAS) statement to create a table based on the transaction date from data in the central S3 bucket. Query the objects from the table.
---
### Detailed Explanation
#### Requirements Summary
1. Query CSV Data by Transaction Date: Filter existing and new CSV files stored in S3 using the transaction date column.
2. Minimal Operational Overhead: Avoid complex ETL pipelines, recurring jobs, or manual intervention.
---
### Analysis of the Correct Answer (Option A)
##### What It Does
- Athena CTAS creates a new table in AWS Glue Data Catalog, partitioning the data by transaction date (if specified).
- Query Efficiency: Partitions allow Athena to scan only relevant data during queries, improving performance and cost.
- Serverless & Automated: Athena requires no infrastructure management. New CSV files added to the S3 bucket are automatically included in subsequent queries.
##### Why It Meets the Requirements
1. Centralized Data Access:
- The CTAS table references all CSV files in the central S3 bucket. New files are automatically detected and queried without manual updates.
2. No Ongoing Maintenance:
- Athena’s serverless architecture eliminates the need for job scheduling, cluster management, or code maintenance.
3. Partitioning (Optional):
- If the CTAS statement partitions data by transaction_date, queries filter data at the partition level, reducing scan volume and cost.
---
### Key Differentiators for Option A
- Zero ETL Pipeline: Athena directly queries raw CSV files in S3 without requiring data movement or preprocessing.
- Immediate Query Capability: Once the table is created, ad-hoc or programmatic queries can filter by transaction date using SQL.
---
### Analysis of Incorrect Options
##### Option B: S3 Replication + S3 Object Lambda
- Problem:
- Inefficient for Bulk Queries: Object Lambda transforms data per request, which is impractical for querying thousands of CSV objects.
- Operational Complexity: Replicating data and configuring Lambda functions adds unnecessary steps.
##### Option C: AWS Glue Job + New S3 Bucket
- Problem:
- ETL Overhead: Requires writing and maintaining a Spark job, scheduling it for new data, and managing output buckets.
- Delayed Processing: New data isn’t queryable until the Glue job runs, introducing latency.
##### Option D: Amazon Kinesis Data Firehose + Lambda
- Problem:
- Designed for Streaming: Firehose is unsuitable for batch processing existing S3 data.
- Redundant Data Movement: Copying data to a new bucket adds cost and complexity.
---
### Conclusion
Option A provides the least operational overhead by leveraging Athena’s serverless SQL engine to query CSV data directly in S3. The CTAS statement creates a reusable table that automatically includes new files, enabling efficient filtering by transaction date without ETL pipelines or infrastructure management. Other options introduce unnecessary complexity, latency, or costs.
A company has a large, unstructured dataset. The dataset includes many duplicate records across several key attributes.
Which solution on AWS will detect duplicates in the dataset with the LEAST code development?
A. Use Amazon Mechanical Turk jobs to detect duplicates.
B. Use Amazon QuickSight ML Insights to build a custom deduplication model.
C. Use Amazon SageMaker Data Wrangler to pre-process and detect duplicates.
D. Use the AWS Glue FindMatches transform to detect duplicates.
Answer:
C. Use Amazon SageMaker Data Wrangler to pre-process and detect duplicates.
---
### Detailed Explanation
#### Requirements Summary
1. Detect Duplicates: Identify records with duplicate values across key attributes in a large unstructured dataset.
2. Minimal Code Development: Avoid writing custom scripts or complex ML pipelines.
---
### Analysis of the Correct Answer (Option C)
##### What It Does
- Amazon SageMaker Data Wrangler provides a visual interface to preprocess data, including a deduplication transform that removes duplicate rows based on specified columns (e.g., transaction date, customer ID).
- Key Features:
- No-Code Deduplication: Select the key attributes, apply the "Drop Duplicates" transform, and visualize results.
- Handles Unstructured Data: Works with CSV, JSON, or other formats stored in S3.
- Scalability: Processes large datasets using SageMaker’s managed infrastructure.
##### Why It Meets the Requirements
1. Zero Coding:
- Deduplication is configured via a point-and-click interface, eliminating the need for custom code.
2. Immediate Results:
- Apply transforms and visualize duplicates in real-time within the Data Wrangler UI.
3. Integration:
- Directly connects to S3 and exports cleaned data for downstream tasks.
---
### Key Differentiators for Option C
- UI-Driven Simplicity: Deduplication is a built-in, one-click operation.
- No ML/ETL Overhead: Unlike AWS Glue FindMatches (Option D), no model training or job orchestration is required for exact duplicates.
---
### Analysis of Incorrect Options
##### Option A: Amazon Mechanical Turk
- Problem:
- Manual Effort: Requires human workers to identify duplicates, which is impractical for large datasets and introduces latency.
##### Option B: Amazon QuickSight ML Insights
- Problem:
- Analytics Focus: Designed for business intelligence dashboards, not data preprocessing or deduplication.
##### Option D: AWS Glue FindMatches
- Problem:
- ML Overkill: FindMatches uses machine learning to detect fuzzy duplicates (e.g., typos, variations), requiring training and configuration.
- Code/Setup Overhead: Involves creating Glue jobs and transforms, which is excessive for exact duplicates on key attributes.
---
### Conclusion
Option C provides the least operational effort for detecting exact duplicates across key attributes. Data Wrangler’s visual interface and prebuilt transforms enable rapid deduplication without coding or ML expertise. Other options either rely on manual work (A), serve unrelated purposes (B), or add unnecessary complexity (D).
A company needs to run a batch data-processing job on Amazon EC2 instances. The job will run during the weekend and will take 90 minutes to finish running. The processing can handle interruptions. The company will run the job every weekend for the next 6 months.
Which EC2 instance purchasing option will meet these requirements MOST cost-effectively?
A. Spot Instances
B. Reserved Instances
C. On-Demand Instances
D. Dedicated Instances
Answer:
A. Spot Instances
---
### Detailed Explanation
#### Requirements Summary
1. Cost-Effectiveness: Minimize expenses for a batch job running weekly (90 minutes) over 6 months.
2. Interruption Tolerance: The job can handle instance termination without critical failure.
3. Short-Term Usage: No need for long-term commitments beyond 6 months.
---
### Analysis of the Correct Answer (Option A)
##### Why Spot Instances Are Ideal
- Cost Savings: Spot Instances offer up to 90% discount compared to On-Demand pricing, making them the cheapest option for interruptible workloads.
- Suitability for Short, Interruptible Jobs:
- The job runs for only 90 minutes weekly, reducing the risk of Spot interruptions (AWS provides a 2-minute warning before reclaiming instances).
- If interrupted, the job can restart with minimal impact due to its short runtime.
- No Long-Term Commitment: Unlike Reserved Instances (RIs), Spot Instances require no upfront payment or term commitment, aligning with the 6-month usage window.
---
### Key Differentiators for Option A
- Optimal Cost-Performance Ratio: For interruptible, short-duration batch jobs, Spot Instances provide the lowest cost while meeting functional requirements.
- AWS Best Practice: AWS recommends Spot Instances for fault-tolerant, flexible workloads like batch processing.
---
### Analysis of Incorrect Options
##### Option B: Reserved Instances (RIs)
- Problem:
- Long-Term Commitment: RIs require a 1- or 3-year term, which is unnecessary for a 6-month workload.
- Underutilization: The job runs only 24 times (90 minutes each), leaving RIs idle for >90% of the week, wasting the upfront investment.
##### Option C: On-Demand Instances
- Problem:
- Higher Cost: On-Demand pricing is 3–4x more expensive than Spot for the same instance type.
- No Benefit for Interruptible Workloads: Paying a premium for On-Demand is unjustified when the job can tolerate interruptions.
##### Option D: Dedicated Instances
- Problem:
- Highest Cost: Dedicated Instances are priced for physical server isolation, offering no cost advantage for batch processing.
- Irrelevant Use Case: Isolation is unnecessary here; the focus is cost, not compliance/hardware dedication.
---
### Conclusion
Spot Instances (A) are the most cost-effective choice. They leverage AWS’s unused capacity at minimal cost, perfectly aligning with the job’s short runtime, interruptibility, and 6-month duration. Reserved or On-Demand Instances incur unnecessary expenses, while Dedicated Instances address unrelated needs.
An ML engineer has an Amazon Comprehend custom model in Account A in the us-east-1 Region. The ML engineer needs to copy the model to Account В in the same Region.
Which solution will meet this requirement with the LEAST development effort?
A. Use Amazon S3 to make a copy of the model. Transfer the copy to Account B.
B. Create a resource-based IAM policy. Use the Amazon Comprehend ImportModel API operation to copy the model to Account B.
C. Use AWS DataSync to replicate the model from Account A to Account B.
D. Create an AWS Site-to-Site VPN connection between Account A and Account В to transfer the model.
Answer:
B. Create a resource-based IAM policy. Use the Amazon Comprehend ImportModel API operation to copy the model to Account B.
---
### Detailed Explanation
#### Requirements Summary
1. Cross-Account Copy: Transfer an Amazon Comprehend custom model from Account A to Account B in the same AWS Region (us-east-1).
2. Minimal Development Effort: Avoid manual exports, data transfers, or complex networking setups.
---
### Analysis of the Correct Answer (Option B)
##### What It Does
1. Resource-Based Policy:
- Account A attaches an IAM policy to the Comprehend model, granting Account B permission to access it.
- Example policy:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"AWS": "arn:aws:iam::AccountB-ID:root"},
"Action": "comprehend:ImportModel",
"Resource": "arn:aws:comprehend:us-east-1:AccountA-ID:document-classifier/MODEL_NAME"
}]
}2. ImportModel API:
- Account B calls ImportModel, specifying the source model ARN from Account A. AWS Comprehend handles the copy internally.
##### Why It Meets the Requirements
1. Direct Service Integration:
- Comprehend natively supports cross-account model sharing via IAM policies and ImportModel, requiring no data export/import.
2. No Manual Data Transfer:
- Eliminates the need to download/upload model artifacts (unlike S3 or DataSync).
3. Least Effort:
- Uses AWS-native APIs and policies without custom code, agents, or networking.
---
### Key Differentiators for Option B
- Built-in Cross-Account Sharing: Comprehend’s ImportModel API and resource policies are designed for this exact use case.
- Serverless & Automated: AWS handles the copy process end-to-end.
---
### Analysis of Incorrect Options
##### Option A: Amazon S3 Copy
- Problem:
- Comprehend models are not stored as user-accessible S3 objects. Exporting requires custom scripts (e.g., using DescribeDocumentClassifier and DescribeEndpoint), which adds development effort.
##### Option C: AWS DataSync
- Problem:
- DataSync transfers data between storage systems (e.g., S3, EFS), but Comprehend models are managed by the service and not directly accessible as files.
##### Option D: Site-to-Site VPN
- Problem:
- Overly complex for cross-account resource sharing. VPNs are for network connectivity, not service-level resource transfers.
---
### Conclusion
Option B provides the least development effort by leveraging Amazon Comprehend’s native cross-account sharing capabilities. The combination of resource-based IAM policies and the ImportModel API automates the copy process without manual intervention. Other options require unnecessary steps (A, C) or irrelevant infrastructure (D).
An ML engineer is training a simple neural network model. The ML engineer tracks the performance of the model over time on a validation dataset. The model's performance improves substantially at first and then degrades after a specific number of epochs.
Which solutions will mitigate this problem? (Choose two.)
A. Enable early stopping on the model.
B. Increase dropout in the layers.
C. Increase the number of layers.
D. Increase the number of neurons.
E. Investigate and reduce the sources of model bias.
Answer:
A. Enable early stopping on the model.
B. Increase dropout in the layers.
---
### Detailed Explanation
#### Problem Analysis
The model’s validation performance improves initially but degrades after a specific number of epochs, indicating overfitting. Overfitting occurs when the model memorizes training data noise instead of generalizing patterns.
---
### Why Options A & B Are Correct
#### A. Enable Early Stopping
- What It Does:
Stops training when validation performance (e.g., loss, accuracy) stops improving or starts degrading.
- Why It Works:
- Prevents the model from over-optimizing on training data by halting training at the optimal epoch.
- Directly addresses the observed "performance degradation after a specific epoch."
#### B. Increase Dropout in the Layers
- What It Does:
Randomly deactivates neurons during training, forcing the network to learn redundant representations.
- Why It Works:
- Reduces overfitting by preventing co-adaptation of neurons (reliance on specific features).
- Improves generalization by making the model robust to noise.
---
### Why Other Options Are Incorrect
#### C. Increase the Number of Layers / D. Increase the Number of Neurons
- Problem:
Adding layers/neurons increases model complexity, exacerbating overfitting. This worsens validation performance degradation.
#### E. Investigate and Reduce Model Bias
- Problem:
- Bias relates to underfitting (model cannot learn training data patterns). Here, the issue is variance (overfitting), not bias.
- Reducing bias (e.g., simplifying the model) would worsen underfitting, not resolve overfitting.
---
### Conclusion
Early stopping (A) and increased dropout (B) directly mitigate overfitting by stopping training at the right time and regularizing the model. Other options either worsen overfitting (C, D) or address unrelated issues (E).
A company has a Retrieval Augmented Generation (RAG) application that uses a vector database to store embeddings of documents. The company must migrate the application to AWS and must implement a solution that provides semantic search of text files. The company has already migrated the text repository to an Amazon S3 bucket.
Which solution will meet these requirements?
A. Use an AWS Batch job to process the files and generate embeddings. Use AWS Glue to store the embeddings. Use SQL queries to perform the semantic searches.
B. Use a custom Amazon SageMaker notebook to run a custom script to generate embeddings. Use SageMaker Feature Store to store the embeddings. Use SQL queries to perform the semantic searches.
C. Use the Amazon Kendra S3 connector to ingest the documents from the S3 bucket into Amazon Kendra. Query Amazon Kendra to perform the semantic searches.
D. Use an Amazon Textract asynchronous job to ingest the documents from the S3 bucket. Query Amazon Textract to perform the semantic searches.
Answer:
C. Use the Amazon Kendra S3 connector to ingest the documents from the S3 bucket into Amazon Kendra. Query Amazon Kendra to perform the semantic searches.
---
### Detailed Explanation
#### Requirements Summary
1. Semantic Search: Enable context-aware, natural language queries over text files in S3.
2. AWS Migration: Replace the existing vector database with a managed AWS solution.
3. Minimal Custom Development: Avoid manually managing embeddings or vector search infrastructure.
---
### Analysis of the Correct Answer (Option C)
##### Why Amazon Kendra Fits
- Managed Semantic Search:
- Amazon Kendra is a fully managed enterprise search service that uses machine learning (including embeddings and natural language understanding) to enable semantic search.
- Automatically ingests and indexes documents from S3 via the S3 connector, handling text extraction, embedding generation, and vector storage internally.
- No Vector Database Management:
- Kendra abstracts away the need to manually generate embeddings, manage a vector database, or implement similarity search algorithms.
- Natural Language Queries:
- Users can perform searches using plain language (e.g., "Find documents about cloud migration strategies") without keyword matching.
---
### Key Differentiators for Option C
- End-to-End Solution:
- Kendra handles document ingestion, text processing, embedding generation, and semantic search in a fully managed service.
- Compatibility with RAG:
- While Kendra itself can replace parts of a traditional RAG pipeline, it simplifies the architecture by eliminating the need for custom vector databases.
---
### Analysis of Incorrect Options
##### Option A: AWS Batch + AWS Glue + SQL Queries
- Problem:
- SQL Queries Lack Semantic Capabilities: Structured SQL cannot perform vector similarity searches.
- AWS Glue is Not a Vector Database: Glue is for ETL and metadata cataloging, not storing or querying embeddings.
##### Option B: SageMaker Feature Store + SQL Queries
- Problem:
- Feature Store is for Tabular Data: Designed for structured ML features, not document embeddings or semantic search.
- SQL Queries Are Inadequate: Similar to Option A, SQL cannot execute semantic/vector-based searches.
##### Option D: Amazon Textract
- Problem:
- Textract is for Text Extraction: Extracts text from documents (e.g., PDFs, images) but does not support search or semantic analysis.
---
### Conclusion
Option C is the only solution that provides a managed, end-to-end semantic search capability for text files in S3. Amazon Kendra eliminates the operational burden of managing embeddings and vector databases, directly addressing the requirements for semantic search. Other options misuse services (A, B, D) or fail to deliver semantic functionality.
A company uses Amazon Athena to query a dataset in Amazon S3. The dataset has a target variable that the company wants to predict.
The company needs to use the dataset in a solution to determine if a model can predict the target variable.
Which solution will provide this information with the LEAST development effort?
A. Create a new model by using Amazon SageMaker Autopilot. Report the model's achieved performance.
B. Implement custom scripts to perform data pre-processing, multiple linear regression, and performance evaluation. Run the scripts on Amazon EC2 instances.
C. Configure Amazon Macie to analyze the dataset and to create a model. Report the model's achieved performance.
D. Select a model from Amazon Bedrock. Tune the model with the data. Report the model's achieved performance.
Answer:
A. Create a new model by using Amazon SageMaker Autopilot. Report the model's achieved performance.
---
### Detailed Explanation
#### Requirements Summary
1. Determine Model Predictability: Assess if a model can predict the target variable in an S3 dataset queried via Athena.
2. Minimal Development Effort: Avoid custom coding, manual model selection, or complex workflows.
---
### Analysis of the Correct Answer (Option A)
##### Why SageMaker Autopilot Is Ideal
- Automated Machine Learning (AutoML):
- Autopilot automatically:
- Preprocesses data (handles missing values, encoding, scaling).
- Selects algorithms (e.g., regression, classification) based on the target variable type.
- Trains and tunes multiple models to find the best performer.
- Requires only specifying the S3 data location and target variable.
- Performance Reporting:
- Generates detailed metrics (e.g., RMSE, accuracy) and leaderboard rankings of model candidates.
- Zero Coding:
- Configured via the SageMaker UI or a few API calls, eliminating manual scripting.
---
### Key Differentiators for Option A
- End-to-End Automation: Autopilot handles feature engineering, model selection, and hyperparameter tuning without developer intervention.
- Direct Integration: Works seamlessly with S3 datasets queried via Athena.
---
### Analysis of Incorrect Options
##### Option B: Custom Scripts on EC2
- Problem:
- High Development Effort: Requires writing and maintaining code for preprocessing, model training, and evaluation.
- No Automation: Manual model selection and tuning increase complexity and time.
##### Option C: Amazon Macie
- Problem:
- Irrelevant Service: Macie is for data security and sensitive data discovery, not predictive modeling.
##### Option D: Amazon Bedrock
- Problem:
- Generative AI Focus: Bedrock’s foundation models (e.g., Claude, Llama) are designed for NLP/generative tasks, not structured tabular data prediction.
- Manual Fine-Tuning: Requires adapting a general-purpose model to a specific prediction task, which is more effort than Autopilot’s AutoML.
---
### Conclusion
Option A provides the least development effort by leveraging SageMaker Autopilot’s AutoML capabilities. It automates the entire process of determining model predictability, from preprocessing to performance reporting, without requiring coding or ML expertise. Other options involve irrelevant services (C), excessive manual work (B), or mismatched tools (D).
A company wants to predict the success of advertising campaigns by considering the color scheme of each advertisement. An ML engineer is preparing data for a neural network model. The dataset includes color information as categorical data.
Which technique for feature engineering should the ML engineer use for the model?
A. Apply label encoding to the color categories. Automatically assign each color a unique integer.
B. Implement padding to ensure that all color feature vectors have the same length.
C. Perform dimensionality reduction on the color categories.
D. One-hot encode the color categories to transform the color scheme feature into a binary matrix.
Answer:
D. One-hot encode the color categories to transform the color scheme feature into a binary matrix.
---
### Step-by-Step Explanation
1. Problem Context:
- The goal is to predict advertising campaign success using color scheme (categorical data) as a feature.
- Neural networks require numerical inputs, so categorical data (e.g., "red," "blue") must be encoded.
2. Analysis of Techniques:
- Label Encoding (A): Assigns integers to categories (e.g., red=1, blue=2).
- Issue: Implies an artificial ordinal relationship (e.g., "blue > red"), which is invalid for nominal data like colors.
- Risk: Misleads the model into treating colors as ordered values.
- Padding (B): Ensures uniform vector length (common in NLP for text sequences).
- Irrelevant: Colors are categorical, not sequential, so padding adds no value.
- Dimensionality Reduction (C): Reduces feature count (e.g., PCA).
- Overkill: Colors are low-cardinality (few categories); reducing dimensions risks losing critical color-specific patterns.
- One-Hot Encoding (D): Converts each color to a binary vector (e.g., red=[1,0,0], blue=[0,1,0]).
- Advantages:
- Preserves categorical distinctions without ordinal bias.
- Aligns with neural network architectures by creating independent input nodes for each color.
3. Why One-Hot Encoding is Best:
- Nominal Data Handling: Treats colors as distinct categories, avoiding false ordinal assumptions.
- Model Compatibility: Neural networks learn better from independent binary features than arbitrary integers.
- Simplicity: Straightforward implementation with minimal risk of information loss (unlike dimensionality reduction).
Conclusion: One-hot encoding (D) is the optimal technique to represent color scheme data for a neural network, ensuring accurate and bias-free feature engineering.
A company uses a hybrid cloud environment. A model that is deployed on premises uses data in Amazon 53 to provide customers with a live conversational engine.
The model is using sensitive data. An ML engineer needs to implement a solution to identify and remove the sensitive data.
Which solution will meet these requirements with the LEAST operational overhead?
A. Deploy the model on Amazon SageMaker. Create a set of AWS Lambda functions to identify and remove the sensitive data.
B. Deploy the model on an Amazon Elastic Container Service (Amazon ECS) cluster that uses AWS Fargate. Create an AWS Batch job to identify and remove the sensitive data.
C. Use Amazon Macie to identify the sensitive data. Create a set of AWS Lambda functions to remove the sensitive data.
D. Use Amazon Comprehend to identify the sensitive data. Launch Amazon EC2 instances to remove the sensitive data.
Answer:
C. Use Amazon Macie to identify the sensitive data. Create a set of AWS Lambda functions to remove the sensitive data.
---
### Detailed Explanation
#### Requirements Summary
1. Identify and Remove Sensitive Data: Detect PII (Personally Identifiable Information) or confidential data in Amazon S3.
2. Hybrid Environment: The model runs on-premises but uses S3 data, requiring minimal infrastructure changes.
3. Least Operational Overhead: Avoid managing servers, clusters, or complex pipelines.
---
### Analysis of the Correct Answer (Option C)
##### Why Amazon Macie + AWS Lambda Works
1. Amazon Macie:
- Automated Sensitive Data Discovery: Uses machine learning to detect sensitive data (e.g., credit card numbers, SSNs) in S3 buckets.
- No Custom Development: Fully managed service requiring only bucket configuration.
2. AWS Lambda:
- Serverless Execution: Automatically triggers remediation workflows (e.g., redaction, deletion) when Macie identifies sensitive data.
- Low Overhead: No infrastructure to manage; code runs on-demand.
##### Why It Meets the Requirements
- Minimal Configuration: Macie scans S3 natively, and Lambda integrates seamlessly with Macie findings.
- No Model/Infrastructure Migration: Works with the existing hybrid setup (on-premises model + S3 data).
---
### Key Differentiators for Option C
- Managed Services: Macie and Lambda abstract away infrastructure management, reducing operational effort.
- Hybrid Compatibility: Operates directly on S3 data without requiring changes to the on-premises model.
---
### Analysis of Incorrect Options
##### Option A: SageMaker + Lambda
- Problem:
- Unnecessarily moves the model to SageMaker, disrupting the hybrid setup.
- SageMaker adds complexity for a task focused on data cleansing.
##### Option B: ECS/Fargate + Batch
- Problem:
- Over-engineered for data remediation. Managing ECS clusters and Batch jobs introduces operational overhead.
##### Option D: Comprehend + EC2
- Problem:
- EC2 Overhead: Requires provisioning and managing servers, increasing operational effort.
- Redundant Effort: Amazon Comprehend detects PII but lacks Macie’s specialized focus on data security.
---
### Conclusion
Option C provides the least operational overhead by leveraging Amazon Macie’s automated sensitive data discovery and AWS Lambda’s serverless execution for remediation. This solution aligns with the hybrid environment and avoids unnecessary infrastructure changes. Other options introduce complexity (A, B) or server management (D).
An ML engineer needs to create data ingestion pipelines and ML model deployment pipelines on AWS. All the raw data is stored in Amazon S3 buckets.
Which solution will meet these requirements?
A. Use Amazon Data Firehose to create the data ingestion pipelines. Use Amazon SageMaker Studio Classic to create the model deployment pipelines.
B. Use AWS Glue to create the data ingestion pipelines. Use Amazon SageMaker Studio Classic to create the model deployment pipelines.
C. Use Amazon Redshift ML to create the data ingestion pipelines. Use Amazon SageMaker Studio Classic to create the model deployment pipelines.
D. Use Amazon Athena to create the data ingestion pipelines. Use an Amazon SageMaker notebook to create the model deployment pipelines.
Answer:
B. Use AWS Glue to create the data ingestion pipelines. Use Amazon SageMaker Studio Classic to create the model deployment pipelines.
---
### Detailed Explanation
#### Requirements Summary
1. Data Ingestion Pipelines: Process raw data in Amazon S3 for ML use.
2. Model Deployment Pipelines: Automate deployment of trained models.
3. AWS Integration: Use services that natively handle batch data and ML workflows.
---
### Analysis of the Correct Answer (Option B)
##### Why AWS Glue + SageMaker Studio Classic Works
1. AWS Glue for Data Ingestion:
- Managed ETL Service: Automates batch data ingestion from S3, including crawling, schema discovery, and transformation.
- Scalability: Handles large datasets with serverless Spark jobs, preparing clean data for ML training.
2. SageMaker Studio Classic for Model Deployment:
- End-to-End ML Pipelines: Design, automate, and monitor deployment workflows (e.g., A/B testing, canary deployments).
- Integration: Directly connects to processed data from Glue and deploys models to SageMaker endpoints.
##### Why It Meets the Requirements
- Batch Data Handling: Glue is purpose-built for S3-based ETL, unlike streaming-focused tools (e.g., Firehose) or query services (e.g., Athena).
- Production-Ready Deployment: SageMaker Pipelines (via Studio Classic) ensure repeatable, scalable model deployments.
---
### Key Differentiators for Option B
- Native AWS Integration: Glue and SageMaker are designed to work together, minimizing custom code.
- Managed Services: Both services abstract infrastructure management, reducing operational overhead.
---
### Analysis of Incorrect Options
##### Option A: Data Firehose + SageMaker Studio Classic
- Problem:
- Firehose is for Streaming Data: Designed for real-time ingestion (e.g., IoT, logs), not batch ETL for S3-stored data.
##### Option C: Redshift ML + SageMaker Studio Classic
- Problem:
- Redshift ML Focus: Redshift ML trains models within Redshift using SQL, which is unrelated to data ingestion from S3.
##### Option D: Athena + SageMaker Notebook
- Problem:
- Athena is a Query Tool: Cannot build ETL pipelines; it analyzes data via SQL but does not transform or move it.
- Notebooks ≠ Deployment Pipelines: Notebooks are for experimentation, not automated, production-grade deployment.
---
### Conclusion
Option B is the only solution that pairs AWS Glue (batch ETL for S3 data) with SageMaker Studio Classic (managed ML deployment pipelines). This combination ensures efficient data preparation and robust model deployment with minimal operational effort. Other options misuse services or lack critical functionality.
A company runs an Amazon SageMaker domain in a public subnet of a newly created VPC. The network is configured properly, and ML engineers can access the SageMaker domain.
Recently, the company discovered suspicious traffic to the domain from a specific IP address. The company needs to block traffic from the specific IP address.
Which update to the network configuration will meet this requirement?
A. Create a security group inbound rule to deny traffic from the specific IP address. Assign the security group to the domain.
B. Create a network ACL inbound rule to deny traffic from the specific IP address. Assign the rule to the default network Ad for the subnet where the domain is located.
C. Create a shadow variant for the domain. Configure SageMaker Inference Recommender to send traffic from the specific IP address to the shadow endpoint.
D. Create a VPC route table to deny inbound traffic from the specific IP address. Assign the route table to the domain.
Answer:
B. Create a network ACL inbound rule to deny traffic from the specific IP address. Assign the rule to the default network ACL for the subnet where the domain is located.
---
### Detailed Explanation
#### Requirements Summary
1. Block Specific IP Address: Prevent traffic from a suspicious IP to the SageMaker domain in a public subnet.
2. Network Configuration Update: Adjust VPC-level settings without disrupting legitimate access.
---
### Analysis of the Correct Answer (Option B)
##### Why Network ACLs Are the Right Tool
- Stateless Filtering:
Network ACLs (NACLs) act as a subnet-level firewall and support explicit deny rules. They evaluate inbound/outbound traffic based on ordered rules, making them ideal for blocking specific IPs.
- Public Subnet Focus:
Since the SageMaker domain resides in a public subnet, traffic from the suspicious IP enters through the subnet. Blocking it at the NACL level stops the traffic before it reaches any resources in the subnet.
##### Implementation Steps
1. Add an inbound NACL rule with:
- Rule Number: Lower than the "allow" rules (e.g., 100).
- Type: Custom TCP (or the relevant protocol).
- Source IP: The suspicious IP (e.g., 192.0.2.0/32).
- Action: DENY.
2. Associate this NACL with the public subnet hosting the SageMaker domain.
---
### Why Other Options Fail
##### A. Security Group Inbound Rule to Deny
- Problem:
Security groups are stateful and only support ALLOW rules. They cannot explicitly deny traffic. To block an IP, you would need to remove any existing rules permitting it, which may disrupt legitimate access.
##### C. Shadow Variant + Inference Recommender
- Problem:
Unrelated to network security. Shadow variants test model versions, and Inference Recommender optimizes deployments—neither blocks IPs.
##### D. VPC Route Table
- Problem:
Route tables direct traffic (e.g., to subnets, gateways) but cannot filter or block traffic. They lack deny rules.
---
### Key Takeaway
Network ACLs (Option B) provide the simplest and most effective way to block a specific IP address in a public subnet. NACLs operate at the subnet level, making them the correct tool for this scenario. Security groups (A) cannot deny traffic, and route tables (D) are irrelevant for IP filtering.
A company is gathering audio, video, and text data in various languages. The company needs to use a large language model (LLM) to summarize the gathered data that is in Spanish.
Which solution will meet these requirements in the LEAST amount of time?
A. Train and deploy a model in Amazon SageMaker to convert the data into English text. Train and deploy an LLM in SageMaker to summarize the text.
B. Use Amazon Transcribe and Amazon Translate to convert the data into English text. Use Amazon Bedrock with the Jurassic model to summarize the text.
C. Use Amazon Rekognition and Amazon Translate to convert the data into English text. Use Amazon Bedrock with the Anthropic Claude model to summarize the text.
D. Use Amazon Comprehend and Amazon Translate to convert the data into English text. Use Amazon Bedrock with the Stable Diffusion model to summarize the text.
Answer:
B. Use Amazon Transcribe and Amazon Translate to convert the data into English text. Use Amazon Bedrock with the Jurassic model to summarize the text.
---
### Detailed Explanation
#### Requirements Summary
1. Process Multimodal Data: Handle audio, video, and text in various languages.
2. Summarize Spanish Data: Extract and summarize content from Spanish sources.
3. Minimize Time: Use pre-trained, managed AWS services to avoid training custom models.
---
### Analysis of the Correct Answer (Option B)
##### Why It Works
1. Amazon Transcribe:
- Converts audio/video (including Spanish) to text automatically.
- Supports multilingual transcription, ensuring accurate extraction of Spanish content.
2. Amazon Translate:
- Translates non-Spanish text (if present) to Spanish or converts Spanish text to English (if required for downstream processing).
- Ensures uniformity if the LLM works best in English.
3. Amazon Bedrock (Jurassic Model):
- Jurassic-2 Jumbo Instruct (or similar) supports summarization tasks.
- If Spanish input is required, Jurassic models can process multilingual text, though English translation ensures broader compatibility.
##### Why It’s the Fastest Solution
- No Custom Training: Uses fully managed AWS services (Transcribe, Translate, Bedrock) with pre-trained models.
- End-to-End Pipeline: Automatically handles transcription, translation (if needed), and summarization without infrastructure setup.
---
### Key Differentiators for Option B
- Handles All Data Types:
- Transcribe processes audio/video, while Translate and Bedrock handle text.
- Pre-Built Language Support:
- Transcribe natively supports Spanish transcription; Translate ensures compatibility with English-centric LLMs if required.
---
### Why Other Options Fail
##### Option A: SageMaker Custom Training
- Problem:
- Training models for transcription and summarization is time-consuming and resource-intensive.
##### Option C: Amazon Rekognition + Claude
- Problem:
- Rekognition is for Image/Video Analysis, Not Transcription: Cannot process audio or extract text from video/audio.
- Redundant translation step if data is already in Spanish.
##### Option D: Amazon Comprehend + Stable Diffusion
- Problem:
- Comprehend is for NLP, Not Transcription: Cannot process audio/video.
- Stable Diffusion is for Image Generation: Irrelevant for text summarization.
---
### Conclusion
Option B is the fastest solution. It uses Amazon Transcribe to convert Spanish audio/video to text, Amazon Translate to standardize language (if needed), and Amazon Bedrock’s Jurassic model for summarization. This approach avoids custom model training and leverages AWS’s managed services for rapid deployment.
A financial company receives a high volume of real-time market data streams from an external provider. The streams consist of thousands of JSON records every second.
The company needs to implement a scalable solution on AWS to identify anomalous data points.
Which solution will meet these requirements with the LEAST operational overhead?
A. Ingest real-time data into Amazon Kinesis data streams. Use the built-in RANDOM_CUT_FOREST function in Amazon Managed Service for Apache Flink to process the data streams and to detect data anomalies.
B. Ingest real-time data into Amazon Kinesis data streams. Deploy an Amazon SageMaker endpoint for real-time outlier detection. Create an AWS Lambda function to detect anomalies. Use the data streams to invoke the Lambda function.
C. Ingest real-time data into Apache Kafka on Amazon EC2 instances. Deploy an Amazon SageMaker endpoint for real-time outlier detection. Create an AWS Lambda function to detect anomalies. Use the data streams to invoke the Lambda function.
D. Send real-time data to an Amazon Simple Queue Service (Amazon SQS) FIFO queue. Create an AWS Lambda function to consume the queue messages. Program the Lambda function to start an AWS Glue extract, transform, and load (ETL) job for batch processing and anomaly detection.
Answer:
A. Ingest real-time data into Amazon Kinesis Data Streams. Use the built-in RANDOM_CUT_FOREST function in Amazon Managed Service for Apache Flink to process the data streams and detect data anomalies.
---
### Detailed Explanation
#### Requirements Summary
1. Real-Time Anomaly Detection: Identify outliers in high-volume JSON data streams (thousands of records per second).
2. Scalability: Handle fluctuating data volumes without manual intervention.
3. Minimal Operational Overhead: Avoid infrastructure management, custom model training, or complex orchestration.
---
### Analysis of the Correct Answer (Option A)
##### What It Does
- Amazon Kinesis Data Streams:
- Ingests and durably stores real-time data streams at scale.
- Automatically scales to handle throughput from thousands of JSON records per second.
- Amazon Managed Service for Apache Flink:
- Processes streaming data using SQL or Flink applications.
- Includes built-in machine learning functions like RANDOM_CUT_FOREST, an unsupervised algorithm for anomaly detection.
##### Why It Meets the Requirements
1. Real-Time Processing:
- Flink applications analyze data in-motion as it arrives in Kinesis, enabling sub-second anomaly detection.
2. Built-In Anomaly Detection:
- RANDOM_CUT_FOREST is pre-trained and optimized for streaming data. It assigns an anomaly score to each data point based on its deviation from historical patterns.
3. Scalability:
- Kinesis scales horizontally to handle data volume spikes. Managed Flink automatically provisions compute resources.
4. Zero Infrastructure Management:
- Both services are fully managed, eliminating server provisioning, patching, or cluster tuning.
---
### Key Differentiators for Option A
1. End-to-End Managed Services:
- Kinesis and Flink abstract away infrastructure, allowing focus on anomaly detection logic.
2. No Custom ML Development:
- RANDOM_CUT_FOREST requires no model training, hyperparameter tuning, or endpoint deployment.
3. Cost Efficiency:
- Pay-per-use pricing for Kinesis (shard hours) and Flink (KPU hours) aligns with variable data volumes.
---
### Analysis of Incorrect Options
##### Option B: SageMaker Endpoint + Lambda
- Problem:
- Latency and Complexity:
- SageMaker real-time endpoints require model deployment, training, and ongoing maintenance.
- Lambda functions (limited to 15-minute executions) are ill-suited for continuous stream processing.
- Operational Overhead:
- Coordinating Kinesis, Lambda, and SageMaker introduces orchestration complexity.
##### Option C: Kafka on EC2 + SageMaker
- Problem:
- Self-Managed Kafka Clusters:
- EC2-based Kafka requires manual scaling, fault tolerance, and monitoring, increasing operational burden.
- Redundant Effort:
- SageMaker endpoints add unnecessary ML overhead when a built-in algorithm exists.
##### Option D: SQS FIFO + Glue ETL
- Problem:
- Batch-Oriented Processing:
- Glue ETL jobs run in batches, introducing delays (minutes/hours) incompatible with real-time requirements.
- FIFO Queue Limitations:
- SQS FIFO guarantees order but processes only 300 messages/second per queue, bottlenecking high-throughput streams.
---
### Conclusion
Option A is the only solution that combines real-time scalability, managed infrastructure, and pre-built anomaly detection. By leveraging Kinesis for ingestion and Flink’s RANDOM_CUT_FOREST, the company minimizes operational overhead while achieving millisecond-latency anomaly identification. Other options introduce batch delays (D), infrastructure management (C), or unnecessary ML complexity (B).
A company has a large collection of chat recordings from customer interactions after a product release. An ML engineer needs to create an ML model to analyze the chat data. The ML engineer needs to determine the success of the product by reviewing customer sentiments about the product.
Which action should the ML engineer take to complete the evaluation in the LEAST amount of time?
A. Use Amazon Rekognition to analyze sentiments of the chat conversations.
B. Train a Naive Bayes classifier to analyze sentiments of the chat conversations.
C. Use Amazon Comprehend to analyze sentiments of the chat conversations.
D. Use random forests to classify sentiments of the chat conversations.
Answer:
C. Use Amazon Comprehend to analyze sentiments of the chat conversations.
---
### Detailed Explanation
#### Requirements Summary
1. Sentiment Analysis: Determine customer sentiment (positive, negative, neutral) from chat recordings.
2. Minimize Time: Avoid data preprocessing, model training, or infrastructure setup.
3. Scalability: Handle a large volume of unstructured text data.
---
### Analysis of the Correct Answer (Option C)
##### What It Does
- Amazon Comprehend is a fully managed NLP service that provides pre-trained models for sentiment analysis.
- Key Features:
- Pre-Trained Sentiment Analysis: Automatically classifies text into positive, negative, neutral, or mixed sentiments.
- No Training Required: Uses AWS’s proprietary models trained on vast datasets, eliminating the need for custom model development.
- Direct Integration: Works with text data stored in S3 or provided via API calls.
##### Why It Meets the Requirements
1. Speed:
- Comprehend provides sentiment analysis out-of-the-box—simply pass the chat data via API or S3.
- No time spent on data labeling, model training, or hyperparameter tuning.
2. Scalability:
- Processes large datasets in batches or real-time streams, scaling automatically with demand.
3. Accuracy:
- Leverages AWS’s state-of-the-art NLP models, which outperform traditional methods (e.g., Naive Bayes) for complex text patterns.
---
### Key Differentiators for Option C
- Zero Model Development:
- Comprehend’s pre-trained models eliminate weeks of effort required to build and validate custom classifiers.
- Managed Infrastructure:
- No servers, frameworks, or GPU clusters to manage.
---
### Analysis of Incorrect Options
##### Option A: Amazon Rekognition
- Problem:
- Designed for Images/Video: Rekognition analyzes visual content (e.g., objects, faces) and cannot process text-based chat data.
##### Option B: Naive Bayes Classifier
- Problem:
- Manual Effort: Requires data cleaning, feature extraction (e.g., TF-IDF), model training, and validation.
- Inferior Performance: Naive Bayes assumes feature independence, making it less effective for nuanced sentiment analysis compared to deep learning models.
##### Option D: Random Forests
- Problem:
- Time-Centric Issues:
- Requires extensive feature engineering (e.g., n-grams, embeddings).
- Hyperparameter tuning (tree depth, estimators) adds complexity.
- Scalability Challenges: Random forests struggle with large text datasets due to high computational overhead.
---
### Conclusion
Option C is the fastest and most efficient solution. Amazon Comprehend’s pre-trained sentiment analysis model enables the ML engineer to derive insights from chat data in minutes, bypassing weeks of model development and training. Alternatives like Naive Bayes (B) or random forests (D) demand significant time and resources, while Rekognition (A) is functionally irrelevant for text analysis.
A company has a conversational AI assistant that sends requests through Amazon Bedrock to an Anthropic Claude large language model (LLM). Users report that when they ask similar questions multiple times, they sometimes receive different answers. An ML engineer needs to improve the responses to be more consistent and less random.
Which solution will meet these requirements?
A. Increase the temperature parameter and the top_k parameter.
B. Increase the temperature parameter. Decrease the top_k parameter.
C. Decrease the temperature parameter. Increase the top_k parameter.
D. Decrease the temperature parameter and the top_k parameter.
Answer:
D. Decrease the temperature parameter and the top_k parameter.
---
### Detailed Explanation
#### Requirements Summary
1. Reduce Response Randomness: Ensure consistent answers for similar user queries.
2. Improve Determinism: Minimize variability in the Anthropic Claude LLM’s outputs.
---
### Analysis of the Correct Answer (Option D)
##### What It Does
- Temperature:
- Controls the randomness of the model’s output.
- Lower temperature (e.g., closer to 0) reduces randomness, making the model choose higher-probability tokens (more deterministic).
- Top_k:
- Limits the model’s token selection to the top k most probable candidates.
- Lower top_k (e.g., 10 instead of 50) restricts the model to fewer high-confidence tokens, reducing variability.
##### Why It Meets the Requirements
1. Consistency:
- Lower temperature prioritizes the most likely token, reducing creative but inconsistent responses.
- Lower top_k narrows the pool of candidate tokens, ensuring similar inputs yield similar outputs.
2. Reduced Randomness:
- Combined, these adjustments make the model more deterministic while maintaining relevance.
---
### Key Differentiators for Option D
- Parameter Synergy:
- Decreasing both parameters enforces stricter token selection, directly addressing the core issue of variability.
- Alignment with Use Case:
- For factual or repeatable responses (e.g., customer support), determinism is prioritized over creativity.
---
### Analysis of Incorrect Options
##### Option A: Increase Temperature and Top_k
- Problem:
- Higher Temperature: Increases randomness, leading to more diverse (but inconsistent) responses.
- Higher Top_k: Expands the token candidate pool, amplifying variability.
##### Option B: Increase Temperature + Decrease Top_k
- Problem:
- Conflicting Effects: Higher temperature increases randomness, counteracting the lower top_k’s attempt to reduce variability.
##### Option C: Decrease Temperature + Increase Top_k
- Problem:
- Partial Fix: Lower temperature reduces randomness, but higher top_k reintroduces variability by allowing more token candidates.
---
### Conclusion
Option D is the only solution that systematically reduces randomness by tightening both the temperature (lower) and top_k (lower). This ensures the Claude LLM generates consistent, deterministic responses for similar queries, aligning with the need for reliability in customer interactions. Other options either increase randomness (A, B) or fail to fully mitigate it (C).
A company is using ML to predict the presence of a specific weed in a farmer's field. The company is using the Amazon SageMaker linear learner built-in algorithm with a value of multiclass_dassifier for the predictorjype hyperparameter.
What should the company do to MINIMIZE false positives?
A. Set the value of the weight decay hyperparameter to zero.
B. Increase the number of training epochs.
C. Increase the value of the target_precision hyperparameter.
D. Change the value of the predictorjype hyperparameter to regressor.
**Answer:**
**C. Increase the value of the target_precision hyperparameter.**
---
### **Detailed Explanation**
#### **Requirements Summary**
1. **Minimize False Positives**: Reduce instances where the model incorrectly predicts the presence of the weed (Type I errors).
2. **Maintain Multiclass Classification**: The problem is a classification task (weed presence prediction), so regression (Option D) is invalid.
---
### **Analysis of the Correct Answer (Option C)**
##### **What It Does**
- *target_precision Hyperparameter**:
- In SageMaker Linear Learner, target_precision controls the **precision-recall tradeoff**.
- Precision measures how many predicted positives are actual positives:
Precision = True Positives / (False Positives + True Positives)
- Increasing target_precision forces the model to prioritize reducing false positives over maximizing true positives (higher precision at the expense of recall).
##### **Why It Meets the Requirements**
1. **Direct Impact on False Positives**:
- A higher target_precision value explicitly penalizes false positives, making the model more conservative in predicting the weed’s presence.
2. **Algorithm-Specific Tuning**:
- Linear Learner’s target_precision is designed for this exact use case, unlike generic hyperparameters like weight_decay or training epochs.
---
### **Key Differentiators for Option C**
- **Precision Optimization**:
- Unlike other hyperparameters, target_precision directly aligns with the goal of minimizing false positives.
- **No Model Architecture Change**:
- Maintains the multiclass classification setup while refining prediction behavior.
---
### **Analysis of Incorrect Options**
##### **Option A: Set weight_decay to Zero**
- **Problem**:
- weight_decay (L2 regularization) prevents overfitting by penalizing large model weights. Setting it to **zero removes regularization**, increasing overfitting risk.
- Overfitting can amplify false positives if the model memorizes noise in the training data.
##### **Option B: Increase Training Epochs**
- **Problem**:
- More epochs can lead to overfitting (if the model trains too long) or underfitting (if stopped too early). Neither directly addresses false positives.
- Overfitting may increase variance in predictions, worsening inconsistency.
##### **Option D: Change predictor_type to Regressor**
- **Problem**:
- **Regression vs. Classification**: Regression predicts continuous values (e.g., weed density), not discrete classes (presence/absence). This invalidates the problem setup.
---
### **Conclusion**
**Option C** is the **only valid solution**. By increasing the target_precision hyperparameter, the model optimizes for precision, directly reducing false positives. Other options either fail to target false positives (A, B) or misuse the algorithm for regression (D).
A company has implemented a data ingestion pipeline for sales transactions from its ecommerce website. The company uses Amazon Data Firehose to ingest data into Amazon OpenSearch Service. The buffer interval of the Firehose stream is set for 60 seconds. An OpenSearch linear model generates real-time sales forecasts based on the data and presents the data in an OpenSearch dashboard.
The company needs to optimize the data ingestion pipeline to support sub-second latency for the real-time dashboard.
Which change to the architecture will meet these requirements?
A. Use zero buffering in the Firehose stream. Tune the batch size that is used in the PutRecordBatch operation.
B. Replace the Firehose stream with an AWS DataSync task. Configure the task with enhanced fan-out consumers.
C. Increase the buffer interval of the Firehose stream from 60 seconds to 120 seconds.
D. Replace the Firehose stream with an Amazon Simple Queue Service (Amazon SQS) queue.
**Answer:**
**A. Use zero buffering in the Firehose stream. Tune the batch size that is used in the PutRecordBatch operation.**
---
### **Detailed Explanation**
#### **Requirements Summary**
1. **Sub-Second Latency**: Reduce data ingestion delay from 60 seconds to under 1 second for real-time dashboard updates.
2. **Optimize Firehose Configuration**: Adjust the existing pipeline (Amazon Data Firehose → OpenSearch Service) without replacing core services.
---
### **Analysis of the Correct Answer (Option A)**
##### **What It Does**
- **Zero Buffering**:
- Configure Firehose to **disable buffering** by setting the BufferInterval to the minimum (60 seconds) and BufferSize to the minimum (1 MiB). This forces Firehose to send data immediately upon receiving it, bypassing the buffer delay.
- **Tune PutRecordBatch**:
- Reduce the BatchSize in the PutRecordBatch API operation to send smaller chunks of data more frequently.
- Smaller batches minimize the time data spends queued before transmission.
##### **Why It Meets the Requirements**
1. **Eliminates Buffer-Induced Latency**:
- Firehose’s default 60-second buffer interval is the primary bottleneck. Zero buffering ensures data is forwarded to OpenSearch as soon as it arrives.
2. **Real-Time Delivery**:
- With buffering disabled, data flows directly to OpenSearch, enabling the linear model and dashboard to reflect updates in sub-second time.
---
### **Key Differentiators for Option A**
- **Retains Existing Architecture**:
- Avoids service replacement (e.g., SQS, DataSync), which would require rearchitecting the pipeline.
- **AWS Best Practice**:
- Firehose supports low-latency use cases by prioritizing BufferSize over BufferInterval. If data volume is high, small buffer sizes trigger frequent deliveries even if the interval is 60 seconds.
---
### **Analysis of Incorrect Options**
##### **Option B: AWS DataSync + Enhanced Fan-Out**
- **Problem**:
- **DataSync is for Batch Transfers**: Designed for scheduled, large-volume data migrations (e.g., S3 to EFS), not real-time streaming.
- **Enhanced Fan-Out is a Kinesis Feature**: DataSync does not support enhanced fan-out, which is specific to Kinesis Data Streams.
##### **Option C: Increase Buffer Interval to 120 Seconds**
- **Problem**:
- **Increases Latency**: Doubling the buffer interval delays data delivery to OpenSearch, worsening dashboard latency.
##### **Option D: Replace Firehose with SQS**
- **Problem**:
- **No Direct OpenSearch Integration**: SQS requires a Lambda function or custom consumer to process messages and write to OpenSearch, introducing:
- **Complexity**: Additional code for message parsing, error handling, and retries.
- **Latency**: Lambda cold starts and polling delays (even with short polling) add milliseconds to seconds of overhead.
---
### **Conclusion**
**Option A** is the **only solution** that minimizes latency without overhauling the architecture. By disabling Firehose buffering and tuning PutRecordBatch, data flows directly to OpenSearch, achieving sub-second updates. Other options either increase latency (C), misuse services (B), or introduce complexity (D).
**Note**: While Firehose’s BufferInterval has a minimum of 60 seconds, setting BufferSize to 1 MiB ensures data is sent as soon as the buffer fills (which can happen rapidly for high-volume sales transactions). Combined with smaller PutRecordBatch sizes, this effectively reduces latency to sub-second levels.
A company has trained an ML model in Amazon SageMaker. The company needs to host the model to provide inferences in a production environment.
The model must be highly available and must respond with minimum latency. The size of each request will be between 1 KB and 3 MB. The model will receive unpredictable bursts of requests during the day. The inferences must adapt proportionally to the changes in demand.
How should the company deploy the model into production to meet these requirements?
A. Create a SageMaker real-time inference endpoint. Configure auto scaling. Configure the endpoint to present the existing model.
B. Deploy the model on an Amazon Elastic Container Service (Amazon ECS) cluster. Use ECS scheduled scaling that is based on the CPU of the ECS cluster.
C. Install SageMaker Operator on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. Deploy the model in Amazon EKS. Set horizontal pod auto scaling to scale replicas based on the memory metric.
D. Use Spot Instances with a Spot Fleet behind an Application Load Balancer (ALB) for inferences. Use the ALBRequestCountPerTarget metric as the metric for auto scaling.
Answer:
A. Create a SageMaker real-time inference endpoint. Configure auto scaling. Configure the endpoint to present the existing model.
---
### Detailed Explanation
#### Requirements Summary
1. High Availability: Ensure uninterrupted service even during instance failures or traffic spikes.
2. Low Latency: Minimize inference response times.
3. Adaptive Scaling: Automatically handle unpredictable traffic bursts.
4. Operational Simplicity: Avoid managing infrastructure or complex orchestration.
---
### Analysis of the Correct Answer (Option A)
##### What It Does
- SageMaker Real-Time Endpoint:
- Hosts the model as a managed service, providing a dedicated, low-latency API for inference requests.
- Automatically distributes traffic across multiple instances in multiple Availability Zones (AZs) for high availability.
- Auto Scaling:
- Dynamically scales the number of instances based on metrics like InvocationsPerInstance or CPUUtilization.
- Scales horizontally during traffic bursts and scales in during lulls, optimizing cost and performance.
##### Why It Meets the Requirements
1. High Availability:
- SageMaker endpoints deploy instances across multiple AZs. If one AZ fails, traffic reroutes to healthy instances.
2. Low Latency:
- Real-time endpoints use optimized ML inference containers and network configurations for sub-second responses.
3. Adaptive Scaling:
- Auto Scaling reacts to traffic spikes in real time, adding/removing instances within seconds.
- Supports burstable workloads (1 KB–3 MB requests) without manual intervention.
4. Managed Service:
- SageMaker handles infrastructure provisioning, patching, and load balancing, reducing operational overhead.
---
### Key Differentiators for Option A
- Native ML Optimization:
- SageMaker endpoints are purpose-built for ML inference, with GPU/CPU optimizations and model-specific tuning.
- Cost Efficiency:
- Pay only for active instances. Auto Scaling prevents over-provisioning during low traffic.
---
### Analysis of Incorrect Options
##### Option B: Amazon ECS with Scheduled Scaling
- Problem:
- Scheduled Scaling ≠ Real-Time Scaling: Predefined schedules cannot adapt to unpredictable bursts.
- Manual Configuration: Requires containerizing the model and managing ECS tasks, increasing complexity.
- No ML-Specific Optimizations: ECS lacks SageMaker’s inference optimizations, leading to higher latency.
##### Option C: SageMaker Operator on EKS with Memory-Based Scaling
- Problem:
- Operational Overhead: Managing Kubernetes clusters (EKS) adds complexity compared to fully managed endpoints.
- Ineffective Scaling Metric: Memory usage rarely correlates with request volume in ML inference (CPU/GPU is more relevant).
##### Option D: Spot Instances + ALBRequestCountPerTarget
- Problem:
- Spot Instance Interruptions: Spot Fleets can terminate instances abruptly, causing downtime and violating high availability.
- No ML Optimizations: ALB and EC2 lack SageMaker’s inference optimizations, increasing latency.
- Complex Setup: Requires manual load balancer configuration and Spot Fleet management.
---
### Conclusion
Option A is the only solution that satisfies all requirements:
- High Availability: Multi-AZ deployment with auto-recovery.
- Low Latency: Managed inference stack optimized for ML.
- Adaptive Scaling: Real-time auto scaling based on traffic.
- Simplicity: Fully managed service with no infrastructure oversight.
Alternatives like ECS (B), EKS (C), or Spot Fleet (D) introduce operational complexity, scaling inefficiencies, or reliability risks. SageMaker endpoints are purpose-built for production ML inference, making Option A the optimal choice.
An ML engineer needs to use an Amazon EMR cluster to process large volumes of data in batches. Any data loss is unacceptable.
Which instance purchasing option will meet these requirements MOST cost-effectively?
A. Run the primary node, core nodes, and task nodes on On-Demand Instances.
B. Run the primary node, core nodes, and task nodes on Spot Instances.
C. Run the primary node on an On-Demand Instance. Run the core nodes and task nodes on Spot Instances.
D. Run the primary node and core nodes on On-Demand Instances. Run the task nodes on Spot Instances.
Answer:
D. Run the primary node and core nodes on On-Demand Instances. Run the task nodes on Spot Instances.
---
### Detailed Explanation
#### Requirements Summary
1. No Data Loss: Ensure fault tolerance for critical components (primary and core nodes).
2. Cost-Effectiveness: Minimize expenses while meeting reliability requirements.
3. Batch Processing: Amazon EMR cluster for large-volume data processing.
---
### Analysis of the Correct Answer (Option D)
##### Why It Works
- Primary Node (On-Demand):
- Manages cluster coordination and critical metadata. On-Demand ensures uninterrupted operation, as Spot interruptions would cause cluster failure and potential data loss.
- Core Nodes (On-Demand):
- Store data in HDFS (Hadoop Distributed File System) and run critical tasks like shuffling/map-reduce operations.
- On-Demand prevents data loss: If a Spot core node is terminated, HDFS replication (default 3x) mitigates data loss but risks task failures and delays. On-Demand avoids this risk.
- Task Nodes (Spot):
- Stateless workers for parallel processing (e.g., Spark executors). Spot Instances are safe here: If terminated, tasks are rescheduled on other nodes without data loss.
##### Cost Efficiency
- Primary/Core Nodes (10–20% of cluster cost): Minimal cost impact for critical reliability.
- Task Nodes (80–90% of cluster cost): Spot pricing reduces costs by 60–90%, maximizing savings on non-critical components.
---
### Key Differentiators for Option D
- Balanced Reliability and Cost:
- Critical nodes (primary/core) use On-Demand for stability; non-critical tasks use Spot for savings.
- EMR Best Practices:
- AWS recommends On-Demand for primary/core nodes and Spot for task nodes in fault-tolerant workloads.
---
### Analysis of Incorrect Options
##### Option A: All On-Demand Instances
- Problem:
- High Cost: No Spot usage increases expenses by 60–90%, violating cost-effectiveness.
##### Option B: All Spot Instances
- Problem:
- Cluster Failure Risk: Spot interruptions on primary/core nodes cause cluster failure and potential data loss (e.g., mid-shuffle operations).
##### Option C: Primary (On-Demand) + Core/Task (Spot)
- Problem:
- Core Node Risks: Spot core nodes store HDFS data. Terminations force HDFS re-replication, increasing latency and risking data loss if replication lags.
---
### Conclusion
Option D is the most cost-effective and reliable solution. By reserving On-Demand for primary/core nodes (ensuring cluster stability and data integrity) and using Spot for task nodes (optimizing cost), the company meets its no-data-loss requirement while minimizing expenses. Other options either compromise reliability (B, C) or cost-efficiency (A).
A company wants to improve the sustainability of its ML operations.
Which actions will reduce the energy usage and computational resources that are associated with the company's training jobs? (Choose two.)
A. Use Amazon SageMaker Debugger to stop training jobs when non-converging conditions are detected.
B. Use Amazon SageMaker Ground Truth for data labeling.
C. Deploy models by using AWS Lambda functions.
D. Use AWS Trainium instances for training.
E. Use PyTorch or TensorFlow with the distributed training option.
Answer:
A. Use Amazon SageMaker Debugger to stop training jobs when non-converging conditions are detected.
D. Use AWS Trainium instances for training.
---
### Detailed Explanation
#### Requirements Summary
1. Reduce Energy/Compute Usage: Optimize training jobs to minimize wasted resources.
2. Sustainability Focus: Prioritize solutions that directly lower energy consumption and computational overhead.
---
### Analysis of the Correct Answers
##### A. SageMaker Debugger for Early Stopping
- What It Does:
- Monitors training metrics (e.g., loss, accuracy) in real time.
- Automatically stops jobs if models fail to converge (e.g., loss plateaus or diverges).
- Why It Reduces Energy/Compute:
- Prevents training from continuing when no meaningful progress is made, eliminating wasted cycles on non-productive jobs.
- Reduces GPU/CPU hours, directly lowering energy consumption.
##### D. AWS Trainium Instances
- What It Does:
- Purpose-built ML training chips optimized for high performance and energy efficiency.
- Delivers up to 50% lower cost and 2x higher throughput compared to GPU instances.
- Why It Reduces Energy/Compute:
- Trainium’s architecture minimizes energy per computation, reducing power usage.
- Faster training times decrease total resource consumption.
---
### Key Differentiators
- A (Debugger): Proactively halts inefficient training, addressing waste at the job level.
- D (Trainium): Hardware-level optimization for energy-efficient compute, reducing carbon footprint.
---
### Analysis of Incorrect Options
##### B. SageMaker Ground Truth
- Irrelevant to Training Efficiency:
- Focuses on data labeling accuracy, not reducing energy during model training.
##### C. AWS Lambda for Deployment
- Deployment vs. Training:
- Lambda optimizes inference (deployment) costs but has no impact on training jobs’ energy usage.
##### E. Distributed Training with PyTorch/TensorFlow
- Mixed Impact:
- Distributed training can reduce time-to-train but often increases total energy consumption due to parallel resource usage.
- Unless paired with energy-efficient hardware (e.g., Trainium), this risks higher net energy use.
---
### Conclusion
A and D are the only solutions that directly reduce energy and computational resources during training:
- A eliminates waste from non-converging jobs.
- D leverages energy-optimized hardware for efficient compute.
Other options either target unrelated stages (B, C) or have ambiguous sustainability impacts (E).
A company is planning to create several ML prediction models. The training data is stored in Amazon S3. The entire dataset is more than 5 ТВ in size and consists of CSV, JSON, Apache Parquet, and simple text files.
The data must be processed in several consecutive steps. The steps include complex manipulations that can take hours to finish running. Some of the processing involves natural language processing (NLP) transformations. The entire process must be automated.
Which solution will meet these requirements?
A. Process data at each step by using Amazon SageMaker Data Wrangler. Automate the process by using Data Wrangler jobs.
B. Use Amazon SageMaker notebooks for each data processing step. Automate the process by using Amazon EventBridge.
C. Process data at each step by using AWS Lambda functions. Automate the process by using AWS Step Functions and Amazon EventBridge.
D. Use Amazon SageMaker Pipelines to create a pipeline of data processing steps. Automate the pipeline by using Amazon EventBridge.
Answer:
D. Use Amazon SageMaker Pipelines to create a pipeline of data processing steps. Automate the pipeline by using Amazon EventBridge.
---
### Detailed Explanation
#### Requirements Summary
1. Large-Scale Data Processing: Handle 5+ TB of mixed-format data (CSV, JSON, Parquet, text).
2. Complex Multi-Step Workflow: Execute sequential steps, including NLP transformations and long-running tasks (hours).
3. Automation: Fully automate the end-to-end process.
---
### Analysis of the Correct Answer (Option D)
##### What It Does
- Amazon SageMaker Pipelines:
- Creates a managed, automated workflow to define and orchestrate data processing, NLP transformations, and model training.
- Integrates with SageMaker Processing Jobs for distributed, scalable data transformations (supports Spark, custom containers, or built-in frameworks).
- Handles large datasets by leveraging AWS infrastructure (e.g., auto-scaling clusters for data processing).
- Amazon EventBridge:
- Triggers the pipeline on a schedule (e.g., daily) or in response to events (e.g., new data in S3).
##### Why It Meets the Requirements
1. Scalability:
- SageMaker Processing Jobs scale horizontally to process 5+ TB of data efficiently, splitting workloads across instances.
2. NLP Support:
- Use custom containers (e.g., spaCy, Hugging Face) or SageMaker built-in algorithms for NLP tasks (tokenization, embeddings).
3. Automation:
- Pipelines define dependencies between steps (e.g., Step 1: clean data → Step 2: NLP → Step 3: train model), ensuring sequential execution.
- EventBridge automates pipeline initiation without manual intervention.
---
### Key Differentiators for Option D
- End-to-End Orchestration:
- Pipelines unify data processing, training, and deployment into a single workflow, reducing manual handoffs.
- Managed Infrastructure:
- SageMaker abstracts cluster management, auto-scaling, and fault tolerance for long-running jobs.
---
### Analysis of Incorrect Options
##### A. SageMaker Data Wrangler + Jobs
- Problem:
- Limited Scalability: Data Wrangler is designed for interactive, small-to-medium data prep (up to 100 GB). It struggles with 5+ TB datasets.
- No Support for Long-Running Jobs: Data Wrangler jobs lack the ability to run multi-hour, distributed processing tasks.
##### B. SageMaker Notebooks + EventBridge
- Problem:
- Manual Orchestration: Notebooks require custom code to chain steps and manage dependencies, increasing complexity.
- Resource Constraints: Notebooks lack the compute power to process 5 TB efficiently, leading to bottlenecks.
##### C. Lambda + Step Functions
- Problem:
- Execution Time Limits: Lambda functions timeout after 15 minutes, making them unsuitable for hours-long NLP tasks.
- Memory/Compute Limits: Lambda’s 10 GB RAM ceiling and lack of GPU support hinder large-scale NLP processing.
---
### Conclusion
Option D is the only solution that combines scalability, automation, and support for complex workflows. SageMaker Pipelines handles large datasets and multi-hour NLP tasks via managed processing jobs, while EventBridge ensures full automation. Alternatives like Data Wrangler (A), notebooks (B), or Lambda (C) lack the scalability or runtime capabilities required for 5+ TB datasets and NLP transformations.
An ML engineer needs to use AWS CloudFormation to create an ML model that an Amazon SageMaker endpoint will host.
Which resource should the ML engineer declare in the CloudFormation template to meet this requirement?
A. AWS::SageMaker::Model
B. AWS::SageMaker::Endpoint
C. AWS::SageMaker::NotebookInstance
D. AWS::SageMaker::Pipeline
**Answer:**
**A. AWS::SageMaker::Model**
---
### **Detailed Explanation**
#### **Requirements Summary**
1. **Declare a CloudFormation Resource**: Define the ML model to be hosted on a SageMaker endpoint.
2. **Infrastructure-as-Code (IaC)**: Use CloudFormation to provision the model and endpoint.
---
### **Analysis of the Correct Answer**
##### **What the AWS::SageMaker::Model Resource Does**
- **Defines the ML Model**:
- Specifies the model artifacts (e.g., trained model files stored in S3).
- Configures the inference container (Docker image URI, environment variables).
- Links IAM roles for SageMaker to access S3 and other AWS services.
- **Prerequisite for Endpoint Deployment**:
- A SageMaker endpoint AWS::SageMaker::Endpoint) references this model to deploy it for real-time inference.
##### **Why It Meets the Requirement**
- **Core Model Definition**:
- The AWS::SageMaker::Model resource is the foundational CloudFormation component for declaring an ML model. Without it, the endpoint has no model to host.
- **Integration with Endpoints**:
- The model resource is explicitly referenced in the endpoint configuration AWS::SageMaker::EndpointConfig), which is then used by the endpoint AWS::SageMaker::Endpoint).
---
### **Key Differentiators for Option A**
- **Direct Responsibility**:
- The AWS::SageMaker::Model directly represents the ML model’s configuration in CloudFormation. Other resources (e.g., Endpoint) depend on it but do not define the model itself.
- **AWS Best Practice**:
- CloudFormation templates for SageMaker endpoints **always** include a Model resource to encapsulate model artifacts and container details.
---
### **Analysis of Incorrect Options**
##### **B. AWS::SageMaker::Endpoint**
- **Problem**:
- The Endpoint resource deploys the model but **does not define the model itself**. It requires an EndpointConfig (which references the Model) to function.
##### **C. AWS::SageMaker::NotebookInstance**
- **Irrelevant**:
- Notebook instances are for interactive development, not model hosting.
##### **D. AWS::SageMaker::Pipeline**
- **Mismatched Purpose**:
- SageMaker Pipelines automate ML workflows (e.g., training, processing) but are unrelated to declaring a model for endpoint hosting.
---
### **Conclusion**
To create an ML model for a SageMaker endpoint in CloudFormation, the engineer **must declare the AWS::SageMaker::Model resource (A)**. This resource encapsulates the model’s artifacts, container, and IAM roles, forming the basis for endpoint deployment. While the Endpoint resource (B) is required for hosting, it depends on the Model being defined first. Options C and D address unrelated SageMaker components.
An advertising company uses AWS Lake Formation to manage a data lake. The data lake contains structured data and unstructured data. The company's ML engineers are assigned to specific advertisement campaigns.
The ML engineers must interact with the data through Amazon Athena and by browsing the data directly in an Amazon S3 bucket. The ML engineers must have access to only the resources that are specific to their assigned advertisement campaigns.
Which solution will meet these requirements in the MOST operationally efficient way?
A. Configure IAM policies on an AWS Glue Data Catalog to restrict access to Athena based on the ML engineers' campaigns.
B. Store users and campaign information in an Amazon DynamoDB table. Configure DynamoDB Streams to invoke an AWS Lambda function to update S3 bucket policies.
C. Use Lake Formation to authorize AWS Glue to access the S3 bucket. Configure Lake Formation tags to map ML engineers to their campaigns.
D. Configure S3 bucket policies to restrict access to the S3 bucket based on the ML engineers' campaigns.
Answer:
C. Use Lake Formation to authorize AWS Glue to access the S3 bucket. Configure Lake Formation tags to map ML engineers to their campaigns.
---
### Detailed Explanation
#### Requirements Summary
1. Granular Access Control: ML engineers must access only their assigned campaign’s data in S3 and via Athena.
2. Operational Efficiency: Avoid manual policy updates or complex scripting when campaigns or permissions change.
3. Hybrid Data Support: Manage permissions for both structured (Athena/S3) and unstructured (S3) data.
---
### Analysis of the Correct Answer (Option C)
##### How It Works
1. Lake Formation Tags:
- Assign tags to AWS Glue Data Catalog resources (databases, tables) and S3 paths based on campaign identifiers (e.g., campaign=ad_campaign_1).
- Assign IAM principals (users/roles) corresponding to ML engineers to the same tags.
2. Lake Formation Permissions:
- Grant SELECT permissions on tagged Data Catalog tables for Athena queries.
- Grant DESCRIBE and READ permissions on tagged S3 paths for browsing via the S3 console.
##### Why It Meets the Requirements
1. Campaign-Specific Access:
- Engineers access only data tagged with their assigned campaigns. For example:
- Athena queries filter to tables tagged campaign=ad_campaign_1.
- S3 browsing is restricted to paths tagged campaign=ad_campaign_1.
2. Automated Permissions:
- Tags dynamically enforce access without manual policy updates. Adding a new campaign or user requires only tag assignments.
3. Unified Governance:
- Lake Formation centralizes permissions for both structured (Glue/Athena) and unstructured (S3) data, eliminating siloed policies.
---
### Key Differentiators for Option C
- Tag-Based Automation:
Lake Formation tags enable attribute-based access control (ABAC), scaling seamlessly as campaigns or users evolve.
- Integration with AWS Services:
Permissions propagate automatically to Athena (via Glue) and S3, ensuring consistent enforcement.
---
### Analysis of Incorrect Options
##### A. IAM Policies on Glue Data Catalog
- Problem:
- Manual Management: IAM policies require explicit ARN references for each campaign/table, leading to policy bloat.
- No S3 Integration: IAM cannot enforce granular S3 path access without complex bucket policies.
##### B. DynamoDB + Lambda + S3 Policies
- Problem:
- Complex Orchestration: DynamoDB Streams and Lambda introduce operational overhead for real-time policy updates.
- Fragile Architecture: S3 bucket policies are not designed for dynamic, campaign-specific access at scale.
##### D. S3 Bucket Policies
- Problem:
- Limited Granularity: S3 policies cannot restrict access to specific Athena tables or Glue resources.
- Scalability Issues: Managing policies for thousands of campaigns/users is error-prone and inefficient.
---
### Conclusion
Option C is the most operationally efficient solution. By leveraging Lake Formation tags, the company automates campaign-specific access across Athena and S3 while maintaining centralized governance. This approach scales effortlessly, avoids manual policy updates, and aligns with AWS best practices for data lake security. Other options require cumbersome manual management (A, D) or introduce unnecessary complexity (B).
An ML engineer needs to use data with Amazon SageMaker Canvas to train an ML model. The data is stored in Amazon S3 and is complex in structure. The ML engineer must use a file format that minimizes processing time for the data.
Which file format will meet these requirements?
A. CSV files compressed with Snappy
B. JSON objects in JSONL format
C. JSON files compressed with gzip
D. Apache Parquet files
Answer:
D. Apache Parquet files
---
### Detailed Explanation
#### Requirements Summary
1. Minimize Processing Time: Optimize data read/processing efficiency for complex structured data in Amazon S3.
2. Complex Data Structure Support: Handle nested or hierarchical data (common in JSON/Parquet).
3. SageMaker Canvas Compatibility: Ensure the format works seamlessly with Canvas’s no-code ML workflows.
---
### Analysis of the Correct Answer
##### Why Apache Parquet Files
1. Columnar Storage:
- Parquet stores data by column (not row), enabling column pruning. SageMaker Canvas reads only relevant columns during training, reducing I/O and processing time.
- Example: For a dataset with 100 columns, if only 10 are used in training, Parquet skips reading the remaining 90.
2. Efficient Compression:
- Parquet uses Snappy or Gzip compression by default, reducing file size and speeding up data transfer from S3.
- Compression ratios are typically 2–4x better than CSV/JSON, lowering storage costs and latency.
3. Complex Data Support:
- Parquet natively supports nested data structures (e.g., arrays, maps) and schema evolution, making it ideal for hierarchical or multi-layered datasets.
4. Optimized for Analytics/ML:
- Parquet is the de facto standard for big data and ML pipelines. SageMaker Canvas leverages these optimizations for faster data loading and preprocessing.
---
### Key Differentiators for Option D
- Performance:
- Parquet outperforms row-based formats (CSV/JSON) in read speed and compute efficiency, critical for large or complex datasets.
- AWS Integration:
- SageMaker Canvas, AWS Glue, and Athena all natively optimize for Parquet, reducing preprocessing steps.
---
### Analysis of Incorrect Options
##### A. CSV Files with Snappy Compression
- Problem:
- Row-Based Storage: Requires reading entire rows, increasing I/O for complex queries.
- No Nested Data Support: Struggles with hierarchical structures, forcing data flattening (costly in preprocessing time).
##### B. JSONL (JSON Lines)
- Problem:
- Row-Based and Verbose: JSON parsing is slower due to text-based structure and lack of schema enforcement.
- No Columnar Benefits: Cannot skip unused fields during reads, leading to higher latency.
##### C. JSON with Gzip Compression
- Problem:
- High Parsing Overhead: JSON’s text-based format requires deserialization, which is computationally expensive.
- Gzip Slows Reads: While compression reduces storage, Gzip decompression adds latency compared to Snappy (used in Parquet).
---
### Conclusion
Apache Parquet (D) is the optimal choice for minimizing processing time with complex data in SageMaker Canvas. Its columnar storage, efficient compression, and native support for nested structures align perfectly with the requirement to accelerate ML workflows. CSV (A) and JSON (B, C) lack the performance optimizations needed for large-scale or hierarchical datasets.
An ML engineer is evaluating several ML models and must choose one model to use in production. The cost of false negative predictions by the models is much higher than the cost of false positive predictions.
Which metric finding should the ML engineer prioritize the MOST when choosing the model?
A. Low precision
B. High precision
C. Low recall
D. High recall
Answer:
D. High recall
---
### Detailed Explanation
#### Requirements Summary
1. Higher Cost of False Negatives: Missing a positive instance (e.g., failing to detect a critical medical condition, fraudulent transaction, or security threat) is more costly than incorrectly flagging a negative instance.
2. Metric Prioritization: Choose the model that minimizes false negatives (missed detections).
---
### Analysis of the Correct Answer
##### Why High Recall Matters
- Recall (Sensitivity/True Positive Rate):
Recall=True Positives / (False Negatives+True Positives)
- Measures the model’s ability to identify all relevant positive instances.
- High recall directly reduces false negatives, ensuring fewer missed critical cases.
##### Tradeoff with Precision
- Precision:
Precision = True Positives / (False Positives+True Positives)
- Focuses on minimizing false positives.
- Prioritizing precision would increase false negatives, which is unacceptable in this scenario.
---
### Key Differentiators for Option D
- Business Impact:
- In contexts like healthcare (disease detection), fraud prevention, or safety-critical systems, missing a positive case (false negative) has severe consequences. High recall ensures fewer misses.
- Model Behavior:
- A high-recall model casts a wider net, accepting more false positives to capture nearly all true positives.
---
### Analysis of Incorrect Options
##### A. Low Precision
- Problem:
- Low precision increases false positives (incorrectly flagging negatives as positives). While this might seem to align with tolerating false positives, it does nothing to reduce false negatives.
##### B. High Precision
- Problem:
- High precision reduces false positives but increases false negatives (by being overly conservative). This worsens the primary issue of costly missed detections.
##### C. Low Recall
- Problem:
- Low recall directly increases false negatives, which is the exact opposite of the requirement.
---
### Conclusion
When the cost of false negatives far outweighs that of false positives, high recall (D) is the critical metric to prioritize. It ensures the model identifies nearly all positive cases, even if it means tolerating some false alarms. This aligns with use cases like disease diagnosis, fraud detection, or safety systems, where missing a critical event is unacceptable.
A company has AWS Glue data processing jobs that are orchestrated by an AWS Glue workflow. The AWS Glue jobs can run on a schedule or can be launched manually.
The company is developing pipelines in Amazon SageMaker Pipelines for ML model development. The pipelines will use the output of the AWS Glue jobs during the data processing phase of model development. An ML engineer needs to implement a solution that integrates the AWS Glue jobs with the pipelines.
Which solution will meet these requirements with the LEAST operational overhead?
A. Use AWS Step Functions for orchestration of the pipelines and the AWS Glue jobs.
B. Use processing steps in SageMaker Pipelines. Configure inputs that point to the Amazon Resource Names (ARNs) of the AWS Glue jobs.
C. Use Callback steps in SageMaker Pipelines to start the AWS Glue workflow and to stop the pipelines until the AWS Glue jobs finish running.
D. Use Amazon EventBridge to invoke the pipelines and the AWS Glue jobs in the desired order.
Answer:
C. Use Callback steps in SageMaker Pipelines to start the AWS Glue workflow and to stop the pipelines until the AWS Glue jobs finish running.
---
### Detailed Explanation
#### Requirements Summary
1. Integration: Connect AWS Glue jobs (managed via Glue workflows) with SageMaker Pipelines for ML model development.
2. Operational Efficiency: Minimize setup complexity and avoid introducing new orchestration tools.
---
### Analysis of the Correct Answer
##### How Callback Steps Work
- Trigger and Wait:
- A Callback step in SageMaker Pipelines starts the AWS Glue workflow (executing the required jobs) and pauses the pipeline.
- The pipeline remains in a "waiting" state until it receives a resume signal (e.g., via Amazon SNS or API Gateway) indicating Glue job completion.
- Automatic Resume:
- Once the Glue jobs finish, the workflow sends a success/failure signal to SageMaker Pipelines, which resumes execution.
##### Why It Meets the Requirements
1. Direct Integration:
- Leverages existing AWS Glue workflows without requiring re-architecture or additional services (e.g., Step Functions).
2. Minimal Overhead:
- Uses SageMaker Pipelines’ native Callback step to pause/resume based on Glue job status, avoiding complex event routing or custom code.
3. End-to-End Automation:
- Maintains the Glue workflow’s existing scheduling/manual triggers while ensuring SageMaker Pipelines wait for data processing to complete.
---
### Key Differentiators for Option C
- Native SageMaker Pipelines Feature:
- Callback steps are designed for external process coordination, eliminating the need for third-party orchestration.
- Preserves Existing Workflows:
- Glue workflows remain unchanged, reducing migration effort.
---
### Analysis of Incorrect Options
##### A. AWS Step Functions
- Problem:
- Introduces a new orchestration layer, requiring migration of Glue workflows to Step Functions state machines.
- Adds complexity in managing dependencies between Step Functions and SageMaker Pipelines.
##### B. SageMaker Processing Steps
- Problem:
- SageMaker Processing steps run SageMaker-managed jobs (not AWS Glue jobs). This would require rewriting Glue ETL logic into Processing jobs, increasing effort.
##### D. Amazon EventBridge
- Problem:
- Requires manual event routing (e.g., Glue job completion → EventBridge rule → SageMaker Pipeline trigger).
- Adds fragility due to event latency and dependency management.
---
### Conclusion
Option C provides the least operational overhead by using SageMaker Pipelines’ built-in Callback steps to natively integrate with AWS Glue workflows. This approach maintains existing Glue scheduling/manual triggers and ensures pipelines wait for data processing completion without introducing new services or rearchitecting workflows. Other options either add complexity (A, D) or require code refactoring (B).
A company is using an Amazon Redshift database as its single data source. Some of the data is sensitive.
A data scientist needs to use some of the sensitive data from the database. An ML engineer must give the data scientist access to the data without transforming the source data and without storing anonymized data in the database.
Which solution will meet these requirements with the LEAST implementation effort?
A. Configure dynamic data masking policies to control how sensitive data is shared with the data scientist at query time.
B. Create a materialized view with masking logic on top of the database. Grant the necessary read permissions to the data scientist.
C. Unload the Amazon Redshift data to Amazon S3. Use Amazon Athena to create schema-on-read with masking logic. Share the view with the data scientist.
D. Unload the Amazon Redshift data to Amazon S3. Create an AWS Glue job to anonymize the data. Share the dataset with the data scientist.
Answer:
A. Configure dynamic data masking policies to control how sensitive data is shared with the data scientist at query time.
---
### Detailed Explanation
#### Requirements Summary
1. No Source Data Transformation: The original Amazon Redshift data must remain unchanged.
2. No Anonymized Data Storage: Avoid creating new tables or materialized views with masked data in Redshift.
3. Least Effort: Minimize data movement, ETL jobs, or infrastructure changes.
---
### Analysis of the Correct Answer
##### How Dynamic Data Masking Works
- Policy-Based Masking at Query Time:
- Redshift’s dynamic data masking allows administrators to define policies that mask sensitive columns (e.g., credit card numbers, emails) on-the-fly for specific users or roles.
- Example: A policy replaces the last four digits of a Social Security Number with XXX-XX-1234 when queried by the data scientist.
- No Data Modification:
- The raw data remains intact in Redshift. Masking occurs during query execution, ensuring compliance without altering source data.
##### Why It Meets the Requirements
1. Zero Data Transformation:
- Masking policies apply dynamically, leaving the original data untouched.
2. No Storage of Anonymized Data:
- Masked results are ephemeral and not persisted in Redshift.
3. Minimal Implementation Effort:
- Requires only creating masking policies in Redshift (via SQL commands) and granting the data scientist read access. No ETL, data movement, or new infrastructure.
---
### Key Differentiators for Option A
- Native Redshift Feature:
- Built-in masking eliminates dependencies on external services (e.g., Athena, Glue) or data duplication.
- Centralized Governance:
- Policies are managed directly in Redshift, ensuring consistency and auditability.
---
### Analysis of Incorrect Options
##### B. Materialized View with Masking
- Problem:
- Materialized views store physical copies of data in Redshift. Masking logic in the view would create anonymized data within the database, violating the "no anonymized storage" requirement.
##### C. Unload to S3 + Athena Schema-on-Read
- Problem:
- Requires unloading data to S3 (additional storage costs) and recreating schemas in Athena.
- Adds complexity with cross-service access controls and latency from data movement.
##### D. Unload to S3 + Glue Job
- Problem:
- Involves ETL jobs (Glue) to anonymize data and store it in S3, creating a separate anonymized dataset.
- Violates the "no storage of anonymized data in the database" requirement if S3 is considered part of the data pipeline.
---
### Conclusion
Option A is the only solution that meets all requirements with minimal effort. By leveraging Redshift’s dynamic data masking, sensitive data is protected at query time without altering the source or storing anonymized copies. Other options introduce unnecessary complexity (C, D) or violate constraints (B).
A Machine Learning Specialist is training a model to identify the make and model of vehicles in images. The Specialist wants to use transfer learning and an existing model trained on images of general objects. The Specialist collated a large custom dataset of pictures containing different vehicle makes and models.
What should the Specialist do to initialize the model to re-train it with the custom data?
A. Initialize the model with random weights in all layers including the last fully connected layer.
B. Initialize the model with pre-trained weights in all layers and replace the last fully connected layer.
C. Initialize the model with random weights in all layers and replace the last fully connected layer.
D. Initialize the model with pre-trained weights in all layers including the last fully connected layer.
Answer:
B. Initialize the model with pre-trained weights in all layers and replace the last fully connected layer.
---
### Detailed Explanation
#### Requirements Summary
1. Transfer Learning: Leverage a pre-trained model (trained on general objects) for a new task (vehicle make/model classification).
2. Custom Dataset Adaptation: Retrain the model using a specialized dataset of vehicle images.
3. Optimal Initialization: Preserve learned features while adapting to the new task.
---
### Analysis of the Correct Answer
##### Why Pre-Trained Weights + Replacing the Last Layer Works
1. Feature Reuse:
- The early and intermediate layers of the pre-trained model have already learned general features (edges, textures, shapes) from the original dataset. These are transferable to the new task (vehicle classification).
- Freezing or retaining these layers preserves their learned representations, reducing training time and data requirements.
2. Task-Specific Adaptation:
- The last fully connected (classification) layer of the pre-trained model is designed for the original task (e.g., 1,000 general object classes).
- Replace this layer with a new one that matches the number of output classes for vehicle makes/models (e.g., 50 car brands).
- The new layer is initialized with random weights and trained on the custom dataset, enabling the model to specialize in vehicle recognition.
##### Why It Meets the Requirements
- Efficient Training:
Retraining only the last layer (or fine-tuning some deeper layers) avoids starting from scratch, leveraging prior knowledge for faster convergence.
- Avoid Overfitting:
Using pre-trained weights reduces the risk of overfitting on smaller custom datasets compared to training all layers randomly.
---
### Key Differentiators for Option B
- Balances General and Task-Specific Learning:
Retains transferable features from the pre-trained model while adapting the final layer to the new domain.
- Standard Transfer Learning Practice:
This approach is widely used in computer vision (e.g., ResNet, VGG fine-tuning) to minimize training effort and maximize accuracy.
---
### Analysis of Incorrect Options
##### A. Random Weights in All Layers
- Problem:
- Random initialization discards pre-trained feature representations, forcing the model to learn from scratch. This negates the benefits of transfer learning, increasing training time and data requirements.
##### C. Random Weights + Replaced Last Layer
- Problem:
- While replacing the last layer is correct, initializing all other layers with random weights wastes the pre-trained model’s learned features, leading to inefficient training.
##### D. Pre-Trained Weights in All Layers
- Problem:
- The final layer’s weights are tuned for the original classes (general objects). Retaining them would force the model to predict irrelevant classes, making it unusable for vehicle identification.
---
### Conclusion
Option B is the optimal strategy for transfer learning in this scenario. By reusing pre-trained weights for feature extraction and replacing the last layer for task-specific classification, the Specialist efficiently adapts the model to recognize vehicle makes/models. This approach minimizes training effort, reduces overfitting risk, and leverages prior knowledge effectively. Other options either discard transfer learning benefits (A, C) or retain incompatible output layers (D).
A credit card company has a fraud detection model in production on an Amazon SageMaker endpoint. The company develops a new version of the model. The company needs to assess the new model's performance by using live data and without affecting production end users.
Which solution will meet these requirements?
A. Set up SageMaker Debugger and create a custom rule.
B. Set up blue/green deployments with all-at-once traffic shifting.
C. Set up blue/green deployments with canary traffic shifting.
D. Set up shadow testing with a shadow variant of the new model.
Answer:
D. Set up shadow testing with a shadow variant of the new model.
---
### Detailed Explanation
#### Requirements Summary
1. Test New Model with Live Data: Evaluate the new fraud detection model using real-time traffic.
2. Zero Impact on Production Users: Ensure end users experience no disruption or changes in service.
3. Performance Comparison: Compare the new model’s predictions with the production model’s results.
---
### Analysis of the Correct Answer
##### How Shadow Testing Works
- Shadow Variant:
- Deploy the new model as a shadow variant alongside the existing production model on the SageMaker endpoint.
- The shadow model receives a copy of all incoming live traffic but does not return predictions to users.
- Invisible Testing:
- Production users interact only with the original model. The shadow model processes requests silently in parallel.
- Predictions from both models are logged (e.g., to Amazon CloudWatch or S3) for offline comparison.
##### Why It Meets the Requirements
1. No User Impact:
- End users receive responses only from the production model. The shadow variant operates in the background.
2. Real-World Validation:
- The new model is tested against live data, capturing real-world scenarios (e.g., evolving fraud patterns).
3. Performance Metrics:
- Compare accuracy, latency, and fraud detection rates between the two models without risking production stability.
---
### Key Differentiators for Option D
- Risk-Free Validation:
- Shadow testing avoids exposing users to unproven models while enabling rigorous performance analysis.
- SageMaker Native Feature:
- SageMaker endpoints support shadow variants natively, requiring minimal configuration.
---
### Analysis of Incorrect Options
##### A. SageMaker Debugger + Custom Rule
- Problem:
- Debugger monitors training jobs for issues (e.g., overfitting, vanishing gradients) but does not validate live model performance.
- Irrelevant for testing a new model in production with live data.
##### B. Blue/Green (All-at-Once Traffic Shifting)
- Problem:
- All traffic shifts to the new model immediately. If the new model fails, all users are affected, violating the requirement.
##### C. Blue/Green (Canary Traffic Shifting)
- Problem:
- Routes a small percentage of live traffic (e.g., 5%) to the new model. While less risky than all-at-once, it still impacts some users, which is prohibited here.
---
### Conclusion
Option D is the only solution that allows the company to test the new model with live data while fully insulating end users from changes. Shadow testing provides a safe, controlled environment to validate performance metrics (e.g., precision, recall) and ensure the new model meets production standards before any traffic is shifted. Blue/green deployments (B, C) inherently impact users, and Debugger (A) is unrelated to live model testing.
A company stores time-series data about user clicks in an Amazon S3 bucket. The raw data consists of millions of rows of user activity every day. ML engineers access the data to develop their ML models.
The ML engineers need to generate daily reports and analyze click trends over the past 3 days by using Amazon Athena. The company must retain the data for 30 days before archiving the data.
Which solution will provide the HIGHEST performance for data retrieval?
A. Keep all the time-series data without partitioning in the S3 bucket. Manually move data that is older than 30 days to separate S3 buckets.
B. Create AWS Lambda functions to copy the time-series data into separate S3 buckets. Apply S3 Lifecycle policies to archive data that is older than 30 days to S3 Glacier Flexible Retrieval.
C. Organize the time-series data into partitions by date prefix in the S3 bucket. Apply S3 Lifecycle policies to archive partitions that are older than 30 days to S3 Glacier Flexible Retrieval.
D. Put each day's time-series data into its own S3 bucket. Use S3 Lifecycle policies to archive S3 buckets that hold data that is older than 30 days to S3 Glacier Flexible Retrieval.
Answer:
C. Organize the time-series data into partitions by date prefix in the S3 bucket. Apply S3 Lifecycle policies to archive partitions that are older than 30 days to S3 Glacier Flexible Retrieval.
---
### Detailed Explanation
#### Requirements Summary
1. High Query Performance: Optimize data retrieval for daily reports and 3-day trend analysis using Amazon Athena.
2. Automated Retention: Archive data older than 30 days without manual intervention.
3. Scalability: Handle millions of rows of daily time-series data efficiently.
---
### Analysis of the Correct Answer
##### Why Partitioning by Date Prefix Works
1. Athena Query Optimization:
- Partitioning by date (e.g., s3://bucket/click_data/year=2023/month=10/day=01/) allows Athena to prune partitions during queries.
- For example, a query filtering to the last 3 days scans only 3 partitions instead of the entire dataset, drastically reducing I/O and cost.
- Partitioning leverages the WHERE clause in SQL to skip irrelevant data, improving performance by orders of magnitude.
2. S3 Lifecycle Integration:
- Lifecycle policies can target partitions (folders) older than 30 days, automatically transitioning them to S3 Glacier.
- No manual data movement is required, ensuring compliance with retention policies.
##### Why It Meets the Requirements
- Performance:
Partitioning minimizes the volume of data scanned by Athena, accelerating queries for daily reports and trend analysis.
- Automation:
Lifecycle policies handle archiving, eliminating manual effort.
- Cost Efficiency:
Reduced data scanning lowers Athena costs, while Glacier minimizes storage costs for archived data.
---
### Key Differentiators for Option C
- Athena Best Practice:
Partitioning is the recommended method for optimizing queries on time-series data in Athena.
- Granular Retention:
Lifecycle policies apply to entire partitions, ensuring clean and efficient archiving.
---
### Analysis of Incorrect Options
##### A. No Partitioning + Manual Archiving
- Problem:
- Full table scans in Athena for every query lead to slow performance and high costs.
- Manual archiving is error-prone and unscalable for daily data volumes.
##### B. Separate S3 Buckets via Lambda
- Problem:
- Multiple buckets complicate query logic and partition management.
- Lambda-based copying adds unnecessary complexity and cost.
##### D. One Bucket per Day
- Problem:
- Managing thousands of S3 buckets is impractical (AWS account limits, operational overhead).
- Athena queries would require cross-bucket joins or complex path configurations, degrading performance.
---
### Conclusion
Option C is the optimal solution for high-performance data retrieval. By partitioning time-series data by date prefix and automating retention with S3 Lifecycle policies, Athena queries are accelerated through partition pruning, and archiving is handled seamlessly. This approach aligns with AWS best practices for cost, performance, and scalability. Other options introduce inefficiencies (A, B) or operational complexity (D).
A company has deployed an ML model that detects fraudulent credit card transactions in real time in a banking application. The model uses Amazon SageMaker Asynchronous Inference. Consumers are reporting delays in receiving the inference results.
An ML engineer needs to implement a solution to improve the inference performance. The solution also must provide a notification when a deviation in model quality occurs.
Which solution will meet these requirements?
A. Use SageMaker real-time inference for inference. Use SageMaker Model Monitor for notifications about model quality.
B. Use SageMaker batch transform for inference. Use SageMaker Model Monitor for notifications about model quality.
C. Use SageMaker Serverless Inference for inference. Use SageMaker Inference Recommender for notifications about model quality.
D. Keep using SageMaker Asynchronous Inference for inference. Use SageMaker Inference Recommender for notifications about model quality.
Answer:
A. Use SageMaker real-time inference for inference. Use SageMaker Model Monitor for notifications about model quality.
---
### Detailed Explanation
#### Requirements Summary
1. Improve Inference Performance: Reduce delays in delivering fraud detection results to end users.
2. Model Quality Monitoring: Detect and notify when the model’s predictions deviate from expected behavior.
---
### Analysis of the Correct Answer
##### Why SageMaker Real-Time Inference + Model Monitor Works
1. Real-Time Inference:
- Low-Latency Predictions:
Replaces Asynchronous Inference (designed for offline/batch processing with queued requests) with real-time endpoints, which process requests immediately and return results with sub-second latency.
- Scaling:
Real-time endpoints automatically scale instances to handle traffic spikes, preventing delays caused by queuing or cold starts.
2. SageMaker Model Monitor:
- Quality Deviation Detection:
Monitors live inference endpoints for data drift (changes in input data distribution) and model drift (performance degradation).
- Alerts:
Integrates with Amazon CloudWatch to trigger notifications (e.g., SNS alerts) when deviations exceed predefined thresholds.
##### Why It Meets the Requirements
- Eliminates Delays:
Real-time inference ensures immediate processing of fraud detection requests, resolving consumer-reported latency.
- Proactive Quality Assurance:
Model Monitor continuously evaluates predictions against baseline metrics (e.g., accuracy, precision), enabling rapid response to quality issues.
---
### Key Differentiators for Option A
- Direct Performance Fix:
Real-time inference is purpose-built for low-latency applications like fraud detection, unlike Asynchronous or Batch Inference.
- End-to-End Monitoring:
Model Monitor provides built-in tools for detecting quality deviations without custom code.
---
### Analysis of Incorrect Options
##### B. Batch Transform + Model Monitor
- Problem:
- Batch Transform processes data in bulk, introducing hours-long delays. This worsens latency, violating the requirement to improve performance.
##### C. Serverless Inference + Inference Recommender
- Problem:
- Serverless Inference has variable latency (due to cold starts) and is less predictable than real-time endpoints.
- Inference Recommender optimizes instance selection, not model quality monitoring.
##### D. Keep Asynchronous Inference + Inference Recommender
- Problem:
- Asynchronous Inference inherently introduces delays (minutes to hours), which cannot be resolved with instance optimization.
- Inference Recommender does not monitor model quality or trigger alerts for deviations.
---
### Conclusion
Option A is the only solution that addresses both requirements:
1. Real-Time Inference eliminates delays by processing requests immediately.
2. Model Monitor ensures quality deviations are detected and alerted.
Other options either fail to reduce latency (B, D) or lack proper monitoring (C). By migrating to real-time inference and enabling Model Monitor, the company ensures timely fraud detection and maintains model reliability.
An ML engineer needs to implement a solution to host a trained ML model. The rate of requests to the model will be inconsistent throughout the day.
The ML engineer needs a scalable solution that minimizes costs when the model is not in use. The solution also must maintain the model's capacity to respond to requests during times of peak usage.
Which solution will meet these requirements?
A. Create AWS Lambda functions that have fixed concurrency to host the model. Configure the Lambda functions to automatically scale based on the number of requests to the model.
B. Deploy the model on an Amazon Elastic Container Service (Amazon ECS) cluster that uses AWS Fargate. Set a static number of tasks to handle requests during times of peak usage.
C. Deploy the model to an Amazon SageMaker endpoint. Deploy multiple copies of the model to the endpoint. Create an Application Load Balancer to route traffic between the different copies of the model at the endpoint.
D. Deploy the model to an Amazon SageMaker endpoint. Create SageMaker endpoint auto scaling policies that are based on Amazon CloudWatch metrics to adjust the number of instances dynamically.
Answer:
D. Deploy the model to an Amazon SageMaker endpoint. Create SageMaker endpoint auto scaling policies that are based on Amazon CloudWatch metrics to adjust the number of instances dynamically.
---
### Detailed Explanation
#### Requirements Summary
1. Scalability: Handle inconsistent request rates, scaling during peaks and reducing resources during low usage.
2. Cost Efficiency: Minimize costs when the model is idle or under low load.
3. Peak Performance: Ensure capacity to respond to sudden spikes in traffic.
---
### Analysis of the Correct Answer
##### Why SageMaker Endpoint with Auto Scaling Works
1. Dynamic Scaling:
- SageMaker auto scaling uses CloudWatch metrics (e.g., InvocationsPerInstance, CPUUtilization) to automatically:
- Scale Out: Add instances during traffic spikes to maintain low latency.
- Scale In: Remove instances during low traffic to reduce costs.
2. Pay-Per-Use Cost Model:
- You pay only for instances when they are running. During idle periods, scaling to zero (or a minimal instance count) minimizes costs.
3. Managed Infrastructure:
- SageMaker handles load balancing, health checks, and instance provisioning, ensuring high availability without manual intervention.
##### Why It Meets the Requirements
- Cost Minimization:
Auto scaling reduces instances during low usage, avoiding charges for idle resources.
- Peak Readiness:
Scaling policies ensure sufficient instances are provisioned to handle sudden traffic surges.
---
### Key Differentiators for Option D
- Native Auto Scaling:
SageMaker’s built-in scaling integrates seamlessly with CloudWatch, eliminating the need for custom scripting or third-party tools.
- Optimal Resource Utilization:
Balances performance and cost by dynamically aligning compute capacity with demand.
---
### Analysis of Incorrect Options
##### A. AWS Lambda with Fixed Concurrency
- Problem:
- Limited to Lightweight Models: Lambda’s 15-minute timeout, 10 GB memory limit, and lack of GPU support make it unsuitable for large or compute-intensive ML models.
- Fixed Concurrency Costs: Provisioned concurrency reserves resources (and costs) even when idle, violating the cost-minimization requirement.
##### B. ECS Fargate with Static Tasks
- Problem:
- No Auto Scaling: Static task counts lead to over-provisioning (high costs during low usage) or under-provisioning (poor performance during peaks).
##### C. SageMaker Endpoint + ALB
- Problem:
- Manual Scaling: Managing multiple model copies and an ALB adds complexity without automated scaling.
- Inefficient Cost: Redundant copies and ALB costs negate savings compared to auto scaling.
---
### Conclusion
Option D is the only solution that combines cost efficiency, scalability, and peak readiness. SageMaker auto scaling dynamically adjusts resources based on live traffic, ensuring optimal performance during demand spikes and minimizing costs during idle periods. Alternatives like Lambda (A) or static architectures (B, C) fail to address either cost or scalability effectively.
A company uses Amazon SageMaker Studio to develop an ML model. The company has a single SageMaker Studio domain. An ML engineer needs to implement a solution that provides an automated alert when SageMaker compute costs reach a specific threshold.
Which solution will meet these requirements?
A. Add resource tagging by editing the SageMaker user profile in the SageMaker domain. Configure AWS Cost Explorer to send an alert when the threshold is reached.
B. Add resource tagging by editing the SageMaker user profile in the SageMaker domain. Configure AWS Budgets to send an alert when the threshold is reached.
C. Add resource tagging by editing each user's IAM profile. Configure AWS Cost Explorer to send an alert when the threshold is reached.
D. Add resource tagging by editing each user's IAM profile. Configure AWS Budgets to send an alert when the threshold is reached.
Answer:
B. Add resource tagging by editing the SageMaker user profile in the SageMaker domain. Configure AWS Budgets to send an alert when the threshold is reached.
---
### Detailed Explanation
#### Requirements Summary
1. Automated Cost Alerts: Trigger notifications when SageMaker compute costs reach a predefined threshold.
2. Centralized Tagging: Apply cost-tracking tags to SageMaker resources (e.g., notebook instances, training jobs) to monitor usage.
---
### Analysis of the Correct Answer
##### Why SageMaker User Profiles + AWS Budgets Works
1. Resource Tagging via SageMaker User Profiles:
- SageMaker Studio allows tagging at the user profile level. Tags added to a user profile propagate to all resources (e.g., notebooks, training jobs) created by that user.
- Example: Tagging a user profile with CostCenter=MLTeam ensures all compute resources inherit this tag, enabling granular cost tracking.
2. AWS Budgets for Alerts:
- AWS Budgets monitors costs in real time and sends alerts via Amazon SNS when costs exceed a threshold.
- Configure a custom budget with filters for SageMaker services and specific tags (e.g., CostCenter=MLTeam).
##### Why It Meets the Requirements
- Automated Alerts:
AWS Budgets proactively notifies stakeholders (e.g., via email or Slack) when SageMaker compute costs near or exceed the threshold.
- Cost Visibility:
Tags enable precise cost allocation to teams, projects, or users, ensuring accountability and accurate monitoring.
---
### Key Differentiators for Option B
- Centralized Tag Management:
Tags applied at the SageMaker user profile level ensure consistency across all resources, avoiding manual tagging per user or resource.
- Proactive Cost Governance:
AWS Budgets is purpose-built for threshold-based alerts, unlike Cost Explorer, which focuses on historical analysis.
---
### Analysis of Incorrect Options
##### A/C: AWS Cost Explorer Alerts
- Problem:
- Cost Explorer alerts are retrospective (triggered after costs are incurred), whereas AWS Budgets provides proactive alerts based on forecasted or real-time spending.
##### C/D: IAM Profile Tagging
- Problem:
- IAM tags apply to IAM roles/users but do not propagate to SageMaker resources (e.g., training jobs, notebook instances). This fails to link compute costs to specific users or teams.
##### D: IAM Profiles + AWS Budgets
- Limitation:
- Even with AWS Budgets, IAM tags cannot track SageMaker compute costs directly, as SageMaker resources do not inherit IAM user tags by default.
---
### Conclusion
Option B is the only solution that ensures automated, proactive cost alerts for SageMaker compute usage. By tagging resources at the SageMaker user profile level and leveraging AWS Budgets, the company achieves granular cost tracking and threshold-based notifications. Other options either lack proactive alerts (A/C) or fail to tag resources effectively (C/D).
A company uses Amazon SageMaker for its ML workloads. The company's ML engineer receives a 50 MB Apache Parquet data file to build a fraud detection model. The file includes several correlated columns that are not required.
What should the ML engineer do to drop the unnecessary columns in the file with the LEAST effort?
A. Download the file to a local workstation. Perform one-hot encoding by using a custom Python script.
B. Create an Apache Spark job that uses a custom processing script on Amazon EMR.
C. Create a SageMaker processing job by calling the SageMaker Python SDK.
D. Create a data flow in SageMaker Data Wrangler. Configure a transform step.
Answer:
D. Create a data flow in SageMaker Data Wrangler. Configure a transform step.
---
### Detailed Explanation
#### Requirements Summary
1. Drop Unnecessary Columns: Remove correlated columns from a 50 MB Parquet file.
2. Minimal Effort: Avoid complex scripting, infrastructure setup, or manual data transfers.
---
### Analysis of the Correct Answer
##### Why SageMaker Data Wrangler Is Optimal
1. No-Code Data Transformation:
- Visual Interface: Data Wrangler provides a point-and-click interface to import the Parquet file, view columns, and select/drop unwanted columns.
- Built-in "Drop Column" Transform: Select the columns to remove and apply the transform with one click.
2. Direct Integration with SageMaker:
- Import data directly from Amazon S3 (no need to download the file).
- Process the 50 MB file in-memory without provisioning clusters or writing code.
3. Automated Export:
- Export the cleaned dataset back to S3 or use it directly in SageMaker Pipelines for model training.
##### Why It Meets the Requirements
- Zero Scripting: Eliminates the need for Python/Spark code.
- No Infrastructure Management: Data Wrangler runs entirely within SageMaker Studio, avoiding EMR clusters or processing jobs.
---
### Key Differentiators for Option D
- Speed and Simplicity:
Complete the task in minutes using pre-built transforms instead of hours coding/testing scripts.
- End-to-End Workflow:
Integrates with other SageMaker services (e.g., training jobs) for seamless ML workflows.
---
### Analysis of Incorrect Options
##### A. Local Python Script
- Problem:
- Requires downloading data to a workstation, writing code, and re-uploading. Adds unnecessary steps and risks data mishandling.
- One-hot encoding is irrelevant to dropping columns.
##### B. Apache Spark on EMR
- Problem:
- Overkill for a 50 MB file. Spark/EMR introduces cluster setup, job configuration, and cost overhead for a simple task.
##### C. SageMaker Processing Job
- Problem:
- Requires writing a custom script and configuring a processing job. More effort than Data Wrangler’s visual transforms.
---
### Conclusion
Option D is the fastest and simplest solution. SageMaker Data Wrangler’s visual interface allows the ML engineer to drop columns in a few clicks without coding or infrastructure management. Alternatives involve unnecessary complexity (B, C) or manual steps (A).
An ML engineer needs to use Amazon SageMaker to fine-tune a large language model (LLM) for text summarization. The ML engineer must follow a low-code no-code (LCNC) approach.
Which solution will meet these requirements?
A. Use SageMaker Studio to fine-tune an LLM that is deployed on Amazon EC2 instances.
B. Use SageMaker Autopilot to fine-tune an LLM that is deployed by a custom API endpoint.
C. Use SageMaker Autopilot to fine-tune an LLM that is deployed on Amazon EC2 instances.
D. Use SageMaker Autopilot to fine-tune an LLM that is deployed by SageMaker JumpStart.
Answer:
D. Use SageMaker Autopilot to fine-tune an LLM that is deployed by SageMaker JumpStart.
---
### Detailed Explanation
#### Requirements Summary
1. Low-Code/No-Code (LCNC) Approach: Minimize manual scripting or infrastructure management for fine-tuning an LLM.
2. Text Summarization Task: Fine-tune a pre-trained LLM for a specific NLP use case.
---
### Analysis of the Correct Answer
##### Why SageMaker Autopilot + JumpStart Works
1. SageMaker JumpStart:
- Provides pre-trained LLMs (e.g., GPT, BERT, T5) optimized for tasks like text summarization.
- Offers one-click fine-tuning workflows with minimal code. Users select the model, upload training data, and configure hyperparameters via a visual interface.
2. SageMaker Autopilot:
- Automates model tuning and training. While Autopilot is traditionally used for tabular data, when combined with JumpStart, it streamlines LLM fine-tuning by:
- Automatically provisioning compute resources.
- Handling distributed training and hyperparameter optimization (HPO).
- Requires only defining the task (text summarization) and dataset.
##### Why It Meets the Requirements
- LCNC Workflow:
JumpStart abstracts away model architecture and training code, while Autopilot automates infrastructure and tuning. Together, they enable fine-tuning with minimal coding.
- Pre-Built LLM Integration:
JumpStart includes LLMs pre-configured for NLP tasks, eliminating the need to manually implement architectures or tokenization.
---
### Key Differentiators for Option D
- End-to-End Automation:
Combines JumpStart’s pre-trained models with Autopilot’s automated tuning, aligning with LCNC principles.
- No Infrastructure Management:
Both services handle resource provisioning, scaling, and optimization behind the scenes.
---
### Analysis of Incorrect Options
##### A/B/C: EC2 Instances or Custom API Endpoints
- Problem:
- Deploying models on EC2 or custom endpoints requires manual infrastructure setup, scripting, and monitoring, violating the LCNC requirement.
- Autopilot alone is not designed for LLM fine-tuning; it focuses on tabular data and classical ML models.
---
### Conclusion
Option D is the only solution that enables low-code/no-code LLM fine-tuning. By leveraging SageMaker JumpStart’s pre-configured LLMs and Autopilot’s automation, the engineer can fine-tune a model for text summarization without writing training scripts or managing infrastructure. Other options require significant coding and manual effort.
A company has an ML model that needs to run one time each night to predict stock values. The model input is 3 MB of data that is collected during the current day. The model produces the predictions for the next day. The prediction process takes less than 1 minute to finish running.
How should the company deploy the model on Amazon SageMaker to meet these requirements?
A. Use a multi-model serverless endpoint. Enable caching.
B. Use an asynchronous inference endpoint. Set the InitialInstanceCount parameter to 0.
C. Use a real-time endpoint. Configure an auto scaling policy to scale the model to 0 when the model is not in use.
D. Use a serverless inference endpoint. Set the MaxConcurrency parameter to 1.
Answer:
D. Use a serverless inference endpoint. Set the MaxConcurrency parameter to 1.
---
### Detailed Explanation
#### Requirements Summary
1. Sporadic Usage: The model runs once nightly with minimal compute demands.
2. Cost Efficiency: Avoid paying for idle infrastructure when the model is inactive (23+ hours/day).
3. Low Latency: Ensure predictions complete within 1 minute.
---
### Analysis of the Correct Answer
##### Why Serverless Inference Is Optimal
1. Automatic Scaling to Zero:
- Serverless endpoints scale to zero when inactive, eliminating costs outside of inference requests.
- No charges for idle instances, making it ideal for infrequent, predictable workloads.
2. Pay-Per-Use Pricing:
- Costs accrue only during the <1-minute nightly inference, billed per millisecond of compute time.
3. Simplified Configuration:
- MaxConcurrency=1 ensures only one request is processed at a time, matching the once-daily requirement.
##### Why It Meets the Requirements
- Zero Idle Costs:
No persistent instances are provisioned, aligning with the need to run the model only once daily.
- Minimal Overhead:
Serverless endpoints handle infrastructure provisioning, scaling, and maintenance automatically.
---
### Key Differentiators for Option D
- Purpose-Built for Intermittent Workloads:
Serverless inference is designed for scenarios with long idle periods and bursty traffic.
- No Cold Start Concerns:
With a nightly schedule, the brief startup time (~10–20 seconds) for the first request is negligible.
---
### Analysis of Incorrect Options
##### A. Multi-Model Serverless Endpoint
- Problem:
- Unnecessary complexity for a single model. Multi-model endpoints are optimized for serving multiple models concurrently.
- Caching provides no benefit for a once-daily job.
##### B. Asynchronous Inference Endpoint
- Problem:
- Designed for large payloads or long processing times (up to 15 minutes). Overkill for a 3 MB input and 1-minute task.
- Requires managing an S3 bucket for input/output, adding operational overhead.
##### C. Real-Time Endpoint with Auto Scaling
- Problem:
- Real-time endpoints cannot scale to zero instances. Minimum instance count is 1, incurring costs even when idle.
- Auto scaling adjusts instance counts but cannot fully eliminate idle costs for daily usage.
---
### Conclusion
Option D is the most cost-effective and operationally simple solution. By using a serverless inference endpoint, the company pays only for the brief nightly inference window, with no charges during idle periods. Other options either incur continuous costs (C), introduce unnecessary complexity (A), or are mismatched to the workload (B).
An ML engineer trained an ML model on Amazon SageMaker to detect automobile accidents from dosed-circuit TV footage. The ML engineer used SageMaker Data Wrangler to create a training dataset of images of accidents and non-accidents.
The model performed well during training and validation. However, the model is underperforming in production because of variations in the quality of the images from various cameras.
Which solution will improve the model's accuracy in the LEAST amount of time?
A. Collect more images from all the cameras. Use Data Wrangler to prepare a new training dataset.
B. Recreate the training dataset by using the Data Wrangler corrupt image transform. Specify the impulse noise option.
C. Recreate the training dataset by using the Data Wrangler enhance image contrast transform. Specify the Gamma contrast option.
D. Recreate the training dataset by using the Data Wrangler resize image transform. Crop all images to the same size.
Answer:
C. Recreate the training dataset by using the Data Wrangler enhance image contrast transform. Specify the Gamma contrast option.
---
### Detailed Explanation
#### Requirements Summary
1. Improve Production Accuracy: Address model underperformance caused by variations in CCTV image quality (e.g., lighting, contrast, brightness).
2. Minimize Time and Effort: Avoid lengthy data collection or retraining from scratch.
---
### Analysis of the Correct Answer
##### What It Does
- Enhance Image Contrast (Gamma Correction):
- Gamma Contrast Transform: Adjusts pixel intensity values using a non-linear operation:
\[
\text{Output Pixel} = \text{Input Pixel}^{\gamma}
\]
- Gamma < 1: Brightens dark regions (useful for underexposed CCTV footage).
- Gamma > 1: Darkens bright regions (useful for overexposed footage).
- Normalizes Lighting Variations: Compensates for inconsistent lighting across CCTV cameras by standardizing image brightness and contrast.
##### Why It Meets the Requirements
1. Targets Root Cause:
- CCTV cameras often produce images with varying exposure levels (e.g., dark nighttime footage vs. bright daylight clips). Gamma correction homogenizes these variations, making the training data more representative of real-world inputs.
2. Quick Implementation:
- Applying Gamma contrast in SageMaker Data Wrangler requires one transform step (no new data collection or model retraining).
3. Domain Adaptation:
- Enhances the model’s ability to generalize across diverse image qualities, directly addressing the production performance gap.
---
### Key Differentiators for Option C
- Preprocessing Over Retraining:
Fixes data distribution mismatches (training vs. production) without altering the model architecture or hyperparameters.
- Data Wrangler Efficiency:
Integrates seamlessly with existing workflows, applying Gamma correction at scale to the entire dataset.
---
### Analysis of Incorrect Options
##### A. Collect More Images
- Problem:
- Time-Consuming: Collecting and labeling new data from all CCTV cameras delays improvements.
- Doesn’t Address Quality Variations: Adding more images without preprocessing perpetuates inconsistencies.
##### B. Corrupt Image Transform (Impulse Noise)
- Problem:
- Irrelevant Noise Injection: Impulse noise (e.g., "salt-and-pepper" artifacts) simulates sensor errors, not lighting variations. This worsens data quality instead of improving it.
##### D. Resize/Crop Images
- Problem:
- Fails to Normalize Lighting: Resizing standardizes dimensions but ignores pixel intensity variations (e.g., dark vs. bright regions).
---
### Conclusion
Option C is the fastest and most effective solution. By applying Gamma contrast in Data Wrangler, the ML engineer standardizes image brightness and contrast across the training dataset, ensuring the model generalizes to diverse CCTV camera outputs. This preprocessing step directly addresses the root cause of production underperformance without requiring new data or complex retraining. Alternatives like noise injection (B) or resizing (D) fail to resolve lighting issues, while data collection (A) introduces unnecessary delays.
A company has an application that uses different APIs to generate embeddings for input text. The company needs to implement a solution to automatically rotate the API tokens every 3 months.
Which solution will meet this requirement?
A. Store the tokens in AWS Secrets Manager. Create an AWS Lambda function to perform the rotation.
B. Store the tokens in AWS Systems Manager Parameter Store. Create an AWS Lambda function to perform the rotation.
C. Store the tokens in AWS Key Management Service (AWS KMS). Use an AWS managed key to perform the rotation.
D. Store the tokens in AWS Key Management Service (AWS KMS). Use an AWS owned key to perform the rotation.
Answer:
A. Store the tokens in AWS Secrets Manager. Create an AWS Lambda function to perform the rotation.
---
### Detailed Explanation
#### Requirements Summary
1. Automated Token Rotation: Rotate API tokens every 3 months without manual intervention.
2. Secure Storage: Safely store tokens and ensure they are encrypted.
3. Integration with Rotation Logic: Execute custom rotation workflows (e.g., generating new tokens, updating APIs).
---
### Analysis of the Correct Answer
##### What It Does
- AWS Secrets Manager:
- Secure Storage: Encrypts API tokens at rest using AWS KMS keys.
- Automatic Rotation: Supports scheduled rotation of secrets (e.g., API tokens) via built-in integration with AWS Lambda.
- Lambda Function:
- Triggers a custom Lambda function to generate a new token, update the external API, and store the new token in Secrets Manager.
- Handles rotation steps (createSecret, setSecret, testSecret, finishSecret) as part of the rotation workflow.
##### Why It Meets the Requirements
1. Automated Rotation:
- Secrets Manager schedules token rotation every 3 months and invokes the Lambda function to execute the rotation logic.
2. Security:
- Tokens are encrypted and access-controlled via IAM policies, ensuring only authorized services/applications can retrieve them.
3. Custom Workflows:
- The Lambda function can interact with external APIs to invalidate old tokens and activate new ones.
---
### Key Differentiators for Option A
- Native Rotation Support:
Secrets Manager is purpose-built for secret rotation, unlike Parameter Store or KMS, which lack built-in rotation automation.
- End-to-End Encryption:
Secrets Manager uses AWS KMS under the hood, ensuring tokens are encrypted in transit and at rest.
---
### Analysis of Incorrect Options
##### B. Systems Manager Parameter Store + Lambda
- Problem:
- No Native Rotation: Parameter Store can store secrets but requires manual or custom-triggered rotation (e.g., EventBridge cron jobs).
- Limited Secret Management: Designed for configuration data, not dedicated secret rotation workflows.
##### C/D. AWS KMS with Managed/Owned Keys
- Problem:
- KMS Manages Encryption Keys, Not Tokens: KMS is used to encrypt/decrypt data, not store or rotate API tokens.
- Key Rotation ≠ Token Rotation: KMS key rotation (e.g., yearly) does not generate new API tokens or update external systems.
---
### Conclusion
Option A is the only solution that combines secure storage, automated rotation, and custom workflows for API tokens. Secrets Manager’s native rotation capabilities and Lambda integration streamline the process, ensuring tokens are refreshed every 3 months without manual effort. Alternatives like Parameter Store (B) or KMS (C/D) lack the automation and purpose-built features required for this use case.
An ML engineer receives datasets that contain missing values, duplicates, and extreme outliers. The ML engineer must consolidate these datasets into a single data frame and must prepare the data for ML.
Which solution will meet these requirements?
A. Use Amazon SageMaker Data Wrangler to import the datasets and to consolidate them into a single data frame. Use the cleansing and enrichment functionalities to prepare the data.
B. Use Amazon SageMaker Ground Truth to import the datasets and to consolidate them into a single data frame. Use the human-in-the-loop capability to prepare the data.
C. Manually import and merge the datasets. Consolidate the datasets into a single data frame. Use Amazon Q Developer to generate code snippets that will prepare the data.
D. Manually import and merge the datasets. Consolidate the datasets into a single data frame. Use Amazon SageMaker data labeling to prepare the data.
Answer:
A. Use Amazon SageMaker Data Wrangler to import the datasets and to consolidate them into a single data frame. Use the cleansing and enrichment functionalities to prepare the data.
---
### Detailed Explanation
#### Requirements Summary
1. Data Consolidation: Merge multiple datasets into a single dataframe.
2. Data Preparation: Address missing values, duplicates, and outliers to ensure the dataset is ML-ready.
3. Efficiency: Minimize manual effort and leverage automated tools.
---
### Analysis of the Correct Answer
##### What It Does
- Amazon SageMaker Data Wrangler:
- Data Import and Consolidation:
- Import datasets from various sources (e.g., S3, databases) directly into Data Wrangler.
- Use visual transforms like Join, Union, or Append to merge datasets into a single dataframe.
- Data Cleansing and Enrichment:
- Missing Values: Apply built-in transforms to fill (e.g., mean/median imputation) or drop missing values.
- Duplicates: Use the Drop Duplicates transform to remove redundant rows.
- Outliers: Apply filters (e.g., Z-score, IQR) or transformations (e.g., winsorization) to handle extreme values.
- Visual Workflow:
- Design and execute the entire data preparation pipeline via a no-code interface.
##### Why It Meets the Requirements
1. Automated Consolidation:
- Data Wrangler simplifies merging datasets without writing custom code (e.g., SQL joins or Pandas operations).
2. Comprehensive Cleaning:
- Pre-built transforms address all data issues (missing values, duplicates, outliers) in a unified workflow.
3. Scalability:
- Handles large datasets efficiently using Spark under the hood, even for distributed processing.
---
### Key Differentiators for Option A
- End-to-End Data Prep:
Combines data ingestion, merging, and cleansing in a single tool, reducing manual effort.
- No-Code/Low-Code:
Eliminates the need for manual scripting, making it accessible for users with limited coding expertise.
---
### Analysis of Incorrect Options
##### B. SageMaker Ground Truth + Human-in-the-Loop
- Problem:
- Ground Truth is designed for data labeling (e.g., annotating images/text), not data cleaning or consolidation.
- Human-in-the-loop is unnecessary for handling missing values or duplicates, which are deterministic tasks.
##### C. Manual Merge + Amazon Q Developer
- Problem:
- Manual Merging: Consolidating datasets manually (e.g., via Pandas) is error-prone and time-consuming.
- Code Generation Overhead: While Amazon Q can generate code snippets, it still requires manual implementation and debugging.
##### D. Manual Merge + SageMaker Data Labeling
- Problem:
- Irrelevant Tool: Data labeling addresses annotation, not data cleansing. Outliers and duplicates require preprocessing, not human labeling.
---
### Conclusion
Option A is the only solution that efficiently consolidates and cleans datasets using a unified, automated workflow. SageMaker Data Wrangler’s no-code interface and built-in transforms directly address missing values, duplicates, and outliers, ensuring the data is ML-ready with minimal effort. Alternatives like manual merging (C, D) or labeling tools (B) fail to streamline the process and introduce unnecessary complexity.
A company has historical data that shows whether customers needed long-term support from company staff. The company needs to develop an ML model to predict whether new customers will require long-term support.
Which modeling approach should the company use to meet this requirement?
A. Anomaly detection
B. Linear regression
C. Logistic regression
D. Semantic segmentation
Answer:
C. Logistic regression
---
### Detailed Explanation
#### Requirements Summary
1. Binary Classification: Predict a categorical outcome (yes/no) indicating whether new customers will require long-term support.
2. Historical Data Utilization: Leverage labeled historical data to train the model.
---
### Analysis of the Correct Answer
##### Why Logistic Regression Works
- Binary Classification:
- Logistic regression models the probability of a binary outcome (e.g., "needs support" vs. "does not need support") using a logistic function.
- Formula:
P(y=1) = 1 / (1+ e−(β0+β1x1+⋯+βnxn))
Where P(y=1) is the probability of requiring long-term support.
- Interpretability:
- Provides coefficients that quantify the impact of each feature (e.g., customer age, interaction history) on the likelihood of needing support.
##### Why It Meets the Requirements
1. Directly Addresses Binary Prediction:
- The problem requires a yes/no prediction, which logistic regression is explicitly designed to handle.
2. Works with Tabular Data:
- Logistic regression performs well on structured, tabular datasets (e.g., customer demographics, transaction history).
---
### Key Differentiators for Option C
- Optimized for Probability Estimation:
Unlike linear regression, logistic regression outputs probabilities bounded between 0 and 1, making it ideal for classification.
- Efficiency:
Fast to train and deploy, even with large datasets.
---
### Analysis of Incorrect Options
##### A. Anomaly Detection
- Problem:
- Anomaly detection identifies rare events or outliers (e.g., fraud), not binary classification. Irrelevant for predicting a common categorical outcome.
##### B. Linear Regression
- Problem:
- Predicts continuous numerical values (e.g., sales revenue), not discrete classes. While it can technically output probabilities, it violates regression assumptions (unbounded output) and performs poorly for classification.
##### D. Semantic Segmentation
- Problem:
- Used in computer vision to classify pixels in images (e.g., identifying objects in photos). Not applicable to tabular customer data.
---
### Conclusion
Option C (Logistic Regression) is the only appropriate approach for predicting a binary outcome like customer support needs. It leverages historical data to estimate probabilities, provides interpretable results, and aligns with the problem’s classification nature. Anomaly detection (A) and semantic segmentation (D) are domain-mismatched, while linear regression (B) is statistically unsuited for categorical targets.
An ML engineer has developed a binary classification model outside of Amazon SageMaker. The ML engineer needs to make the model accessible to a SageMaker Canvas user for additional tuning.
The model artifacts are stored in an Amazon S3 bucket. The ML engineer and the Canvas user are part of the same SageMaker domain.
Which combination of requirements must be met so that the ML engineer can share the model with the Canvas user? (Choose two.)
A. The ML engineer and the Canvas user must be in separate SageMaker domains.
B. The Canvas user must have permissions to access the S3 bucket where the model artifacts are stored.
C. The model must be registered in the SageMaker Model Registry.
D. The ML engineer must host the model on AWS Marketplace.
E. The ML engineer must deploy the model to a SageMaker endpoint.
Answer:
B. The Canvas user must have permissions to access the S3 bucket where the model artifacts are stored.
C. The model must be registered in the SageMaker Model Registry.
---
### Detailed Explanation
#### Requirements Summary
1. Cross-Team Model Sharing: Enable a SageMaker Canvas user to access and tune a binary classification model developed outside SageMaker.
2. SageMaker Domain Integration: Both users are part of the same SageMaker domain.
---
### Analysis of the Correct Answers
##### B. S3 Bucket Permissions
- What It Does:
- SageMaker Canvas requires read access to the S3 bucket storing the model artifacts (e.g., model.tar.gz, training scripts, dependencies).
- Without this access, Canvas cannot load the model for tuning or inference.
- Why It’s Required:
- Canvas uses the model artifacts to reconstruct the model environment (e.g., framework, dependencies) during tuning.
##### C. SageMaker Model Registry
- What It Does:
- The Model Registry catalogs models, versions, and metadata, enabling centralized governance and sharing within a SageMaker domain.
- Registering the model allows Canvas users to discover, import, and modify it via a no-code interface.
- Why It’s Required:
- Canvas integrates directly with the Model Registry to list available models. Unregistered models are not visible in Canvas.
---
### Key Differentiators
- B (S3 Permissions): Ensures the raw model artifacts are accessible to Canvas.
- C (Model Registry): Provides a managed workflow for sharing and versioning models within SageMaker.
---
### Analysis of Incorrect Options
##### A. Separate Domains
- Problem:
- Sharing models across domains is possible, but the question specifies the users are in the same domain. Separate domains are unnecessary and complicate access.
##### D. AWS Marketplace
- Problem:
- AWS Marketplace is for public/private model sharing outside the organization. Irrelevant for internal sharing within a SageMaker domain.
##### E. SageMaker Endpoint
- Problem:
- Hosting the model on an endpoint is required for real-time inference but not for sharing or tuning in Canvas.
---
### Conclusion
To share the model with a Canvas user:
1. Register the model in the SageMaker Model Registry (C) to make it discoverable.
2. Grant S3 permissions (B) to ensure Canvas can access the model artifacts.
Other options (A, D, E) introduce unnecessary steps or misalign with the use case.
A company is building a deep learning model on Amazon SageMaker. The company uses a large amount of data as the training dataset. The company needs to optimize the model's hyperparameters to minimize the loss function on the validation dataset.
Which hyperparameter tuning strategy will accomplish this goal with the LEAST computation time?
A. Hyperband
B. Grid search
C. Bayesian optimization
D. Random search
Answer:
A. Hyperband
---
### Detailed Explanation
#### Requirements Summary
1. Optimize Hyperparameters: Minimize validation loss by efficiently tuning hyperparameters.
2. Minimize Computation Time: Reduce resource usage and training duration for a large dataset.
---
### Analysis of the Correct Answer
##### What Hyperband Does
- Bandit-Based Resource Allocation:
- Hyperband dynamically allocates computational resources by running multiple trials (hyperparameter configurations) in parallel.
- Uses successive halving to terminate underperforming trials early, reallocating resources to promising configurations.
- Early Stopping:
- Poorly performing trials are stopped after a few epochs, preventing wasted compute on configurations unlikely to succeed.
##### Why It Minimizes Computation Time
1. Eliminates Inefficient Trials:
- Early stopping reduces the total number of epochs run for poor configurations. For example, a trial that would take 100 epochs might be stopped after 10 if it performs poorly.
2. Parallel Exploration:
- Tests many configurations simultaneously, leveraging distributed training resources efficiently.
---
### Key Differentiators for Option A
- Adaptive Resource Allocation:
Prioritizes promising hyperparameter configurations early, avoiding exhaustive training of all candidates.
- Scalability:
Particularly effective for large datasets and deep learning models, where training each trial to completion is costly.
---
### Analysis of Incorrect Options
##### B. Grid Search
- Problem:
- Exhaustively tests every combination in a predefined grid. For \(N\) hyperparameters with \(k\) values each, this requires \(k^N\) trials.
- Computationally prohibitive for large datasets or high-dimensional hyperparameter spaces.
##### C. Bayesian Optimization
- Problem:
- Uses probabilistic models to guide hyperparameter selection but trains each trial to completion.
- Lacks early stopping, leading to higher total compute time compared to Hyperband.
##### D. Random Search
- Problem:
- Randomly samples hyperparameters but trains all trials to completion.
- More efficient than grid search but still wastes resources on poor configurations.
---
### Conclusion
Hyperband (A) is the most efficient strategy for minimizing computation time. By terminating underperforming trials early and focusing resources on promising configurations, it achieves faster convergence to optimal hyperparameters compared to grid search (B), Bayesian optimization (C), or random search (D). This makes it ideal for large-scale deep learning tasks on SageMaker.
A company is planning to use Amazon Redshift ML in its primary AWS account. The source data is in an Amazon S3 bucket in a secondary account.
An ML engineer needs to set up an ML pipeline in the primary account to access the S3 bucket in the secondary account. The solution must not require public IPv4 addresses.
Which solution will meet these requirements?
A. Provision a Redshift cluster and Amazon SageMaker Studio in a VPC with no public access enabled in the primary account. Create a VPC peering connection between the accounts. Update the VPC route tables to remove the route to 0.0.0.0/0.
B. Provision a Redshift cluster and Amazon SageMaker Studio in a VPC with no public access enabled in the primary account. Create an AWS Direct Connect connection and a transit gateway. Associate the VPCs from both accounts with the transit gateway. Update the VPC route tables to remove the route to 0.0.0.0/0.
C. Provision a Redshift cluster and Amazon SageMaker Studio in a VPC in the primary account. Create an AWS Site-to-Site VPN connection with two encrypted IPsec tunnels between the accounts. Set up interface VPC endpoints for Amazon S3.
D. Provision a Redshift cluster and Amazon SageMaker Studio in a VPC in the primary account. Create an S3 gateway endpoint. Update the S3 bucket policy to allow IAM principals from the primary account. Set up interface VPC endpoints for SageMaker and Amazon Redshift.
Answer:
D. Provision a Redshift cluster and Amazon SageMaker Studio in a VPC in the primary account. Create an S3 gateway endpoint. Update the S3 bucket policy to allow IAM principals from the primary account. Set up interface VPC endpoints for SageMaker and Amazon Redshift.
---
### Detailed Explanation
#### Requirements Summary
1. Cross-Account S3 Access: Allow Redshift ML and SageMaker in the primary account to securely access an S3 bucket in a secondary account.
2. No Public IPv4 Addresses: Ensure all communication occurs over private AWS networks.
---
### Analysis of the Correct Answer
##### What It Does
1. S3 Gateway Endpoint:
- Creates a private connection between the primary account’s VPC and Amazon S3, bypassing the public internet.
- Routes S3 traffic through AWS’s private backbone, eliminating the need for public IPs or NAT gateways.
2. Cross-Account Bucket Policy:
- The secondary account’s S3 bucket policy grants access to the primary account’s IAM principals (e.g., Redshift ML role, SageMaker execution role). Example policy snippet:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"AWS": "arn:aws:iam::PRIMARY_ACCOUNT_ID:root"},
"Action": ["s3:GetObject", "s3:ListBucket"],
"Resource": ["arn:aws:s3:::SECONDARY_BUCKET/*", "arn:aws:s3:::SECONDARY_BUCKET"]
}]
}3. Interface VPC Endpoints (PrivateLink):
- Amazon SageMaker and Redshift: Enable private connectivity to these services within the VPC, ensuring no public internet exposure.
##### Why It Meets the Requirements
- Private Network Connectivity:
- S3 gateway and interface VPC endpoints route traffic through AWS’s private network, avoiding public IPs.
- Cross-Account Access:
- Bucket policies and IAM roles enforce secure access without data replication or public exposure.
---
### Key Differentiators for Option D
- Simplified Architecture:
Uses native AWS services (VPC endpoints, IAM, S3 policies) without complex networking (e.g., VPN, Direct Connect).
- Cost Efficiency:
Avoids data transfer charges and infrastructure overhead of peering/VPN.
---
### Analysis of Incorrect Options
##### A. VPC Peering + Route Table Updates
- Problem:
- VPC peering connects VPCs but does not inherently grant S3 access. S3 is a regional service, not VPC-bound.
- Removing the default route (0.0.0.0/0) blocks internet access but does not resolve cross-account S3 access.
##### B. Direct Connect + Transit Gateway
- Problem:
- Overkill for cross-account S3 access. Direct Connect is for hybrid cloud (on-premises-to-AWS) connectivity, not inter-account S3.
- Transit Gateway adds unnecessary complexity and cost.
##### C. Site-to-Site VPN + Interface Endpoints
- Problem:
- VPNs are designed for connecting to on-premises networks, not cross-account AWS resources.
- Interface VPC endpoints for S3 are redundant if a gateway endpoint is already used.
---
### Conclusion
Option D is the most efficient and secure solution. By leveraging S3 gateway endpoints for private cross-account access and VPC interface endpoints for SageMaker/Redshift, the pipeline operates entirely within AWS’s private network. This satisfies the requirement to avoid public IPs while enabling seamless access to the secondary account’s S3 data. Other options introduce unnecessary complexity (A, B, C) or misalign with the use case.
A company is using an AWS Lambda function to monitor the metrics from an ML model. An ML engineer needs to implement a solution to send an email message when the metrics breach a threshold.
Which solution will meet this requirement?
A. Log the metrics from the Lambda function to AWS CloudTrail. Configure a CloudTrail trail to send the email message.
B. Log the metrics from the Lambda function to Amazon CloudFront. Configure an Amazon CloudWatch alarm to send the email message.
C. Log the metrics from the Lambda function to Amazon CloudWatch. Configure a CloudWatch alarm to send the email message.
D. Log the metrics from the Lambda function to Amazon CloudWatch. Configure an Amazon CloudFront rule to send the email message.
Answer:
C. Log the metrics from the Lambda function to Amazon CloudWatch. Configure a CloudWatch alarm to send the email message.
---
### Detailed Explanation
#### Requirements Summary
1. Monitor ML Metrics: Track model metrics (e.g., accuracy, latency) via a Lambda function.
2. Threshold-Based Alerts: Send email notifications when metrics breach predefined thresholds.
---
### Analysis of the Correct Answer
##### What It Does
1. Log Metrics to Amazon CloudWatch:
- The Lambda function publishes custom metrics to CloudWatch using the AWS SDK (e.g., put_metric_data).
- Example metric:
import boto3
cloudwatch = boto3.client('cloudwatch')
cloudwatch.put_metric_data(
Namespace='MLModelMetrics',
MetricData=[{
'MetricName': 'ErrorRate',
'Value': error_rate,
'Unit': 'Percent'
}]
)2. CloudWatch Alarm:
- Create an alarm in CloudWatch that triggers when the metric (e.g., ErrorRate) exceeds a threshold (e.g., >10%).
- Configure the alarm to send notifications via Amazon SNS (Simple Notification Service), which can forward emails to subscribers.
##### Why It Meets the Requirements
- Real-Time Monitoring:
CloudWatch collects metrics in real time, enabling immediate detection of threshold breaches.
- Automated Alerts:
SNS integrates with CloudWatch alarms to send emails without manual intervention.
---
### Key Differentiators for Option C
- Native AWS Integration:
CloudWatch is purpose-built for metric monitoring, while SNS handles notifications.
- Scalability:
Supports dynamic thresholds and multiple notification channels (e.g., email, SMS, Lambda).
---
### Analysis of Incorrect Options
##### A. CloudTrail for Metrics
- Problem:
- CloudTrail logs API activity (e.g., who created an S3 bucket), not application metrics. It cannot trigger alerts based on custom thresholds.
##### B/D. CloudFront for Metrics
- Problem:
- CloudFront is a content delivery network (CDN) for caching and distributing web content. It does not store or monitor application metrics.
---
### Conclusion
Option C is the only solution that directly addresses the requirement. By logging metrics to CloudWatch and configuring alarms with SNS, the ML engineer ensures timely email alerts when thresholds are breached. Other options misuse services (A, B, D) or lack the ability to trigger notifications.
A Machine Learning Specialist must build out a process to query a dataset on Amazon S3 using Amazon Athena. The dataset contains more than 800,000 records stored as plaintext CSV files. Each record contains 200 columns and is approximately 1.5 MB in size. Most queries will span 5 to 10 columns only.
How should the Machine Learning Specialist transform the dataset to minimize query runtime?
A. Convert the records to Apache Parquet format.
B. Convert the records to JSON format.
C. Convert the records to GZIP CSV format.
D. Convert the records to XML format.
Answer:
A. Convert the records to Apache Parquet format.
---
### Detailed Explanation
#### Requirements Summary
1. Minimize Query Runtime: Optimize Amazon Athena performance for queries that access 5–10 columns out of 200.
2. Reduce Data Scanned: Avoid reading unnecessary columns or rows.
3. Leverage Efficient Data Formats: Improve compression and query efficiency.
---
### Analysis of the Correct Answer
##### Why Apache Parquet Works
- Columnar Storage:
Parquet stores data by column (not row), enabling Athena to read only the columns referenced in the query. For a dataset with 200 columns, this reduces I/O by 95–97.5% when querying 5–10 columns.
- Compression:
Parquet uses efficient compression algorithms (e.g., Snappy, GZIP), shrinking file sizes and reducing the volume of data scanned.
- Predicate Pushdown:
Athena skips irrelevant data blocks using metadata (e.g., min/max values), further reducing scan time.
##### Why It Meets the Requirements
- Query Speed:
Columnar storage and compression reduce data scanned from 1.5 MB × 800,000 = 1.2 TB (CSV) to ~100–300 GB (Parquet), accelerating queries.
- Cost Efficiency:
Athena pricing is based on data scanned. Parquet cuts costs by up to 90%.
---
### Key Differentiators for Option A
- Columnar Optimization:
Unlike row-based formats (CSV, JSON, XML), Parquet aligns with Athena’s ability to skip unused columns.
- AWS Best Practice:
Amazon recommends Parquet for Athena to minimize costs and latency.
---
### Analysis of Incorrect Options
##### B. JSON Format
- Problem:
- Row-based structure forces Athena to scan all 200 columns, even when querying 5–10.
- Larger file sizes (JSON is verbose) increase scan time and costs.
##### C. GZIP CSV
- Problem:
- Compression reduces storage size but does not eliminate row-based scanning. Athena must decompress and process all columns.
##### D. XML Format
- Problem:
- Extremely verbose and complex to parse, increasing query runtime and costs.
---
### Conclusion
Apache Parquet (A) is the optimal format for minimizing Athena query runtime. By storing data column-wise and compressing it, Parquet reduces the volume of data scanned and accelerates queries. Alternatives like JSON (B), GZIP CSV (C), or XML (D) retain row-based inefficiencies and fail to address the core issue of column pruning.
A company has an ML model that generates text descriptions based on images that customers upload to the company's website. The images can be up to 50 MB in total size.
An ML engineer decides to store the images in an Amazon S3 bucket. The ML engineer must implement a processing solution that can scale to accommodate changes in demand.
Which solution will meet these requirements with the LEAST operational overhead?
A. Create an Amazon SageMaker batch transform job to process all the images in the S3 bucket.
B. Create an Amazon SageMaker Asynchronous Inference endpoint and a scaling policy. Run a script to make an inference request for each image.
C. Create an Amazon Elastic Kubernetes Service (Amazon EKS) cluster that uses Karpenter for auto scaling. Host the model on the EKS cluster. Run a script to make an inference request for each image.
D. Create an AWS Batch job that uses an Amazon Elastic Container Service (Amazon ECS) cluster. Specify a list of images to process for each AWS Batch job.
Answer:
B. Create an Amazon SageMaker Asynchronous Inference endpoint and a scaling policy. Run a script to make an inference request for each image.
---
### Detailed Explanation
#### Requirements Summary
1. Scalability: Handle fluctuating demand for image-to-text processing.
2. Operational Simplicity: Minimize infrastructure management.
3. Large Payload Support: Process images up to 50 MB in size.
---
### Analysis of the Correct Answer
##### Why SageMaker Asynchronous Inference Works
1. Managed Scaling:
- SageMaker Asynchronous Inference endpoints automatically scale instance counts based on the size of the request queue (via CloudWatch metrics like ApproximateBacklogSizePerInstance).
- A scaling policy ensures instances are added during demand spikes and removed during lulls, optimizing cost and performance.
2. Asynchronous Processing:
- Supports large payloads (up to 1 GB) and long processing times. Users upload images to S3, and the endpoint processes them asynchronously, returning results via S3 or Amazon SNS.
3. Low Overhead:
- SageMaker manages infrastructure provisioning, patching, and load balancing. The engineer only needs to deploy the model and configure scaling policies.
##### Why It Meets the Requirements
- Scalability:
Auto scaling adjusts capacity dynamically to match incoming request volume.
- Handles Large Images:
Asynchronous Inference decouples request submission from processing, avoiding timeouts for large payloads.
- No Infrastructure Management:
SageMaker handles instance lifecycle, reducing operational tasks like cluster setup or node tuning.
---
### Key Differentiators for Option B
- Serverless-Like Experience:
SageMaker abstracts server management, unlike EKS or AWS Batch, which require manual scaling and configuration.
- Cost Efficiency:
Pay only for active inference time, with no charges when the endpoint scales to zero during inactivity.
---
### Analysis of Incorrect Options
##### A. SageMaker Batch Transform
- Problem:
- Designed for batch processing fixed datasets, not real-time or on-demand requests. Requires manual job scheduling and cannot scale dynamically with demand.
##### C. Amazon EKS with Karpenter
- Problem:
- High Operational Overhead: Requires Kubernetes expertise to manage pods, deployments, and Karpenter configurations.
- Cold Starts: Scaling from zero adds latency, unlike SageMaker’s managed warm pools.
##### D. AWS Batch with ECS
- Problem:
- Batch-Centric: Suited for periodic bulk jobs, not dynamic request processing. Requires manual job submissions and compute environment management.
---
### Conclusion
Option B is the most efficient and scalable solution. SageMaker Asynchronous Inference endpoints handle variable demand automatically, process large payloads, and minimize operational overhead. Alternatives like Batch Transform (A), EKS (C), or AWS Batch (D) require manual scaling, lack real-time responsiveness, or introduce infrastructure management complexity.
An agency collects census information within a country to determine healthcare and social program needs by province and city. The census form collects responses for approximately 500 questions from each citizen.
Which combination of algorithms would provide the appropriate insights? (Choose two.)
A. The factorization machines (FM) algorithm
B. The Latent Dirichlet Allocation (LDA) algorithm
C. The principal component analysis (PCA) algorithm
D. The k-means algorithm
E. The Random Cut Forest (RCF) algorithm
Answer:
C. The principal component analysis (PCA) algorithm
D. The k-means algorithm
---
### Detailed Explanation
#### Requirements Summary
1. High-Dimensional Data: Census responses include 500 variables per citizen.
2. Regional Insights: Group provinces/cities into clusters with similar healthcare and social program needs.
3. Actionable Patterns: Reduce data complexity and identify trends for policy decisions.
---
### Analysis of the Correct Answers
##### C. Principal Component Analysis (PCA)
- What It Does:
- Reduces the dimensionality of the 500-variable dataset by identifying orthogonal components (principal components) that capture the maximum variance.
- Simplifies data while preserving critical patterns, enabling efficient analysis.
- Why It’s Needed:
- Directly analyzing 500 variables is computationally intensive and prone to noise. PCA extracts key latent factors (e.g., "socioeconomic status," "health indicators") for clearer insights.
##### D. k-means Algorithm
- What It Does:
- Clusters provinces/cities into groups based on similarity in their PCA-transformed features.
- Identifies regions with comparable needs (e.g., high healthcare demand, low education access).
- Why It’s Needed:
- Enables targeted resource allocation by grouping regions with similar census-derived characteristics.
---
### Key Workflow
1. PCA: Reduce 500 variables to 10–20 principal components (retaining ~90% variance).
2. k-means: Cluster regions using the reduced components to identify patterns (e.g., urban vs. rural needs).
---
### Why Other Options Fail
- A. Factorization Machines (FM): Designed for supervised learning (e.g., recommendation systems), not unsupervised clustering or dimensionality reduction.
- B. Latent Dirichlet Allocation (LDA): Topic modeling for text data, irrelevant to numerical census responses.
- E. Random Cut Forest (RCF): Anomaly detection, not suited for grouping regions or reducing dimensionality.
---
### Conclusion
PCA (C) and k-means (D) provide a streamlined pipeline to simplify high-dimensional census data and derive actionable regional clusters. This approach minimizes noise, optimizes computation, and aligns with the goal of identifying province/city-specific needs.
A company needs to give its ML engineers appropriate access to training data. The ML engineers must access training data from only their own business group. The ML engineers must not be allowed to access training data from other business groups.
The company uses a single AWS account and stores all the training data in Amazon S3 buckets. All ML model training occurs in Amazon SageMaker.
Which solution will provide the ML engineers with the appropriate access?
A. Enable S3 bucket versioning.
B. Configure S3 Object Lock settings for each user.
C. Add cross-origin resource sharing (CORS) policies to the S3 buckets.
D. Create IAM policies. Attach the policies to IAM users or IAM roles.
Answer:
D. Create IAM policies. Attach the policies to IAM users or IAM roles.
---
### Detailed Explanation
#### Requirements Summary
1. Data Isolation: ML engineers must access training data only from their own business group.
2. Single AWS Account: All data resides in shared S3 buckets within one account.
3. Granular Access Control: Restrict access programmatically without compromising cross-group data.
---
### Analysis of the Correct Answer
##### How IAM Policies Work
1. Policy Design:
- Create IAM policies that grant access to S3 paths (prefixes or buckets) specific to each business group.
- Example policy for Business Group A:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:ListBucket"],
"Resource": [
"arn:aws:s3:::training-data/business-group-a/*",
"arn:aws:s3:::training-data/business-group-a"
]
}]
}2. IAM Roles/Users:
- Attach these policies to IAM roles assumed by SageMaker training jobs or directly to IAM users for engineers.
- Engineers inherit permissions based on their assigned role/user, ensuring they can only access their group’s data.
##### Why It Meets the Requirements
- Data Segregation:
Policies enforce strict boundaries between business groups’ S3 paths, preventing accidental or intentional cross-group access.
- Scalability:
Easily add new groups by creating new policies and assigning them to users/roles.
- Integration with SageMaker:
SageMaker training jobs use IAM roles to access S3, ensuring compliance with the policies during model training.
---
### Key Differentiators for Option D
- Fine-Grained Permissions:
IAM policies provide precise control over S3 objects, unlike bucket-wide settings (e.g., versioning, Object Lock).
- AWS Best Practice:
IAM is the standard method for enforcing least-privilege access in AWS.
---
### Analysis of Incorrect Options
##### A. S3 Versioning
- Problem:
- Tracks object versions but does not restrict access between business groups. Irrelevant to access control.
##### B. S3 Object Lock
- Problem:
- Prevents object deletion/modification (for compliance/retention) but does not isolate data by group.
##### C. CORS Policies
- Problem:
- Governs cross-origin web requests (e.g., browser-based access) but does not restrict IAM user/role permissions.
---
### Conclusion
Option D is the only solution that enforces business group data isolation in a single AWS account. By crafting IAM policies tied to S3 paths and assigning them to users/roles, the company ensures ML engineers access only their designated datasets. Other options (A, B, C) fail to address access control and focus on unrelated S3 features.
A company needs to host a custom ML model to perform forecast analysis. The forecast analysis will occur with predictable and sustained load during the same 2-hour period every day.
Multiple invocations during the analysis period will require quick responses. The company needs AWS to manage the underlying infrastructure and any auto scaling activities.
Which solution will meet these requirements?
A. Schedule an Amazon SageMaker batch transform job by using AWS Lambda.
B. Configure an Auto Scaling group of Amazon EC2 instances to use scheduled scaling.
C. Use Amazon SageMaker Serverless Inference with provisioned concurrency.
D. Run the model on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster on Amazon EC2 with pod auto scaling.
Answer:
C. Use Amazon SageMaker Serverless Inference with provisioned concurrency.
---
### Detailed Explanation
#### Requirements Summary
1. Predictable, Sustained Daily Load: Forecast analysis runs during a fixed 2-hour window with consistent traffic.
2. Quick Response Times: Low-latency inference during peak periods.
3. AWS-Managed Infrastructure: No operational overhead for scaling or server management.
---
### Analysis of the Correct Answer
##### Why SageMaker Serverless Inference with Provisioned Concurrency Works
1. Serverless Architecture:
- SageMaker Serverless Inference automatically provisions and scales compute resources based on incoming request volume.
- AWS fully manages infrastructure, including instance provisioning, patching, and termination.
2. Provisioned Concurrency:
- Pre-warms a specified number of instances before the 2-hour window to eliminate cold starts, ensuring immediate responsiveness.
- Scales to zero after the window, incurring no costs during idle periods.
3. Sustained Performance:
- Handles high-volume requests during predictable traffic spikes without manual scaling.
---
### Key Differentiators for Option C
- Managed Auto Scaling:
AWS dynamically adjusts capacity to match the 2-hour workload, ensuring consistent performance without manual intervention.
- Cost Efficiency:
Pay only for compute used during the 2-hour window, with no charges when idle.
---
### Analysis of Incorrect Options
##### A. SageMaker Batch Transform + Lambda
- Problem:
- Batch Transform is designed for offline bulk processing, not real-time inference. Latency is too high for quick responses.
- Requires manual scheduling and lacks auto scaling for dynamic traffic.
##### B. EC2 Auto Scaling Group
- Problem:
- Manual Infrastructure Management: Requires configuring EC2 instances, installing dependencies, and maintaining the ML environment.
- Over-provisioning risks during scaling, leading to higher costs.
##### D. EKS with Pod Auto Scaling
- Problem:
- Operational Overhead: Managing Kubernetes clusters (EKS) requires expertise in pods, nodes, and deployments.
- Cold starts and scaling delays persist unless pre-warming is manually configured.
---
### Conclusion
Option C is the only solution that meets all requirements:
- AWS-Managed Infrastructure: SageMaker Serverless Inference handles scaling, provisioning, and maintenance.
- Predictable Performance: Provisioned concurrency ensures zero cold starts during the 2-hour window.
- Cost Optimization: Resources scale to zero outside the usage window, minimizing expenses.
Alternatives like EC2 (B) or EKS (D) require manual infrastructure management, while Batch Transform (A) is unsuitable for real-time inference.
A company's ML engineer has deployed an ML model for sentiment analysis to an Amazon SageMaker endpoint. The ML engineer needs to explain to company stakeholders how the model makes predictions.
Which solution will provide an explanation for the model's predictions?
A. Use SageMaker Model Monitor on the deployed model.
B. Use SageMaker Clarify on the deployed model.
C. Show the distribution of inferences from A/В testing in Amazon CloudWatch.
D. Add a shadow endpoint. Analyze prediction differences on samples.
Answer:
B. Use SageMaker Clarify on the deployed model.
---
### Detailed Explanation
#### Requirements Summary
1. Explain Model Predictions: Provide interpretable insights into how the sentiment analysis model makes decisions.
2. Stakeholder Transparency: Highlight key features influencing predictions (e.g., specific words in text that drive sentiment scores).
---
### Analysis of the Correct Answer
##### What SageMaker Clarify Does
- Feature Attribution:
- Uses techniques like SHAP (SHapley Additive exPlanations) to quantify the contribution of each input feature (e.g., words, phrases) to the model’s prediction.
- Example: For a text input like "The product is excellent but delivery was slow", Clarify might attribute positive sentiment to "excellent" and negative sentiment to "slow".
- Global and Local Explanations:
- Global: Identifies overall important features across the dataset (e.g., "price" and "customer service" are key drivers of sentiment).
- Local: Explains individual predictions (e.g., why a specific review was classified as negative).
##### Why It Meets the Requirements
- Actionable Insights:
- Clarify generates visual reports (e.g., bar charts, heatmaps) showing feature importance, making it easy for stakeholders to understand model behavior.
- Integration with SageMaker Endpoints:
- Works seamlessly with deployed SageMaker endpoints to analyze live inference data without disrupting production traffic.
---
### Key Differentiators for Option B
- Purpose-Built for Explainability:
Unlike monitoring or A/B testing tools, Clarify is explicitly designed to interpret model predictions.
- Supports NLP Models:
Tailored for text-based models like sentiment analysis, providing token-level explanations.
---
### Analysis of Incorrect Options
##### A. SageMaker Model Monitor
- Problem:
- Focuses on detecting data drift, quality issues, or model performance degradation. Does not explain why a prediction was made.
##### C. CloudWatch Inference Distributions
- Problem:
- Shows metrics like latency or error rates but lacks feature-level explanations. Irrelevant to interpretability.
##### D. Shadow Endpoint Analysis
- Problem:
- Compares predictions between models but does not explain the reasoning behind individual predictions.
---
### Conclusion
SageMaker Clarify (B) is the only solution that directly addresses the need to explain model predictions. By leveraging SHAP values and generating interpretable reports, it provides stakeholders with clear, actionable insights into how features influence sentiment analysis results. Other options focus on monitoring (A, C) or validation (D), not explainability.
A company is running ML models on premises by using custom Python scripts and proprietary datasets. The company is using PyTorch. The model building requires unique domain knowledge. The company needs to move the models to AWS.
Which solution will meet these requirements with the LEAST effort?
A. Use SageMaker built-in algorithms to train the proprietary datasets.
B. Use SageMaker script mode and premade images for ML frameworks.
C. Build a container on AWS that includes custom packages and a choice of ML frameworks.
D. Purchase similar production models through AWS Marketplace.
Answer:
B. Use SageMaker script mode and premade images for ML frameworks.
---
### Detailed Explanation
#### Requirements Summary
1. Migrate On-Premises PyTorch Models to AWS: Transition custom PyTorch workflows with minimal rework.
2. Preserve Unique Domain Knowledge: Maintain proprietary logic and datasets.
3. Minimize Effort: Avoid rebuilding containers or retraining models from scratch.
---
### Analysis of the Correct Answer
##### Why SageMaker Script Mode Works
- Premade PyTorch Containers:
SageMaker provides prebuilt Docker images for PyTorch (and other frameworks), preconfigured with dependencies, CUDA, and SageMaker SDK integration.
- Custom Script Support:
- Retain existing PyTorch training/inference scripts.
- Pass scripts directly to SageMaker via PyTorch estimator:
from sagemaker.pytorch import PyTorch
estimator = PyTorch(
entry_point="custom_script.py", # Existing PyTorch code
role=IAM_ROLE,
framework_version="2.0.0",
instance_type="ml.g5.xlarge",
)
estimator.fit({"training": s3_input_data})- Managed Infrastructure:
SageMaker handles instance provisioning, scaling, logging, and model deployment, eliminating on-premises infrastructure management.
##### Why It Meets the Requirements
- Zero Code Rewrite:
Reuse existing PyTorch scripts with minor adjustments (e.g., SageMaker’s input/output paths).
- No Containerization Overhead:
Premade images eliminate the need to build, test, and maintain custom Docker containers.
- Domain Knowledge Retention:
Proprietary logic and datasets remain unchanged, ensuring continuity in model behavior.
---
### Key Differentiators for Option B
- Seamless PyTorch Integration:
Script mode is designed for custom code in popular frameworks, reducing migration friction.
- AWS-Managed Environment:
Focus on models, not infrastructure.
---
### Analysis of Incorrect Options
##### A. SageMaker Built-In Algorithms
- Problem:
Requires replacing custom PyTorch logic with predefined algorithms, which may not align with unique domain requirements.
##### C. Custom Containers
- Problem:
Overkill for PyTorch workflows. Premade images already include PyTorch and SageMaker SDK, making custom containers redundant.
##### D. AWS Marketplace Models
- Problem:
Marketplace models lack the company’s proprietary domain logic and would require retraining on sensitive datasets, increasing effort.
---
### Conclusion
Option B is the most efficient solution. By leveraging SageMaker Script Mode and premade PyTorch images, the company migrates its custom models to AWS with minimal code changes and no container development. This preserves domain-specific logic while offloading infrastructure management to AWS. Other options introduce unnecessary complexity (C), incompatibility (A), or loss of control (D).
A company is using Amazon SageMaker and millions of files to train an ML model. Each file is several megabytes in size. The files are stored in an Amazon S3 bucket. The company needs to improve training performance.
Which solution will meet these requirements in the LEAST amount of time?
A. Transfer the data to a new S3 bucket that provides S3 Express One Zone storage. Adjust the training job to use the new S3 bucket.
B. Create an Amazon FSx for Lustre file system. Link the file system to the existing S3 bucket. Adjust the training job to read from the file system.
C. Create an Amazon Elastic File System (Amazon EFS) file system. Transfer the existing data to the file system. Adjust the training job to read from the file system.
D. Create an Amazon ElastiCache (Redis OSS) cluster. Link the Redis OSS cluster to the existing S3 bucket. Stream the data from the Redis OSS cluster directly to the training job.
Answer:
B. Create an Amazon FSx for Lustre file system. Link the file system to the existing S3 bucket. Adjust the training job to read from the file system.
---
### Detailed Explanation
#### Requirements Summary
1. Improve Training Performance: Accelerate data access for millions of small files (several MB each) stored in Amazon S3.
2. Minimize Implementation Time: Avoid time-consuming data migration or complex reconfiguration.
---
### Analysis of the Correct Answer
##### Why Amazon FSx for Lustre Works
1. High-Performance File System:
- FSx for Lustre is optimized for low-latency, high-throughput access, ideal for ML training workloads requiring rapid I/O.
- Provides submillisecond latencies and hundreds of GB/s throughput, significantly outperforming direct S3 reads.
2. Seamless S3 Integration:
- FSx for Lustre can automatically sync with an existing S3 bucket, creating a POSIX-compliant file system that mirrors the S3 data.
- No manual data transfer is needed; FSx imports data on-demand or during initial setup.
3. SageMaker Integration:
- SageMaker training jobs can mount the FSx file system directly, enabling fast access to datasets without code changes.
##### Why It Meets the Requirements
- No Data Migration:
FSx links to the existing S3 bucket, eliminating time-consuming data transfers.
- Immediate Performance Gains:
Training jobs read from FSx instead of S3, reducing latency and improving throughput for small-file workloads.
---
### Key Differentiators for Option B
- Optimized for Small Files:
FSx for Lustre handles millions of small files efficiently, unlike S3 (object storage) or EFS (slower metadata performance).
- Zero Data Movement:
Retains the existing S3 bucket as the source of truth while leveraging FSx for accelerated access.
---
### Analysis of Incorrect Options
##### A. S3 Express One Zone
- Problem:
- Data Migration Overhead: Requires transferring millions of files to a new bucket, which is time-consuming.
- Object Storage Limitations: Even with higher throughput, S3 remains suboptimal for small-file, high-I/O workloads.
##### C. Amazon EFS
- Problem:
- Slower Metadata Performance: EFS struggles with metadata-heavy operations (e.g., listing/opening millions of small files).
- Data Transfer Delay: Moving data to EFS adds time and complexity.
##### D. Amazon ElastiCache (Redis)
- Problem:
- Mismatched Use Case: Redis is for in-memory key-value caching, not bulk file storage or ML training I/O.
- Complex Integration: Streaming files from Redis to SageMaker is non-standard and introduces latency.
---
### Conclusion
Option B is the fastest and most effective solution. By linking FSx for Lustre to the existing S3 bucket, the company achieves immediate performance improvements without data migration. FSx’s high-speed file system is purpose-built for ML training workloads with small files, reducing latency and maximizing throughput. Alternatives like S3 Express One Zone (A) or EFS (C) introduce delays, while ElastiCache (D) is unfit for the use case.
A company wants to develop an ML model by using tabular data from its customers. The data contains meaningful ordered features with sensitive information that should not be discarded. An ML engineer must ensure that the sensitive data is masked before another team starts to build the model.
Which solution will meet these requirements?
A. Use Amazon Made to categorize the sensitive data.
B. Prepare the data by using AWS Glue DataBrew.
C. Run an AWS Batch job to change the sensitive data to random values.
D. Run an Amazon EMR job to change the sensitive data to random values.
Answer:
B. Prepare the data by using AWS Glue DataBrew.
---
### Detailed Explanation
#### Requirements Summary
1. Mask Sensitive Data: Protect sensitive information in tabular customer data without discarding it.
2. Preserve Data Structure: Maintain meaningful ordered features for downstream ML model development.
3. Efficient Data Preparation: Ensure the masking process is secure, repeatable, and requires minimal coding.
---
### Analysis of the Correct Answer
##### Why AWS Glue DataBrew Works
1. No-Code Data Masking:
- DataBrew provides pre-built transformations (e.g., masking, redaction, hashing) to anonymize sensitive columns (e.g., PII, credit card numbers).
- Example: Replace a Social Security Number with XXX-XX-XXXX or hash email addresses to preserve uniqueness without exposing raw data.
2. Maintain Data Integrity:
- Transforms data in place, retaining the original structure and order of features critical for ML workflows.
- Supports schema enforcement to ensure no accidental data loss or corruption.
3. Workflow Automation:
- Create reusable recipes to apply masking rules consistently across datasets.
- Schedule jobs to process data automatically, ensuring masked datasets are ready for the next team.
##### Why It Meets the Requirements
- Compliance:
Masking ensures sensitive data is protected while retaining its utility for model training.
- Speed and Simplicity:
DataBrew’s visual interface eliminates coding effort, allowing rapid implementation compared to custom EMR/Batch jobs.
---
### Key Differentiators for Option B
- Purpose-Built for Data Preparation:
DataBrew is designed for secure, repeatable transformations, unlike Macie (A), which only identifies sensitive data.
- Managed Service:
Requires no infrastructure management, unlike AWS Batch (C) or EMR (D), which involve cluster setup and code development.
---
### Analysis of Incorrect Options
##### A. Amazon Macie
- Problem:
Macie identifies and classifies sensitive data but does not mask or transform it. It is irrelevant to the requirement of anonymizing data.
##### C/D. AWS Batch or EMR Jobs
- Problem:
- Custom Code Overhead: Require writing scripts for masking (e.g., using PySpark or Python), increasing development time and risk of errors.
- Infrastructure Management: Involve configuring compute environments (Batch) or clusters (EMR), adding unnecessary complexity.
---
### Conclusion
Option B is the optimal solution. AWS Glue DataBrew enables secure, no-code masking of sensitive data while preserving dataset structure for ML workflows. It eliminates manual coding and infrastructure management, aligning with the need for speed and compliance. Alternatives like Macie (A) fail to mask data, while Batch (C) and EMR (D) introduce unnecessary complexity.
An ML engineer needs to deploy ML models to get inferences from large datasets in an asynchronous manner. The ML engineer also needs to implement scheduled monitoring of the data quality of the models. The ML engineer must receive alerts when changes in data quality occur.
Which solution will meet these requirements?
A. Deploy the models by using scheduled AWS Glue jobs. Use Amazon CloudWatch alarms to monitor the data quality and to send alerts.
B. Deploy the models by using scheduled AWS Batch jobs. Use AWS CloudTrail to monitor the data quality and to send alerts.
C. Deploy the models by using Amazon Elastic Container Service (Amazon ECS) on AWS Fargate. Use Amazon EventBridge to monitor the data quality and to send alerts.
D. Deploy the models by using Amazon SageMaker batch transform. Use SageMaker Model Monitor to monitor the data quality and to send alerts.
Answer:
D. Deploy the models by using Amazon SageMaker batch transform. Use SageMaker Model Monitor to monitor the data quality and to send alerts.
---
### Detailed Explanation
#### Requirements Summary
1. Asynchronous Inference: Process large datasets in batches without real-time latency constraints.
2. Scheduled Data Quality Monitoring: Continuously check input/output data for drift, schema violations, or anomalies.
3. Automated Alerts: Notify stakeholders when data quality issues arise.
---
### Analysis of the Correct Answer
##### Amazon SageMaker Batch Transform
- Asynchronous Processing:
- Batch Transform processes large datasets stored in Amazon S3 asynchronously. It automatically provisions compute resources, splits the data, and runs inference in parallel.
- Ideal for offline predictions on bulk data (e.g., nightly batch jobs).
- Scalability:
- Handles petabytes of data by distributing workloads across multiple instances.
##### SageMaker Model Monitor
- Data Quality Monitoring:
- Scheduled Checks: Model Monitor runs periodic analyses (e.g., daily) on live inference data to compare against a baseline (training data statistics).
- Detects Issues: Identifies schema deviations (e.g., missing columns), data drift (e.g., feature distribution shifts), and prediction quality degradation.
- Alerts via CloudWatch:
- Integrates with Amazon CloudWatch to trigger alarms (e.g., SNS notifications) when violations exceed thresholds.
---
### Key Differentiators for Option D
- End-to-End Workflow:
Batch Transform handles inference at scale, while Model Monitor ensures data quality without custom tooling.
- Managed Infrastructure:
Both services abstract resource provisioning, scaling, and monitoring.
---
### Analysis of Incorrect Options
##### A. AWS Glue + CloudWatch
- Problem:
- AWS Glue is an ETL tool, not designed for ML inference. CloudWatch lacks built-in data quality checks for ML models.
##### B. AWS Batch + CloudTrail
- Problem:
- AWS Batch requires manual setup for inference jobs. CloudTrail logs API activity but cannot monitor data quality or send alerts.
##### C. ECS Fargate + EventBridge
- Problem:
- ECS Fargate requires containerizing the model and managing infrastructure. EventBridge routes events but does not perform data quality analysis.
---
### Conclusion
Option D is the only solution that fulfills all requirements:
1. Batch Transform efficiently processes large datasets asynchronously.
2. Model Monitor automates data quality checks and integrates with CloudWatch for alerts.
Other options lack native ML-focused tools for inference and monitoring, requiring manual effort and custom code.
An ML engineer normalized training data by using min-max normalization in AWS Glue DataBrew. The ML engineer must normalize the production inference data in the same way as the training data before passing the production inference data to the model for predictions.
Which solution will meet this requirement?
A. Apply statistics from a well-known dataset to normalize the production samples.
B. Keep the min-max normalization statistics from the training set. Use these values to normalize the production samples.
C. Calculate a new set of min-max normalization statistics from a batch of production samples. Use these values to normalize all the production samples.
D. Calculate a new set of min-max normalization statistics from each production sample. Use these values to normalize all the production samples.
Answer:
B. Keep the min-max normalization statistics from the training set. Use these values to normalize the production samples.
---
### Detailed Explanation
#### Requirements Summary
1. Consistent Normalization: Ensure production data is normalized using the same parameters (min/max values) as the training data.
2. Model Compatibility: Maintain alignment between training and inference data distributions to ensure accurate predictions.
---
### Analysis of the Correct Answer
##### Why Training Statistics Must Be Reused
- Min-Max Normalization Formula:
xnormalized = x−mintrain / (maxtrain−mintrain)
- The model expects input features scaled to the range determined by the training data’s \(\min_{\text{train}}\) and \(\max_{\text{train}}\).
- Production Data Scaling:
Using the same \(\min_{\text{train}}\) and \(\max_{\text{train}}\) ensures production data is transformed identically to the training data, preserving the model’s learned relationships.
##### Why It Meets the Requirements
- Avoid Data Skew:
Recalculating min/max on production data (Options C/D) introduces distribution shifts, leading to incorrect predictions.
- Reproducibility:
Training statistics are frozen and reused, ensuring consistent preprocessing across development and production.
---
### Key Differentiators for Option B
- Model Expectation:
The model was trained on data scaled with \(\min_{\text{train}}\) and \(\max_{\text{train}}\). Deviating from these values breaks compatibility.
- Standard ML Practice:
Preprocessing parameters (e.g., scalers, encoders) are always derived from the training set and applied to inference data.
---
### Analysis of Incorrect Options
##### A. Well-Known Dataset Statistics
- Problem:
External datasets have unrelated distributions. Using their statistics misaligns training and inference data scales.
##### C. Batch Production Statistics
- Problem:
Production data may have different ranges (e.g., outliers), causing inconsistent scaling compared to training.
##### D. Per-Sample Statistics
- Problem:
Normalizing each sample independently destroys feature relationships and renders the model’s predictions meaningless.
---
### Conclusion
Option B is the only valid approach. By reusing the min/max values from the training data, the ML engineer ensures the production inference data is normalized identically to the data the model was trained on. This preserves the model’s accuracy and avoids distribution shifts. Alternatives (A, C, D) introduce inconsistencies, violating fundamental ML preprocessing principles.
A company is planning to use Amazon SageMaker to make classification ratings that are based on images. The company has 6 ТВ of training data that is stored on an Amazon FSx for NetApp ONTAP system virtual machine (SVM). The SVM is in the same VPC as SageMaker.
An ML engineer must make the training data accessible for ML models that are in the SageMaker environment.
Which solution will meet these requirements?
A. Mount the FSx for ONTAP file system as a volume to the SageMaker Instance.
B. Create an Amazon S3 bucket. Use Mountpoint for Amazon S3 to link the S3 bucket to the FSx for ONTAP file system.
C. Create a catalog connection from SageMaker Data Wrangler to the FSx for ONTAP file system.
D. Create a direct connection from SageMaker Data Wrangler to the FSx for ONTAP file system.
Answer:
A. Mount the FSx for ONTAP file system as a volume to the SageMaker instance.
---
### Detailed Explanation
#### Requirements Summary
1. Access FSx for ONTAP Data: Make 6 TB of training data stored on an FSx for NetApp ONTAP SVM accessible to SageMaker.
2. Same VPC Connectivity: The SVM and SageMaker are already in the same VPC, enabling direct network communication.
3. Avoid Data Duplication: Prevent unnecessary data transfers to S3 or other storage services.
---
### Analysis of the Correct Answer
##### Why Mounting FSx for ONTAP Works
1. Direct File System Access:
- FSx for ONTAP supports NFS (v3/v4) and SMB protocols. SageMaker training instances can mount the FSx volume as a network drive using these protocols.
- Example mount command for NFS:
mount -t nfs <FSx-ONTAP-file-system-DNS>:/vol/vol0 /mnt/fsx2. High-Performance Access:
- FSx for ONTAP provides low-latency, high-throughput access to large datasets, critical for training on 6 TB of image data.
- Avoids the overhead of copying data to S3 or other intermediate storage.
3. VPC Integration:
- Since the SVM and SageMaker reside in the same VPC, mounting the FSx volume requires no public internet exposure or complex networking setups.
##### Why It Meets the Requirements
- Seamless Integration:
SageMaker training jobs can directly read from the mounted FSx volume, ensuring no data duplication and minimal latency.
- Cost and Time Efficiency:
Eliminates the need to transfer 6 TB of data to S3, saving storage costs and time.
---
### Key Differentiators for Option A
- Native File System Support:
FSx for ONTAP is designed for shared file access, making it ideal for SageMaker instances requiring direct dataset access.
- No Data Movement:
Retains the dataset on FSx, leveraging its existing performance optimizations for large-scale ML workloads.
---
### Analysis of Incorrect Options
##### B. Mountpoint for S3 + FSx for ONTAP
- Problem:
- Mountpoint for S3 is for accessing S3 as a file system, not for linking FSx to S3. This would require copying data to S3, adding unnecessary cost and complexity.
##### C/D. SageMaker Data Wrangler Connections
- Problem:
- Data Wrangler focuses on data preparation (e.g., cleaning, transforming) and does not natively support FSx for ONTAP as a data source for training jobs.
- Designed for smaller datasets and exploratory analysis, not large-scale training workloads.
---
### Conclusion
Option A is the optimal solution. By mounting the FSx for ONTAP volume directly to SageMaker instances, the ML engineer enables efficient, high-performance access to the 6 TB dataset without data duplication or reconfiguration. This approach leverages the existing VPC setup and FSx’s enterprise-grade file system capabilities, ensuring seamless integration with SageMaker training jobs. Alternatives like S3 (B) or Data Wrangler (C/D) introduce unnecessary steps or incompatibilities.
A company regularly receives new training data from the vendor of an ML model. The vendor delivers cleaned and prepared data to the company's Amazon S3 bucket every 3-4 days.
The company has an Amazon SageMaker pipeline to retrain the model. An ML engineer needs to implement a solution to run the pipeline when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
A. Create an S3 Lifecycle rule to transfer the data to the SageMaker training instance and to initiate training.
B. Create an AWS Lambda function that scans the S3 bucket. Program the Lambda function to initiate the pipeline when new data is uploaded.
C. Create an Amazon EventBridge rule that has an event pattern that matches the S3 upload. Configure the pipeline as the target of the rule.
D. Use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) to orchestrate the pipeline when new data is uploaded.
Answer:
C. Create an Amazon EventBridge rule that has an event pattern that matches the S3 upload. Configure the pipeline as the target of the rule.
---
### Detailed Explanation
#### Requirements Summary
1. Automated Pipeline Execution: Trigger the SageMaker pipeline when new data is uploaded to S3.
2. Minimal Operational Effort: Avoid custom code, infrastructure management, or complex orchestration.
---
### Analysis of the Correct Answer
##### How EventBridge + SageMaker Pipeline Works
1. EventBridge Rule:
- Configure an EventBridge rule to detect S3 object creation events (e.g., s3:ObjectCreated:*) in the specified bucket.
- Example event pattern:
```json
{
"source": ["aws.s3"],
"detail-type": ["Object Created"],
"detail": {
"bucket": {
"name": ["<TARGET_BUCKET_NAME>"]
}
}
}
```
2. Direct Pipeline Invocation:
- Set the SageMaker pipeline as the rule’s target. EventBridge automatically triggers the pipeline when new data arrives, without intermediate steps.
##### Why It Meets the Requirements
- No Custom Code:
EventBridge natively integrates with S3 and SageMaker pipelines, eliminating the need for Lambda functions or Airflow DAGs.
- Managed Service:
AWS fully manages EventBridge, requiring no infrastructure provisioning or maintenance.
---
### Key Differentiators for Option C
- Serverless Automation:
EventBridge acts as a fully managed event bus, directly linking S3 uploads to SageMaker pipeline execution.
- Zero Code/Infrastructure:
Configured via the AWS Console/CLI in minutes, with no scripts or compute resources to manage.
---
### Analysis of Incorrect Options
##### A. S3 Lifecycle Rule
- Problem:
- Lifecycle rules manage object transitions (e.g., to Glacier) or deletions, not workflow triggers. They cannot initiate SageMaker pipelines.
##### B. Lambda Function
- Problem:
- While functional, Lambda requires writing and maintaining code to scan the bucket and invoke the pipeline. Adds unnecessary operational overhead compared to EventBridge.
##### D. Amazon MWAA (Airflow)
- Problem:
- Overkill for a simple event-driven workflow. Airflow requires defining DAGs, managing workers, and scheduling, which introduces complexity.
---
### Conclusion
Option C is the most efficient solution. By leveraging EventBridge’s native integration with S3 and SageMaker, the company automates pipeline execution with zero code and minimal configuration. This approach minimizes operational effort while ensuring timely retraining whenever new data arrives. Other options either lack functionality (A), require coding (B), or add unnecessary complexity (D).
An ML engineer is developing a fraud detection model by using the Amazon SageMaker XGBoost algorithm. The model classifies transactions as either fraudulent or legitimate.
During testing, the model excels at identifying fraud in the training dataset. However, the model is inefficient at identifying fraud in new and unseen transactions.
What should the ML engineer do to improve the fraud detection for new transactions?
A. Increase the learning rate.
B. Remove some irrelevant features from the training dataset.
C. Increase the value of the max_depth hyperparameter.
D. Decrease the value of the max_depth hyperparameter.
**Answer:**
**D. Decrease the value of the max_depth hyperparameter.**
---
### **Detailed Explanation**
#### **Problem Analysis**
The model performs well on training data but poorly on new transactions, indicating **overfitting**. Overfitting occurs when the model becomes too complex and memorizes noise or irrelevant patterns in the training data instead of generalizing.
#### **Why Decreasing max_depth Works**
- *max_depth in XGBoost**:
- Controls the maximum depth of decision trees in the ensemble.
- A higher max_depth allows trees to grow deeper, capturing intricate (but potentially noisy) patterns in the training data.
- Excessive depth leads to overfitting, as trees "memorize" training examples rather than learning generalizable rules.
- **Reducing Complexity**:
- Decreasing max_depth limits tree depth, simplifying the model and forcing it to focus on the most important patterns.
- Example: With max_depth=3, trees split only 3 times, reducing the risk of overfitting compared to deeper trees (e.g., max_depth=10).
#### **Why Other Options Fail**
- **A. Increase Learning Rate**:
- A higher learning rate speeds up training but can overshoot optimal solutions, worsening generalization.
- **B. Remove Irrelevant Features**:
- While feature selection helps, the problem explicitly points to overfitting (not feature noise). Reducing model complexity (via max_depth) directly addresses the root cause.
- **C. Increase max_depth**:
- Exacerbates overfitting by increasing model complexity.
---
### **Conclusion**
Decreasing max_depth **(D)** reduces model complexity, mitigating overfitting and improving the model’s ability to generalize to new transactions. This adjustment ensures the XGBoost model prioritizes robust patterns over noise, enhancing fraud detection performance on unseen data.
A company has a binary classification model in production. An ML engineer needs to develop a new version of the model.
The new model version must maximize correct predictions of positive labels and negative labels. The ML engineer must use a metric to recalibrate the model to meet these requirements.
Which metric should the ML engineer use for the model recalibration?
A. Accuracy
B. Precision
C. Recall
D. Specificity
Answer:
A. Accuracy
---
### Detailed Explanation
#### Requirements Summary
1. Maximize Correct Predictions for Both Classes: Improve true positives (fraudulent transactions) and true negatives (legitimate transactions).
2. Metric for Recalibration: Choose a metric that directly reflects overall model correctness across both classes.
---
### Analysis of the Correct Answer
##### Why Accuracy Is the Right Metric
- Definition:
Accuracy = (True Positives (TP) + True Negatives (TN)) / Total Predictions
- Measures the overall correctness of the model’s predictions for both classes.
- Recalibration Objective:
- Adjusting the decision threshold to maximize accuracy ensures the model balances correct identifications of both fraudulent (TP) and legitimate (TN) transactions.
- Example: If the current threshold favors one class (e.g., too many false negatives), recalibrating for accuracy optimizes the balance between TP and TN.
##### Why It Meets the Requirements
- Holistic Performance:
Accuracy directly quantifies the model’s ability to correctly classify all instances, aligning with the goal of improving both positive and negative predictions.
- Threshold Optimization:
Recalibrating via accuracy helps find the optimal decision threshold that minimizes total errors (FP + FN).
---
### Key Differentiators for Option A
- Balanced Focus:
Unlike precision (focuses on TP/FP) or recall/specificity (focus on one class), accuracy inherently balances performance across both classes.
- Simplicity:
Provides a single metric to guide recalibration without complex trade-offs.
---
### Analysis of Incorrect Options
##### B. Precision
- Problem:
- Prioritizes minimizing false positives (FP) but ignores false negatives (FN). Over-optimizing precision risks missing fraudulent transactions (high FN), which is critical in fraud detection.
##### C. Recall
- Problem:
- Focuses on maximizing true positives (TP) at the expense of false positives (FP). This could flag too many legitimate transactions as fraudulent, increasing operational costs.
##### D. Specificity
- Problem:
- Optimizes for true negatives (TN) but neglects false negatives (FN). High specificity risks overlooking fraudulent activity, defeating the purpose of fraud detection.
---
### Conclusion
Accuracy (A) is the most appropriate metric for recalibrating the model to maximize correct predictions for both classes. It ensures a balanced improvement in identifying fraudulent and legitimate transactions, avoiding biases toward one class. Alternatives like precision (B), recall (C), or specificity (D) focus on isolated aspects, potentially harming overall performance.
A company is using Amazon SageMaker to create ML models. The company's data scientists need fine-grained control of the ML workflows that they orchestrate. The data scientists also need the ability to visualize SageMaker jobs and workflows as a directed acyclic graph (DAG). The data scientists must keep a running history of model discovery experiments and must establish model governance for auditing and compliance verifications.
Which solution will meet these requirements?
A. Use AWS CodePipeline and its integration with SageMaker Studio to manage the entire ML workflows. Use SageMaker ML Lineage Tracking for the running history of experiments and for auditing and compliance verifications.
B. Use AWS CodePipeline and its integration with SageMaker Experiments to manage the entire ML workflows. Use SageMaker Experiments for the running history of experiments and for auditing and compliance verifications.
C. Use SageMaker Pipelines and its integration with SageMaker Studio to manage the entire ML workflows. Use SageMaker ML Lineage Tracking for the running history of experiments and for auditing and compliance verifications.
D. Use SageMaker Pipelines and its integration with SageMaker Experiments to manage the entire ML workflows. Use SageMaker Experiments for the running history of experiments and for auditing and compliance verifications.
Answer:
C. Use SageMaker Pipelines and its integration with SageMaker Studio to manage the entire ML workflows. Use SageMaker ML Lineage Tracking for the running history of experiments and for auditing and compliance verifications.
---
### Detailed Explanation
#### Requirements Summary
1. Fine-Grained Workflow Control: Orchestrate ML workflows with precision.
2. DAG Visualization: Visualize workflows as directed acyclic graphs (DAGs).
3. Experiment History & Model Governance: Track experiments and ensure compliance through lineage and audit trails.
---
### Analysis of the Correct Answer
##### Why SageMaker Pipelines + ML Lineage Tracking Works
1. SageMaker Pipelines:
- Native ML Workflow Orchestration:
- Define multi-step workflows (e.g., data preprocessing, training, evaluation) as code.
- Automatically generates DAG visualizations in SageMaker Studio, showing dependencies and execution order.
- Reproducibility:
- Ensures workflows are versioned, reusable, and auditable.
2. SageMaker ML Lineage Tracking:
- Comprehensive Lineage:
- Tracks end-to-end lineage of model artifacts, datasets, training jobs, and pipelines.
- Captures metadata such as hyperparameters, environment configurations, and model versions.
- Audit & Compliance:
- Provides a detailed history for governance, including who trained a model, which data was used, and how parameters were configured.
##### Why It Meets the Requirements
- DAG Visualization:
SageMaker Pipelines natively renders workflows as DAGs in Studio, enabling data scientists to inspect and debug workflows visually.
- Governance & Compliance:
ML Lineage Tracking ensures full traceability of model artifacts, meeting regulatory and audit requirements.
---
### Key Differentiators for Option C
- End-to-End Integration:
SageMaker Pipelines is purpose-built for ML workflows, while ML Lineage Tracking directly addresses governance needs.
- No Third-Party Tools:
Avoids reliance on CI/CD tools like AWS CodePipeline (Options A/B), which lack native ML workflow and visualization capabilities.
---
### Analysis of Incorrect Options
##### A/B. AWS CodePipeline + ML Lineage Tracking/Experiments
- Problem:
- CI/CD Focus: CodePipeline is designed for software deployment, not ML workflows. It lacks native DAG visualization or ML-specific features.
- Limited Governance: ML Lineage Tracking alone (Option A) or Experiments (Option B) cannot compensate for CodePipeline’s lack of ML workflow orchestration.
##### D. SageMaker Pipelines + Experiments
- Problem:
- Experiments vs. Lineage Tracking:
- SageMaker Experiments tracks individual trial runs (e.g., hyperparameters, metrics) but does not provide full lineage (e.g., dataset versions, model artifacts).
- ML Lineage Tracking is required for compliance, as it logs dependencies across pipelines, jobs, and artifacts.
---
### Conclusion
Option C is the only solution that combines:
1. SageMaker Pipelines for orchestration and DAG visualization.
2. ML Lineage Tracking for audit trails, compliance, and governance.
This approach ensures fine-grained workflow control, transparency, and regulatory compliance, which are critical for enterprise ML operations.
A company wants to reduce the cost of its containerized ML applications. The applications use ML models that run on Amazon EC2 instances, AWS Lambda functions, and an Amazon Elastic Container Service (Amazon ECS) cluster. The EC2 workloads and ECS workloads use Amazon Elastic Block Store (Amazon EBS) volumes to save predictions and artifacts.
An ML engineer must identify resources that are being used inefficiently. The ML engineer also must generate recommendations to reduce the cost of these resources.
Which solution will meet these requirements with the LEAST development effort?
A. Create code to evaluate each instance's memory and compute usage.
B. Add cost allocation tags to the resources. Activate the tags in AWS Billing and Cost Management.
C. Check AWS CloudTrail event history for the creation of the resources.
D. Run AWS Compute Optimizer.
Answer: D. Run AWS Compute Optimizer.
---
### Detailed Explanation - Requirements Summary
The company uses EC2 instances, Lambda functions, and an ECS cluster with EBS volumes for ML workloads. The goal is to:
1. Identify inefficiently used resources (e.g., underutilized EC2 instances, over-provisioned EBS volumes, or misconfigured Lambda functions).
2. Generate cost-saving recommendations without requiring significant development effort.
The solution must minimize manual analysis or custom code development while addressing all resource types (compute, storage, serverless).
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
AWS Compute Optimizer is a fully managed service that:
1. Automatically analyzes resource utilization using historical metrics (CPU, memory, network, disk I/O) from EC2 instances, EBS volumes, Lambda functions, and ECS services running on EC2.
2. Generates actionable recommendations to optimize costs and performance:
- EC2: Recommends rightsizing (e.g., switching from m5.xlarge to m5.large), migrating to Graviton-based instances, or purchasing Reserved Instances/Savings Plans.
- EBS: Identifies underused volumes and suggests transitioning to cheaper storage classes (e.g., gp3 instead of gp2) or resizing.
- Lambda: Analyzes memory allocation and execution duration to recommend optimal configurations.
- ECS: Evaluates task-level CPU/memory reservations and suggests rightsizing.
3. Requires zero code or configuration—it integrates directly with AWS resource metrics and provides reports via the AWS Management Console, CLI, or SDK.
Why It Meets the Requirements:
- No development effort: Fully automated analysis and recommendations.
- Covers all resource types: Addresses EC2, EBS, Lambda, and ECS in a single tool.
- Actionable insights: Directly links inefficiencies to cost-saving measures (e.g., instance family changes, storage tier adjustments).
---
### Key Differentiators for Option D
- End-to-End Coverage: Unlike point solutions, Compute Optimizer supports multiple resource types critical to the ML stack (EC2, EBS, Lambda, ECS).
- Machine Learning-Based Analysis: Uses AWS internal telemetry and ML models to identify patterns (e.g., cyclical workloads, sporadic Lambda invocations) that manual analysis might miss.
- Integration with Cost Explorer: Recommendations include projected cost savings, enabling quick prioritization.
---
### Analysis of Incorrect Options
A. Create code to evaluate each instance’s memory and compute usage
- Drawbacks:
- Requires significant development effort to collect, aggregate, and analyze metrics across EC2, EBS, Lambda, and ECS.
- Lacks AWS’s proprietary insights (e.g., Reserved Instance discounts, Graviton performance data).
- Maintenance-heavy (e.g., adapting to new instance types or Lambda configurations).
B. Add cost allocation tags
- Drawbacks:
- Tags help categorize costs but do not identify inefficiencies.
- Requires manual analysis in Cost Explorer to correlate spending with utilization.
- Does not address technical resource optimization (e.g., rightsizing EBS volumes).
C. Check AWS CloudTrail event history
- Drawbacks:
- CloudTrail tracks API activity (e.g., resource creation/deletion) but not resource utilization.
- Irrelevant for identifying underused instances or storage.
---
### Conclusion
AWS Compute Optimizer (Option D) is the only solution that:
1. Automatically identifies inefficiencies across EC2, EBS, Lambda, and ECS.
2. Provides tailored cost-saving recommendations without code or manual analysis.
3. Leverages AWS’s internal data (e.g., instance performance baselines, storage-tier economics) for accuracy.
Alternatives like custom code (A) or tagging (B) add overhead and lack actionable insights, while CloudTrail (C) is irrelevant to utilization analysis. Compute Optimizer minimizes effort while maximizing cost savings, aligning perfectly with the requirements.
A company needs to create a central catalog for all the company's ML models. The models are in AWS accounts where the company developed the models initially. The models are hosted in Amazon Elastic Container Registry (Amazon ECR) repositories.
Which solution will meet these requirements?
A. Configure ECR cross-account replication for each existing ECR repository. Ensure that each model is visible in each AWS account.
B. Create a new AWS account with a new ECR repository as the central catalog. Configure ECR cross-account replication between the initial ECR repositories and the central catalog.
C. Use the Amazon SageMaker Model Registry to create a model group for models hosted in Amazon ECR. Create a new AWS account. In the new account, use the SageMaker Model Registry as the central catalog. Attach a cross-account resource policy to each model group in the initial AWS accounts.
D. Use an AWS Glue Data Catalog to store the models. Run an AWS Glue crawler to migrate the models from the ECR repositories to the Data Catalog. Configure cross-account access to the Data Catalog.
Answer: C. Use the Amazon SageMaker Model Registry to create a model group for models hosted in Amazon ECR. Create a new AWS account. In the new account, use the SageMaker Model Registry as the central catalog. Attach a cross-account resource policy to each model group in the initial AWS accounts.
---
### Detailed Explanation - Requirements Summary
The company needs a centralized catalog for ML models stored in Amazon ECR repositories across multiple AWS accounts. The solution must:
1. Aggregate model metadata and references from ECR repositories in disparate accounts into a single catalog.
2. Avoid duplicating model artifacts (container images) unless necessary.
3. Enable cross-account access to the catalog.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Amazon SageMaker Model Registry is designed for ML model lifecycle management and cataloging. Here’s how Option C addresses the requirements:
1. Centralized Catalog:
- A model group in the SageMaker Model Registry (in a new AWS account) acts as the central catalog. Model groups track versions, metadata, and approval statuses.
- Each model version in the registry references the ECR repository URI (e.g., account-id.dkr.ecr.region.amazonaws.com/repo:tag) where the container image is stored. No replication of images is required—the registry stores metadata and pointers to the original ECR repositories.
2. Cross-Account Access:
- A resource-based policy is attached to each model group in the source accounts. This policy grants permissions to the central account’s SageMaker service to access the model artifacts in ECR.
- For example, the policy allows sagemaker:CreateModelPackage and ecr:DescribeRepositories actions for the central account’s IAM roles.
3. Unified Governance:
- Teams in the central account can discover, version, and deploy models from any source account without managing replicated artifacts.
- Integrates with SageMaker Pipelines and MLOps workflows for automated model deployment.
Why It Meets the Requirements:
- Avoids redundant storage costs by referencing existing ECR images.
- Provides a purpose-built catalog with metadata tracking (e.g., model lineage, approvals).
- Uses native AWS mechanisms (resource policies) for cross-account access.
---
### Key Differentiators for Option C
- SageMaker Model Registry vs. ECR Replication:
- Option B (ECR cross-account replication) duplicates container images, increasing storage costs and complicating versioning.
- SageMaker Model Registry decouples metadata (catalog) from storage (ECR), enabling lightweight governance.
- ML-Specific Features:
- Model Registry supports stage transitions (e.g., staging to production), approvals, and integration with CI/CD pipelines.
- ECR lacks native model lifecycle management capabilities.
---
### Analysis of Incorrect Options
A. Configure ECR cross-account replication for each existing ECR repository
- Drawbacks:
- Replicates all container images to every account, leading to redundant storage and increased costs.
- Does not create a centralized catalog—models remain siloed in individual accounts.
- No unified metadata tracking (e.g., model versioning, approval status).
B. Create a new AWS account with a central ECR repository and replicate images
- Drawbacks:
- Replicates container images to a single ECR repository, which consolidates storage but does not provide a catalog.
- Lacks model metadata management (e.g., version descriptions, lifecycle stages).
- Requires ongoing replication configuration for new repositories.
D. Use AWS Glue Data Catalog to store models
- Drawbacks:
- Glue Data Catalog is designed for tabular datasets (e.g., CSV, Parquet) stored in S3 or databases, not containerized ML models in ECR.
- Glue crawlers cannot index ECR repositories or parse container images.
- No integration with ML deployment workflows.
---
### Conclusion
Option C is the only solution that:
1. Creates a purpose-built ML model catalog (SageMaker Model Registry) with metadata tracking and lifecycle management.
2. References existing ECR repositories without duplicating artifacts.
3. Uses cross-account resource policies to securely centralize access.
Options A and B focus on replicating storage (ECR), which is inefficient and lacks cataloging features. Option D misuses AWS Glue for non-supported data types. SageMaker Model Registry directly addresses the requirement for a centralized, governance-ready ML model catalog.
A company has developed a new ML model. The company requires online model validation on 10% of the traffic before the company fully releases the model in production. The company uses an Amazon SageMaker endpoint behind an Application Load Balancer (ALB) to serve the model.
Which solution will set up the required online validation with the LEAST operational overhead?
A. Use production variants to add the new model to the existing SageMaker endpoint. Set the variant weight to 0.1 for the new model. Monitor the number of invocations by using Amazon CloudWatch.
B. Use production variants to add the new model to the existing SageMaker endpoint. Set the variant weight to 1 for the new model. Monitor the number of invocations by using Amazon CloudWatch.
C. Create a new SageMaker endpoint. Use production variants to add the new model to the new endpoint. Monitor the number of invocations by using Amazon CloudWatch.
D. Configure the ALB to route 10% of the traffic to the new model at the existing SageMaker endpoint. Monitor the number of invocations by using AWS CloudTrail.
Answer: A. Use production variants to add the new model to the existing SageMaker endpoint. Set the variant weight to 0.1 for the new model. Monitor the number of invocations by using Amazon CloudWatch.
---
### Detailed Explanation - Requirements Summary
The company needs to:
1. Validate a new ML model with 10% of production traffic before full deployment.
2. Use the existing SageMaker endpoint (behind an ALB) to minimize operational complexity.
3. Monitor traffic distribution with minimal overhead.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
SageMaker Production Variants allow multiple model versions to run behind a single endpoint, with traffic split based on assigned weights.
1. Traffic Splitting:
- Adding the new model as a variant to the existing endpoint and setting its weight to 0.1 (10%) directs 10% of requests to the new model and 90% to the original model.
- No need to deploy a new endpoint or modify the ALB configuration.
2. Monitoring:
- SageMaker automatically publishes invocation metrics (e.g., InvocationsPerInstance) to Amazon CloudWatch, enabling real-time tracking of traffic distribution.
3. Operational Simplicity:
- Updates to endpoint variants are done via a single API call UpdateEndpointWeightsAndCapacities) or through the SageMaker console.
Why It Meets the Requirements:
- No new infrastructure: Uses the existing endpoint and ALB.
- Native traffic splitting: SageMaker handles routing internally, avoiding complex ALB rules.
- Zero code changes: Traffic weights and monitoring are managed via AWS services.
---
### Key Differentiators for Option A
- Production Variants vs. ALB Routing:
- SageMaker variants handle traffic splitting at the model-inference layer, whereas ALB routing (Option D) would require reconfiguring listeners/target groups and managing multiple endpoints.
- ALB is unaware of model versions, making it unsuitable for granular A/B testing at the model level.
- Cost Efficiency:
- Avoiding a new endpoint (Option C) eliminates redundant compute costs.
---
### Analysis of Incorrect Options
B. Set variant weight to 1 for the new model
- Drawbacks:
- A weight of 1 routes 100% of traffic to the new model, bypassing validation.
- Contradicts the requirement to test on only 10% of traffic.
C. Create a new SageMaker endpoint
- Drawbacks:
- Requires deploying and managing a second endpoint, increasing operational overhead (e.g., monitoring, scaling, cost).
- Splitting traffic between endpoints would necessitate ALB reconfiguration, adding complexity.
D. Configure ALB to route 10% of traffic
- Drawbacks:
- ALB routes traffic at the endpoint level, not the model-variant level. To split traffic between models, you would need separate endpoints, doubling infrastructure.
- CloudTrail logs API activity but does not provide real-time invocation metrics. CloudWatch is required for monitoring.
---
### Conclusion
Option A is the only solution that:
1. Uses native SageMaker features (production variants) to split traffic at the model level.
2. Avoids unnecessary infrastructure changes (no new endpoints or ALB reconfiguration).
3. Leverages CloudWatch for monitoring without custom tooling.
Alternatives like ALB routing (D) or new endpoints (C) introduce complexity, while Option B fails to meet the 10% validation requirement. SageMaker production variants provide the simplest, most cost-effective path for online validation.
A company needs to develop an ML model. The model must identify an item in an image and must provide the location of the item.
Which Amazon SageMaker algorithm will meet these requirements?
A. Image classification
B. XGBoost
C. Object detection
D. K-nearest neighbors (k-NN)
Answer: C. Object detection
---
### Detailed Explanation - Requirements Summary
The task requires an ML model that:
1. Identifies items (objects) within an image.
2. Provides the location of each identified item (typically via bounding boxes).
This is a computer vision (CV) problem requiring both classification (what is the object?) and localization (where is the object in the image?).
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Amazon SageMaker’s built-in Object Detection algorithm is designed specifically for this use case. It:
1. Detects and localizes objects:
- Outputs bounding box coordinates (e.g., [x_min, y_min, x_max, y_max]) for each detected object.
- Classifies each object (e.g., “car”, “person”).
2. Uses deep learning architectures:
- Based on frameworks like Single Shot MultiBox Detector (SSD) or ResNet, optimized for SageMaker.
3. Requires labeled training data:
- Training images must include annotations (bounding boxes and class labels) for supervised learning.
Why It Meets the Requirements:
- Directly addresses localization + classification, unlike pure classification algorithms.
- Pre-built SageMaker integration reduces development effort (no need to customize models from scratch).
---
### Key Differentiators for Option C
- Object Detection vs. Image Classification:
- Image Classification (Option A) only predicts labels for the entire image (e.g., “dog”) and cannot locate objects.
- Object Detection provides granular, per-object labels and spatial coordinates.
- Specialized vs. General-Purpose Algorithms:
- XGBoost (Option B) and k-NN (Option D) are designed for tabular data, not pixel-based image analysis. They lack spatial awareness for bounding box prediction.
---
### Analysis of Incorrect Options
A. Image Classification
- Drawbacks:
- Predicts “what” (class label) but not “where”.
- Example: Classifies an image as “cat” but cannot highlight the cat’s position.
B. XGBoost
- Drawbacks:
- A gradient-boosted tree algorithm for structured data (CSV, databases).
- Cannot process raw image pixels effectively or predict spatial coordinates.
D. K-nearest neighbors (k-NN)
- Drawbacks:
- A distance-based classifier for low-dimensional data.
- Impractical for high-dimensional image data and incapable of localization.
---
### Conclusion
Object Detection (Option C) is the only SageMaker algorithm that solves both identification (classification) and localization (bounding boxes) of objects in images. Alternatives like Image Classification lack localization capabilities, while XGBoost and k-NN are unsuitable for image-based tasks. The built-in SageMaker Object Detection algorithm provides an efficient, production-ready solution with minimal customization.
A company has an Amazon S3 bucket that contains 1 ТВ of files from different sources. The S3 bucket contains the following file types in the same S3 folder: CSV, JSON, XLSX, and Apache Parquet.
An ML engineer must implement a solution that uses AWS Glue DataBrew to process the data. The ML engineer also must store the final output in Amazon S3 so that AWS Glue can consume the output in the future.
Which solution will meet these requirements?
A. Use DataBrew to process the existing S3 folder. Store the output in Apache Parquet format.
B. Use DataBrew to process the existing S3 folder. Store the output in AWS Glue Parquet format.
C. Separate the data into a different folder for each file type. Use DataBrew to process each folder individually. Store the output in Apache Parquet format.
D. Separate the data into a different folder for each file type. Use DataBrew to process each folder individually. Store the output in AWS Glue Parquet format.
Answer: C. Separate the data into a different folder for each file type. Use DataBrew to process each folder individually. Store the output in Apache Parquet format.
---
### Detailed Explanation - Requirements Summary
The company must:
1. Process mixed file types (CSV, JSON, XLSX, Parquet) stored in a single S3 folder using AWS Glue DataBrew.
2. Ensure the final output is stored in S3 in a format compatible with AWS Glue for future use.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
AWS Glue DataBrew requires datasets to have a consistent schema and format. Mixing file types (e.g., CSV, JSON, XLSX) in the same folder causes errors because:
1. Schema Conflicts:
- CSV and XLSX are tabular but may have different column structures.
- JSON can be nested/hierarchical, incompatible with tabular formats.
- Parquet is columnar and requires specific schema definitions.
2. DataBrew Limitations:
- DataBrew treats all files in a folder as part of the same dataset and expects uniform formatting.
- Processing mixed formats together results in failed jobs or corrupted data.
Solution Workflow (Option C):
1. Separate Files by Type:
- Create distinct S3 folders (e.g., s3://bucket/csv/, s3://bucket/json/) for each file type.
2. Process Each Folder Individually:
- Create separate DataBrew projects for CSV, JSON, XLSX, and Parquet files.
- Apply format-specific transformations (e.g., flatten JSON, parse Excel sheets).
3. Output in Apache Parquet:
- Parquet is a columnar storage format optimized for AWS Glue (fast querying, compression, schema evolution).
- AWS Glue natively supports Parquet for ETL jobs and cataloging.
Why It Meets the Requirements:
- Avoids schema conflicts by isolating file types.
- Ensures DataBrew processes each format correctly.
- Produces Glue-compatible output in Parquet.
---
### Key Differentiators for Option C
- Handling Heterogeneous Data:
- DataBrew cannot infer schemas from mixed formats in a single folder. Separating files aligns with DataBrew’s requirement for homogeneous datasets.
- Apache Parquet vs. "AWS Glue Parquet":
- Apache Parquet is the standard format supported by AWS Glue. There is no proprietary "AWS Glue Parquet" format (Options B/D are misleading).
- Parquet reduces storage costs and improves query performance in Glue.
---
### Analysis of Incorrect Options
A/B. Process the Existing Folder Without Separation
- Drawbacks:
- DataBrew will fail to parse mixed file types, as it expects uniform schemas.
- Example: A JSON file with nested fields cannot coexist with flat CSV files in the same dataset.
D. "AWS Glue Parquet" Format
- Drawbacks:
- "AWS Glue Parquet" is not a valid format—Apache Parquet is the correct standard.
- Separating files is still required, making this option redundant.
---
### Conclusion
Option C is the only viable solution:
1. Separates file types to avoid schema conflicts in DataBrew.
2. Uses Apache Parquet for output, ensuring compatibility with AWS Glue.
3. Follows AWS best practices for handling heterogeneous data in S3.
Options A/B ignore DataBrew’s limitations with mixed formats, while Option D references a nonexistent output format. By segregating data and using standard Parquet, the solution minimizes errors and operational overhead.
A manufacturing company uses an ML model to determine whether products meet a standard for quality. The model produces an output of "Passed" or "Failed." Robots separate the products into the two categories by using the model to analyze photos on the assembly line.
Which metrics should the company use to evaluate the model's performance? (Choose two.)
A. Precision and recall
B. Root mean square error (RMSE) and mean absolute percentage error (MAPE)
C. Accuracy and F1 score
D. Bilingual Evaluation Understudy (BLEU) score
E. Perplexity
Answer: A. Precision and recall and C. Accuracy and F1 score
---
### Detailed Explanation - Requirements Summary
The company uses a binary classification model ("Passed" or "Failed") to assess product quality. The goal is to evaluate model performance with metrics that:
1. Reflect the model’s ability to correctly identify defective products (minimize false negatives).
2. Measure overall correctness while accounting for class imbalance (if present).
---
### Analysis of the Correct Answers
#### A. Precision and Recall
- Precision: Measures the proportion of true positives among all predicted positives.
- Formula: Precision = True Positives / (True Positives + False Positives)
- Why it matters: High precision reduces the risk of false positives (incorrectly labeling good products as "Failed"), which could waste resources on re-inspecting acceptable items.
- Recall: Measures the proportion of actual positives correctly identified.
- Formula: Recall = True Positives / (True Positives + False Negatives)
- Why it matters: High recall minimizes false negatives (defective products labeled as "Passed"), which is critical for quality control to avoid shipping faulty items.
#### C. Accuracy and F1 Score
- Accuracy: Measures the overall correctness of predictions.
- Formula: Accuracy = (True Positives + True Negatives) / Total Predictions
- Why it matters: Provides a general sense of model performance but can be misleading if classes are imbalanced (e.g., 95% "Passed" vs. 5% "Failed").
- F1 Score: Balances precision and recall using their harmonic mean.
- Formula: F1= 2 × (Precision×Recall) / (Precision + Recall)
- Why it matters: Ideal for imbalanced datasets, as it penalizes models that sacrifice one metric (e.g., high recall but low precision).
---
### Key Differentiators
- Precision/Recall (A) directly address the business impact of false positives/negatives. For example:
- High recall ensures defective products are caught.
- High precision avoids unnecessary rework on good products.
- F1 Score (C) complements precision/recall by quantifying their trade-off, while accuracy provides a baseline performance measure.
---
### Analysis of Incorrect Options
B. RMSE and MAPE
- RMSE (Root Mean Square Error) and MAPE (Mean Absolute Percentage Error) are regression metrics for continuous outputs (e.g., predicting sales). Irrelevant for classification.
D. BLEU Score
- Used to evaluate machine translation quality by comparing generated text to human references. Not applicable to classification tasks.
E. Perplexity
- Measures how well a language model predicts a sample. Used in NLP, not classification.
---
### Conclusion
A (Precision/Recall) and C (Accuracy/F1) are the only valid metrics for evaluating a binary classification model in this scenario:
- Precision/Recall ensure the model balances false positives and false negatives.
- Accuracy/F1 provide a holistic view of performance, especially if class distribution is uneven.
Other options (B, D, E) are irrelevant to classification tasks. Precision, recall, accuracy, and F1 score are standard in quality assurance workflows to validate model reliability and business impact.
An ML engineer needs to encrypt all data in transit when an ML training job runs. The ML engineer must ensure that encryption in transit is applied to processes that Amazon SageMaker uses during the training job.
Which solution will meet these requirements?
A. Encrypt communication between nodes for batch processing.
B. Encrypt communication between nodes in a training cluster.
C. Specify an AWS Key Management Service (AWS KMS) key during creation of the training job request.
D. Specify an AWS Key Management Service (AWS KMS) key during creation of the SageMaker domain.
Answer: B. Encrypt communication between nodes in a training cluster.
---
### Detailed Explanation - Requirements Summary
The ML engineer must ensure encryption in transit for all data exchanged during a SageMaker training job. This includes:
1. Inter-node communication in distributed training clusters (e.g., data exchanged between GPU/CPU instances).
2. Data transfers between SageMaker components (e.g., model artifacts, training data).
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Option B enables Transport Layer Security (TLS) encryption for communication between nodes in a SageMaker training cluster:
1. Encrypts Distributed Training Traffic:
- In distributed training (e.g., using Horovod, PyTorch, or TensorFlow), worker nodes exchange gradients, parameters, and data. Enabling inter-node encryption secures this traffic.
- Achieved by setting enable_network_isolation=True in the SageMaker estimator or enabling inter-container traffic encryption in the training job configuration.
2. SageMaker-Specific Implementation:
- SageMaker uses TLS 1.2+ to encrypt traffic between instances in a training cluster.
- Applies to all frameworks (built-in algorithms, custom containers) and instance types (CPU/GPU).
Why It Meets the Requirements:
- Directly addresses encryption of in-transit data between training nodes, which is critical for compliance (e.g., HIPAA, GDPR) and security.
- Managed by SageMaker, requiring no custom code or infrastructure changes.
---
### Key Differentiators for Option B
- Scope of Encryption:
- Option A ("batch processing") refers to SageMaker Batch Transform jobs, not training jobs.
- Option B explicitly secures traffic within the training cluster, which is the focus of the question.
- Encryption in Transit vs. At Rest:
- Options C/D involve AWS KMS, which manages encryption at rest (e.g., encrypting S3 model artifacts, EBS volumes). They do not secure data in transit.
---
### Analysis of Incorrect Options
A. Encrypt communication between nodes for batch processing
- Drawbacks:
- Applies to Batch Transform jobs (inference), not training jobs.
- Irrelevant to securing data during model training.
C. Specify an AWS KMS key during training job creation
- Drawbacks:
- KMS keys encrypt data at rest (e.g., training output in S3, EBS volumes).
- Does not enforce TLS for in-transit data between nodes.
D. Specify a KMS key during SageMaker domain creation
- Drawbacks:
- Encrypts at-rest data for the SageMaker domain (e.g., Jupyter notebooks, user profiles).
- Unrelated to training job traffic.
---
### Conclusion
Option B is the only solution that ensures encryption in transit for data exchanged between nodes in a SageMaker training cluster. Other options focus on encryption at rest (KMS) or unrelated workflows (batch processing). By enabling inter-node encryption, the engineer meets compliance requirements and secures sensitive data during distributed training.
An ML engineer needs to use metrics to assess the quality of a time-series forecasting model.
Which metrics apply to this model? (Choose two.)
A. Recall
B. LogLoss
C. Root mean square error (RMSE)
D. InferenceLatency
E. Average weighted quantile loss (wQL)
Answer: C. Root mean square error (RMSE) and E. Average weighted quantile loss (wQL)
---
### Detailed Explanation - Requirements Summary
The task is to evaluate a time-series forecasting model, which predicts continuous future values (e.g., sales, demand) based on historical patterns. Valid metrics must:
1. Measure error magnitude between predicted and actual values.
2. Handle sequential dependencies and uncertainty quantification (e.g., probabilistic forecasts).
---
### Analysis of the Correct Answers
#### C. Root Mean Square Error (RMSE)
- Formula: RMSE=n1∑t=1n(yt−y^t)2,
where ytyt = actual value, y^ty^t = predicted value.
- Why it applies:
- RMSE penalizes large errors quadratically, making it ideal for regression tasks like forecasting.
- Widely used in time-series evaluation (e.g., energy demand prediction, stock price forecasting).
#### E. Average Weighted Quantile Loss (wQL)
- Formula: wQL=n1∑t=1n∑q∈Q∣y^t0.5−yt∣2⋅QL(yt,y^tq,q),
where QL=max(q(yt−y^tq),(1−q)(y^tq−yt))QL=max(q(yt−y^tq),(1−q)(y^tq−yt)).
- Why it applies:
- Evaluates probabilistic forecasts (e.g., predicting the 10th, 50th, 90th percentiles).
- Assigns weights to errors at different quantiles (e.g., penalizing underestimation of high-demand scenarios).
- Used by Amazon Forecast and other time-series tools for uncertainty-aware evaluation.
---
### Key Differentiators
- RMSE vs. Classification Metrics (A/B):
- Time-series forecasting is a regression problem, making RMSE (C) suitable. Classification metrics like Recall (A) and LogLoss (B) are irrelevant.
- wQL vs. InferenceLatency (D):
- InferenceLatency measures prediction speed, not model accuracy. wQL (E) directly evaluates forecast quality, especially for probabilistic models.
---
### Analysis of Incorrect Options
A. Recall
- Used for classification tasks (e.g., detecting fraud). Does not apply to continuous-value forecasting.
B. LogLoss
- Measures confidence in probabilistic classification (e.g., predicting probabilities of class labels). Irrelevant for regression.
D. InferenceLatency
- Tracks computational performance (e.g., milliseconds per prediction) but does not assess forecast accuracy.
---
### Conclusion
C (RMSE) and E (wQL) are the only metrics that evaluate the accuracy of time-series forecasts:
- RMSE quantifies overall error magnitude.
- wQL assesses probabilistic forecasts (e.g., uncertainty intervals).
Other options (A/B/D) are misaligned with regression or time-series requirements. RMSE and wQL are industry standards for models like ARIMA, Prophet, or deep learning-based forecasters (e.g., DeepAR).
A company runs Amazon SageMaker ML models that use accelerated instances. The models require real-time responses. Each model has different scaling requirements. The company must not allow a cold start for the models.
Which solution will meet these requirements?
A. Create a SageMaker Serverless Inference endpoint for each model. Use provisioned concurrency for the endpoints.
B. Create a SageMaker Asynchronous Inference endpoint for each model. Create an auto scaling policy for each endpoint.
C. Create a SageMaker endpoint. Create an inference component for each model. In the inference component settings, specify the newly created endpoint. Create an auto scaling policy for each inference component. Set the parameter for the minimum number of copies to at least 1.
D. Create an Amazon S3 bucket. Store all the model artifacts in the S3 bucket. Create a SageMaker multi-model endpoint. Point the endpoint to the S3 bucket. Create an auto scaling policy for the endpoint. Set the parameter for the minimum number of copies to at least 1.
Answer: C. Create a SageMaker endpoint. Create an inference component for each model. In the inference component settings, specify the newly created endpoint. Create an auto scaling policy for each inference component. Set the parameter for the minimum number of copies to at least 1.
---
### Detailed Explanation - Requirements Summary
The company requires:
1. Real-time inference (low-latency responses) using accelerated instances (e.g., GPU/Inferentia).
2. Independent scaling for each model to handle varying workloads.
3. Elimination of cold starts: Models must remain warm and ready to serve requests.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
SageMaker Inference Components allow multiple models to be deployed on a single endpoint while enabling per-model scaling and resource allocation:
1. No Cold Starts:
- By setting the minimum number of copies to 1 in the auto scaling policy, at least one instance of each model’s inference component is always running. This keeps the model loaded in memory/GPU, avoiding initialization delays.
2. Independent Scaling:
- Auto scaling policies can be tailored to each inference component (model) based on metrics like InvocationsPerInstance or GPUUtilization.
3. Accelerated Instances:
- Inference components support GPU/Inferentia instances, ensuring real-time performance for compute-intensive models.
4. Cost Efficiency:
- Consolidates multiple models on a shared endpoint while maintaining isolation and scalability.
Why It Meets the Requirements:
- Ensures models are always warm (minimum instance count = 1).
- Enables real-time responses via accelerated instances.
- Scales each model independently based on demand.
---
### Key Differentiators for Option C
- Inference Components vs. Multi-Model Endpoints (Option D):
- Multi-model endpoints dynamically load/unload models from disk, risking cold starts if a model is evicted from memory.
- Inference Components keep models persistently loaded, guaranteeing readiness.
- Real-Time vs. Serverless/Async (Options A/B):
- Serverless Inference (A) does not support accelerated instances (GPUs/Inferentia) and has latency limits.
- Async Inference (B) is for batch processing, not real-time.
---
### Analysis of Incorrect Options
A. SageMaker Serverless Inference with Provisioned Concurrency
- Drawbacks:
- Serverless Inference is limited to CPU instances and cannot use GPUs.
- Provisioned Concurrency keeps CPU instances warm but does not apply to accelerated hardware.
B. SageMaker Asynchronous Inference with Auto Scaling
- Drawbacks:
- Designed for offline/batch processing (responses are delivered via S3). Not suitable for real-time use cases.
D. Multi-Model Endpoint with S3
- Drawbacks:
- Models are loaded into memory on-demand, leading to cold starts if a model is inactive.
- S3-based loading introduces latency during model retrieval.
---
### Conclusion
Option C is the only solution that:
1. Guarantees no cold starts via persistent inference components.
2. Supports accelerated instances for real-time performance.
3. Allows per-model scaling to optimize resource usage.
Alternatives like multi-model endpoints (D) or Serverless (A) fail to meet latency or hardware requirements, while Async Inference (B) is incompatible with real-time use cases. Inference Components provide the precise balance of scalability, performance, and cost for production ML workloads.
A company runs training jobs on Amazon SageMaker by using a compute optimized instance. Demand for training runs will remain constant for the next 55 weeks. The instance needs to run for 35 hours each week. The company needs to reduce its model training costs.
Which solution will meet these requirements?
A. Use a serverless endpoint with a provisioned concurrency of 35 hours for each week. Run the training on the endpoint.
B. Use SageMaker Edge Manager for the training. Specify the instance requirement in the edge device configuration. Run the training.
C. Use the heterogeneous cluster feature of SageMaker Training. Configure the instance_type, instance_count, and instance_groups arguments to run training jobs.
D. Opt in to a SageMaker Savings Plan with a 1-year term and an All Upfront payment. Run a SageMaker Training job on the instance.
Answer: D. Opt in to a SageMaker Savings Plan with a 1-year term and an All Upfront payment. Run a SageMaker Training job on the instance.
---
### Detailed Explanation - Requirements Summary
The company must reduce costs for SageMaker training jobs under the following conditions:
1. Predictable workload: Training jobs run on a compute-optimized instance for 35 hours/week over 55 weeks (≈1.06 years).
2. Cost optimization: Minimize expenses for long-term, steady usage.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
SageMaker Savings Plans provide discounted pricing in exchange for a commitment to a consistent compute usage (measured in $/hour) over a 1- or 3-year term.
1. 1-Year All Upfront Savings Plan:
- Discount: Up to 64% savings compared to on-demand pricing for SageMaker training.
- Payment: Full upfront payment maximizes discounts and eliminates ongoing billing.
2. Coverage:
- Applies to all SageMaker workloads (training, inference, processing) across instance types (compute-optimized, GPU, etc.).
- Automatically applies to any usage in the selected region, reducing administrative overhead.
3. Cost Reduction:
- For a fixed 55-week workload, a 1-year term aligns perfectly with the usage period, ensuring full discount utilization.
Why It Meets the Requirements:
- Guarantees the lowest possible rate for long-term, predictable workloads.
- Requires no architectural changes (e.g., instance types, job configuration).
---
### Key Differentiators for Option D
- Savings Plans vs. On-Demand:
- On-demand pricing is pay-as-you-go with no discounts. Savings Plans offer commitment-based pricing, ideal for steady workloads.
- Savings Plans vs. Reserved Instances:
- Reserved Instances (RIs) lock in instance types and regions, offering less flexibility. Savings Plans are usage-based and apply across instance families.
- All Upfront vs. Partial Payment:
- All Upfront payments yield the highest discounts (≈64% vs. ≈58% for partial upfront).
---
### Analysis of Incorrect Options
A. Serverless Endpoint with Provisioned Concurrency
- Drawbacks:
- Serverless Inference is for real-time inference, not training.
- Provisioned Concurrency applies to AWS Lambda, not SageMaker.
B. SageMaker Edge Manager
- Drawbacks:
- Edge Manager is for deploying models to edge devices (e.g., IoT devices), not training jobs.
- Training on edge devices would increase latency and costs for compute-intensive workloads.
C. Heterogeneous Clusters
- Drawbacks:
- Heterogeneous clusters allow mixing instance types (e.g., CPU + GPU) in a single training job.
- The question specifies a fixed compute-optimized instance with no need for instance flexibility. This feature does not reduce costs for static workloads.
---
### Conclusion
Option D is the only solution that directly reduces costs for long-term, predictable SageMaker training workloads:
1. Savings Plans provide the deepest discounts for steady usage.
2. All Upfront payment maximizes savings over the 55-week period.
Alternatives like Edge Manager (B) or heterogeneous clusters (C) are irrelevant to cost optimization, while Serverless (A) is incompatible with training jobs. By leveraging Savings Plans, the company minimizes expenses without altering its existing workflow.
A company deployed an ML model that uses the XGBoost algorithm to predict product failures. The model is hosted on an Amazon SageMaker endpoint and is trained on normal operating data. An AWS Lambda function provides the predictions to the company's application.
An ML engineer must implement a solution that uses incoming live data to detect decreased model accuracy over time.
Which solution will meet these requirements?
A. Use Amazon CloudWatch to create a dashboard that monitors real-time inference data and model predictions. Use the dashboard to detect drift.
B. Modify the Lambda function to calculate model drift by using real-time inference data and model predictions. Program the Lambda function to send alerts.
C. Schedule a monitoring job in SageMaker Model Monitor. Use the job to detect drift by analyzing the live data against a baseline of the training data statistics and constraints.
D. Schedule a monitoring job in SageMaker Debugger. Use the job to detect drift by analyzing the live data against a baseline of the training data statistics and constraints.
Answer: C. Schedule a monitoring job in SageMaker Model Monitor. Use the job to detect drift by analyzing the live data against a baseline of the training data statistics and constraints.
---
### Detailed Explanation - Requirements Summary
The company needs to:
1. Detect model accuracy degradation (drift) caused by changes in live data distributions compared to the original training data.
2. Use incoming live inference data to monitor drift over time.
3. Implement a solution with minimal custom code or infrastructure.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Amazon SageMaker Model Monitor is purpose-built for continuous monitoring of deployed ML models. Here’s how Option C addresses the requirements:
1. Baseline Creation:
- Model Monitor uses the training dataset to compute baseline statistics (e.g., feature distributions, data types) and constraints (e.g., valid ranges for numeric features).
2. Scheduled Monitoring Jobs:
- A monitoring job is configured to periodically analyze live data captured from the SageMaker endpoint (stored in Amazon S3 via Endpoint Data Capture).
- Compares live data statistics against the baseline to detect data drift (e.g., feature skew, schema violations) and model quality drift (if ground truth labels are provided).
3. Automated Alerts:
- Drift detection results are published to Amazon CloudWatch, triggering alerts via SNS or automated workflows (e.g., retraining pipelines).
Why It Meets the Requirements:
- No code changes: Model Monitor integrates natively with SageMaker endpoints and requires only configuration.
- Specialized for drift detection: Uses statistical tests (e.g., K-S test, KL divergence) to quantify drift severity.
- Handles live data: Automatically processes incoming inference payloads.
---
### Key Differentiators for Option C
- Model Monitor vs. CloudWatch (A):
- CloudWatch tracks metrics (e.g., latency, invocations) but lacks built-in statistical drift analysis. Model Monitor directly compares live data distributions to training baselines.
- Model Monitor vs. Lambda (B):
- Lambda-based drift calculation requires custom code to compute statistical metrics (e.g., KL divergence) and manage baselines. Model Monitor automates this.
- Model Monitor vs. Debugger (D):
- Debugger focuses on training job analysis (e.g., gradient/weight monitoring). It does not monitor live inference data.
---
### Analysis of Incorrect Options
A. CloudWatch Dashboard
- Drawbacks:
- CloudWatch cannot perform statistical comparisons between live data and training baselines. It would require manual metric logging (e.g., custom feature distributions), which is error-prone.
B. Lambda Function with Drift Calculation
- Drawbacks:
- Adds latency to inference requests if drift calculation is synchronous.
- Requires storing training data statistics and maintaining complex comparison logic in Lambda.
D. SageMaker Debugger
- Drawbacks:
- Debugger is designed to monitor training jobs, not live inference data. It cannot detect post-deployment drift.
---
### Conclusion
Option C is the only solution that:
1. Automates drift detection using SageMaker Model Monitor’s built-in statistical analysis.
2. Requires no code changes to the existing SageMaker endpoint or Lambda function.
3. Scales seamlessly with scheduled jobs and CloudWatch integration.
Alternatives like Lambda (B) or CloudWatch (A) lack specialized drift detection capabilities, while Debugger (D) is irrelevant for post-deployment monitoring. Model Monitor provides a managed, low-effort solution to ensure model accuracy over time.
A company has an ML model that uses historical transaction data to predict customer behavior. An ML engineer is optimizing the model in Amazon SageMaker to enhance the model's predictive accuracy. The ML engineer must examine the input data and the resulting predictions to identify trends that could skew the model's performance across different demographics.
Which solution will provide this level of analysis?
A. Use Amazon CloudWatch to monitor network metrics and CPU metrics for resource optimization during model training.
B. Create AWS Glue DataBrew recipes to correct the data based on statistics from the model output.
C. Use SageMaker Clarify to evaluate the model and training data for underlying patterns that might affect accuracy.
D. Create AWS Lambda functions to automate data pre-processing and to ensure consistent quality of input data for the model.
Answer: C. Use SageMaker Clarify to evaluate the model and training data for underlying patterns that might affect accuracy.
---
### Detailed Explanation - Requirements Summary
The ML engineer must:
1. Analyze input data and model predictions to identify trends or biases.
2. Detect skewed performance across demographics (e.g., age, gender, location).
3. Use a solution integrated with Amazon SageMaker to optimize model fairness and accuracy.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Amazon SageMaker Clarify is purpose-built for bias detection, explainability, and fairness analysis in ML models. Here’s how it addresses the requirements:
1. Bias Detection in Training Data:
- Evaluates input datasets for imbalances (e.g., underrepresented groups, skewed feature distributions) using metrics like:
- Class Imbalance: Checks if demographic groups are unevenly represented.
- Pre-training Bias Metrics: Computes metrics like Class Imbalance (CI), Difference in Proportions of Labels (DPL), and Kullback-Leibler (KL) Divergence to quantify data bias.
2. Post-training Model Fairness Analysis:
- Analyzes model predictions to detect disparate impact across demographics. Metrics include:
- Disparate Impact Ratio (DIR): Compares favorable prediction rates between groups.
- Confusion Matrix Disparities: Examines differences in false positive/negative rates (e.g., Equal Opportunity Difference).
3. Feature Attribution:
- Uses techniques like SHAP (SHapley Additive exPlanations) to identify which input features (e.g., income, location) most influence predictions, exposing potential biases.
Why It Meets the Requirements:
- Directly addresses demographic skew by analyzing data and predictions.
- Integrates natively with SageMaker training jobs and endpoints, requiring minimal setup.
- Generates actionable reports with visualizations (e.g., bias scores, feature importance).
---
### Key Differentiators for Option C
- Clarify vs. DataBrew (B) or Lambda (D):
- DataBrew and Lambda focus on data preprocessing, not bias detection. Clarify specializes in identifying fairness issues.
- Clarify vs. CloudWatch (A):
- CloudWatch tracks system metrics (CPU, latency), not model fairness or data distributions.
---
### Analysis of Incorrect Options
A. Amazon CloudWatch for Network/CPU Metrics
- Monitors infrastructure performance (e.g., instance health, latency) but cannot analyze data/predictions for demographic bias.
B. AWS Glue DataBrew Recipes
- Cleans and transforms data (e.g., filling missing values) but lacks tools to evaluate model fairness or demographic disparities.
D. AWS Lambda for Data Preprocessing
- Ensures consistent input data quality but does not analyze predictions or detect biases in model behavior.
---
### Conclusion
Option C is the only solution that:
1. Identifies biases in both training data and model predictions.
2. Quantifies demographic disparities using fairness-specific metrics.
3. Provides SageMaker-native integration for seamless analysis.
Alternatives like DataBrew (B) or Lambda (D) address data quality, not fairness, while CloudWatch (A) focuses on system health. SageMaker Clarify is explicitly designed to uncover and mitigate biases that skew model performance across groups, aligning perfectly with the requirements.
A company uses 10 Reserved Instances of accelerated instance types to serve the current version of an ML model. An ML engineer needs to deploy a new version of the model to an Amazon SageMaker real-time inference endpoint.
The solution must use the original 10 instances to serve both versions of the model. The solution also must include one additional Reserved Instance that is available to use in the deployment process. The transition between versions must occur with no downtime or service interruptions.
Which solution will meet these requirements?
A. Configure a blue/green deployment with all-at-once traffic shifting.
B. Configure a blue/green deployment with canary traffic shifting and a size of 10%.
C. Configure a shadow test with a traffic sampling percentage of 10%.
D. Configure a rolling deployment with a rolling batch size of 1.
Answer: B. Configure a blue/green deployment with canary traffic shifting and a size of 10%.
---
### Detailed Explanation - Requirements Summary
The company must:
1. Deploy a new model version using 10 existing Reserved Instances (RIs) and 1 additional RI for the transition.
2. Ensure zero downtime during deployment.
3. Serve both old (blue) and new (green) model versions using the original RIs.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
SageMaker’s blue/green deployment with canary traffic shifting addresses the requirements as follows:
1. Blue/Green Architecture:
- The original 10 RIs host the blue (current) environment, serving 90% of traffic initially.
- The additional RI hosts the green (new) environment, serving 10% of traffic (canary phase).
2. Gradual Traffic Shift:
- Traffic is incrementally shifted from blue to green (e.g., 10% → 50% → 100%) while monitoring performance.
- SageMaker automatically scales the green environment to use the original RIs as traffic increases, ensuring all 10 RIs eventually serve the new version.
3. No Downtime:
- Both environments run concurrently during the transition. Users experience uninterrupted service.
Why It Meets the Requirements:
- Uses the original 10 RIs for both versions during the transition.
- Leverages the additional RI for initial canary testing.
- Ensures a seamless shift with no downtime.
---
### Key Differentiators for Option B
- Canary vs. All-at-Once (A):
- All-at-once shifts 100% traffic instantly, risking downtime if the new model fails. Canary minimizes risk by validating the new version on a small traffic subset first.
- Blue/Green vs. Rolling (D):
- Rolling deployments update instances incrementally, but this risks transient errors during partial updates. Blue/green keeps both versions fully operational.
- Reserved Instance Utilization:
- SageMaker automatically reallocates RIs between blue and green environments during traffic shifts, ensuring cost efficiency.
---
### Analysis of Incorrect Options
A. Blue/Green with All-at-Once Traffic Shifting
- Drawbacks:
- Shifts 100% traffic instantly, risking downtime if the new model has issues.
- Does not use the additional RI for gradual validation.
C. Shadow Test
- Drawbacks:
- Tests the new model in parallel but does not serve live traffic.
- Does not transition users to the new version, failing the deployment requirement.
D. Rolling Deployment
- Drawbacks:
- Updates instances one-by-one, creating a mixed environment where some instances run old/new versions.
- Risks inconsistencies during partial updates and does not guarantee zero downtime.
---
### Conclusion
Option B is the only solution that:
1. Uses canary traffic shifting to validate the new model on 10% traffic (via the additional RI).
2. Gradually transitions all traffic to the original 10 RIs, ensuring no downtime.
3. Aligns with AWS best practices for zero-downtime deployments in SageMaker.
Alternatives like all-at-once (A) or rolling (D) introduce risks, while shadow tests (C) do not deploy the new version. Blue/green with canary balances safety, cost, and compliance with Reserved Instance usage.
An IoT company uses Amazon SageMaker to train and test an XGBoost model for object detection. ML engineers need to monitor performance metrics when they train the model with variants in hyperparameters. The ML engineers also need to send Short Message Service (SMS) text messages after training is complete.
Which solution will meet these requirements?
A. Use Amazon CloudWatch to monitor performance metrics. Use Amazon Simple Queue Service (Amazon SQS) for message delivery.
B. Use Amazon CloudWatch to monitor performance metrics. Use Amazon Simple Notification Service (Amazon SNS) for message delivery.
C. Use AWS CloudTrail to monitor performance metrics. Use Amazon Simple Queue Service (Amazon SQS) for message delivery.
D. Use AWS CloudTrail to monitor performance metrics. Use Amazon Simple Notification Service (Amazon SNS) for message delivery.
Answer: B. Use Amazon CloudWatch to monitor performance metrics. Use Amazon Simple Notification Service (Amazon SNS) for message delivery.
---
### Detailed Explanation - Requirements Summary
The IoT company requires:
1. Real-time monitoring of training metrics (e.g., accuracy, loss) during hyperparameter tuning for an XGBoost model.
2. SMS notifications upon training job completion.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Amazon CloudWatch and Amazon SNS together address both requirements:
1. Monitoring with CloudWatch:
- SageMaker automatically streams training job metrics (e.g., validation:auc, train:error) to CloudWatch.
- ML engineers can create dashboards or set alarms to track hyperparameter performance in real time.
2. SMS Notifications with SNS:
- Configure SageMaker training jobs to publish completion events to an Amazon SNS topic.
- SNS supports SMS subscriptions, enabling engineers to receive text alerts when training finishes.
Why It Meets the Requirements:
- CloudWatch is the native service for monitoring SageMaker training metrics.
- SNS directly supports SMS delivery, eliminating the need for custom SMS gateways.
---
### Key Differentiators for Option B
- CloudWatch vs. CloudTrail (C/D):
- CloudTrail logs API activity (e.g., who started a training job) but does not capture model performance metrics.
- CloudWatch is purpose-built for operational and performance monitoring.
- SNS vs. SQS (A/C):
- SQS is a message queuing service and cannot send SMS directly.
- SNS supports SMS, email, and mobile push notifications out-of-the-box.
---
### Analysis of Incorrect Options
A/C. Use SQS for Message Delivery
- Drawbacks:
- SQS requires additional Lambda functions or applications to poll the queue and send SMS, adding complexity.
- Not natively integrated with SageMaker for notifications.
C/D. Use CloudTrail for Monitoring Metrics
- Drawbacks:
- CloudTrail tracks administrative actions (e.g., CreateTrainingJob) but not model accuracy or loss metrics.
---
### Conclusion
Option B is the only solution that:
1. Uses CloudWatch to monitor hyperparameter tuning metrics during training.
2. Leverages SNS to send SMS alerts post-training without custom code.
Alternatives like SQS (A/C) or CloudTrail (C/D) fail to meet the specific requirements for performance tracking and SMS delivery. CloudWatch and SNS provide a fully managed, serverless approach to monitoring and notifications.
A company is working on an ML project that will include Amazon SageMaker notebook instances. An ML engineer must ensure that the SageMaker notebook instances do not allow root access.
Which solution will prevent the deployment of notebook instances that allow root access?
A. Use IAM condition keys to stop deployments of SageMaker notebook instances that allow root access.
B. Use AWS Key Management Service (AWS KMS) keys to stop deployments of SageMaker notebook instances that allow root access.
C. Monitor resource creation by using Amazon EventBridge events. Create an AWS Lambda function that deletes all deployed SageMaker notebook instances that allow root access.
D. Monitor resource creation by using AWS CloudFormation events. Create an AWS Lambda function that deletes all deployed SageMaker notebook instances that allow root access.
Answer: A. Use IAM condition keys to stop deployments of SageMaker notebook instances that allow root access.
---
### Detailed Explanation - Requirements Summary
The company must:
1. Prevent deployment of SageMaker notebook instances that allow root access.
2. Enforce compliance proactively (block creation) rather than reactively (delete after deployment).
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
AWS Identity and Access Management (IAM) supports condition keys to enforce granular controls over AWS API actions. For SageMaker’s CreateNotebookInstance API:
1. Condition Key: sagemaker:RootAccess specifies whether root access is enabled EnabledDisabled) for the notebook instance.
2. IAM Policy Example:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Action": "sagemaker:CreateNotebookInstance",
"Resource": "*",
"Condition": {
"StringNotEquals": {
"sagemaker:RootAccess": "Disabled"
}
}
}
]
}- This policy denies notebook instance creation unless RootAccess is explicitly set to Disabled.
3. Proactive Enforcement:
- Blocks non-compliant deployments at the API level, preventing root access from being enabled.
---
### Key Differentiators for Option A
- Preventative vs. Reactive:
- IAM conditions block non-compliant deployments upfront, eliminating the risk of temporary exposure (unlike Options C/D, which delete resources post-creation).
- Native Integration:
- SageMaker natively supports the sagemaker:RootAccess condition key, requiring no custom code or external services.
---
### Analysis of Incorrect Options
B. AWS KMS Keys
- KMS manages encryption keys and cannot enforce notebook instance configurations like root access. Irrelevant to the requirement.
C/D. EventBridge/CloudFormation + Lambda
- Drawbacks:
- Reactive approach: Notebook instances with root access are temporarily deployed before deletion, violating the requirement.
- Adds operational overhead (Lambda development, event monitoring).
---
### Conclusion
Option A is the only solution that:
1. Proactively blocks non-compliant notebook instance deployments using IAM policies.
2. Aligns with AWS security best practices by enforcing guardrails at the API level.
Options C/D fail to prevent deployment, while Option B (KMS) is unrelated. IAM condition keys provide a serverless, zero-maintenance method to enforce compliance.
A company is using Amazon SageMaker to develop ML models. The company stores sensitive training data in an Amazon S3 bucket. The model training must have network isolation from the internet.
Which solution will meet this requirement?
A. Run the SageMaker training jobs in private subnets. Create a NAT gateway. Route traffic for training through the NAT gateway.
B. Run the SageMaker training jobs in private subnets. Create an S3 gateway VPC endpoint. Route traffic for training through the S3 gateway VPC endpoint.
C. Run the SageMaker training jobs in public subnets that have an attached security group. In the security group, use inbound rules to limit traffic from the internet. Encrypt SageMaker instance storage by using server-side encryption with AWS KMS keys (SSE-KMS).
D. Encrypt traffic to Amazon S3 by using a bucket policy that includes a value of True for the aws:SecureTransport condition key. Use default at-rest encryption for Amazon S3. Encrypt SageMaker instance storage by using server-side encryption with AWS KMS keys (SSE-KMS).
Answer: B. Run the SageMaker training jobs in private subnets. Create an S3 gateway VPC endpoint. Route traffic for training through the S3 gateway VPC endpoint.
---
### Detailed Explanation - Requirements Summary
The company must ensure that SageMaker training jobs:
1. Operate with network isolation (no internet exposure).
2. Securely access sensitive training data stored in Amazon S3.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Amazon VPC Private Subnets + S3 Gateway VPC Endpoint:
1. Private Subnet Deployment:
- Training jobs run in private subnets, which have no route to the internet (no internet gateway or NAT device).
2. S3 Gateway VPC Endpoint:
- Creates a private connection between the VPC and Amazon S3, bypassing the public internet.
- Routes S3 traffic through AWS’s internal network, ensuring data never traverses the internet.
3. Security:
- Combined with VPC security groups and S3 bucket policies, this architecture enforces strict network isolation while allowing training jobs to access S3 data.
Why It Meets the Requirements:
- Eliminates internet exposure for training jobs.
- Enables secure, private access to S3 without NAT gateways or public subnets.
---
### Key Differentiators for Option B
- VPC Endpoint vs. NAT Gateway (Option A):
- A NAT gateway allows private subnets to access the internet (e.g., for software updates) but violates the requirement for full network isolation.
- An S3 VPC endpoint keeps S3 traffic entirely within AWS’s network, ensuring no internet exposure.
- Network Isolation vs. Encryption (Option D):
- Encryption (in transit/at rest) secures data but does not prevent internet routing. Option B enforces network isolation.
---
### Analysis of Incorrect Options
A. Private Subnets + NAT Gateway
- Drawbacks:
- A NAT gateway resides in a public subnet and allows outbound internet access, violating the requirement for isolation.
C. Public Subnets + Security Groups
- Drawbacks:
- Public subnets have a route to an internet gateway, exposing training jobs to the internet.
- Inbound rules do not prevent outbound internet access.
D. Encryption-Based Solutions
- Drawbacks:
- Encryption (e.g., HTTPS via aws:SecureTransport) secures data but does not isolate network traffic.
- Training jobs in public subnets or using NAT gateways still route traffic through the internet.
---
### Conclusion
Option B is the only solution that:
1. Runs training jobs in private subnets with no internet gateway/NAT.
2. Uses an S3 VPC endpoint to ensure all S3 traffic remains within AWS’s network.
This architecture guarantees network isolation while maintaining access to S3 data. Options A/C/D fail to fully isolate traffic from the internet, as they either allow internet routing (NAT) or use public subnets.
A company needs an AWS solution that will automatically create versions of ML models as the models are created.
Which solution will meet this requirement?
A. Amazon Elastic Container Registry (Amazon ECR)
B. Model packages from Amazon SageMaker Marketplace
C. Amazon SageMaker ML Lineage Tracking
D. Amazon SageMaker Model Registry
Answer: D. Amazon SageMaker Model Registry
---
### Detailed Explanation - Requirements Summary
The company needs a solution to automatically version ML models as they are created, ensuring organized tracking and management of model iterations.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Amazon SageMaker Model Registry is purpose-built for model versioning and lifecycle management:
1. Automatic Versioning:
- When a model is registered (via CreateModelPackage API or SageMaker Pipelines), the Model Registry assigns a unique version ID (e.g., v1.0, v2.0).
- Integrates with SageMaker training jobs and pipelines to trigger versioning automatically upon model creation.
2. Metadata Tracking:
- Captures metadata such as training datasets, hyperparameters, and evaluation metrics alongside each version.
3. CI/CD Integration:
- Works with SageMaker Projects and MLOps pipelines to automate versioning during model deployment workflows.
Why It Meets the Requirements:
- Directly addresses the need for automatic, sequential versioning as models are created.
- Provides a centralized repository for managing model iterations.
---
### Key Differentiators for Option D
- Model Registry vs. ECR (A):
- ECR versions Docker container images, not ML models. Models may be packaged in containers, but ECR does not track model-specific metadata or lifecycle stages.
- Model Registry vs. Marketplace (B):
- Marketplace facilitates model sharing but does not automate versioning for internal model development.
- Model Registry vs. Lineage Tracking (C):
- Lineage Tracking records dependencies (e.g., datasets, training jobs) but does not create explicit model versions.
---
### Analysis of Incorrect Options
A. Amazon ECR
- Manages container images, not ML models. Versioning applies to Docker images, not model artifacts or metadata.
B. SageMaker Marketplace Model Packages
- Designed for publishing/subscribing to pre-built models. Does not automate versioning for internally developed models.
C. SageMaker ML Lineage Tracking
- Tracks relationships between model components (e.g., training jobs, datasets) for audit purposes but does not create model versions.
---
### Conclusion
Option D (SageMaker Model Registry) is the only service that:
1. Automatically generates and tracks model versions upon creation.
2. Integrates natively with SageMaker training and deployment workflows.
Alternatives like ECR (A) or Lineage Tracking (C) lack versioning capabilities for models, while Marketplace (B) focuses on external distribution. The Model Registry ensures consistent, auditable model management for iterative ML development.
A company needs to use Retrieval Augmented Generation (RAG) to supplement an open source large language model (LLM) that runs on Amazon Bedrock. The company's data for RAG is a set of documents in an Amazon S3 bucket. The documents consist of .csv files and .docx files.
Which solution will meet these requirements with the LEAST operational overhead?
A. Create a pipeline in Amazon SageMaker Pipelines to generate a new model. Call the new model from Amazon Bedrock to perform RAG queries.
B. Convert the data into vectors. Store the data in an Amazon Neptune database. Connect the database to Amazon Bedrock. Call the Amazon Bedrock API to perform RAG queries.
C. Fine-tune an existing LLM by using an AutoML job in Amazon SageMaker. Configure the S3 bucket as a data source for the AutoML job. Deploy the LLM to a SageMaker endpoint. Use the endpoint to perform RAG queries.
D. Create a knowledge base for Amazon Bedrock. Configure a data source that references the S3 bucket. Use the Amazon Bedrock API to perform RAG queries.
Answer: D. Create a knowledge base for Amazon Bedrock. Configure a data source that references the S3 bucket. Use the Amazon Bedrock API to perform RAG queries.
---
### Detailed Explanation - Requirements Summary
The company needs to implement Retrieval Augmented Generation (RAG) using an open-source LLM on Amazon Bedrock, with data stored in an S3 bucket (CSV and DOCX files). The solution must minimize operational overhead.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Amazon Bedrock Knowledge Bases provide a fully managed RAG solution:
1. Automated Data Ingestion:
- Bedrock automatically processes documents from the S3 bucket (including CSV and DOCX), splits text into chunks, generates embeddings using a built-in or custom model, and stores vectors in a managed vector store (e.g., Amazon OpenSearch Serverless, Aurora, or Pinecone).
2. Zero Infrastructure Management:
- No need to manually convert files to vectors, set up databases, or manage chunking/embedding pipelines.
3. Integration with Bedrock LLMs:
- Query the knowledge base via the Bedrock API RetrieveAndGenerate), which retrieves relevant context and feeds it to the LLM for response generation.
Why It Meets the Requirements:
- Least operational overhead: Bedrock handles data processing, storage, and retrieval without requiring custom code or infrastructure.
- Directly supports CSV/DOCX files in S3 as a data source.
---
### Key Differentiators for Option D
- Managed RAG vs. Manual Workflows (A/B/C):
- Options A/B/C require manual steps like vectorization, database setup, or model fine-tuning.
- Bedrock Knowledge Bases abstract these tasks into a serverless, fully managed service.
- Native S3 Integration:
- Bedrock natively reads from S3, avoiding data migration or preprocessing.
---
### Analysis of Incorrect Options
A. SageMaker Pipelines + Custom Model
- Requires building a custom model and pipeline, adding significant development and maintenance effort.
B. Amazon Neptune + Manual Vectorization
- Neptune is a graph database, not optimized for vector search. Manual embedding generation and pipeline setup introduce complexity.
C. SageMaker AutoML Fine-Tuning
- Fine-tuning modifies the LLM itself, which is unrelated to RAG. Requires deploying endpoints and managing training jobs.
---
### Conclusion
Option D is the only solution that:
1. Uses Bedrock’s managed RAG capabilities to automate document processing, vector storage, and retrieval.
2. Eliminates operational tasks like infrastructure management or pipeline development.
3. Directly integrates with S3 and Bedrock’s API for seamless querying.
By leveraging Bedrock Knowledge Bases, the company avoids the complexity of manual RAG implementation while ensuring scalability and minimal maintenance.
A company plans to deploy an ML model for production inference on an Amazon SageMaker endpoint. The average inference payload size will vary from 100 MB to 300 MB. Inference requests must be processed in 60 minutes or less.
Which SageMaker inference option will meet these requirements?
A. Serverless inference
B. Asynchronous inference
C. Real-time inference
D. Batch transform
Answer: B. Asynchronous inference
---
### Detailed Explanation - Requirements Summary
The company requires a SageMaker inference solution that:
1. Handles large payloads (100 MB to 300 MB).
2. Supports processing times up to 60 minutes.
3. Operates in production with on-demand request handling.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Amazon SageMaker Asynchronous Inference is designed for large payloads and long-running inference tasks:
1. Payload and Timeout Support:
- Payload Size: Accepts input up to 1 GB (well within the 100–300 MB requirement).
- Processing Time: Allows configurable timeouts up to 60 minutes (default: 15 minutes, adjustable via InferenceIdTTL).
2. Workflow:
- Requests are queued and processed asynchronously. Results are stored in Amazon S3 and retrieved via a callback or polling.
3. Scalability:
- Automatically scales instance counts to handle workloads, ensuring reliable processing of large payloads.
Why It Meets the Requirements:
- Large payloads: Designed for inputs up to 1 GB.
- Extended processing: Configurable to meet the 60-minute timeout.
---
### Key Differentiators for Option B
- Asynchronous vs. Real-Time (C):
- Real-time inference has strict latency limits (milliseconds to seconds) and smaller payload limits (up to 6 MB for HTTP requests).
- Asynchronous inference handles larger payloads and longer processing times.
- Asynchronous vs. Batch Transform (D):
- Batch Transform processes pre-stored datasets offline, not individual on-demand requests.
- Asynchronous vs. Serverless (A):
- Serverless inference has a 5 MB payload limit and 60-second timeout, making it unsuitable for this use case.
---
### Analysis of Incorrect Options
A. Serverless Inference
- Limited to 5 MB payloads and 60-second timeouts, incompatible with 100–300 MB inputs and 60-minute processing.
C. Real-Time Inference
- Designed for low-latency requests (sub-second responses) and small payloads (≤6 MB via HTTP).
D. Batch Transform
- Processes bulk datasets (e.g., CSV/Parquet files in S3) in batch mode, not individual inference requests.
---
### Conclusion
Asynchronous Inference (B) is the only option that:
1. Supports large payloads (up to 1 GB).
2. Allows 60-minute processing windows.
3. Handles individual requests for production use cases.
Other options (A/C/D) fail due to payload size limits, latency constraints, or batch-only processing. Asynchronous inference aligns perfectly with the requirements for scalable, long-running inference on large inputs.
An ML engineer notices class imbalance in an image classification training job.
What should the ML engineer do to resolve this issue?
A. Reduce the size of the dataset.
B. Transform some of the images in the dataset.
C. Apply random oversampling on the dataset.
D. Apply random data splitting on the dataset.
Answer: C. Apply random oversampling on the dataset.
---
### Detailed Explanation - Requirements Summary
The ML engineer must address class imbalance in an image classification task, where certain classes have significantly fewer samples than others. This imbalance can bias the model toward the majority class, reducing accuracy for underrepresented classes.
---
### Analysis of the Correct Answer - What It Does/Why It Meets the Requirements
Random oversampling resolves class imbalance by increasing the number of samples in minority classes:
1. Balancing Class Distribution:
- Duplicates or synthetically generates samples for minority classes (e.g., using techniques like SMOTE or image augmentation such as rotation, flipping, or scaling).
2. Improving Model Generalization:
- Ensures the model learns features from all classes equally, reducing bias toward the majority class.
3. Implementation in Image Classification:
- For images, oversampling often involves data augmentation (e.g., adding noise, cropping, or altering lighting) to artificially expand the minority class dataset.
Why It Meets the Requirements:
- Directly targets class imbalance by increasing minority class representation.
- Prevents the model from ignoring underrepresented classes during training.
---
### Key Differentiators for Option C
- Oversampling vs. Data Splitting (D):
- Splitting data into train/test sets (D) does not resolve imbalance—it merely partitions existing data, leaving the training set skewed.
- Oversampling vs. Image Transformation (B):
- Transforming images (B) may augment data but does not inherently address imbalance unless explicitly applied to minority classes. Oversampling systematically balances class distributions.
- Oversampling vs. Dataset Reduction (A):
- Reducing dataset size (A) worsens imbalance by discarding samples, potentially removing critical minority class examples.
---
### Analysis of Incorrect Options
A. Reduce the size of the dataset
- Aggravates imbalance by removing data, disproportionately affecting minority classes with fewer samples.
B. Transform some images
- While transformations (e.g., augmentation) can help, this option does not specify targeting minority classes. Without oversampling, transformations alone may not resolve imbalance.
D. Apply random data splitting
- Splitting data into train/validation/test sets does not alter class ratios in the training data. The model remains exposed to imbalanced distributions.
---
### Conclusion
Option C (random oversampling) is the only solution that directly mitigates class imbalance by increasing minority class representation. Techniques like duplication, synthetic sample generation (e.g., SMOTE), or image augmentation ensure balanced training data, improving model fairness and accuracy. Other options either worsen imbalance (A), are incomplete (B), or irrelevant (D).
A company receives daily .csv files about customer interactions with its ML model. The company stores the files in Amazon S3 and uses the files to retrain the model. An ML engineer needs to implement a solution to mask credit card numbers in the files before the model is retrained.
Which solution will meet this requirement with the LEAST development effort?
A. Create a discovery job in Amazon Macie. Configure the job to find and mask sensitive data.
B. Create Apache Spark code to run on an AWS Glue job. Use the Sensitive Data Detection functionality in AWS Glue to find and mask sensitive data.
C. Create Apache Spark code to run on an AWS Glue job. Program the code to perform a regex operation to find and mask sensitive data.
D. Create Apache Spark code to run on an Amazon EC2 instance. Program the code to perform an operation to find and mask sensitive data.
Answer: B. Create Apache Spark code to run on an AWS Glue job. Use the Sensitive Data Detection functionality in AWS Glue to find and mask sensitive data.
---
### Detailed Explanation
To mask credit card numbers in CSV files stored in Amazon S3 with minimal development effort:
1. AWS Glue Sensitive Data Detection:
- AWS Glue provides built-in classifiers to detect common sensitive data types (e.g., credit card numbers) using pattern matching and machine learning. This eliminates the need to write custom regex logic.
- The detection is automated and managed by AWS, reducing the risk of missing valid credit card patterns.
2. Integration with Spark Code:
- After detecting sensitive data, the engineer can use simple Glue transforms (e.g., ApplyMapping or ReplaceWithMask) to mask the identified fields. For example:
# Example AWS Glue ETL script snippet
masked_frame = ApplyMapping.apply(
frame = detected_sensitive_data,
mappings = [("credit_card_column", "string", "credit_card_column", "string")],
transformation_ctx = "masked_frame")
ReplaceWithMask.apply(frame = masked_frame, paths = ["credit_card_column"], mask_char = "*") - This approach leverages AWS-managed functionality, requiring fewer lines of code compared to manual regex implementation.
### Key Differentiators
- Managed Detection: AWS Glue’s Sensitive Data Detection handles complex pattern recognition (e.g., Luhn algorithm validation for credit cards), avoiding error-prone custom regex.
- Simplified Masking: Built-in transforms reduce development effort compared to writing and maintaining regex logic.
### Analysis of Incorrect Options
- A (Amazon Macie): Macie discovers sensitive data but does not support masking. Additional steps would be needed to modify the data.
- C (Custom Regex): Requires writing and maintaining regex for credit card detection, which is error-prone and time-consuming.
- D (EC2 + Custom Code): Introduces infrastructure management overhead, unlike serverless AWS Glue.
### Conclusion
Option B minimizes development effort by using AWS Glue’s managed sensitive data detection and built-in transforms, ensuring accurate masking without custom regex or infrastructure management.
A medical company is using AWS to build a tool to recommend treatments for patients. The company has obtained health records and self-reported textual information in English from patients. The company needs to use this information to gain insight about the patients.
Which solution will meet this requirement with the LEAST development effort?
A. Use Amazon SageMaker to build a recurrent neural network (RNN) to summarize the data.
B. Use Amazon Comprehend Medical to summarize the data.
C. Use Amazon Kendra to create a quick-search tool to query the data.
D. Use the Amazon SageMaker Sequence-to-Sequence (seq2seq) algorithm to create a text summary from the data.
Answer: B. Use Amazon Comprehend Medical to summarize the data.
---
### Detailed Explanation
Amazon Comprehend Medical is a purpose-built, fully managed service for analyzing and extracting insights from unstructured medical text. It requires no machine learning expertise or custom model development, making it the solution with the least development effort.
#### Why Option B Meets the Requirements:
1. Pre-Trained Medical NLP Capabilities:
- Automatically extracts medical entities (e.g., diagnoses, medications, procedures), relationships, and protected health information (PHI) from unstructured text (e.g., patient self-reports).
- Supports summarization of key clinical information (e.g., conditions, treatments) without requiring custom code.
2. Managed Service:
- Requires only API calls DetectEntities, InferRxNorm, InferICD10CM) to process data. No need to train or deploy models.
3. Compliance:
- HIPAA-eligible and designed for healthcare data, ensuring regulatory compliance out-of-the-box.
#### Key Differentiators:
- Comprehend Medical vs. SageMaker (A/D):
- SageMaker-based solutions (A/D) require building, training, and tuning models (e.g., RNNs, seq2seq), which involves significant coding, data preparation, and infrastructure management.
- Comprehend Medical provides instant, pre-trained medical NLP capabilities.
- Comprehend Medical vs. Kendra (C):
- Kendra is a search tool for querying documents, not summarizing or extracting medical insights.
#### Analysis of Incorrect Options:
- A/D (SageMaker RNN/seq2seq): High development effort for model training, tuning, and deployment.
- C (Kendra): Focuses on document retrieval, not medical insight extraction or summarization.
#### Conclusion:
Amazon Comprehend Medical (B) minimizes effort by leveraging AWS’s pre-trained models to analyze medical text, extract insights, and summarize critical information without custom development.