DAT255: Deep learning - Lecture 15 Attention and Transformers
1/3
Earn XP
Description and Tags
Flashcards covering key concepts related to attention mechanisms and Transformers, based on lecture notes.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
4 Terms
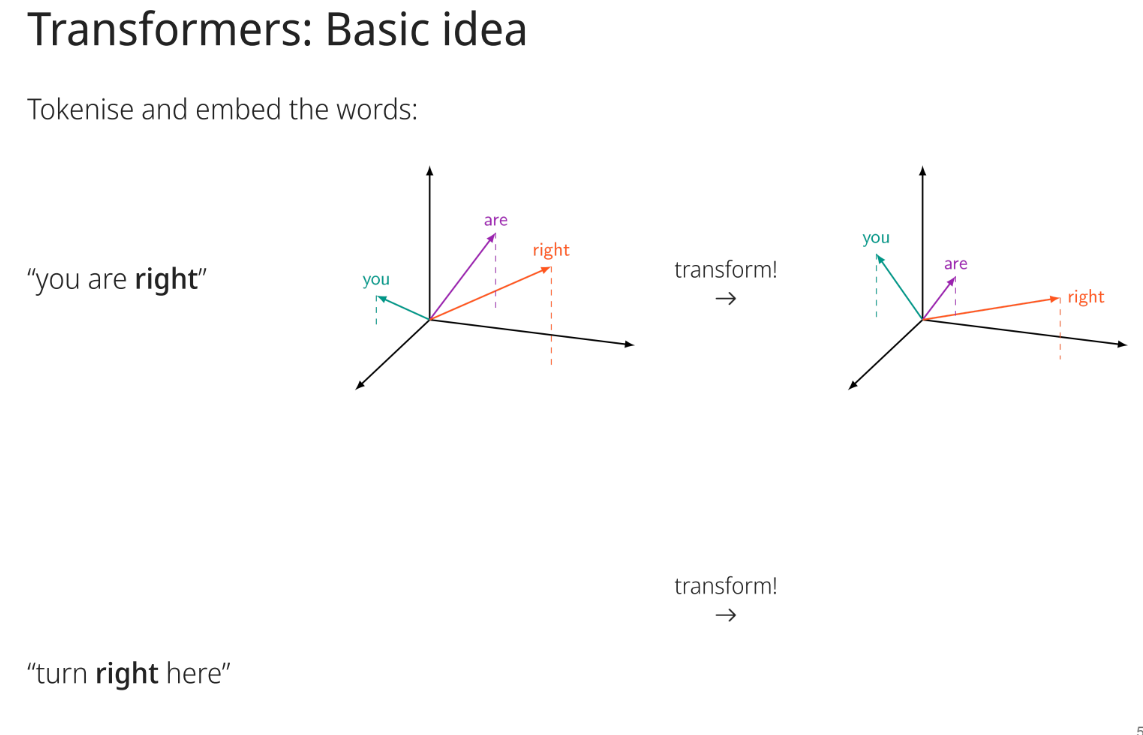
What is the main concept behind Transformers?
To compute relations between vectors and use these relations to transform the vectors into new ones, creating a better suited representation for the task.This is achieved by utilizing self-attention mechanisms, allowing the model to weigh the influence of different input elements.
What is the formula for scaled dot-product self-attention for a single head?
attention(Q, K, V) = softmax [QKT / √D] V
![<p>attention(Q, K, V) = softmax [QKT / √D] V</p>](https://knowt-user-attachments.s3.amazonaws.com/bec733ec-8e70-4170-bf0e-dc53f5df2867.png)
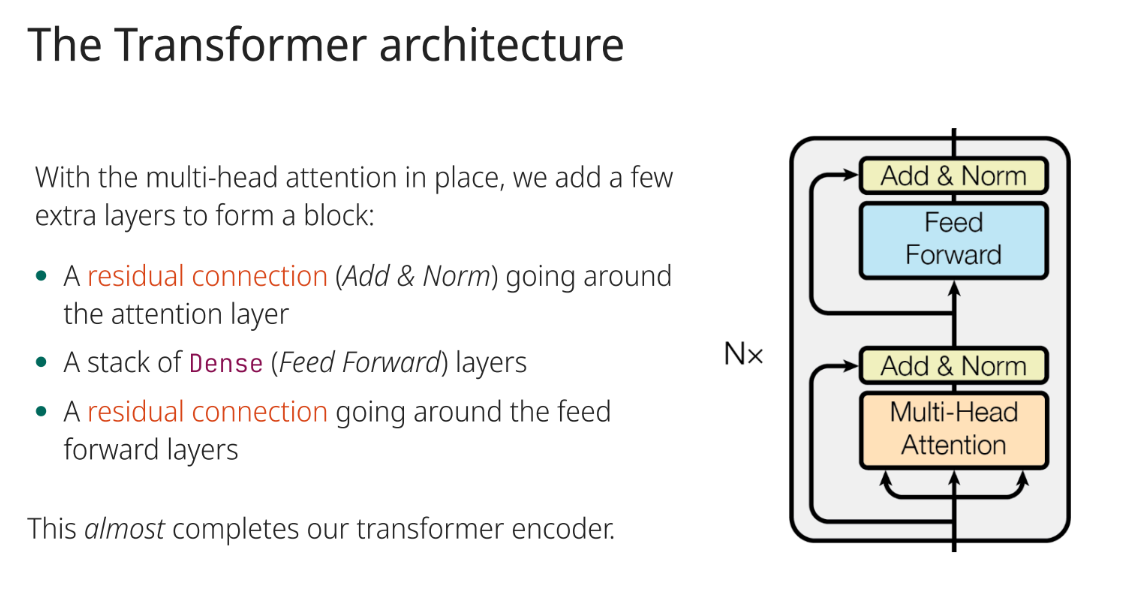
What additional layers are added to the multi-head attention to form a transformer block?
A residual connection (Add & Norm) around the attention layer, a stack of Dense (Feed Forward) layers, and a residual connection around the feed forward layers.
What are the positional encoding Options?
Count token positions, then embed them/Sinusoidal encoding