Parallel Computing (Ch. 12)
1/49
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
50 Terms
no - people can get in the way…ten people on a construction site is better than 100
instead, adding more people who can work on houses simultaneously will work since they’re not all on the same house
Does adding more people to a task always get the job done faster? Why?
the simultaneous use of multiple computing resources to solve a problem
a problem is broken into discrete parts that can be solved concurrently
each part is broken further down into a series of instructions
instructions from each part execute simultaneously on different processors
Define parallel computing.
by solving larger problems that are impossible to solve on a single computer
How does parallel computing save time?
a single computer with multiple processors/cores
an arbitrary number of such computers connected by a network
What 2 things can computer resources be in parallel computing?
Classifies parallel computer architecture along the two independent dimensions of Instruction Stream and Data Stream. Each of these dimensions can have either the Single or Multiple state.
What is Flynn’s Taxonomy for parallel computer architectures?
single instruction: only one instruction stream is being acted on by the CPU during any one clock cycle
multiple instruction: every processor may be executing a different instruction stream
In Flynn’s Taxonomy, what is single instruction? What is multiple instruction?
single data: only one data stream is being used as input during any one clock cycle
multiple data: each processing unit can operate on a different data element
In Flynn’s Taxonomy, what is single data? What is multiple data?
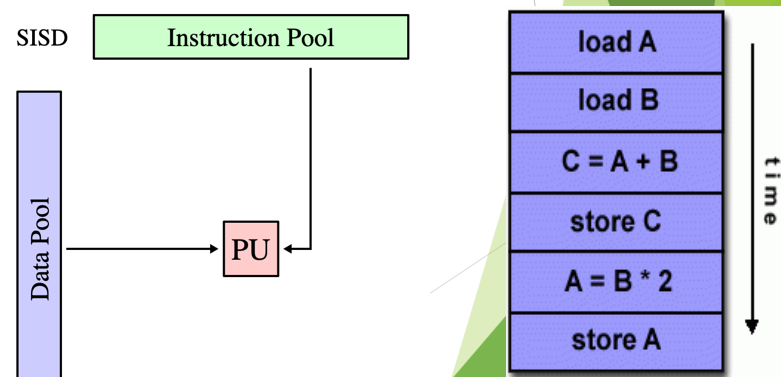
a serial (non-parallel) computer
deterministic execution
What is Single Instruction/Single Data Stream (SISD)?
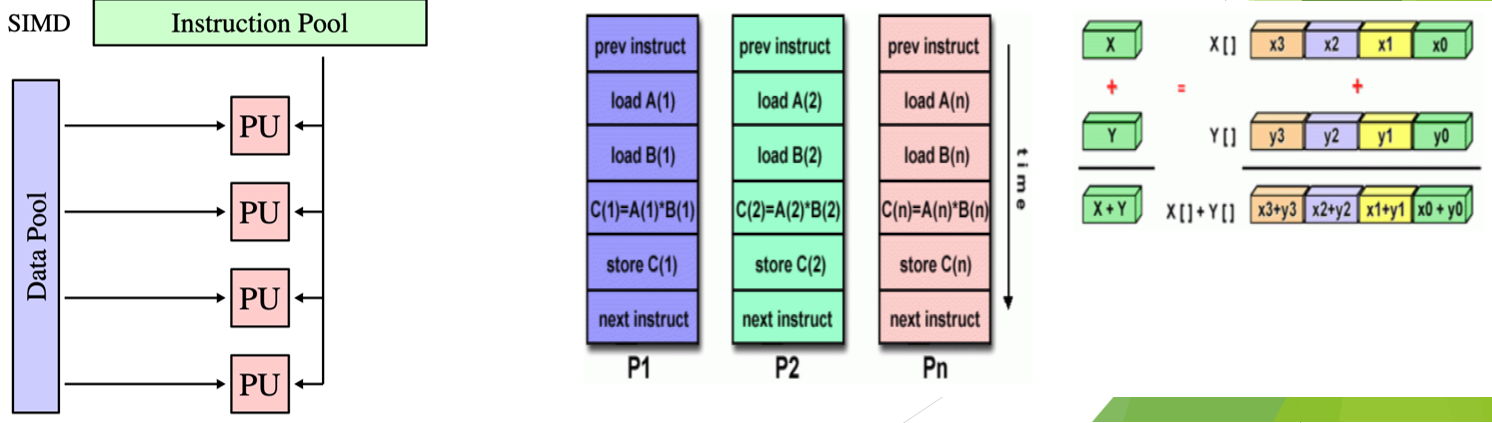
a type of parallel computer
best suited for specialized problems characterized by a high degree of regularity such as adjusting the contrast in a digital image
What is Single Instruction/Multiple Data Streams (SIMD)?
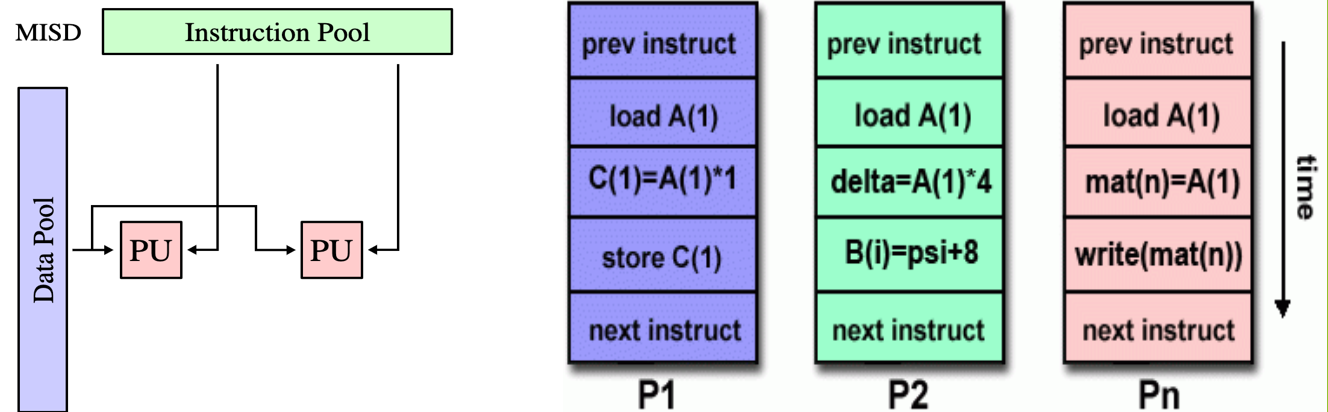
a type of parallel computer
uncommon architecture
possible uses could be implementing multiple cryptography algorithms while attempting to crack a single coded message
What is Multiple Instruction/Single Data Streams (MISD)?
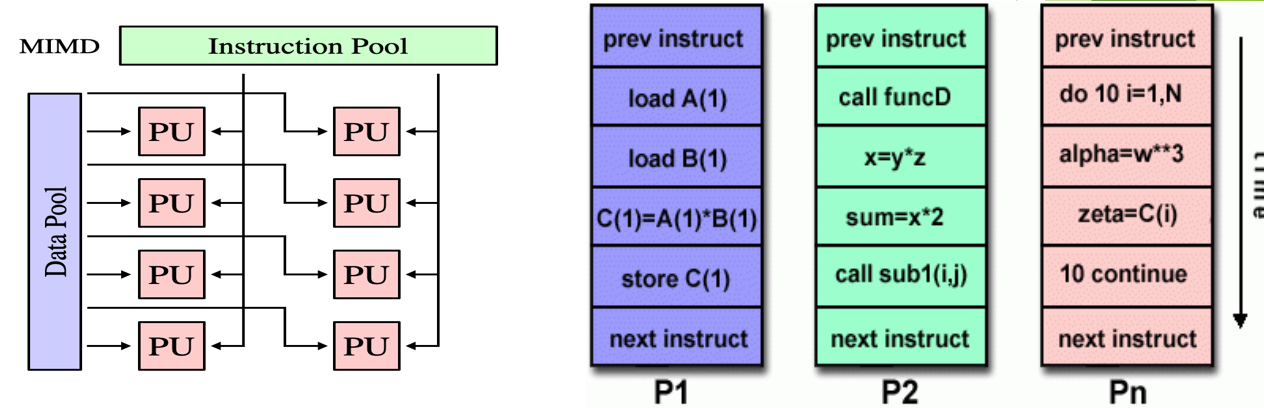
a type of parallel computer (most common)
execution can be synchronous or asynchronous
What is Multiple Instruction/Multiple Data Stream (MIMD)?
single core
multi core
multicore hyper-threading
GPU accelerated
parallel clusters
List the 5 kinds of parallel computing hardware.
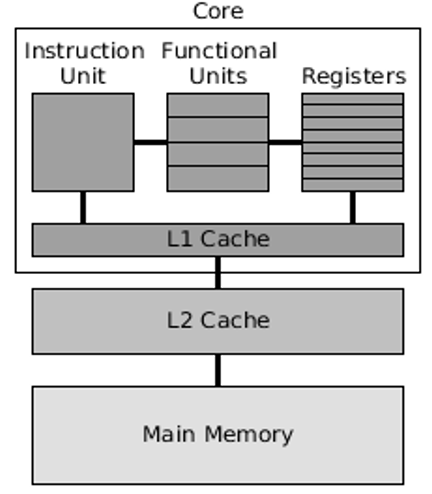
functional unit - dedicated hardware component capable of performing a specific operation, like addition
instructional unit - the part of the processor that decodes and manages the execution of an individual instruction
Describe the two units that both single and multi core hardware have.
single core
Which hardware component of parallel computing is this?
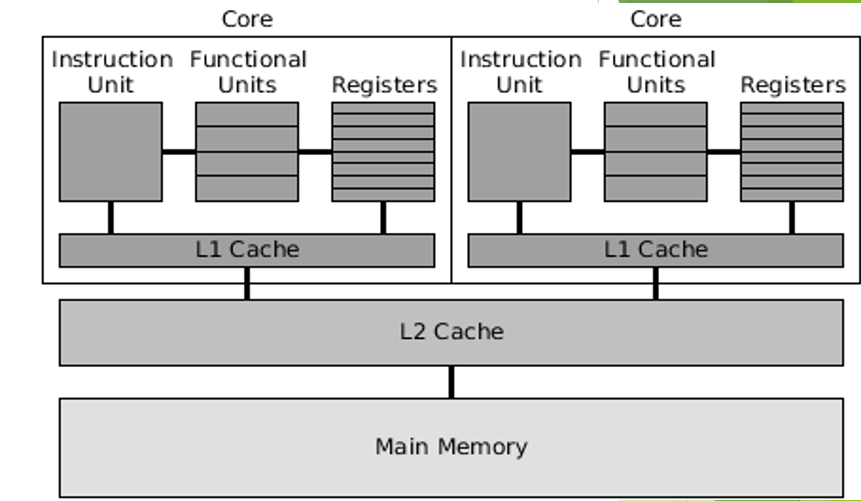
multicore
Which hardware component of parallel computing is this?
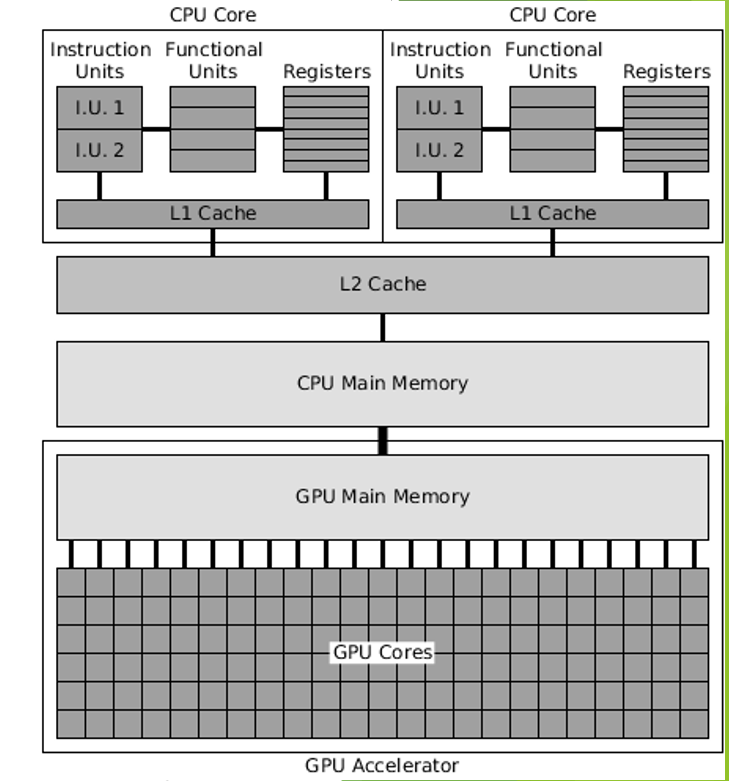
GPU accelerated
Which hardware component of parallel computing is this?
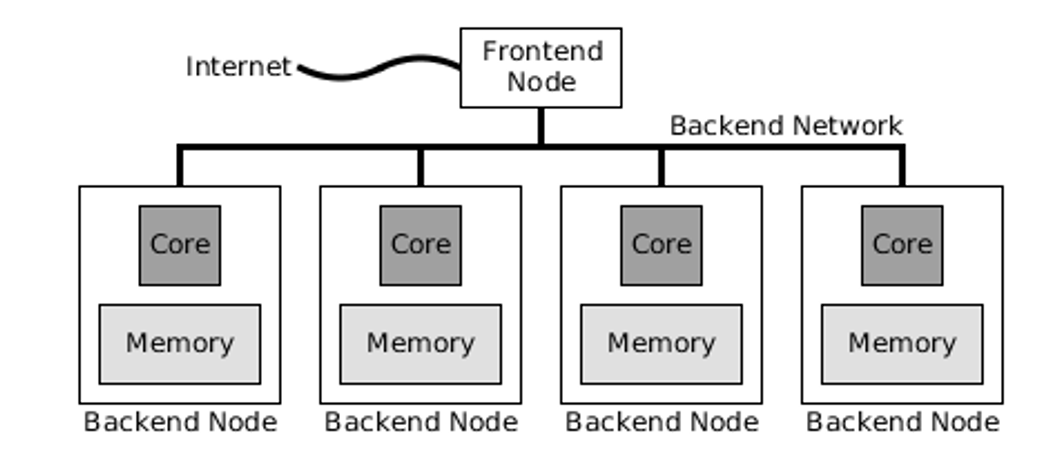
single core node parallel clusters
Which hardware component of parallel computing is this?
GPU accelerated cluster
Which hardware component of parallel computing is this?
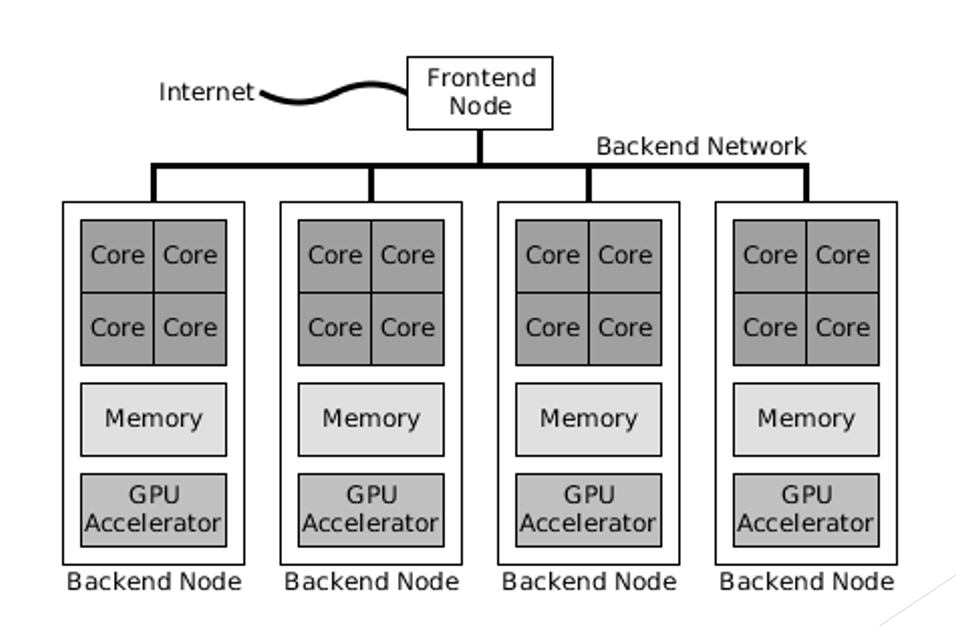
more than one thread can run on each core
one physical core works like two logical cores that can handle different software threads
two logical cores can work through tasks more efficiently than a traditional single-threaded core
Describe multicore hyper-threading.
processors designed to work with a small series of instructions across a potentially vast amount of data
used to facilitate processing-intensive operations
more computing power for performing the same operation on multiple data elements simultaneously
Describe GPU Accelerated hardware.
nodes connected through high-speed local area networks
similar tasks assigned to each node
each node runs its instance of an OS
What are clusters?
to overcome low resource problems and poor performance due to large tasks running simultaneously on one node
to solve problems requiring more cores, GPUs, main memory, or disk storage than can fit on one node
Why use clusters?
single core node (outdated)
multicore node
GPU accelerated
What are the 3 kinds of parallel clusters? Which is outdated?
multicore parallel programs
multicore-cluster (hybrid) programs
GPU-accelerated parallel programs
What are the 3 categories of parallel computing software?
multicore parallel programs
Which parallel computing software type does this convey?
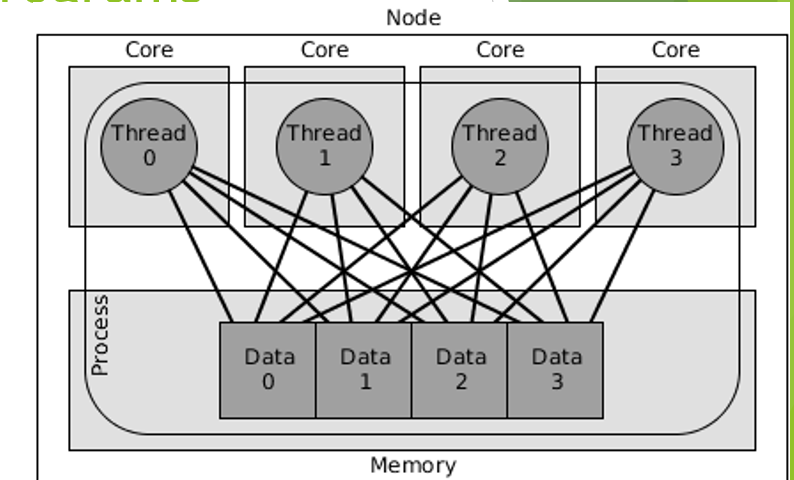
multicore cluster parallel programs
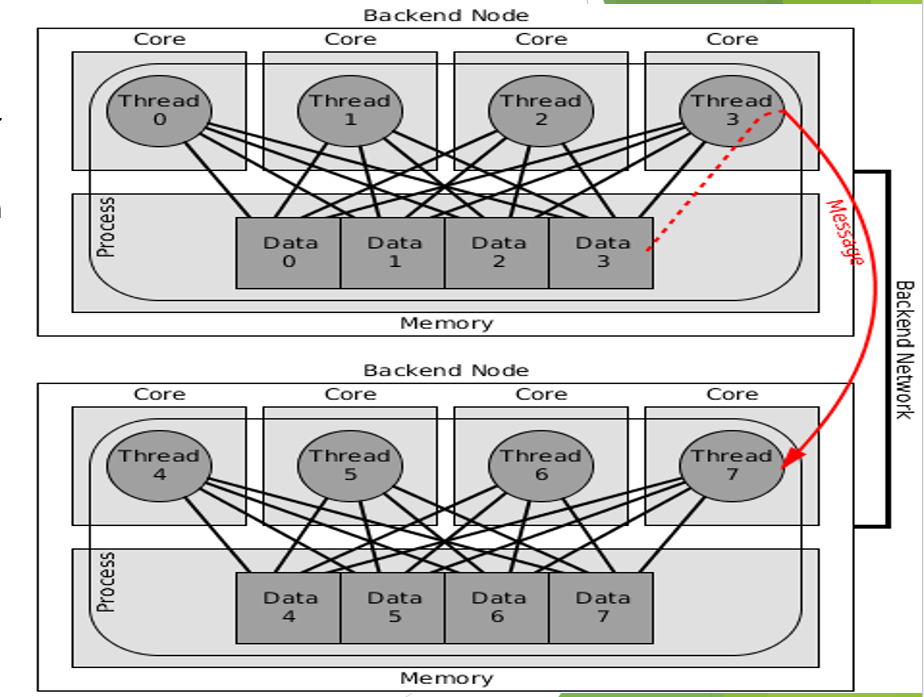
Which parallel computing software type does this convey?
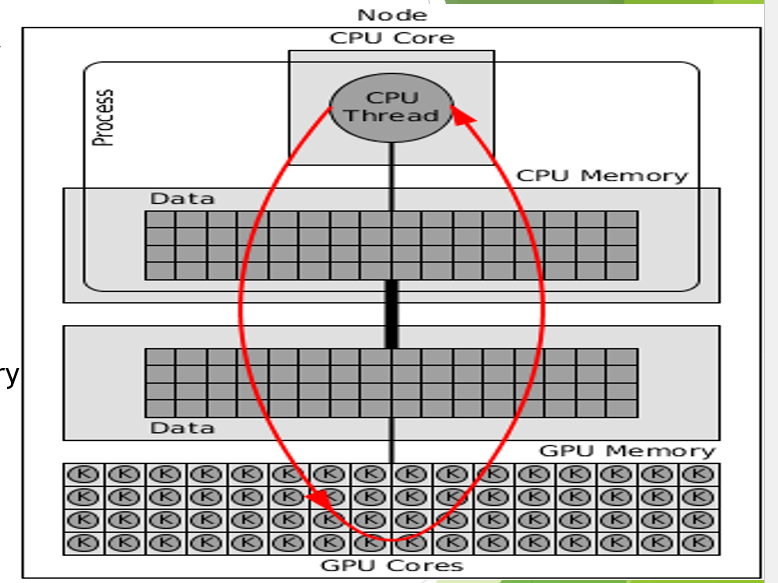
GPU accelerated parallel programs
Which parallel computing software type does this convey?
one
multiple
shared memory
Answer the following about multicore parallel programs:
How many processes?
How many threads?
What is the mode of communication?
one or more
no
no
message passing
Answer the following about cluster parallel programs:
How many threads per process?
Are there thread synchronization issues?
Is there shared data?
What is the mode of communication?
one
multiple; one
yes, parallel programming within a node
message passing between nodes
Answer the following about multicore cluster parallel programs:
How many processes per node?
How many threads per process? Per core?
Is there shared memory?
What is the mode of communication?
CPU puts data in CPU memory, then CPU copies data over to GPU memory, GPU runs a computational kernel, CPU copies output data from GPU memory to CPU memory, CPU reports results
GPU runs a large number of threads, each thread takes input data from the GPU memory, computes the results, and stores the results back in GPU memory
Answer the following about GPU accelerated parallel programs:
How does data move?
What is a computational kernel?
execution time for parallelization
speedup
efficiency
What are the 3 performance metrics for parallel systems?
the part of the computation that must be performed sequentially (“inherently sequential part”)
the part of the computation that can be performed in parallel (“parallelizable part“)
the overhead that the parallel algorithm has, which the sequential algorithm does not
What are the 3 components to the execution time that a parallel algorithm would require if it were implemented?
communication overhead between cores
computations that are performed redundantly
the overhead of creating multiple threads
What does the overhead of the parallel algorithm contain? (3 things)
Sp = time on a sequential processor / time on p parallel processors
What is the equation for speedup?
p
What is our ideal speedup, Sp, equal to?
yes…there is communication overheads between processors; this might be fairly small for shared memory or large for distributed memory
Can Sp be smaller than p? Why or why not?
E(p) = speedup / number of processors = Sp / p * 100%
E(p) is usually written as a percentage
What is the equation for efficiency?
50%: we are only using half of the processor’s capabilities on our computation…half is lost in overheads or idling while waiting for something
100%: we are using all the processors all the time on our computation
What does E(p) = 0.5 (50%) mean?
What does E(p) = 1.0 (100%) mean?
linear speedup - using over 100% of processor (rare)
What does E(p) > 1 indicate?
when we need to gauge the cost of a parallel system
When is efficiency useful?
Let f be the fraction of operations in a computation that must be performed sequentially, where 0 ≤ f ≤ 1. The maximum theoretical speedup ψ achievable by a parallel computer with p processors for this computation is ψ ≤ 1 / (f + (1-f) / p).
(1-f) is the proportion of execution time spent on the part that can be parallelized
State Amdahl’s Law.
1/f where f is the proportion of execution time spent on the sequential part
How can you calculate the upper limit of speedup
the upper limit of speedup determined by the sequential fraction of the code
Define strong scaling.
Amdahl’s law
Which laws emphasizes that improving the percentage of a program that can be parallelized has more impact than increasing the amount of parallelism (cores)
highly parallelized
Parallel computing with many processors is only useful for what kind of programs?
Given a parallel program that solves a problem in a given amount of time using p processors, let s denote the fraction of the program's total execution time spent executing sequential code. The scaled speedup achievable by this program, as a function of the number of processors is
Scaled Speedup Ss(p) = p+(1−p)s
State Gustafson’s Law.
when the number of processors increases, people use the larger number of processors to solve a larger problem in the same amount of time
State Gustafson’s Law in layman’s term.
no - increases linearly with respect to the number of processors
With Gustafson’s Law, is there an upper limit for the scaled speedup? How does the scaled speedup increase?
when the scaled speedup is calculated based on the amount of work done for a scaled problem size
What is weak scaling.