Quizz by the prof
1/42
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
43 Terms
Statement: We should standardize our target if it has a different scale than the inputs.
False :
In linear/logistic regression, you do not need to scale the target variable y
Statement: 1-NN (1-Nearest Neighbor) is sensitive to the scale of the variables.
True
K-NN algorithms rely on distance metrics. if one variable has a way bigger range, the larger variable will doinate the distance calculation, making the smaller variable effectively invisible to the model
Statement: We should normalize the test set based on the relevant statistics as measured on the test set.
False
This is a classic case of Data leakage. You must normalize th etest set using the statistics from the training set.
In a real-world scenario, you won’t have the future data to calculate a mean, so your model must process new data using the parameters it learned during training
what can you do about features being on different scales ?- One-hot encoding, standardize, variable selection, discretize
standardize
suppose you are using ridge regressionand you notice that the training error and the validation error are almost equal and fairly high, what is your diagnosis
the model is underfitting
It is too simple and has high bias, failing to capture the underlying patterns in the data
what is the model behavior when lambda is too high in Ridge Regression
The model wil underfit
Excessive regularization penalizes coefficients too heavely, pushing the model towards high bias
what is the relationship between training, validation, and test error
The test error is almost never lower than the training error
if training and validation error are high, test error will typically be high as well
what caracterizes overfitting in Ridge Regression
very low training error, but significantly higher validation error (high variance)
solution for a model with high bias (underfitting)
decrease the regilarization parameter
add more features or interaction terms
use a mode complex model architecture
is a node's Gini impourity generally lower of greater, or always lower/greater than it's parents ?
The weighted average Gini impurity of the children is always lower than or equal to the parent’s impurity
→ an individual child node : generally lower, but it could technically have a higher Gini impurity than its parents as long as teh overall split improves purity
effect of decreasing tree depth on variance
decreasing depth reduces variance (overfitting) by preventing the tree from creating rules that are too specific to the training data
hyperparameters to control Tree Overfitting
max depth
min sample split
min sample leaf
max leaf nodes
scale dependence in decision trees ?
decision trees are not affected by the scale of features because they use threshold based splits rather than distance calculations
what is validation set used for
for hyperparameter tuning and model selection
what is the test set used for
for final evaluation of generalization performance
I take the decision which model to puch throigh production based on the validation performance as it is a modelling decsion
True
True or False : logistic regression is a classification model that learns a linear mapping (function) from input to a probabolity (output)
True. Logistic regression is a classification model that maps input features to a probability by first learning a linear relationship and then passing it through a non-linear transformation.
While it might seem contradictory to call it "linear" when the output is a curved S-shape (the sigmoid), the term refers to the math happening under the hood.
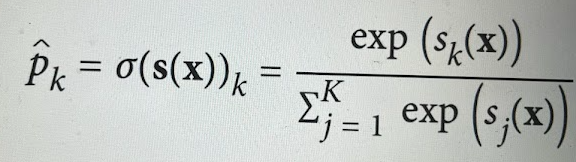
- can you select the right answers : (picture)
p^ is a vector with k elements and its value lies between 0 and 1,
sk(x) is a vector and its values lies between 0 and 1.
sk(x) is a scalar and its values lies between 0 and 1.
the softmax function is used with multinomial logistic regression
p^ is a vector with k elements and its value lies between 0 and 1,
the softmax function is used with multinomial logistic regression
T/F It is possible to model interaction effects with logistic regression.
correct. Interaction terms can be explicitly added to a logistic regression model by including the product of two or more independent variables as a new feature. This allows the model to capture how the effect of one predictor depends on the value of another.
T/F If classes are linearly separable, logistic regression is a good choice of algorithm to try.
correct. Logistic regression is a linear classifier, meaning it creates a linear decision boundary. While it works well for linearly separable data, it is worth noting that if classes are perfectly separable, the coefficients can technically grow to infinity during training (a phenomenon called "perfect separation"), which is usually handled via regularization.
T/F The choice of similarity measure for KNN depends on personal preference.
This is incorrect.
The choice of a distance or similarity measure (such as Euclidean, Manhattan, or Minkowski distance) should be a data-driven decision, not a personal preference. The choice depends on:
The nature of the features: For example, Manhattan distance is often better for high-dimensional data or when features are discrete.
The scale of variables: $k$-NN is highly sensitive to the scale of variables, so distance measures behave differently depending on how the data is normalized.
Model Performance: Usually, the best metric is chosen via cross-validation on the validation set to see which one yields the highest accuracy for that specific dataset.
T/F The ROC is a better evaluation metric than the profit curve because it is more stable.
FALSE
"Better" depends entirely on the goal. While the ROC curve is more stable because it is independent of class proportions and costs, the Profit Curve is often superior for business decisions because it incorporates the actual financial costs and benefits of different types of errors (False Positives vs. False Negatives).
T/F AUROC (Area Under the ROC Curve) is a ranking metric.
TRUE
Explanation: AUROC measures how well the model ranks individuals. Specifically, it represents the probability that a randomly chosen positive instance will be ranked higher by the model than a randomly chosen negative instance. It does not care about absolute probability values, only the relative order.
Evaluation with accuracy attributes equal costs to the different types of errors a model makes.
TRUE
Explanation: Accuracy simply calculates $\frac{\text{Correct Predictions}}{\text{Total Predictions}}$. By doing so, it treats a False Positive (Type I error) and a False Negative (Type II error) as having the exact same impact on the score. This is why accuracy is a poor metric for imbalanced datasets or high-stakes scenarios (like medical diagnoses).
Statement: We can measure the Bayes Error of a linear regression for a vision task on the test set.
FALSE
Explanation: The Bayes Error is the theoretical minimum error rate possible for a given problem (the "noise" in the system that no model can overcome). Since we do not know the true underlying probability distribution of the data, we cannot "measure" it directly. We can only estimate it (for example, by using human performance as a proxy in vision tasks).
Statement: Boosting makes a weak classifier stronger (reduces bias).
Answer: TRUE
Explanation: Boosting is an ensemble technique that trains models sequentially. Each new model focuses on the errors (residuals) of the previous ones. This process incrementally reduces the bias of the overall ensemble, turning "weak learners" into a single "strong learner."
Statement: Non-pruned decision trees are typically high bias models.
FALSE
Explanation: Non-pruned decision trees are actually high variance (low bias) models. Because they are allowed to grow until they perfectly split the training data, they capture every tiny detail and noise in the set. Pruning is the technique used to increase bias slightly in order to decrease the high variance
Statement: Soft majority voting averages the (weighted) outputs of the base learners and assigns the label with the highest average score.
TRUE
Explanation: In Soft Voting, the ensemble predicts the class label based on the predicted probabilities (the "confidence") of each base learner. It calculates the average of these probabilities and picks the class with the highest result. This is generally more powerful than Hard Voting, which only looks at the final class labels (0 or 1).
Statement: Stacking with the same base algorithm will most likely perform worse than with different algorithms.
Answer: TRUE
Explanation: The power of Stacking comes from diversity. If all base models are the same algorithm (e.g., all Decision Trees), they will likely make the same types of errors. Stacking different algorithms (e.g., a KNN, a Logistic Regression, and an SVM) allows the meta-learner to learn which model is most reliable for different types of data points.
Statement: Homogeneous ensemble methods use the same base algorithm.
TRUE
Explanation: Homogeneous ensembles use multiple instances of the same type of model. The most famous example is a Random Forest, which consists purely of Decision Trees. In contrast, Heterogeneous ensembles (like many Stacking implementations) combine different types of algorithms
Statement: Random forests will always achieve better performance than bagging.
Answer: FALSE
Explanation: While Random Forests are generally more powerful because they reduce tree correlation (by subsampling features), they are not "always" better. On datasets with very few features or where every feature is critically important, standard bagging might perform just as well or occasionally better.
Statement: Random forest can be efficiently trained making use of parallel processing capabilities.
TRUE
Explanation: Because each tree in a Random Forest is built independently using its own bootstrap sample, they can be trained simultaneously across multiple CPU cores. This makes Random Forests highly scalable for large datasets compared to sequential models like Boosting.
Statement: Boosting typically uses decision tree stumps (a tree with only one split) because they are low variance, high bias.
Answer: TRUE
Explanation: Boosting aims to reduce bias. It starts with "weak learners"—models that are only slightly better than random guessing. A decision stump (a tree with only one split) is the classic weak learner: it has high bias (it's too simple) but low variance (it doesn't change much with different data). Boosting then sequentially combines these to build a complex, low-bias "strong learner."
Statement: Adding neurons (linearly activated or otherwise) to the hidden layer of the neural network always increases complexity.
Answer: FALSE
Explanation: While adding non-linearly activated neurons (like ReLU or Sigmoid) increases the model's capacity to learn complex patterns, adding linearly activated neurons does not. Multiple layers of linear neurons mathematically collapse into a single linear transformation (a single layer). Therefore, it doesn't add any "representational" complexity—it just adds redundant parameters.
Statement: Gradient descent in the context of a neural network will approximate any function with its global optimum on the training set (Universal Approximation Theorem).
Answer: FALSE
Explanation: This is a tricky one. The Universal Approximation Theorem states that a network with at least one hidden layer exists that can approximate any continuous function. However, it does not guarantee that Gradient Descent will find the global optimum. In practice, gradient descent can get stuck in local minima or saddle points, especially in non-convex neural network loss landscapes.
Statement: Deep learning always uses neural networks.
Answer: TRUE
Explanation: Deep learning is specifically defined as a subfield of machine learning that utilizes Artificial Neural Networks with multiple layers (hence the word "deep"). While other models like Random Forests can have many levels, they are not classified as "Deep Learning.
Statement: The perceptron is able to solve XOR.
Answer: FALSE
Explanation: A standard (single-layer) perceptron is a linear classifier. Because the XOR problem is not linearly separable (you cannot separate the 0s and 1s with a single straight line), a single-layer perceptron cannot solve it. You need a Multi-Layer Perceptron (MLP) with at least one hidden layer to handle XOR.
Statement: The output neuron of a neural network can include a non-linear activation function.
Answer: TRUE
Explanation: In fact, the choice of activation in the output layer is critical and depends on the task. For binary classification, we use the Sigmoid function; for multi-class classification, we use Softmax; and for regression, we often use a Linear (identity) activation.
Statement: Neural networks offer poor interpretability.
Answer: TRUE
Explanation: Neural networks are often described as "black boxes." Because they consist of thousands or millions of weights and complex non-linear transformations, it is very difficult for a human to understand exactly why a model made a specific prediction compared to simpler models like Decision Trees or Linear Regression.
Statement: We should choose the learning rate on the training set, as this is the set we use gradient descent on.
FALSE
Explanation: This is a major "trap" question! While Gradient Descent operates on the training set, the Learning Rate is a hyperparameter. Like all hyperparameters, it must be chosen based on performance on the Validation Set. If you choose a learning rate that minimizes training error perfectly, you might end up with a rate that leads to massive overfitting or unstable convergence that doesn't generalize.
Statement: Ranking based on uplift is superior to ranking based on response.
Answer: TRUE
Explanation: Ranking by "Response" only identifies who is likely to buy. This often targets "Sure Things" (people who would have bought anyway). Uplift Modeling identifies the "Persuadables"—those whose behavior will actually change because of the treatment. Targeting based on uplift maximizes the return on investment (ROI) by avoiding wasteful spending on people who don't need the incentive.
Statement: Taking current spending into account in an expected-value based approach does not always lead to better business results (compared to ignoring customer value).
Answer: TRUE
Explanation: If you only target high-value customers (those who spend the most), you might ignore high-potential customers who are currently spending little but are highly "persuadable." Furthermore, if high-value customers are "Sure Things," targeting them adds zero incremental value, making the business result worse than a strategy that ignores current value to focus on growth potential.
Statement: Letting data scientists operate independently in organizational silos is a good practice as it enables specialization.
Answer: FALSE
Explanation: This is a major trap in corporate strategy. Siloed data scientists often build models that are technically brilliant but solve the wrong business problem because they lack context. Successful AI implementation requires cross-functional collaboration between data scientists, domain experts, and business stakeholders to ensure the models align with actual business goals and constraints.