Data Science
1/48
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
49 Terms
Nominal
data is a categorical type of data that represents labels or names without a specific order or ranking.
Ordinal
data is a categorical type of data that has a defined order or ranking, allowing for comparison of relative positions.
Categorical
data represents distinct categories or groups.
Numerical
data is a type of data that represents quantifiable values, allowing for mathematical calculations and comparisons.
Discrete
Difference between units on scale is constant but can only take certain values
Interval
Difference between units on scale is constant, but no zero point - measures exact difference.
Scatterplot/ line plot/ scatterplot matrix
Compare two variables (numerical/numerical)
Joint plot
Compare two variables (numerical / numerical data)
Bivariate Kernel Density Plot
Numerical/ numerical data
Boxplot / violin plot
categorical / numerical data
Heatmap
Categorical / categorical data
Probability Distribution
between 0 and 1
Bernoulli Random Variable
Two possible outcomes
Binomial Random Variable
How many successes after n times
Central limit theorem
Distribution of the sample mean will approximately normal if large sample.
-normalize data by data version of mean
Bootstrap
Sampling with replacements
-provide consistence
-helps quantify errors when making inferences
Confidence Intervals
Measure variation in a statistic
Null Hypothesis
No effect or nothing of interest
Alternative Hypothesis
There is an effect
Test Statistic
Denote difference between null and alternative hypothesis
Rejection Criterion
Rejects Null Hypothesis
Type I Error
Rejects Null Hypothesis when it is true, false positive
Type II Error
Hypothesis Testing
Model that helps decide between different hypotheses using falsification
P-Value
probability of getting a more extreme value than the observed test statistic given Null hypothesis is true.
-Lower p value = lower the risk of type I error
Rejects null hypothesis
p-value < 0.05
-Null Hypothesis unlikely to be making a type I error
Binomial Distribution
Probability distribution that describes the number of successes in a fixed number of independent trials of binary experiment.
probability of K successes n trials and p probability of successes
t-test
Numerical vs Categorical/ Two Categories
Compares variables with two values vs numerical. It answers the question of means of two groups are different.
Kruskal-Wallis Test
Same as t-test but with many categories.
Hypothesis test that compares multiple values vs numerical variables but does not specify which category is different.
-ranks the sum of two and check if ranks differ
Pearson’s Correction
Numerical vs Numerical
Measures strength/direction of the linear relationship and answers the question of two variables move together.
Between -1 and 1, if 0 = non-linear relationship
Spearman’s Correlation
Used if there is non-linear relationship
correlation does not equal to causation
X^s Test of Independence
compares two categories and measure whether there is dependence.
H0: independent, no association
Ha: dependent, is an association
Family Error
Probability of making at least one type I error.
What does probability answers
Count all the test in the same statistical family together
Bonferroni Correction
k test simultaneously
rejects p-value <= alpha/2
Adjust for multiple comparisons to control the family-wise error rate
Multiple Hypothesis Test
The more hypothesis testing the more type I error accrue
Using Bonferroni Correction will help reduce this risk by adjusting the threshold.
Alpha_new
adjust significance level for each individual test
Data Set Cards
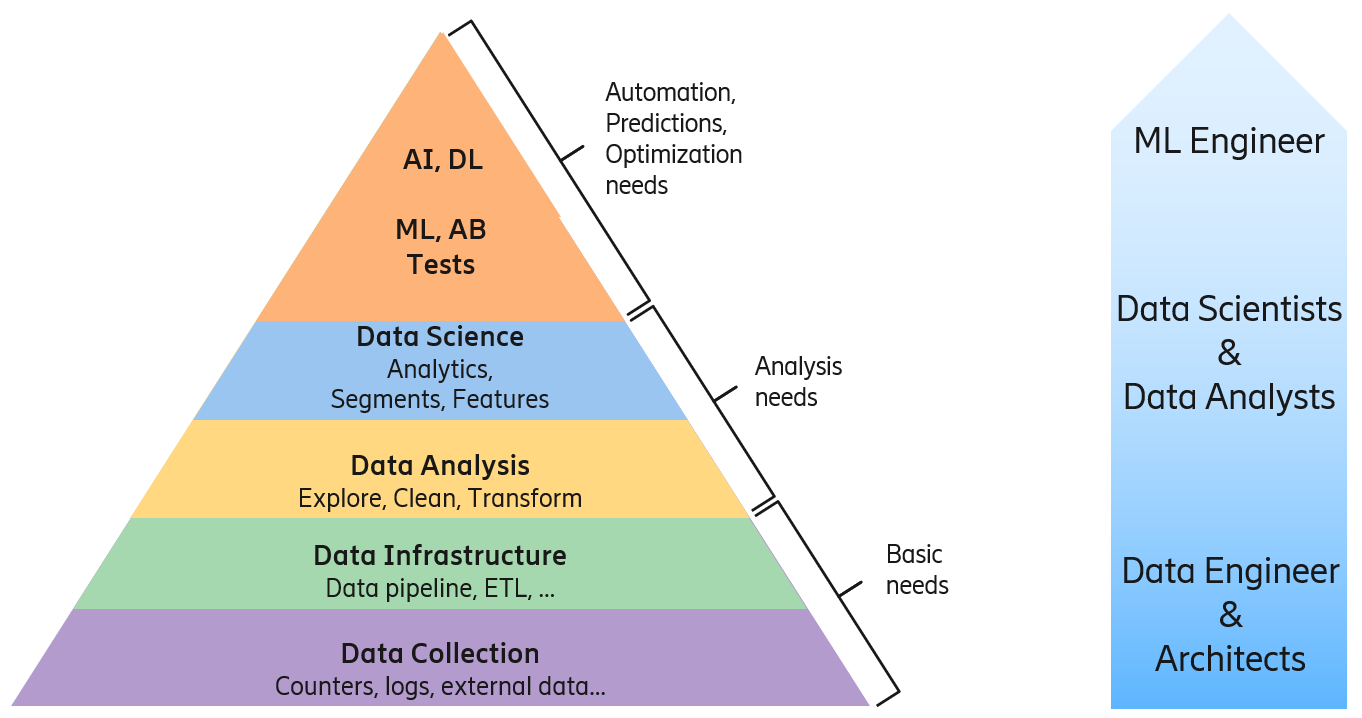
Clustering
Unsupervised technique used to group similar datas
K-Means
Distance-based clustering algorithm
Uses distance to measure intra - cluster “coherence“
Finds local optimum
clustering metric-sum of squares
Pros:
Simplicity
Scalability
Convergence
Cons:
Sensitive to outliers
Cluster shape
Choosing K values
Convex
data from A to B without going out of the circle
Elbow
Find the optimal K value for K-means
Can be very hard to find the “elbow“ when line is linear
Silhouette Scores
Metric for evaluating any clustering (not only to choose the best k for k-means). Returns the average of silhouette coefficients over all samples
-1: cluster is incorrect
0: overlapping
1: strong structure
Hierarchical Clustering
Bottom up method
does not require number of cluster k to run
Can interpret dendrogram (“tree-based“)
Expensive in terms of comute and memory
Curse of Dimensionality
High dimensional data tends to be sparse and hard to analyze, more features cause complication to model.
Principal Components Analysis (PCA)
reduce dimensionality while preserving as much information as possible.
Goal: find the subspace and project the data.
Benefits: Simplifies data without losing information and helps with visualization.
The Process of PCA
1)Feature Matrix
2) Standardize data(sensitve to scale)
3) Compute the Covariance Matrix E
4) Find the Eigenvalues and Eigenvector
5) project the data
Eigenvalues
How much variance (information) in each direction
Eigenvector
new axes or direction