Lecture 5 - "Standard Error on the mean"
1/10
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
11 Terms
Goal of “Best Estimate of Parent Mean”
to find the best estimate of the mean of a parent distribution
Probability for each xi(data point) is proportional
to the exponential expression involving μ and the standard deviation σ
Maximum likelihood method
Means we calculate the value of μ that maximizes the probability of observing the given data
maximize the overall probability of observing all the data points (multiplying individual probabilites)
need to solve for μ
leads to conclusion that the best etimate for the mean is the sample mean (μ’), which is simply the average of all the data points
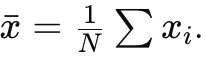
Using maximum likelihood approach shows the sample mean is the best estimate for:
the true mean of the parent distribution
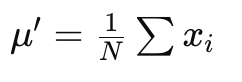
Sample Mean
best estimate of the true mean of a parent distribution is the sample mean
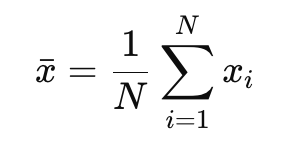
Error in the mean (error in estimating the mean DN)
difference between the the sample mean xˉ and the true mean μ
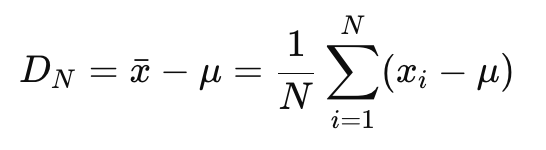
Deriving the Standard Error (compute variance of the error in the mean DN)
take square of the error and sum it over all measurements… shows that error decreases as the number of measurements N increases
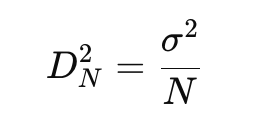
Standard Error on the mean
standard deviation of the distribution of means
tells you how precise your sample mean is, based on number of measurements
more measurements take, the smaller the error
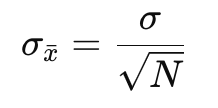
What two factors do the precision of experimental results depend on?
the precision of individual measurements (std, )
and number of measurements N
Standard Error quantifies:
how much the sample mean is likely to vary from the true population mean
Larger sample sizes reduce:
the standard error, improving the precision of sample mean as an estimate of the true mean