Paper 4 - Unit 19 - Computational thinking and problem solving
1/47
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
48 Terms
Bubble sort algorithm (for loop)

Bubble sort nested FOR loop disadvantage
• Iterations continue...
...after the array is sorted
Bubble sort improvement
Use of a flag to indicate if any swaps have taken place
If the inner loop has made all comparisons with no changes...
...flag/value set accordingly
A comparison checks the flag/value at the end of each inner loop...
...if it is sorted it breaks out/stops
Bubble sort algorithm (repeat until)

Insertion sort
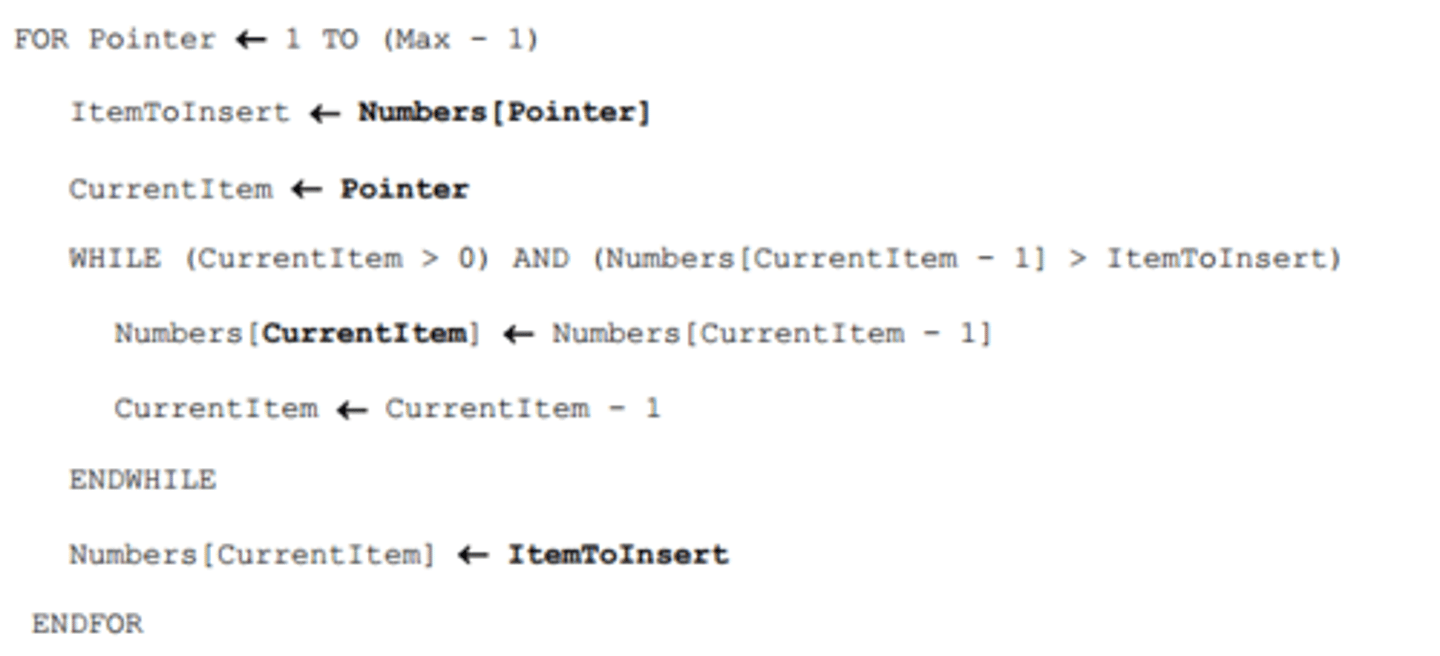
Insertion sort efficiency factors
The size of the array - Better with larger arrays
How ordered the items already are - because it will stop as soon as it is sorted
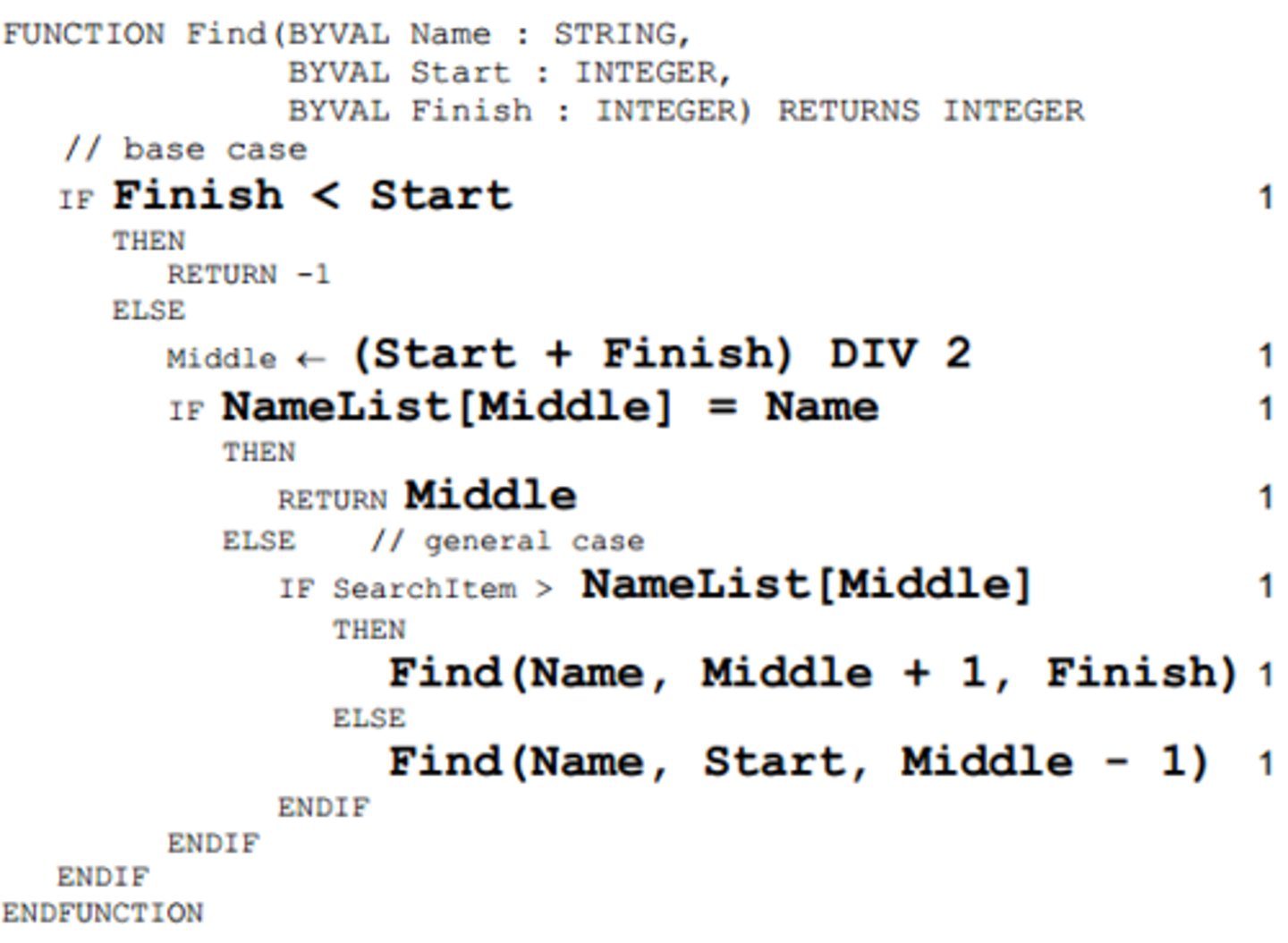
Binary search algorithm (recursive)
Linked list node declaration (record)

Linked list declaration as array

Example linked list declaration in python

Linked list benefit over an array for implementing a stack
A linked list is a dynamic data structure / not restricted in size
Has greater freedom to expand or contract by adding or removing nodes as necessary
Allows more efficient editing using pointers (instead of moving the data)
An array is a static data structure...
...generally fixed in size
When the array is full, the stack cannot be extended any further.
Null pointer
A pointer that doesn't point to any data/node/address
Remember to ensure that when setting NULL pointer that it is not an array index i.e. don't use 0 if 0 is an index use -1
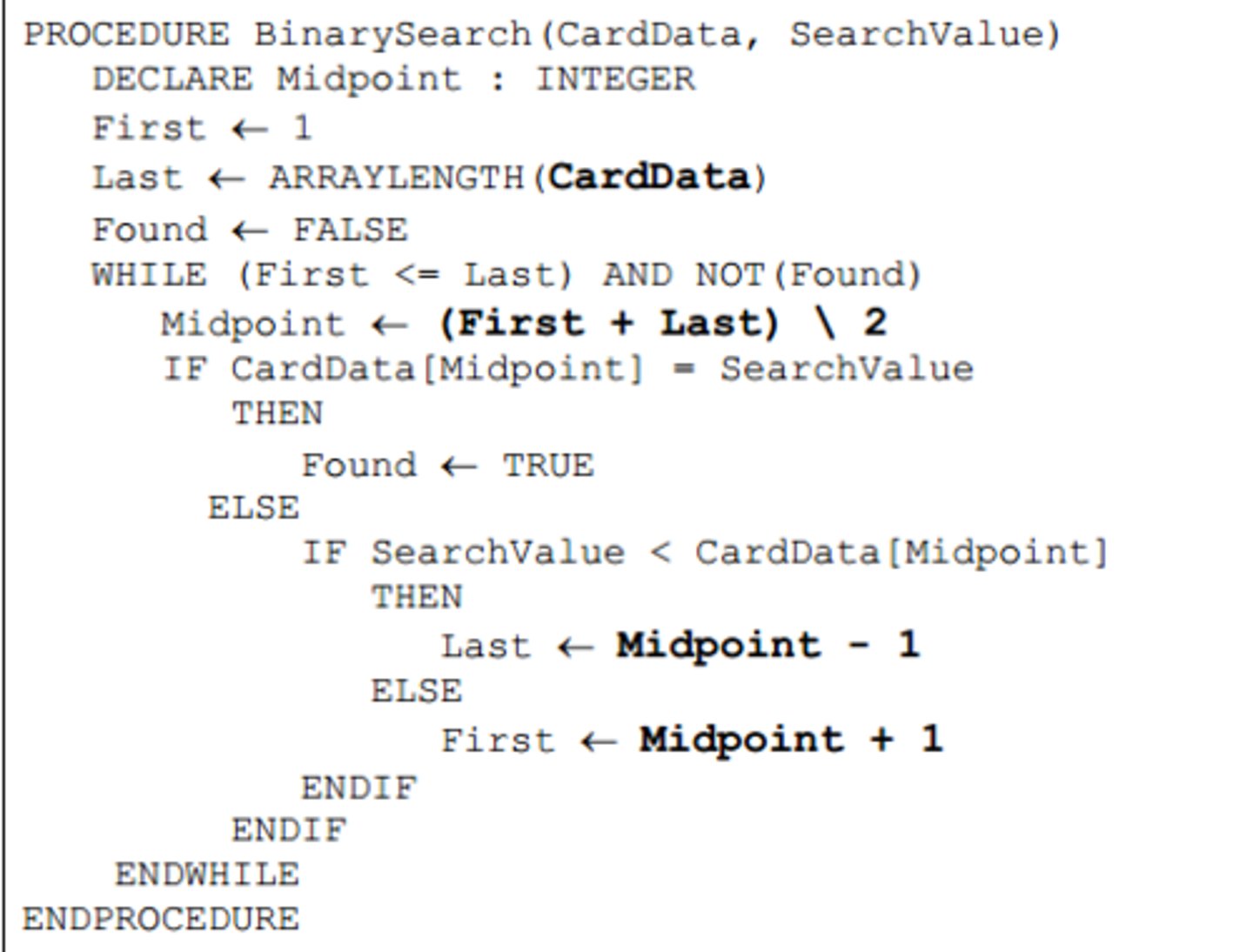
Binary search algorithm (Iterative)
Array declaration of records

Why an array needs to be sorted before a binary search algorithm can be used
It doesn't check every value
The midpoint is the middle element, not the middle numerical value
When the higher/lower elements are discarded they will not be the higher/lower elements
It might discard the value you are looking for
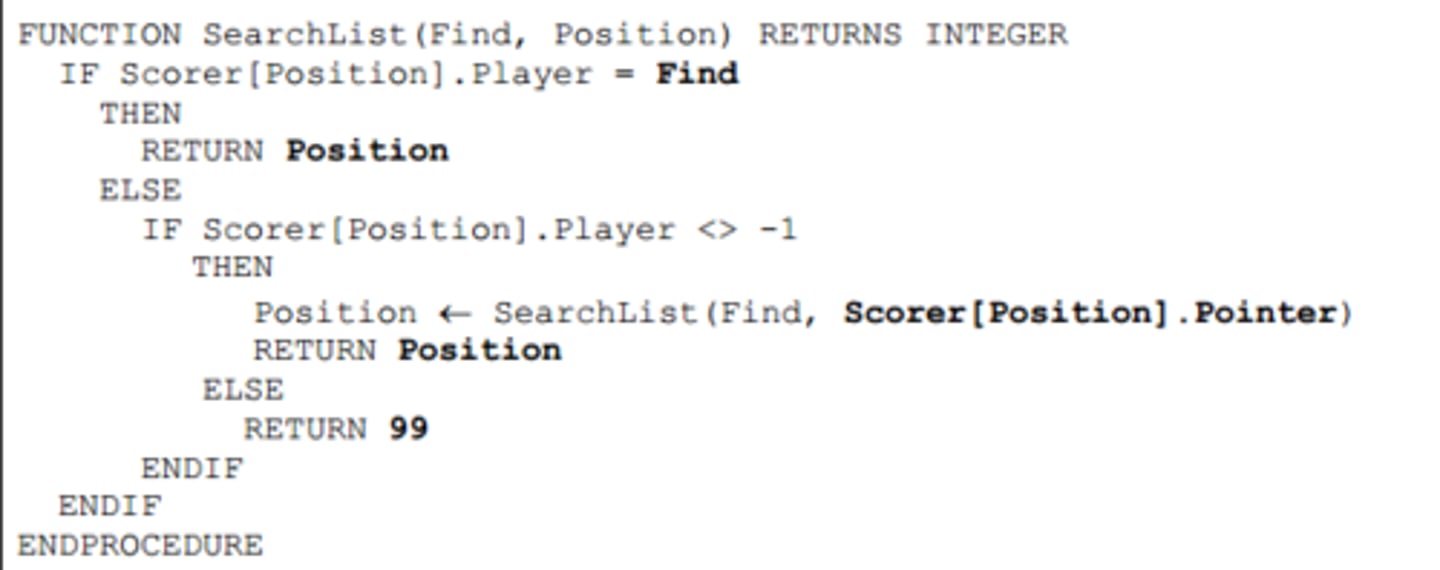
Linked list search (recursive)
Binary search explanation
Find mid-point and compare to searched value
Discard greater/lower half
Find and compare to mid-point of new list
Continue until value found
Linked list delete (recursive)

Linked list find
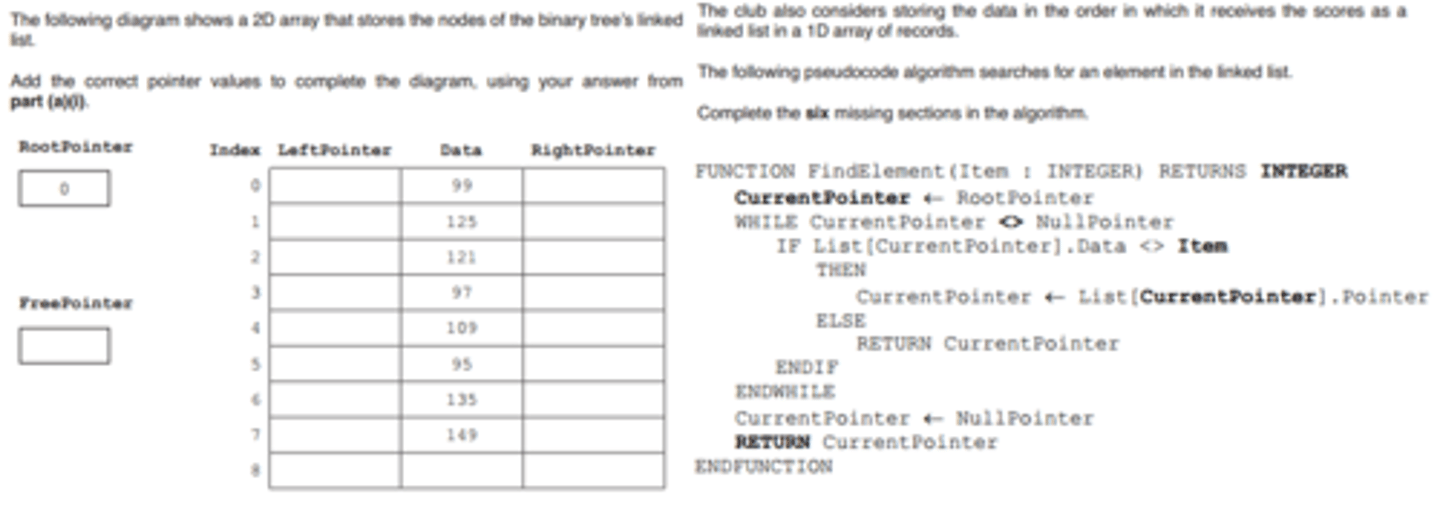
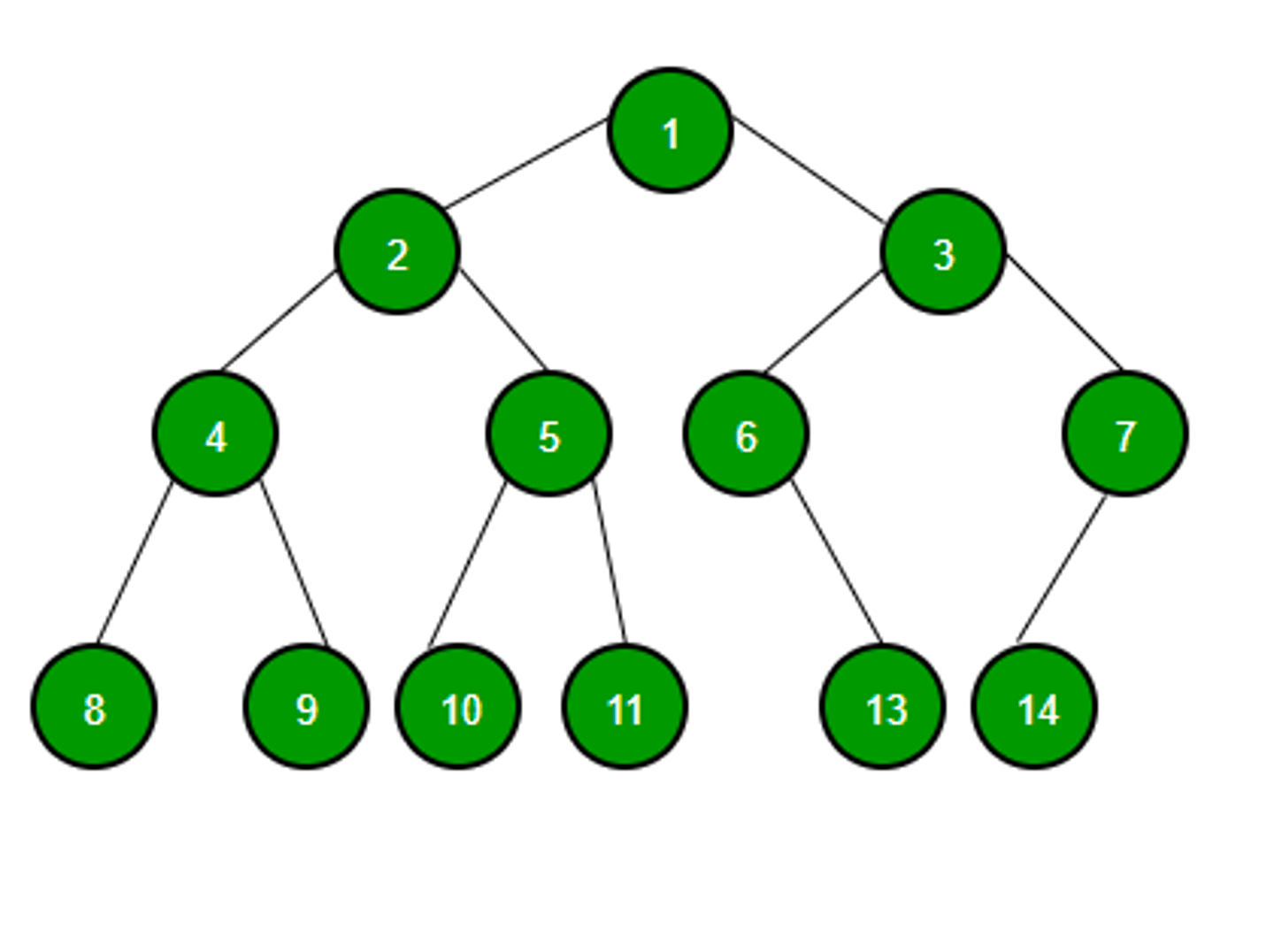
Binary Tree Example
Tree incomplete in picture - complete using linked list
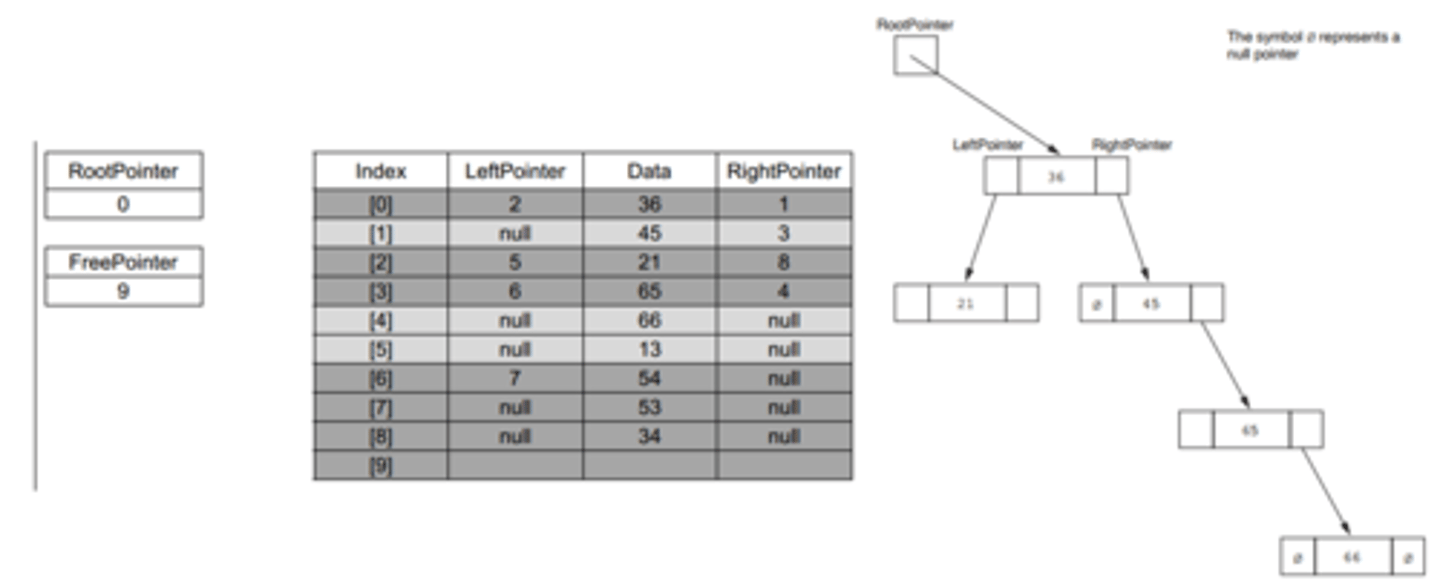
Hash table benefit
Hash is better for a large number of objects/records
A hashing algorithm/hash performed on key field/record (to form the address)...
...to allow direct access to the object...
...so it is likely to be faster in finding the object
Comparison - In a linked list, each object needs to be checked until found // sequentially/linear accessed...
...the left/right/next pointer is followed // have to trace pointers
Hash table - insert record

Hash table - search
Queue
(Linear) data structure
First in First out // FIFO // An item is added to the end of the queue and an item is removed from the front
All items are kept in the order they are entered
It has a head pointer and a tail pointer
Can be static or dynamic
Can be circular...
...when the (tail) pointer reaches the last position it returns to the first
Circular queue
Data structure in which the operations are performed based on FIFO (First In First Out) principle and the last position is connected back to the first position to make a circle.
Circular queue - Remove (array)
Note when start pointer is 5, it returns back to 0
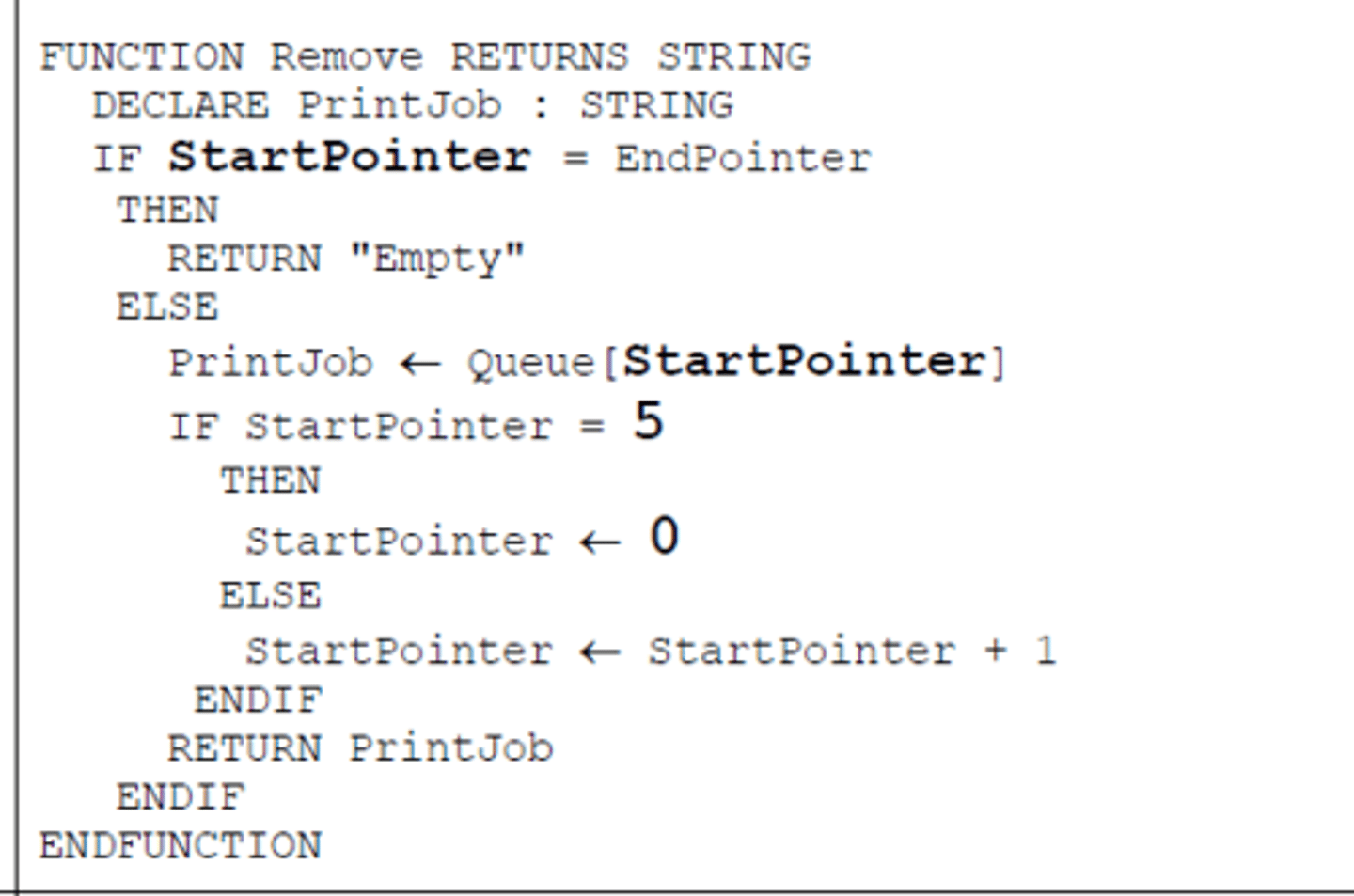
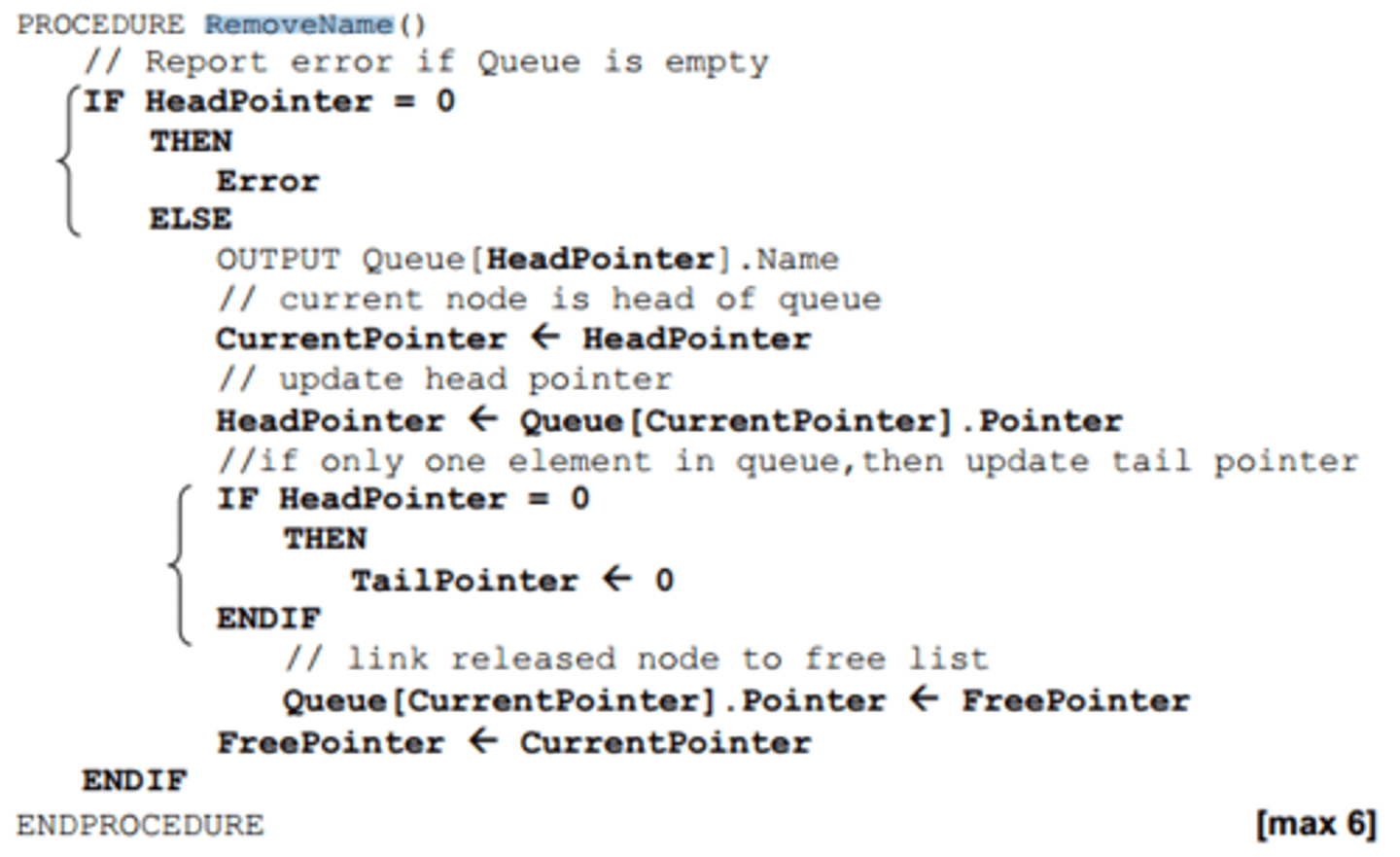
Queue - Remove (linked list)
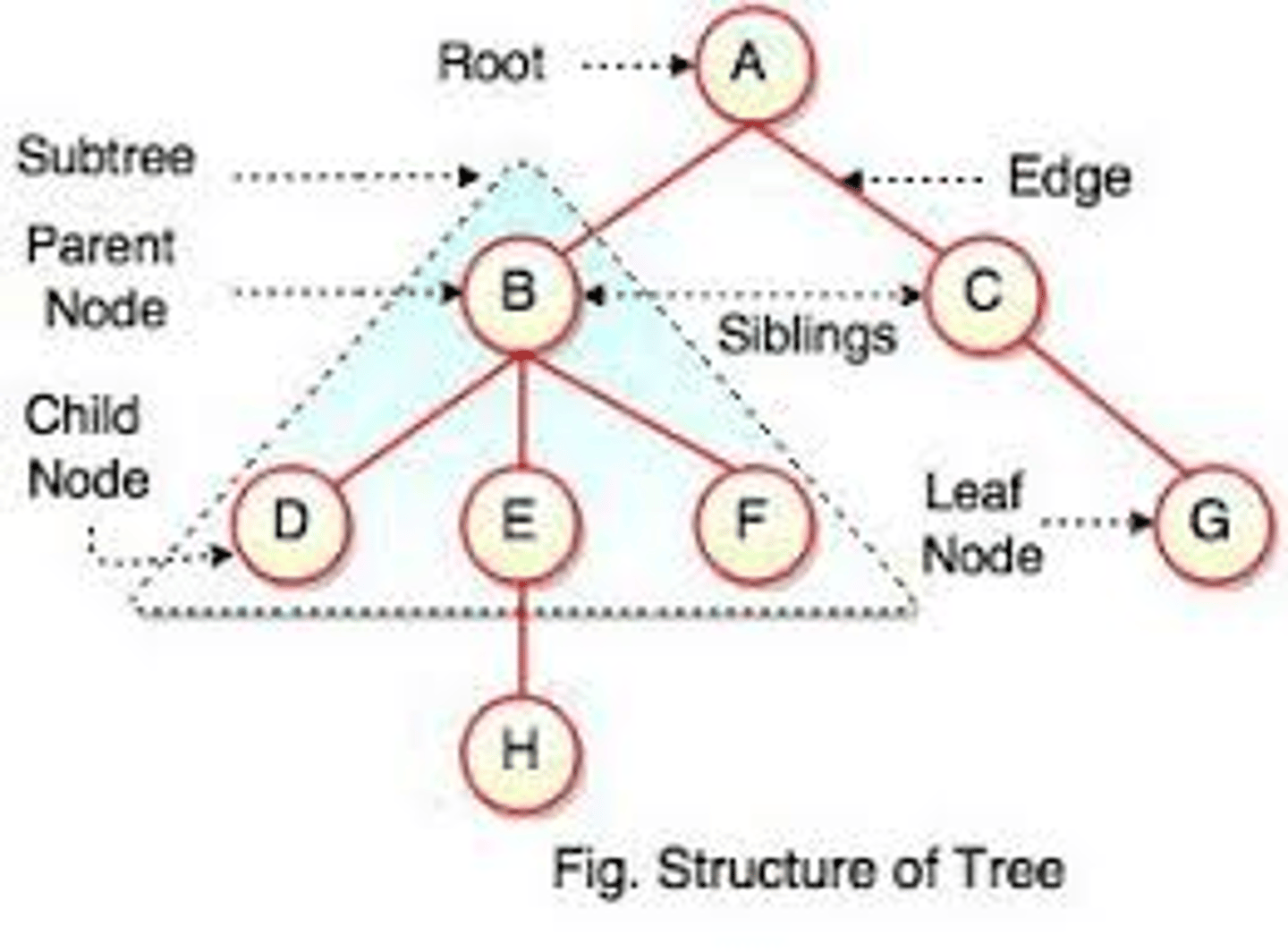
Tree
Nonlinear data structure, compared to arrays, linked lists, stacks and queues which are linear data structures.
Can be empty with no nodes or a tree is a structure consisting of one node called the root and zero or one or more subtrees.
Binary Tree
Tree data structure in which each node has at most two children, which are referred to as the left child and the right child.
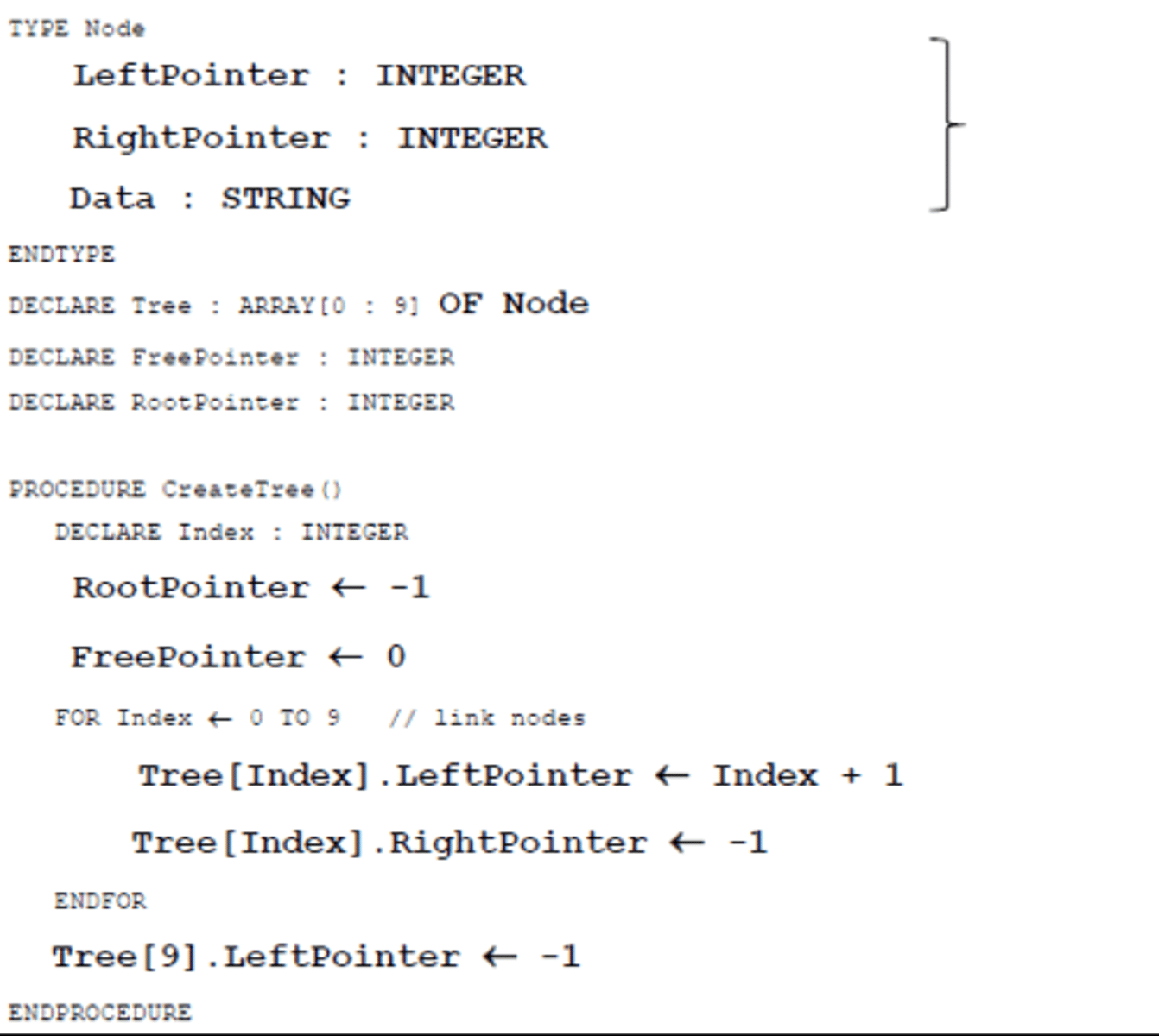
Binary Tree - Create empty tree example
Binary Tree - Add to Tree example

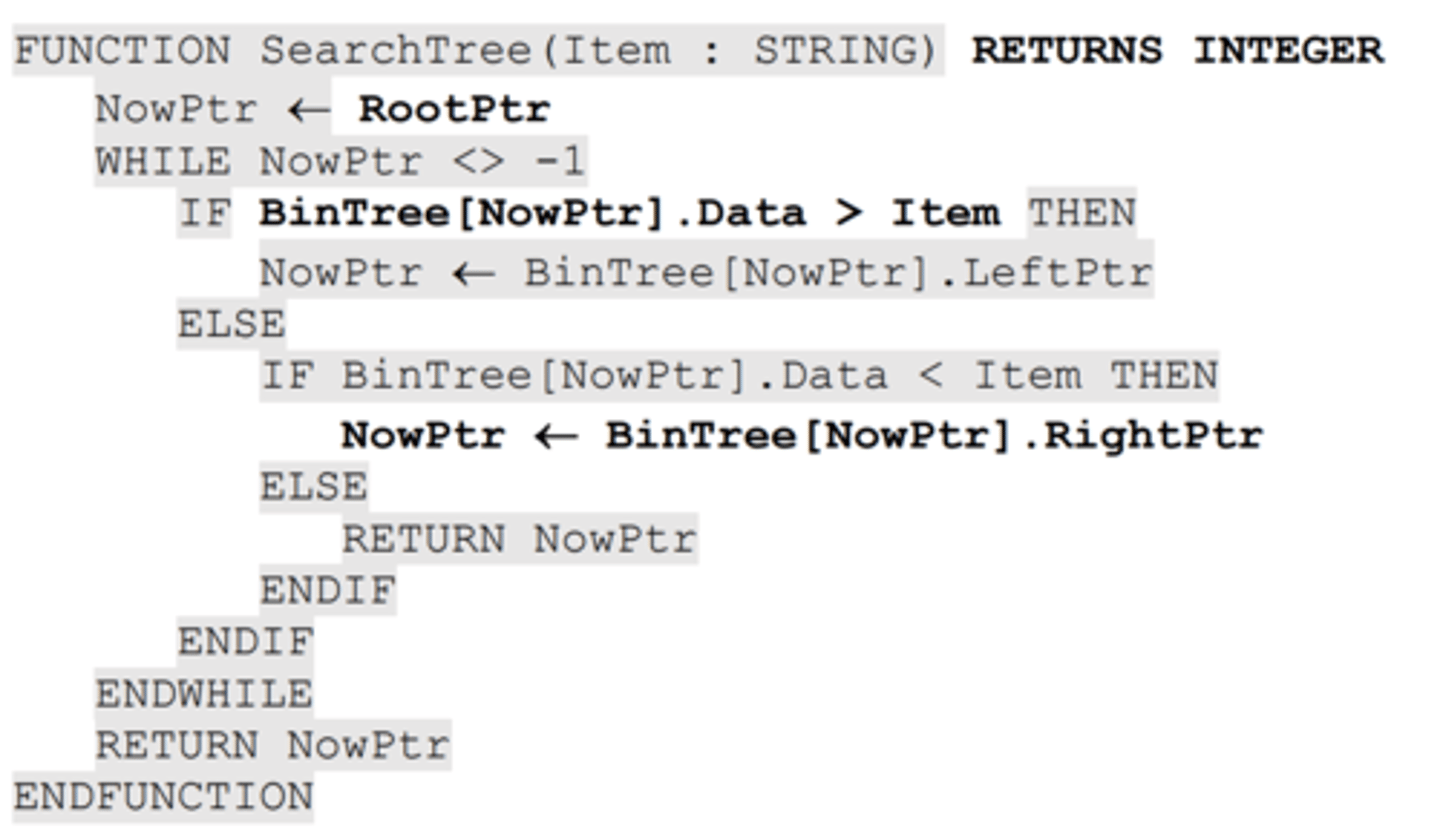
Binary Tree - Search tree
Binary Tree - Traverse tree recursive example

Stack
Last In First Out (LIFO)
Operations
create stack
add item to stack (push)
remove item from stack (pop)
Stack with recursion
A LIFO data structure
The compiler must produce object code to...
…push return addresses / values of local variables onto a stack
…with each recursive call
… to set up winding
…pop return addresses / values of local variables off the stack
…after the base case is reached
… to implement unwinding.
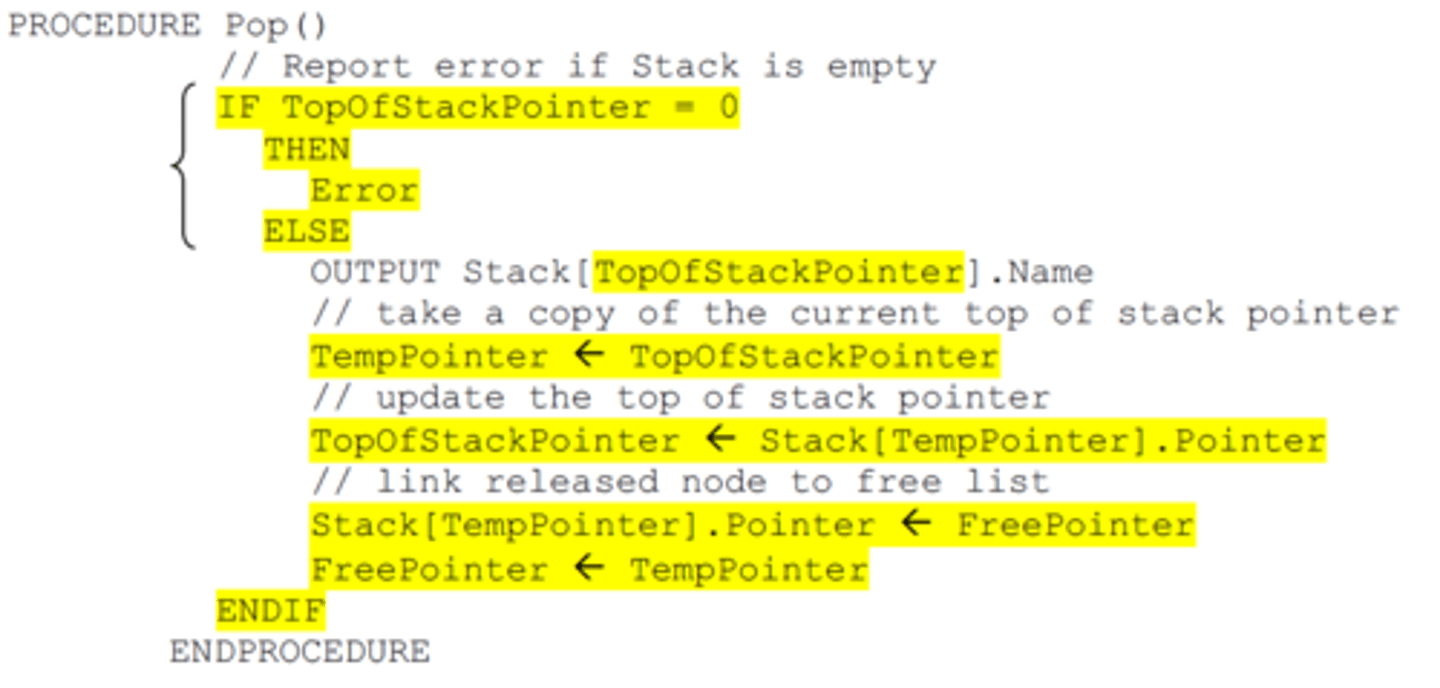
Stack (pop)
Stack (push)

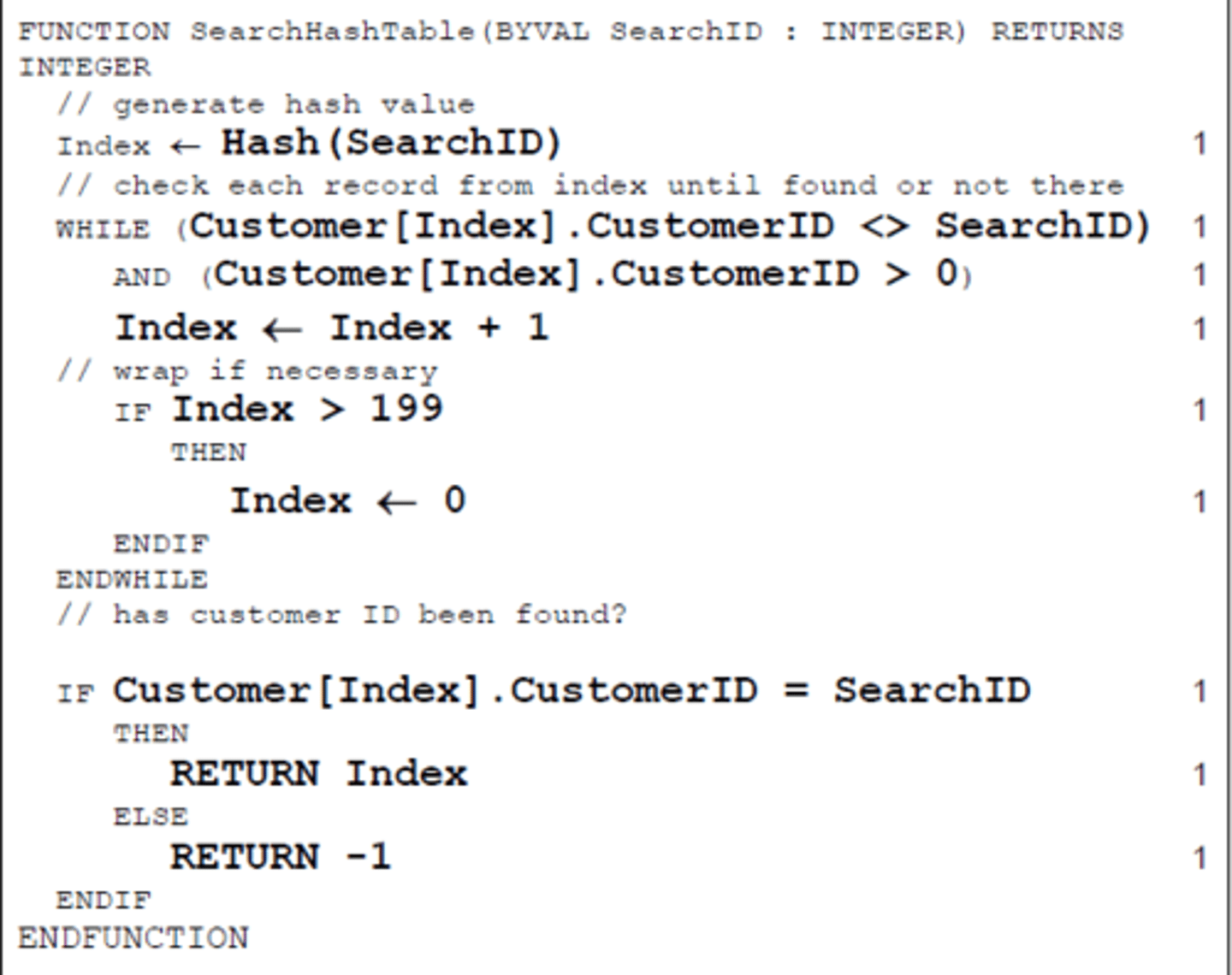
Dealing with collision
Create an overflow area...the 'home' record has a pointer to the others with the same key
Store the overflow record at the next available address in sequence
Redesign the hash function... to generate a wider range of indexes to create fewer collisions
Dealing with collision - next location

Recursion features
It is defined in terms of itself // it calls itself
It has a stopping condition // base case
It has a general case
It is a self-contained subroutine
It can return data to its previous call
Unwinding can occur once the base case is reached
How recursion works
(When the recursive call is made) all values/data are put on the stack
When the stopping condition/base case is met the algorithm unwinds
The last set of values are taken off the stack (in reverse order)
Dictionary declaration
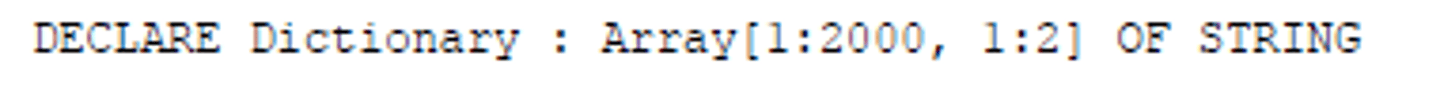
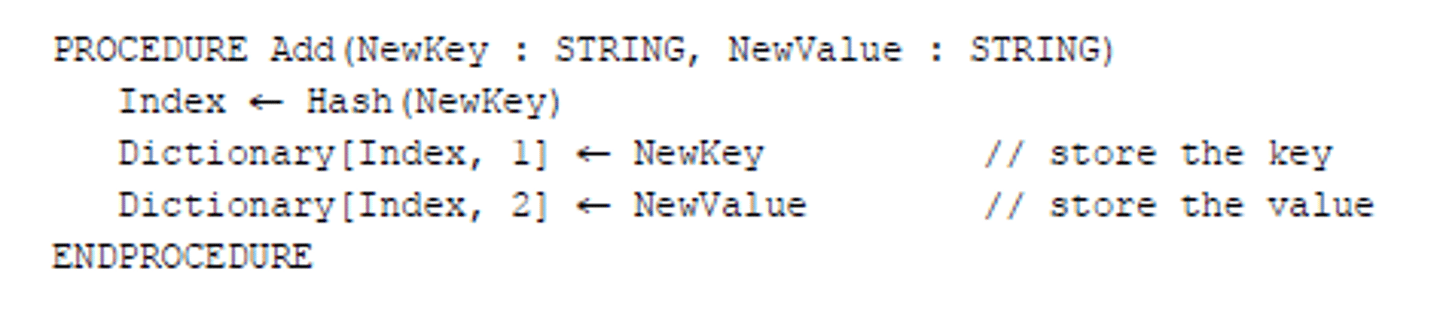
Dictionary Add key with hash
Factors that may affect the performance of a sorting algorith.
The initial order of the data
The number of data items to be sorted
The efficiency of the sorting algorithm
Big O Notation
A way of expressing the worst-case run-time of an algorithm
Useful for comparing the speed of two algorithms.
Linear Search Big O
O(n)
Time to search increases linearly in relation to the number of items in the list
Time to search increases more rapidly for a linear search than a binary search
Binary Search Big O
O(log n)...
...uses logarithmic time
Time to search increases linearly as the number of items increases exponentially
Time to search increases less rapidly for a binary search than a linear search
Bubble Sort Big O
O(n^2)