Parallel Computing
1/25
Earn XP
Description and Tags
Flashcards for COMP3221
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
26 Terms
Briefly describe what Instruction Level Parallelism (Pipelining) is? How well does it scale? What are the required changes that need to be made to code to support pipelining?
Different stages of instruction execution (fetch, decode, execute, write back) can overlap.
Does not scale well (only supports 10-20 simultaneously pipelined instructions).
Does not require changes to code, legacy code automatically benifits from pipelining.
What are the three major parallel computing architectures? Give an example of a programming framework for each one.
Shared Memory Parallelism
OpenMP
Distributed Memory Parallelism
MPI
General Purpose Graphics Processing Unit (GP-GPU)
OpenCL
What is the difference between the terms “parallel” and “concurrent” in the context of computing?
Two programs run concurrently if they run within the same time frame.
Two programs run in parallel if their execution is performed simultaneously.
Parallelism implies concurrenct (BUT NOT VICE VERSA).
What is Flynn’s Taxonomy? What are the 4 different categories outlined by Flynn’s Taxonomy?
Flynn’s Taxonomy is a classification of computer architectures based on the number of concurrent instructions streams and data streams they can process.
Single-Instruction Single-Data (SISD): Single core CPUs
Single-Instruction Multiple-Data (SIMD): GP-GPUs
Multiple-Instruction Multiple-Data (MIMD): Multi-core CPU’s and cluster computing.
Multiple-Instruction Single-Data (MISD): Specialised hardware.
Explain the concept of simultaneous multithreading (a.k.a Hyperthreading). What type of performance increase can you expect from simultaneous multithreading?
Simultaneous multithreading (hyperthreading) is when two or more threads run concurrently on the same core.
If one thread stops running (e.g. to wait for a memory access request), the other thread takes over.
Performance improvements of only 15%-30%
What is cache coherency?
Cache coherency is the act of maintaining a consistent view of memory for/across all cores.
Given an example scenario which cache coherency tries to solve.
Core 1 reads memory address x and stores this value in its L1 cache.
Core 2 does the same thing, reads memory address x, and stores this value in its L1 cache.
Core 1 changes the value of x in its L1 cache.
Core 2 reads the value of x from its L1 cache, but this is now an outdated/old value!
How is cache coherency enforced? What problem does this mechanism present? What is this problem called?
A unit on the CPU called the cache controller will detect any writes to low-level caches and propgate these changes to higher level caches.
This presents a problem if two cores constantly write to two different addresses that are on the same cache line, but never read each others’ updated data.
This is known issue is known as false sharing.
What is the difference between a process and a thread?
Processes are:
Whole executable programs,
that have their own independent address spaces,
require explicit comminication to communicate with one another,
are computationally expensive to create.
Threads are:
Execution units that make up a program,
Share the same address space as other threads in the program,
can therefore communicate implicitly,
are computationally cheaper to spawn.
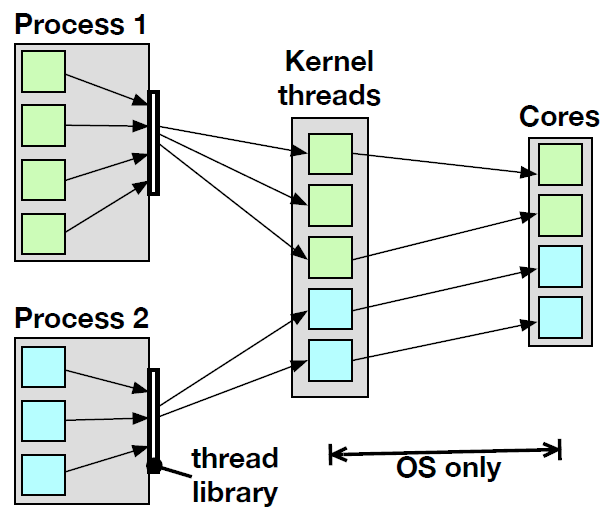
What is the difference between user-level threads and kernel-level threads?
User-level threads cannot access cores directly, instead they are mapped onto kernel-level threads via an OS service called the scheduler.
Kernel-level threads have direct access to the cores (can be directly mapped to CPU cores).
What is meant by a “map” in the context of parallel computing?
A “map” (a.k.a a data parallel problem), is any computational task where a single instruction is applied to a, iterable collection of items. That is therefore to say a SIMD parallel problem.
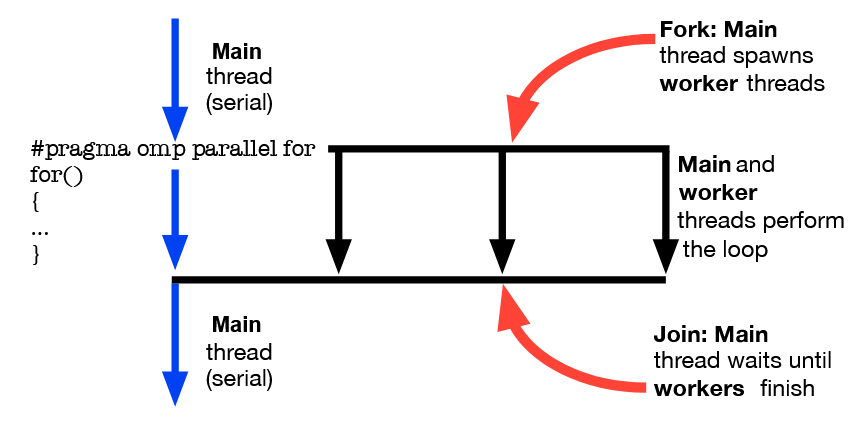
What is meant by the term “fork-join construction” in the context of parallel computation.
“Fork-join construction” is a program execution paradigm where a (serial) main thread spawns (forks into) multiple worker threads. These worker threads then run concurrently to complete some tasks. When the worker threads have completed their tasks, the result from each thread is aggregated, and the threads are destroyed (that is, they join back up with the main thread).
Explain what is meant by an “embarrisingly parallel problem”.
An “embarrisingly parallel problem” is one that can be easily divided into multiple subtasks that require little to no communication, synchronisation with each other, and have little to no data dependencies between each other. It is very easy to get such tasks to work correctly in parallel.
Give three examples of additional overheads that may be incurred when using a parallel algorithm over an equivalent serial algorithm.
A computation overhead is incurred due to the need to create, schedule, and destroy threads.
Overheads may be incurred due to the need for various communication (not present in serial) between threads.
May be additional computation overheads required to, for example, partitiona a problem between multiple threads.
How is the term “speed-up” mathematically defined in parallel computation?
S = ts/tp
What is meant by the term “super-linear” speed-up?
“Super-linear” speed-up is acheived when the speed-up, S, acheived by implementing a parallel solution is greater than the number of processors assigned to the task.
S(p) > p
Super-linear speedups are possible (because parallel algoritms can benefit from better utilisation of CPU cache), but are exceedingly rare due to all of the additional overheads that parallel algorithms bring.
What is the formula for parallel “efficiency” (E)? What is the ideal value of E? What sorts of values of E would you expect for super-linear speed-up?
E = S/p = ts/(ptp)
The “ideal” value of E should be = 1, that is, the speed-up matches the number of processors.
For super-linear speed-up you would expect values of E > 1.
Derive the equation for Ahmdal’s law.

Derive the equation for the Gustafson-Barsis law.

Explain briefly what the “Jacobi” method is and where it is used.
The Jacobi method is used to reslove data races in calculations that update values in an array where the updated value depends on previous values in the array.
Works by first creating a temporary copy of the original array. Threads then read (and only read) the values of the array from this temporary copy and use the values to update the original array. Since the threads are only reading from the temporary array and not writing to the temporary array, data races are eliminated.
Explain briefly what the “Red-Black Gauss Seidel” method is and where it is used.
The Red-Black Gauss Seidel is used to resolve data dependencies in image smoothing, heat equation, diffusion equation algorithms. In these algorithms smoothing is acheived by updating an array value with the mean of it’s two neighbouring values.
The Red-Black Gauss Seidel method works by first updating all even indicies and then updating all odd indicies. Since updating even indicies involves reading from odd indicies and writing to even indicies (and vice versa updating odd indicies involves reading from even indicies writing to odd indicies), data races are eliminated.
What is meant by the term “thread-safe” in the context of parallel computing?
A program/method/function is “thread-safe” if it can be executed by multiple threads concurrently without leading to unexpected behaviour, data races, memory corruption etc.
Give three reasons why critical regions can incur large overheads.
Threads entering and exiting the critical region require synchronisation (additional computation is required to acheive this).
Threads that are blocked and the entrance will be idle (which leads to poor load balancing).
The OS scheduler may suspend idle threads in favour of active threads (that do not necessarily belong to your application)!
What is meant by the term “serialisation” in the context of parallel computation?
“Serialisation” occurs as a result of implementing critical regions. Since only one thread can access a critical region at a time, this essentially means that the part of the code enclosed in a critical region will run in serial. Due to the overheads incurred by ciritical regions, the performance here could be worse than the equivilent section of serial code.
What are the four steps to ensuring thread safety?
Identify data dependecies
Enclose sections with data dependencies in critical regions
Reduce size / number of critical regions until required performance is acheived.
If further scaling / performance is required might need to rethink solution / algorithm all together!
What are “atomics” in the context of parallel computation?
“Atomics” are like critical regions that ony work on single arithmetic operations (such as incrementation, i++). Atomics exploit hardware primatives to prevent data races. They are much more efficient than critical regions due to this hardware level implementation.