Module 6 - Cause & Effect Learning
1/42
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
43 Terms
Classical Conditioning
learning to reach a predictive stimulus
when one stimulus repeatedly and continuously follows another one
- We develop a condition response as a result to those experiences
The predictive stimulus predicts the eliciting stimulus
- The eliciting stimulus triggers the reflex/response
- Learn to anticipate what elicits the reflex behavior and respond ahead of time to the predictive stimulus (this is where the adaptiveness is achieved)
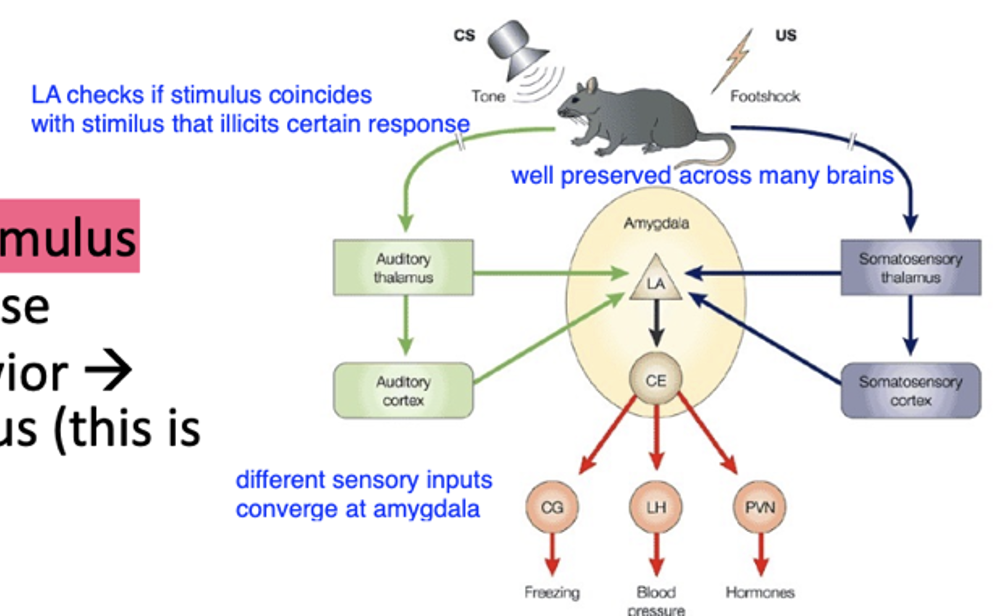
Amygdala
- Amygdala gets response before rest of the brain, sees blur
why blurs can cause fear response
- shock is nauseous stimulus, noise is not, if hear toaster (in this case toaster shocks us) we get nauseous stimulus, through pairing of neutral and nauseous stimuli
- brain learns relationship and predicts, cause and effect learning, boils down to prediction making
Unconditioned stimulus (US)
- The stimulus that automatically elicited the behaviour (usually innate)
- E.g., the food elicited the slobber
Unconditioned Response (UR)
- The behaviour that is automatically elicited
- Unlearned, often reflexive
Conditioned Stimulus (CS)
- The stimulus that predicts the US
- Is a learned (thus conditioned) stimulus
Conditioned Response (CR)
- The behaviour that occurs to the CS
- Often very similar to the UR
- Occurs because the CS predicts the US
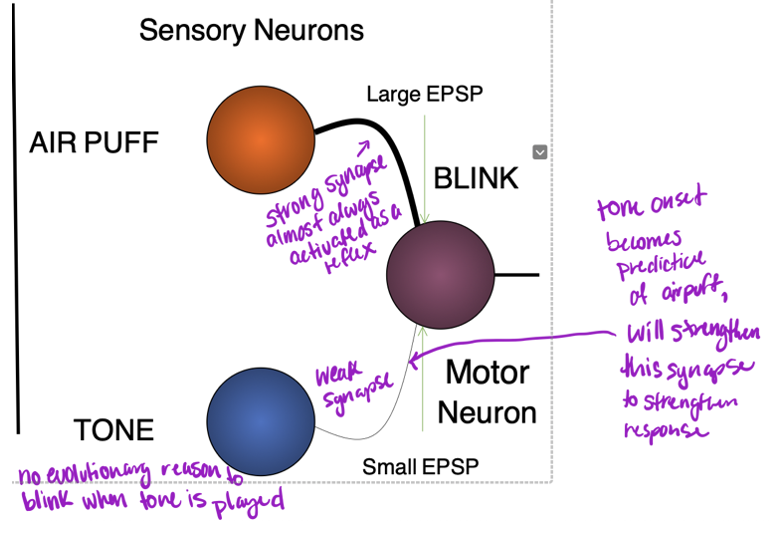
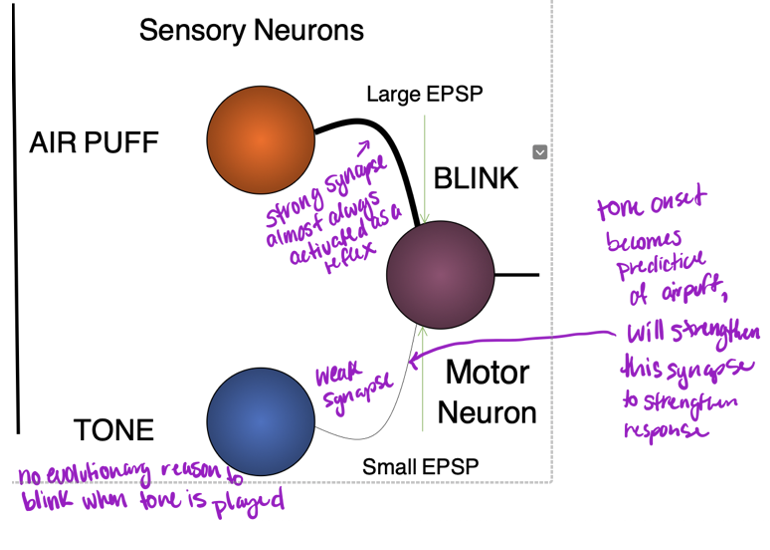
Stimulus-Response (S-R) Learning
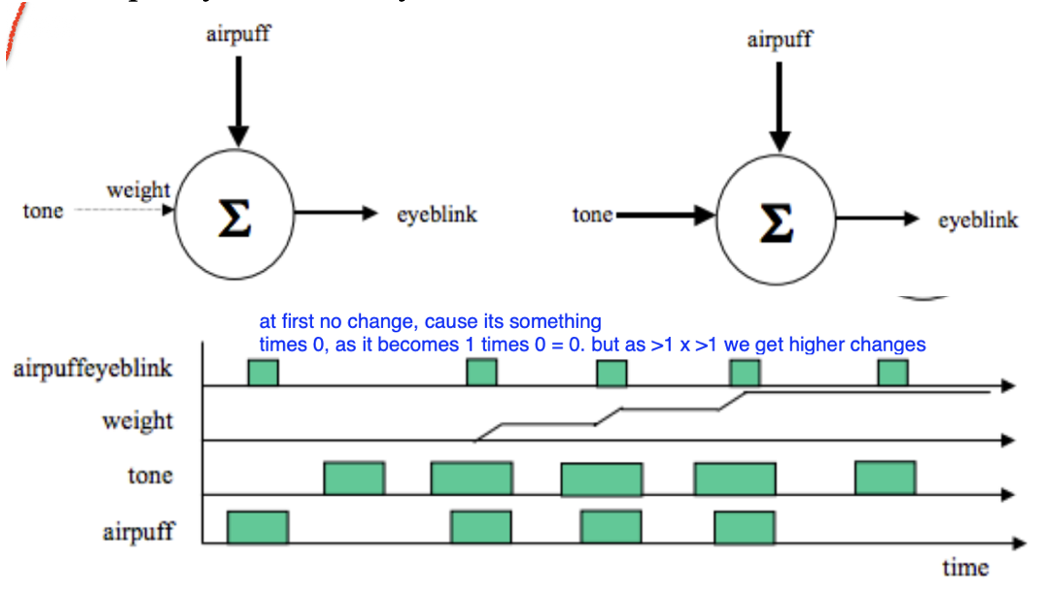
• When applying an air puff to the eye, we blink – typical response
• Sensory neurons process air puff, synapse between those neurons and motor neurons
- When these are active they send glutamate molecules to activate motor neurons that process it are not connected to the same motor neurons
- No reason for us to eye blink (after a while strong synapse forms)
Hebbs statement
“Neurons that fire together get wired together.”
- “When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A's efficiency, as one of the cells firing B, is increased.”
- if 2 cells are active close enough in time, connectivity between those two strengthens that’s what Hebb is saying (congruity)
- connectivity between cells will increase, coactivation results in strengthening
Hebb Rule
• Hebb proposed that synapses are strengthened by learned associations
• This would happen when two interconnected cells are excited simultaneously: When activity in the presynaptic cell leads to firing in the postsynaptic cell, this coincident activity causes a strengthening of the active synapse (e.g., the association between the auditory neuron and the motor neuron)
Hebbian Learning
deltaWij = change in weight of synapse
y = learning rate (learn after repeated instances)
xjxi = coactivation product, xj is output of postsynaptic neuron and xi is output of presynaptic neuron
when neurons active xj and xi are one
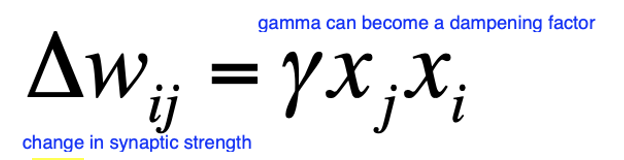
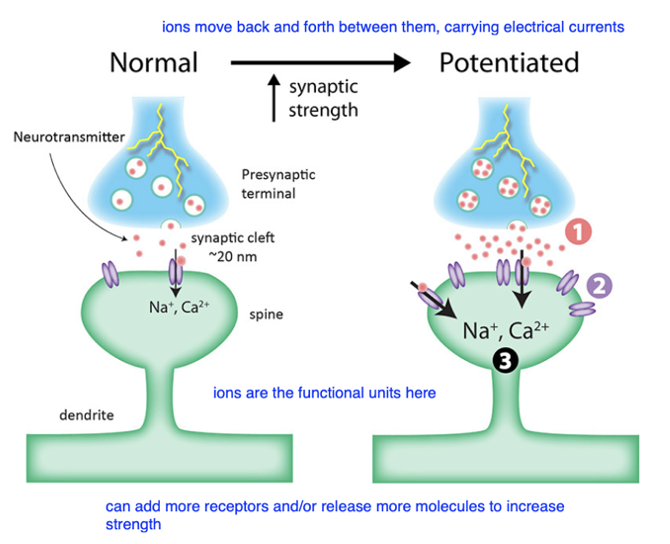
Neuron communication model for Hebb
weak synaptic connection becomes strong
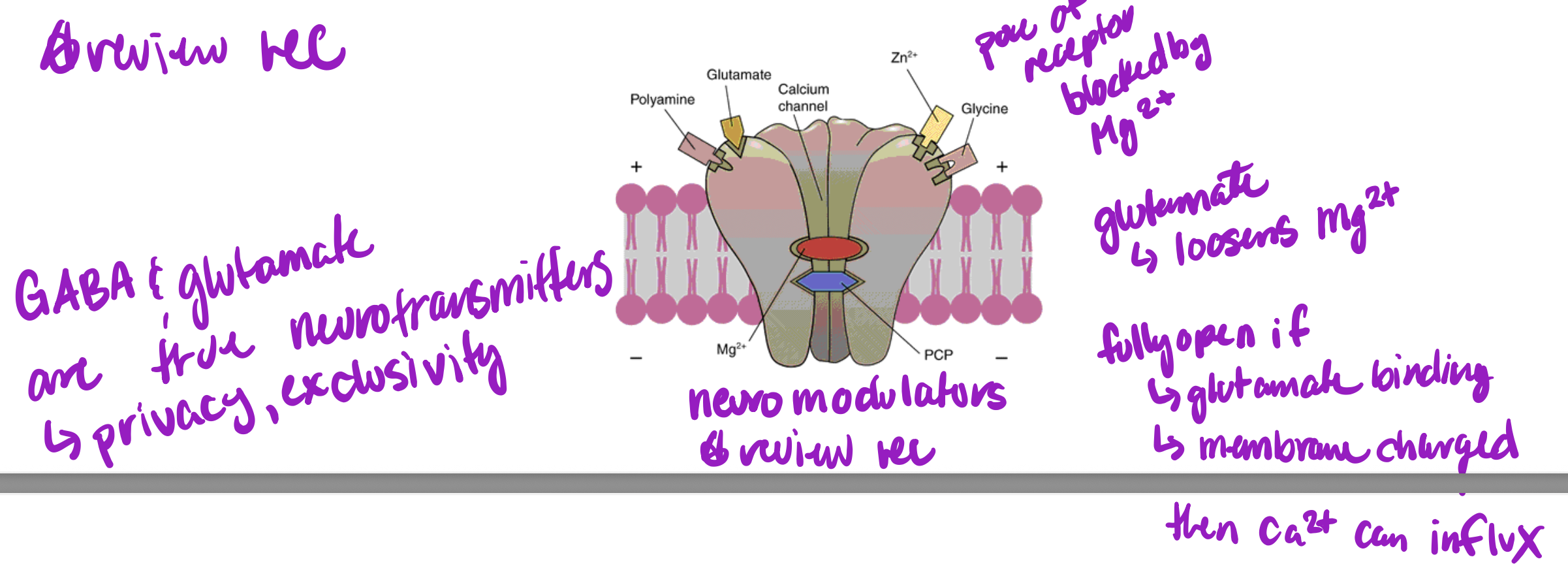
NMDA Receptor
NMDA receptor blocked by Mg
glutamate loosens Mg
fully opens upon glutamate binding and membrane charged
then Ca can influx
leads to glutamate receptors being inserted on post-synaptic neuron
Parameters of Classical Conditioning
• Relationship between UR and CR is critical
- CS must predict the US or no conditioning
- Sometimes the UR and CR are the same or so it seems
- At other times, UR and CR are similar or in similar family of behavior
• The CR can be opposite of the UR
- Compensatory response (why relapse is common)
- If predicted to go up, you respond by going down
Extinction
If CS-US pairing is terminated (CS— >nothing), then the CR will also fade away
- Extinction is not unlearning or habituation
- extinction learning is just learning another thing, brain puts them against each other, both fade away
- delete button is inhibition of protein synthesis
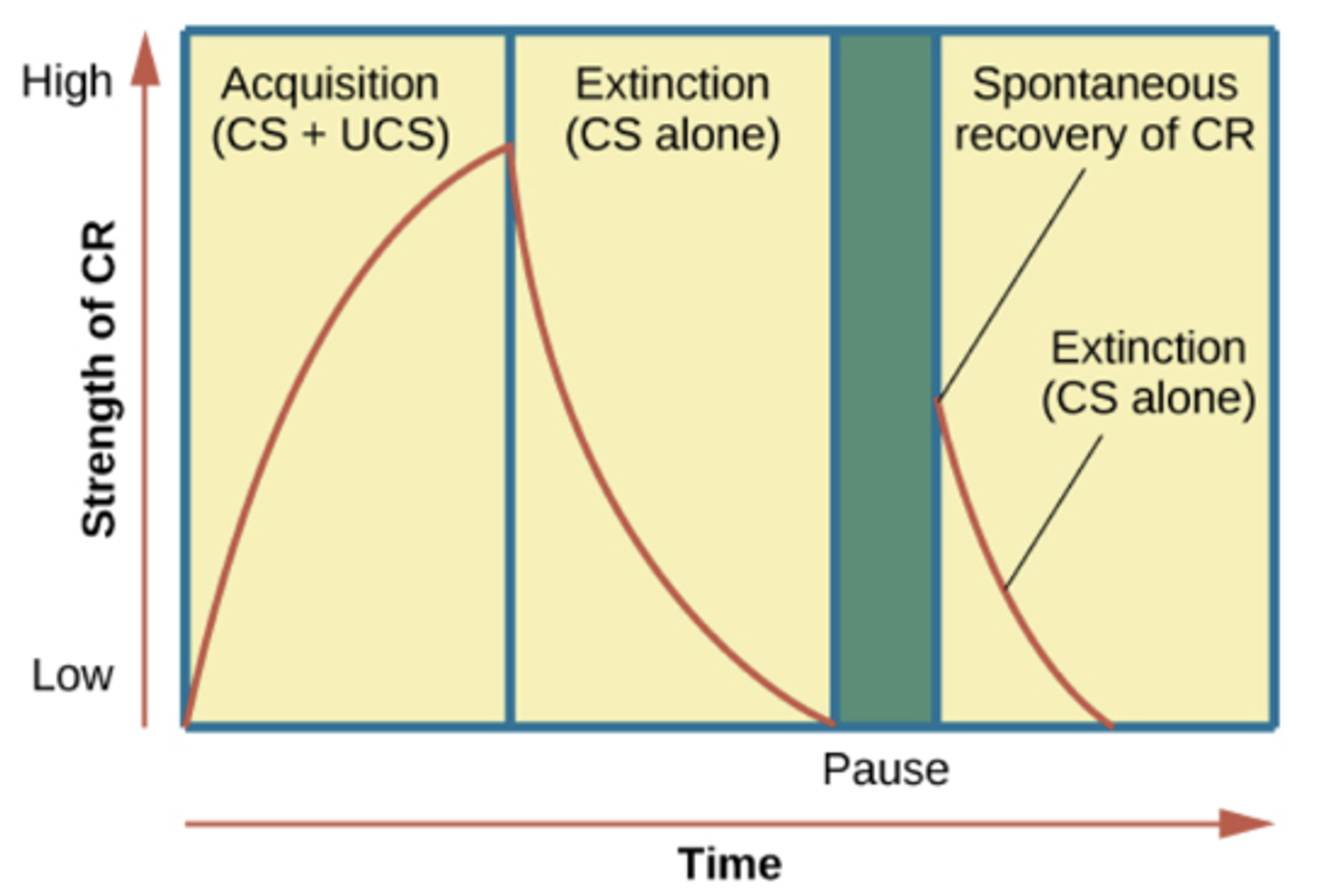
Spontaneous Recovery
- Sometimes when conditions are similar to CS, the animal shows the CR
- Unpredictable; almost as if the “suddenly remembered”
- More likely to occur when the animal is stressed, tired, hungry, etc.
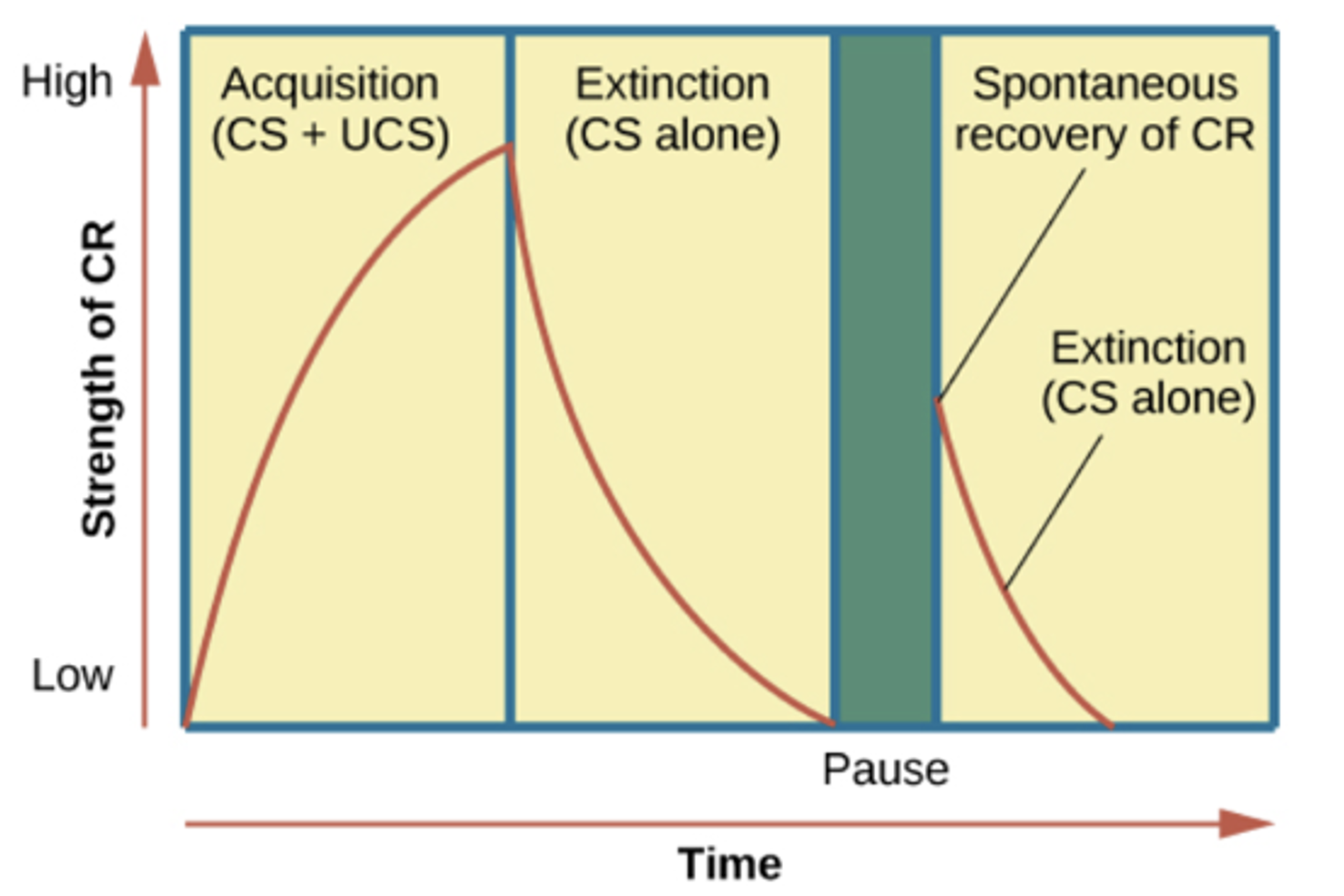
Relearning
- Relearning is faster than original learning
- True if extinction occurred and if just haven’t had the experience for a while
- Extinction will lose unless memory is forgotten
Generalization
: CR will occur to stimuli that are similar to the original CS
Dicrimination
Can train the animal so the CR only occurs to very specific CSs
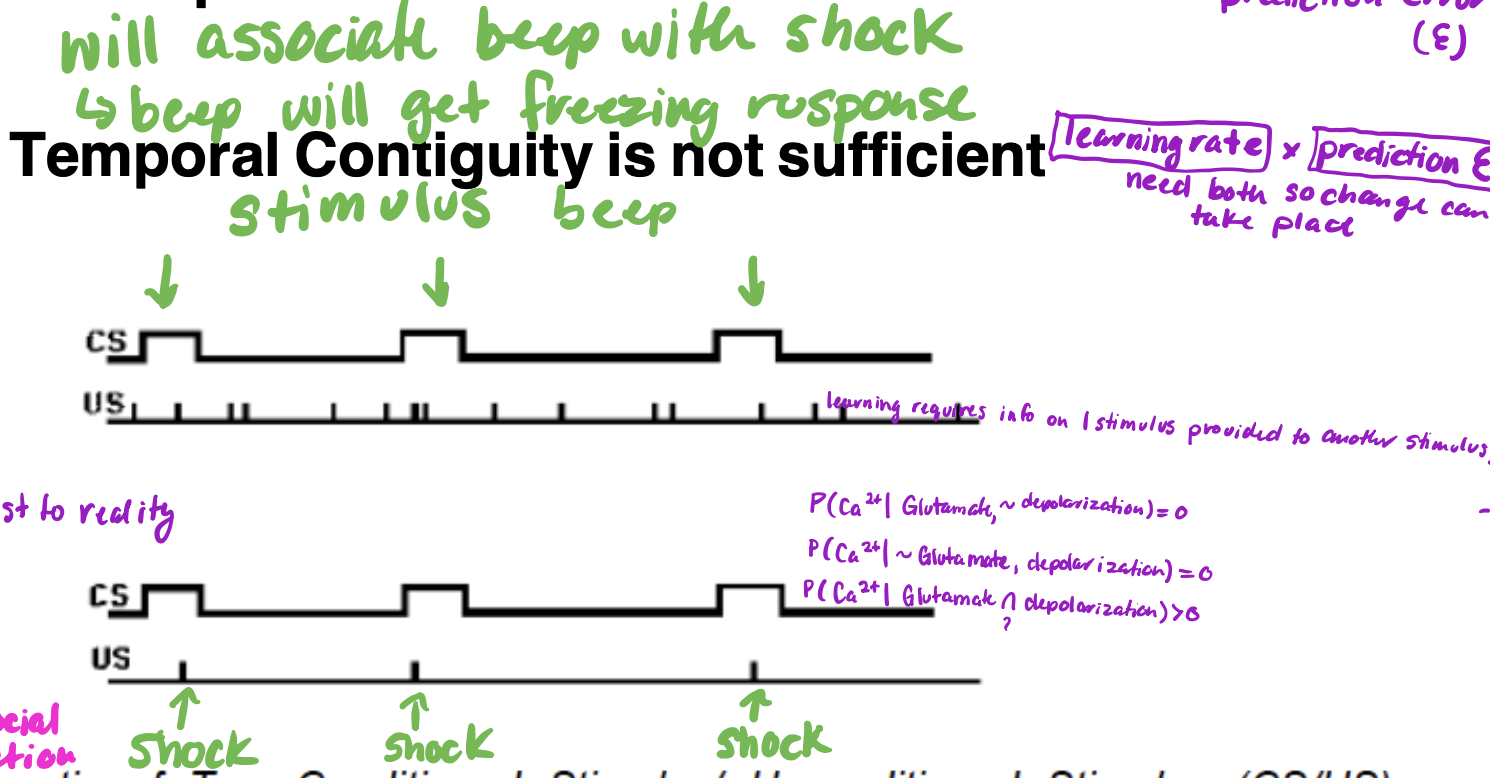
Robert Rescorla’s Critique
emphasizes the information that one stimulus provides about the other one rather than temporal contiguity (information value of CS is what matters)
• It is rather representational rather than purely associative/reflexive
- learning is based on information one stimulus provides about another stimulus
Prediction error
• learning rate x prediction error = something to change in state of animals brain, very economical way of representing the animals world
• prediction error = difference between our model of world and actual model
• model of world, want gamma less than 1 so that we gradually bring our model closer to real world
• ultimate aim of system is to adapt to environment, learning rate x prediction is algorithm neurons firing together is mechanical way this is achieved, assumes learning is passive

Rescorla’s critique on temporal congruity
• there is temporal contiguity but there is also contingency P(getting shock given CS) = 1
• contingency is value of CS with respect to US.
relative P(US given CS) = P(US | not CS), if these are equal then there is no learning.
- If temporal congruity is everything, learning would still occur. for learning, these should not be equal.
- if P of shock during CS is not equal to P of shock outside of CS there is learning
Signal Relation between CS and US
no information to be learned when they are equal
Negative contingency space - CS still has info to learn but predict absence (ex. calves associate mothers with absence of risk)
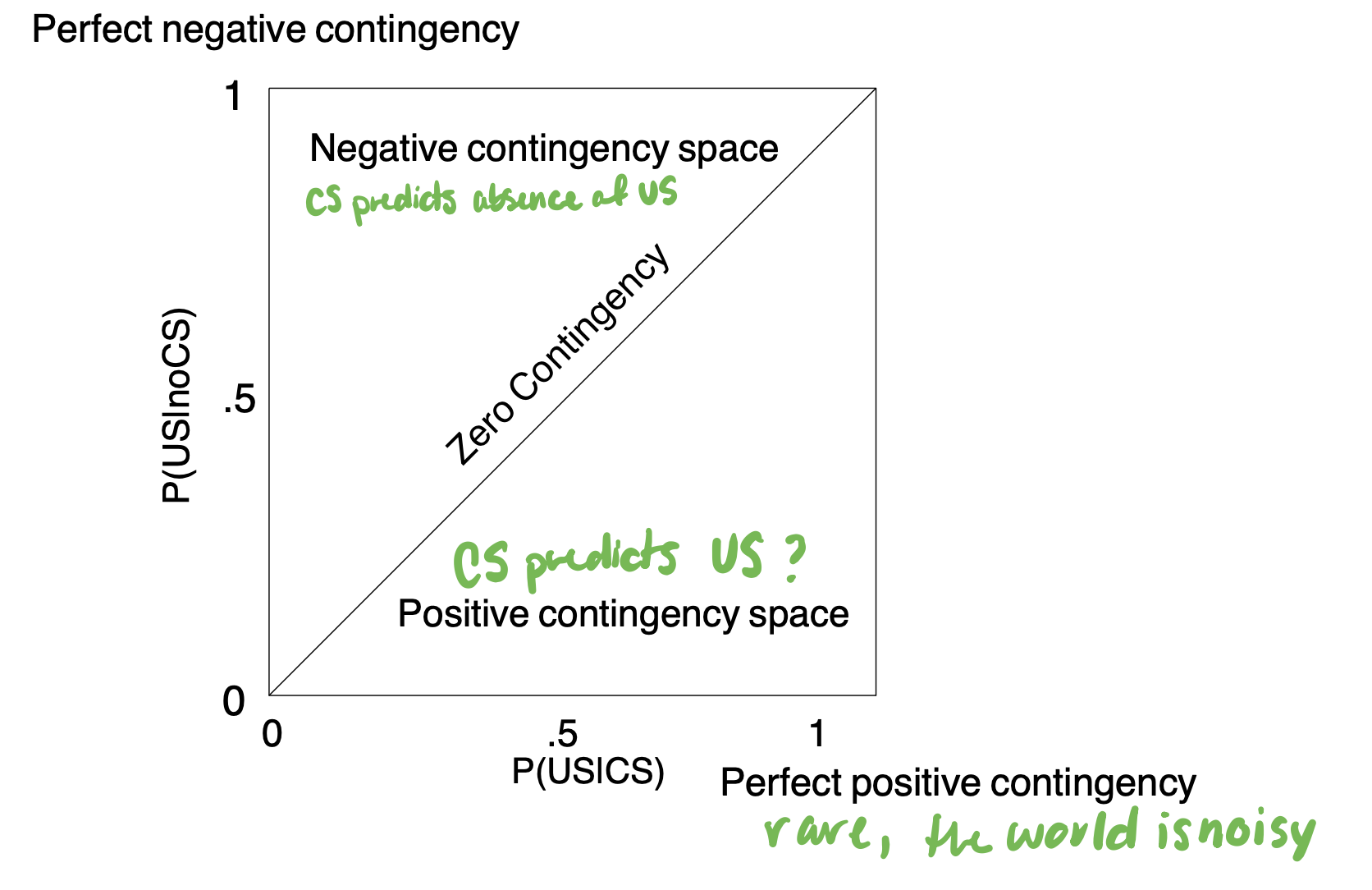
Rescorla conclusion
- temporal congruity is NOT sufficient and NOT necessary because learning can occur in the absence of things
conditioning appears to depend more on the information that CS provides about the US rather than the pure temporal contiguity between them
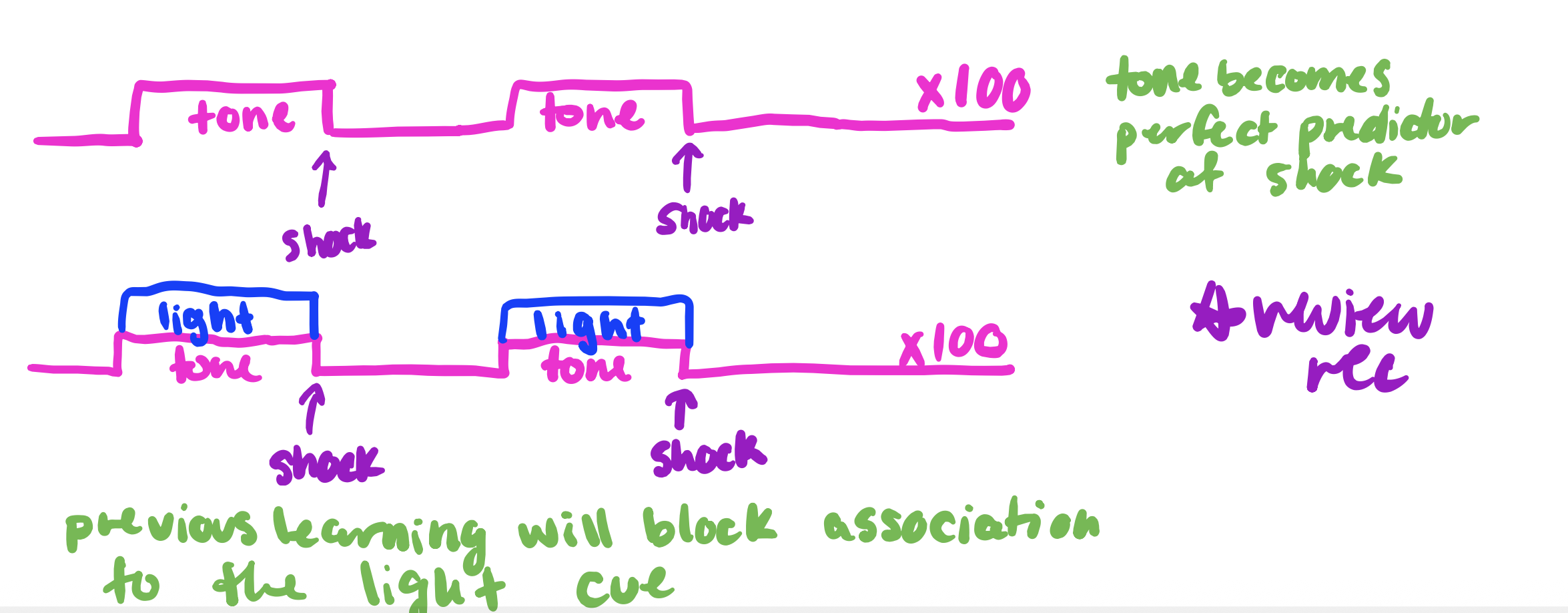
Overshadowing
- Use one “weak” and one “strong” CS
- CS1 + CS2 -> US
• Reaction to weaker stimulus is blotted out by stronger CS
Rescorla Wagner Model
deltaVi = amount learned (conditioned) on a given trial ~ synaptic weight
alpha = learning rate (increase here results in more learning) (salience of CS)
beta = salience of US
(lambda - Vsum) = total amount of conditioning that can occur to a particular CS-US pairing
lambda - prediction error (what u get from environment)
Vsum - what u expect
(maximum amount of learning) - (amount of learning that already ocurred)
- this equation shows on average how brain seems to learn but learning is an individual phenomenon, not an average one
- marginal gain of synaptic weight becomes less over time, shows most learning occurs at the beginning
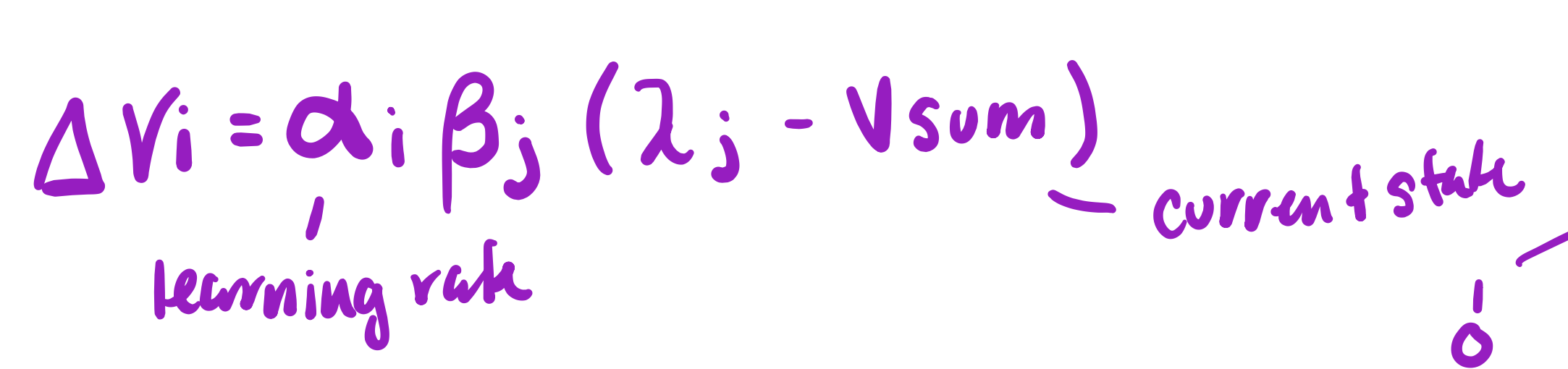
Rescorla-Wagner recap
• CS-US association increases proportional to which US is surprising
• Larger prediction error -> greater learning
• When you fail to predict the US, you want to increase your likelihood of predicting it in the future (given the same CS).
- ∆Vn = 𝛽 x prediction error
- Learning is prediction error x dampening factors
- learning is prediction error times dampening factor to reduce noise cause there is too much noise in the environment
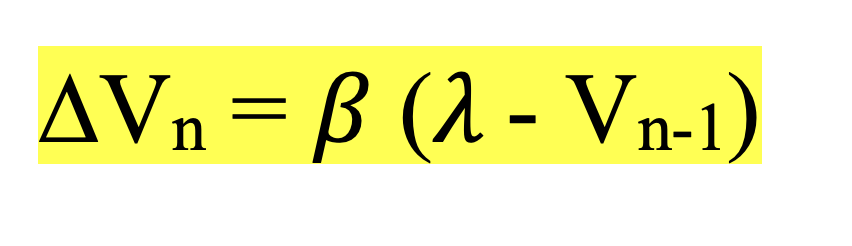
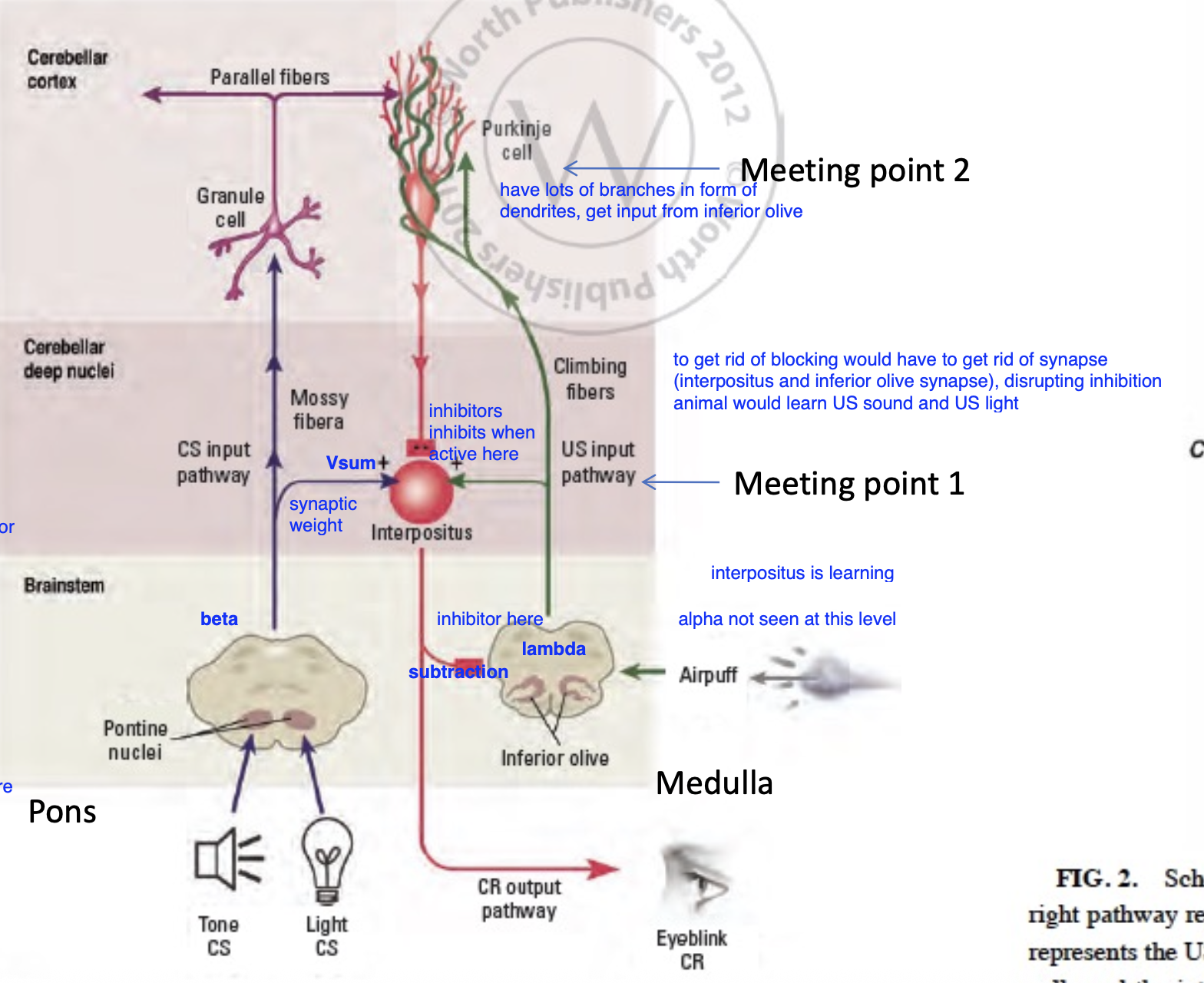
Eye-Blink Conditioning and Cerebellum
• Tone (CS) and light (CS) go to pontine nuclei (beta – dampening factor)
- Travels from pontine nuclei to interpositus (Vsum) and purkinje cell (GABAnergic)
- Purkinje cell quiets the interpos inhibitors, learns when its time for uninhibition
• Air puff (US) travels to inferior olive (lambda)
- From inferior olive goes to purkinje cell and interpositus
• Interpositus nucleus is a coincidence detector (connects sound to reflex)
- CR output of eyeblink
- As learning continues, will inhibit inferior olive
- Makes prediction error smaller and smaller
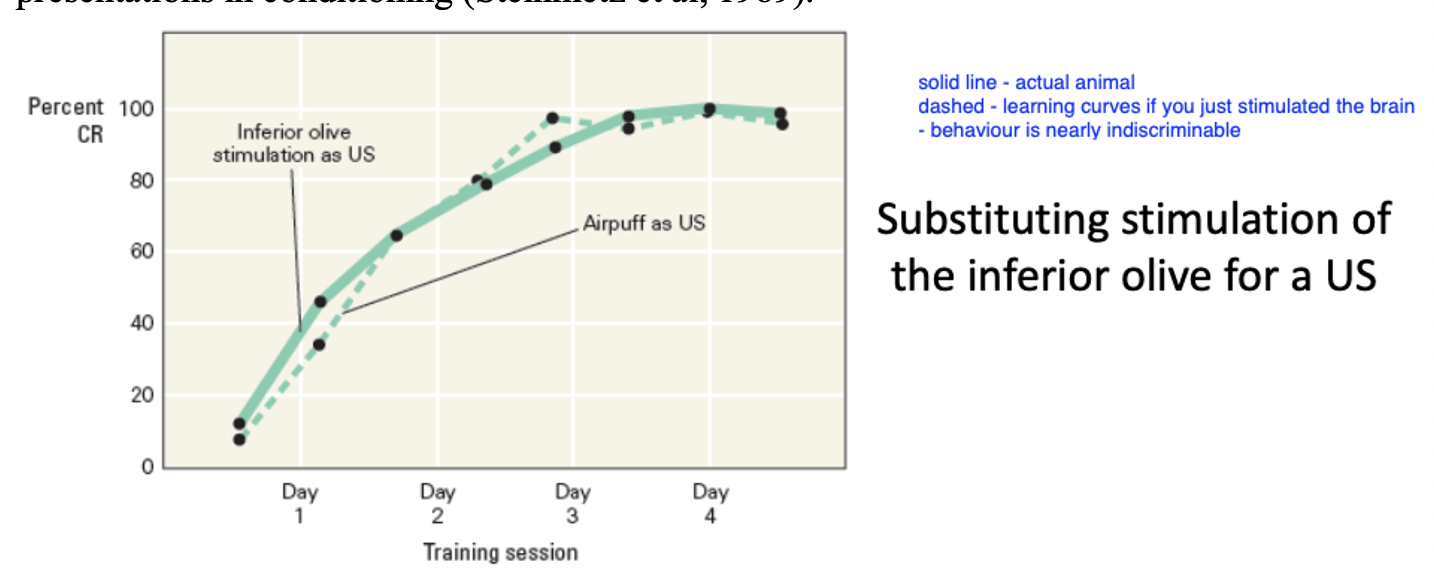
brain stimulation instead of behavioural training
should be possible to generate conditioned eyeblink response by pairing electrical stimulation of the pontine nuclei (CS) with electrical stimulation of inferior olive (US) with no presentation of external stimuli
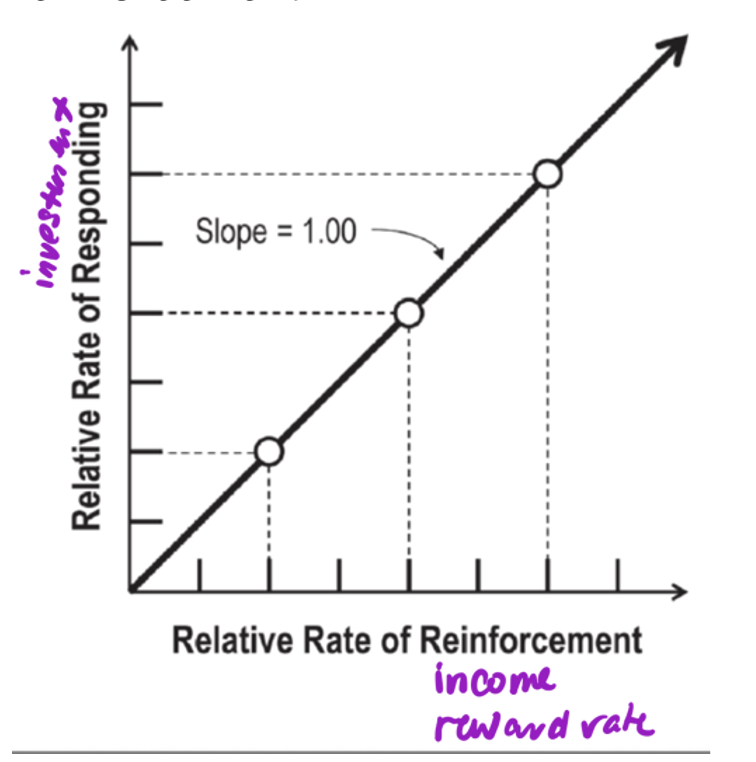
Herrnstein’s Two Parameter Matching Equation
- Matching law is innate
- Bisons grazing in a patch distribute themselves in terms of reward rate, move to richer patches - this is matching
Prob of being at one patch (P1) over another (P2) is equal to richness of patch 1 (R1) over richness of patch 2 (R2).

Relative Rate Graph
• Relative rate of responding varies or matches
- Note that this assumes animals are comparing one reinforcement source to another
- How good is alternative 1 in comparison to alternative 2
• Basic assumption: animals match the relative rate of responding to the relative rate of reinforcement
• biomechanical cost (spending of energy) and opportunity cost of not doing anything else while in patch, nature is economical
• think of any biological choice as one with a cost associated with it, always comes with at least an opportunity cost
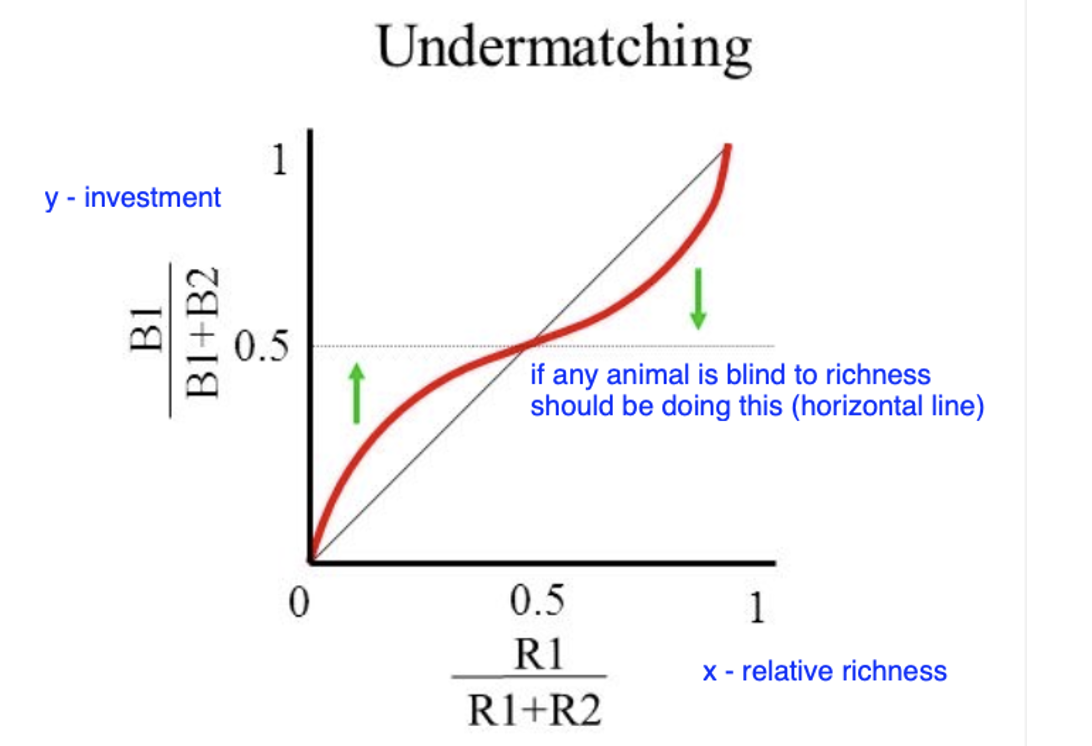
2 deviations from matching
• Baum (1974) adds two parameters to deal with consistent deviations noted in animals
• b (Bias)
• a (reward sensitivity or matching)
- Accounts for deviation with matching
Baum new matching formula
Log(P1/P2) = a log(R1/R2) log(b)
a - reward sensitivity or matching
b - bias

undermatching
under sensitivity to reward: a < 1.0
invest everything on poorer patch, some animals do this
- Any preference less extreme than the matching relation would predict
- a = 1.0: perfect matching
(horizontal line is chance)
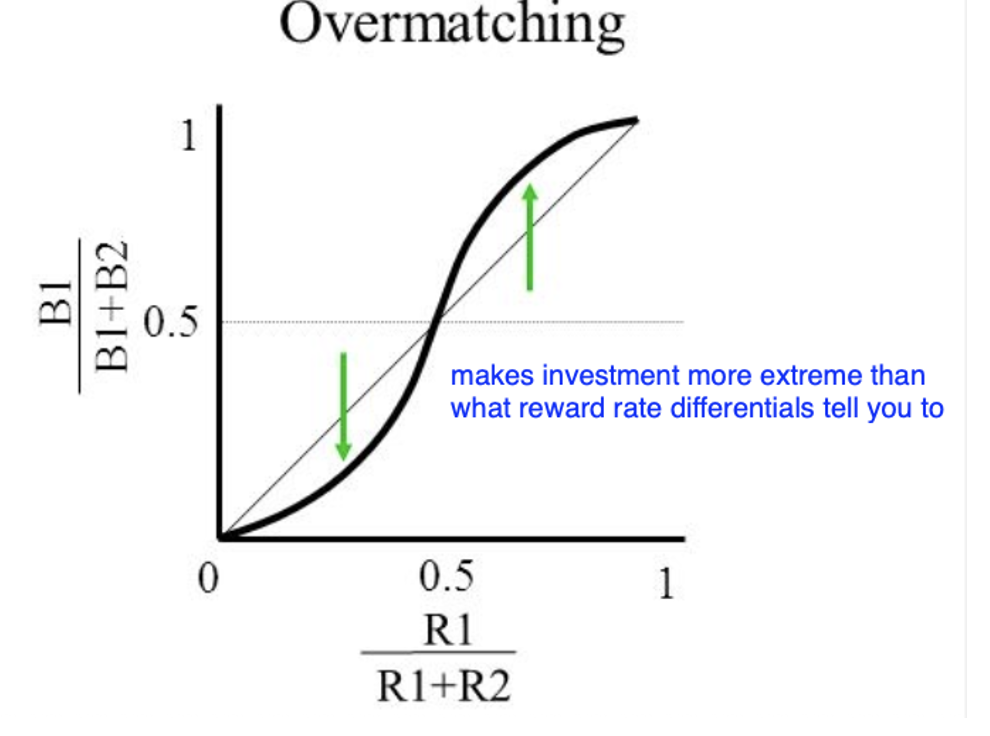
overmatching
a > 1.0: overmatching or over sensitivity to reward
invest everything on richer patch and ignore poor patch
- A preference that is more extreme than the equation would predict
- Organism is more sensitive than predicted to differences in reinforcer alternatives
Why undermatch?
• Reward sensitivity: discrimination or sensitivity model
- Tell us how sensitive the animal is to changes in the (rate) of reward between the two alternatives
- Can the animal tell the difference between changing reinforcement ratios
- Can the animal adapt its behavior as the reinforcement situation changes
- We can study a different circumstance and observe how the animal adjusts
Accuracy bias
invest more than you should to be accurate
• playing Mario, want to be really accurate, comes at cost of time, takes longer to make certain action. if human
• stays in a task long enough you become an optimal agent behaving in way that maximizing reward of task, this happens in noise investment as well
Intertemporal Choice (Delay Discounting)
• Often a matter of delaying immediate gratification (R+) in order to obtain a
greater reward (R+) later.
• Study or go to party?
difficulty for organisms to have long time horizon
Pigeon Intertemporal choice
- Choice A = immediate small reward
- Choice B = 4s Delay à large reward
• Direct choice procedure
- Pigeons choose immediate, small reward
• Concurrent-chain procedure
- Could learn to choose the larger reward
- Only if a long enough delay between initial choice and the next link
Value Discounting and Self-Control
idea that imposing a delay between a choice and the eventual outcomes
helps organisms make “better” (higher R+) outcomes, which works for people,
too.
• Longer one has to wait for a given reward, less exciting is the prospect of getting
the reward: The value of reinforcer is reduced by how long one has to wait for it.
- time serves as prospective cost of prospects
- longer the time interval, the more uncertainty is faced in nature, nothing is certain, if reward is available now might not be available tomorrow
- maybe berry isn’t ripe now but later will be gone so may choose to eat it now. always factors that paly into value discounting
Value Discounting function
• V - value of R+
• M- magnitude of R+
• D – delay of reward
• K (lambda) – discounting rate: is a correction factor for how much the animal is influenced
by the delay
• All this equation is saying is that the value of a reward is inversely affected by how long you have to wait to receive it.
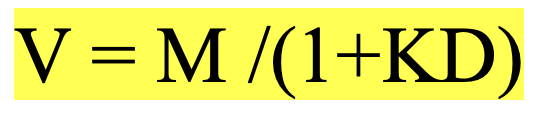
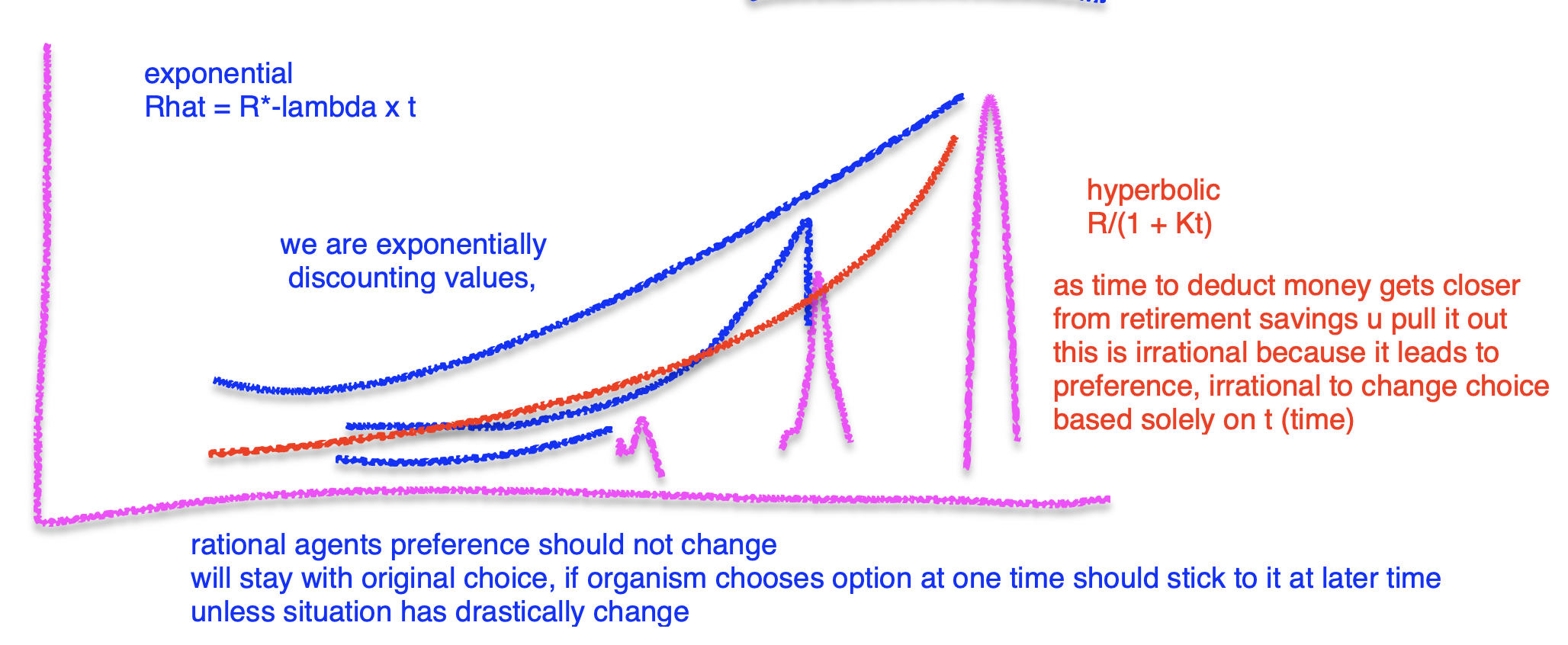
hyperbolic discounting
• exponential discount - rational option, what classical economics states to do
• hyperbolic discount is irrational, choice u switch to may be worse
- do people discount exponential or hyperbolic? turns out to be hyperbolic rate, animals seem to discount hyperbolically as well
can see crossover
• Because reward values decreases rapidly at first, given the delays involved at T1,
the value of the large reward is smaller than the value of the small reward: predicts preference reversals
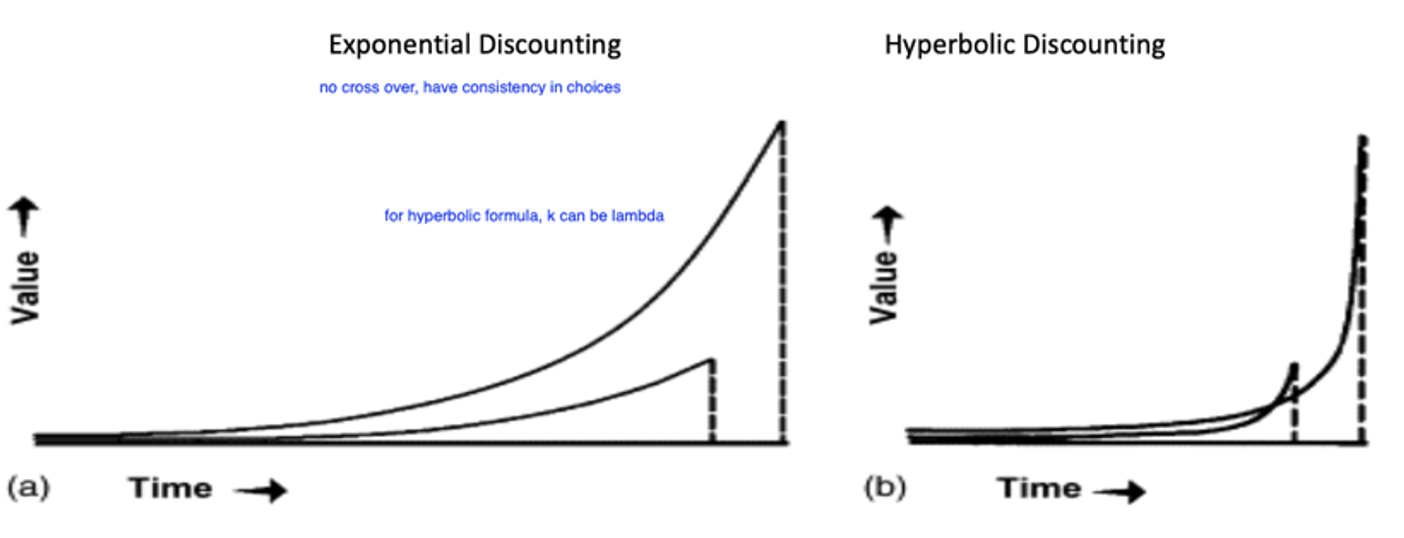
Hyperbolic vs. Exponential
see overlap in hyperbolic
no crossover iin exponential, consistent with choice
Temporal discounting and brain
• if you give choice to kids, they go for immediate (marshmallow example), discount rate is high for kids
• as we get older, discount rate seems to decrease, health of prefrontal cortex plays role in this
• if inhibit prefrontal cortex of rat more likely to choose immediate smaller reward
• Prefrontal cortex – deep thought, never make a decision under the influence
if inhibit prefrontal cortex, more likely to choose smaller reward