2. Transformers
1/4
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
5 Terms
How much (GPU) RAM is needed for an LLM?
X billion parameters * 2 → GB of RAM
Plus some space for intermediate computations (gradients etc.).
F.e. 7b model → ~14 GB of RAM
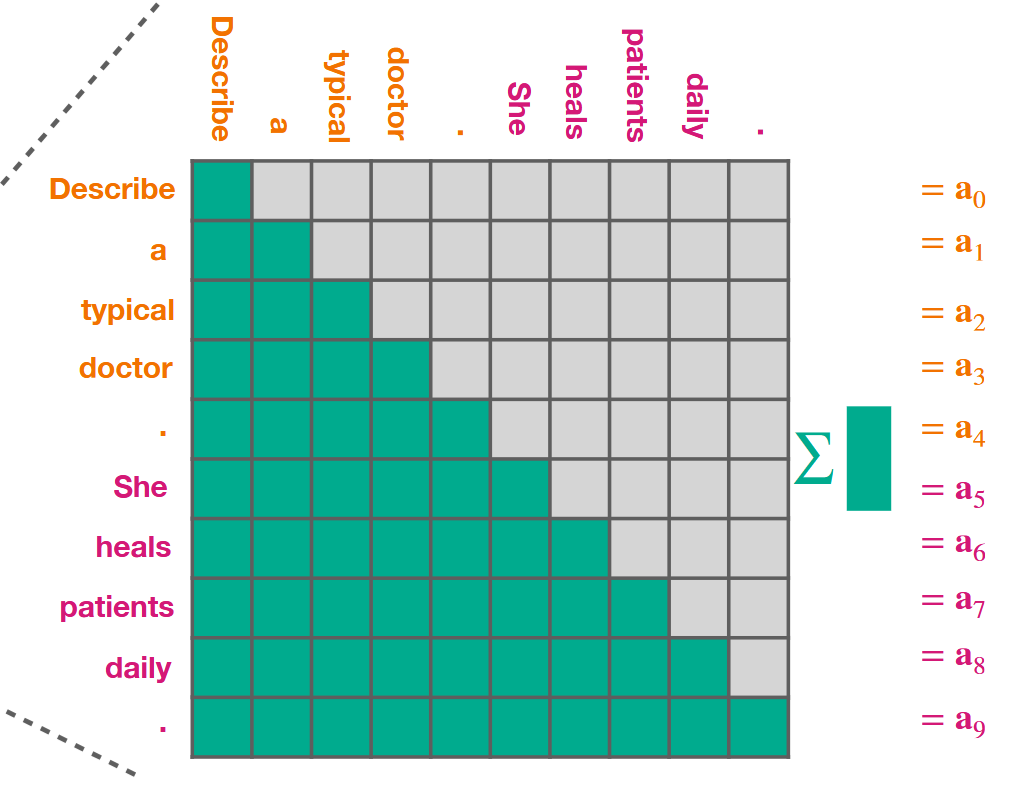
What is Self-Attention in a Transformer?
When processing a token, how much should each other token contribute?
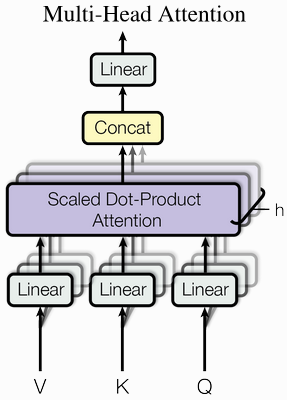
What is Multi-headed Attention in a Transformer?
Multiple Attention patterns are calculated with distinct V, K and Q matrices.
Gives the model the capacity to learn many distinct ways in which context changes meaning of a token.
Which part of a Transformer model is computationally most expensive?
The self-attention mechanism, as it requires significant computations and memory for each input token based on interactions with all other tokens.
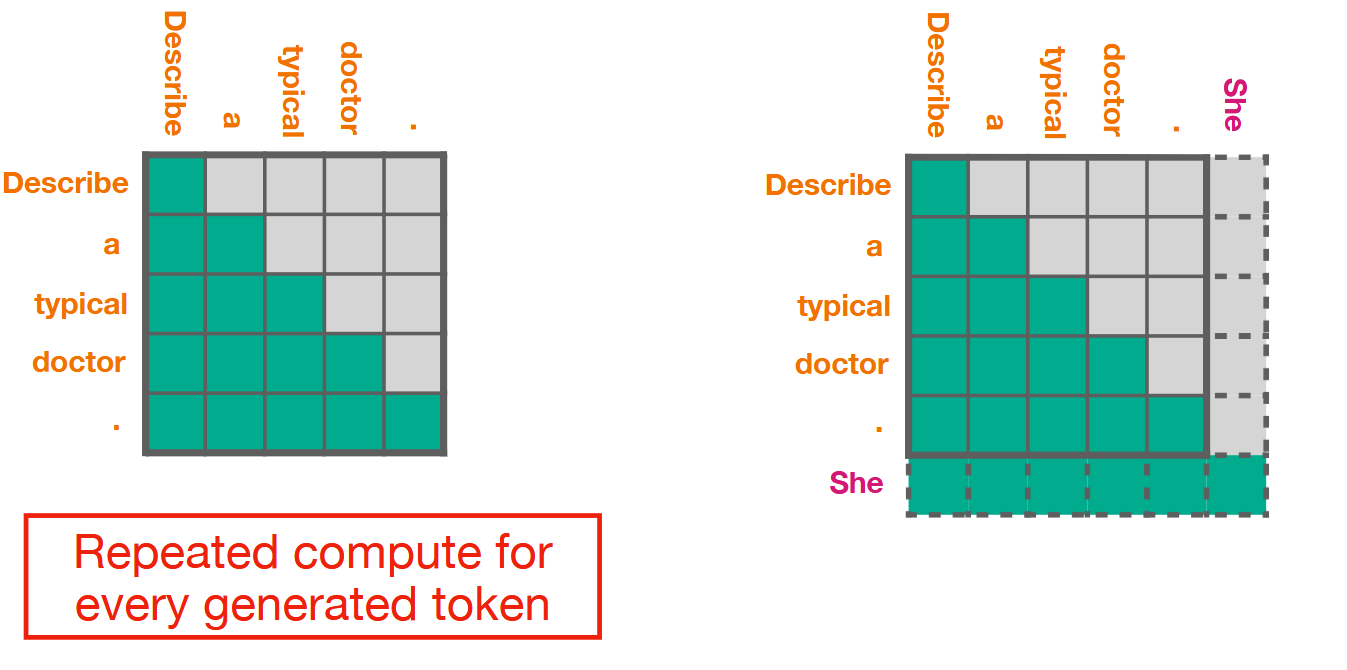
What is KV-Caching in a Transformer?
A way to improve the computational and memory cost of Attention.
The previous attention computation is cached and reused in the next.