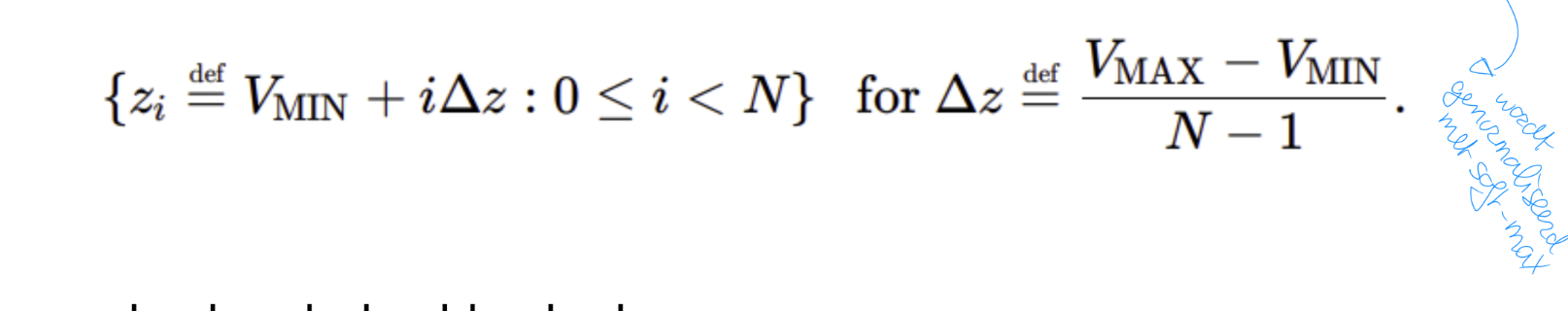H4: Deep-Q-learning (DQN)
1/20
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
21 Terms
Value function approximation
problem
solution
gevolg
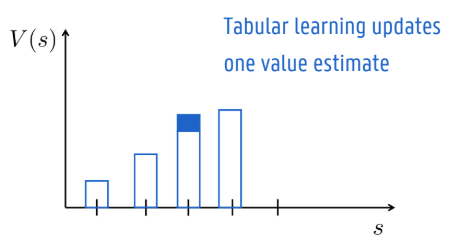
So far, we represented the value function by a lookup table
every state s has an entry V(s)
every state-action pair has an entry Q(s,a)
This introduces challenges when dealing with large state spaces:
very large memoryrequirements; or even intractable infinite-sized value tables
a lot of exploration needed to visit each (s,a) pair infinitely often
tabular Q-learning updates only one table element per time step
Solution:
use function approximation (e.g., a linear function, a parabolic function, a highly non-linear function)
Vθ(s)≃Vπ(s)
Qθ(s,a)≃Qπ(s,a)
-> θ verwijst naar feit dat het parameters gebruikt
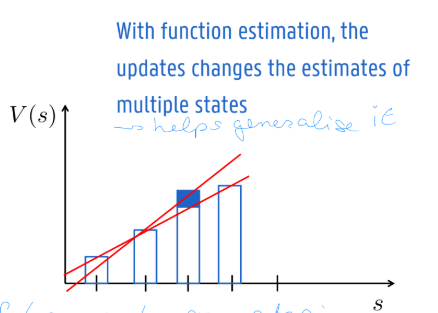
using function approximation, we can generalise from seen states to unseen states
Function Approximation enables Generalization
Value functions often have underlying relationships that agents can learn and exploit
Function approximators can discover these underlying relationships
what to optimize?
MSE loss in supervised learning: L(θ)=∑i=1N(yi−fθ(xi))^2
Our target is de optimale Q-functie: L(θ)=∑(s,a)(q∗(s,a)−Qθ(s,a))^2
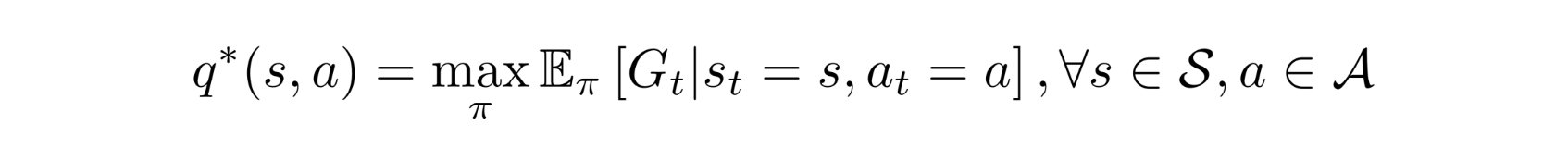
We do not know the optimal Q-function
We do not know the optimal policy to sample actions, we can only take random actions
-> Try GPI; but without convergence guarantees due to the use of function approximations
In tegenstelling tot supervised learning, waarbij een netwerk traint op een statische dataset met vaste labels, heeft Reinforcement Learning geen "ground truth" om de action-value functie Q(s,a) te optimaliseren.
• Het Doel: Het doel is om de optimale Q-functie (q∗) te benaderen, maar deze is onbekend.
• De Loss-functie: Er wordt gebruikgemaakt van de Mean Squared Error (MSE) loss. Omdat het werkelijke label ontbreekt, wordt de Bellman-vergelijking gebruikt om een schatting van de target te maken: r+γmaxa′Q(s′,a′).
semi-gradient
Een cruciaal wiskundig concept dat hier wordt geïntroduceerd, is de semi-gradiënt. Bij het berekenen van de gradiënt voor de gewichtsaanpassing (θ) negeren we de afhankelijkheid van de target van diezelfde θ. Dit wordt gedaan omdat het meenemen van de volledige gradiënt door de target heen de berekening extreem complex en onstabiel zou maken.
Neural-fitted Q-iteration
Neural Fitted Q-iteration (NFQ) is een algoritme dat een neuraal netwerk gebruikt als functie-approximator om de Q-functie te benaderen binnen een Q-learning raamwerk,. Het bouwt voort op werk rond stabiele functiebenadering en het gebruik van een replay-buffer.
Online Version:
De parameters van het netwerk worden onmiddellijk na elke stap bijgewerkt op basis van een enkel tuple (s,a,r,s′).

Batch Version:
Er wordt eerst een batch van ervaringen verzameld voordat een update plaatsvindt. Dit heeft als voordeel dat de variantie van de gradiënt wordt verlaagd, wat het leerproces stabieler maakt.

Batch updating reduces the variance of the gradient
2 problems leading to instable learning
1. Niet-i.i.d. data: In RL zijn opeenvolgende toestanden sterk gecorreleerd; de data zijn niet onafhankelijk en identiek verdeeld (niet i.i.d.), wat de aannames van de meeste optimalisatiemethoden schendt.
Samples are not independently distributed: sequential states are strongly correlated, even under e-greedy exploration
Samples are not identically distributed: the data generating process – our policy - is changing over time
2. Variabele Targets: Omdat de target wordt berekend met hetzelfde netwerk dat wordt getraind, verschuift het doel voortdurend wanneer de gewichten worden aangepast. Dit wordt omschreven als "het jagen op je eigen staart"
Solutions for both problems
Om deze problemen op te lossen, introduceert de overgang naar een robuustere Deep Q-Network (DQN)-architectuur twee technieken:
Experience Replay Buffer: Een geheugen waarin ervaringen uit het verleden worden opgeslagen en willekeurig worden gesampled om de correlatie tussen opeenvolgende stappen te verbreken.
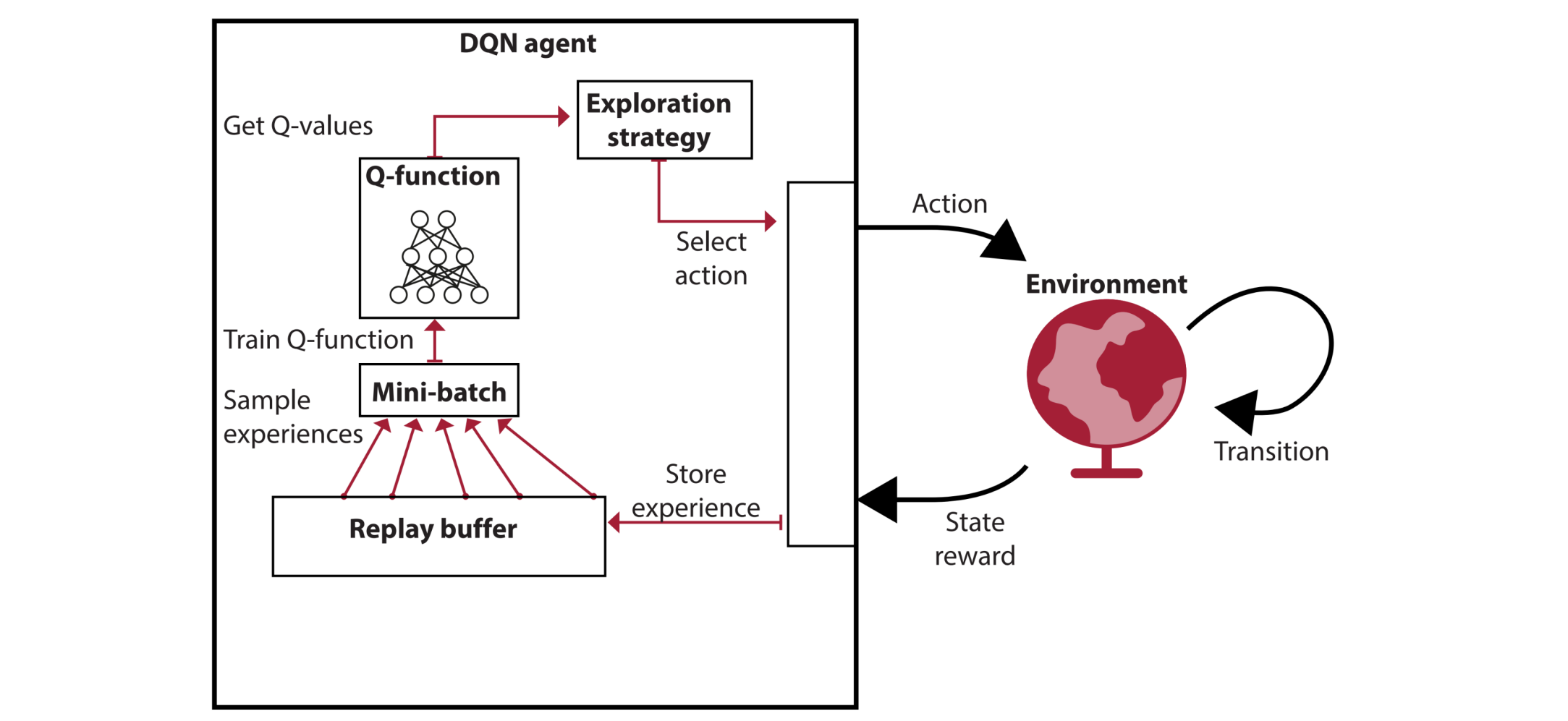
Target Network: Een kopie van het neurale netwerk die minder frequent wordt bijgewerkt om een stabielere target te bieden tijdens de gradiëntafdaling.
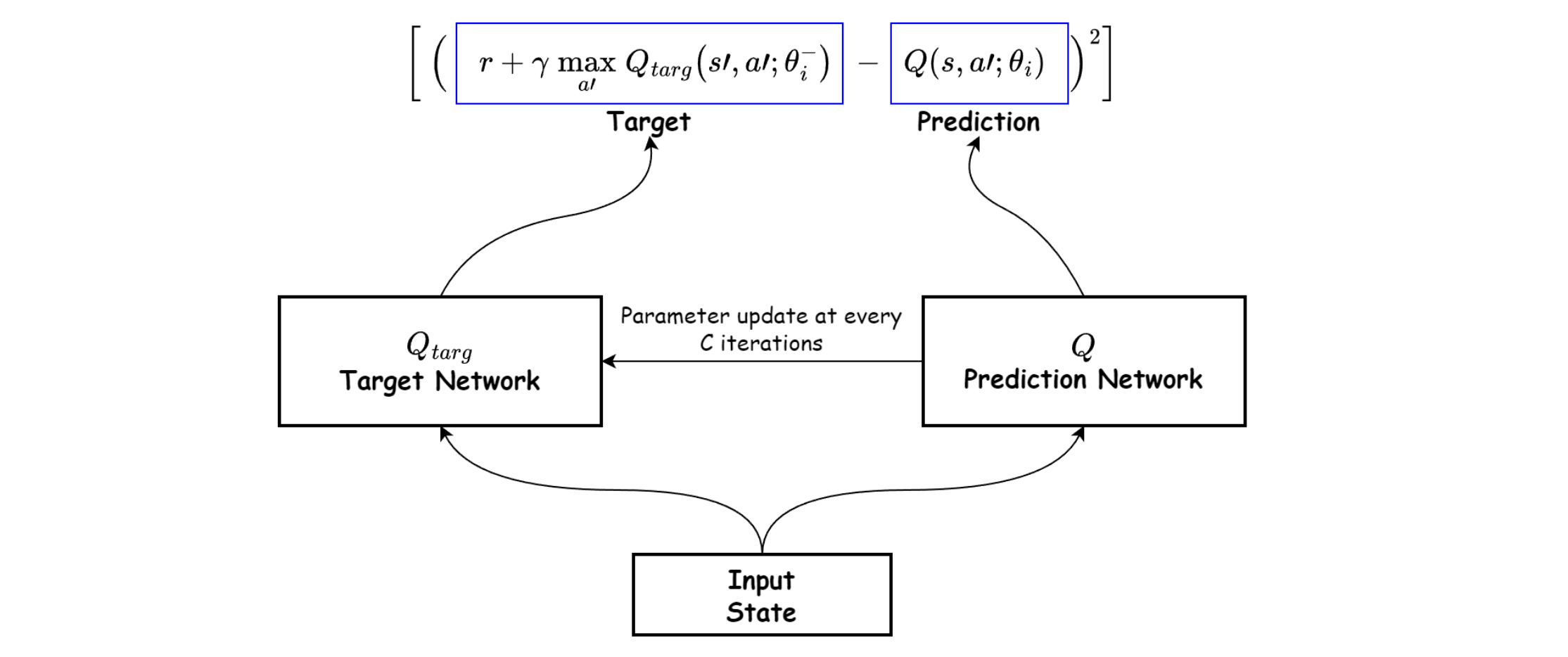
polyak averaging
Vanilla DQN updates target network every C steps θ−=θ
We calculate targets with progressively increasing stale data
After target update network, the whole landscape of the loss function changes
Polyak averaging: mix target network with tiny bit of the online network every step
θ−=τ⋅θ+(1−τ)⋅θ−
(met τ zeer klein)
Double deep Q learning
1. Het probleem: Maximization Bias
Zelfde probleem als bij gewone Q-learning
2. De oplossing: Ontkoppeling
Het basisconcept van Double Q-learning is om de selectie van een actie los te koppelen van de evaluatie van die actie,.
• In plaats van één vraag te stellen ("Wat is de waarde van de beste actie?"), stelt DDQN twee aparte vragen:
1. Welke actie is volgens mijn huidige kennis de beste? (Selectie).
2. Wat is de waarde van deze specifieke actie volgens een tweede, onafhankelijke bron? (Evaluatie).
3. Implementatie in Deep Q-Networks
Hoewel je in theorie vier aparte netwerken zou kunnen trainen, is dat in de praktijk te rekenintensief. Double Deep Q-Learning lost dit efficiënt op door gebruik te maken van de twee netwerken die al aanwezig zijn in de DQN-architectuur,:
Het huidige netwerk (θ): Dit netwerk wordt gebruikt om de actie met de hoogste waarde te kiezen via een
argmax-operatie,.Het Target Network (θ−): Dit netwerk, dat minder vaak wordt bijgewerkt, wordt vervolgens gebruikt om de waarde van die gekozen actie te schatten,,.
De wiskundige target voor de update in DDQN wordt hiermee: (bovenste versie)
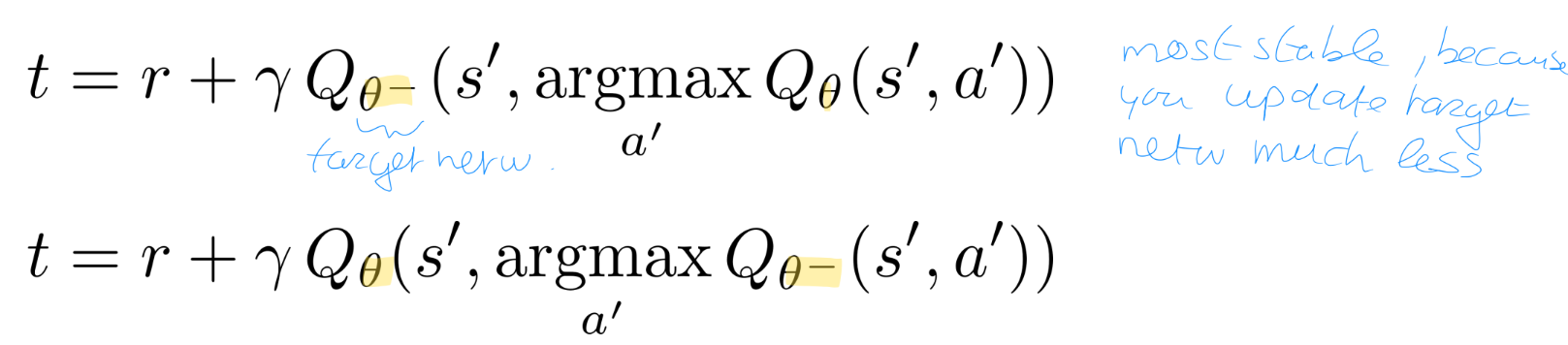
4. Waarom dit beter werkt
toevallige positieve uitschieters in de schattingen geneutraliseerd,.
stabieler leergedrag,
een betere convergentie
aanzienlijk hogere scores in complexe omgevingen zoals Atari-games,.
korte recap (grote lijnen opnoemen)

Dueling DQN: decomposing the Q function
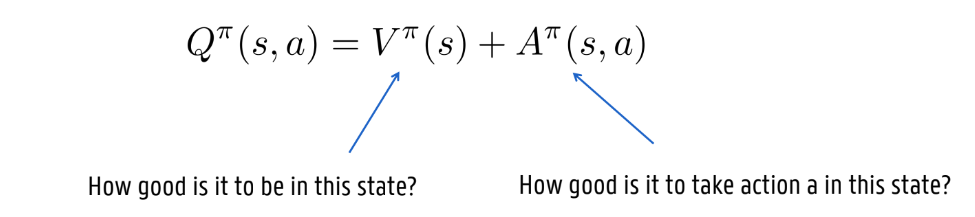
Q-values of the same state share information in the value function
in DQN, experience only updates one Q-value at a time
in many states, relative difference between Q-values of actions is tiny compared to absolute value of Q
small amounts of noise may lead to re-ordering of Q(s,a) → abrupt policy changes
small differences in advantages
-> In many states, the difference in Q-values is very small
State-Value functie V(s): Hoe goed is het om in een bepaalde toestand s te zijn? Dit is een scalaire waarde voor de toestand, ongeacht de actie,.
Advantage functie A(s,a): Wat is de relatieve meerwaarde (het voordeel) van het kiezen van actie a ten opzichte van andere acties in die specieke toestand s?,.
Dueling DQN: Why decoupling usefull
The dueling architecture can learn which states are (or are not) valuable without having to learn the effect of each action in that state.
This is useful in states where actions do not affect the environment in a relevant way.
A sample Q(s,a) helps also better estimating the Q-values of other actions in that state
Higher sample-efficiency
because V(s) shared by all actions in a state
more noise resistant
Dueling DQN: How to calculate Q?
Als je V en A simpelweg bij elkaar optelt, ontstaat er een wiskundig probleem: je kunt niet uniek bepalen welk deel van de Q-waarde uit V komt en welk deel uit A (het netwerk zou bijvoorbeeld V altijd op 0 kunnen houden),. Om dit op te lossen, dwingt men de advantage-stroom af om een gemiddelde van nul te hebben:
Q(s,a)=V(s)+(A(s,a)−∣A∣1a′∑A(s,a′))
Door het gemiddelde van alle advantages in die staat af te trekken, wordt de decompositie "identiceerbaar", wat het leerproces aanzienlijk stabiliseert,.
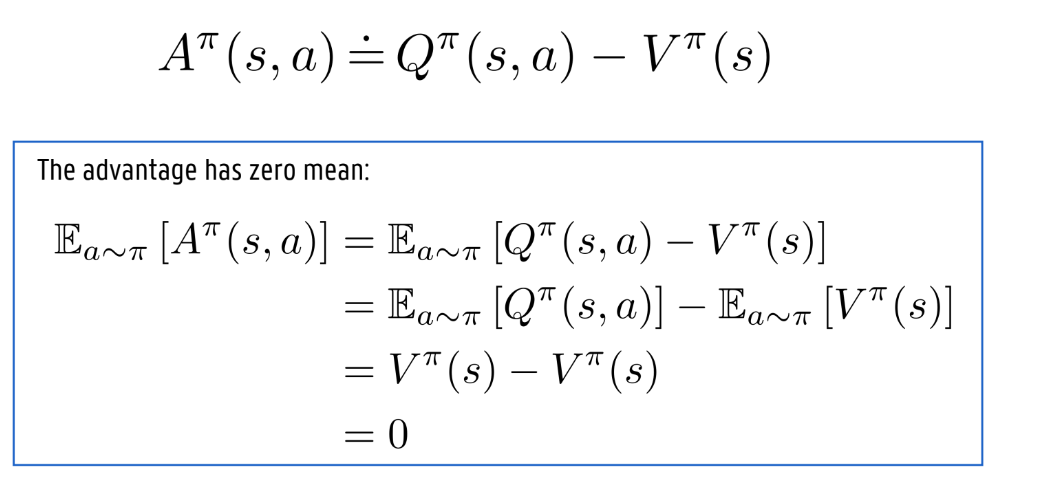
prioritized replay buffer: TD-error sampling
First idea:
Keep track of TD error per tuple in the replay buffer
Sampling tuples with the highest (absolute value) TD error
Prioritize sampling those tuples that give better learning progress
Priority of a tuple = magnitude of TD error
pi=∣δi∣=∣ri+maxaQθ−(si′,a)−Qθ(si,ai)∣
Drawbacks:
need to recalculate priorities of all samples in buffer after Q-network update
Solution:
only recalculate TD errors for the replayed batch
insert new samples with maximum priority (= assign them the max TD-error of samples already in the batch)
noisy nature of TD errors
TD errors have high variance, even more so when using neural networks
learning should not fixate on highest errors
What if a tuple has coincidentally a TD error of zero on its first replay?
Solution:
stochastic sampling from buffer
prioritized replay buffer: stochastic sampling

prioritized replay buffer: weighted importance sampling
Convergence of SGD is based on the idea that the batch composition follows the true underlying data distribution
-> Prioritized sampling introduces bias in the data
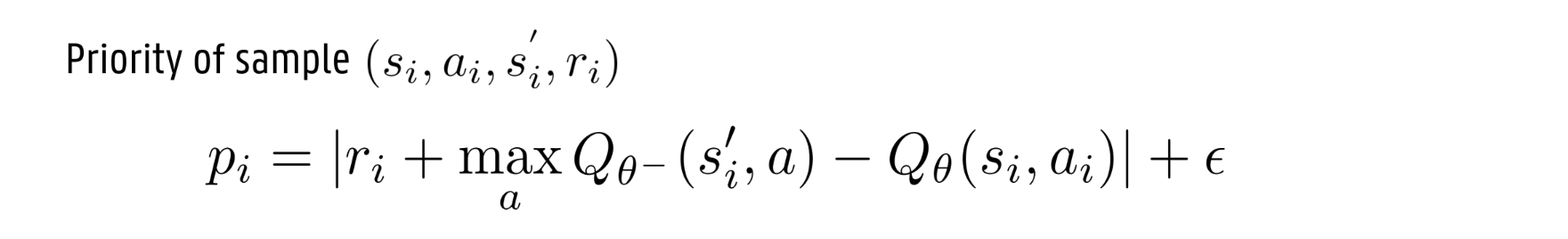
Correct bias by weighing the loss term for each sample
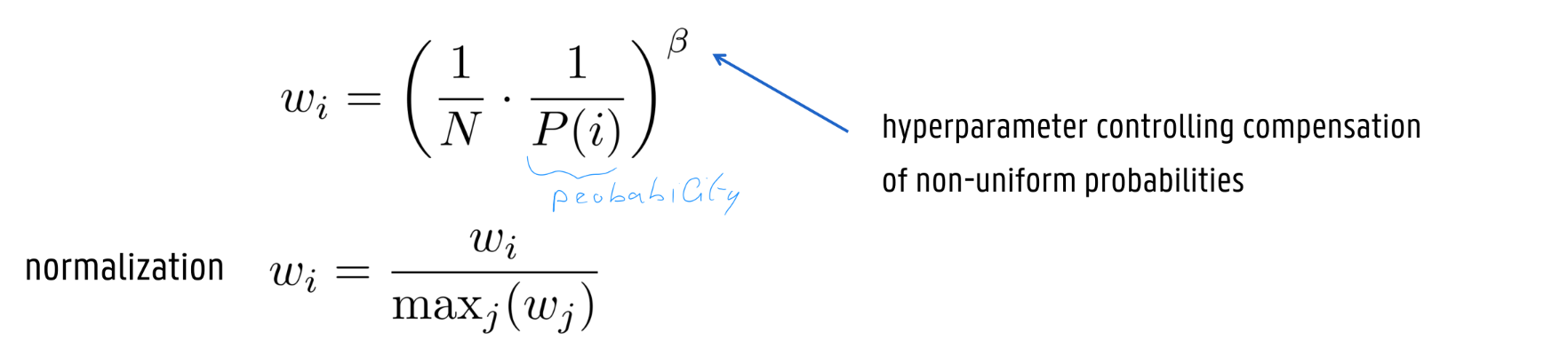
Gradient update with prioritized experience replay:
N-step DQN
wat + probleem
More sample efficient DQN
Correct unrolling from 1-step to 2-step DQN would be:
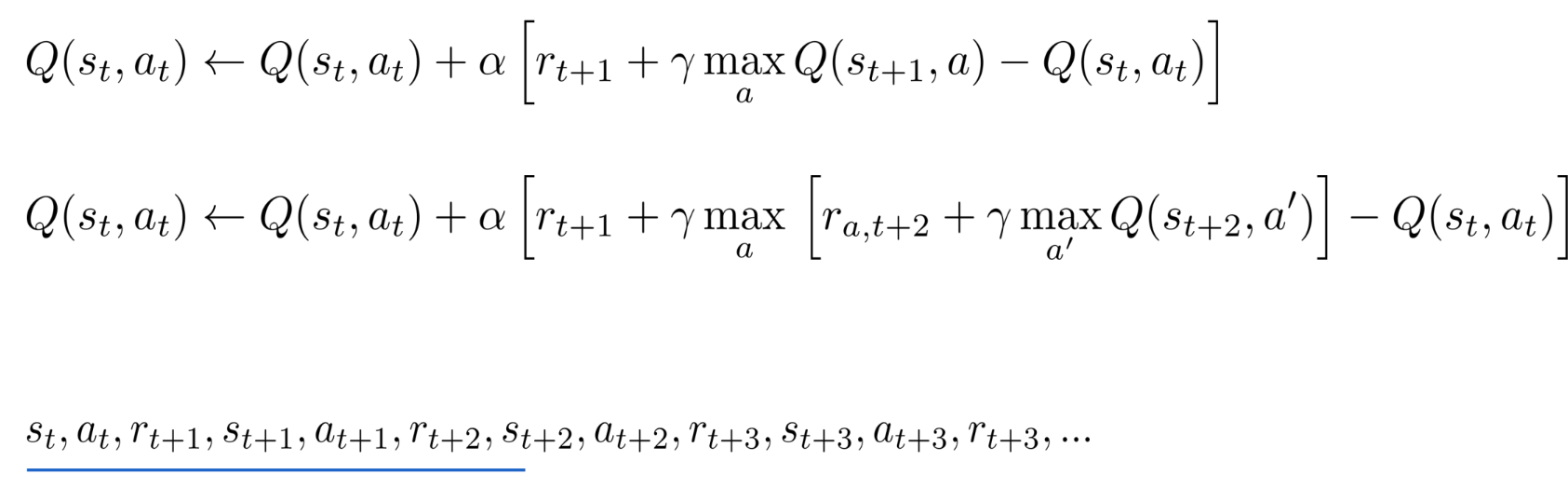
Problem:
We can only use our experience from our replay buffer if at+1 was the greedy action:
at+1=arg maxaQθ(st+1,a)
De Uitdaging: Off-policy Leren
DQN is een off-policy algoritme, wat betekent dat het leert van ervaringen in een replay buffer die zijn gegenereerd door een (oudere) policy. Dit zorgt voor een wiskundig probleem bij n-step updates:
• De n-staps update is eigenlijk alleen correct als de acties tussen stap t en t+n overeenkomen met de huidige optimale (greedy) policy.
• Als de agent in de replay buffer een actie heeft genomen die niet de actie is die de huidige policy zou kiezen, klopt de opgetelde beloning niet meer voor de huidige waarde-schatting.
N-step DQN: oplossingen
3 possible solutions:
Ignore the problem for small n – works surprisingly well!
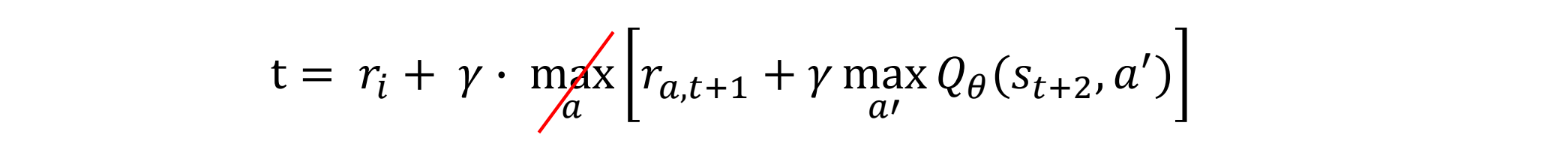
Cut the trace – dynamically choose n to get only on-policy data
Works well when data is mostly on-policy, and action space is small
Importance sampling
Weigh probability of state transitions under target and behavior policy
Noisy networks: idee
more sample efficient DQN
Idea: learnable exploration strategy
ϵϵ-greedy exploration introduces state-independent, decorrelated noise to the policy
NoisyNet: apply learned perturbations to the weights of the linear layers in the Q-network
a single change to the noise vector induces a consistent, state-dependent change in the policy at every time step
learnable: the network can learn which parts of the state space benefit more from exploration
In tegenstelling tot traditionele methoden zoals ϵ-greedy, die toestand-onafhankelijke ruis introduceren door simpelweg een willekeurige actie te kiezen, past NoisyNet geleerde verstoringen toe op de gewichten van de lineaire lagen in het Q-netwerk,.
• Toestand-afhankelijk: Een enkele verandering in de ruisvector zorgt voor een consistente verandering in de strategie die afhankelijk is van de huidige toestand.
• Leerbaar: Het netwerk kan via gradiëntafdaling (gradient descent) zelf leren welke delen van de toestandsruimte meer baat hebben bij exploratie,.
Noisy networks: forward pass
Sample transition from the replay buffer (si,ai,si′,ri)
Pass through the target network Qθ− and the current (online) network Qθ
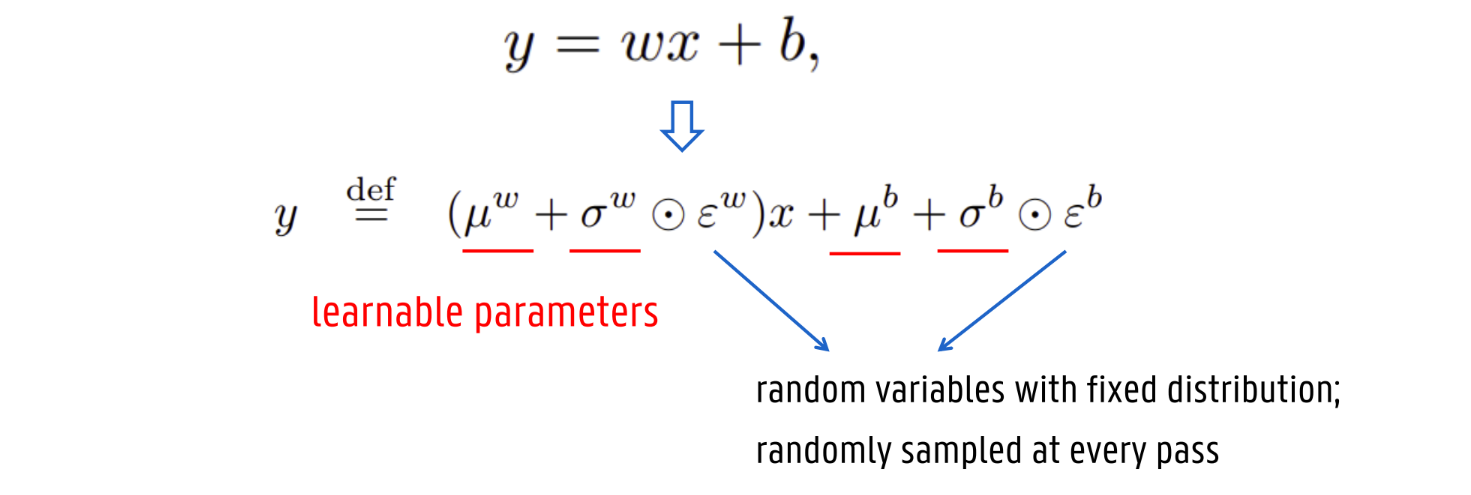
In the linear layers, the calculation changes:
Bij een standaard lineaire laag (y=wx+b) zijn de gewichten vast. In een NoisyNet-laag worden de gewichten en de bias vervangen door een combinatie van leerbare parameters (μ en σ) en een stochastische component (ϵ):
noisy networks + DQN
Wanneer Noisy Networks worden toegepast op DQN (Noisy DQN), zijn er enkele kleine verschillen in de uitvoering:
Geen ϵ-greedy nodig: De standaard exploratie-heuristieken worden vervangen door de ruis in het netwerk zelf.
The experience buffer is now filled with actions greedily selected from the (randomised) action-value function
Gradient through all parameters of the target and current network
Nieuwe loss functie
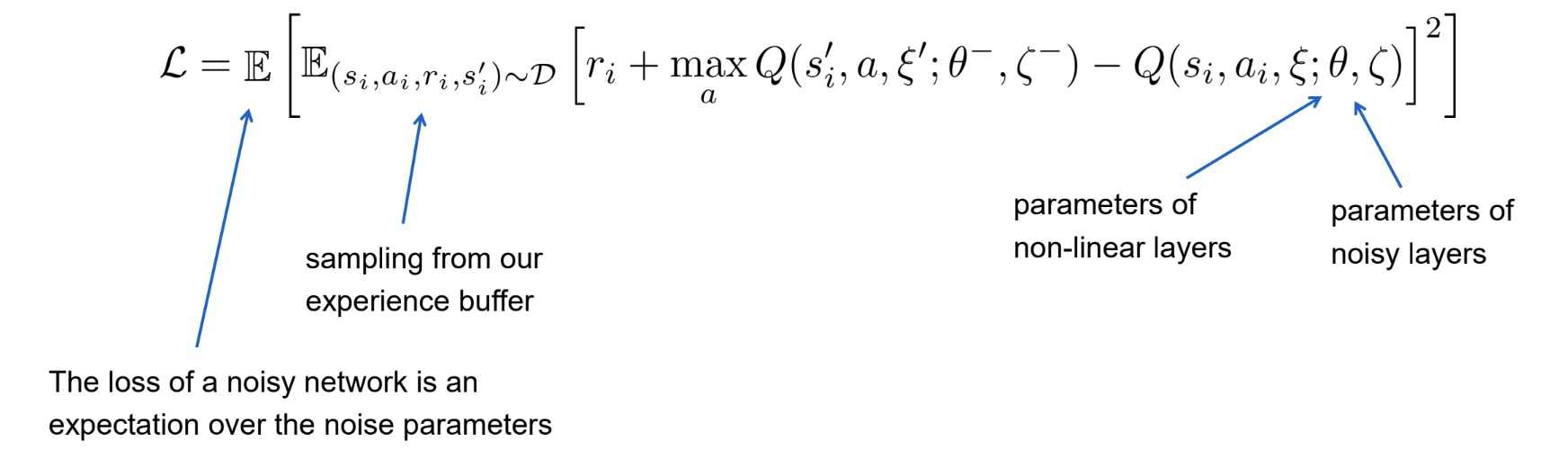
Distributional DQN
Distributional DQN is een geavanceerde variant van het DQN-algoritme die, in plaats van alleen de verwachte gemiddelde waarde (mean) van de toekomstige beloningen te schatten, de volledige waarschijnlijkheidsverdeling van de returns probeert te leren,.
Zπ(s,a)
It can be proven that this distribution, for a given transition, also satifies a Bellman recurrence:
Zπ(s,a)=r(s,a,s′)+γZπ(s′,a′)
Omdat een continue verdeling lastig te modelleren is met een neuraal netwerk, gebruikt Distributional DQN vaak een categorische distributie,:
De mogelijke waarden van de return worden verdeeld over een vast aantal atomen (bins), gelijkmatig verspreid tussen een minimumwaarde (VMIN) en een maximumwaarde (VMAX).
Het neuraal netwerk voorspelt voor elke actie de waarschijnlijkheidsmassa (de kans) voor elk van deze atomen.