stats 3
1/63
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
64 Terms
fit of the model
The degree to which a statistical model represents the data collected
outcomei=(model)+errori
the data we observe can be predicted from the model we choose to fit plus some amount of error
parameter p
are not measured and are (usually) constants believed to represent some fundamental truth about the relations between variables in the mode
variables
are measured constructs that vary across entities in the sample
the mean
is a hypothetical value: it is a model created to summarize the data and there will be error in prediction
error/deviance
he score predicted by the model for that entity subtracted from the corresponding observed score.
standard deviation
tells us about how well the mean represents the sample data
sampling distribution
is the frequency distribution of sample means (or whatever parameter you’re trying to estimate) from the same population
standard error of the mean (SE)/ standard error
tells us how widely sample means spread around the population mean
central limit theorem
as samples get large (usually defined as greater than 30), the sampling distribution has a normal distribution with a mean equal to the population mean
confidence intervals
boundaries within which we believe the population value will fall
t-distribution
is a family of probability distributions that change shape as the sample size gets bigger (when the sample is very big, it has the shape of a normal distribution)
5% threshold
only when there is a 5% chance (or 0.05 probability) of getting the result we have (or one more extreme) if no effect exists are we confident enough to accept that the effect is genuine
alpha (α)
the long-run error rate that you are prepared to accept
the probability of accepting an effect in our population as true, when no such effect exists
systematic variation
ariation that can be explained by the model that we’ve fitted to the data (and, therefore, due to the hypothesis that we’re testing).
unsystematic variation
variation that cannot be explained by the model that we’ve fitted. In other words, it is error, or variation not attributable to the effect we’re investigating.
test statistic
The ratio of effect relative to error
significant test statistic
tells us that the model would be unlikely to fit this well if the there was no effect in the population
type 1 error
occurs when we believe that there is a genuine effect in our population, when in fact there isn’t
type 2 error
occurs when we believe that there is no effect in the population when, in reality, there is
familywise or experiment-wise error rate
error rate across statistical tests conducted on the same data
Bonferroni correction
divide α by the number of comparisons, k, to control for familywise error rate
moderator variable
affects the relationship between two others
centering
refers to the process of transforming a variable into deviations around a fixed point
mediation
refers to a situation when the relationship between a predictor variable and an outcome variable can be explained by their relationship to a third variable
the four conditions of mediation
1. the predictor variable must significantly predict the outcome variable in model 1
2. the predictor variable must significantly predict the mediator in model 2
3. the mediator must significantly predict the outcome variable in model 3
4. the predictor variable must predict the outcome variable less strongly in model 3 than in model 1.
three linear model of mediation
1. A linear model predicting the outcome from the predictor variable. The b value coefficient for the predictor gives us the value of c
2. A linear model predicting the mediator from the predictor variable. The b value for the predictor gives us the value of a
3. A linear model predicting the outcome from both the predictor variable and the mediator. The b-value for the predictor gives us the value of c’ and the b-value for the mediator gives us the value of b
Sobel test
assesses the significance of the indirect effect
index of mediation
standardized indirect effect
dummy variable
is a way of representing groups of people using only zeros and ones
direct effect
the effect of the predictor independent of the mediator
indirect effect
the effect of the predictor through the mediator
p-hacking
testing multiple hypotheses but only reporting the significant ones
HARKing
formulating or modifying hypotheses after data have already been analyzed to make the results seem predicted and theoretically sound
rules for residuals
having a standardized residual greater then 3.24 (3)
more than 1% of the sample has a standardized residual above 2.58 (2.5)
more than 5% of the sample have a residual above 1.96 (2)
cooks distance
can be thought of as a general measure of influence of a point on the values of the regression coefficients
greater than 1 may be cause for concern
point with high leverage
An observation with an outlying value on a predictor variable
can have a large effect on the estimate of regression coefficients
greater than 3 x ((k+1)/n) or 2 x ((k+1)/n)
Mahalanobis distance
indicates the distance of cases from the means of the predictor variables
influential cases have values above 25 in large samples (500), above 15 in smaller samples (100), and above 11 in small samples (30)
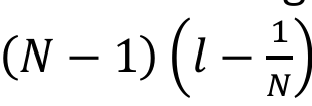
detecting multicollinearity
1. correlations between predictors (!) higher than .80 or .90
2. VIF of a predictor >10
3. tolerance of a predictor <.10
ways of bias entering
parameter estimates
standard errors and confidence intervals
test statistics and p-values
outlier
score very different from the rest of the data
assumption
is a condition that ensures that what you’re attempting to do works
main assumptions
additivity and linearity
normality of something or other
homoscedasticity/homogeneity of variance
independence
additivity and linearity
means that the relationship between the outcome variable and predictors is accurately described by the equation of the linear model
central limit theorem
egardless of the shape of the population, parameters estimates of that population will have a normal distribution provided the samples are ‘big enough’
should have at least 30
impact of homoscedasticity
parameters
null hypothesis significance testing
homoscedasticity/homogeneity of variance
In designs in which you test groups of cases this assumption means that these groups come from populations with the same variance. In correlational designs, this assumption meansia that the variance of the outcome variable should be stable at all levels of the predictor variable.
Independence
the errors in your model are not related to each other
z-scores for outliers
in a normal distribution we’d expect about 5% to be greater than 1.96 (we often use 2 for convenience), 1% to have absolute values greater than 2.58, and none to be greater than about 3.29
skewness
positive values indicate a pile-up on the left of the distribution
negative values indicate a pile-up on the right
kurtosis
positive values indicate a heavy-tailed distribution
negative scores indicate a light-tailed distribution
the further away from zero the less likely that its normally distributed
Levenes test
tests the null hypothesis that the variances in different groups are equal
Levene’s test is significant at p ≤ 0.05 then people tend to conclude that the null hypothesis is incorrect and that the variances are significantly different therefore, the assumption of homogeneity of variances has been violated
Kolmogorov–Smirnov test/ Shapiro–Wilk test
compare the scores in the sample to a normally distributed set of scores with the same mean and standard deviation.
If the test is non-significant (p > 0.05) it tells us that the distribution of the sample is not significantly different from a normal distribution
Q-Q plot
kurtosis is shown up by the dots sagging above or below the line,
skew is shown up by the dots snaking around the line in an ‘S’ shape.
TWAT
trim the data
winsorizing
apply a robust estimation method
transform the data
trimming the data
means deleting some scores from the extremes
should be done only if you have good reason to believe that this case is not from the population that you intended to sample
percentage based rule
would be, for example, deleting the 10% of highest and lowest scores
trimmed mean
calculate the mean in a sample that has been trimmed
standard deviation based rule
involves calculating the mean and standard deviation of a set of scores, and then removing values that are a certain number of standard deviations greater than the mean
Winsorizing
involves replacing outliers with the next highest score that is not an outlier
Robust methods
non-parametric tests that do not rely on the assumption of normality
bootstrap
the sample data are treated as a population from which smaller samples (called bootstrap samples) are taken (putting each score back before a new one is drawn from the sample). The parameter of interest (e.g., the mean) is calculated in each bootstrap sample
transforming data
you do something to every score to correct for distributional problems, outliers, lack of linearity or unequal variances
if you are looking at relationships between variables you can transform only the problematic variable, but if you are looking at differences between variables (e.g., changes in a variable over time) you must transform all the relevant variables.