H7: Ensembles
1/10
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
11 Terms
ensembles
wat
3 soorten
Combineren van vele zwakke modellen in 1 sterk model
2 cruciale stappen:
zorg dat alle modellen verschillende dingen leren
combineer individuele voorspellingen
Voting: Train modellen op light verschillende datasets en combineer ze door gebruik te maken van middeling (averaging) of stemmen.
Boosting: Train modellen die de voorspellingen van vorige modellen verbeteren
Stacking: Train een model dat voorspellingen van andere modellen gebruikt als input.
voting classifiers
4 soorten
Train verschillende modellen op verschillende versies van de data.
Bagging: sample van de dataset met vervanging (replacement)
Pasting: sample zonder vervanging (replacement)
Random subspaces: gebruik verschillende subsets van de features
Random patches: selecteer zowel random datapunten als random feature subsets.
Meestal zijn de verschillende modellen van hetzelfde type (vb decision tree).
bagging vs pasting
Bagging: sample van de dataset met vervanging (replacement)
Pasting: sample zonder vervanging (replacement)
Voor beide methoden kunnen training samples meerdere keren gesampled worden voor verschillende modellen.
Met Bagging kunnen samples zelfs meerdere keren gesampled worden voor hetzelfde model.

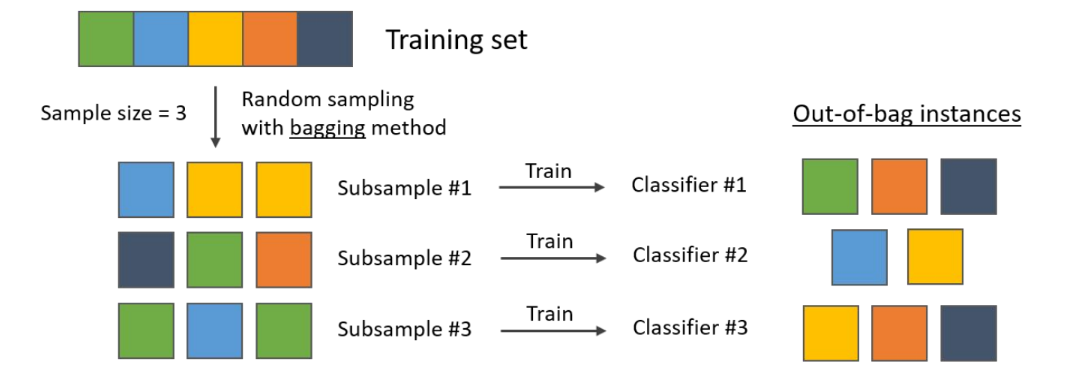
out-of-bag samples
De training instanties die niet gesampled werden om een bepaald model te trainen.
Elke instantie in de training set zal een out-of-bag sample zijn voor meerdere modellen.
out-of-bag evaluation
Het Concept Out-of-Bag evaluatie is een manier om te meten hoe goed een Bagging-ensemble (zoals een Random Forest) presteert, zonder dat je een aparte test- of validatieset opzij hoeft te zetten.
Hoe het werkt (Stap voor Stap)
1. Het ontstaan van "Out-of-Bag" data: Bij Bagging traint elk individueel model (bijvoorbeeld elke boom in het bos) op een random selectie van de data, getrokken met teruglegging. Wiskundig gezien betekent dit dat elk model gemiddeld slechts 63% van de unieke trainingsdata ziet. De overige 37% die niet in de training van dat specifieke model zat, noemen we de Out-of-Bag (OOB) samples voor dat model.
2. De Evaluatie (De "Gratis" Test): Omdat elk model bepaalde datapunten niet heeft gezien tijdens het trainen, kunnen we die punten gebruiken als een eerlijke test voor dat model.
◦ Voor elk datapunt in je originele dataset zoek je alle bomen die niet op dit punt getraind zijn.
◦ Je laat enkel die bomen stemmen (voting) om een voorspelling te maken voor dat punt.
◦ Je vergelijkt de voorspelling met de werkelijkheid om de fout te berekenen.
Samengevat Je test het model eigenlijk op de "restjes" data die de individuele bomen toevallig niet hebben gezien tijdens het leren. Hierdoor krijg je een betrouwbare schatting van de generalisatie-fout zonder dat je kostbare data hoeft te verliezen aan een validatieset
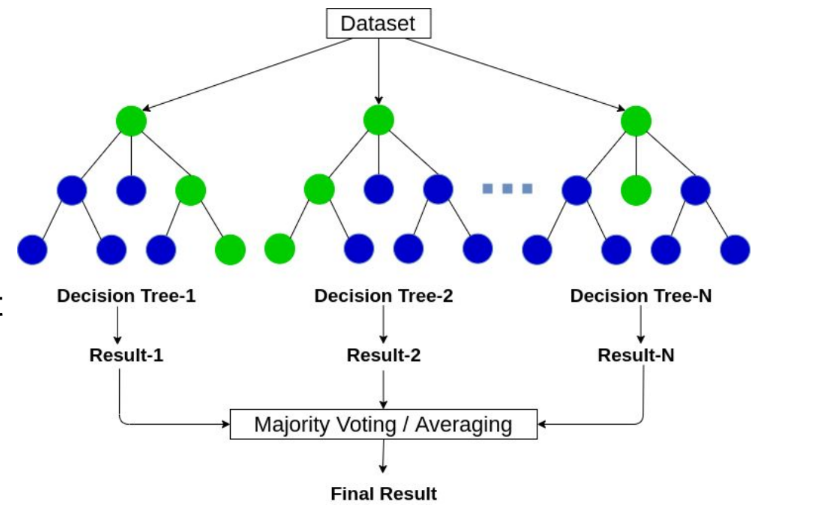
Random Forests
= Ensemble van beslissingsbomen getraind met bagging
Kan gebruikt worden voor classificatie en regressie
"Random"
elke boom is getraind op een random subset van de data
Op elk level, nemen we een random subset van de features en berekenen we de beste split van deze subset
Extra bomen: Gebruik een random threshold om nog meer diversiteit toe te voegen aan de bomen.
Boosting
2 soorten
Train verschillende modellen die elk anders fouten corrigeren.
Adaboost:
train een sequentie van modellen waar elk volgend model meer focust op de datapunten die de vorige modellen niet accuraat konden voorspellen
Gradient boost:
Train een model om de error (residual) te voorspellen van de vorige modellen.
Integenstelling tot voting, is de training van deze modellen sequentieel en kan ze niet in parallel worden uitgevoerd.
Adaboost (principe)
Elk sequentieel model is getraint om meer te focussen op de samples waarvoor voorspelling van vorige modellen fout waren
2 types van gewichten
Instance weight w(i): gewicht van elk sample
Predictor weight α(i): gewicht van elk model
Het instantie gewicht wordt gebruikt om meer te focussen op samples die misgeclassificeerd waren door de vorige modellen.
Het predictor gewicht wordt gebruikt om de finale predictie te berekenen.
gradient boost
Sequentiele aanpak, net zoals Adaboost
De volgende predictor probeert de residual error te voorspellen gemaakt door de vorige predictor
De finale output is de som van de voorspellingen van de individuele modellen.
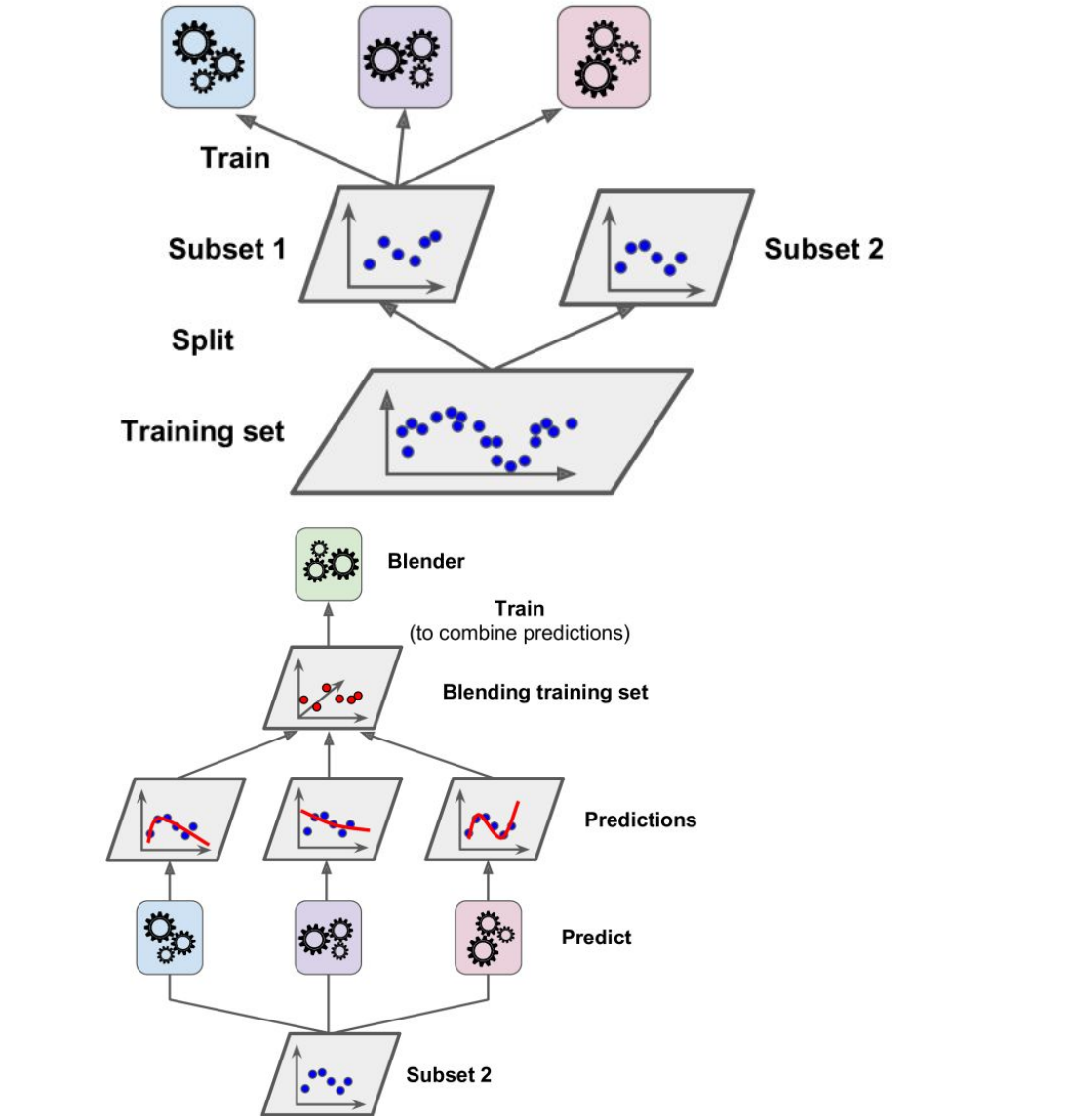
Stacking
Train een model om voorspellingen van andere modellen te combineren.
Splits de train set in 2
Train verschillende modellen op het eerste deel
Extract de voorspellingen van de modellen voor het tweede deel = Blending data set
Train een model op de voorspellingen van de eerste modellen.
Samenvatting
Ensembles combineren meerdere zwakke modellen in 1 sterk model
2 cruciale stappen
Zorg dat alle modellen verschillende dingen leren
combineer individuele voorspellingen
3 manieren om te combineren
Voting: Train modellen op licht verschillende datasets en combineer ze door gebruik te maken van averaging of voting
bagging: sample training data met vervanging
pasting: sample training data zonder vervanging
random subspaces: gebruik verschillende subsets van features
random patches: gebruik zowel random geselecteerde samples en features
Boosting: Train modellen die de voorspellingen van vorige modellen verbeteren
Adaboost: elk sequentieel model focust meer op de datapunten die verkeerde voorspellingen hadden bij vorige modellen
Gradient Boost: elk sequentieel model probeert de residuele error te voorspellen van de vorige modellen.
Stacking: Train een model dat voorspellingen van andere modellen gebruikt als input