REMOTE SENSING MIDTERM UNIT 5
1/14
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
15 Terms
Hard vs Fuzzy Classification
Hard Classification: One possible end product of remote sensing imagery is a discrete class for each pixel in an image.
Fuzzy Classification: A similar goal is to determine the % composition of classes within each pixel (since most pixels are mixtures of materials)
output of classification
nominal variable
T/F If two classes have identical reference training state variables, they can not be distinguished using RS data alone
TRUE
Three types of classification
Unsupervised
Supervised
Hybrid
Supervised Classification
Requires “training pixels”, pixels where both the spectral values and the class is known.
Analyst specifies certain “known” areas in the image, and statistics about the DNs in these areas are used to categorize the entire scene
This is referred to as the “training” stage
Unsupervised Classification
No extraneous data is used: classes are determined purely on difference in spectral values.
No training stage, pixels are run through an iterative clustering algorithm, and “similar” groups of pixels are classified thematically
4 Supervised Classification types
Non-Parametric
Minimum distance
Parallelpiped
Nearest-Neighbor Classifiers
Parametric
Gaussian Maximum Likelihood
Minimum Distance Classifier
Concept: Measures the Euclidean distance between an unknown pixel and the mean (centroid) of each training class.
Decision Rule: The pixel is assigned to the class with the closest mean.
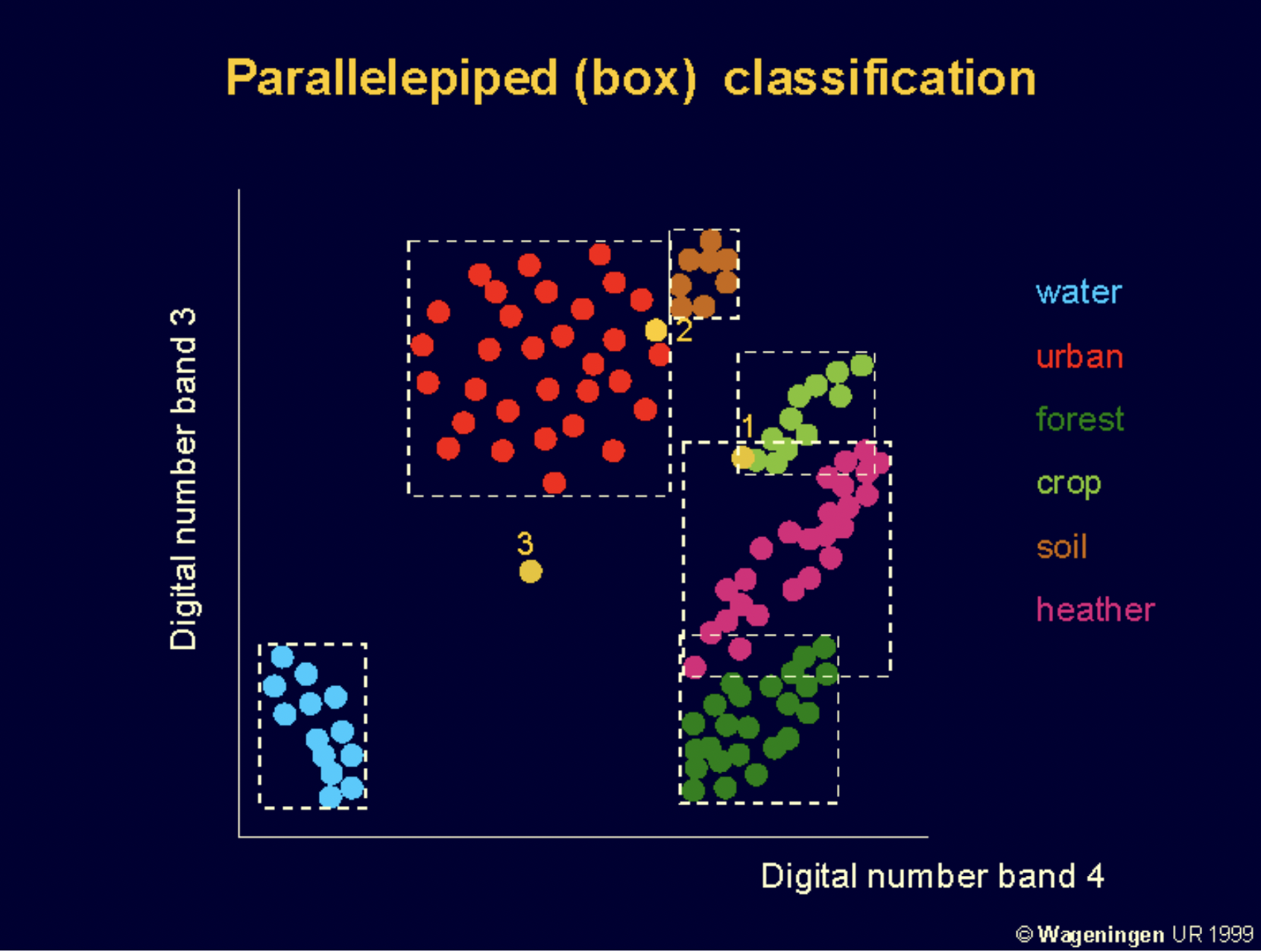
Parallelepiped Classifier
Creates a box-shaped decision boundary using min-max values from training samples for each band. If a pixel falls within the box, it is assigned to that class. If it falls in multiple boxes, it remains unclassified or is assigned based on a rule (e.g., closest mean).
Nearest-Neighbor Classifier
To classify an unknown pixel into m classes, the classifier computes the Euclidean distance of the pixel to be classified to the nearest training data pixel.
It could use a majority rule, “the nearest group of pixels”
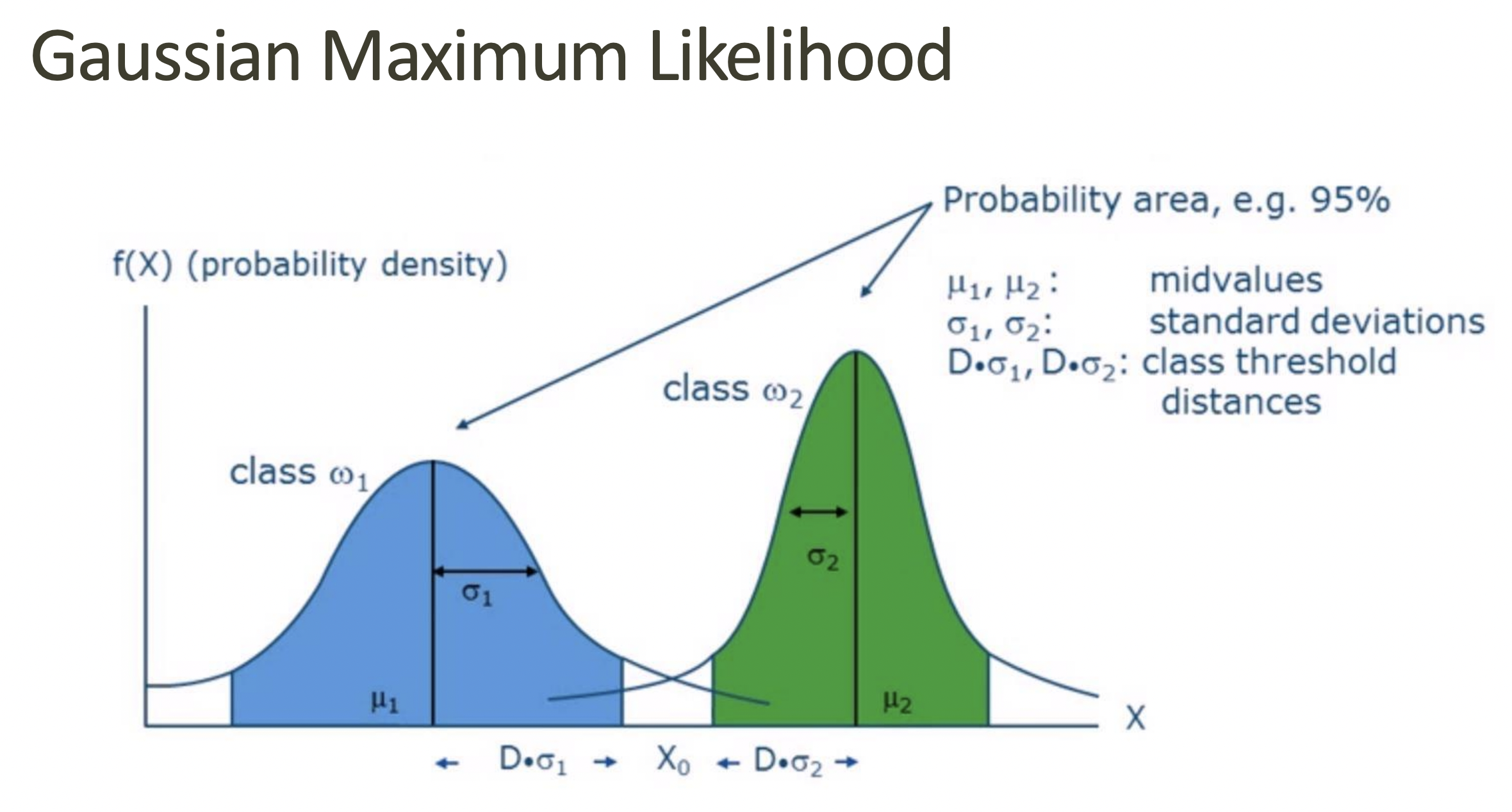
Gaussian Maximum Likelihood Classifier (MLC)
Assumes each class follows a Gaussian (normal) distribution and assigns a pixel based on the highest probability (likelihood) of belonging to a class.
Benefits: Takes into account variance and covariance
Downsides: computationally expensive, assumed normal distribution for classes
When to use each supervised classification type
Use Minimum Distance and Parallelepiped for fast classification but only when class boundaries are well-defined.
Use Nearest-Neighbor (k-NN) if class distributions are complex and not Gaussian.
Use Maximum Likelihood (MLC) for the highest accuracy when you have large training samples and Gaussian-distributed data.
Chain method
Program reads the data and builds clusters.
A minimum distance to mean approach is used to associate each pixel to a cluster
K-means
1) Initial mean (seed) specified for K clusters.
2) Pixels closest to this mean are assign to each cluster
3) Reiteration (migration of pixels)
sources of variability that influence classification accuracy (4)
Sensor-Related Variability (low spatial resolution, few bands, low radiometric resolution (bits) → less info = less accurate categories
Environmental conditions ie cloud cover, shadows from topographic features
Training Data: misclassification, not enough training data, similar spectral responses (building v dry soil)
Model Choosing a parametric model for non parametric data