5-2: deep learning & algorithms in unsupervised learning
1/14
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
15 Terms
ANN (artificial neural network)
inspired by biological processes scientists were able to observe in the brain
perceptron vs neuron
inputs vs dendrites
nodes vs nucleus
signals vs electrical impulses
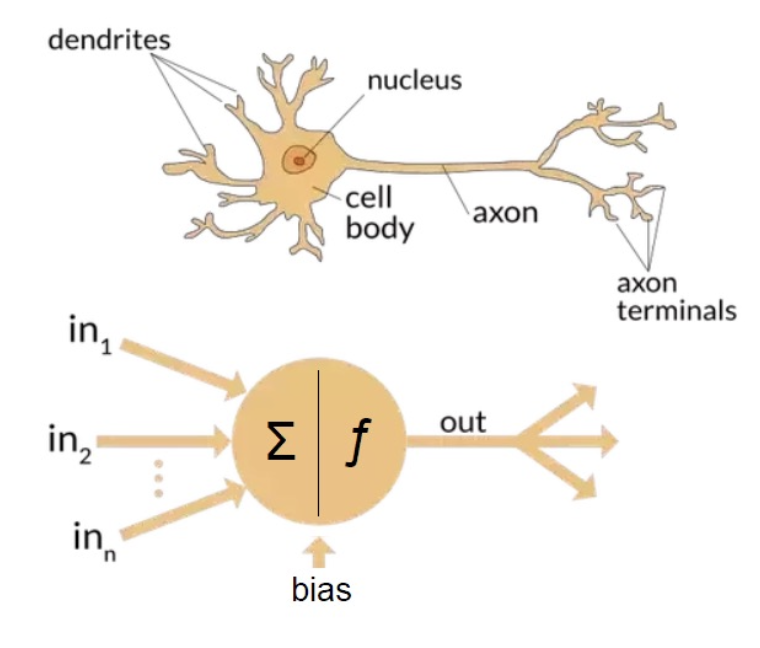
simplest ANN: perception (single neuron)
receives inputs
applies weights to these inputs
sums the weighted inputs
passes the sum through an activation function
produces an output
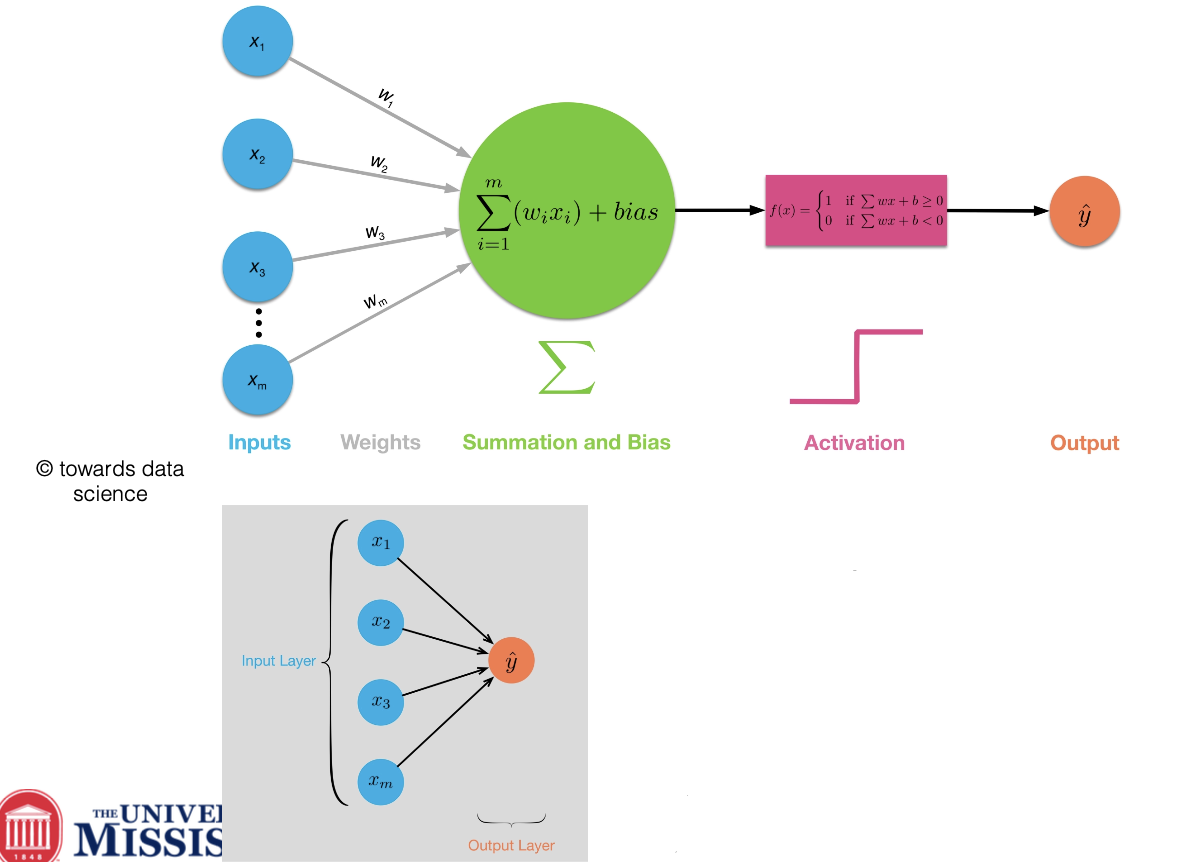
multi-layer perceptron for non-linear classification
complex non-linear function can be learned as a composition of simple processing units
at least one hidden layer can solve any type of non-linear classification task
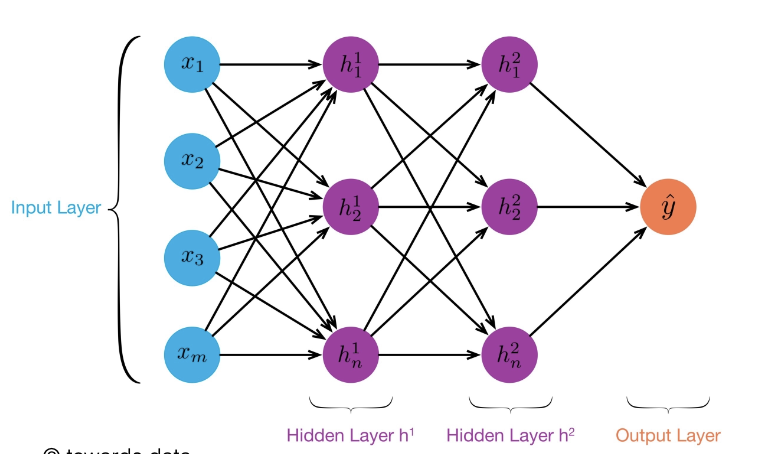
multi-layer perceptron for non-linear classification: deep neural networks
when a network has more than on hidden layer
benefits
can learn hierarchical features
can capture more complex patterns in data
multi-layer perceptron for non-linear classification: feedforward neural networks
the simplest type of ANN where information moves in only one direction, from input to output
layers
input layer: receives the initial data
hidden layers: processes the information
output ayers: produces the final prediction
multi-layer perceptron for non-linear classification
activates at hidden layers can be viewed as features extracted as functions of inputs
every hidden layer presents a level of abstraction
number of layers is known as depth of ANN
advantages of ANN
handling complex relationships
automatic feature learning
versatility
high performance
scalability
transfer learning
disadvantages of ANN
black box nature
data hungry
computational resources
overfitting risk
hyperparameter tuning
data quality sensitivity
comparisons of algorithms/classifiers
K-means clustering
purpose: partitions data into K distinct, non-overlapping clusters
how it works: iteratively assigns data points to the nearest cluster center and updates center positions
hierarchical clustering
purpose: creates a tree-like structure of nested clusters
types: agglomerative (bottom-up), divisive (top-down)
DBSCAN (density-based spatial clustering of applications with noise):
purpose: identifies clusters of arbitrary shape based on the density of data points
advantage: can detect outliers and doesn't require specifying the number of clusters
principal component analysis (PCA):
purpose: reduces the dimensionality of data while preserving as much variance as possible
how it works: identifies orthogonal axes (principal components) that capture maximum variance
t-SNE (t-distributed stochastic neighbor embedding):
purpose: visualizes high-dimensional data in 2D or 3D space
advantage: preserves local structure, revealing clusters and patterns
UMAP (uniform manifold approximation and projection):
purpose: similar to t-SNE but preserves more global structure and is computationally faster